library(tidyverse)
library(dplyr)
library(readxl)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 5 Instructions
challenge_5
railroads
cereal
air_bnb
pathogen_cost
australian_marriage
public_schools
usa_households
Introduction to Visualization
Challenge Overview
Today’s challenge is to:
- read in a data set, and describe the data set using both words and any supporting information (e.g., tables, etc)
- tidy data (as needed, including sanity checks)
- mutate variables as needed (including sanity checks)
- create at least two univariate visualizations
- try to make them “publication” ready
- Explain why you choose the specific graph type
- Create at least one bivariate visualization
- try to make them “publication” ready
- Explain why you choose the specific graph type
R Graph Gallery is a good starting point for thinking about what information is conveyed in standard graph types, and includes example R code.
(be sure to only include the category tags for the data you use!)
Read in data
Read in one (or more) of the following datasets, using the correct R package and command.
- cereal.csv ⭐
- Total_cost_for_top_15_pathogens_2018.xlsx ⭐
- Australian Marriage ⭐⭐
- AB_NYC_2019.csv ⭐⭐⭐
- StateCounty2012.xls ⭐⭐⭐
- Public School Characteristics ⭐⭐⭐⭐
- USA Households ⭐⭐⭐⭐⭐
library(readxl)
# xlsx files
statecounty <- read_excel("_data/statecounty2012.xls",skip=4,col_names= c("state", "delete", "county",
"delete", "employees"))%>%select(-2,-4)%>%
filter(!str_detect(state, "Total"))%>%
filter(!str_detect(state,"Military"))%>%
filter(!str_detect(state,"NOTE"))
statecounty# A tibble: 2,931 × 3
state county employees
<chr> <chr> <dbl>
1 AE APO 2
2 AK ANCHORAGE 7
3 AK FAIRBANKS NORTH STAR 2
4 AK JUNEAU 3
5 AK MATANUSKA-SUSITNA 2
6 AK SITKA 1
7 AK SKAGWAY MUNICIPALITY 88
8 AL AUTAUGA 102
9 AL BALDWIN 143
10 AL BARBOUR 1
# … with 2,921 more rows State_total <- statecounty%>%group_by(state)%>%mutate(employees_total=sum(employees))
State_total# A tibble: 2,931 × 4
# Groups: state [54]
state county employees employees_total
<chr> <chr> <dbl> <dbl>
1 AE APO 2 2
2 AK ANCHORAGE 7 103
3 AK FAIRBANKS NORTH STAR 2 103
4 AK JUNEAU 3 103
5 AK MATANUSKA-SUSITNA 2 103
6 AK SITKA 1 103
7 AK SKAGWAY MUNICIPALITY 88 103
8 AL AUTAUGA 102 4257
9 AL BALDWIN 143 4257
10 AL BARBOUR 1 4257
# … with 2,921 more rows ggplot(State_total, aes(x=employees_total)) +
geom_histogram(bins=14)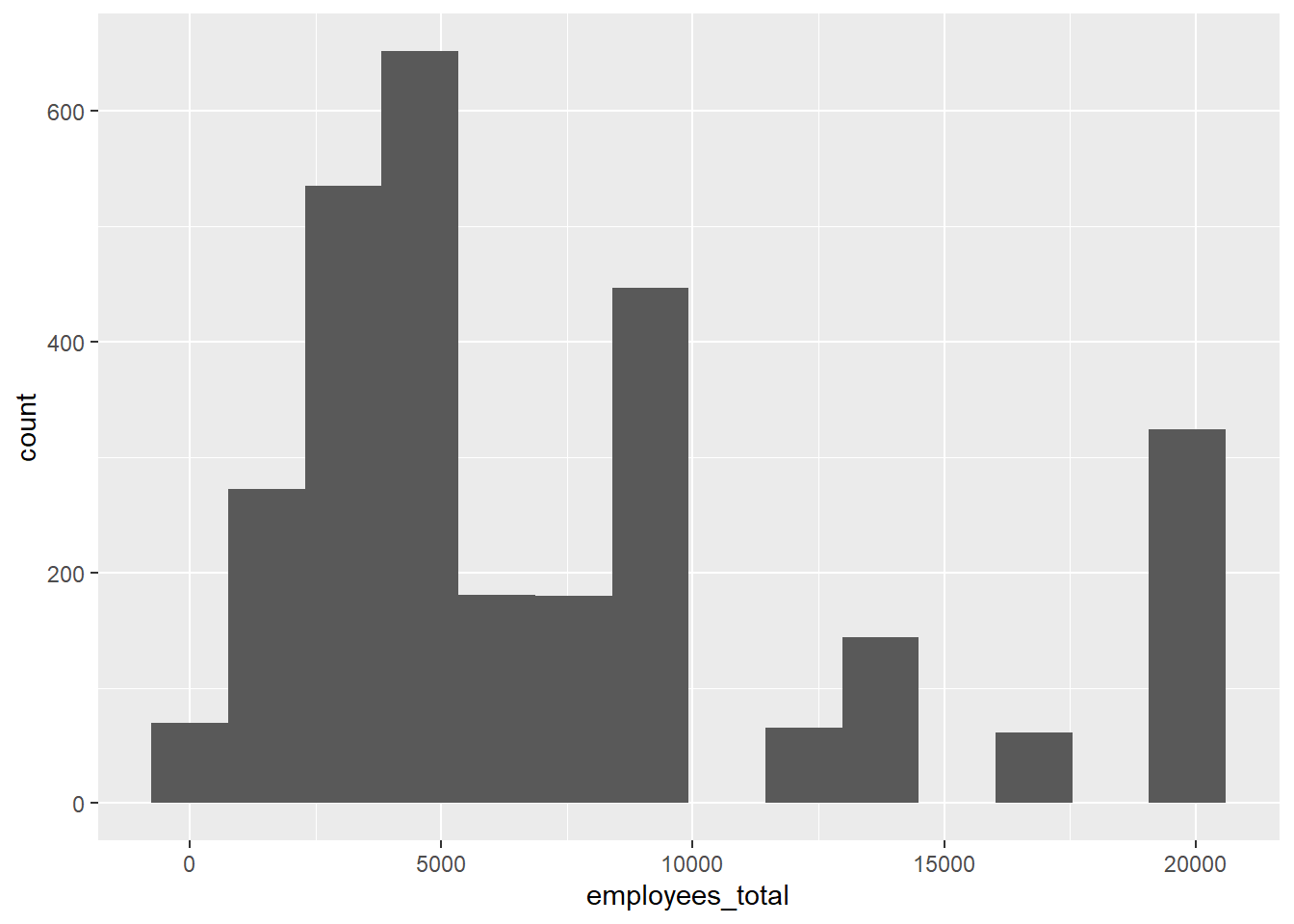
ggplot(State_total, aes(x=state,y=employees)) +
geom_boxplot()+scale_x_discrete(guide = guide_axis(n.dodge=10))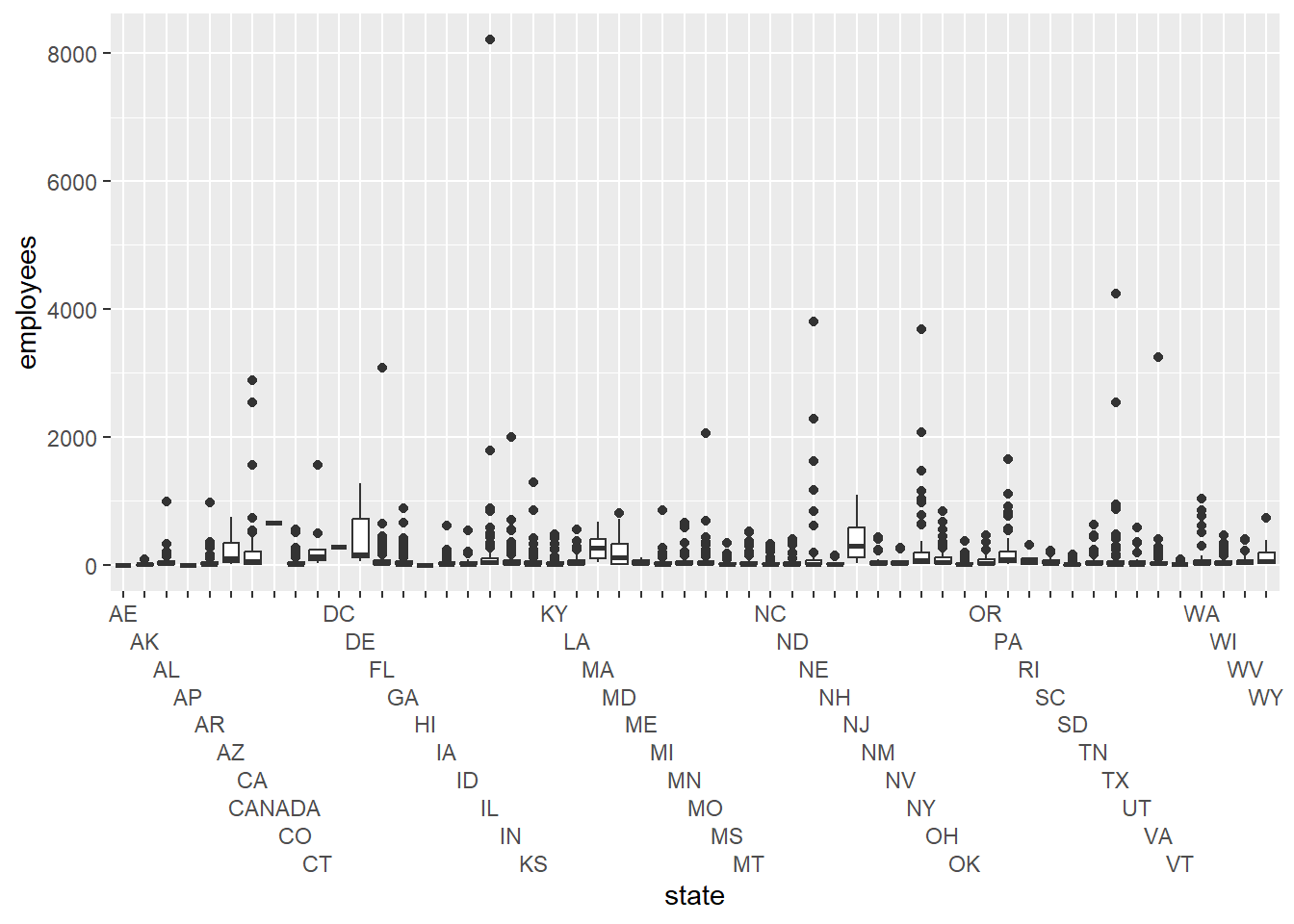
unique(State_total$state) [1] "AE" "AK" "AL" "AP" "AR" "AZ" "CA" "CO"
[9] "CT" "DC" "DE" "FL" "GA" "HI" "IA" "ID"
[17] "IL" "IN" "KS" "KY" "LA" "MA" "MD" "ME"
[25] "MI" "MN" "MO" "MS" "MT" "NC" "ND" "NE"
[33] "NH" "NJ" "NM" "NV" "NY" "OH" "OK" "OR"
[41] "PA" "RI" "SC" "SD" "TN" "TX" "UT" "VA"
[49] "VT" "WA" "WI" "WV" "WY" "CANADA"Briefly describe the data
Tidy Data (as needed)
Is your data already tidy, or is there work to be done? Be sure to anticipate your end result to provide a sanity check, and document your work here.
Are there any variables that require mutation to be usable in your analysis stream? For example, do you need to calculate new values in order to graph them? Can string values be represented numerically? Do you need to turn any variables into factors and reorder for ease of graphics and visualization?
Document your work here.
Univariate Visualizations
Bivariate Visualization(s)
Any additional comments?