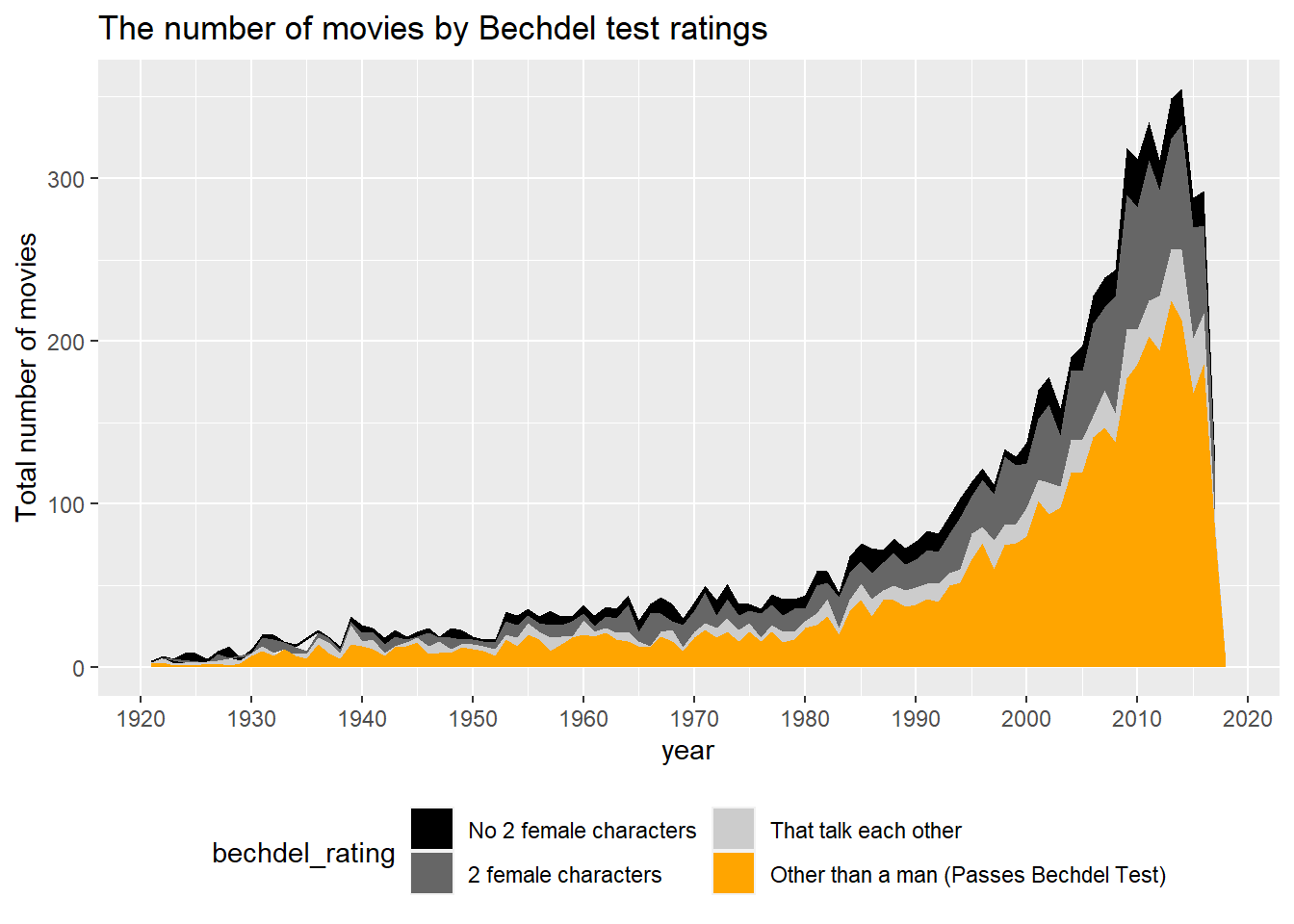
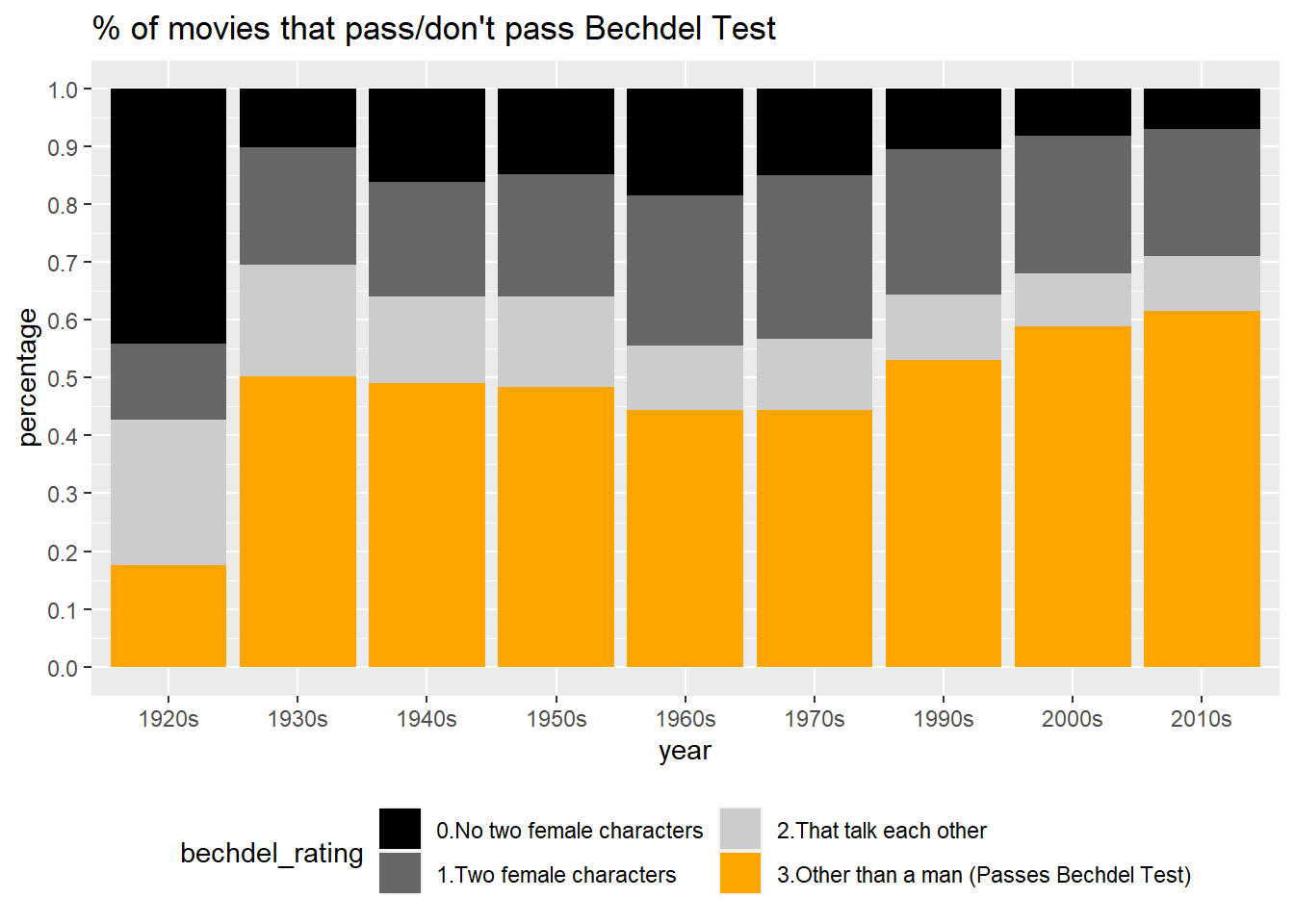
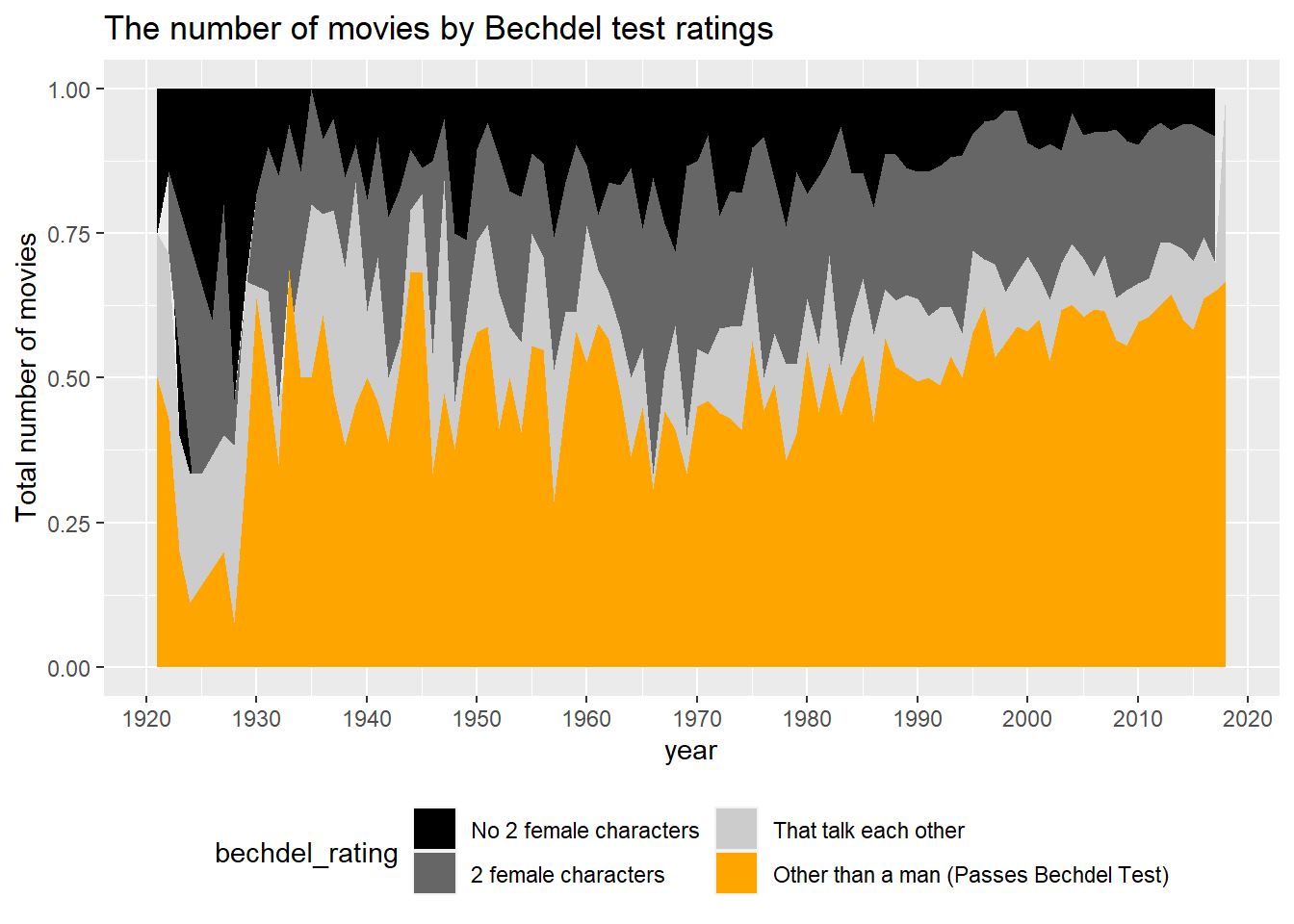
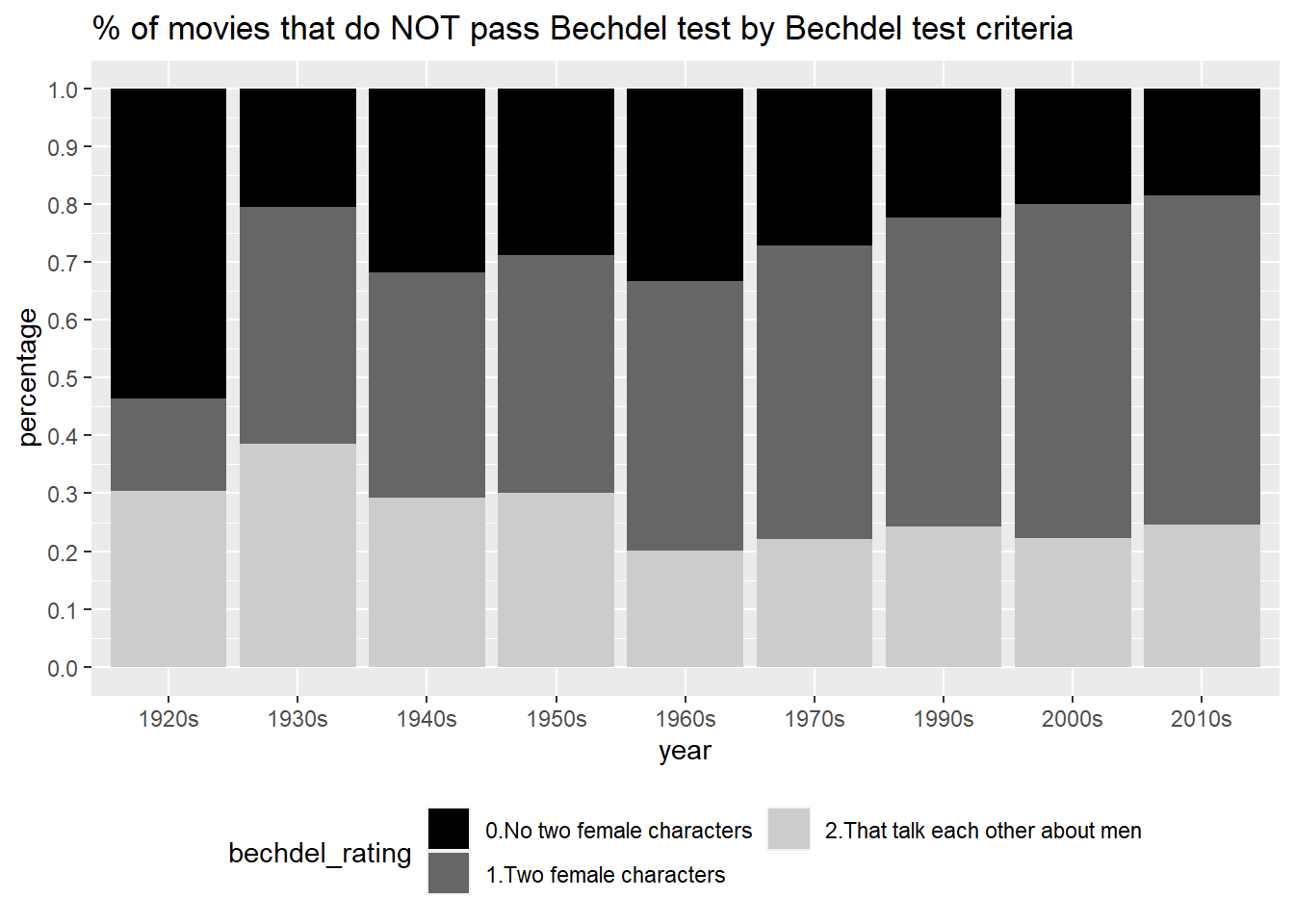
Rows: 7,736
Columns: 39
$ title <chr> "'71", "'Gator Bait", "'night, Mother", "(500) Da…
$ original_title <chr> "'71", "'Gator Bait", "'night, Mother", "(500) Da…
$ tagline <chr> NA, "UNTAMED AND DEADLY, she ruled the swamp with…
$ imdb_id <chr> "tt2614684", "tt0074080", "tt0090556", "tt1022603…
$ movielens_id <dbl> 252178, 88950, 34760, 19913, 45261, 8420, 8329, 1…
$ overview <chr> "A young British soldier must find his way back t…
$ production_companies <chr> " Screen Yorkshire, British Film Institute (BFI),…
$ production_countries <chr> "GB", "US", "US", "US", "US", "FR", "ES", "ES", "…
$ status <chr> "Released", "Released", "Released", "Released", "…
$ release_date <date> 2014-10-10, 1974-06-01, 1986-09-12, 2009-07-17, …
$ runtime <dbl> 99, 88, 96, 95, 96, 95, 78, 85, 80, 102, 95, 103,…
$ revenue <dbl> 1625847, 0, 442000, 60722734, 230600, 0, 30448000…
$ budget <dbl> 0.00e+00, 0.00e+00, 0.00e+00, 7.50e+06, 0.00e+00,…
$ original_language <chr> "en", "en", "en", "en", "en", "fr", "es", "es", "…
$ spoken_languages <chr> " en", " en", " en", " en, fr, sv", " en", " en, …
$ genres <chr> "[{'id': 53, 'name': 'Thriller'}, {'id': 28, 'nam…
$ War <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ Drama <dbl> 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0…
$ Action <dbl> 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0…
$ Thriller <dbl> 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0…
$ Crime <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0…
$ Western <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0…
$ Documentary <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ Romance <dbl> 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0…
$ Family <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1…
$ Animation <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ Comedy <dbl> 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1…
$ Horror <dbl> 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0…
$ Mystery <dbl> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ Adventure <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0…
$ History <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ ScienceFiction <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0…
$ Fantasy <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0…
$ Music <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ years <chr> "2010s", "1970s", "1990s", "2000s", "2000s", "195…
$ id <dbl> 5159, 9738, 3155, 434, 7382, 3409, 3646, 4764, 50…
$ year <dbl> 2014, 1973, 1986, 2009, 2009, 1956, 2007, 2009, 2…
$ bechdel_rating <fct> 0, 0, 3, 1, 1, 3, 3, 1, 3, 2, 3, 3, 3, 1, 3, 1, 3…
$ bechdel_pass <fct> 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1…