library(tidyverse)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE)Read in a dataset
I decided to use a dataset from open source called The Armed Conflict Location & Event Data Project (ACLED) https://acleddata.com/about-acled/. One of my sphere of interests is social movements and protests but I have never worked with qualitative data related to this topic. So I decided to find related dataset.
library(readr)
protest_orig <- read.csv("_data/protest.csv", head = TRUE, sep=";")
library(summarytools)
Attaching package: 'summarytools'The following object is masked from 'package:tibble':
viewprint(
dfSummary(protest_orig,
varnumbers = FALSE,
na.col = FALSE,
style = "multiline",
plain.ascii = FALSE,
headings = FALSE,
graph.magnif = .8),
method = "render"
)| Variable | Stats / Values | Freqs (% of Valid) | Graph | Valid | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| data_id [integer] |
|
3734 distinct values |  |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| iso [integer] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| event_id_cnty [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| event_id_no_cnty [integer] |
|
2817 distinct values |  |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| event_date [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| year [integer] | 1 distinct value |
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| time_precision [integer] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| event_type [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| sub_event_type [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| actor1 [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| assoc_actor_1 [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| inter1 [integer] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| actor2 [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| assoc_actor_2 [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| inter2 [integer] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| interaction [integer] |
|
17 distinct values |  |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| region [character] | 1. Europe |
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| country [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| admin1 [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| admin2 [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| admin3 [logical] |
|
0 (0.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| location [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| latitude [numeric] |
|
615 distinct values |  |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| longitude [numeric] |
|
611 distinct values |  |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| geo_precision [integer] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| source [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| source_scale [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| notes [character] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| fatalities [integer] |
|
|
 |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| timestamp [integer] |
|
341 distinct values |  |
3734 (100.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| iso3 [character] |
|
|
 |
3734 (100.0%) |
Generated by summarytools 1.0.1 (R version 4.2.1)
2022-12-20
Brief description of the data
The dataset I use in this task contains information about protests and acts of political violence in 9 countries of Eastern and Central Europe in 2021.
- The dataframe includes 3734 cases. Each case is a protest event.
- There are 31 variables
- Variables that contain information about the event: date, event type, sub event type, actors (participants), place, source of information, notes (details of what happened during the protest) and number of fatalities.
- Variables that contain different numeric and character identifiers of the country, event, type, actors, interaction.
Clean the data
From the first sight, the data does not need much cleaning. For example, we do not see much missing data. However, it makes sense to
Remove certain columns. (1) For example, we can see name of the country and character identifier so we can leave one of them. (2) Also there is column “notes” which contains details of the event. It may be used only for qualitative analysis. (3) “Admin3” has all NA’s. “Admin2” is the same as “location” but in English, so I leave “location” and remove “admin2”. (4) All cases happened in Europe so it probably makes sense to remove column “region”. I will leave latitude and longitude in case one want to visualize a map. (5) I will remove some of the identifiers.
Organize dates
Replace empty sting
Mutate variables due to the codebook https://acleddata.com/acleddatanew/wp-content/uploads/2021/11/ACLED_Codebook_v1_January-2021.pdf
Transform variables with information about actors. In current dataset many actor (participant groups) has information about origin country in brackets. It may be some country or international. I would like to make from information in brackets another column.
# Leave selected columns
protest_data <- select(protest_orig, "data_id", "event_date", "year", "event_type", "sub_event_type", "actor1", "assoc_actor_1", "inter1", "actor2", "assoc_actor_2", "inter2", "interaction", "country", "admin1", "location", "latitude", "longitude", "source", "source_scale", "fatalities")
# Organize dates
library(stringr)
protest_data <- select(protest_data, !contains("year"))
protest_data <- protest_data %>%
mutate(event_date=str_remove(event_date,".2021"))%>%
mutate(event_date=str_replace_all(event_date, c(".12" = " Dec", ".11" = " Nov", ".10" = " Oct", ".09" = " Sep", ".08" = " Aug", ".07" = " Jul", ".06" = " Jun", ".05" = " May", ".04" = " Apr", ".03" = " Mar", ".02" = " Feb", ".01" = " Jan"))) %>%
separate(col=event_date, into=c("day", "month"), sep=" ", remove = TRUE)
# Replace empty sting with NA's
library(dplyr)
protest_data <- na_if(protest_data, '')
# Mutate variables due to the codebook
protest_data <- protest_data %>%
mutate(actor1_type = case_when(
inter1 == 1 ~ "State Forces",
inter1 == 3 ~ "Political Militas",
inter1 == 5 ~ "Rioters",
inter1 == 6 ~ "Protesters",
inter1 == 8 ~ "External/Other Forces"))
protest_data <- protest_data %>%
mutate(actor2_type = case_when(
inter2 == 1 ~ "State Forces",
inter2 == 3 ~ "Political Militas",
inter2 == 5 ~ "Rioters",
inter2 == 6 ~ "Protesters",
inter2 == 7 ~ "Civilians",
inter2 == 8 ~ "External/Other Forces",
inter2 == 0 ~ "NA"))
protest_data <- na_if(protest_data, 'NA')
protest_data <- select(protest_data, !contains("Inter1"))
protest_data <- select(protest_data, !contains("Inter2"))
protest_data <- protest_data %>%
mutate(interact_type = case_when(interaction == 10 ~ "sole military action",
interaction == 13 ~ "military versus political militia",
interaction == 15 ~ "military versus rioters",
interaction == 16 ~ "military versus protesters",
interaction == 17 ~ "military versus civilians",
interaction == 18 ~ "military versus other",
interaction == 33 ~ "political militia versus political militia",
interaction == 37 ~ "political militia versus civilians",
interaction == 50 ~ "sole rioter action",
interaction == 55 ~ "rioters versus rioters",
interaction == 56 ~ "rioters versus protesters",
interaction == 57 ~ "rioters versus civilians",
interaction == 58 ~ "rioters versus others",
interaction == 60 ~ "sole protester action",
interaction == 66 ~ "protesters versus protesters",
interaction == 78 ~ "other actor versus civilians",
interaction == 80 ~ "sole other action"))
protest_data <- select(protest_data, !contains("Interaction"))Clean the data: continuing
Variables with actors (actor1, assoc_actor_1, actor2, assoc_actor_2) are not clear. Some of them include countries in brackets, some contain several organizations or movements.
For actor1” and “actor2” I decided to separate name and country.
Next tasks: - Turn variables with information about actor1 into two variables (add country_from) - Turn variables with information about actor2 into two variables (add country_from2)
# Turn variables with information about actor1 into two variables (add country_from)
## Remove " " to prepare for separation
protest_data <- protest_data %>%
mutate(actor1=str_replace_all(actor1, c (" the Czech Republic" = " Czechia", "Czech Republic" = "Czechia", " the United Kingdom" = " UK", "United Kingdom" = "UK"))) %>%
mutate(actor1=str_replace_all(actor1, c ("Police Forces of" = "Police_Forces", "Military Forces of" = "Military_Forces", "Private Security Forces" = "Private_Security_Forces", "Unidentified Armed Group" = "Unidentified_Armed_Group", "Government of" = "Government"))) %>%
mutate(actor1=str_replace_all(actor1, c("PNL: National Liberal Party" = "PLN:_National_Liberal_Party (Poland)"))) %>%
mutate(actor1=str_replace_all(actor1, c (" Prison Guards" = " Prison_Guards", " Border Guards" = " Border_Guards", " Border Police" = " Border_Police")))
## Separate columns and tidy data
protest_data <- protest_data %>%
separate(col=actor1, into=c("actor_1", "country_from", "info3", "info4"), sep=" ", remove = FALSE)Warning: Expected 4 pieces. Missing pieces filled with `NA` in 3730 rows [1, 2,
3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].protest_data <- select(protest_data, !contains("info3"))
protest_data <- protest_data %>%
unite("actor_1", actor_1, info4, remove = TRUE)
protest_data <- protest_data %>%
mutate(actor_1 = str_remove(actor_1, "_NA"))
protest_data <- select(protest_data, !contains("info4"))
protest_data <- protest_data %>%
mutate(country_from=str_replace_all(country_from, "\\*|\\(|\\)", ""))
protest_data <- protest_data %>%
mutate(actor_1=str_replace_all(actor_1, c("_" = " ")))
protest_data <- rename(protest_data, "actor1_combined" = "actor1")
# Turn variables with information about actor2 into two variables (add country_from2)
## Remove " " to prepare for separation
protest_data <- protest_data %>%
mutate(actor2=str_replace_all(actor2, c (" the Czech Republic" = " Czechia", "Czech Republic" = "Czechia", " the United Kingdom" = " UK", "United Kingdom" = "UK"))) %>%
mutate(actor2=str_replace_all(actor2, c ("Police Forces of" = "Police_Forces", "Military Forces of" = "Military_Forces", "Private Security Forces" = "Private_Security_Forces", "Unidentified Armed Group" = "Unidentified_Armed_Group"))) %>%
mutate(actor2=str_replace_all(actor2, c("TISAP: There is Such A People" = "TISAP:_There_is_Such_A_People", "GERB: Citizens for European Development of" = "GERB:_Citizens_for_European_Development")))
## Separate columns and tidy data
protest_data <- protest_data %>%
separate(col=actor2, into=c("actor_2", "country_from2", "info3", "info4"), sep=" ", remove = FALSE)Warning: Expected 4 pieces. Additional pieces discarded in 1 rows [1981].Warning: Expected 4 pieces. Missing pieces filled with `NA` in 311 rows [1, 2,
4, 14, 15, 24, 28, 29, 30, 37, 48, 55, 67, 68, 69, 70, 159, 180, 191, 192, ...].protest_data <- select(protest_data, !contains("info3"))
protest_data <- protest_data %>%
unite("actor_2", actor_2, info4, remove = TRUE)
protest_data <- protest_data %>%
mutate(actor_2 = str_remove(actor_2, "_NA"))
protest_data <- select(protest_data, !contains("info4"))
protest_data <- protest_data %>%
mutate(country_from2=str_replace_all(country_from2, "\\*|\\(|\\)", "")) %>%
mutate(actor_2=str_replace_all(actor_2, c("_" = " ")))
protest_data <- rename(protest_data, "actor2_combined" = "actor2")
protest_data <- na_if(protest_data, 'NA')
# Unify countries names
protest_data <- protest_data %>%
mutate(actor1_combined = str_replace_all(actor1_combined, c (" Czechia" = " the Czech Republic", "Czechia" = "Czech Republic", " UK" = " the United Kingdom", "UK" = "United Kingdom"))) %>%
mutate(country_from = str_replace_all(country_from, c (" Czechia" = " the Czech Republic", "Czechia" = "Czech Republic", " UK" = " the United Kingdom", "UK" = "United Kingdom"))) %>%
mutate(actor2_combined = str_replace_all(actor2_combined, c (" Czechia" = " the Czech Republic", "Czechia" = "Czech Republic", " UK" = " the United Kingdom", "UK" = "United Kingdom"))) %>%
mutate(country_from2 = str_replace_all(country_from2, c (" Czechia" = " the Czech Republic", "Czechia" = "Czech Republic", " UK" = " the United Kingdom", "UK" = "United Kingdom")))Clean the data: continuing
Columns “assoc_actor_1” and “assoc_actor_2” contain information about organizations, movements or institutions which took part in the protest and countries they are from. But one cell may contain several organisation and several countries. So first I am going to separate each organization.
Another problem is that unlike “actor1” and “actor2”, “assoc_actor_1” and “assoc_actor_2” have many names of specific organizations. Sometimes name include countries sometimes country is written in brackets. So to me it seems impossible to separate information about organization and country because we need to check a lot of strings and write down the countries by hand. So for now I think one who will work with such dataset need to work with a specific names. I decided to leave them as well as “actor1_combined” and “actor2_combined” but I am not sure if it is right thing to do.
# Turn variables with information about assoc_actor_1 into several variables
## Separate organizations
protest_data <- protest_data %>%
separate(col=assoc_actor_1, into=c("assoc_actor1_A", "assoc_actor1_B", "assoc_actor1_C", "assoc_actor1_D", "assoc_actor1_E", "assoc_actor1_F", "assoc_actor1_G", "assoc_actor1_H", "assoc_actor1_I", "assoc_actor1_J"), sep=";", remove = TRUE)Warning: Expected 10 pieces. Missing pieces filled with `NA` in 2497 rows [1, 3,
4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 18, 19, 20, 21, 22, 24, ...].# Turn variables with information about assoc_actor_2 into several variables
## Separate organizations
protest_data <- protest_data %>%
separate(col=assoc_actor_2, into=c("assoc_actor2_A", "assoc_actor2_B", "assoc_actor2_C", "assoc_actor2_D", "assoc_actor2_E"), sep=";", remove = TRUE)Warning: Expected 5 pieces. Missing pieces filled with `NA` in 147 rows [1,
4, 14, 15, 24, 28, 29, 30, 48, 55, 67, 68, 69, 70, 159, 180, 191, 192, 199,
203, ...].# Relocate columns
protest_data <- protest_data %>%
relocate(actor1_type, .after = sub_event_type) %>%
relocate(actor2_type, .after = assoc_actor1_J) %>%
relocate(interact_type, .after = assoc_actor2_E)Provide a narrative about the data set
The dataset gives information about protests and acts of political violence in 9 countries of Eastern and Central Europe in 2021. The countries included in the dataframe are Bulgaria, Czech Republic, Estonia, Hungary, Latvia, Lithuania, Poland, Romania, Slovakia. The cases are events. So we have all information about the protest event. When and where it happened, who took part in it, was it peaceful or violet, how many fatalities it had and from which source we know about it.
- What happened? Variables “event_type”, “sub_event_type” and “fatalities” gives information about how we categorize political event. “event_type”, “sub_event_type” are categorical variables which mean type of the event and basically refer to different levels and types of radicalization during the protest.
ggplot(protest_data, aes(event_type)) + geom_bar()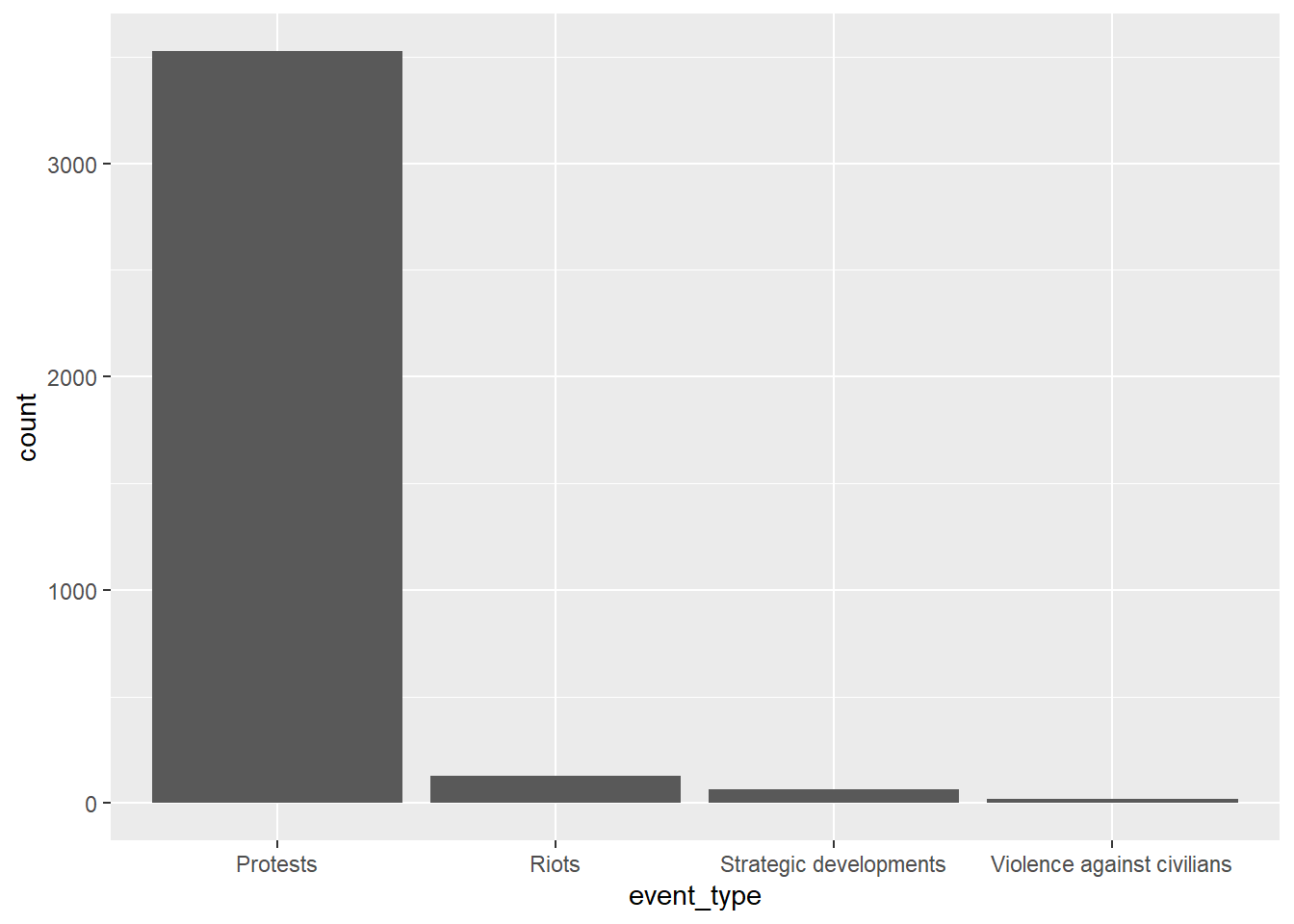
table(protest_data$fatalities)
0 1 2 5
3728 4 1 1 When the event happened? Variables “day” and “month” contains information about event date.
Where it happened? There are several variables which help to understand where protest took place. They all are categorical. First, we know “country”, second, administrative division (“admin1”),third, city or village (“location”). Columns “longitude” and “latitude” may be used to visualize a map of events.
ggplot(protest_data, aes(country)) + geom_bar()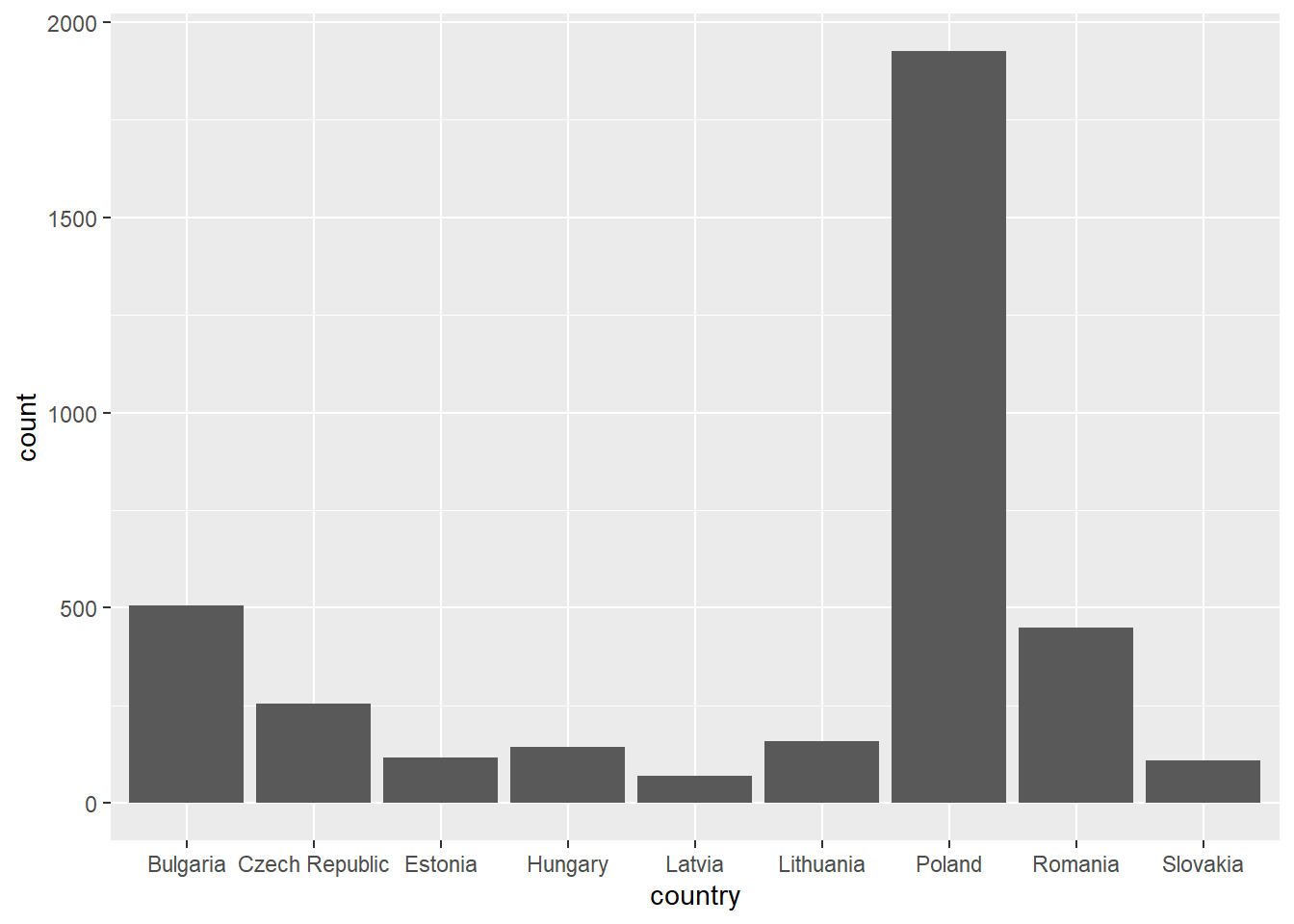
- Who participated?
Variables “actor1_type” and “actor2_type” give information about type of group which took part in the protest. Actor one has 5 types, actor two 6. “Interact_type” contains 17 types of interaction which are different combinations of “actor1_type” and “actor2_type”. These variables are categorical.
Variables “actor_1” and “actor_2” contain more specific information about groups which participated. “Country_from1” and “country_from2” refer to countries these groups are from.
These values were taken from “actor1_combined” and “actor2_combined” which contain information about group and county in one column.
From “Assoc_actor1_A” to “Assoc_actor1_J” and from “Assoc_actor2_A” to “Assoc_actor2_E” we can see names of organizations or more specific information about groups.
table(protest_data$actor1_type)
External/Other Forces Political Militas Protesters
7 20 3525
Rioters State Forces
128 54 - Also we have source of data in “source” which indicates name of the paper or web source. “source_scale” refers to type of source.
Identify potential research questions that your dataset can help answer
Data may be used to see how different countries react to different types of violence at political protests. Also we can do some descriptive statistics and look which type of protest in which countries happened more often in 2021.
I think it might be also interesting to look if news about more violent protests went to national or international scale of papers and magazines. And if news for example about peaceful protest are as important for national scale media as violent.