library(tidyverse)
library(ggplot2)
library(readxl)
library(lubridate)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 7
challenge_7
Transaction Data
Visualizing Multiple Dimensions
Below I have read in the inventory transaction data. There will be more detail about that data set to follow. On the read in, I have eliminated unnecessary columns, as well as observations that are not relevant to our findings.
transactions_sept_oct_orig <- read_excel("Inventory Transactions 9_1_2022-11_3_2022.xlsx",
skip = 5,
col_names = c("pos_id","product","delete","patient_name","transaction_date","qty_sold","daily_allottment_oz","weight_grams","cost","price","owner_name","owner_location","vendor","sold_by","receipt_no","delete","delete","delete","delete","delete"))%>%
filter(sold_by != "Michaela Bowen")%>%
select(!contains("delete"))The transactions data frame we are working with consist of the completed sales transactions at Resinate, Northampton Spanning from 09/01/2022 through 11/03/2022. There are 25,880 instances of 14 variables, meaning that nearly 26,000 items were sold during this time period, between nearly 7,700 transactions. Each instance is a product sold, rather than a complete transaction. All products were sold by 8 employees during this time. The variables describe the product type, category, date, patient name, receipt number, budtender, and other transaction information.
#number of products sold
nrow(transactions_sept_oct_orig)[1] 25883#number of transactions
n_distinct(transactions_sept_oct_orig$receipt_no)[1] 7734#number of employees
n_distinct(transactions_sept_oct_orig$sold_by)[1] 8#number of customers
n_distinct(transactions_sept_oct_orig$patient_name)[1] 5121Tidy Data
Mutated Columns:
date: I am separating out this date column into hour, minute, and second in order to pin point time of day in which customers are ordering certain products.category,category_names: I created these two variables from the 3 letter abbreviation at the beginning of the product name. This will aid in isolating specific categories of product rather thantier: I am planning to create an ordinal column that has the Flower Tier Specification. A,B,C, and D describe the percentage of Total Active Canabinoids in each and thus determine their price.FirstName,LastName: I also separated the first and last name of the Budtender so that I could only include first names in the visualizationhouse_product: Boolean which states whether a product is 3rd Party or notisCannabis: Boolean which states whether a product is cannabis or non-cannabisweekdayLabel: Day of the Week
transactions_sept_oct_working <- transactions_sept_oct_orig%>%
#separating date, month, year, minute and second (thinking about removing second option, as it may not be useful)
mutate(
date = as.Date(transaction_date),
day = day(transaction_date),
hour = hour(transaction_date),
minute = minute(transaction_date),
second = second(transaction_date))%>%
mutate(
format_date = format(date, "%m/%d/%Y"),
format_hour = paste(hour, minute, second, sep = ":")
)%>%
#pulling the category abbreviation to determine category and create a category column
mutate(
category = substr(product,1,3)
)%>%
#changing the abbreviations into full category names
mutate(
category_names = case_when(
category == "FLO" | category == "Flo" ~ "Flower",
category == "PRJ" & weight_grams == 0.5 ~ "Joint 0.5g",
category == "PRJ" & weight_grams == 1 ~ "Joint 1g",
category == "PRJ" & weight_grams == 2.5 ~ "Joint 0.5g 5pk",
category == "PRJ" ~ "Other Joint",
category == "EDI" ~ "Edible",
category == "CON" | category == "Con" | category == "MIP" ~ "Concentrate",
category == "VAP" | category == "Vap" ~ "Vaporizer",
category == "ACC" | category == "Pax" | category == "PAX" | category == "Hig" | category == "Bov" ~ "Accessories",
category == "CLO" | category == "Res" ~ "Clothing",
category == "HTC" ~ "ignore",
category == "SAM" ~ "ignore",
category == "TOP" ~ "Topical",
category == "REW" ~ "ignore")
)%>%
#created a logical variable to determine if flower was in house, or 3rd party
mutate(
house_product = if_else((vendor == "Resinate, Inc."), "Resinate", "3rd Party", "NA")
)%>%
mutate(
flower_tier = case_when(
category_names == "Flower" & (price == 48 | price == 50) ~ "A Tier",
category_names == "Flower" & price == 45 ~ "B Tier",
category_names == "Flower" & price == 40 ~ "C Tier",
category_names == "Flower" & (price == 30 | price == 35) ~ "D Tier"
)
)%>%
#created an isCannabis boolean column to separate accessories from cannabis product
mutate(
isCannabis = case_when(
(category_names == "Flower" | category_names == "Joint 0.5g" | category_names == "Joint 1g"| category_names == "Other Joint" | category_names == "Joint 0.5g 5pk"| category_names == "Edible" | category_names == "Concentrate" | category_names == "Vaporizer" | category_names == "Topical") ~ TRUE,
(category_names == "Accessories" | category_names == "ignore" | category_names == "Clothing") ~ FALSE
))%>%
#separating the first and last names of the budtenders for anonymity purposes
extract(sold_by, c("FirstName", "LastName"), "([^ ]+) (.*)")%>%
#day of the week label
mutate(weekdayLabel = wday(date, label = TRUE))
#ensuring that the category, and category names columns contain no NA values and are accurately coded
unique(transactions_sept_oct_working$category_names) [1] "Joint 0.5g" "Flower" "Joint 1g" "Concentrate"
[5] "Edible" "Vaporizer" "Joint 0.5g 5pk" "Accessories"
[9] "Topical" "Other Joint" "ignore" "Clothing" unique(transactions_sept_oct_working$category) [1] "PRJ" "FLO" "MIP" "CON" "EDI" "VAP" "Hig" "TOP" "Bov" "ACC" "Pax" "SAM"
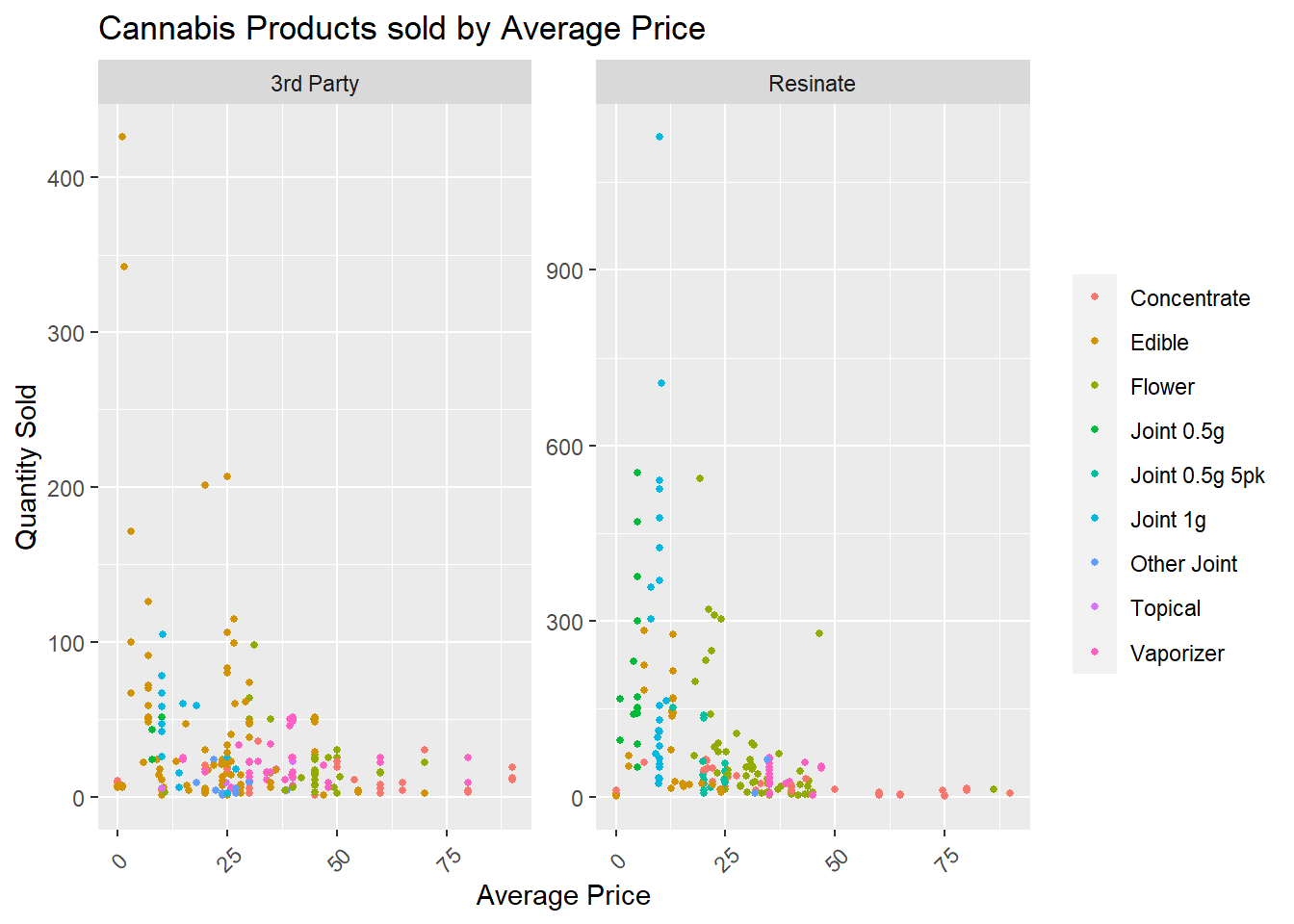
[13] "Res" "PAX" "HTC" "CLO" "REW"Below is the total items sold by Average price and category. It is further divided into 3rd Party and House product.
Simple Multi-Dimension Graph
sold_by_price <- transactions_sept_oct_working%>%
group_by(product)%>%
filter(isCannabis == TRUE)%>%
mutate(avg_price = mean(price),
products_sold = sum(qty_sold))%>%
select(-qty_sold)%>%
distinct()%>%
ggplot(aes(x = avg_price, y = products_sold, color = category_names)) +
ylim(0,NA) +
geom_point(size = 1)+
labs(title = "Cannabis Products sold by Average Price")+
xlab("Average Price") +
ylab("Quantity Sold") +
facet_wrap(vars(house_product), scales = "free_y") +
theme(legend.title=element_blank(),axis.text.x = element_text(angle = 45, vjust = 0.5) )
sold_by_price