Code
# install useful libraries
library(tidyverse)
library(stringr)
library(tidyr)
library(dplyr)
library(ggplot2)
library(summarytools)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)# install useful libraries
library(tidyverse)
library(stringr)
library(tidyr)
library(dplyr)
library(ggplot2)
library(summarytools)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Today’s challenge is to:
Read in one (or more) of the following datasets, using the correct R package and command.
This time, let’s use the “debt_intrillions.csv”
library(readxl)
data <- read_excel("_data/debt_in_trillions.xlsx")
head(data)# A tibble: 6 × 8
`Year and Quarter` Mortgage `HE Revolving` Auto …¹ Credi…² Stude…³ Other Total
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 03:Q1 4.94 0.242 0.641 0.688 0.241 0.478 7.23
2 03:Q2 5.08 0.26 0.622 0.693 0.243 0.486 7.38
3 03:Q3 5.18 0.269 0.684 0.693 0.249 0.477 7.56
4 03:Q4 5.66 0.302 0.704 0.698 0.253 0.449 8.07
5 04:Q1 5.84 0.328 0.72 0.695 0.260 0.446 8.29
6 04:Q2 5.97 0.367 0.743 0.697 0.263 0.423 8.46
# … with abbreviated variable names ¹`Auto Loan`, ²`Credit Card`,
# ³`Student Loan`The excel workbook “debt_in_trillions” shows the amount of debt by category (mortgage, HE Revolving, Auto Loan, Credit Card, Student Loan, other, and total) for each quarter from 2003 until 2021 Q2. This workbook doesn’t indicate but considering its huge amount we can guess that this data is information of debt amount of a country or some regions (definitely not individual or one organization).
This dataset consists of 8 columns and 74 lines. The following is the name of the columns.
Examining the excel worksheet exposes a number of important aspects of the data. * First column includes the last 2 digits of year and quarter * The value in eighth column is the sum of the values in second column through seventh column
str(data)tibble [74 × 8] (S3: tbl_df/tbl/data.frame)
$ Year and Quarter: chr [1:74] "03:Q1" "03:Q2" "03:Q3" "03:Q4" ...
$ Mortgage : num [1:74] 4.94 5.08 5.18 5.66 5.84 ...
$ HE Revolving : num [1:74] 0.242 0.26 0.269 0.302 0.328 0.367 0.426 0.468 0.502 0.528 ...
$ Auto Loan : num [1:74] 0.641 0.622 0.684 0.704 0.72 0.743 0.751 0.728 0.725 0.774 ...
$ Credit Card : num [1:74] 0.688 0.693 0.693 0.698 0.695 0.697 0.706 0.717 0.71 0.717 ...
$ Student Loan : num [1:74] 0.241 0.243 0.249 0.253 0.26 ...
$ Other : num [1:74] 0.478 0.486 0.477 0.449 0.447 ...
$ Total : num [1:74] 7.23 7.38 7.56 8.07 8.29 ...This is the overview of the dataset.
view(dfSummary(data))Also, the year values in “Year and Quarter” column are character and only the last two digits of the year so they should be converted to numeric values and then added 2000.
data1 <- data %>%
separate(`Year and Quarter`, c("Year", "Quarter"), sep=":", remove = FALSE)
data1$Year <- as.integer(data1$Year) + 2000data_long <- data1 %>%
pivot_longer(
cols = Mortgage:Total,
names_to = "type of debt",
values_to = "amount"
)In order to visualize the amount change every year, let’s summarize the data by year.
# Creating a data calculated by year
data_year <- data1 %>%
group_by(Year) %>%
summarise_at (vars(Mortgage:Other), list(mean))
head(data_year)# A tibble: 6 × 7
Year Mortgage `HE Revolving` `Auto Loan` `Credit Card` `Student Loan` Other
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2003 5.22 0.268 0.663 0.693 0.246 0.472
2 2004 6.09 0.397 0.736 0.704 0.300 0.426
3 2005 6.80 0.534 0.780 0.724 0.377 0.404
4 2006 7.87 0.595 0.806 0.746 0.450 0.422
5 2007 8.79 0.626 0.808 0.804 0.524 0.412
6 2008 9.26 0.685 0.804 0.853 0.604 0.410Any additional comments?
ggplot(data_year, aes(Year)) +
geom_line(aes(y=Mortgage, color="Mortgage")) +
geom_line(aes(y= `HE Revolving`, color="HE_Revolving")) +
geom_line(aes(y= `Auto Loan`, color="Auto_Loan")) +
geom_line(aes(y= `Credit Card`, color="Credit Card")) +
geom_line(aes(y= `Student Loan`, color="Student Loan"))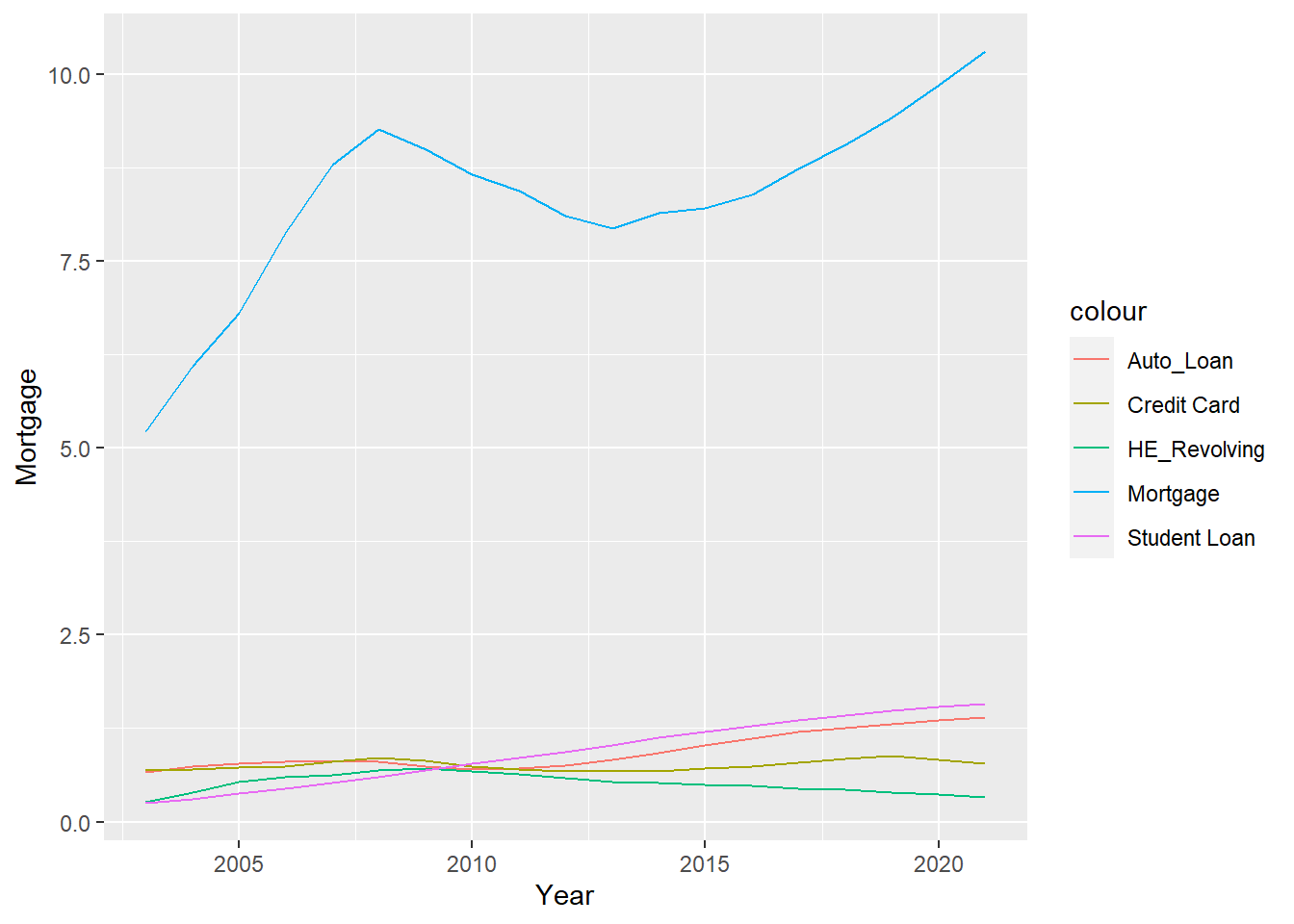
This graph tells that * Mortgage always accounts for the majority of debt. * All types of debt are on the rise except HE_Revolving. * Mortgage debt has decreased significantly in 2013.
Please note that the data of 2021 includes only two quarters.