library(tidyverse)
library(ggplot2)
library(dplyr)
library(summarytools)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 5 Instructions
challenge_5
air_bnb
Erika_Nagai
Introduction to Visualization
Challenge Overview
Today’s challenge is to:
- read in a data set, and describe the data set using both words and any supporting information (e.g., tables, etc)
- tidy data (as needed, including sanity checks)
- mutate variables as needed (including sanity checks)
- create at least two univariate visualizations
- try to make them “publication” ready
- Explain why you choose the specific graph type
- Create at least one bivariate visualization
- try to make them “publication” ready
- Explain why you choose the specific graph type
R Graph Gallery is a good starting point for thinking about what information is conveyed in standard graph types, and includes example R code.
(be sure to only include the category tags for the data you use!)
AB_NYC_2019.csv
Read in data
Using “read_csv” function, I read in AB_NYC_2019.csv as “ab_df”
ab_df = read_csv("_data/AB_NYC_2019.csv")Briefly describe the data
I explored this dataset to understand how it is structured and what kind of data is included
This dataset consists of 16 columns (variables) and 48895 rows. It includes the follwoing variables.
str(ab_df)spc_tbl_ [48,895 × 16] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ id : num [1:48895] 2539 2595 3647 3831 5022 ...
$ name : chr [1:48895] "Clean & quiet apt home by the park" "Skylit Midtown Castle" "THE VILLAGE OF HARLEM....NEW YORK !" "Cozy Entire Floor of Brownstone" ...
$ host_id : num [1:48895] 2787 2845 4632 4869 7192 ...
$ host_name : chr [1:48895] "John" "Jennifer" "Elisabeth" "LisaRoxanne" ...
$ neighbourhood_group : chr [1:48895] "Brooklyn" "Manhattan" "Manhattan" "Brooklyn" ...
$ neighbourhood : chr [1:48895] "Kensington" "Midtown" "Harlem" "Clinton Hill" ...
$ latitude : num [1:48895] 40.6 40.8 40.8 40.7 40.8 ...
$ longitude : num [1:48895] -74 -74 -73.9 -74 -73.9 ...
$ room_type : chr [1:48895] "Private room" "Entire home/apt" "Private room" "Entire home/apt" ...
$ price : num [1:48895] 149 225 150 89 80 200 60 79 79 150 ...
$ minimum_nights : num [1:48895] 1 1 3 1 10 3 45 2 2 1 ...
$ number_of_reviews : num [1:48895] 9 45 0 270 9 74 49 430 118 160 ...
$ last_review : Date[1:48895], format: "2018-10-19" "2019-05-21" ...
$ reviews_per_month : num [1:48895] 0.21 0.38 NA 4.64 0.1 0.59 0.4 3.47 0.99 1.33 ...
$ calculated_host_listings_count: num [1:48895] 6 2 1 1 1 1 1 1 1 4 ...
$ availability_365 : num [1:48895] 365 355 365 194 0 129 0 220 0 188 ...
- attr(*, "spec")=
.. cols(
.. id = col_double(),
.. name = col_character(),
.. host_id = col_double(),
.. host_name = col_character(),
.. neighbourhood_group = col_character(),
.. neighbourhood = col_character(),
.. latitude = col_double(),
.. longitude = col_double(),
.. room_type = col_character(),
.. price = col_double(),
.. minimum_nights = col_double(),
.. number_of_reviews = col_double(),
.. last_review = col_date(format = ""),
.. reviews_per_month = col_double(),
.. calculated_host_listings_count = col_double(),
.. availability_365 = col_double()
.. )
- attr(*, "problems")=<externalptr> print(summarytools::dfSummary(ab_df,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.80,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Data Frame Summary
ab_df
Dimensions: 48895 x 16Duplicates: 0
| Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id [numeric] |
|
48895 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| name [character] |
|
|
 |
16 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| host_id [numeric] |
|
37457 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| host_name [character] |
|
|
 |
21 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| neighbourhood_group [character] |
|
|
 |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| neighbourhood [character] |
|
|
 |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| latitude [numeric] |
|
19048 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| longitude [numeric] |
|
14718 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| room_type [character] |
|
|
 |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| price [numeric] |
|
674 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| minimum_nights [numeric] |
|
109 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| number_of_reviews [numeric] |
|
394 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| last_review [Date] |
|
1764 distinct values |  |
10052 (20.6%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| reviews_per_month [numeric] |
|
937 distinct values |  |
10052 (20.6%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| calculated_host_listings_count [numeric] |
|
47 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| availability_365 [numeric] |
|
366 distinct values |  |
0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.1)
2022-12-20
AB_NYC_2019 documents the information on the accommodation in New York (as you can figure out from the name of the original csv file and the average longitude and latitude) that is registered on Air BnB as of sometime in 2019. The information includes 1) id and name of the accommodation 2) id and name of the host 3) geographic information of the accommodation (neighbourhood_group, latitude, longitude) 4) reservation-related information of the accommodation (room type, price, minimum night per stay) 5) information of the reviews (date of last review, total number of review, average number of review per month) 6) days available of the accommodation per year
The accommodations without any review have NA (missing value) in last_review and reviews_per_month as we can see that the number of missing values in last_review and reviews_per_month (10052) matches the number of accommodations whose number_of_review is 0
ab_df %>% filter(`number_of_reviews` == 0) %>%
count()# A tibble: 1 × 1
n
<int>
1 10052Tidy Data
This dataset is quite tidy because one row means one observation (one accommodation), however it can be separated into host_df dataframe and accommodation_df dataframe to make this dataset cleaner and easier to use.
I created accommodation_df as follows removing host_name, calculated_host_listings_count columns. (* We should NOT remove host_id because it will be necessary if we want to join accomodation_df and host_df)
accommodation_df <- ab_df %>%
select(-c(host_name, calculated_host_listings_count))
head(accommodation_df)# A tibble: 6 × 14
id name host_id neigh…¹ neigh…² latit…³ longi…⁴ room_…⁵ price minim…⁶
<dbl> <chr> <dbl> <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl>
1 2539 Clean & q… 2787 Brookl… Kensin… 40.6 -74.0 Privat… 149 1
2 2595 Skylit Mi… 2845 Manhat… Midtown 40.8 -74.0 Entire… 225 1
3 3647 THE VILLA… 4632 Manhat… Harlem 40.8 -73.9 Privat… 150 3
4 3831 Cozy Enti… 4869 Brookl… Clinto… 40.7 -74.0 Entire… 89 1
5 5022 Entire Ap… 7192 Manhat… East H… 40.8 -73.9 Entire… 80 10
6 5099 Large Coz… 7322 Manhat… Murray… 40.7 -74.0 Entire… 200 3
# … with 4 more variables: number_of_reviews <dbl>, last_review <date>,
# reviews_per_month <dbl>, availability_365 <dbl>, and abbreviated variable
# names ¹neighbourhood_group, ²neighbourhood, ³latitude, ⁴longitude,
# ⁵room_type, ⁶minimum_nightsAnd here is host_df.
host_df <- ab_df %>%
select(c(host_id, host_name, calculated_host_listings_count))
head(host_df)# A tibble: 6 × 3
host_id host_name calculated_host_listings_count
<dbl> <chr> <dbl>
1 2787 John 6
2 2845 Jennifer 2
3 4632 Elisabeth 1
4 4869 LisaRoxanne 1
5 7192 Laura 1
6 7322 Chris 1host_df needs to be cleaned because it has several duplicated information. For example, host_id should be unique however the same host_id appear multiple times as the below table shows.
host_df %>% group_by(host_id) %>%
count() %>%
arrange(desc(n))# A tibble: 37,457 × 2
# Groups: host_id [37,457]
host_id n
<dbl> <int>
1 219517861 327
2 107434423 232
3 30283594 121
4 137358866 103
5 12243051 96
6 16098958 96
7 61391963 91
8 22541573 87
9 200380610 65
10 1475015 52
# … with 37,447 more rowsSo I removed duplicated rows by using distinct() function.
host_df <- host_df %>% distinct(host_id, .keep_all = TRUE) %>%
arrange(desc(calculated_host_listings_count))
head(host_df)# A tibble: 6 × 3
host_id host_name calculated_host_listings_count
<dbl> <chr> <dbl>
1 219517861 Sonder (NYC) 327
2 107434423 Blueground 232
3 30283594 Kara 121
4 137358866 Kazuya 103
5 16098958 Jeremy & Laura 96
6 12243051 Sonder 96Also, I renamed the column name calculated_host_listings_count to make it easier to understand
colnames(host_df)[3] <- "total_accommodation_count"
head(host_df)# A tibble: 6 × 3
host_id host_name total_accommodation_count
<dbl> <chr> <dbl>
1 219517861 Sonder (NYC) 327
2 107434423 Blueground 232
3 30283594 Kara 121
4 137358866 Kazuya 103
5 16098958 Jeremy & Laura 96
6 12243051 Sonder 96print(summarytools::dfSummary(host_df,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.80,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Data Frame Summary
host_df
Dimensions: 37457 x 3Duplicates: 0
| Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| host_id [numeric] |
|
37457 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| host_name [character] |
|
|
 |
18 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| total_accommodation_count [numeric] |
|
47 distinct values |  |
0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.1)
2022-12-20
Univariate Visualizations
First, I took a look at the price per night. Most accommodations are concentrated under $600 per night (though still expensive).
ggplot(accommodation_df, aes(price)) +
geom_histogram(aes(y= ..density.., binwidth = 20, alpha = 0.5)) +
geom_density(alpha = 0.5, fill="red")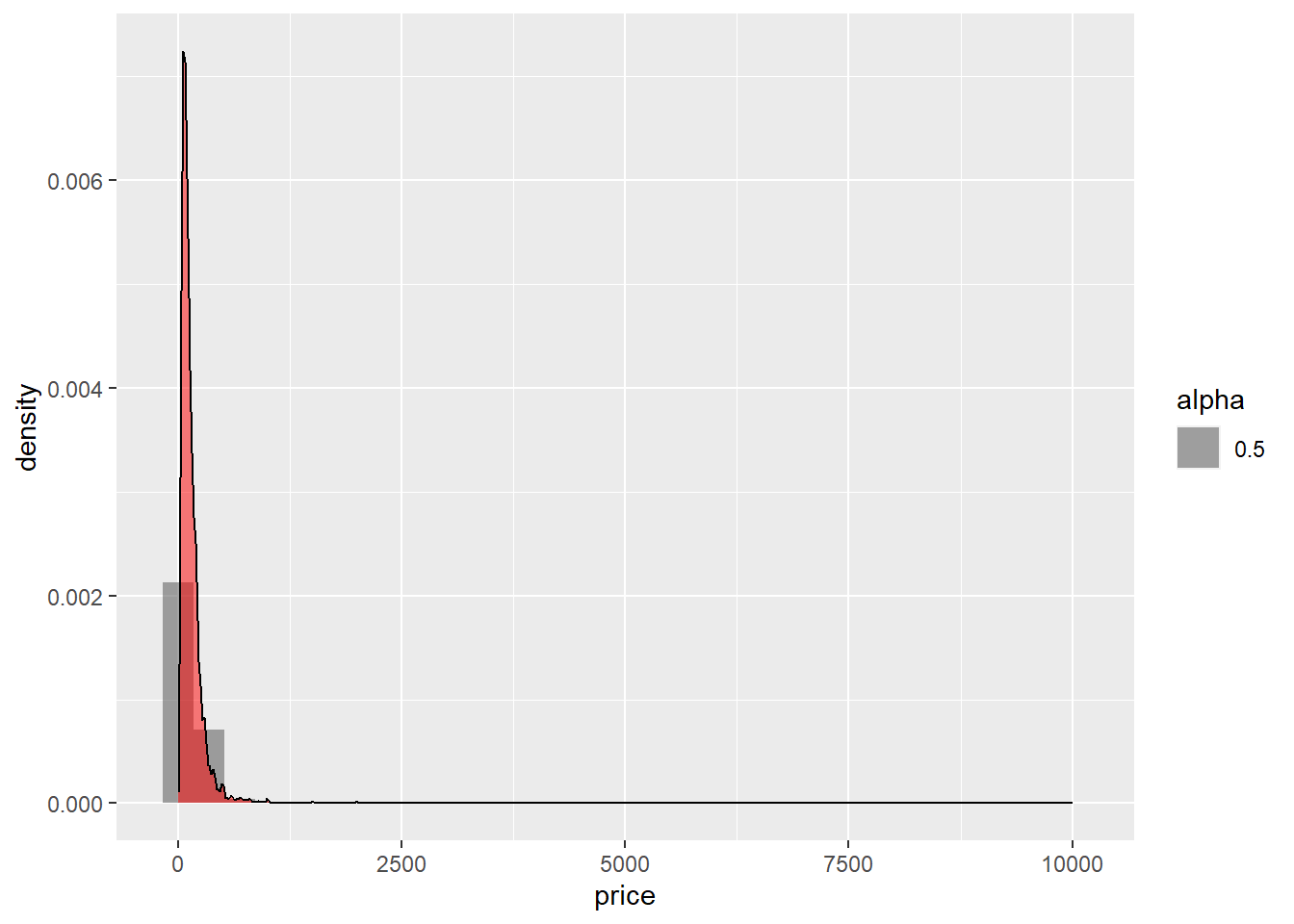
A box-and-whisker diagram shows that there are several Outliers that cost more than USD 2500 per night.
ggplot(accommodation_df, aes(price)) + geom_boxplot()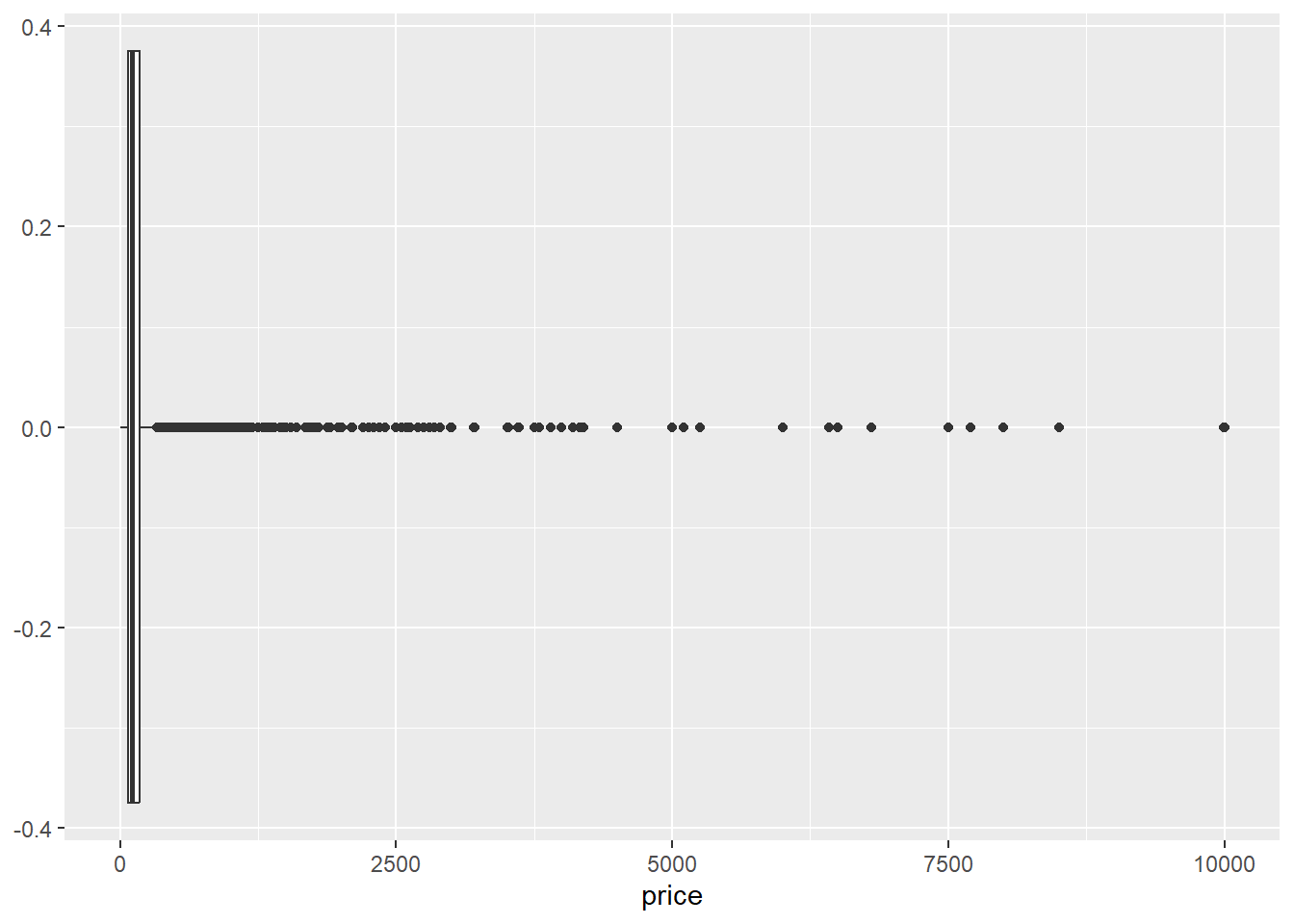
However, it is difficult to see the distribution of smaller values because of some extremely big values so we may need to filter out the accommodation whose price is high, so I decided to analyze only those accommodations whose rates fall between the first (69.0) and third quartiles (175.0)
summary(accommodation_df$price) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0 69.0 106.0 152.7 175.0 10000.0 Bivariate Visualization
ggplot(accommodation_df, aes(price)) +
geom_histogram(binwidth = 10) +
labs(title = "Price per night by room types") +
theme_bw() +
facet_wrap(vars(room_type))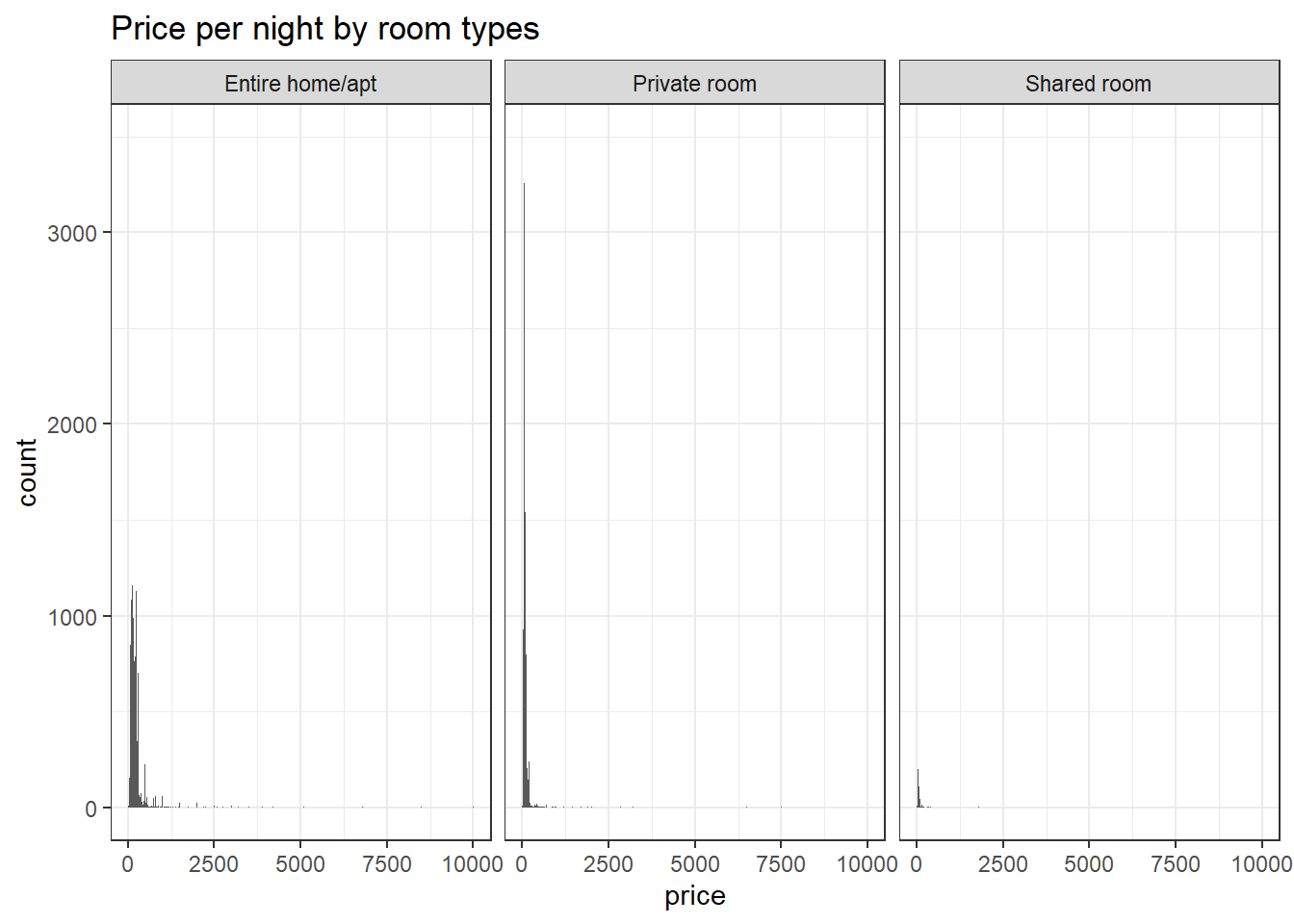
## TRY SCALE PACKAGELet’s take a look at the difference in price by room types and neighborhood. (Please note that this data does NOT include accommodation that don’t fall between IQR (69-175 USD)
# Room type
ggplot(accommodation_df %>% filter(price >= 69 & price<= 175), aes(price)) +
geom_histogram(binwidth = 10) +
labs(title = "Price per night by room types") +
theme_bw() +
facet_wrap(vars(room_type))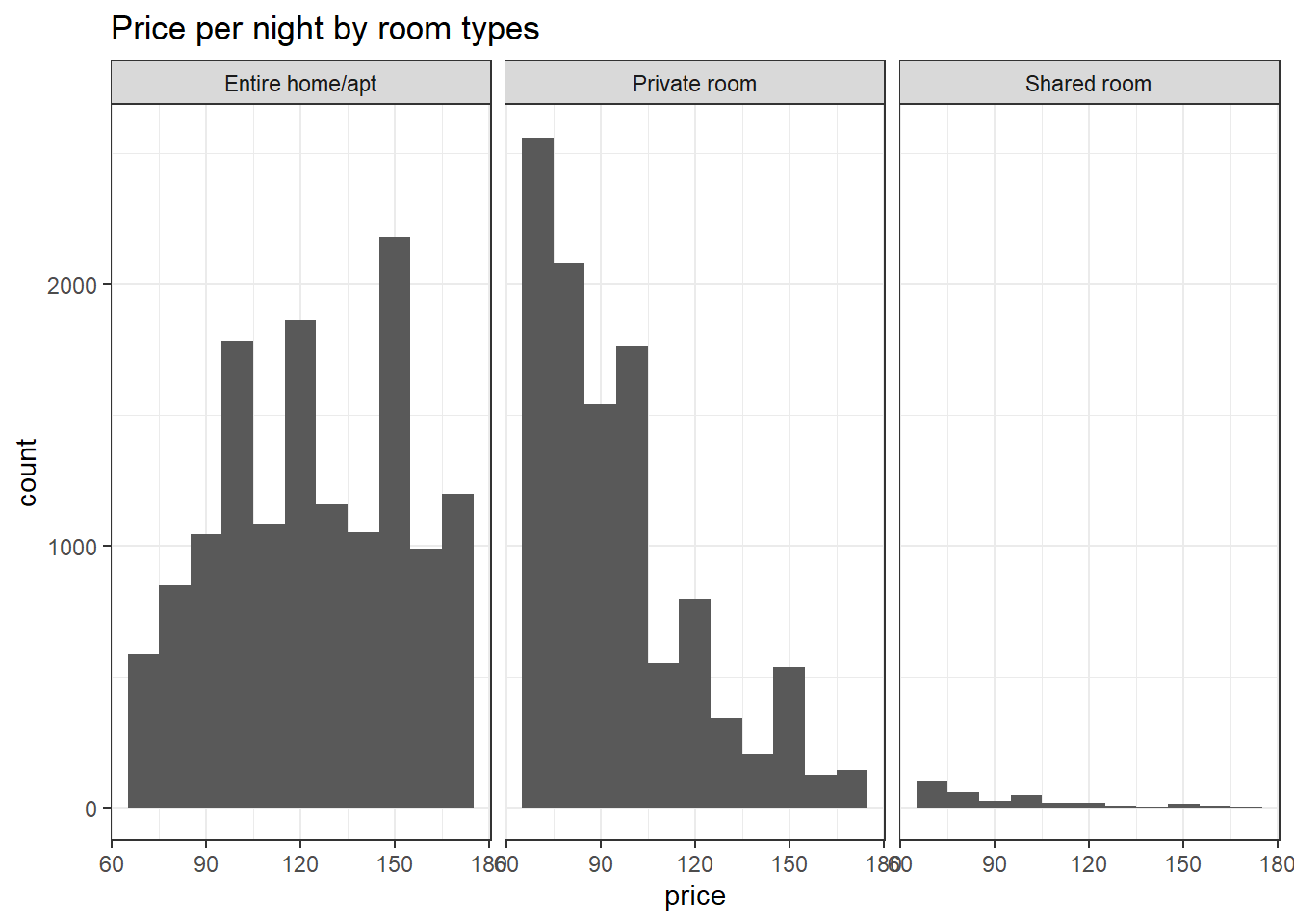
# Neighborhood
ggplot(accommodation_df %>% filter(price >= 69 & price <= 175), aes(price)) +
geom_histogram() +
labs(title = "price per night by neighborhood") +
theme_bw() +
facet_wrap(vars(neighbourhood_group))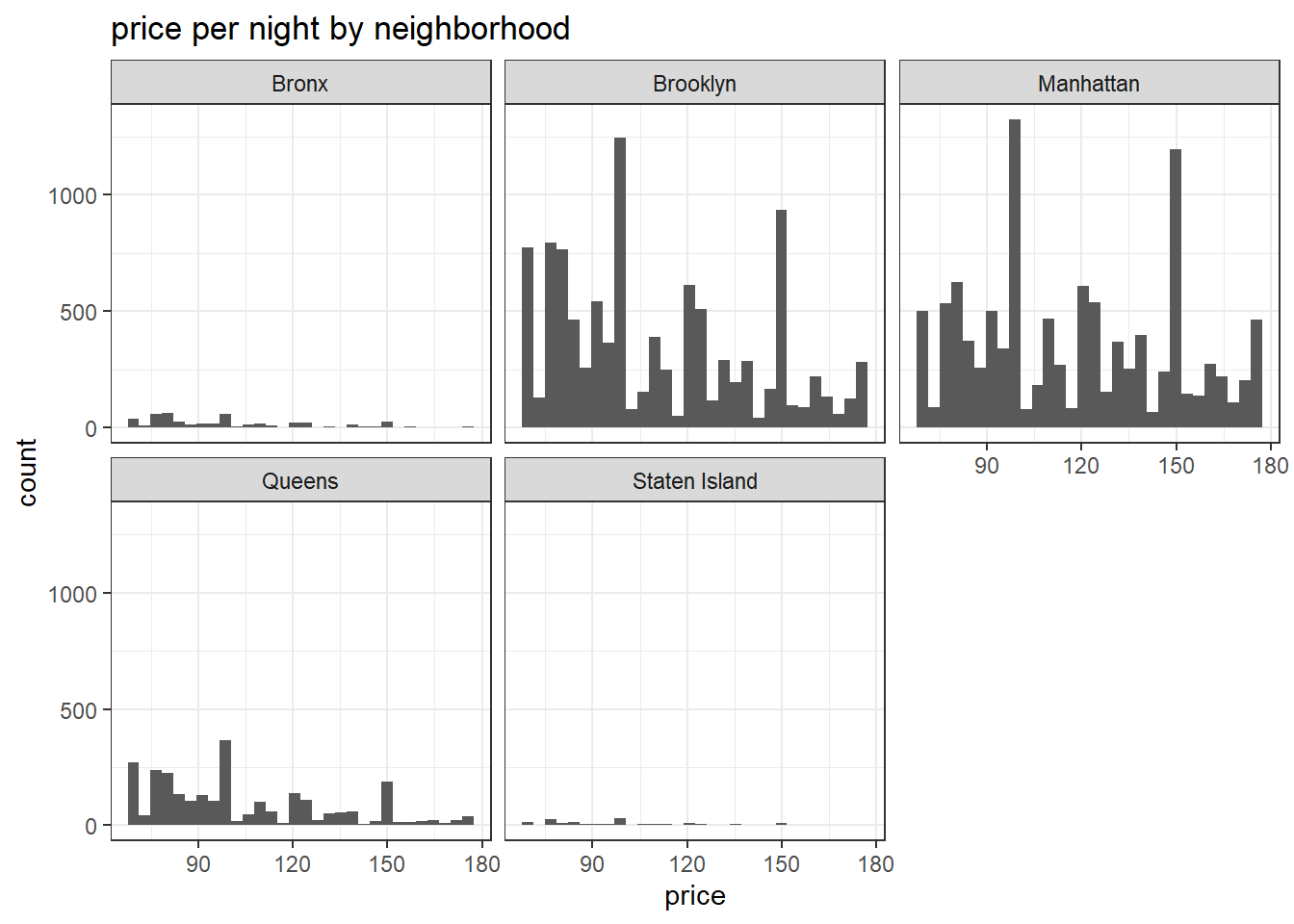
Question!
Since this dataset had some outliers that had a huge value in price and it was hard to visualize the distribution and trend so I decided to use the data that fall within IQR. I don’t know if it was good practice. What is your recommendation?