This dataset is one part of PISA 2018 dataset with a focus on schools. It covers 80 countries and different regions within each country. The dataset documents 21,903 schools’ responses regarding 187 questions. Some key identifiers include CNT (Country Name), STRATUM (Region Name) and OECD (belongs to or not OECD)
Tidy Data (as needed)
The dataset covers 80 countries and regions including 21903 schools’ responses regrading 187 questions. So I decided to narrow my reach here to five countries. I’d like to look at schools responses regarding a set of questions “SC155”. SC155 survey the accessibility to digital device and its related training as well as assistance. I clean the data and group_by data as regional code. I decided to concentrate my analysis on a series questions of digital device (SC115Q). So I make two different datasets at first. One includes all identifier information. The other covers the columns that contains “SC155Q”. Then, I use function “cbind” to combine these two into a new dataset (pisa2018_joint).Furthermore, I mutate 11 columns to calculate every country average regarding 11 questions. After that, I recognize the data with keeping columns of CNT, Region, OECD and 11 questions. Furthermore, I found that the questions from SC155Q01HA to SC155Q01HA focus on the accessibility to digital devices while the questions from SC155Q05HA to SC155Q11HA stress on if the schools offer enough training, support, and incentives. I mutate two new variables–“Accessibility” and “Human_Resource_Support that respectively calculate the average of the former and the latter. Besides, I caculate every country average for”Accessibility” and “Human_Resource_Support.” After tidying data, the dataset has four columns and 80 rows.
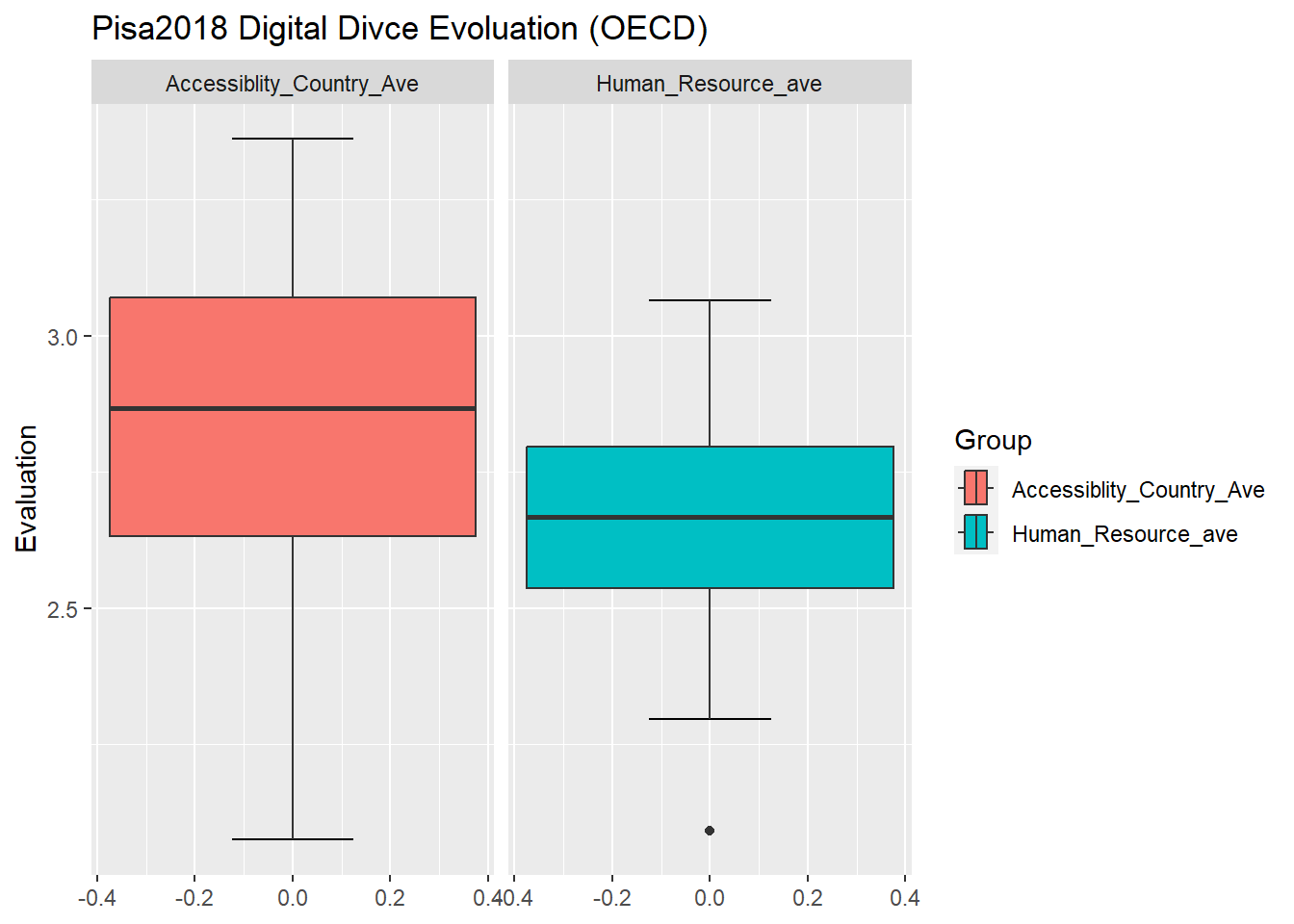
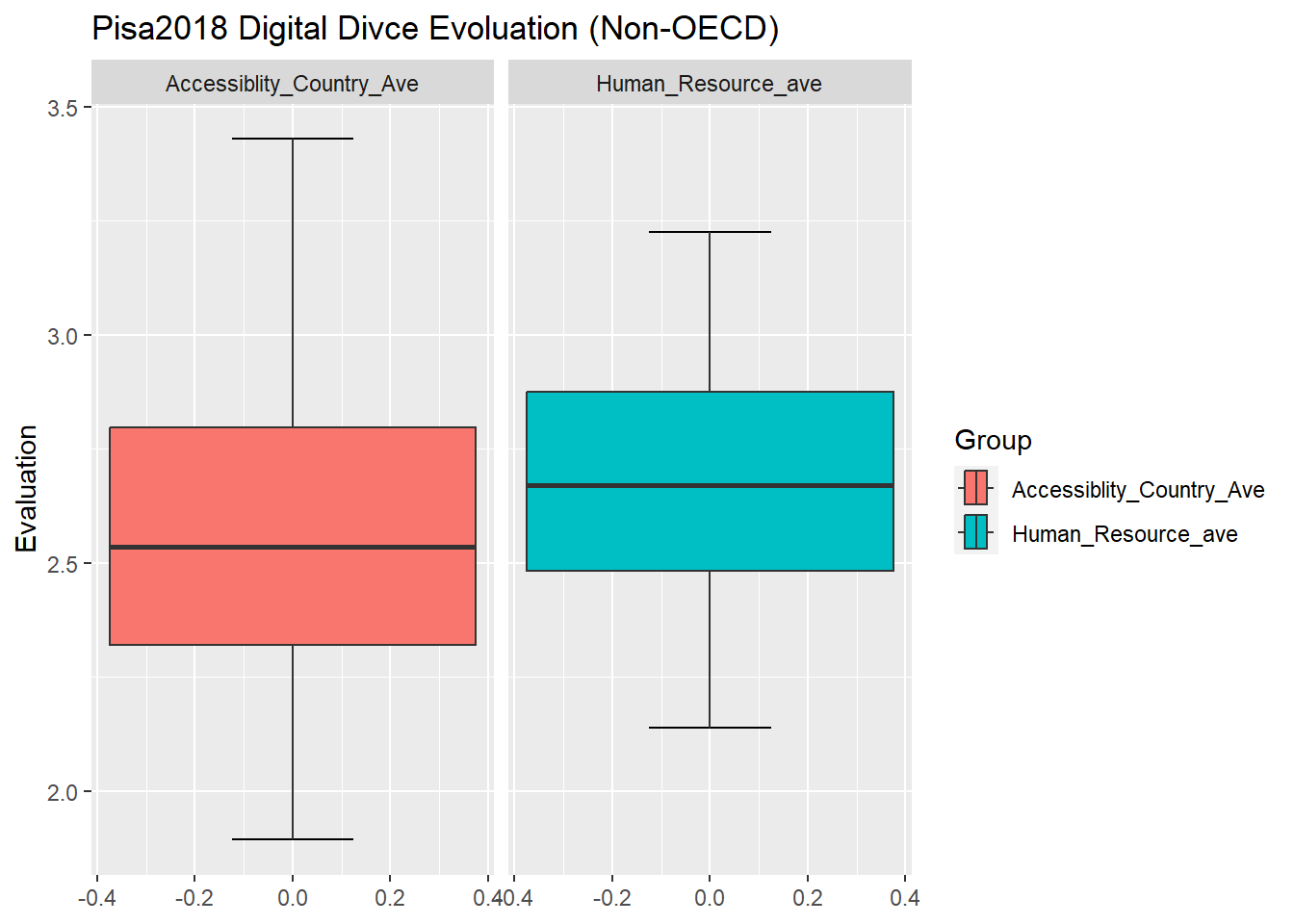
In order to further tidy data and create comparative graphics, I first used pivot_longer to create two new variables “Group” and “Evaluation”.I put the original variables–“Accessibility_Country_Ave” and “Human_Resource_ave” names to the “Group” and values to “Evaluation.” The box plot enjoys the reputation for clearly showing the distribution of a group of numbers, which allows me to disclose the distribution and general situation of every country’s evaluation on digital devices. After cleaning and rearranging the dataset, I create four graphics. The boxplot graphics reveal that the OECD countries enjoy the higher access to digital devices than non-OECD countries. But these two groups have reported that their human resource evaluations are in the similar range. The latter reflects the limits to this survey’s methodology. Because this survey is reliance on schools’ self-report. There is no any objective measurements for them to measure their access to and human resources support on digital devices. Therefore, instead of reflecting that OECD countries lack human resources support, the data may show OECD and non-OECD countries have distinct expectations on human resources support. So self-report can only demonstrate the gap between their expectations and current situations.
# choose five countries to look at regional difference within the countries# United Kingdom (GBR), Hong Kong (HKG), Philippines (PHL), Argentina (ARG), Brazil(BRA)pisa2018_joint_case_study <- pisa2018_joint %>%select(CNT, STRATUM, OECD, SC155Q01HA,SC155Q02HA, SC155Q03HA, SC155Q04HA, SC155Q05HA, SC155Q06HA, SC155Q07HA, SC155Q08HA, SC155Q09HA, SC155Q10HA, SC155Q11HA) %>%group_by(STRATUM) %>%arrange(STRATUM) %>%filter(CNT=="GBR"| CNT=="HKG"| CNT=="PHL"| CNT=="ARG"| CNT=="BRA"|CNT=="FRA" )pisa2018_joint_case_study
# A tibble: 2,114 × 14
# Groups: STRATUM [129]
CNT STRATUM OECD SC155Q0…¹ SC155…² SC155…³ SC155…⁴ SC155…⁵ SC155…⁶ SC155…⁷
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ARG ARG0101 0 1 1 1 1 1 2 2
2 ARG ARG0101 0 NA NA NA NA NA NA NA
3 ARG ARG0101 0 2 1 2 2 2 2 2
4 ARG ARG0101 0 2 1 2 3 2 2 1
5 ARG ARG0101 0 1 1 2 2 2 2 2
6 ARG ARG0101 0 3 2 3 2 2 2 1
7 ARG ARG0101 0 1 1 1 1 1 3 1
8 ARG ARG0101 0 1 1 1 1 1 1 1
9 ARG ARG0101 0 NA NA NA NA NA NA NA
10 ARG ARG0101 0 1 1 1 1 2 2 2
# … with 2,104 more rows, 4 more variables: SC155Q08HA <dbl>, SC155Q09HA <dbl>,
# SC155Q10HA <dbl>, SC155Q11HA <dbl>, and abbreviated variable names
# ¹SC155Q01HA, ²SC155Q02HA, ³SC155Q03HA, ⁴SC155Q04HA, ⁵SC155Q05HA,
# ⁶SC155Q06HA, ⁷SC155Q07HA
From the question of SC15501HA to SC15505HA focus on the accessibility to digital device while the rest of six questions focus on human resource (teachers’ training, assistance and motivation). So I decided to mutate two columns. One named “Accessibility’ refers to the average of the first five questions of SC155. The other one called”Human Resource Support” refers to the average of the rest six questions.
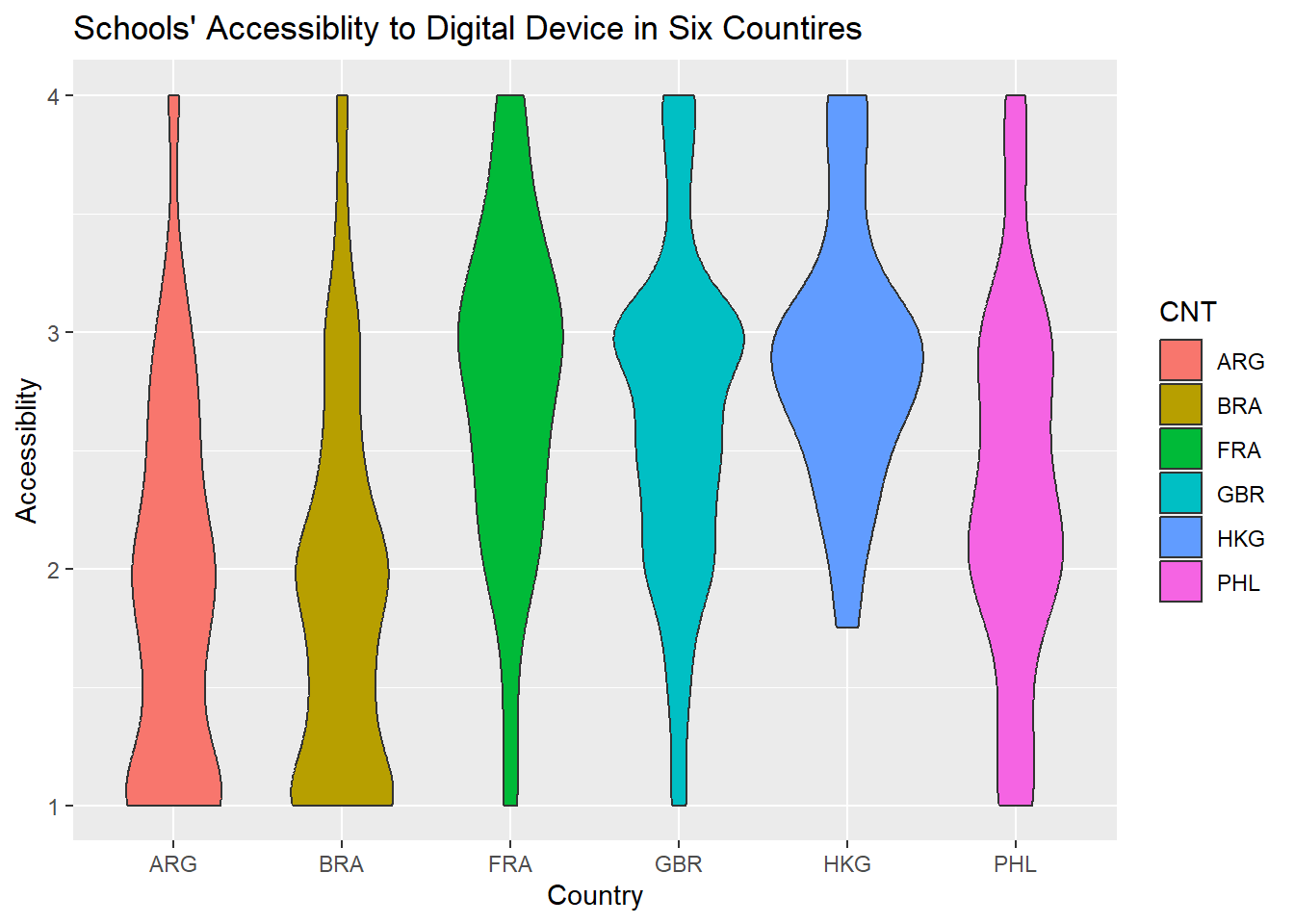
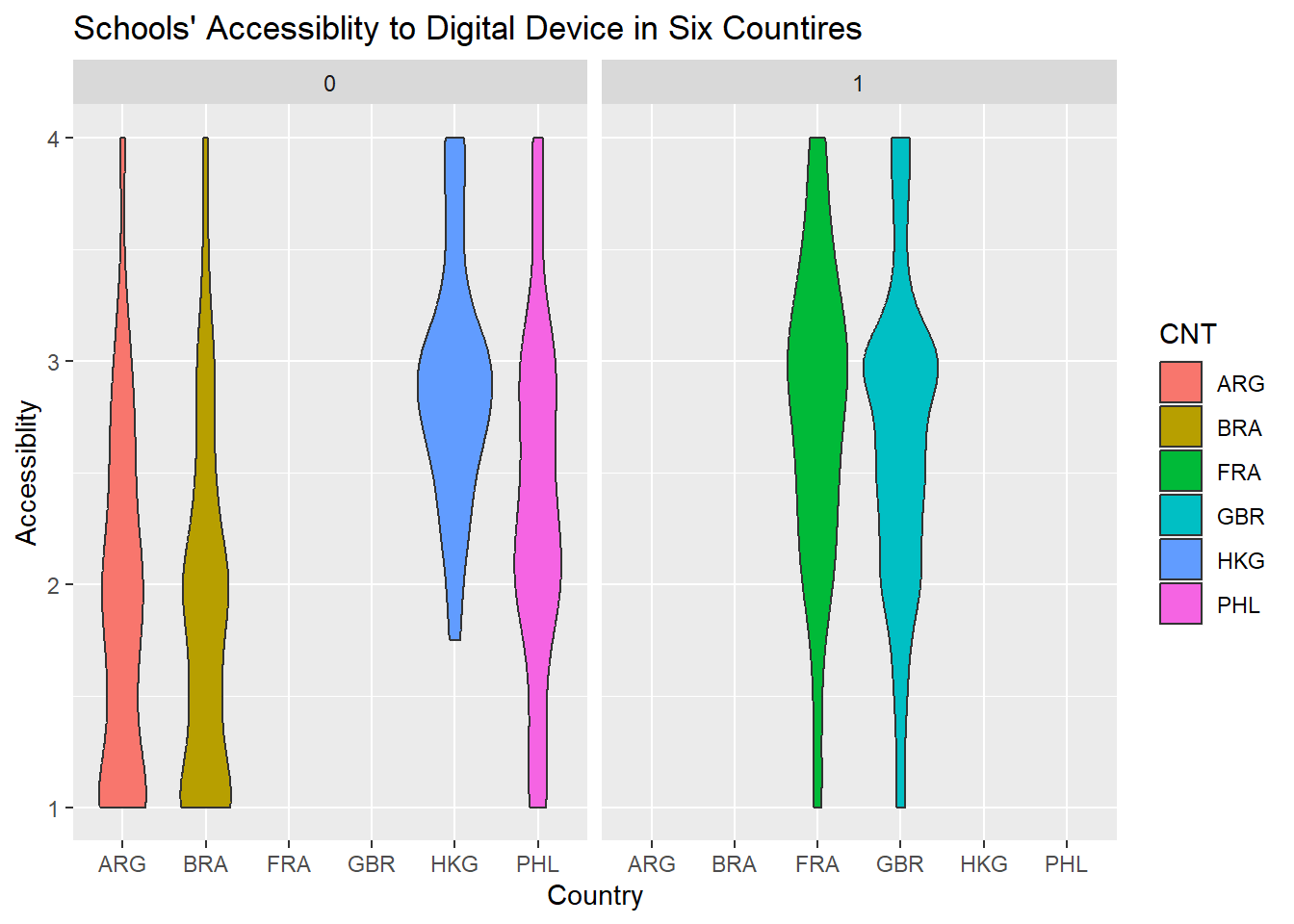
I produced the violin graphics to investigate the distribution of schools’ responses regarding accessibility to and human resource support for digital device. the graphics reveal that there are the limited access to digital advice in Brazil and Argentine. Many schools there expressed “strongly disagree.” By contrast, Schools in the United Kingdom and Hong Kong enjoyed smooth access to digital advice because most schools reported positive responses (3 means agree). The Philippines is between these two scenarios. most schools expressed “disagree” instead of “strongly disagree.” In terms of “Human Resource Support”
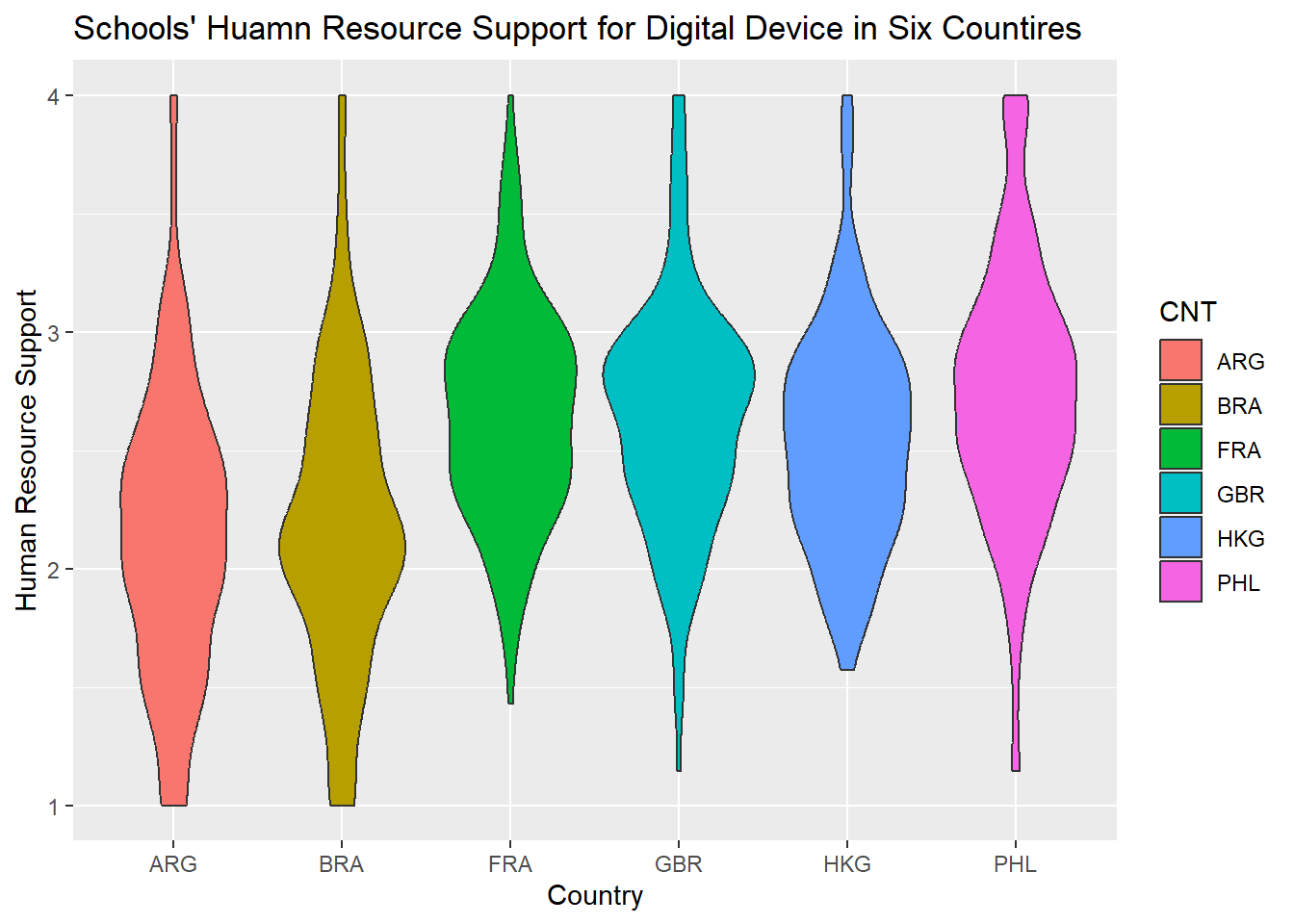
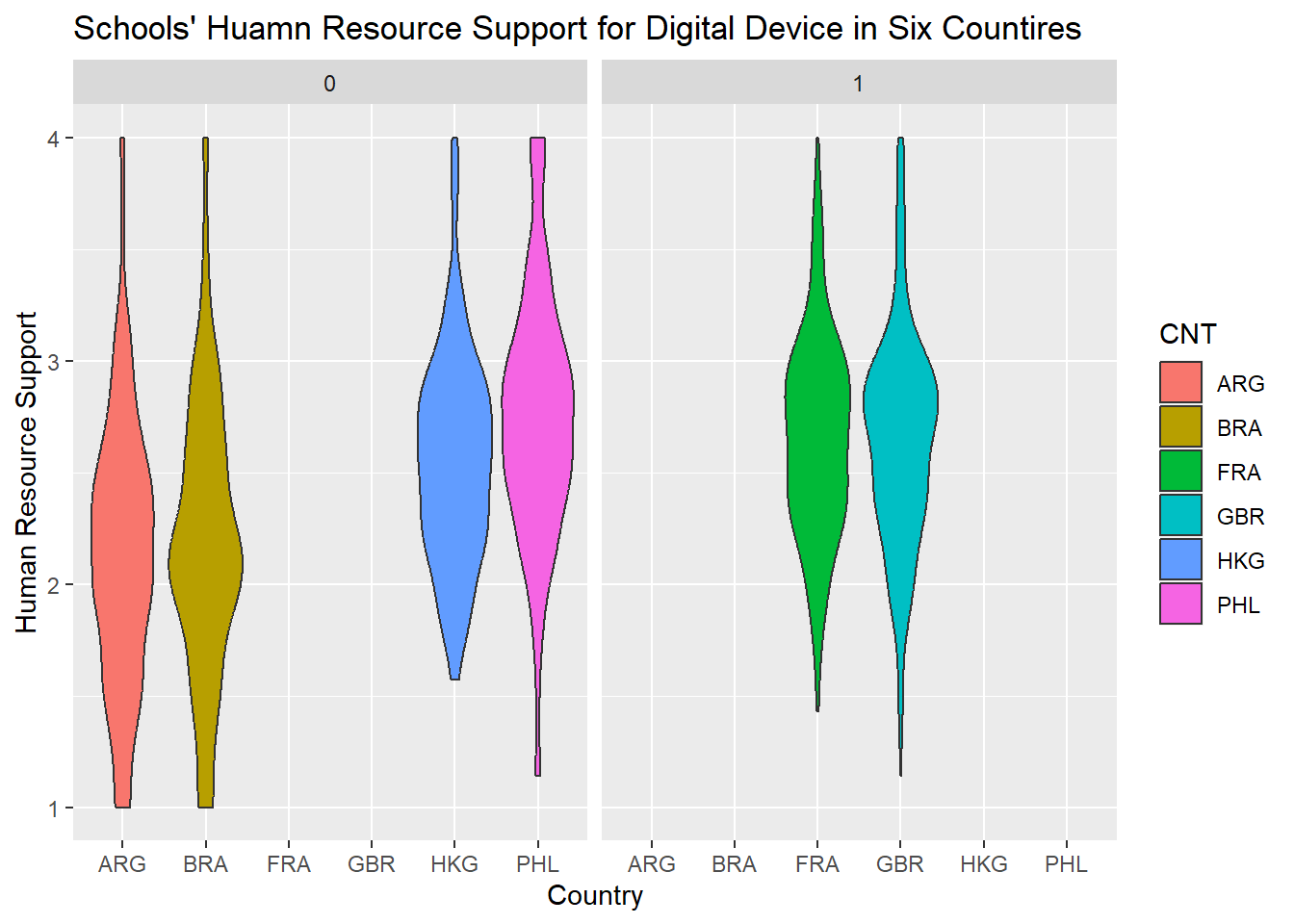
Compared with “Accessibility,” most schools offered more positive responses to “Human Resource Support.” The data reflect that the median and mean of the latter were significantly higher than that of
# violin graphicpisa2018_case_study_clean %>%ggplot(aes(CNT, Accessiblity,fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Accessiblity")+ggtitle("Schools' Accessiblity to Digital Device in Six Countires")
pisa2018_case_study_clean %>%ggplot(aes(CNT, Human_Resource_Support, fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Human Resource Support")+ggtitle("Schools' Huamn Resource Support for Digital Device in Six Countires")
pisa2018_case_study_clean %>%ggplot(aes(CNT, Accessiblity,fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Accessiblity")+ggtitle("Schools' Accessiblity to Digital Device in Six Countires")+facet_wrap(~OECD)
pisa2018_case_study_clean %>%ggplot(aes(CNT, Human_Resource_Support, fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Human Resource Support")+ggtitle("Schools' Huamn Resource Support for Digital Device in Six Countires")+facet_wrap(~OECD)
#xlab(label) ylab(label) ggtitle(label)
The violin graphic shares similar reputation for uncovering the distribution within a collection of data. I use the violin graphics to disclose the evaluation of digital devices in six countries with the dimension of “Accessibility” and “Human Resource Support”. The graphic has shows, whatever accessibility and human resource support, Hong Kong, France and Brain report higher grades than Argentina, Brazil, and the Philippines. most schools’ in Hong Kong, France and Brain response are around the range of “agree” while most schools’ in Argentina, Brazil, the Philippines replies are around the range of “disagree”, which reflects that schools in Argentina, Brazil, the Philippines are not satisfied by their current situation. I also use an alternative dimension–OECD or Non-OECD to create two violin plots. In terms of “Accessibility,” Hong Kong has a better access to digital devices than Argentina, Brazil, the Philippines. the similar situation happens to the evaluation of “Human Resources Support.” The fact may be interpreted that Hong Kong has more enough fiscal resources to support their schools. In fact, the plot demonstrates the variation of the evaluation on digital devices in non-OECD countries. By contrast, two OECD countries–France and Brain share the similar shape in terms of accessibility and human resource support, which reflects that most schools in these two countries believe that they enjoy an good access to digital device and receive enough human resources support.
Bivariate Visualization(s)
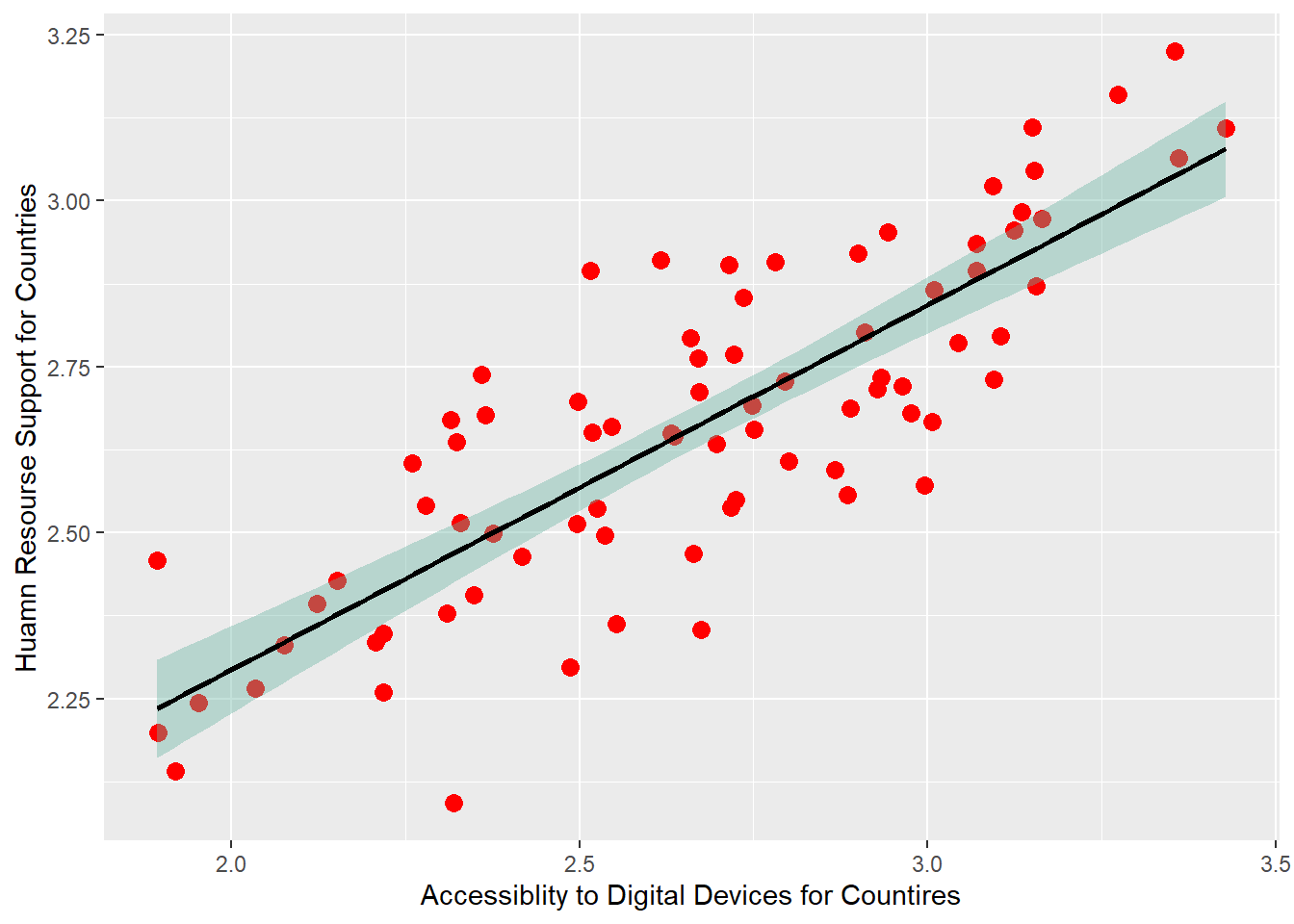
# Bivariate Visualization--point plotpisa2018_joint_clean %>%ggplot(aes(x=Accessiblity_Country_Ave, y=Human_Resource_ave))+geom_point(color="red", size=3)+xlab("Accessiblity to Digital Devices for Countires")+ylab("Huamn Resourse Support for Countries")+geom_smooth(method=lm , color="black", fill="#69b3a2", se=TRUE)
The point plot is good at showing the relationship between two groups of numbers. I use it to capture the correlation between “accessibility to digital devices” and”Human Resource Support” in each country. The smooth line has demonstrated the positive correlation between them.
Source Code
---title: "Challenge 5 Guanhua Tan"author: "Guanhua Tan"description: "Introduction to Visualization"date: "10/16/2022"format: html: toc: true code-copy: true code-tools: truecategories: - challenge_5 - pisa2018---```{r}#| label: setup#| warning: false#| message: falseinstall.packages("treemap")install.packages("leaflet")library(tidyverse)library(ggplot2)library(treemap)library(leaflet)knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```## Challenge OverviewToday's challenge is to:1) read in a data set, and describe the data set using both words and any supporting information (e.g., tables, etc)2) tidy data (as needed, including sanity checks)3) mutate variables as needed (including sanity checks)4) create at least two univariate visualizations- try to make them "publication" ready- Explain why you choose the specific graph type5) Create at least one bivariate visualization- try to make them "publication" ready- Explain why you choose the specific graph type[R Graph Gallery](https://r-graph-gallery.com/) is a good starting point for thinking about what information is conveyed in standard graph types, and includes example R code.(be sure to only include the category tags for the data you use!)## Read in dataI use my own data set pisa2018 school questionnaire.```{r}# read the datapisa <-read_csv('_data/CY07_MSU_SCH_QQQ.csv')dim(pisa)length(unique(pisa$CNT))pisa2018 <- pisa %>%select(starts_with("SC155"))dim(pisa2018)```### Briefly describe the dataThis dataset is one part of PISA 2018 dataset with a focus on schools. It covers 80 countries and different regions within each country. The dataset documents 21,903 schools' responses regarding 187 questions. Some key identifiers include CNT (Country Name), STRATUM (Region Name) and OECD (belongs to or not OECD)## Tidy Data (as needed)The dataset covers 80 countries and regions including 21903 schools' responses regrading 187 questions. So I decided to narrow my reach here to five countries. I'd like to look at schools responses regarding a set of questions "SC155". SC155 survey the accessibility to digital device and its related training as well as assistance. I clean the data and group_by data as regional code. I decided to concentrate my analysis on a series questions of digital device (SC115Q). So I make two different datasets at first. One includes all identifier information. The other covers the columns that contains "SC155Q". Then, I use function "cbind" to combine these two into a new dataset (pisa2018_joint).Furthermore, I mutate 11 columns to calculate every country average regarding 11 questions. After that, I recognize the data with keeping columns of CNT, Region, OECD and 11 questions. Furthermore, I found that the questions from SC155Q01HA to SC155Q01HA focus on the accessibility to digital devices while the questions from SC155Q05HA to SC155Q11HA stress on if the schools offer enough training, support, and incentives. I mutate two new variables--"Accessibility" and "Human_Resource_Support that respectively calculate the average of the former and the latter. Besides, I caculate every country average for "Accessibility" and "Human_Resource_Support." After tidying data, the dataset has four columns and 80 rows.```{r}pisa2018_joint <-cbind(pisa[,1:12], pisa2018) %>%select(CNT, STRATUM, OECD, SC155Q01HA,SC155Q02HA, SC155Q03HA, SC155Q04HA, SC155Q05HA, SC155Q06HA, SC155Q07HA, SC155Q08HA, SC155Q09HA, SC155Q10HA, SC155Q11HA)pisa2018_joint$Accessiblity=rowMeans(pisa2018_joint[,c("SC155Q01HA","SC155Q02HA", "SC155Q03HA","SC155Q04HA")])pisa2018_joint$Human_Resource_Support=rowMeans(pisa2018_joint[,c("SC155Q05HA","SC155Q06HA", "SC155Q07HA","SC155Q08HA","SC155Q09HA", "SC155Q10HA", "SC155Q11HA")])pisa2018_joint_clean <-pisa2018_joint %>%select(CNT, STRATUM, OECD, Accessiblity, Human_Resource_Support) %>%group_by(CNT) %>%mutate(Accessiblity_Country_Ave=mean(Accessiblity, na.rm=T)) %>%mutate(Human_Resource_ave=mean(Human_Resource_Support, na.rm=T)) %>%select(CNT,OECD, Accessiblity_Country_Ave, Human_Resource_ave) %>%distinct() %>%arrange(desc(Accessiblity_Country_Ave))pisa2018_joint_clean```## Univariate Visualizations```{r}pisa2018_OECD <-pisa2018_joint_clean %>%filter(OECD=="1") %>%pivot_longer(cols=c(Accessiblity_Country_Ave, Human_Resource_ave), names_to ="Group", values_to ="Evaluation")pisa2018_OECD %>%ggplot(aes(Evaluation,fill=Group))+stat_boxplot(geom ="errorbar", # Error barswidth =0.25) +geom_boxplot()+facet_wrap(~Group)+labs(title="Pisa2018 Digital Divce Evoluation (OECD)")+coord_flip()``````{r}# regional differences in Non-OECD countriespisa2018_NONOECD <-pisa2018_joint_clean %>%filter(OECD=="0") %>%pivot_longer(cols=c(Accessiblity_Country_Ave, Human_Resource_ave), names_to ="Group", values_to ="Evaluation")pisa2018_NONOECD %>%ggplot(aes(Evaluation,fill=Group))+stat_boxplot(geom ="errorbar", # Error barswidth =0.25)+geom_boxplot()+facet_wrap(~Group)+labs(title="Pisa2018 Digital Divce Evoluation (Non-OECD)")+coord_flip()```In order to further tidy data and create comparative graphics, I first used pivot_longer to create two new variables "Group" and "Evaluation".I put the original variables--"Accessibility_Country_Ave" and "Human_Resource_ave" names to the "Group" and values to "Evaluation." The box plot enjoys the reputation for clearly showing the distribution of a group of numbers, which allows me to disclose the distribution and general situation of every country's evaluation on digital devices. After cleaning and rearranging the dataset, I create four graphics. The boxplot graphics reveal that the OECD countries enjoy the higher access to digital devices than non-OECD countries. But these two groups have reported that their human resource evaluations are in the similar range. The latter reflects the limits to this survey's methodology. Because this survey is reliance on schools' self-report. There is no any objective measurements for them to measure their access to and human resources support on digital devices. Therefore, instead of reflecting that OECD countries lack human resources support, the data may show OECD and non-OECD countries have distinct expectations on human resources support. So self-report can only demonstrate the gap between their expectations and current situations.```{r}# choose five countries to look at regional difference within the countries# United Kingdom (GBR), Hong Kong (HKG), Philippines (PHL), Argentina (ARG), Brazil(BRA)pisa2018_joint_case_study <- pisa2018_joint %>%select(CNT, STRATUM, OECD, SC155Q01HA,SC155Q02HA, SC155Q03HA, SC155Q04HA, SC155Q05HA, SC155Q06HA, SC155Q07HA, SC155Q08HA, SC155Q09HA, SC155Q10HA, SC155Q11HA) %>%group_by(STRATUM) %>%arrange(STRATUM) %>%filter(CNT=="GBR"| CNT=="HKG"| CNT=="PHL"| CNT=="ARG"| CNT=="BRA"|CNT=="FRA" )pisa2018_joint_case_study```From the question of SC15501HA to SC15505HA focus on the accessibility to digital device while the rest of six questions focus on human resource (teachers' training, assistance and motivation). So I decided to mutate two columns. One named "Accessibility' refers to the average of the first five questions of SC155. The other one called "Human Resource Support" refers to the average of the rest six questions.```{r}#further tidy datapisa2018_joint_case_study$Accessiblity=rowMeans(pisa2018_joint_case_study[,c("SC155Q01HA","SC155Q02HA", "SC155Q03HA","SC155Q04HA")])pisa2018_joint_case_study$Human_Resource_Support=rowMeans(pisa2018_joint_case_study[,c("SC155Q05HA","SC155Q06HA", "SC155Q07HA","SC155Q08HA","SC155Q09HA", "SC155Q10HA", "SC155Q11HA")])pisa2018_case_study_clean <- pisa2018_joint_case_study %>%select(CNT,STRATUM,OECD, Accessiblity, Human_Resource_Support)pisa2018_case_study_clean```I produced the violin graphics to investigate the distribution of schools' responses regarding accessibility to and human resource support for digital device. the graphics reveal that there are the limited access to digital advice in Brazil and Argentine. Many schools there expressed "strongly disagree." By contrast, Schools in the United Kingdom and Hong Kong enjoyed smooth access to digital advice because most schools reported positive responses (3 means agree). The Philippines is between these two scenarios. most schools expressed "disagree" instead of "strongly disagree." In terms of "Human Resource Support"Compared with "Accessibility," most schools offered more positive responses to "Human Resource Support." The data reflect that the median and mean of the latter were significantly higher than that of ```{r}# violin graphicpisa2018_case_study_clean %>%ggplot(aes(CNT, Accessiblity,fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Accessiblity")+ggtitle("Schools' Accessiblity to Digital Device in Six Countires")pisa2018_case_study_clean %>%ggplot(aes(CNT, Human_Resource_Support, fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Human Resource Support")+ggtitle("Schools' Huamn Resource Support for Digital Device in Six Countires")pisa2018_case_study_clean %>%ggplot(aes(CNT, Accessiblity,fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Accessiblity")+ggtitle("Schools' Accessiblity to Digital Device in Six Countires")+facet_wrap(~OECD)pisa2018_case_study_clean %>%ggplot(aes(CNT, Human_Resource_Support, fill=CNT), na.rm=T) +geom_violin()+xlab("Country")+ylab("Human Resource Support")+ggtitle("Schools' Huamn Resource Support for Digital Device in Six Countires")+facet_wrap(~OECD)#xlab(label) ylab(label) ggtitle(label)```The violin graphic shares similar reputation for uncovering the distribution within a collection of data.I use the violin graphics to disclose the evaluation of digital devices in six countries with the dimension of "Accessibility" and "Human Resource Support". The graphic has shows, whatever accessibility and human resource support, Hong Kong, France and Brain report higher grades than Argentina, Brazil, and the Philippines. most schools' in Hong Kong, France and Brain response are around the range of "agree" while most schools' in Argentina, Brazil, the Philippines replies are around the range of "disagree", which reflects that schools in Argentina, Brazil, the Philippines are not satisfied by their current situation.I also use an alternative dimension--OECD or Non-OECD to create two violin plots. In terms of "Accessibility," Hong Kong has a better access to digital devices than Argentina, Brazil, the Philippines. the similar situation happens to the evaluation of "Human Resources Support." The fact may be interpreted that Hong Kong has more enough fiscal resources to support their schools. In fact, the plot demonstrates the variation of the evaluation on digital devices in non-OECD countries. By contrast, two OECD countries--France and Brain share the similar shape in terms of accessibility and human resource support, which reflects that most schools in these two countries believe that they enjoy an good access to digital device and receive enough human resources support.## Bivariate Visualization(s)```{r}# Bivariate Visualization--point plotpisa2018_joint_clean %>%ggplot(aes(x=Accessiblity_Country_Ave, y=Human_Resource_ave))+geom_point(color="red", size=3)+xlab("Accessiblity to Digital Devices for Countires")+ylab("Huamn Resourse Support for Countries")+geom_smooth(method=lm , color="black", fill="#69b3a2", se=TRUE)```The point plot is good at showing the relationship between two groups of numbers. I use it to capture the correlation between "accessibility to digital devices" and"Human Resource Support" in each country. The smooth line has demonstrated the positive correlation between them.