There are 119,390 observations and 32 variables in this dataset (rows). We can infer from the variable names that it contains hotel reservation information. 18 variables include numerical values, whereas 14 variables contain character values. Nevertheless, a few character variables and a few numerical variables genuinely represent dates. Except for “adr,” all of the variable names are sufficiently descriptive. The term “adr” stands for “average daily rate.” Therefore, I substituted “average daily rate” for the original column name “adr.”
The dataset includes two different kinds of hotels: resort hotels and city hotels. Bookings are made for the years 2015, 2016 and 2017. The information includes reservations from 178 nations. Thus, the information should belong to a significant global network of hotels. The dataset includes no-shows as well as completed and canceled reservations. Therefore, each observation contains data on a reservation, such as the hotel category and the country for which the reservation is made, the number of visitors, the dates, the daily rates, the lengths of stays, and some categorical information about the customer and the reservation channel. Each row and each column in the dataset correspond to an observation. Thus, pivoting is not required.
Code
hotel.bookings <-mutate( hotel.bookings, number_of_guests = adults + children + babies,total_stay = stays_in_weekend_nights + stays_in_week_nights) # adding two new variables
Generated by summarytools 1.0.1 (R version 4.2.1) 2022-12-21
Some descriptive statistics for the data’s numeric variables are included in this table. For instance, 37% of reservations are canceled in reality. Reservations are typically made 104 days prior to the intended arrival date. Every reservation is typically booked for 1.97 people. An average of one reservation every ten includes a child or infant. The typical stay lasts 3.43 days. 22% of reservations are modified after the fact. Last but not least, hotels’ average daily charge is $101.
There are just four numerical variables that are missing values. However, when we look at the dataset itself and the summary table above, we can see that some “NULL” values appear as strings. Agent and Company variables in the summary table contain “NULL” values. I’ll check each column independently to see if it contains the value “NULL” as a final sanity check.
For reservations, 0.41% of the “country” data, 13.89% of the “agent” data, and 94.31% of the “business” data are missing.
Some analysis
The summary table indicates that a city hotel’s daily fee might reach $5,400 while resort hotels only charge $508 per day. I think that’s the actual situation.
Now let’s do some in depth analysis on the given data.
hotel arrival_date_year country agent number_of_guests total_stay
1 Resort Hotel 2017 GBR 273 2 10
2 Resort Hotel 2015 PRT NULL 2 0
3 Resort Hotel 2015 PRT NULL 2 0
4 Resort Hotel 2015 PRT NULL 4 1
5 Resort Hotel 2015 PRT 240 2 0
6 Resort Hotel 2015 PRT 250 1 0
7 Resort Hotel 2015 PRT NULL 2 0
8 Resort Hotel 2015 PRT 240 2 0
9 Resort Hotel 2015 PRT 305 2 2
10 Resort Hotel 2015 PRT 305 1 2
reservation_status average_daily_rate
1 Check-Out -6.38
2 Check-Out 0.00
3 Check-Out 0.00
4 Check-Out 0.00
5 Check-Out 0.00
6 Check-Out 0.00
7 Check-Out 0.00
8 Check-Out 0.00
9 Canceled 0.00
10 Check-Out 0.00
Therefore, it appears that the row with the average daily fee of 5,400 dollars is an error. A row with a negative average daily rate is also present. I’ll take both of them away.
hotel.bookings %>%select(hotel, average_daily_rate) %>%group_by(hotel) %>%summarise_if(is.numeric, list(min = min, max = max, mean = mean, std_dev = sd, median = median), na.rm =TRUE)
# A tibble: 2 × 6
hotel min max mean std_dev median
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 City Hotel 0 510 105. 39.3 99.9
2 Resort Hotel 0 508 95.0 61.4 75
# A tibble: 10 × 2
country average_daily_rate
<chr> <dbl>
1 DJI 273
2 AIA 265
3 AND 203.
4 UMI 200
5 LAO 182.
6 MYT 178.
7 NCL 176.
8 GEO 169.
9 COM 165.
10 FRO 155.
Code
table(hotel.bookings$arrival_date_month)
April August December February January July June March
11089 13877 6780 8068 5929 12661 10939 9792
May November October September
11791 6794 11160 10508
City hotels charge an average of $11 more per night than resort hotels. In contrast, the price variety for resort hotels is greater than that for city hotels.
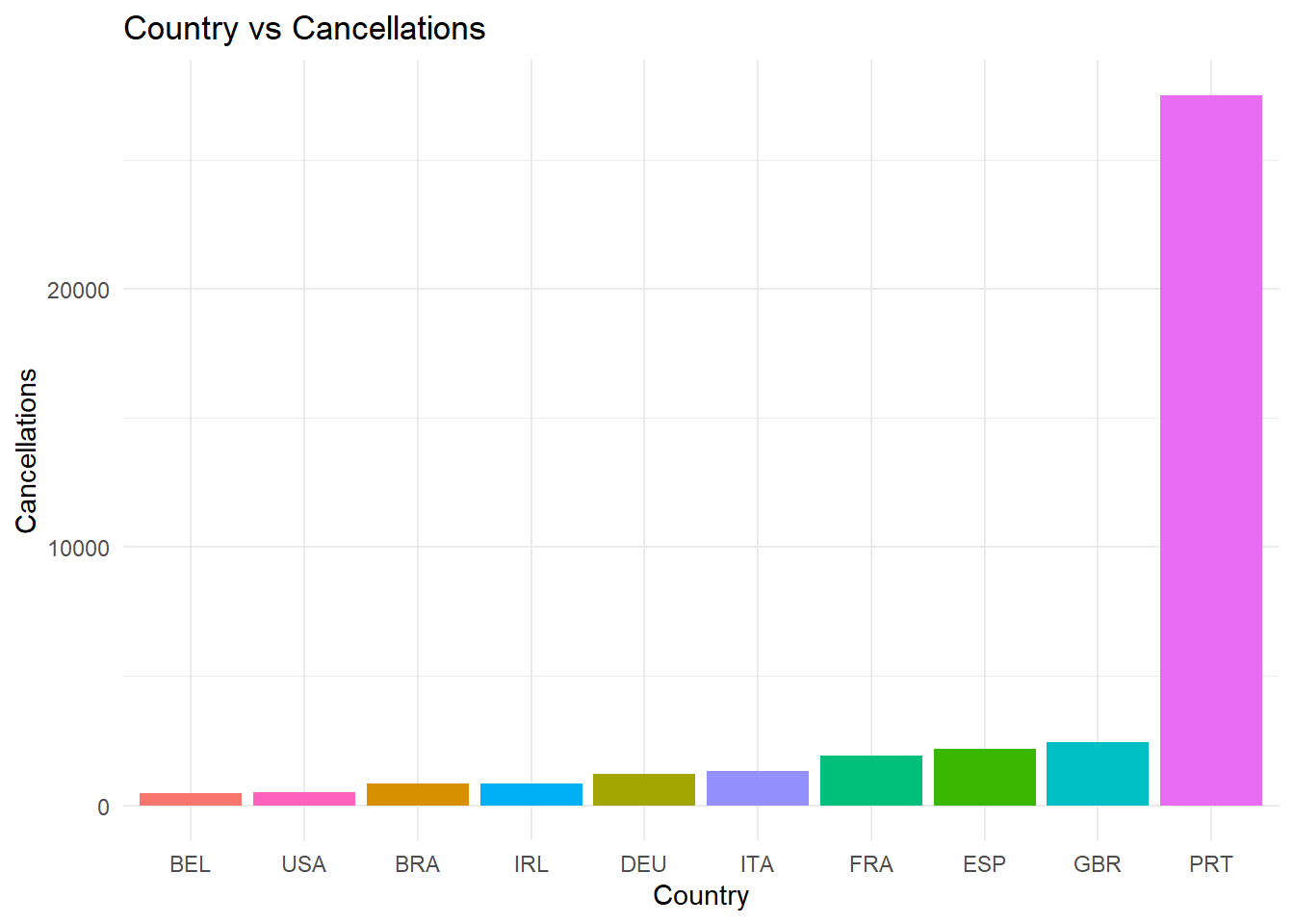
Portugal, Great Britain, France, Spain, Germany, Italy, Ireland, Belgium, Brazil, and the Netherlands top the list of countries with the most reservations, followed by Great Britain, France, and Spain. But as we can see, 56% of hotel reservations for Portugal are really canceled. Italy and Spain each have a 35% share of this percentage. Nevertheless, out of all of them, Portugal has hosted a total of 37,670 visitors over the course of three years.
The most expensive hotels, according to average daily rates, are found in Djibouti, Anguilla, Andorra, United States Minor Outlying Islands, Laos, and so on. It appears that hotels in small nations with few visitors are significantly more expensive.
The busiest times of the year for hotels are in August, July, and May, respectively.
Finally, Let me check how many rows have a daily rate of zero last.
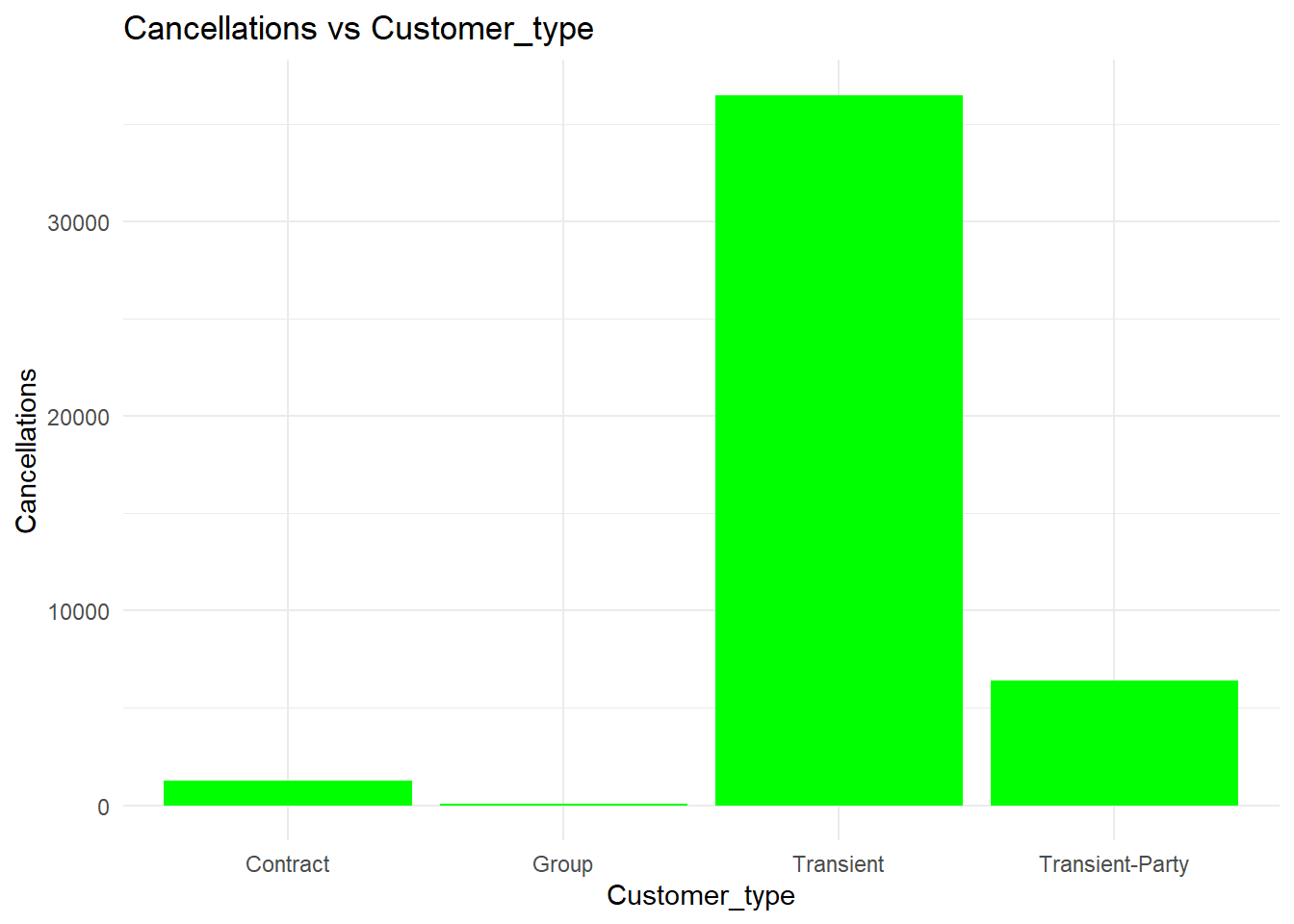
ggplot(hotel.bookings, aes(x = customer_type, y = is_canceled))+geom_col(fill ="green")+theme_minimal()+labs(title ="Cancellations vs Customer_type",x ="Customer_type",y ="Cancellations" )
From the above graph we can clearly infer that the transient customers are the ones who do most number of cancellations and the group customers are the ones doing least number of cancellations.
From the above graph we can clearly see that the number of cancellations differ for the people from different countries and is maximum for thr person from Portugal.
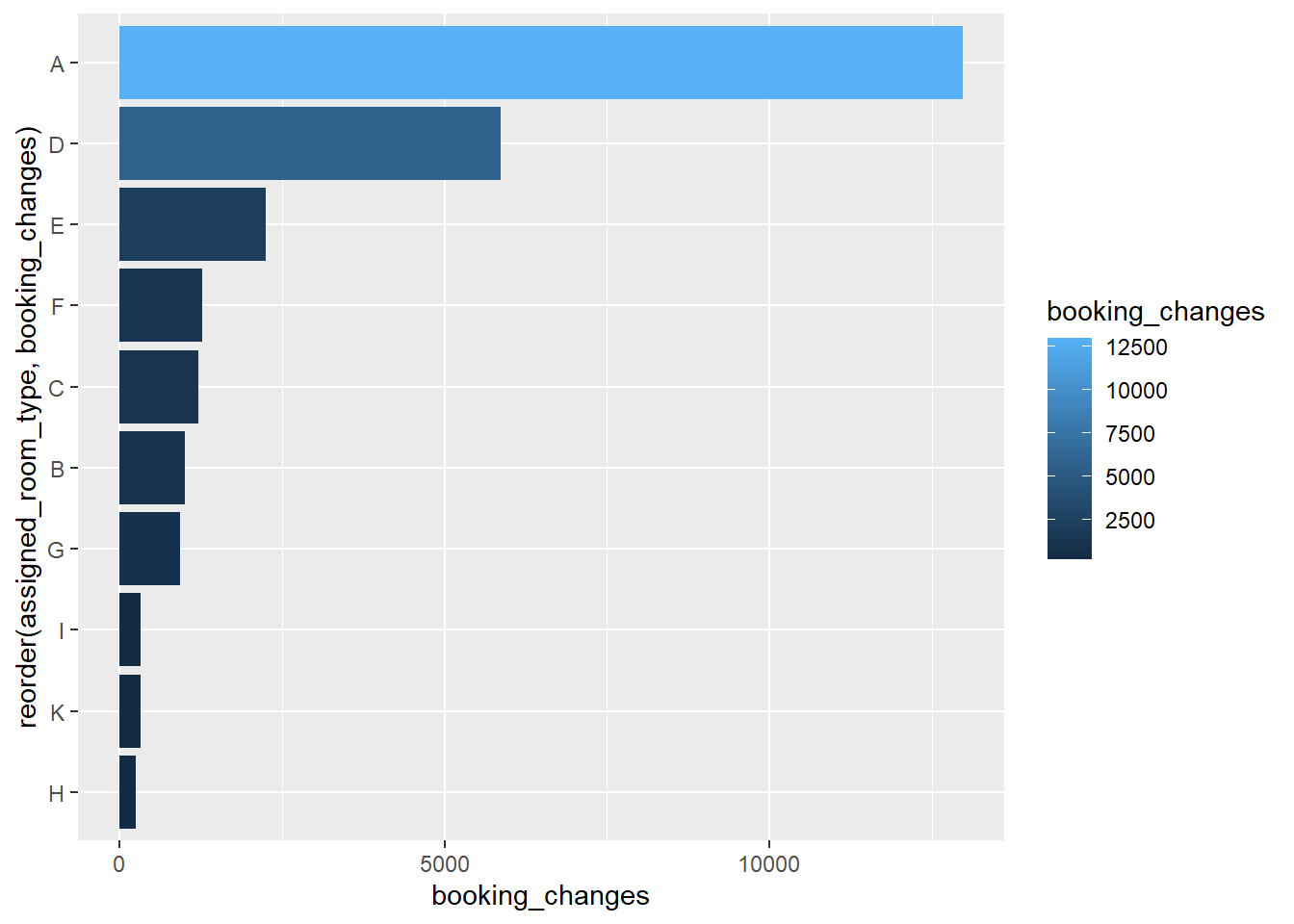
ggplot(data = booking_changes_room_type, mapping =aes(x = booking_changes, y =reorder(assigned_room_type, booking_changes))) +geom_col(mapping =aes(fill = booking_changes), position ="dodge")
Code
labs(x =NULL, y =NULL,fill =NULL,title ="room type and booking changes") +scale_fill_brewer(palette =1) +theme_minimal() +theme(legend.position ="top")
NULL
From the above graph we can clearly see that there is a lot of co-relation between the room_type assigned and the booking changes. The people who were assigned room A are the ones doing most number of booking changes.
I have failed to answer the questions What distinguishes hotel reservations for resorts from those for cities? I can also improvise on building visualizations for the data.
Source Code
---title: "Homework-3"author: "Siddharth Nammara Kalyana Raman"date: "12/17/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - hw2 - hotel_bookings---```{r}#load the librarieslibrary(tidyverse)library(psych)library(summarytools)knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```## Read Data```{r}#read datahotel.bookings <-read.csv("_data/hotel_bookings.csv")```## Describe Data```{r}#checking the dimensions of the datadim(hotel.bookings)```Changing the column name to make it more readable```{r}colnames(hotel.bookings)colnames(hotel.bookings)[28] <-"average_daily_rate"```view first few rows of the data```{r}head(hotel.bookings)```Checking the characted data types```{r}table(sapply(hotel.bookings, function(x) typeof(x)))``````{r}sapply( hotel.bookings, function(x) n_distinct(x) )```finding the unique values for each column```{r}unique(hotel.bookings$hotel)unique(hotel.bookings$arrival_date_year)unique(hotel.bookings$reservation_status)unique(hotel.bookings$distribution_channel)unique(hotel.bookings$customer_type)```There are 119,390 observations and 32 variables in this dataset (rows). We can infer from the variable names that it contains hotel reservation information. 18 variables include numerical values, whereas 14 variables contain character values. Nevertheless, a few character variables and a few numerical variables genuinely represent dates. Except for "adr," all of the variable names are sufficiently descriptive. The term "adr" stands for "average daily rate." Therefore, I substituted "average daily rate" for the original column name "adr."The dataset includes two different kinds of hotels: resort hotels and city hotels. Bookings are made for the years 2015, 2016 and 2017. The information includes reservations from 178 nations. Thus, the information should belong to a significant global network of hotels. The dataset includes no-shows as well as completed and canceled reservations. Therefore, each observation contains data on a reservation, such as the hotel category and the country for which the reservation is made, the number of visitors, the dates, the daily rates, the lengths of stays, and some categorical information about the customer and the reservation channel. Each row and each column in the dataset correspond to an observation. Thus, pivoting is not required.```{r}hotel.bookings <-mutate( hotel.bookings, number_of_guests = adults + children + babies,total_stay = stays_in_weekend_nights + stays_in_week_nights) # adding two new variables``````{r}print(dfSummary(hotel.bookings, varnumbers=FALSE, plain.ascii=FALSE, style="grid", graph.magnif=0.80, valid.col=TRUE),method='render', table.classes='table-condensed')```Some descriptive statistics for the data's numeric variables are included in this table. For instance, 37% of reservations are canceled in reality. Reservations are typically made 104 days prior to the intended arrival date. Every reservation is typically booked for 1.97 people. An average of one reservation every ten includes a child or infant. The typical stay lasts 3.43 days. 22% of reservations are modified after the fact. Last but not least, hotels' average daily charge is $101.Let's check for null values```{r}colSums(is.na(hotel.bookings))```There are just four numerical variables that are missing values. However, when we look at the dataset itself and the summary table above, we can see that some "NULL" values appear as strings. Agent and Company variables in the summary table contain "NULL" values. I'll check each column independently to see if it contains the value "NULL" as a final sanity check.```{r}nulls <-sapply(hotel.bookings, function(x) table(grepl("NULL", x)))for (i in1:32) {if (!is.na(nulls[[i]][2])) {print(nulls[i]) }}```Thus, `country`, `agent` and `company` have "NULL" values. ```{r}#rounding up the valuesround(100*prop.table(table(grepl("NULL", hotel.bookings$country))), 2)round(100*prop.table(table(grepl("NULL", hotel.bookings$agent))), 2)round(100*prop.table(table(grepl("NULL", hotel.bookings$company))), 2)```For reservations, 0.41% of the "country" data, 13.89% of the "agent" data, and 94.31% of the "business" data are missing.## Some analysisThe summary table indicates that a city hotel's daily fee might reach $5,400 while resort hotels only charge $508 per day. I think that's the actual situation.Now let's do some in depth analysis on the given data.```{r}hotel.bookings %>%arrange(desc(average_daily_rate)) %>%slice_head(n=10) %>%select(hotel, arrival_date_year, country, agent, number_of_guests, total_stay, reservation_status, average_daily_rate)``````{r}hotel.bookings %>%arrange(average_daily_rate) %>%slice_head(n=10) %>%select(hotel, arrival_date_year, country, agent, number_of_guests, total_stay, reservation_status, average_daily_rate)```Therefore, it appears that the row with the average daily fee of 5,400 dollars is an error. A row with a negative average daily rate is also present. I'll take both of them away.```{r}hotel.bookings <- hotel.bookings %>%filter(average_daily_rate>=0& average_daily_rate<=510)``````{r}hotel.bookings %>%select(hotel, average_daily_rate) %>%group_by(hotel) %>%summarise_if(is.numeric, list(min = min, max = max, mean = mean, std_dev = sd, median = median), na.rm =TRUE)``````{r}hotel.bookings %>%select(country) %>%group_by(country) %>%count() %>%arrange(desc(n)) %>%head(n=10)``````{r}hotel.bookings %>%filter(country %in%c("PRT", "GBR", "ESP", "FRA", "ITA")) %>%select(country,is_canceled) %>%group_by(country) %>%summarise_if(is.numeric, mean, na.rm =TRUE) %>%arrange(desc(is_canceled))``````{r}hotel.bookings %>%filter(reservation_status =="Check-Out") %>%select(country, number_of_guests) %>%group_by(country) %>%summarise_if(is.numeric, sum, na.rm =TRUE) %>%arrange(desc(number_of_guests)) %>%head(n=10)``````{r}hotel.bookings %>%filter(reservation_status =="Check-Out") %>%select(country, number_of_guests) %>%group_by(country) %>%summarise_if(is.numeric, sum, na.rm =TRUE) %>%arrange(desc(number_of_guests)) %>%head(n=10)``````{r}hotel.bookings %>%select(country, average_daily_rate) %>%group_by(country) %>%summarise_if(is.numeric, mean, na.rm =TRUE) %>%arrange(desc(average_daily_rate)) %>%head(n=10)``````{r}table(hotel.bookings$arrival_date_month)```City hotels charge an average of $11 more per night than resort hotels. In contrast, the price variety for resort hotels is greater than that for city hotels.Portugal, Great Britain, France, Spain, Germany, Italy, Ireland, Belgium, Brazil, and the Netherlands top the list of countries with the most reservations, followed by Great Britain, France, and Spain. But as we can see, 56% of hotel reservations for Portugal are really canceled. Italy and Spain each have a 35% share of this percentage.Nevertheless, out of all of them, Portugal has hosted a total of 37,670 visitors over the course of three years.The most expensive hotels, according to average daily rates, are found in Djibouti, Anguilla, Andorra, United States Minor Outlying Islands, Laos, and so on. It appears that hotels in small nations with few visitors are significantly more expensive.The busiest times of the year for hotels are in August, July, and May, respectively.Finally, Let me check how many rows have a daily rate of zero last.```{r}hotel.bookings %>%filter(average_daily_rate ==0) %>%count()```1959 reservations have a daily rate of nothing.```{r}hotel.bookings %>%filter(average_daily_rate ==0) %>%group_by(country) %>%count() %>%arrange(desc(n)) %>%head()```Portugal makes up the majority of the zero values. Therefore, further research into the accuracy of hotel data for Portugal is ```{r}head(hotel.bookings)``````{r}colnames(hotel.bookings)``````{r}ggplot(hotel.bookings, aes(x = customer_type, y = is_canceled))+geom_col(fill ="green")+theme_minimal()+labs(title ="Cancellations vs Customer_type",x ="Customer_type",y ="Cancellations" ) ```From the above graph we can clearly infer that the transient customers are the ones who do most number of cancellations and the group customers are the ones doing least number of cancellations.```{r}cancel_data<-hotel.bookings %>%select(country, is_canceled) %>%group_by(country) %>%summarise_if(is.numeric, sum, na.rm =TRUE) %>%arrange(desc(is_canceled)) %>%head(n=10)``````{r}ggplot(data = cancel_data, mapping =aes(x= is_canceled, y=reorder(country, is_canceled)))+geom_col(aes(fill = country))+theme_minimal()+coord_flip()+labs(title ="Country vs Cancellations",y ="Country",x ="Cancellations")+theme(legend.position ="none")```From the above graph we can clearly see that the number of cancellations differ for the people from different countries and is maximum for thr person from Portugal.```{r}booking_changes_room_type<-hotel.bookings %>%select(assigned_room_type, booking_changes) %>%group_by(assigned_room_type) %>%summarise_if(is.numeric, sum, na.rm =TRUE) %>%arrange(desc(booking_changes)) %>%head(n=10)``````{r}ggplot(data = booking_changes_room_type, mapping =aes(x = booking_changes, y =reorder(assigned_room_type, booking_changes))) +geom_col(mapping =aes(fill = booking_changes), position ="dodge") labs(x =NULL, y =NULL,fill =NULL,title ="room type and booking changes") +scale_fill_brewer(palette =1) +theme_minimal() +theme(legend.position ="top")```From the above graph we can clearly see that there is a lot of co-relation between the room_type assigned and the booking changes. The people who were assigned room A are the ones doing most number of booking changes.I have failed to answer the questions What distinguishes hotel reservations for resorts from those for cities? I can also improvise on building visualizations for the data.