Code
library(tidyverse)
library(viridis)
library(viridisLite)
library(readxl)
library(summarytools)
library(wordcloud)
library(wordcloud2)
library(tm)
library(SnowballC)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(viridis)
library(viridisLite)
library(readxl)
library(summarytools)
library(wordcloud)
library(wordcloud2)
library(tm)
library(SnowballC)
knitr::opts_chunk$set(echo = TRUE)A software company has gathered qualitative and quantitative feedback from 24 client organizations using three surveys at different stages of the client relationship: purchase decision, launch, and early results. At most, three individual people from each institution responded to at least one survey, two people responded to two surveys, and no one person responded to all three surveys. Given the small sample size of only 31 respondents across the 3 surveys, and given the overlap in feedback across the three surveys, this analysis will combine all available data into a single set for an initial analysis.
At the outset, it should be noted that the conclusions drawn from this data will be limited due to the small sample size. The value of this analysis, therefore, aims to find strong trends and to determine what changes, if any, to the surveys would yield more business intelligence.
The data has been sanitized to protect the privacy of those involved. Client email addresses are replaced with a new variable, UserID, where the letter corresponds to an organization and the number corresponds to the respondent from that organization. To illustrate, R1, R2, R3 are three different people from the same organization. This will allow analysis of individuals and organization-based feedback.
Since there is some overlap in organizations, respondents, and questions across the three surveys, the first step will be a full_join, with a calculation of x/2 to align the 10-point ratings with the 5-point ratings. A full join will allow analysis of as much data as possible, while requiring careful handling of NA values.
# assign x/2 function
mydivide <- function(x){x/2}
# read in each sheet
survey1_orig <- read_xlsx("_data/ClientSurveys.xlsx", sheet =1)
survey2_orig <- read_xlsx("_data/ClientSurveys.xlsx", sheet =2) %>%
mutate(across(starts_with("How would"), funs(mydivide)),
.keep = "unused")
survey3_orig <- read_xlsx("_data/ClientSurveys.xlsx", sheet =3) %>%
mutate(across(starts_with(c("How", "Overall")), funs(mydivide)),
.keep = "unused")
# full join to keep all data, key = UserID
joinedsurveys_orig <- survey2_orig %>%
full_join(x = survey2_orig, y=survey1_orig, by = "UserID") %>%
full_join(survey3_orig, by = "UserID")As with most surveys, the questions are too long for column names, so each is renamed with the simplest phrasing possible. The new names contain prefixes and suffixes that will help with sorting later. For instance, rating questions begin with “qr_”, free text questions begin with “qf_”, and selection questions begin with “qs_”. The full text of each question is listed in the appendix at the end of this document.
# look at colnames to rename them
# colnames(joinedsurveys_orig)
# assign clean data frame
surveys_renamed <- joinedsurveys_orig
#rename columns
colnames(surveys_renamed) <- c("Timestamp1",
"UserID",
"delete",
"delete2",
"qs_prompted_adoption",
"qf_goal_constituents",
"qf_launcheffort_staffrolestime",
"qr_launcheffort_retaskstaff",
"qr_launcheffort_generatecontent",
"qr_launcheffort_techIT",
"qr_launcheffort_staffadoption",
"qf_launcheffort_detail",
"qr_benefit_donorengagement",
"qr_benefit_increasedgifts",
"qr_benefit_costsavings",
"qr_benefit_timesavings",
"qr_benefit_GOproductivity",
"qf_benefit_detail",
"qf_donorcommsbefore",
"qf_process_content",
"qf_donor_relationship",
"qf_donor_interaction",
"qf_donor_response",
"qf_donor_analytics",
"qf_team_analytics",
"qf_support_detail",
"qf_Olacking",
"qf_biggest_success",
"qf_reality_vs_expectations",
"qf_client_advice",
"qf_Oimprove",
"qr_implementationsupport",
"Timestamp2",
"qs_prompted_adoption",
"qs_choice_over_competitors",
"qf_feature_detail",
"qr_benefit_donorengagement",
"qr_benefit_increasedgifts",
"qr_benefit_costsavings",
"qr_benefit_timesavings",
"qr_benefit_GOproductivity",
"qf_choice_factors",
"Timestamp3",
"qs_onboard_lacking",
"qf_onboard_lacking_detail",
"qs_onboard_wentwell",
"qf_onboard_wentwell_detail",
"qf_onboard_communication_detail",
"qf_onboard_interpretneeds_detail",
"delete3",
"qr_onboard_communication",
"qr_onboard_interpretneeds",
"qr_onboard_overall")
# view new column names
# colnames(surveys_renamed)After renaming, pivoting and grouping is used to combine the repeated questions into the same variable. For instance, surveys 1 and 2 both ask, “What prompted your adoption of [the software product]?” This step gets those responses into the same column while maintaining the distinct timestamps and UserIDs for each instance. At first, the dataset includes 53 columns, and after de-duplicating the 6 repeated questions, it has 47 columns.
# combine repeated questions
deduped_questions <- surveys_renamed %>%
# result is 53 variables
pivot_longer(cols = (starts_with("q")),
names_to = "question",
values_to = "response",
values_transform = list(response = as.character),
values_drop_na = TRUE) %>%
group_by(question) %>%
pivot_wider(names_from = "question",
names_sort = TRUE,
values_from = "response")
# confirmed reduction in columns and same number of rows
dim(deduped_questions)[1] 32 47With the names abbreviated and the repeated questions regrouped, further cleaning can be done. First, the columns are sorted alphabetically to make use of the naming conventions. Two unneeded questions about sizing and shipping for a gift are removed as well as one row with a test response. Various spellings of “n/a”, “N/A”, and “???” are mutated to NA values. The fields that had been mutated from numeric to character for the pivot are converted back to numeric values, and then those numeric columns are moved to the front of the data set after UserID.
The result is a tidy data set where each of 31 respondents and all of their responses are on the same row beginning with the UserID, and 44 variables are organized into separate columns for analysis.
# cleaning steps
surveys_clean <- deduped_questions %>%
# alpha-order columns
select(order(colnames(deduped_questions))) %>%
# remove deletes
select(-starts_with("delete")) %>%
# remove test row, should get 31 x 45
filter(is.na(qf_goal_constituents) | qf_goal_constituents != "test") %>%
# deal with NAs
mutate(across(where(is.character), ~na_if(.,"n/a"))) %>%
mutate(across(where(is.character), ~na_if(.,"N/A"))) %>%
mutate(across(where(is.character), ~na_if(.,"N/a"))) %>%
mutate(across(where(is.character), ~na_if(.,"???"))) %>%
# group
group_by(sort("UserID")) %>%
# arrange by client
arrange("UserID") %>%
# convert back to numeric
mutate(across(starts_with("qr"), ~as.numeric(.))) %>%
# move numeric values to front
relocate(where(is.numeric)) %>%
# bring UserID to the leftmost
relocate("UserID")
dim(surveys_clean)[1] 31 45With a richer data set, it’s possible that significant correlations could be found between client characteristics and the feedback they give, such as length of time with the software, staff size, usage categories, etc. However, since this analysis seeks to identify broad trends across aspects of performance and the effort required to implement the software, the primary focus will be on those performance and effort variables rather than trends among organizations or respondents.
A total of 13 questions asked respondents to rate feedback on a scale of 1-5 (as noted in the cleaning steps above, those on a scale of 1-10 were recalculated). A simple boxplot with a point overlay of individual ratings gives a general idea of the quantitative data. A “jitter” positioning on the geom_point helps make it easier to see the quantity of responses and generally where they were.
# set up rating data, 177 x 3
ratings <- surveys_clean %>%
ungroup() %>%
select(starts_with("qr") | "UserID") %>%
pivot_longer(cols = starts_with("qr"),
names_to = "question",
values_to = "rating",
values_drop_na = TRUE)
# boxplot with jitter point
ratings %>%
ggplot(aes(question, rating)) +
geom_boxplot(fill = "#fde725") +
coord_flip() +
geom_point(alpha = .4,
size = .2,
position = "jitter") +
labs(title = "Exploratory Visualization of All Ratings")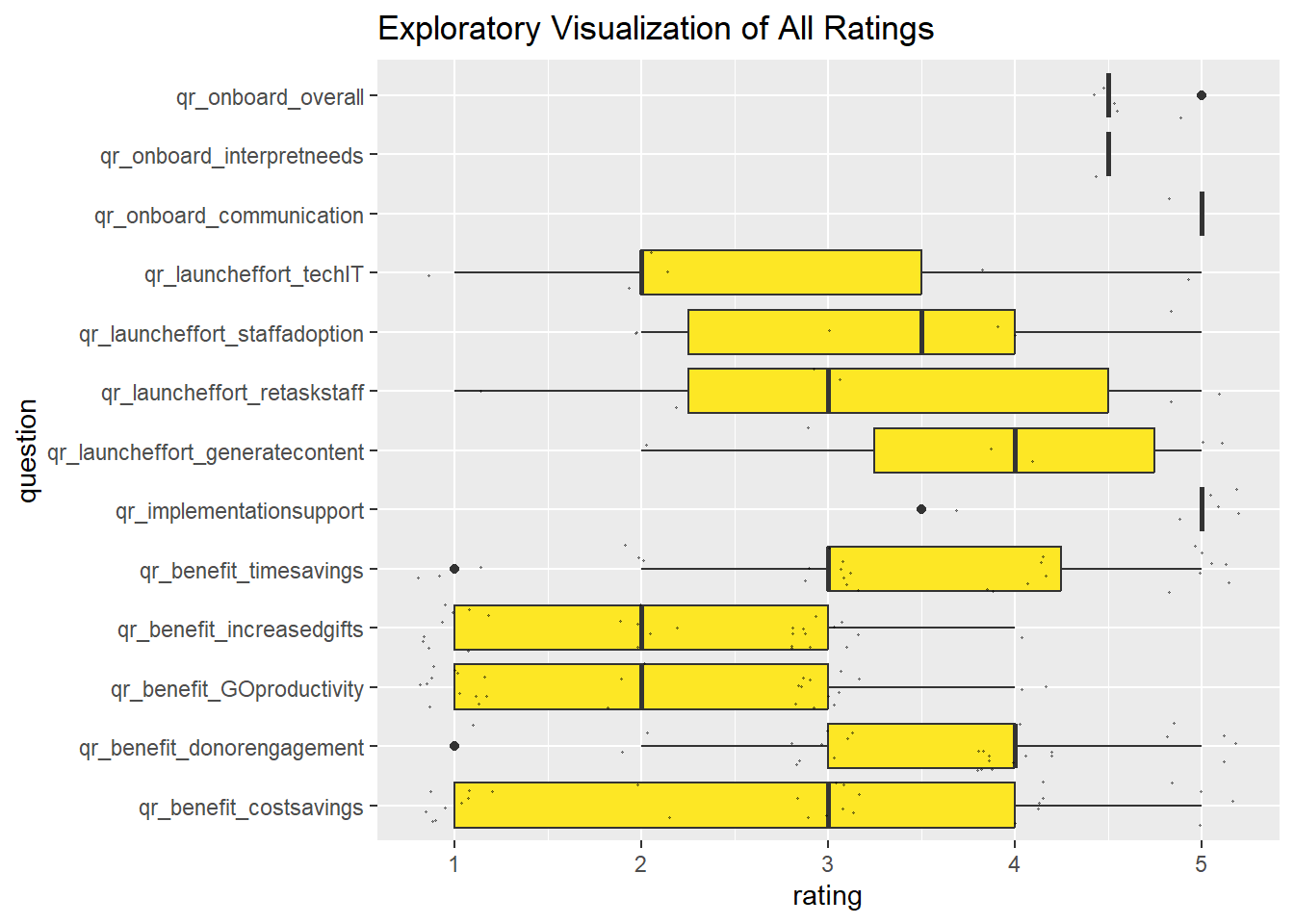
In the plot above, the range and density of responses are easy to see. With this view, it is clear that only one person responded to the “interpret needs” question, about 5-6 responded to “launch effort” questions, and a much larger sample responded to “benefit” questions. The one person who responded regarding how well the software company interpreted their needs during setup responded with the most positive possible rating. The launch effort and benefit questions require further plotting to analyze, as neither tells a clear story from this noisy plot. It is also not very helpful to see benefits ranked against effort.
From the boxplot below, arranged by decreasing medians, it is clear that improved donor engagement and time savings are the benefits most strongly reported. Cost savings has the broadest span with a mean in the center of the rating options. Both increased gifts and gift officer productivity are on the lower end of benefits experienced, since both have means greater than the minimum rating, it is safe to interpret that these benefits have been seen to some degree. It is notable that cost savings, increased gifts, and gift officer productivity all have significant responses at the minimum rating; the software company should pay attention to those who are reporting none of these benefits.
# set up benefits data
benefits <- surveys_clean %>%
ungroup() %>%
select(starts_with("qr_ben") | "UserID") %>%
rename("cost savings" = "qr_benefit_costsavings",
"improved donor engagement" = "qr_benefit_donorengagement",
"gift officer productivity" = "qr_benefit_GOproductivity",
"increased gifts" = "qr_benefit_increasedgifts",
"time savings" = "qr_benefit_timesavings") %>%
pivot_longer(cols = !UserID,
names_to = "question",
values_to = "rating",
values_drop_na = TRUE)
# boxplot
benefits %>%
group_by(question) %>%
ggplot(aes(rating, question )) +
geom_boxplot(fill = "#5ec962",
xlim= c(0,5)) +
scale_y_discrete(limits = c("gift officer productivity",
"increased gifts",
"cost savings",
"time savings",
"improved donor engagement")) +
labs(title = "Degree of Product Benefits Experienced", x = "Client Rating (low to high)" , y = NULL) +
theme_minimal()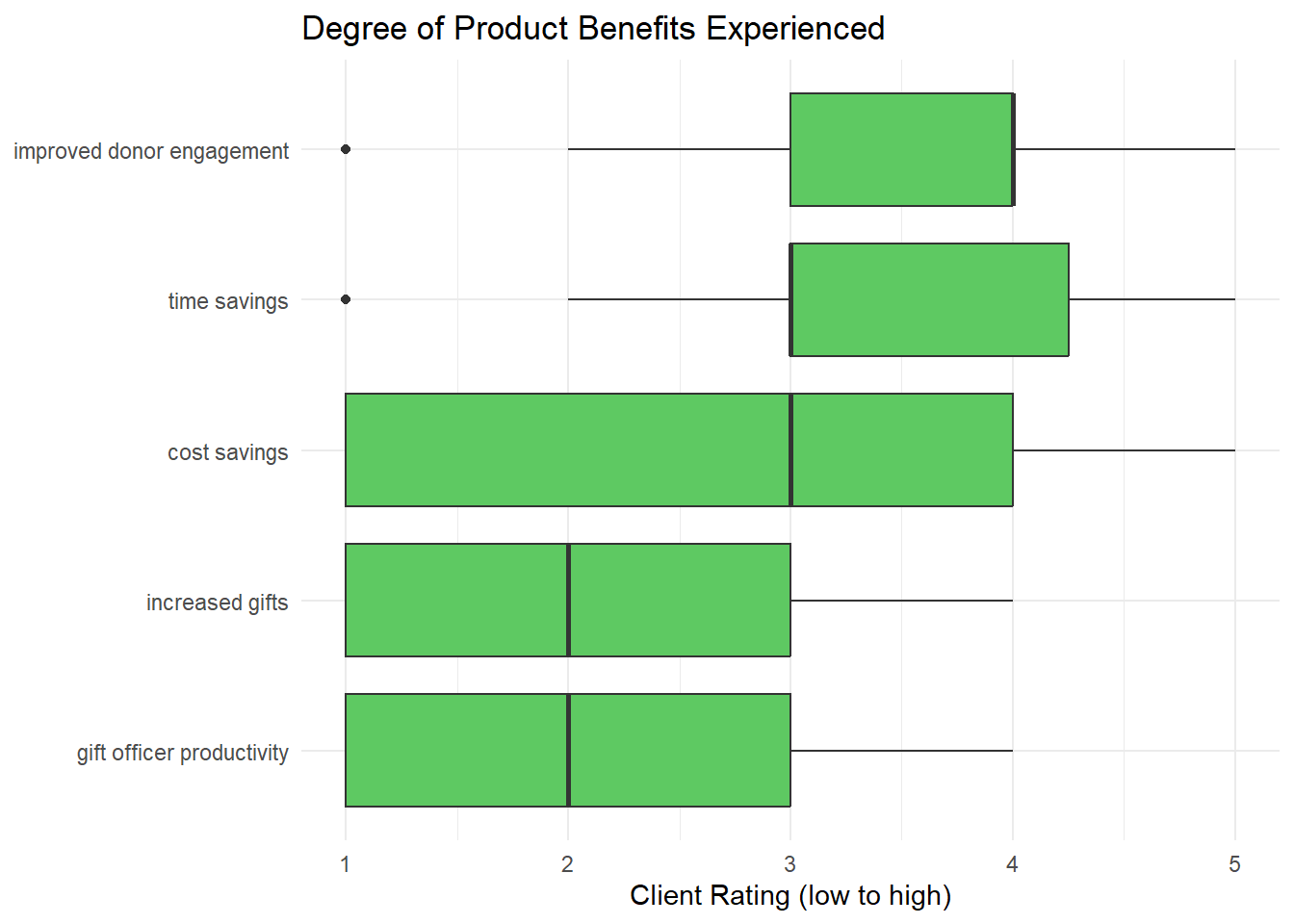
Notably, one qualitative question on the survey regarding internal staff metrics (nearly synonymous with gift officer productivity), all four respondents to that free text question indicated they had not looked at the internal analytics. Therefore, it is possible that these benefits may be going unnoticed. The software company may wish to increase attention to that feature. It should be noted that no person gave feedback on both the gift officer productivity rating AND the internal analytics question. Nonetheless, the strong trends of each group indicate a possible gap that the software company should note.
On the way to creating the boxplot above, other plots were attempted that were not as helpful.
# geom_jtter
benefits %>%
ggplot(aes(question, rating)) +
geom_jitter(width = .1,
height = .1,
alpha = .2,
size = 10,) +
scale_color_viridis_d() +
scale_x_discrete(limits = c("gift officer productivity",
"increased gifts",
"cost savings",
"time savings",
"improved donor engagement")) +
coord_flip() +
labs(title = "Density of Benefit Ratings: View A") +
theme_minimal()
# geom_count
benefits %>%
ggplot(aes(question, rating)) +
geom_count(color = "#440154FF") +
scale_size_area(max_size = 10) +
coord_flip() +
scale_x_discrete(limits = c("gift officer productivity",
"increased gifts",
"cost savings",
"time savings",
"improved donor engagement")) +
theme_minimal() +
labs(title = "Density of Benefit Ratings: View B") +
theme(legend.position = "none")
# density of ratings for each benefit
benefits %>%
ggplot(aes(rating, group = question, fill = question)) +
geom_density(alpha = .9) +
facet_wrap("question") +
scale_fill_viridis_d() +
theme_minimal() +
labs(title = "Density of Benefit Ratings: View C") +
theme(legend.position = "none")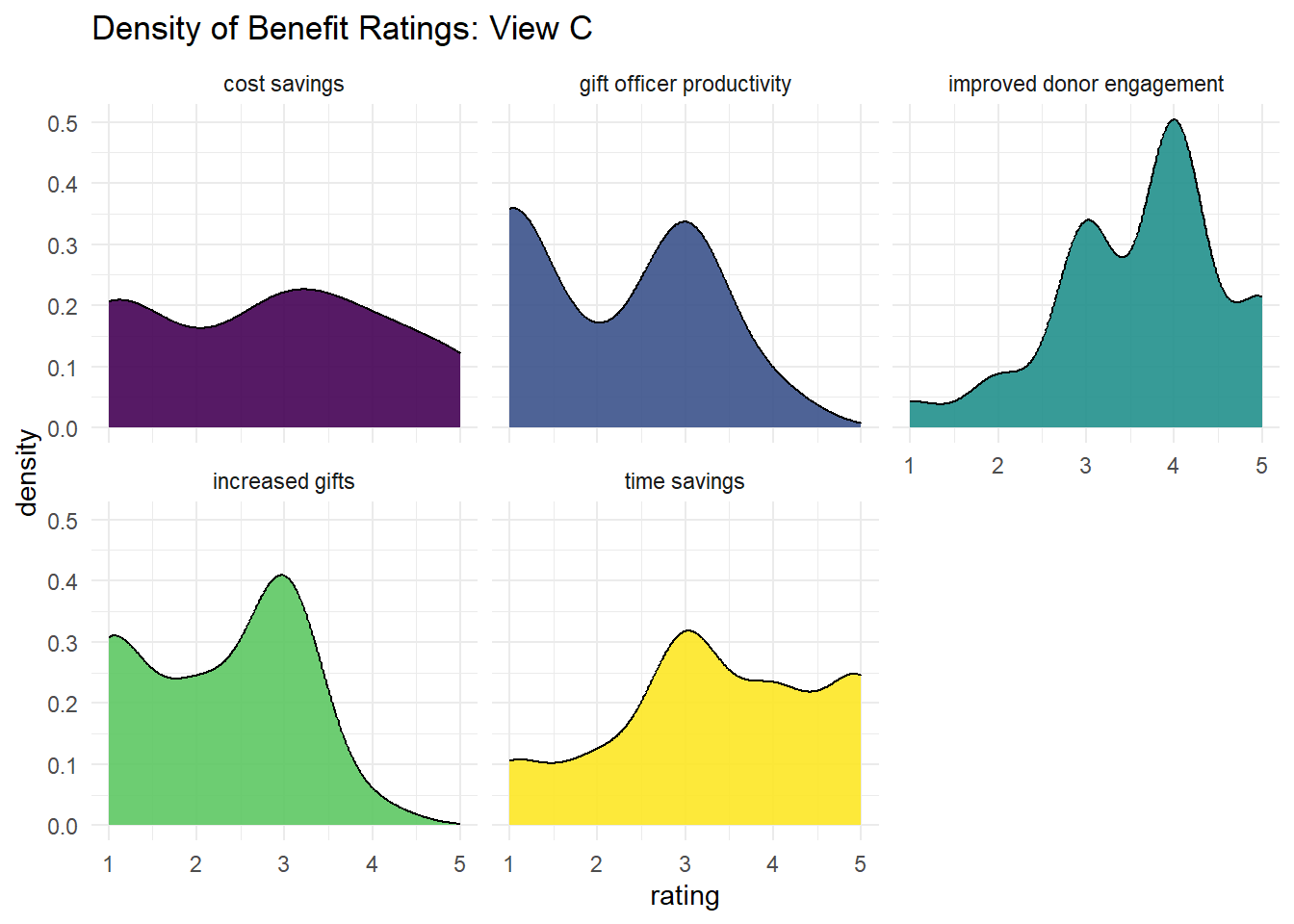
Above is a jitter plot that gives a general, but ultimately unhelpful, indication of the density of response ratings for each benefit, as does a geom_count plot where the size of dots represents frequency of responses. There is also a density plot that illustrated the frequency with which each rating was received for each benefit, and there is limited knowledge to gain here. If these were plotting average ratings over time, that would be much more interesting. Still, it can be noted that some benefits had greater variability in ratings than others, such as improved donor engagement and cost savings.
Further analysis could group ratings to take another view. For instance it could be argued that a rating of 1 = low, ratings of 2-3 = moderate, and ratings of 4-5 = high. New trends could emerge with this approach, but perhaps not.
The next group of ratings for investigation are those regarding the degree of effort required for launching the software product, across four aspects: the involvement of IT/technical staff, the work of retasking existing staff for a new model of work, the effort required for staff to be trained on and adopt the software, and the work of generating the content for the ultimate output. See below for how these were rated in relation to one another.
#set up launch data
launch <- surveys_clean %>%
ungroup() %>%
select(starts_with("qr_launch") | "UserID") %>%
rename("generate content" = "qr_launcheffort_generatecontent",
"retasking staff" = "qr_launcheffort_retaskstaff",
"staff adoption" = "qr_launcheffort_staffadoption",
"IT/technical staff" = "qr_launcheffort_techIT" ) %>%
pivot_longer(cols = !UserID,
names_to = "question",
values_to = "rating",
values_drop_na = TRUE)
# plot on boxplot, in increasing order
launch %>%
arrange() %>%
ggplot(aes(question, rating)) +
geom_boxplot(fill = "#2D708EFF") +
coord_flip() +
scale_x_discrete(limits = c("generate content" , "staff adoption" , "retasking staff" , "IT/technical staff")) +
labs(title = "Degree of Effort Required for Launch",
subtitle = "*based on only 6 responses",
y = "Client Rating (low to high)",
x = NULL) +
theme_minimal()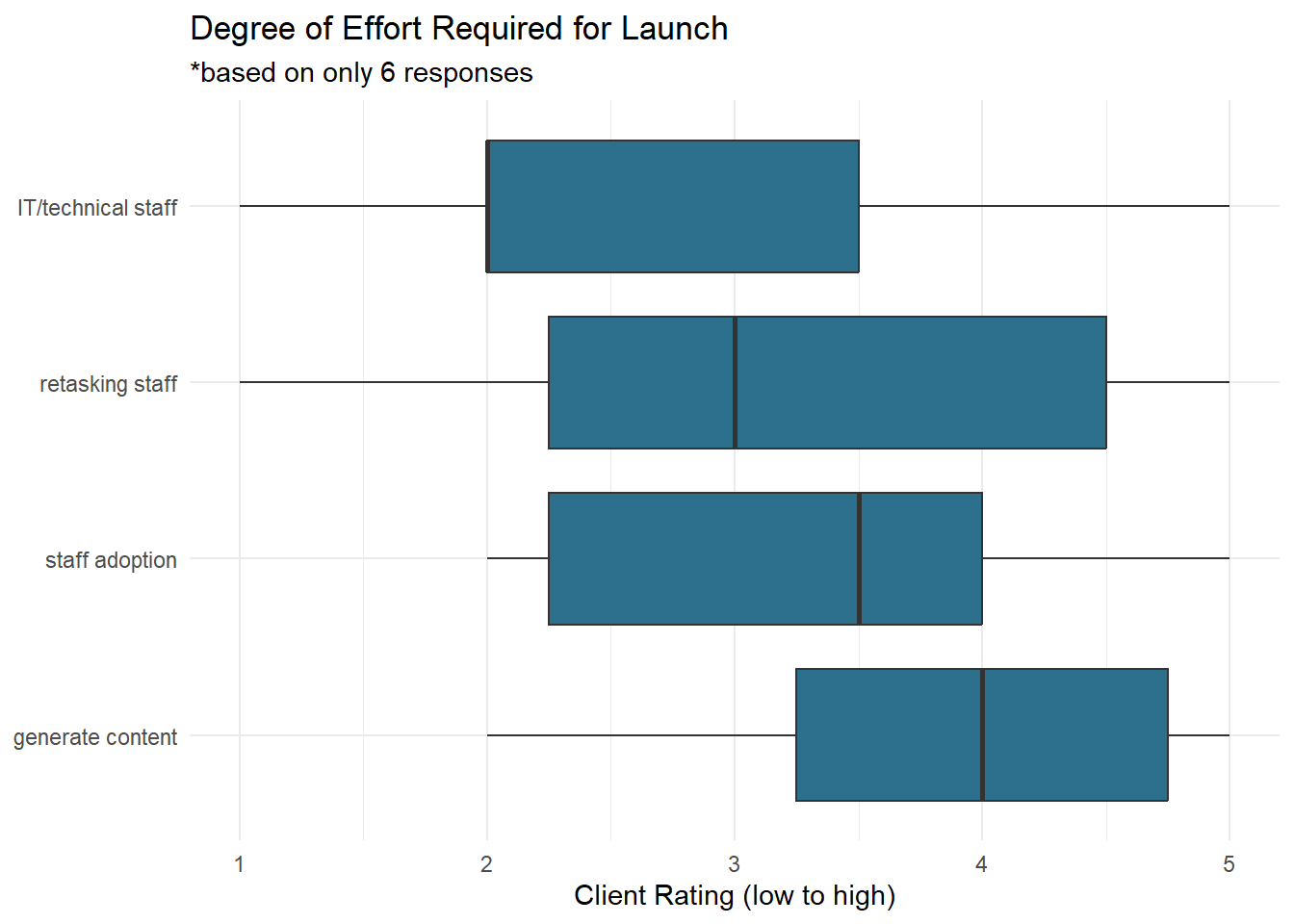
This visualization makes it easy to see which aspects were the easiest, and which were the hardest. The lowest is the effort required by IT/technical staff. Next, the effort of retasking staff to make internal team adjustments to roles of work, followed closely by the effort of staff learning to use the software, shown as staff adoption. The greatest degree of effort reported was for generating content within the system. Given the context, this last is an excellent finding.
To explain further, the greatest amount of effort required is the substantive work that makes use of the product. On the other hand, if staff adoption took the most work, the software company would certainly want to improve the onboarding and training process. It’s also great that the technical staff assistance needed is minimal, and that the staff who will be using the product take more effort to learn it. To add context, this is a specialized product for domain experts, and so it is expected that there be substantial effort involved in training them to use it. The amount of effort required to generate content is the point of the product and projects anyway, so that makes sense to take the most effort.
That said, it would be interesting to compare the degree of effort required to generate content with and without the software: is it decreased, even if it still requires the most effort? Furthermore, it would be interesting to compare the effort ratings over time for the same organization: is year two easier than year one, and year three easier still?
Another facet the surveys explored were the factors that led the organizations to adopt the software in the first place. For this question, which was present in two of the surveys, the answers were in a multi-selection format, where respondents could select any number of the options listed. The following visualization is based on the responses only, and so there may have been other options provided that no one selected.
To set up this for plotting, NA values were omitted so that the percentage of respondents who selected a given option could be calculated from an accurate total. It was a challenge to figure out how to get a single column of 28 responses into a rectangular format for plotting. Mutate allowed the addition of sum columns to the data, and later the full text column was dropped. Once regular expressions based on distinct keywords were identified, the addition of summed columns was straightforward. At that point, the data was quite repetitive, and so the next step was to take a single row and pivot it to a vertical format. What results is a table including just the keyword of each factor and the number of times it appeared in the data.
This was ideal for visualizing the part-to-whole relationship of what proportion of respondents selected each option. The final step was to add a column with the percentage as a function of the sum over the total responses, and then to reformat decimal results into percentages rounded to a single decimal place.
# set up adoption selection question data
adoption <- surveys_clean %>%
ungroup() %>%
select(contains("prompted_adoption")) %>%
na.omit()
# add count and percentage of occurences to df
adoption_df <- adoption %>%
mutate(personalization = sum(str_count(.,regex("personalization")))) %>%
mutate(campaign = sum(str_count(.,regex("campaign")))) %>%
mutate(reporting = sum(str_count(.,regex("reporting")))) %>%
mutate(digitize = sum(str_count(.,regex("digitize")))) %>%
mutate(flexibility = sum(str_count(.,regex("Flexibility")))) %>%
select(!starts_with("q")) %>%
slice(1) %>%
# pivot
pivot_longer(c("personalization",
"campaign",
"reporting",
"digitize",
"flexibility"),
names_to = "feature",
values_to = "votes") %>%
# add column for percentages
mutate(per = votes / 28) %>%
mutate(per = round (per*100, digits = 1)) %>%
arrange(desc(votes))
# plot
adoption_df %>%
arrange(desc(per)) %>%
ggplot(aes(x = feature, y = per)) +
geom_bar(stat = "identity",
fill = "#7ad151") +
scale_y_continuous(limits = c(0,80)) +
scale_x_discrete(limits = c("flexibility","campaign","reporting",
"digitize", "personalization")) +
labs(title = "Factors that Prompted Adoption",
x = "reason",
y = "% adopted the software for this reason") +
theme_classic() +
theme(axis.title.y=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()) +
coord_flip() +
geom_text(data = filter(adoption_df, feature == "personalization"), aes(x=feature, y=0,
label = paste0("Desire for increased personalization in routine donor relationship-building ", per ,"%")), hjust = -0.01) +
geom_text(data = filter(adoption_df, feature == "digitize"), aes(x=feature, y=0,
label = paste0("Digitize/modernize the advancement office ", per ,"%")), hjust = -0.01) +
geom_text(data = filter(adoption_df, feature == "reporting"), aes(x=feature, y=0,
label = paste0("Solve the burden of donor stewardship reporting ", per ,"%")), hjust = -0.01) +
geom_text(data = filter(adoption_df, feature == "campaign"), aes(x=feature, y=0,
label = paste0("Increased demands of a campaign ", per ,"%")), hjust = -0.01) +
geom_text(data = filter(adoption_df, feature == "flexibility"), aes(x=feature, y=0,
label = paste0(per ,"% Flexibility vs. print for campaign materials")), hjust = 0) 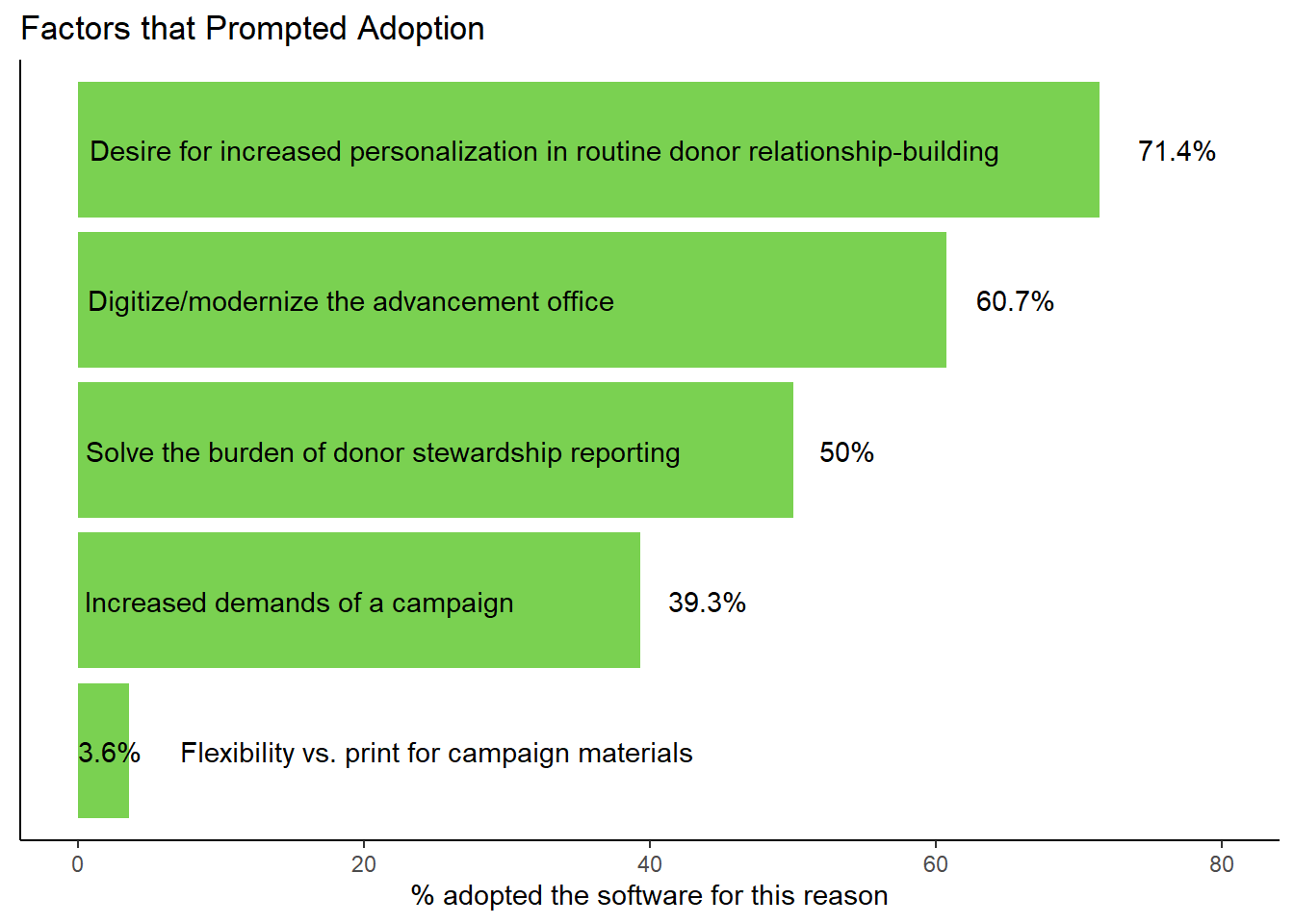
The above plot required manual labeling to place the many-word factors onto the value bars themselves. This is much easier to read than a legend or separate axis labels. With more time, it would have been better to place the percentage labels individually rather than with many spaces added to the x labels. This may not render well in all cases.
However, despite its shortfalls, this is a really clear visual of how these factors ranked for the respondents in adopting the software. Personalization of donor communications is a clear priority, followed by a desire to digitize and modernize. At about the same interval is the desire to solve the administrative burden of producing and sharing stewardship reports, followed again at about the same interval by increased demands of a fundraising campaign. The least favored option, at less than 10% as popular as the next factor and only 5% as popular as the most selected option, is the flexibility offered by the platform over print campaign materials.
The software company should note these rankings as they approach the market and try to win new clients. They are likely to benefit from emphasizing the possibility for personalization and modernization. Perhaps the flexibility of digital vs. print campaign materials would be a greater focus for those organizations that report increased campaign demands.
Of course, not all of the questions on the survey asked respondents to rate categories. Several questions were free text questions that allowed the clients to mention the features, issues, and processes that were most pressing for them. A closer look at their text-as-data could yield interesting findings for the software company, or in the least, could help define further questions for future surveys and research.
A word cloud provides a general sense of the frequency that words appear in a body, or corpus, of text. Most of the time, the words in the center and in larger sizes are used more frequently. The survey responses were first cleaned by identifying and removing NA values, and then by using text mining tools in the tm package: remove punctuation, change all characters to lowercase, ignore common English words that would add little value (like “the”, “and”, “to”, etc.), and finally to group words with the same root or “stem” together. This last part is helpful so that words like “report,” “reports,” and “reporting” are grouped together rather than being counted separately. These functions add value that are especially useful when analyzing large corpora of text, but are also helpful in this case.
After the text was cleaned, the frequency of 6 instances was used as the minimum parameter for what would appear in the word cloud. This was a subjective decision based on observation of several options, and this seemed the clearest and most helpful view of the data. The resulting word cloud is below.
# isolate and prepare freetext responses
freetext <- surveys_clean %>%
ungroup() %>%
# select only the freetext variables
select(starts_with("qf_") | "UserID") %>%
# change "did not select" responses to NA
mutate(qf_feature_detail = if_else(str_detect(qf_feature_detail, "select"),
NA_character_, qf_feature_detail)) %>%
mutate(across(na.rm = TRUE))
# set up free text corpus
ftcorpus <- Corpus(VectorSource(freetext))
# inspect(ftcorpus)
# replace symbols and special characters with spaces
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
ftcorpus <- tm_map(ftcorpus, toSpace, "/")
ftcorpus <- tm_map(ftcorpus, toSpace, "@")
ftcorpus <- tm_map(ftcorpus, toSpace, "\\|")
ftcorpus <- tm_map(ftcorpus, toSpace, "NA")
ftcorpus <- tm_map(ftcorpus, toSpace, "\n")
ftcorpus <- tm_map(ftcorpus, toSpace, "c\\(")
# clean corpus for useful words only
ftclean <- tm_map(ftcorpus, tolower)
ftclean <- tm_map(ftclean, removeNumbers)
ftclean <- tm_map(ftclean, removePunctuation)
ftclean <- tm_map(ftclean, removeWords, stopwords("english"))
ftclean <- tm_map(ftclean, stemDocument)
# check the result
# inspect(ftclean)
#build wordcloud
wordcloud(ftclean,
min.freq = 6,
colors = viridis(24),
random.order = F)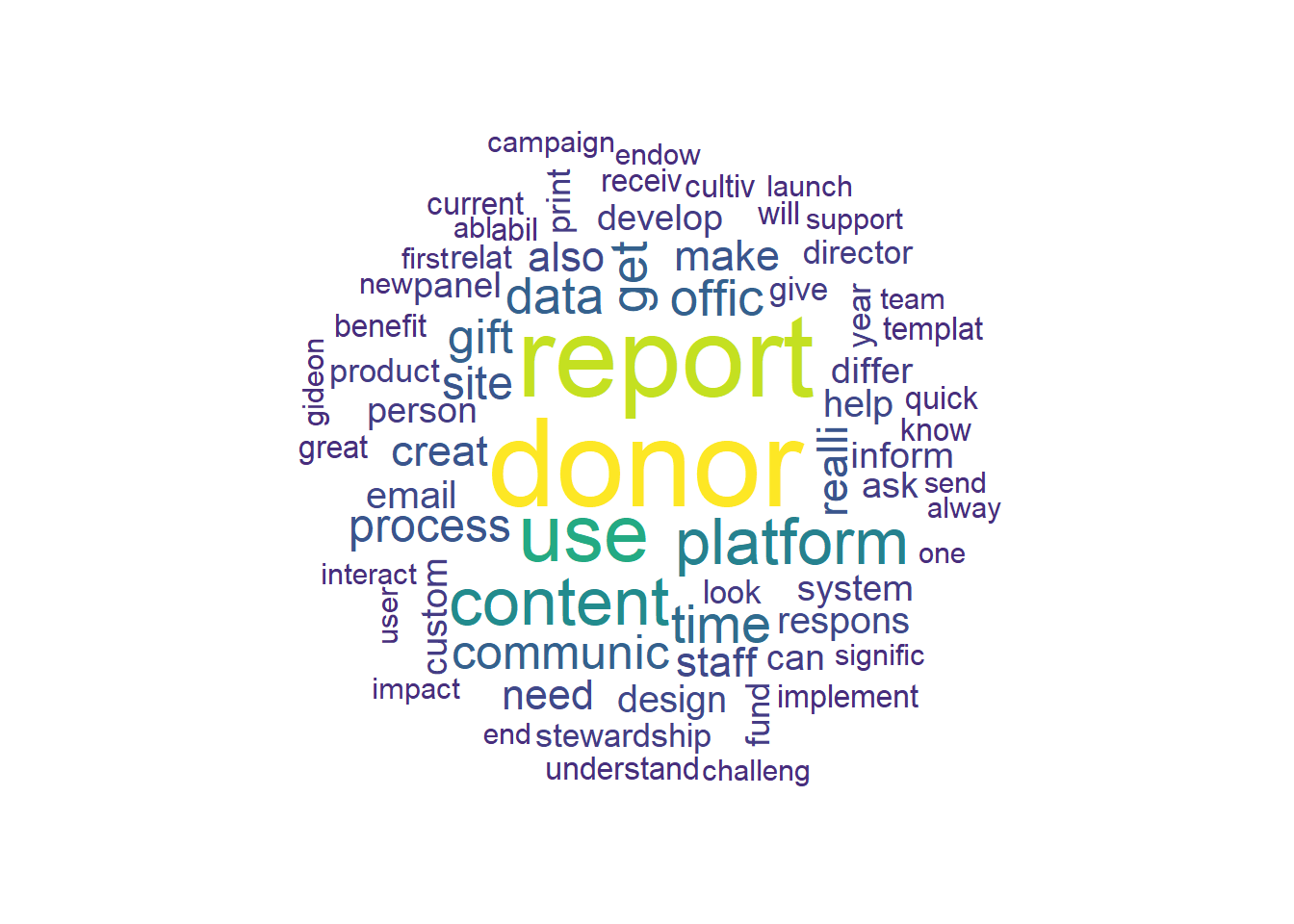
This visualization makes it easy to identify the top five wordstems respondents used: donor, report, use, content, and platform. To begin to interpret this outcome, it is unsurprising that these are the top five words. After all, the software is a platform for sharing reports and content with donors, and the questions are aimed at the staff who use that platform. No big surprises there. One strange output is the wordstem, “realli”, which upon investigation turns out to be many uses of the word really. It would be interesting to compare these words respondents used most to the frequency with which the same words appear in the prompts.
After the top five, the rest are more difficult to rank visually in a word cloud, so a barplot will be helpful here. Since the barplot is more orderly and therefore easier to read, the minimum frequency used in this plot is increased from 6 to 8 occurrences. The result is below in descending order.
# set up ordered list of most frequent stem words
dtm <- DocumentTermMatrix(ftclean)
freq <- colSums(as.matrix(dtm))
freq <- freq[order(freq, decreasing=TRUE)]
# create data set with words and its frequency
wf <- data.frame(word=names(freq), freq=freq)
# plot word frequency
ggplot(subset(wf, freq > 8),
aes(x = reorder(word, freq), freq)) +
geom_bar(stat="identity", fill = "#21918c") +
coord_flip() +
theme_minimal() +
labs(title = "Most Frequently Used Words in Survey Responses", y = "times used", x = "root word")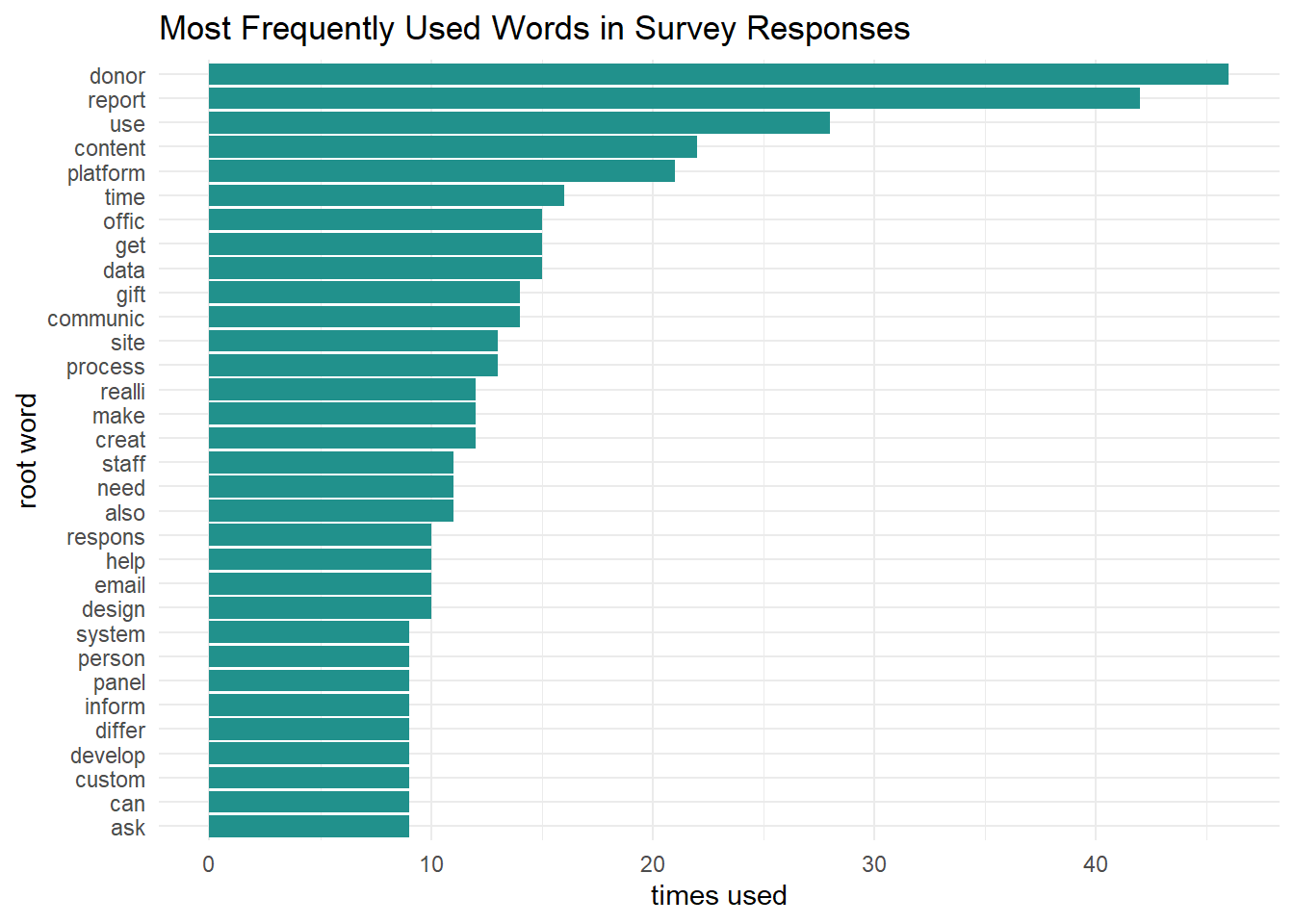
A barplot stacks the words neatly, and with them sorted by frequency, it is very easy to identify their frequency in relation to one another. It is also much easier to read the words themselves. After the top five, it is now possible to identify the next group of most frequently used words: time, office/officer, get, data, gift, and communicate/communication. We now know that time is a high concern for this group, as well as (possibly) “getting data”, (possibly) “gift officers”, and various aspects of communication. It could be interesting to follow up with an analysis of two-word pairs to see if these theories play out.
Despite the relatively small sample size, several strong trends emerge in the results of these surveys. The software company now has a sense of which factors were most powerful in prompting its adoption, which aspects of launching the software required the most effort, which benefits were being experienced most at the time of the survey, and what concepts the respondents are considering most when given the chance to respond in their own words. These are valuable findings that can help shape the company’s onboarding program, business development, and product refinement.
The use of R in this analysis was critical to its success and replicability. The “viridis” color palette was selected for its high visual accessibility. The analysis includes both quantitative analysis and qualitative analysis and approaches many aspects of data cleaning and tidying that were unique to each grouping of survey questions.
Acknowledgment and much gratitude is due to Professors Meredith Rolfe and Dr. Rosemary Pang; DACSS tutors Maddie Hertz, Sathvik Thogaru, and Leah Dion; and classmates who helped along the way. Thanks as well to the online R coding community on GitHub, StackOverflow, and R-Bloggers.com. This global community gave guidance and training, asked interesting questions, infused the learning process with humanity and good humor, and was boldly vulnerable. Many thanks to all of you.
Complete Survey Questions and Renaming Notes
# [1] "Timestamp.x"
# [2] "UserID"
# [3] "What size sweatshirt would you like (we are out of mediums, sorry!)?.x"
# renamed: delete
# [4] "What address should we ship the sweatshirt to?.x"
# renamed: delete
# [5] "What prompted your adoption of O?.x"
# renamed:prompted_adoption
# [6] "What is your annual fundraising goal, and how many constituents do you reach out to with O?.x"
# renamed:goal_constituents
# [7] "Outside of your user base, how many individuals support processes within O and what are their individual roles? If possible, please estimate what percentage of their time is O focused..x"
# renamed: launcheffort_staffrolestime
# [8] "Please indicate the scale of effort required for launching the various aspects of O (1 = Low level of effort; 5 = High level of effort). [Retasking of staff].x"
# renamed: launcheffort_retaskstaff
# [9] "Please indicate the scale of effort required for launching the various aspects of O (1 = Low level of effort; 5 = High level of effort). [Generating content].x"
# renamed: launcheffort_generatecontent
# [10] "Please indicate the scale of effort required for launching the various aspects of O (1 = Low level of effort; 5 = High level of effort). [Tech/Interface with IT].x"
# renamed: launcheffort_techIT
# [11] "Please indicate the scale of effort required for launching the various aspects of O (1 = Low level of effort; 5 = High level of effort). [Challenges with staff adoption and comfort].x"
# renamed: launcheffort_staffadoption
# [12] "Please add any comments or details that would help us understand your ratings better....12.x"
# renamed: launcheffort_detail
# [13] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Improved number or quality of donor engagement touches (whether measured or anecdotal)].x"
# renamed: benefit_donorengagement
# [14] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Increase in financial contributions].x"
# renamed: benefit_increasedgifts
# [15] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Cost savings].x"
# renamed: benefit_costsavings
# [16] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Time savings].x"
# renamed: benefit_timesavings
# [17] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Increased gift officer productivity].x"
# renamed: benefit_GOproductivity
# [18] "Please add any comments or details that would help us understand your ratings better....18.x"
# renamed: benefit_detail
# [19] "How did you manage philanthropic communications before O?.x"
# renamed: donor_commsbefore
# [20] "What is your process for developing content, and how do you know what content to feed to each donor as you’re personalizing sites/reports? To what extent is this decided/produced by gift officers versus other team members?.x"
# renamed: process_content
# [21] "What challenges of donor relationship-building is O helping to solve for you?.x"
# renamed: donor_relationship
# [22] "How has O changed, facilitated, or limited your interaction with donors?.x"
# renamed: donor_interaction
# [23] "What has been the donor response to hyper-personalized communications?.x"
# renamed: donor_response
# [24] "What have you learned from looking at the end-donor use data O provides?.x"
# renamed: donor_analytics
# [25] "What have you learned about your internal team through the aggregate analytics module?.x"
# renamed: team_analytics
# [26] "How would you rate SA/O’s implementation and support?.x"
# renamed: rateO_implementationsupport
# [27] "Is there anything you would like to expand upon regarding your selection above?.x"
# renamed: rateO_support_detail
# [28] "What could have been handled better?.x"
# renamed: O_lacking
# [29] "What is the biggest O-facilitated success your organization can point to (either with an individual donor relationship or in the aggregate)?.x"
# renamed: biggest_success
# [30] "How was the reality of O different from your expectations (both positive and negative)?.x"
# renamed: reality_vs_expectations
# [31] "What advice would you have for future O users?.x"
# renamed: client_advice
# [32] "How can O improve (in big and small ways)? Your complete candor would be much appreciated..x"
# renamed: O_improve
# [33] "Timestamp.y"
# renamed: reorder to beginning
# [34] "What prompted your adoption of O?.y"
# renamed: prompted_adoption2
# [35] "Why did you choose O over other platforms you were exploring?"
# renamed: O_over_competitors
# [36] "If \"unique product features\" was selected in the above question, can you please elaborate?"
# renamed: feature_detail
# [37] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Improved number or quality of donor engagement touches (whether measured or anecdotal)].y"
# renamed: benefit_donorengagement2
# [38] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Increase in financial contributions].y"
# renamed: benefit_increasedgifts2
# [39] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Cost savings].y"
# renamed: benefit_costsavings2
# [40] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Time savings].y"
# renamed: benefit_timesavings2
# [41] "Please indicate the degree to which you have experienced the following benefits from O (1 = To a small degree; 5 = To a great degree). [Increased gift officer productivity].y"
# renamed: benefit_GOproductivity2
# [42] "Please share any other factors your team considered before selecting O (if applicable)."
# renamed: choice_factors
# [43] "Timestamp"
# [44] "Overall, how did the onboarding process go for you?"
# renamed: onboard_overall
# [45] "What part of the onboarding process could O have handled better?"
# renamed: onboard_lacking
# [46] "Please expand on your selections above:...5"
# renamed: onboard_lacking_detail
# [47] "What part of the onboarding process did O handle especially well?"
# renamed: onboard_wentwell
# [48] "Please expand on your selections above:...7"
# renamed: onboard_wentwell_detail
# [49] "How effectively did we communicate during the onboarding process?"
# renamed: onboard_communication
# [50] "Please expand on your selections above:...9"
# renamed: onboard_communication_detail
# [51] "How effectively did we interpret your needs during the onboarding process?"
# renamed: onboard_interpretneeds
# [52] "Please expand on your selections above:...11"
# renamed: onboard_interpretneeds_detail
# [53] "Are you willing to talk about your onboarding experience with future O clients?"
# renamed: onboard_shareexperience