library(tidyverse)
library(ggplot2)
library(lubridate)
library(dplyr)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 7
challenge_7
Harsha Kanaka Eswar Gudidpudi
abc_poll_2021.csv
Visualizing Multiple Dimensions
Challenge Overview
Today’s challenge is to:
- read in a data set, and describe the data set using both words and any supporting information (e.g., tables, etc)
- tidy data (as needed, including sanity checks)
- mutate variables as needed (including sanity checks)
- Recreate at least two graphs from previous exercises, but introduce at least one additional dimension that you omitted before using ggplot functionality (color, shape, line, facet, etc) The goal is not to create unneeded chart ink (Tufte), but to concisely capture variation in additional dimensions that were collapsed in your earlier 2 or 3 dimensional graphs.
- Explain why you choose the specific graph type
- If you haven’t tried in previous weeks, work this week to make your graphs “publication” ready with titles, captions, and pretty axis labels and other viewer-friendly features
R Graph Gallery is a good starting point for thinking about what information is conveyed in standard graph types, and includes example R code. And anyone not familiar with Edward Tufte should check out his fantastic books and courses on data visualizaton.
(be sure to only include the category tags for the data you use!)
Read in data
Read in one (or more) of the following datasets, using the correct R package and command.
- eggs ⭐
- abc_poll ⭐⭐
- australian_marriage ⭐⭐
- hotel_bookings ⭐⭐⭐
- air_bnb ⭐⭐⭐
- us_hh ⭐⭐⭐⭐
- faostat ⭐⭐⭐⭐⭐
# Read in the data
df <- read.csv("_data/abc_poll_2021.csv")
head(df) id xspanish complete_status ppage
1 7230001 English qualified 68
2 7230002 English qualified 85
3 7230003 English qualified 69
4 7230004 English qualified 74
5 7230005 English qualified 77
6 7230006 English qualified 70
ppeduc5
1 High school graduate (high school diploma or the equivalent GED)
2 Bachelor\x92s degree
3 High school graduate (high school diploma or the equivalent GED)
4 Bachelor\x92s degree
5 High school graduate (high school diploma or the equivalent GED)
6 Bachelor\x92s degree
ppeducat ppgender ppethm pphhsize
1 High school Female White, Non-Hispanic 2
2 Bachelors degree or higher Male White, Non-Hispanic 2
3 High school Male White, Non-Hispanic 2
4 Bachelors degree or higher Female White, Non-Hispanic 1
5 High school Male White, Non-Hispanic 3
6 Bachelors degree or higher Male White, Non-Hispanic 2
ppinc7 ppmarit5 ppmsacat ppreg4
1 $25,000 to $49,999 Now Married Metro area South
2 $150,000 or more Now Married Metro area South
3 $100,000 to $149,999 Now Married Metro area South
4 $25,000 to $49,999 Divorced Metro area NorthEast
5 $10,000 to $24,999 Now Married Metro area MidWest
6 $75,000 to $99,999 Now Married Metro area MidWest
pprent ppstaten
1 Owned or being bought by you or someone in your household Florida
2 Owned or being bought by you or someone in your household Kentucky
3 Owned or being bought by you or someone in your household Florida
4 Owned or being bought by you or someone in your household Pennsylvania
5 Owned or being bought by you or someone in your household Michigan
6 Owned or being bought by you or someone in your household Missouri
PPWORKA ppemploy Q1_a Q1_b
1 Retired Not working Approve Approve
2 Retired Not working Approve Approve
3 Retired Not working Disapprove Disapprove
4 Retired Not working Approve Approve
5 Retired Not working Approve Approve
6 Employed part-time (by someone else) Working part-time Approve Approve
Q1_c Q1_d Q1_e Q1_f Q2 Q3 Q4
1 Disapprove Approve Approve Disapprove Not so concerned Yes Good
2 Approve Approve Approve Approve Somewhat concerned Yes Good
3 Disapprove Disapprove Disapprove Approve Very concerned Yes Poor
4 Approve Approve Approve Approve Somewhat concerned Yes Excellent
5 Approve Approve Approve Approve Somewhat concerned Yes Excellent
6 Approve Approve Disapprove Approve Not so concerned Yes Excellent
Q5 QPID ABCAGE Contact
1 Optimistic A Democrat 65+ No, I am not willing to be interviewed
2 Optimistic An Independent 65+ No, I am not willing to be interviewed
3 Pessimistic Something else 65+ No, I am not willing to be interviewed
4 Pessimistic An Independent 65+ Yes, I am willing to be interviewed
5 Optimistic A Democrat 65+ No, I am not willing to be interviewed
6 Optimistic A Democrat 65+ No, I am not willing to be interviewed
weights_pid
1 0.6382
2 0.5493
3 0.8488
4 0.8126
5 0.4994
6 0.4043Briefly describe the data
The dataset consists of 527 observations, each representing an individual. The variables in the dataset include demographic information such as age, gender, ethnicity, education level, household size, income range, marital status, and region of residence. The dataset also includes variables related to work status, employment, and political affiliation. Additionally, there are multiple-choice questions and responses, along with measures of concern, self-perceived quality of life, and optimism/pessimism about the future. The dataset also contains information about the individual’s willingness to be interviewed and weights assigned to each observation. The dataset provides a comprehensive overview of various demographic and socio-political factors for a sample of individuals. It offers valuable insights into the characteristics and perspectives of the respondents, making it suitable for analyzing relationships and patterns among the variables and drawing conclusions about the population they represent.
dim(df)[1] 527 31summary(df) id xspanish complete_status ppage
Min. :7230001 Length:527 Length:527 Min. :18.00
1st Qu.:7230132 Class :character Class :character 1st Qu.:40.00
Median :7230264 Mode :character Mode :character Median :55.00
Mean :7230264 Mean :53.39
3rd Qu.:7230396 3rd Qu.:67.00
Max. :7230527 Max. :91.00
ppeduc5 ppeducat ppgender ppethm
Length:527 Length:527 Length:527 Length:527
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
pphhsize ppinc7 ppmarit5 ppmsacat
Length:527 Length:527 Length:527 Length:527
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
ppreg4 pprent ppstaten PPWORKA
Length:527 Length:527 Length:527 Length:527
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
ppemploy Q1_a Q1_b Q1_c
Length:527 Length:527 Length:527 Length:527
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Q1_d Q1_e Q1_f Q2
Length:527 Length:527 Length:527 Length:527
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Q3 Q4 Q5 QPID
Length:527 Length:527 Length:527 Length:527
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
ABCAGE Contact weights_pid
Length:527 Length:527 Min. :0.3240
Class :character Class :character 1st Qu.:0.6332
Mode :character Mode :character Median :0.8451
Mean :1.0000
3rd Qu.:1.1516
Max. :6.2553 # Get unique values for the ppstaten column
unique_ppstaten <- unique(df$ppstaten)
cat(paste(unique_ppstaten, collapse = ", "))Florida, Kentucky, Pennsylvania, Michigan, Missouri, New Jersey, Georgia, Washington, New Hampshire, Maryland, California, Arizona, Texas, North Dakota, Connecticut, Massachusetts, Oregon, Illinois, Arkansas, South Carolina, Tennessee, Hawaii, Kansas, Colorado, Louisiana, Virginia, Wisconsin, Vermont, Ohio, North Carolina, New York, Nevada, Nebraska, Idaho, Alabama, Minnesota, Montana, Utah, New Mexico, Oklahoma, Indiana, South Dakota, Mississippi, Delaware, District of Columbia, West Virginia, Wyoming, Maine, Iowastr(df)'data.frame': 527 obs. of 31 variables:
$ id : int 7230001 7230002 7230003 7230004 7230005 7230006 7230007 7230008 7230009 7230010 ...
$ xspanish : chr "English" "English" "English" "English" ...
$ complete_status: chr "qualified" "qualified" "qualified" "qualified" ...
$ ppage : int 68 85 69 74 77 70 26 76 78 47 ...
$ ppeduc5 : chr "High school graduate (high school diploma or the equivalent GED)" "Bachelor\x92s degree" "High school graduate (high school diploma or the equivalent GED)" "Bachelor\x92s degree" ...
$ ppeducat : chr "High school" "Bachelors degree or higher" "High school" "Bachelors degree or higher" ...
$ ppgender : chr "Female" "Male" "Male" "Female" ...
$ ppethm : chr "White, Non-Hispanic" "White, Non-Hispanic" "White, Non-Hispanic" "White, Non-Hispanic" ...
$ pphhsize : chr "2" "2" "2" "1" ...
$ ppinc7 : chr "$25,000 to $49,999" "$150,000 or more" "$100,000 to $149,999" "$25,000 to $49,999" ...
$ ppmarit5 : chr "Now Married" "Now Married" "Now Married" "Divorced" ...
$ ppmsacat : chr "Metro area" "Metro area" "Metro area" "Metro area" ...
$ ppreg4 : chr "South" "South" "South" "NorthEast" ...
$ pprent : chr "Owned or being bought by you or someone in your household" "Owned or being bought by you or someone in your household" "Owned or being bought by you or someone in your household" "Owned or being bought by you or someone in your household" ...
$ ppstaten : chr "Florida" "Kentucky" "Florida" "Pennsylvania" ...
$ PPWORKA : chr "Retired" "Retired" "Retired" "Retired" ...
$ ppemploy : chr "Not working" "Not working" "Not working" "Not working" ...
$ Q1_a : chr "Approve" "Approve" "Disapprove" "Approve" ...
$ Q1_b : chr "Approve" "Approve" "Disapprove" "Approve" ...
$ Q1_c : chr "Disapprove" "Approve" "Disapprove" "Approve" ...
$ Q1_d : chr "Approve" "Approve" "Disapprove" "Approve" ...
$ Q1_e : chr "Approve" "Approve" "Disapprove" "Approve" ...
$ Q1_f : chr "Disapprove" "Approve" "Approve" "Approve" ...
$ Q2 : chr "Not so concerned" "Somewhat concerned" "Very concerned" "Somewhat concerned" ...
$ Q3 : chr "Yes" "Yes" "Yes" "Yes" ...
$ Q4 : chr "Good" "Good" "Poor" "Excellent" ...
$ Q5 : chr "Optimistic" "Optimistic" "Pessimistic" "Pessimistic" ...
$ QPID : chr "A Democrat" "An Independent" "Something else" "An Independent" ...
$ ABCAGE : chr "65+" "65+" "65+" "65+" ...
$ Contact : chr "No, I am not willing to be interviewed" "No, I am not willing to be interviewed" "No, I am not willing to be interviewed" "Yes, I am willing to be interviewed" ...
$ weights_pid : num 0.638 0.549 0.849 0.813 0.499 ...Tidy Data (as needed)
Is your data already tidy, or is there work to be done? Be sure to anticipate your end result to provide a sanity check, and document your work here.
Taking the selected columns Q1_a, Q1_b, Q1_c, Q1_d, Q1_e, and Q1_f and transforming them into two new columns: Question and Response. The Question column contains the names of the original columns, and the Response column contains the corresponding values. It becomes easier to perform operations such as grouping, filtering, and plotting.
tidy_data <- df %>%
select(ppgender, ppethm, ppmarit5, ppinc7, ppstaten, Q1_a, Q1_b, Q1_c, Q1_d, Q1_e, Q1_f, Q2, Q3, Q4, Q5) %>%
pivot_longer(cols = c(Q1_a, Q1_b, Q1_c, Q1_d, Q1_e, Q1_f),
names_to = "Question",
values_to = "Response") %>%
filter(!is.na(Response))
head(tidy_data %>% select(Question, Response))# A tibble: 6 × 2
Question Response
<chr> <chr>
1 Q1_a Approve
2 Q1_b Approve
3 Q1_c Disapprove
4 Q1_d Approve
5 Q1_e Approve
6 Q1_f DisapproveAre there any variables that require mutation to be usable in your analysis stream? For example, do you need to calculate new values in order to graph them? Can string values be represented numerically? Do you need to turn any variables into factors and reorder for ease of graphics and visualization?
Creating a new column called “ppage_category” the cut() function. This new column categorizes the values in the “ppage” column into different age groups based on specified intervals. The resulting “ppage_category” column provides a categorical representation of the age groups: “Young”, “Middle-aged”, “Senior”, and “Unknown”.
selected_data <- df[, c("id", "ppage", "ppeducat", "ppgender", "ppethm", "pphhsize", "ppinc7")]
selected_data$ppage_category <- cut(selected_data$ppage,
breaks = c(0, 30, 50, 70, Inf),
labels = c("Young", "Middle-aged", "Senior", "Unknown"))Document your work here.
Visualization with Multiple Dimensions
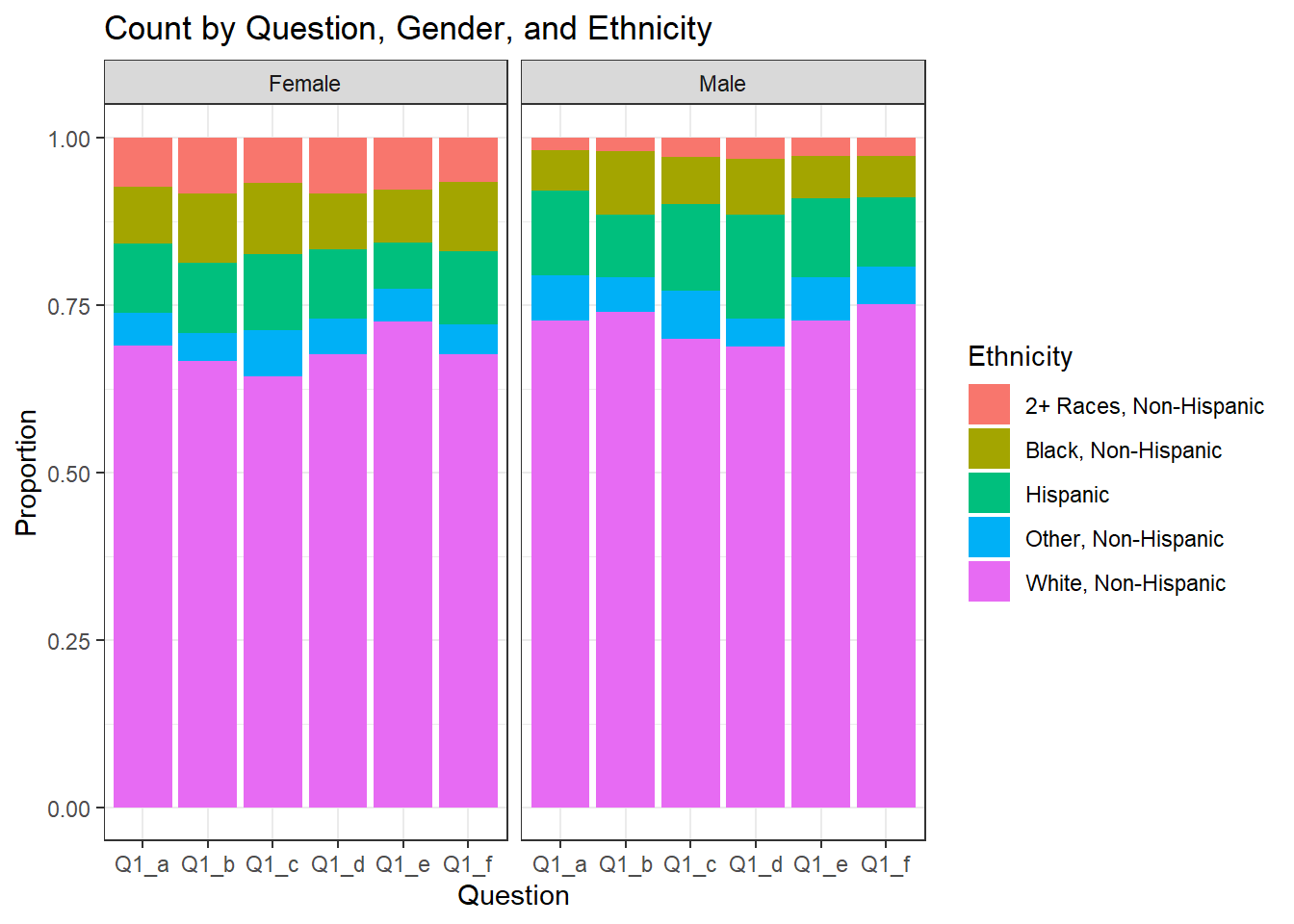
creating two visualizations. The first is a bar chart showing the count of responses for each question. The second is a stacked bar chart displaying the count of responses for each question, grouped by gender and ethnicity.These visualizations allow us to explore the distribution of responses across different questions and examine how it varies by gender and ethnicity.
# Create a bar chart of count by Question and Response
ggplot(tidy_data, aes(x = Question, fill = Response)) +
geom_bar() +
labs(title = "Count by Question and Response",
x = "Question",
y = "Count",
fill = "Response") +
theme_bw()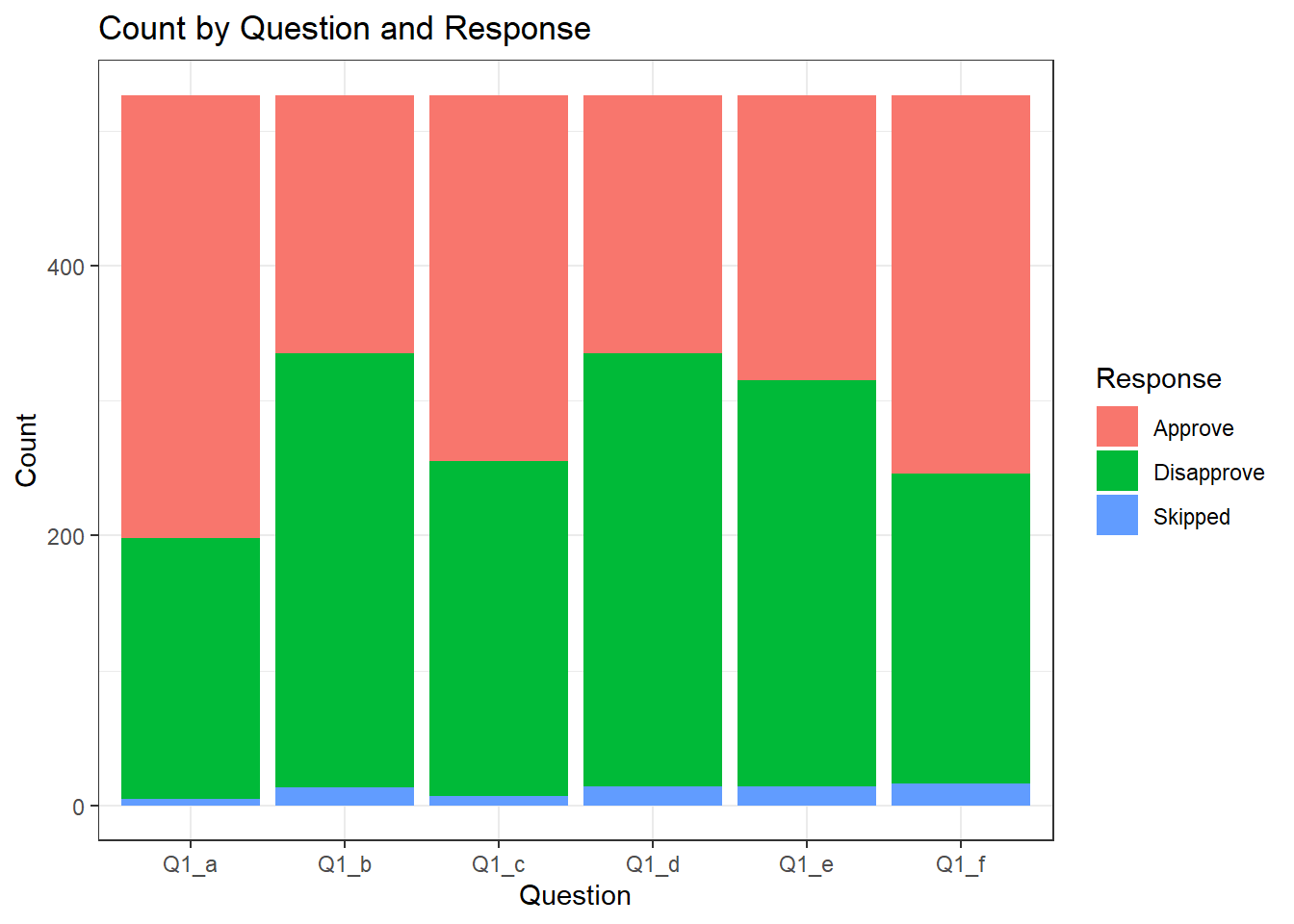
# Create a stacked bar chart of count by Question response Approve, grouped by Gender and Ethnicity
ggplot(tidy_data %>%filter(Response == "Approve"), aes(x = Question, fill = ppethm)) +
geom_bar(position = "fill") +
facet_wrap(~ppgender) +
labs(title = "Count by Question, Gender, and Ethnicity",
x = "Question",
y = "Proportion",
fill = "Ethnicity") +
theme_bw()