Generated by summarytools 1.0.1 (R version 4.2.2) 2023-04-04
We can see there are many attributes in this dataset,we can choose several of them to analysis.
str(airbnbData)
'data.frame': 48895 obs. of 16 variables:
$ id : int 2539 2595 3647 3831 5022 5099 5121 5178 5203 5238 ...
$ name : chr "Clean & quiet apt home by the park" "Skylit Midtown Castle" "THE VILLAGE OF HARLEM....NEW YORK !" "Cozy Entire Floor of Brownstone" ...
$ host_id : int 2787 2845 4632 4869 7192 7322 7356 8967 7490 7549 ...
$ host_name : chr "John" "Jennifer" "Elisabeth" "LisaRoxanne" ...
$ neighbourhood_group : chr "Brooklyn" "Manhattan" "Manhattan" "Brooklyn" ...
$ neighbourhood : chr "Kensington" "Midtown" "Harlem" "Clinton Hill" ...
$ latitude : num 40.6 40.8 40.8 40.7 40.8 ...
$ longitude : num -74 -74 -73.9 -74 -73.9 ...
$ room_type : chr "Private room" "Entire home/apt" "Private room" "Entire home/apt" ...
$ price : int 149 225 150 89 80 200 60 79 79 150 ...
$ minimum_nights : int 1 1 3 1 10 3 45 2 2 1 ...
$ number_of_reviews : int 9 45 0 270 9 74 49 430 118 160 ...
$ last_review : chr "2018-10-19" "2019-05-21" "" "2019-07-05" ...
$ reviews_per_month : num 0.21 0.38 NA 4.64 0.1 0.59 0.4 3.47 0.99 1.33 ...
$ calculated_host_listings_count: int 6 2 1 1 1 1 1 1 1 4 ...
$ availability_365 : int 365 355 365 194 0 129 0 220 0 188 ...
Univariate Visualizations
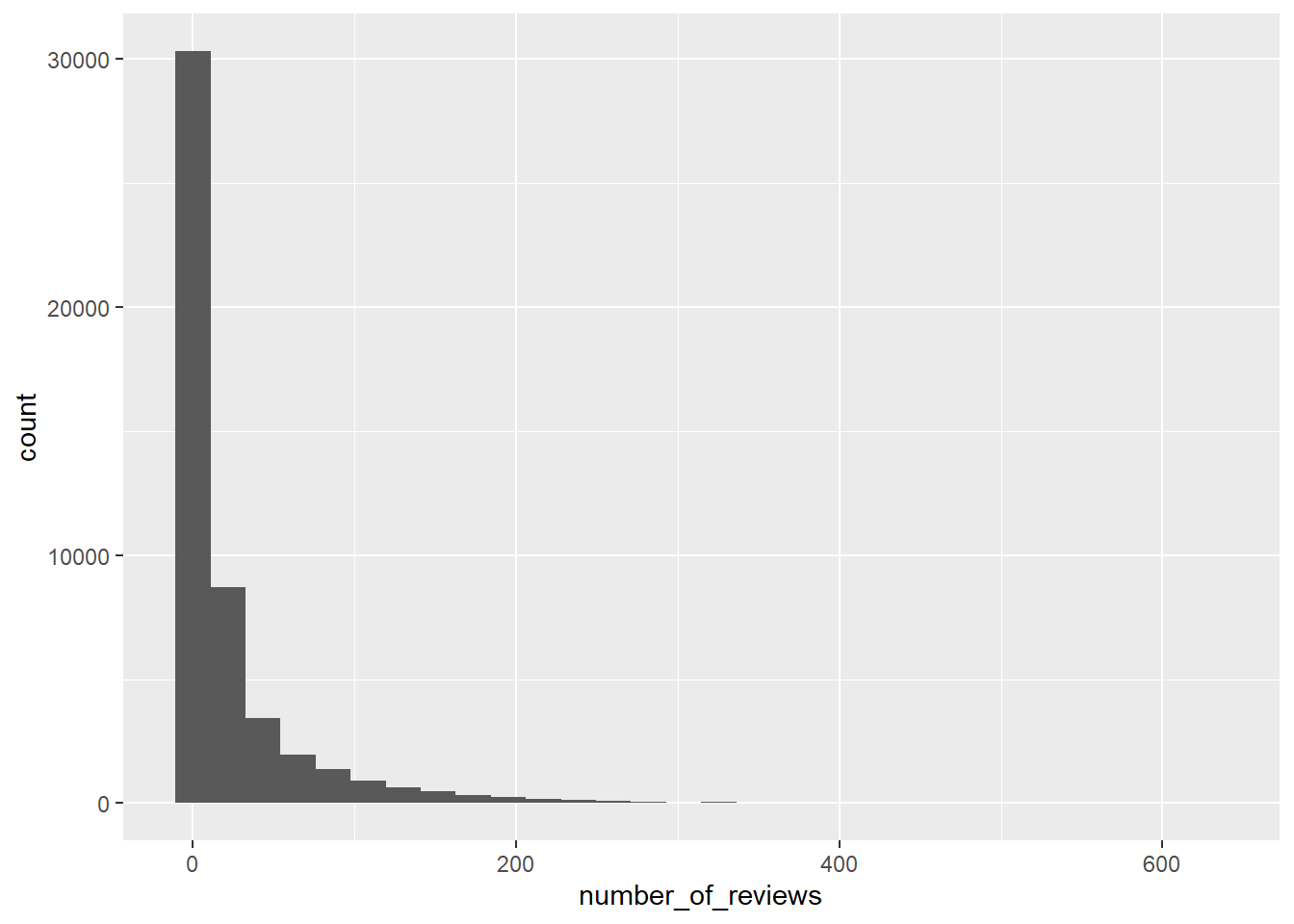
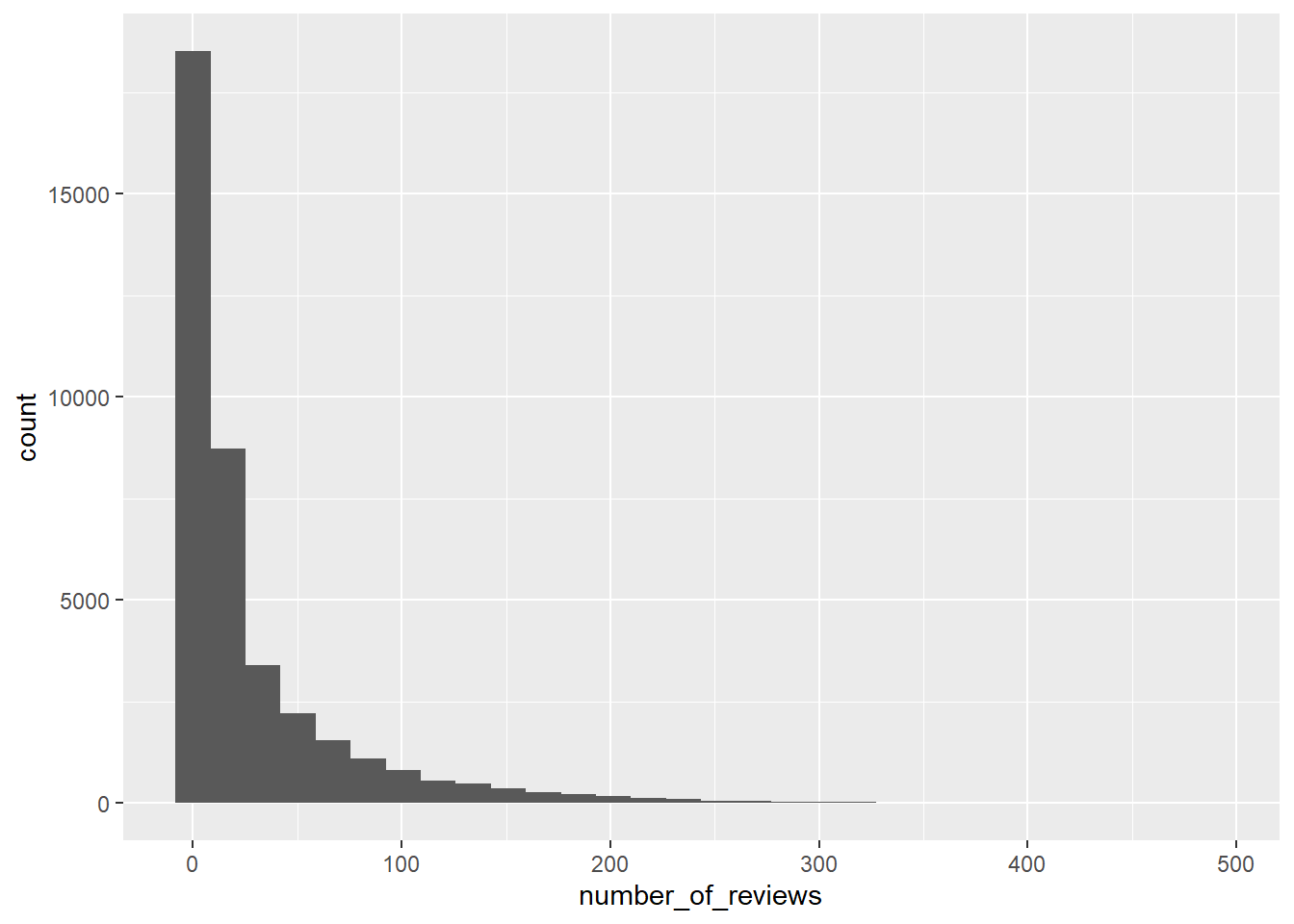
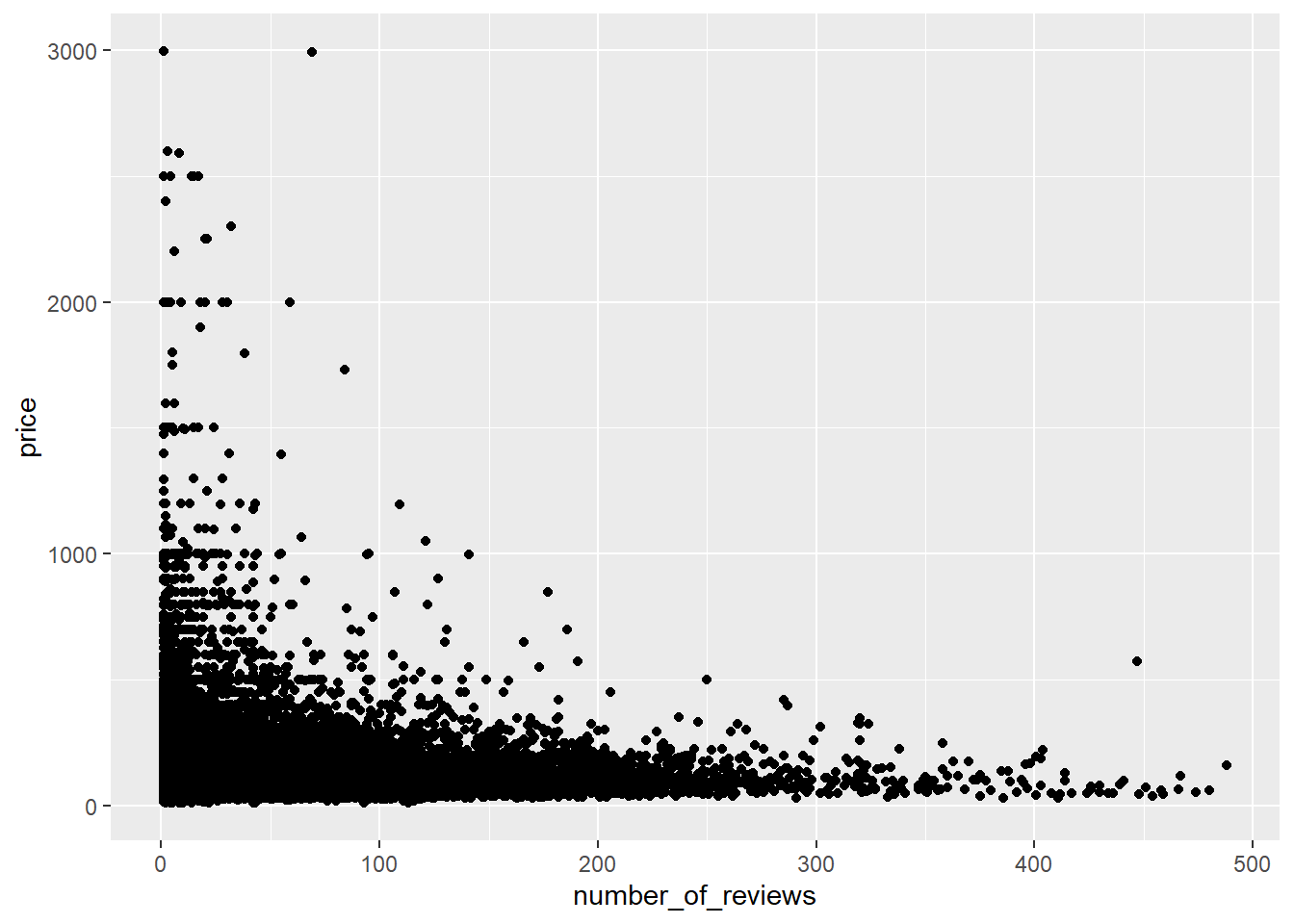
Firstly,I’m curious about the number of reviews. We can use ggplot() and geom_histogram() to show it’s basic character.We can see that the number of reviews mainly concerntrate between 0 and 500.So we can try to tidy them.
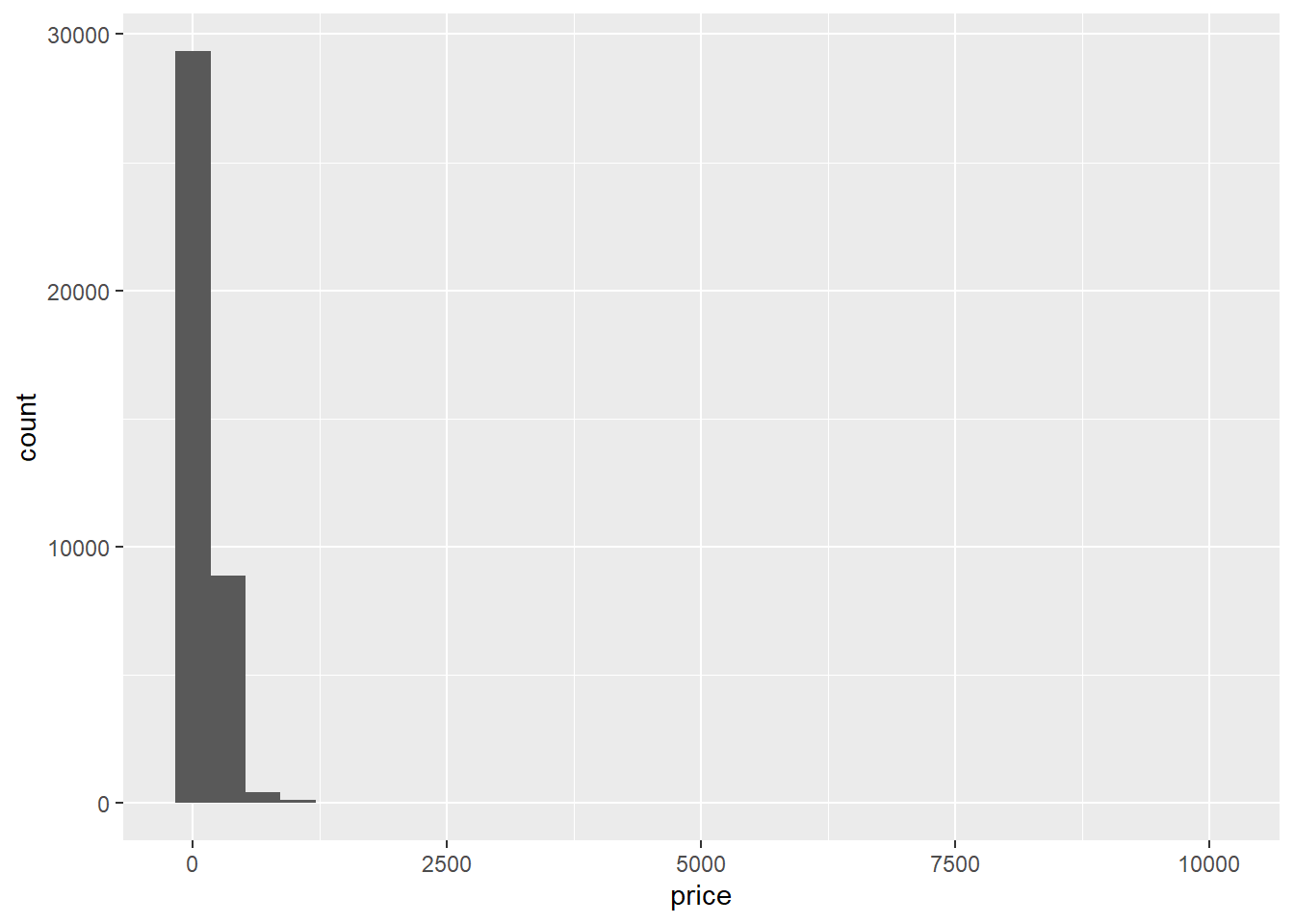
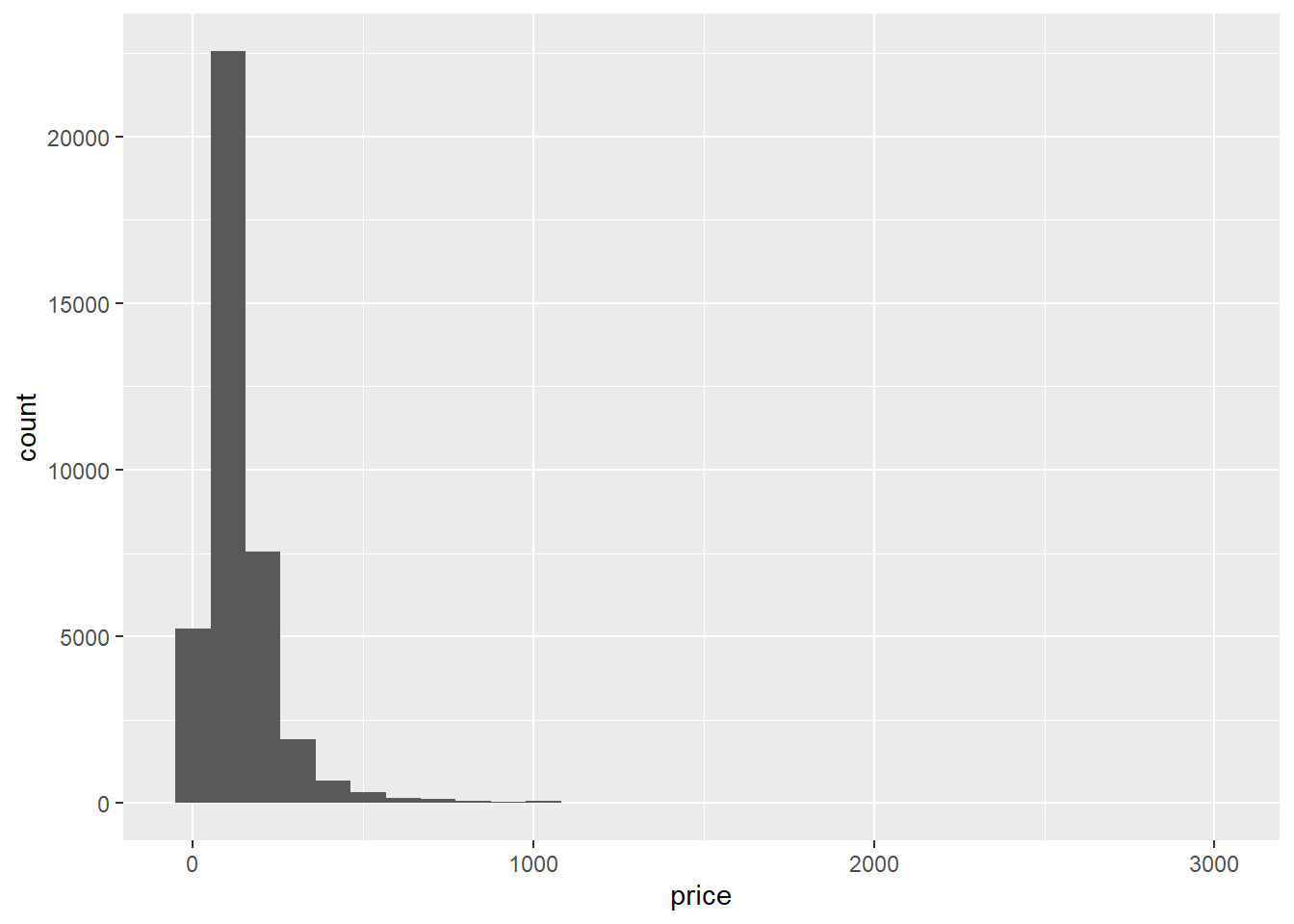
It seems that the number of evaluations is negatively correlated with the price.
Source Code
---title: "Challenge_5"author: "Xinyang Mao"description: "Introduction to Visualization"date: "04/04/2023"format: html: toc: true code-copy: true code-tools: truecategories: - challenge_5 - air_bnb---```{r}#| label: setup#| warning: false#| message: falselibrary(tidyverse)library(ggplot2)knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```## Challenge OverviewToday's challenge is to:1) read in a data set, and describe the data set using both words and any supporting information (e.g., tables, etc)2) tidy data (as needed, including sanity checks)3) mutate variables as needed (including sanity checks)4) create at least two univariate visualizations - try to make them "publication" ready - Explain why you choose the specific graph type5) Create at least one bivariate visualization - try to make them "publication" ready - Explain why you choose the specific graph type[R Graph Gallery](https://r-graph-gallery.com/) is a good starting point for thinking about what information is conveyed in standard graph types, and includes example R code.(be sure to only include the category tags for the data you use!)## Read in dataRead in one (or more) of the following datasets, using the correct R package and command.- AB_NYC_2019.csv ⭐⭐⭐In this challenge I chose the airbnb dataset.```{r}airbnbData <-read.csv("_data/AB_NYC_2019.csv")head(airbnbData)```### Briefly describe the data```{r}print(summarytools::dfSummary(airbnbData,varnumbers =FALSE,plain.ascii =FALSE, style ="grid", graph.magnif =0.70, valid.col =FALSE),method ='render',table.classes ='table-condensed')```We can see there are many attributes in this dataset,we can choose several of them to analysis.```{r}str(airbnbData)```## Univariate VisualizationsFirstly,I'm curious about the number of reviews.We can use `ggplot()` and `geom_histogram()` to show it's basic character.We can see that the number of reviews mainly concerntrate between 0 and 500.So we can try to tidy them.```{r}ggplot(airbnbData,aes(number_of_reviews)) +geom_histogram()``````{r}range(airbnbData$number_of_reviews)````filter()` can help to filter the outliers.```{r}airbnb_filtered <- airbnbData %>%filter(number_of_reviews >0& number_of_reviews <500)airbnb_filtered %>%ggplot(aes(number_of_reviews))+geom_histogram()```## Bivariate Visualization(s)I also wonder what's the relationship between `number_of_reviews` and `price`.We can observe the `price` attribute firstly.```{r}ggplot(airbnb_filtered,aes(price))+geom_histogram()``````{r}range(airbnb_filtered$price)```Also,we can filter the outliers of `price`,to keep the all of valid value in the range of 0~3000.```{r}airbnb_filtered <- airbnb_filtered %>%filter(price >0& price <3000)airbnb_filtered %>%ggplot(aes(price))+geom_histogram()```Now we can explore the relationship between `number_of_reviews` and `price`,let's have a look.We can use `geom_point()` to draw the Scatter chart.```{r}airbnb_filtered %>%ggplot(aes(number_of_reviews,price))+geom_point()```It seems that the number of evaluations is negatively correlated with the price.