library(tidyverse)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 6: Visualizing USA Households Data
laurenzichittella
challenge_6
usa_households
Visualizing Time and Relationships
Chunk 1: Read in data
The dataset I chose to utilize for this task measures the distribution of household income in the US between 1967 and 2019 by race and Hispanic origin.
During import of this file, I will limit observations to those that represent data by filtering out the header and footer sections. In addition, variables will be renamed from their original form in the xlsx file so new values are easier to understand and program with.
library(readxl)
library(stringr)
# Import data
usa_hh_raw <- read_excel( "_data/USA Households by Total Money Income, Race, and Hispanic Origin of Householder 1967 to 2019.xlsx"
, skip = 5
, col_names = c("hhorigin_year", "hh_n_k", "del", "pctdis_lt_15k", "pctdis_15_lt_25k", "pctdis_25_lt_35k", "pctdis_35_lt_50k", "pctdis_50_lt_75k", "pctdis_75_lt_100k","pctdis_100_lt_150k", "pctdis_150_lt_200k", "pctdis_ge_200k", "med_income", "me_med_income", "mean_income", "me_mean_income"))%>%
select(!contains("del"))
# remove footers obs
usa_hh_tidier <-
head(usa_hh_raw, -31)Chunk 2: Tidy data
Each observation in this dataset should represent a distinct race and Hispanic status, year of measure collection, and method for measure collection.
Tidying the file wasn’t straight forward because of a few characteristics in the original data including:
- Use of a single column to define race and Hispanic origin and year of measure
- Heavy utilization of footnotes in the combined race and Hispanic origin and year of measure
- Presence of multiple records per single combination of race and Hispanic origin, driven by these footnotes
Steps to resolving data issues 1) Create three new variables from original single column representing “combined race and Hispanic origin and year of measure” to represent race and Hispanic origin, year of measure collection, and footnote for method of measure collection perfectly) 2) Remove columns replaced by new variables
Steps to finalize cleaning of data
- Remove records with “header” for race and Hispanic status (measure values missing)
- Convert measure values to numeric type columns
- Convert year to date field
# mutate to create vars for hhorigin, year, footnotes
# define hhorigin
usa_hh_tidier <-
usa_hh_tidier %>%
mutate(temp_hhorigin = case_when(is.na(mean_income)~ hhorigin_year, TRUE ~ NA_character_),
hhorigin = str_replace(temp_hhorigin, "\\d+", ""))%>%
fill(hhorigin, .direction = "down")
#define measure year & footnote
usa_hh_tidier <-
usa_hh_tidier %>%
mutate(temp_year= case_when(!is.na(hh_n_k)~ hhorigin_year, TRUE ~ NA_character_),
year = substr(temp_year, 1, 4),
year_footnote = substr(temp_year, 5, nchar(temp_year)))
#remove blank rows without metrics
usa_hh_tidy <-
usa_hh_tidier %>%
filter(!is.na(mean_income))
#clean old columns
usa_hh_tidy <-
usa_hh_tidy %>%
select(!contains("hhorigin_year") & !contains("temp"))
#convert character metrics to numeric
usa_hh_tidy <-
usa_hh_tidy %>%
mutate_at(c(1:14), as.numeric) %>%
mutate('measure_date' = make_date(year = year, month = 3, day = 1)) %>%
select(!contains("year")) %>%
filter(!is.na(mean_income))
head(usa_hh_tidy)# A tibble: 6 × 16
hh_n_k pctdi…¹ pctdi…² pctdi…³ pctdi…⁴ pctdi…⁵ pctdi…⁶ pctdi…⁷ pctdi…⁸ pctdi…⁹
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 128451 9.1 8 8.3 11.7 16.5 12.3 15.5 8.3 10.3
2 128579 10.1 8.8 8.7 12 17 12.5 15 7.2 8.8
3 127669 10 9.1 9.2 12 16.4 12.4 14.7 7.3 8.9
4 127586 10.1 9.1 9.2 11.9 16.3 12.6 14.8 7.5 8.5
5 126224 10.4 9 9.2 12.3 16.7 12.2 15 7.2 8
6 125819 10.6 10 9.6 12.1 16.1 12.4 14.9 7.1 7.2
# … with 6 more variables: med_income <dbl>, me_med_income <dbl>,
# mean_income <dbl>, me_mean_income <dbl>, hhorigin <chr>,
# measure_date <date>, and abbreviated variable names ¹pctdis_lt_15k,
# ²pctdis_15_lt_25k, ³pctdis_25_lt_35k, ⁴pctdis_35_lt_50k, ⁵pctdis_50_lt_75k,
# ⁶pctdis_75_lt_100k, ⁷pctdis_100_lt_150k, ⁸pctdis_150_lt_200k,
# ⁹pctdis_ge_200k table(usa_hh_tidy$hhorigin)
ALL RACES ASIAN ALONE
55 20
ASIAN ALONE OR IN COMBINATION ASIAN AND PACIFIC ISLANDER
20 14
BLACK BLACK ALONE
35 20
BLACK ALONE OR IN COMBINATION HISPANIC (ANY RACE)
20 50
WHITE WHITE ALONE
35 20
WHITE ALONE, NOT HISPANIC WHITE, NOT HISPANIC
20 30 table(usa_hh_tidy$year_footnote) < table of extent 0 > print(summarytools::dfSummary(usa_hh_tidy,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.70,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Data Frame Summary
usa_hh_tidy
Dimensions: 339 x 16Duplicates: 0
| Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| hh_n_k [numeric] |
|
338 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_lt_15k [numeric] |
|
142 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_15_lt_25k [numeric] |
|
104 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_25_lt_35k [numeric] |
|
87 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_35_lt_50k [numeric] |
|
92 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_50_lt_75k [numeric] |
|
92 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_75_lt_100k [numeric] |
|
86 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_100_lt_150k [numeric] |
|
130 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_150_lt_200k [numeric] |
|
103 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| pctdis_ge_200k [numeric] |
|
114 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| med_income [numeric] |
|
338 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| me_med_income [numeric] |
|
307 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mean_income [numeric] |
|
339 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| me_mean_income [numeric] |
|
310 distinct values |  |
2 (0.6%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| hhorigin [character] |
|
|
 |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| measure_date [Date] |
|
53 distinct values |  |
0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.2)
2023-04-04
Chunk 3: Time Dependent Visualization
I would like to look at changes in median income overtime by household origin. This will be difficult to evaluate perfectly per presence of mulitple measures of median income per group when different methods were employed to collect information (see year_footnote). To avoid dealing with this, I will utilize the min value when more than one exists.
Turns out HH origin is a bit much as well. I’m going to simply these values for the sake of a clean plot prior to generating any graphic as well
To clean the display of median outcome, will divide by 1000 and make sure labels reflect this change in unit
# change unit of med income to x 1000
# clean up hhorigin
# limit to dates after 2000
usa_hh_tidy_g <-
usa_hh_tidy %>%
mutate(med_incomeK = med_income/1000) %>%
mutate(clean_origin = case_when ( str_detect(hhorigin, 'ASIAN') ~ "Asian"
, str_detect(hhorigin, 'BLACK') ~ "Black"
, str_detect(hhorigin, 'HISPANIC') ~ "Hispanic" , str_detect(hhorigin, 'WHITE') ~ "White"
,TRUE ~ "Other" ))
# Select minimum median income, remove reocrds for all origins combined
usa_hh_tidy_med_income<-
usa_hh_tidy_g %>%
group_by(clean_origin, measure_date)%>%
summarise(med_income = min(med_incomeK)) %>%
arrange(clean_origin, measure_date ) %>%
filter(!clean_origin=="Other")
usa_hh_tidy_med_income %>%
ggplot( aes(x=measure_date, y=med_income, group=clean_origin, color = clean_origin)) +
geom_line()+
ggtitle("Median Income by Year and Household Race and Hispanic Status")+
labs(y = "Median Income * 1000", x = "Year", colour = "Household Race and Hispanic Status")+
theme(axis.text.x = element_text(angle = 90))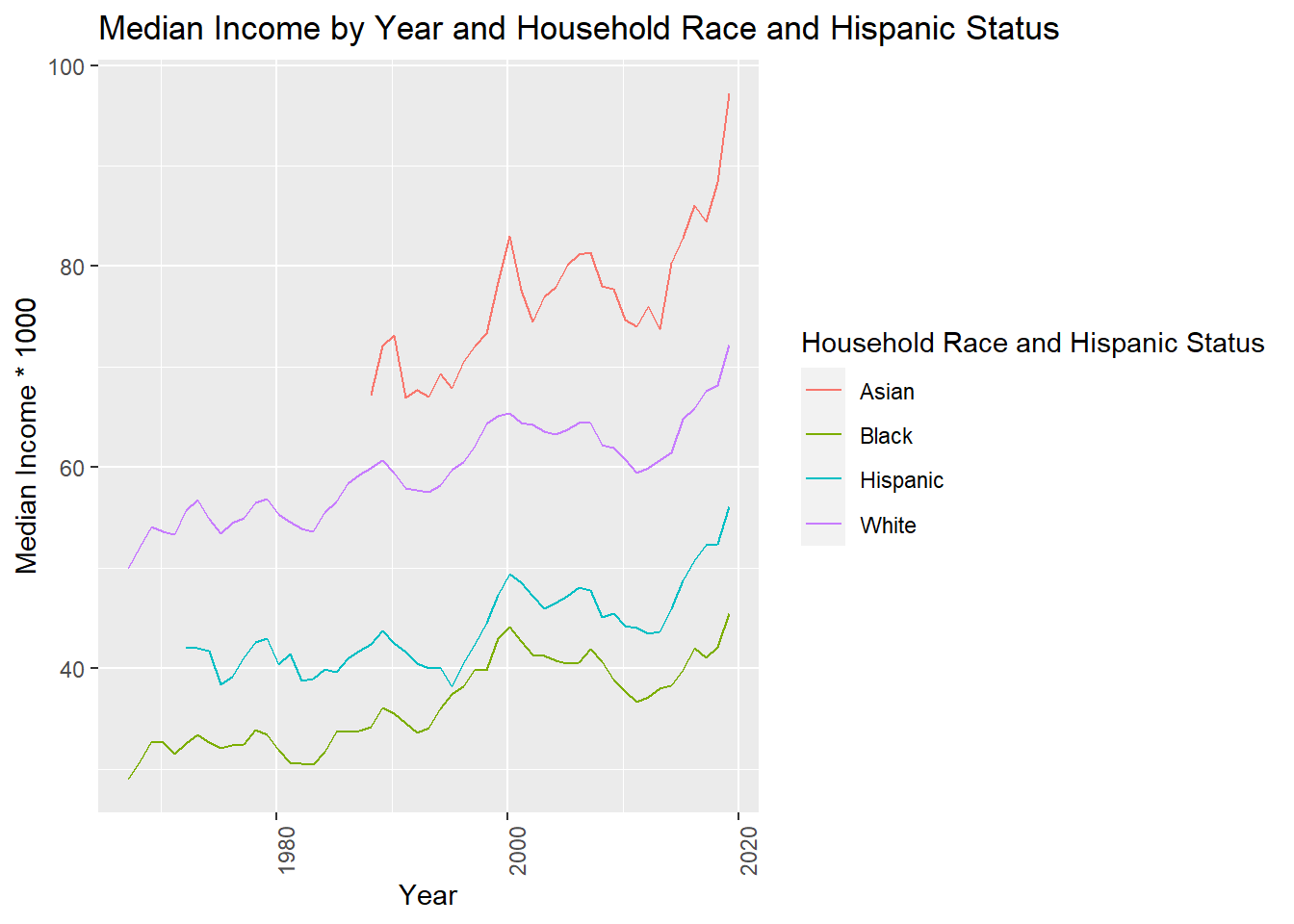
Chunk 4: Time Dependent Visualization (cont)
Weird stuff in the year distribution! Rather than spend a year looking into this, I will limit graph to 2000 forward.
# limit to time period starting in 2000
usa_hh_tidy_med_income_2020 <-
usa_hh_tidy_med_income %>%
filter(measure_date > '1999-01-01')
usa_hh_tidy_med_income_2020 %>%
ggplot( aes(x=measure_date, y=med_income, group=clean_origin, color = clean_origin)) +
geom_line()+
ggtitle("Median Income 2000-2020, by Year and Household Race and Hispanic Status")+
labs(y = "Median Income, * $1000)", x = "Year", colour = "Household Race and Hispanic Status")+
theme(axis.text.x = element_text(angle = 90))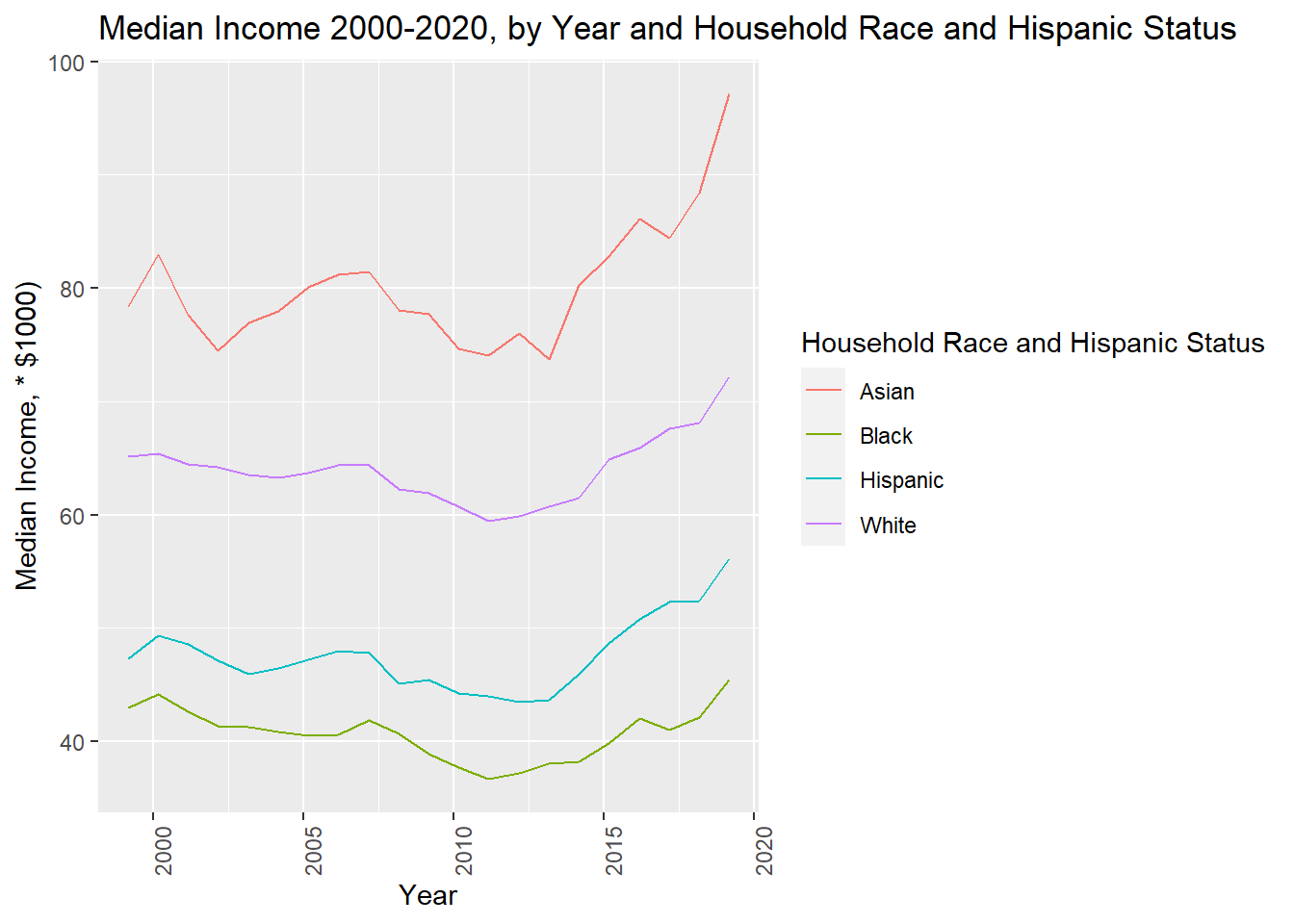
Chunk 5: Visualizing Part-Whole Relationships
I’ll try a couple of things to look at differences income by household race and Hispanic status
- A stacked bar char showing percent income by race and Hispanic status over time
- A pie chart based on mean income over all years, 2000 forward
#try a stacked bar
usa_hh_tidy_pct_med_income_2020 <-
usa_hh_tidy_med_income_2020 %>%
group_by(measure_date)%>%
mutate(perc= med_income/sum(med_income))
ggplot(usa_hh_tidy_pct_med_income_2020, aes(fill=clean_origin, y=perc, x=measure_date)) +
geom_bar(position="stack", stat="identity")+
ggtitle("Distribution of Income by Year and Household Race and Hispanic Status")+
scale_y_continuous(name= "Percent Income",
label = scales::percent) 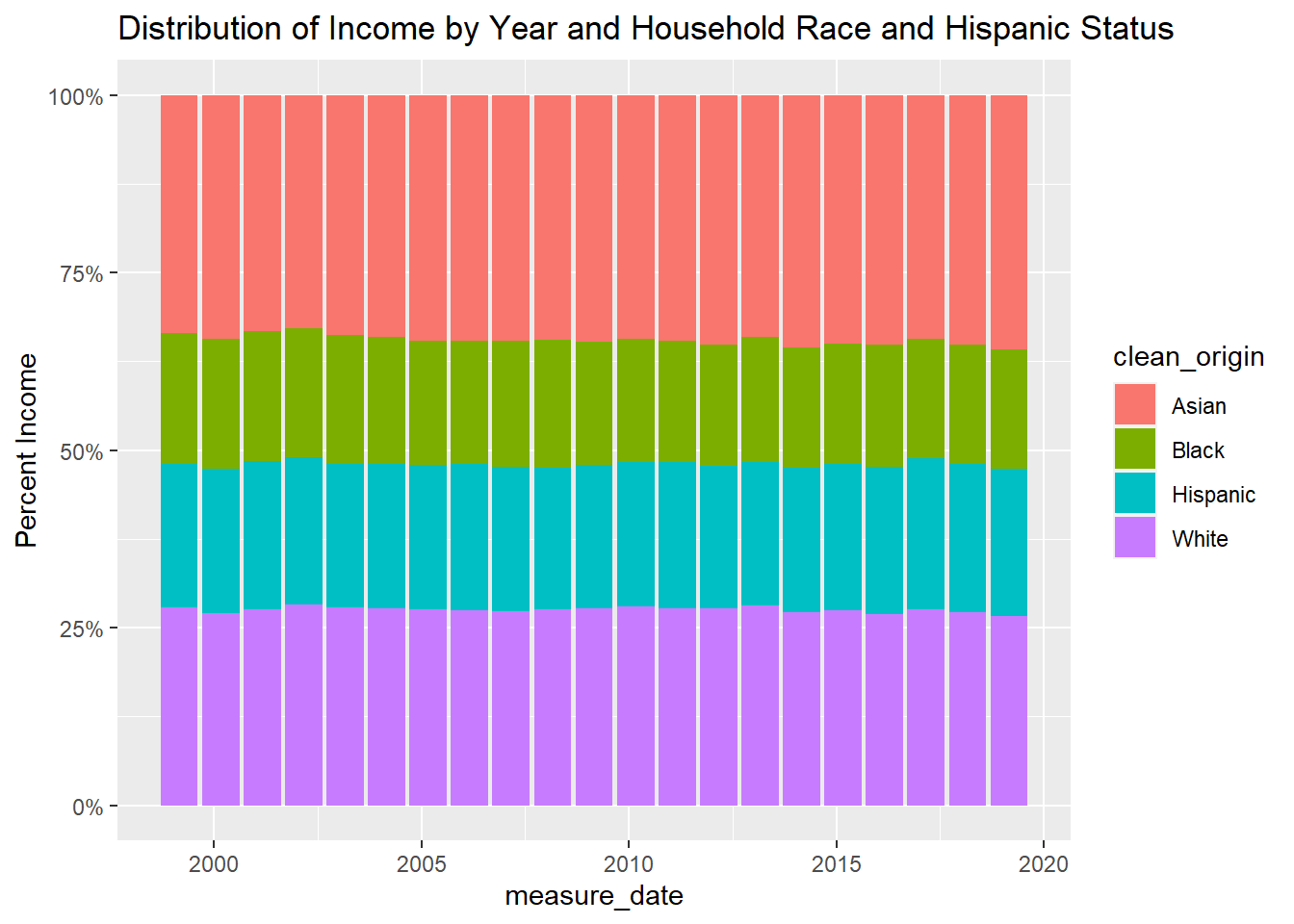
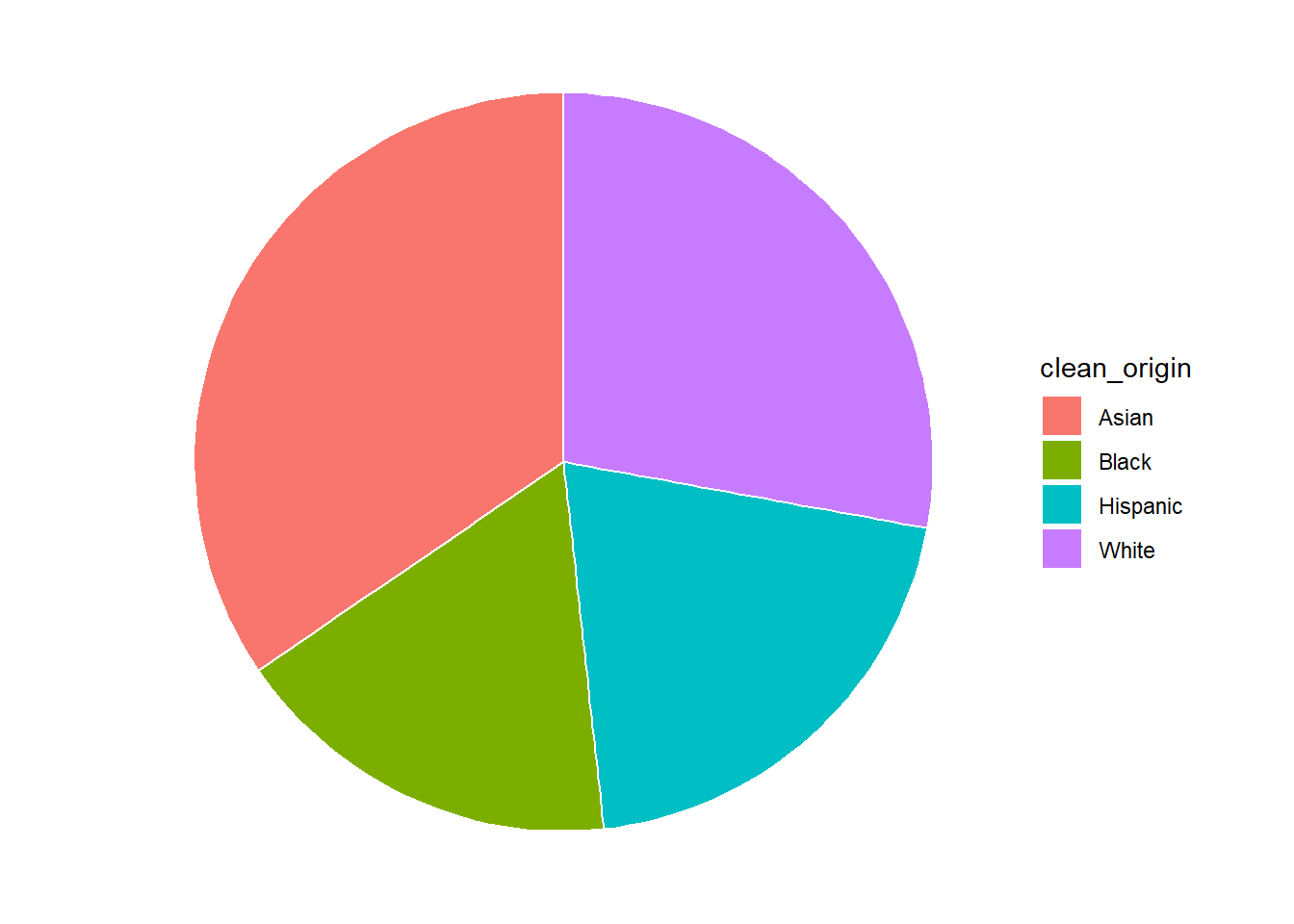
# try a basic pie chart
usa_hh_tidy_overall<-
usa_hh_tidy_g %>%
filter(measure_date > '1999-01-01' & !clean_origin=="Other")
usa_hh_tidy_overall_g<-
usa_hh_tidy_overall %>%
group_by(clean_origin)%>%
summarise(med_income = min(med_incomeK)) %>%
arrange(clean_origin )
ggplot(usa_hh_tidy_overall_g, aes(x="", y=med_income, fill=clean_origin)) +
geom_bar(stat="identity", width=1, color="white") +
coord_polar("y", start=0) +
theme_void()