Code
library(tidyverse)
library(here)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)library(tidyverse)
library(here)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)First I loaded the “FAOSTAT_cattle_dairy.csv dataset. This dataset was already largely tidy, but I finished the process by removing variables that were redundant or only had one case, leaving each column with its own variable and each row as an occurrence.
cattle_dairy <- here("posts","_data","FAOSTAT_cattle_dairy.csv")%>%
read_csv()
cattle_dairy# A tibble: 36,449 × 14
Domain Cod…¹ Domain Area …² Area Eleme…³ Element Item …⁴ Item Year …⁵ Year
<chr> <chr> <dbl> <chr> <dbl> <chr> <dbl> <chr> <dbl> <dbl>
1 QL Lives… 2 Afgh… 5318 Milk A… 882 Milk… 1961 1961
2 QL Lives… 2 Afgh… 5420 Yield 882 Milk… 1961 1961
3 QL Lives… 2 Afgh… 5510 Produc… 882 Milk… 1961 1961
4 QL Lives… 2 Afgh… 5318 Milk A… 882 Milk… 1962 1962
5 QL Lives… 2 Afgh… 5420 Yield 882 Milk… 1962 1962
6 QL Lives… 2 Afgh… 5510 Produc… 882 Milk… 1962 1962
7 QL Lives… 2 Afgh… 5318 Milk A… 882 Milk… 1963 1963
8 QL Lives… 2 Afgh… 5420 Yield 882 Milk… 1963 1963
9 QL Lives… 2 Afgh… 5510 Produc… 882 Milk… 1963 1963
10 QL Lives… 2 Afgh… 5318 Milk A… 882 Milk… 1964 1964
# … with 36,439 more rows, 4 more variables: Unit <chr>, Value <dbl>,
# Flag <chr>, `Flag Description` <chr>, and abbreviated variable names
# ¹`Domain Code`, ²`Area Code`, ³`Element Code`, ⁴`Item Code`, ⁵`Year Code`cattle_dairy_new <- cattle_dairy %>%
select(-c('Domain', 'Domain Code', 'Area Code', 'Element', 'Element Code', 'Item Code', 'Year Code', 'Unit', 'Flag'))
cattle_dairy_new# A tibble: 36,449 × 5
Area Item Year Value `Flag Description`
<chr> <chr> <dbl> <dbl> <chr>
1 Afghanistan Milk, whole fresh cow 1961 700000 FAO estimate
2 Afghanistan Milk, whole fresh cow 1961 5000 Calculated data
3 Afghanistan Milk, whole fresh cow 1961 350000 FAO estimate
4 Afghanistan Milk, whole fresh cow 1962 700000 FAO estimate
5 Afghanistan Milk, whole fresh cow 1962 5000 Calculated data
6 Afghanistan Milk, whole fresh cow 1962 350000 FAO estimate
7 Afghanistan Milk, whole fresh cow 1963 780000 FAO estimate
8 Afghanistan Milk, whole fresh cow 1963 5128 Calculated data
9 Afghanistan Milk, whole fresh cow 1963 400000 FAO estimate
10 Afghanistan Milk, whole fresh cow 1964 780000 FAO estimate
# … with 36,439 more rowsThis dataset consists of five variables with the following types: Area: string Item: string Year: double Value: double Flag Description: string
The overall dataset represents values for whole fresh cow milk in different countries across different years, as well as whether the data was estiamted/calculated.
One potential research question could investigate the difference in values with respect to the area. For example: Which area produced the most whole fresh cow milk? What country produced the least whole fresh cow milk? What was the distribution of average whole fresh cow milk production for each area?
Another research question could investigate the change in milk production with respect to year. For example: Did the production of whole fresh cow milk increase from 1961 to 2018? During which year was the most cow milk produced and during which year was the least produced?
A third research question could investigate the relationship between the method of estimating/calculating values and the values themselves. For example: Is there a difference between the average of values described as “Calculated data” and “FAO estimates”.
Lastly, this dataset could be used to investigate relationships between multiple variables, such as year and area. For example: Did some areas see an increase in production from 1961 to 2018 while others saw a decrease? Was the magnitude of change in production different across areas?
I calculated statistics for the numerical variable, value, including mean, median, and standard deviation. I also calculated frequencies of the categorical variables, including Area, and Flag Description. Lastly, I grouped the values by Area and calculated the same statistics.
cattle_dairy_new %>%
summarize(`Mean of Milk Value` = mean(`Value`,na.rm=TRUE),
`Median Milk Value` = median(`Value`, na.rm=TRUE),
`Standard Deviation of Milk Value` = sd(`Value`, na.rm = TRUE))# A tibble: 1 × 3
`Mean of Milk Value` `Median Milk Value` `Standard Deviation of Milk Value`
<dbl> <dbl> <dbl>
1 4410235. 43266 25744621.table(cattle_dairy_new$Area)
Afghanistan
174
Africa
174
Albania
174
Algeria
174
American Samoa
174
Americas
174
Angola
174
Antigua and Barbuda
174
Argentina
174
Armenia
81
Asia
174
Australia
174
Australia and New Zealand
174
Austria
174
Azerbaijan
81
Bahamas
174
Bahrain
174
Bangladesh
174
Barbados
174
Belarus
81
Belgium
57
Belgium-Luxembourg
117
Belize
174
Benin
174
Bermuda
174
Bhutan
174
Bolivia (Plurinational State of)
174
Bosnia and Herzegovina
81
Botswana
174
Brazil
174
British Virgin Islands
52
Brunei Darussalam
76
Bulgaria
174
Burkina Faso
174
Burundi
174
Cabo Verde
174
Cambodia
174
Cameroon
174
Canada
174
Caribbean
174
Central African Republic
174
Central America
174
Central Asia
81
Chad
174
Chile
150
China, Hong Kong SAR
174
China, mainland
174
China, Taiwan Province of
174
Colombia
174
Comoros
174
Congo
174
Costa Rica
174
Côte d'Ivoire
174
Croatia
81
Cuba
174
Cyprus
174
Czechia
78
Czechoslovakia
96
Democratic People's Republic of Korea
174
Democratic Republic of the Congo
174
Denmark
174
Djibouti
174
Dominica
174
Dominican Republic
174
Eastern Africa
174
Eastern Asia
174
Eastern Europe
174
Ecuador
174
Egypt
174
El Salvador
174
Eritrea
78
Estonia
81
Eswatini
174
Ethiopia
78
Ethiopia PDR
96
Europe
174
Falkland Islands (Malvinas)
174
Fiji
174
Finland
174
France
174
French Guyana
174
French Polynesia
174
Gabon
174
Gambia
174
Georgia
81
Germany
174
Ghana
174
Greece
174
Grenada
174
Guadeloupe
174
Guatemala
174
Guinea
174
Guinea-Bissau
174
Guyana
174
Haiti
174
Honduras
174
Hungary
174
Iceland
174
India
174
Indonesia
174
Iran (Islamic Republic of)
174
Iraq
174
Ireland
174
Israel
174
Italy
174
Jamaica
174
Japan
174
Jordan
174
Kazakhstan
81
Kenya
174
Kuwait
174
Kyrgyzstan
81
Lao People's Democratic Republic
174
Latvia
81
Lebanon
174
Lesotho
174
Liberia
174
Libya
174
Liechtenstein
174
Lithuania
81
Luxembourg
57
Madagascar
174
Malawi
174
Malaysia
174
Mali
174
Malta
174
Martinique
174
Mauritania
174
Mauritius
174
Melanesia
174
Mexico
174
Middle Africa
174
Mongolia
174
Montenegro
39
Montserrat
174
Morocco
174
Mozambique
174
Myanmar
174
Namibia
174
Nepal
174
Netherlands
174
Netherlands Antilles (former)
174
New Caledonia
174
New Zealand
174
Nicaragua
174
Niger
174
Nigeria
174
Niue
174
North Macedonia
81
Northern Africa
174
Northern America
174
Northern Europe
174
Norway
174
Oceania
174
Oman
174
Pakistan
174
Palestine
81
Panama
174
Papua New Guinea
174
Paraguay
174
Peru
174
Philippines
174
Poland
174
Polynesia
174
Portugal
174
Puerto Rico
174
Qatar
174
Republic of Korea
174
Republic of Moldova
81
Réunion
174
Romania
174
Russian Federation
81
Rwanda
174
Saint Lucia
174
Saint Vincent and the Grenadines
174
Samoa
174
Sao Tome and Principe
174
Saudi Arabia
174
Senegal
174
Serbia
39
Serbia and Montenegro
42
Seychelles
174
Sierra Leone
174
Slovakia
78
Slovenia
81
Solomon Islands
174
Somalia
174
South Africa
174
South America
174
South Sudan
21
South-eastern Asia
174
Southern Africa
174
Southern Asia
174
Southern Europe
174
Spain
174
Sri Lanka
174
Sudan
21
Sudan (former)
153
Suriname
174
Sweden
174
Switzerland
174
Syrian Arab Republic
174
Tajikistan
81
Thailand
174
Togo
174
Tonga
174
Trinidad and Tobago
174
Tunisia
174
Turkey
174
Turkmenistan
81
Uganda
174
Ukraine
81
United Arab Emirates
174
United Kingdom of Great Britain and Northern Ireland
174
United Republic of Tanzania
174
United States of America
174
United States Virgin Islands
174
Uruguay
174
USSR
93
Uzbekistan
81
Vanuatu
174
Venezuela (Bolivarian Republic of)
174
Viet Nam
174
Wallis and Futuna Islands
174
Western Africa
174
Western Asia
174
Western Europe
174
World
174
Yemen
174
Yugoslav SFR
93
Zambia
174
Zimbabwe
174 table(cattle_dairy_new$`Flag Description`)
Aggregate, may include official, semi-official, estimated or calculated data
3070
Calculated data
13136
Data not available
74
FAO data based on imputation methodology
2270
FAO estimate
7045
Official data
10044
Unofficial figure
810 area_average <- cattle_dairy_new %>%
group_by(Area) %>%
summarize(`Mean of Value by Area` = mean(`Value`,na.rm=TRUE),
`Median Value by Area` = median(`Value`, na.rm=TRUE),
`Standard Deviation of Value by Area` = sd(`Value`, na.rm = TRUE))
area_average# A tibble: 232 × 4
Area `Mean of Value by Area` `Median Value by Area` Standard…¹
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 903662. 600000 1001961.
2 Africa 18861019. 15058869 19310283.
3 Albania 275446. 198000 290691.
4 Algeria 599219. 440000 742649.
5 American Samoa 3611. 31.5 5349.
6 Americas 56060267. 45081600. 55005137.
7 Angola 164004. 157000 135649.
8 Antigua and Barbuda 6402. 6200 2652.
9 Argentina 3279105. 2400000 3381678.
10 Armenia 276119. 277840 217086.
# … with 222 more rows, and abbreviated variable name
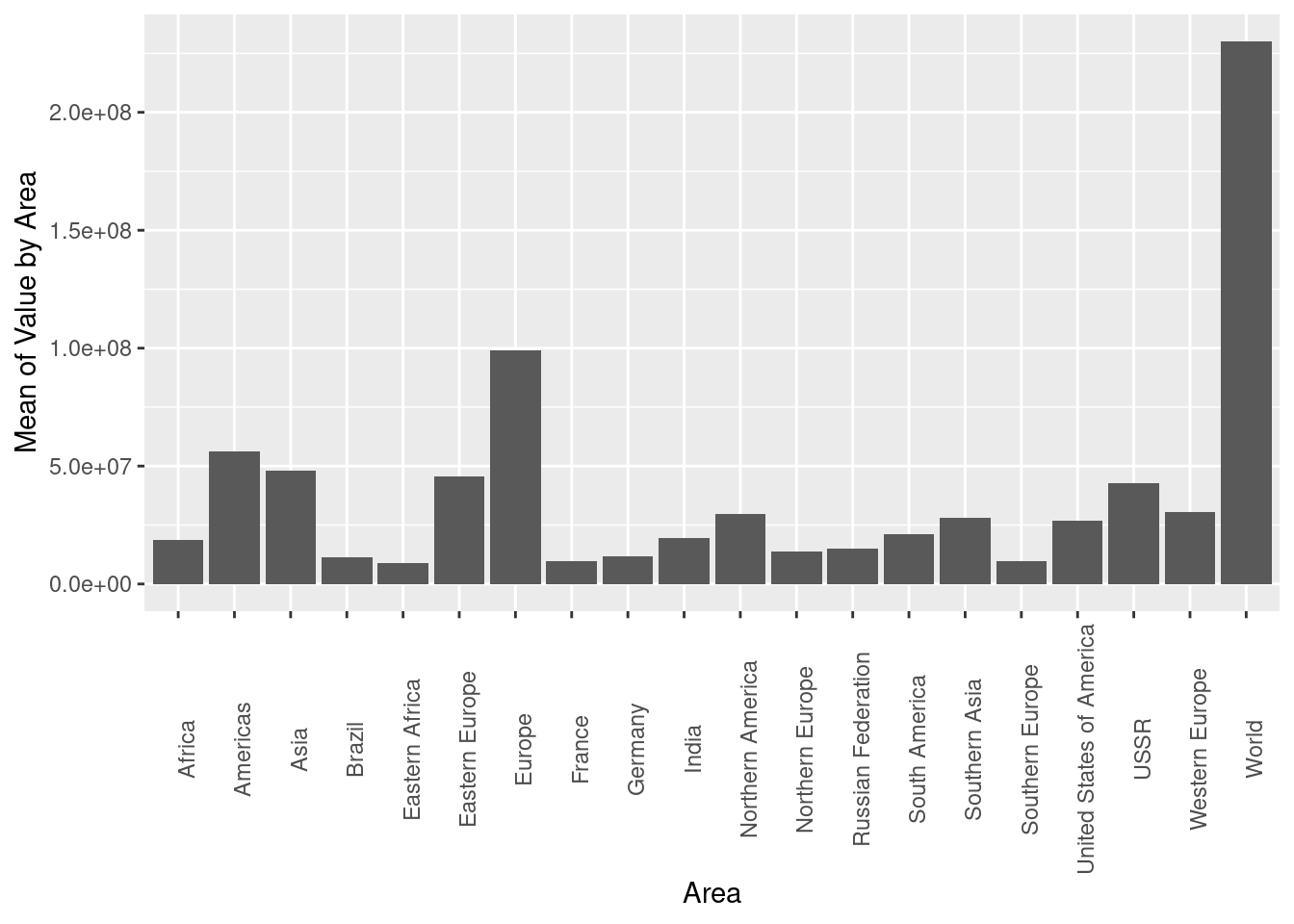
# ¹`Standard Deviation of Value by Area`In this section, I plotted a bar chart of the top 20 average values by Area in order to compare the magnitudes of these values. The limitation of this plot is that the consolidated values, such as the World and continent totals are plotted alongside the individual countries, which makes it difficult to compare the average values of the top individual countries. For a more refined ananlysis, I could remove consolidated values so individual countries are the only ones remaining.
area_average <- area_average[order(-area_average$`Mean of Value by Area`),]
area_average_top20 <- area_average[1:20,]
area_average_top20 %>%
ggplot(aes(x=Area,y=`Mean of Value by Area`)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 90))