Code
library(tidyverse)
library(ggplot2)
library(viridis)
library(dplyr)
library(plotly)
library(hrbrthemes)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(ggplot2)
library(viridis)
library(dplyr)
library(plotly)
library(hrbrthemes)
knitr::opts_chunk$set(echo = TRUE)data_r = read_csv("_data/WDI/Indicators.csv")Rows: 5656458 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): CountryName, CountryCode, IndicatorName, IndicatorCode
dbl (2): Year, Value
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.data_r# A tibble: 5,656,458 × 6
CountryName CountryCode IndicatorName Indic…¹ Year Value
<chr> <chr> <chr> <chr> <dbl> <dbl>
1 Arab World ARB Adolescent fertility rate (bir… SP.ADO… 1960 1.34e+2
2 Arab World ARB Age dependency ratio (% of wor… SP.POP… 1960 8.78e+1
3 Arab World ARB Age dependency ratio, old (% o… SP.POP… 1960 6.63e+0
4 Arab World ARB Age dependency ratio, young (%… SP.POP… 1960 8.10e+1
5 Arab World ARB Arms exports (SIPRI trend indi… MS.MIL… 1960 3 e+6
6 Arab World ARB Arms imports (SIPRI trend indi… MS.MIL… 1960 5.38e+8
7 Arab World ARB Birth rate, crude (per 1,000 p… SP.DYN… 1960 4.77e+1
8 Arab World ARB CO2 emissions (kt) EN.ATM… 1960 5.96e+4
9 Arab World ARB CO2 emissions (metric tons per… EN.ATM… 1960 6.44e-1
10 Arab World ARB CO2 emissions from gaseous fue… EN.ATM… 1960 5.04e+0
# … with 5,656,448 more rows, and abbreviated variable name ¹IndicatorCodeTo summarize from homework2. For the analysis and produce conclusions to the research questions we have used the World Development Indicators dataset. It describes 247 countries data over a period of 56 years (1960-2015) using 1344 indicators.
HYPOTHESIS: Life expectancy is getting better for the majority of the countries across the globe. Country’s development and growth can be motivating factors for increase in life expectancy.
GOALS: Analysis of the dataset to identify if the hypothesis is supported or not? Identifying major factors and how much impact do they have in the increase of a country’s life expectancy?
summary(data_r) CountryName CountryCode IndicatorName IndicatorCode
Length:5656458 Length:5656458 Length:5656458 Length:5656458
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Year Value
Min. :1960 Min. :-9.825e+15
1st Qu.:1984 1st Qu.: 6.000e+00
Median :1997 Median : 6.400e+01
Mean :1994 Mean : 1.071e+12
3rd Qu.:2006 3rd Qu.: 1.347e+07
Max. :2015 Max. : 1.103e+16 To summerize the data and understand all the columns and its datatypes we have used summary function. This will give us mean, first quartile, and 3rd quartile for the numerical attributes.
continentData = read_csv("_data/WDI/Continents_Countries_v2.csv")Rows: 249 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): CountryCode, Continent
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message. data <- left_join(data_r, continentData, by = 'CountryCode')# Removing Null values
data <- data %>%
filter(!(Continent == "NA"))
data# A tibble: 4,827,592 × 7
CountryName CountryCode IndicatorName Indic…¹ Year Value Conti…²
<chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 Afghanistan AFG Adolescent fertility r… SP.ADO… 1960 1.45e+2 Asia
2 Afghanistan AFG Age dependency ratio (… SP.POP… 1960 8.17e+1 Asia
3 Afghanistan AFG Age dependency ratio, … SP.POP… 1960 5.09e+0 Asia
4 Afghanistan AFG Age dependency ratio, … SP.POP… 1960 7.66e+1 Asia
5 Afghanistan AFG Arms imports (SIPRI tr… MS.MIL… 1960 4 e+7 Asia
6 Afghanistan AFG Birth rate, crude (per… SP.DYN… 1960 5.13e+1 Asia
7 Afghanistan AFG CO2 emissions (kt) EN.ATM… 1960 4.14e+2 Asia
8 Afghanistan AFG CO2 emissions (metric … EN.ATM… 1960 4.61e-2 Asia
9 Afghanistan AFG CO2 emissions from gas… EN.ATM… 1960 0 Asia
10 Afghanistan AFG CO2 emissions from gas… EN.ATM… 1960 0 Asia
# … with 4,827,582 more rows, and abbreviated variable names ¹IndicatorCode,
# ²ContinentGrouping data with continent by extracting new dataset of continents using country code. This will help to group the data based on continents. As there are few NA values in continent droping those rows to have a tidy dataset.
data_LifeExpectancy <- data %>%
filter(IndicatorName == "Life expectancy at birth, total (years)")
data_LifeExpectancy# A tibble: 10,247 × 7
CountryName CountryCode IndicatorName Indic…¹ Year Value Conti…²
<chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 Afghanistan AFG Life expectancy … SP.DYN… 1960 32.3 Asia
2 Albania ALB Life expectancy … SP.DYN… 1960 62.3 Europe
3 Algeria DZA Life expectancy … SP.DYN… 1960 46.1 Africa
4 Angola AGO Life expectancy … SP.DYN… 1960 33.0 Africa
5 Antigua and Barbuda ATG Life expectancy … SP.DYN… 1960 61.8 North …
6 Argentina ARG Life expectancy … SP.DYN… 1960 65.2 South …
7 Armenia ARM Life expectancy … SP.DYN… 1960 65.9 Asia
8 Aruba ABW Life expectancy … SP.DYN… 1960 65.6 North …
9 Australia AUS Life expectancy … SP.DYN… 1960 70.8 Oceania
10 Austria AUT Life expectancy … SP.DYN… 1960 68.6 Europe
# … with 10,237 more rows, and abbreviated variable names ¹IndicatorCode,
# ²ContinentAs we are interested in narrowing down World’s development based on few indicators. We are obtaining small subset of the dataset based on the indicator for all the years across the world. One example subset is of life expectancy dataset. As one of our research questions tries to find the trend of average life expectancy for all the years.
data_group <- data_LifeExpectancy %>%
group_by(CountryName)
data_group# A tibble: 10,247 × 7
# Groups: CountryName [200]
CountryName CountryCode IndicatorName Indic…¹ Year Value Conti…²
<chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 Afghanistan AFG Life expectancy … SP.DYN… 1960 32.3 Asia
2 Albania ALB Life expectancy … SP.DYN… 1960 62.3 Europe
3 Algeria DZA Life expectancy … SP.DYN… 1960 46.1 Africa
4 Angola AGO Life expectancy … SP.DYN… 1960 33.0 Africa
5 Antigua and Barbuda ATG Life expectancy … SP.DYN… 1960 61.8 North …
6 Argentina ARG Life expectancy … SP.DYN… 1960 65.2 South …
7 Armenia ARM Life expectancy … SP.DYN… 1960 65.9 Asia
8 Aruba ABW Life expectancy … SP.DYN… 1960 65.6 North …
9 Australia AUS Life expectancy … SP.DYN… 1960 70.8 Oceania
10 Austria AUT Life expectancy … SP.DYN… 1960 68.6 Europe
# … with 10,237 more rows, and abbreviated variable names ¹IndicatorCode,
# ²ContinentGrouped the data based on country to obtain few statistics
data_group %>%
summarise(Average_LifeExpectancy = mean(Value, nr.rm = TRUE),
Median_LifeExpectancy = median(Value, nr.rm = TRUE))# A tibble: 200 × 3
CountryName Average_LifeExpectancy Median_LifeExpectancy
<chr> <dbl> <dbl>
1 Afghanistan 46.6 46.9
2 Albania 71.1 71.8
3 Algeria 61.8 65.2
4 Angola 41.7 40.9
5 Antigua and Barbuda 69.8 70.3
6 Argentina 70.6 70.9
7 Armenia 70.2 70.3
8 Aruba 71.9 73.2
9 Australia 76.0 76.0
10 Austria 74.6 74.5
# … with 190 more rowsAs grouped by country we have obtained the means and medians of life expectancy over the years. In the statistics some countries have mean life expectancy same as median life expectancy like Armenia, Australia, etc. This explains that there is no sudden spike in the growth of life expectancy over the years.
data_group %>%
ggplot( aes(x=Year, y=Value, group= Continent, color=Continent)) +
geom_line() +
scale_color_viridis(discrete = TRUE) +
ggtitle("Life Expectancy trend over the years grouped by Continents") +
ylab("Life Expectancy")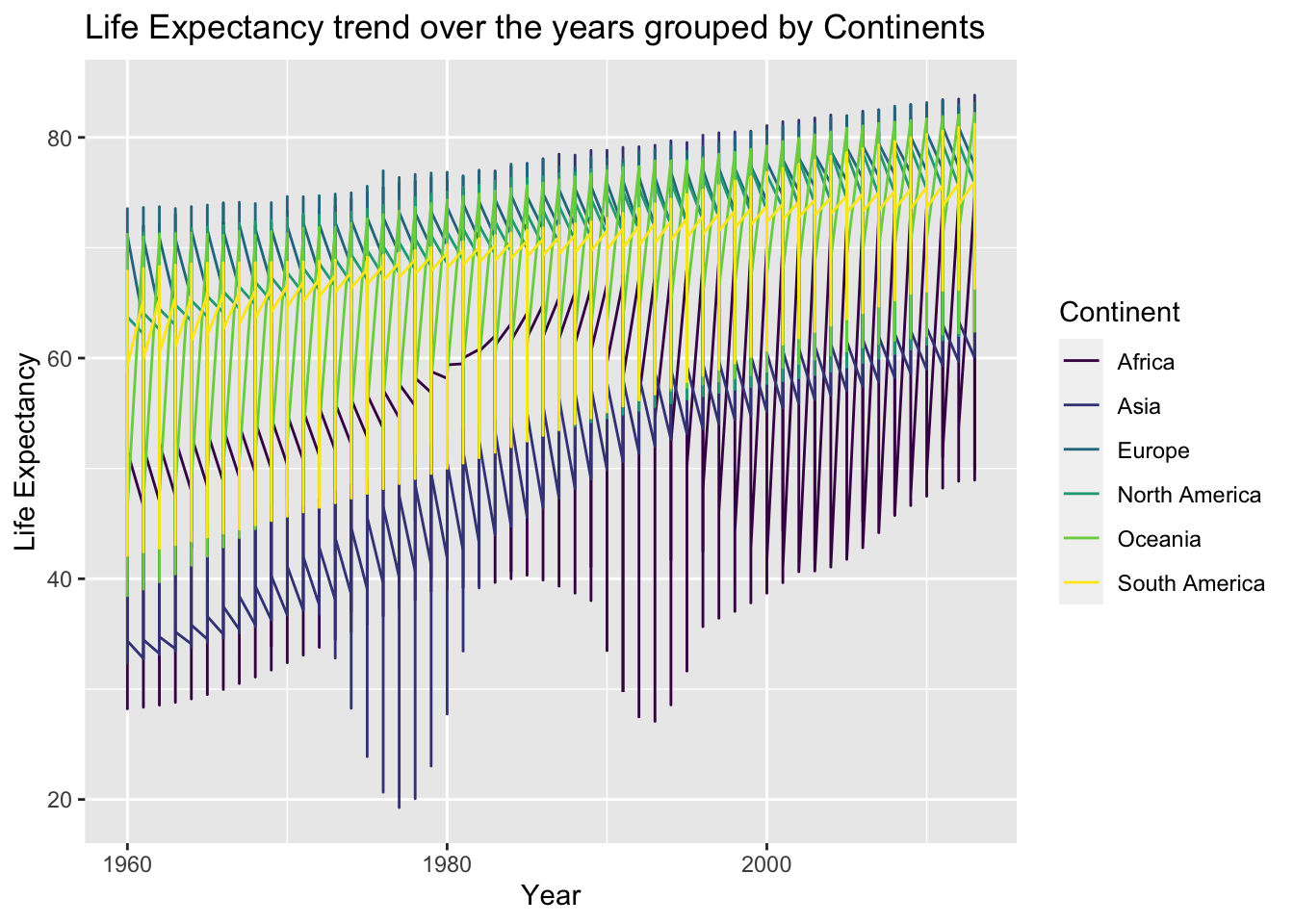
To get an overal trend of the life expectancy line plot played a decent role. As you can see the curve increase over the years. However, here the data is based on continents. For continents the life expectancy has been increasing.
# Libraries
# Interactive version
p <- data_group %>%
# prepare text for tooltip
mutate(text = paste("Country:", CountryName, "LifeExpectancy:", Value, "Year:", Year, "Continent:", Continent, sep=" ")) %>%
# Classic ggplot
ggplot( aes(x=Year, y=Value, size = Value/5, color = Continent, text=text)) +
geom_point(alpha=0.5) +
scale_size(range = c(.1, 1), name="Continents Names")
# turn ggplot interactive with plotly
pp <- ggplotly(p, tooltip="text")
ppTo further understand the trend of the life expectancy based on the continents I have used scatter plot and grouped it based on continents which will give some edge in identifying their country based on the continent. However, due to huge set of countries it can be challenging to exactly spot the country.
This is the visualization of the world map depicting life expectancies of the countries for the period of 60 years. Based on life expectancies, color changes over time.User will be able to understand whether life expectancy is increasing or decreasing for the countries, based on the color saturation.User will also be able to find life expectancies of the countries for a particular year. By hovering on a country , user can view - the year, country code, life expectancy
# Load dataset from github
data_filtered <- data %>%
filter(IndicatorName %in% c("Life expectancy at birth, total (years)", "Adjusted net national income (current US$)", "Population, total", "GDP per capita (constant 2005 US$)", "Gross national expenditure (constant 2005 US$)", "Merchandise exports (current US$)", "Net official development assistance received (current US$)", "Age dependency ratio (% of working-age population)", "Arms exports (SIPRI trend indicator values)")) %>%
filter(CountryName=="China")
# Plot
data_filtered %>%
ggplot( aes(x=Year, y=Value, group=IndicatorName, fill=IndicatorName)) +
geom_area() +
scale_fill_viridis(discrete = TRUE) +
theme(legend.position="none") +
ggtitle("World Development Indicators over the years") +
theme_ipsum() +
theme(
legend.position="none",
panel.spacing = unit(0, "lines"),
strip.text.x = element_text(size = 8),
plot.title = element_text(size=13)
) +
facet_wrap(~IndicatorName, scale="free_y")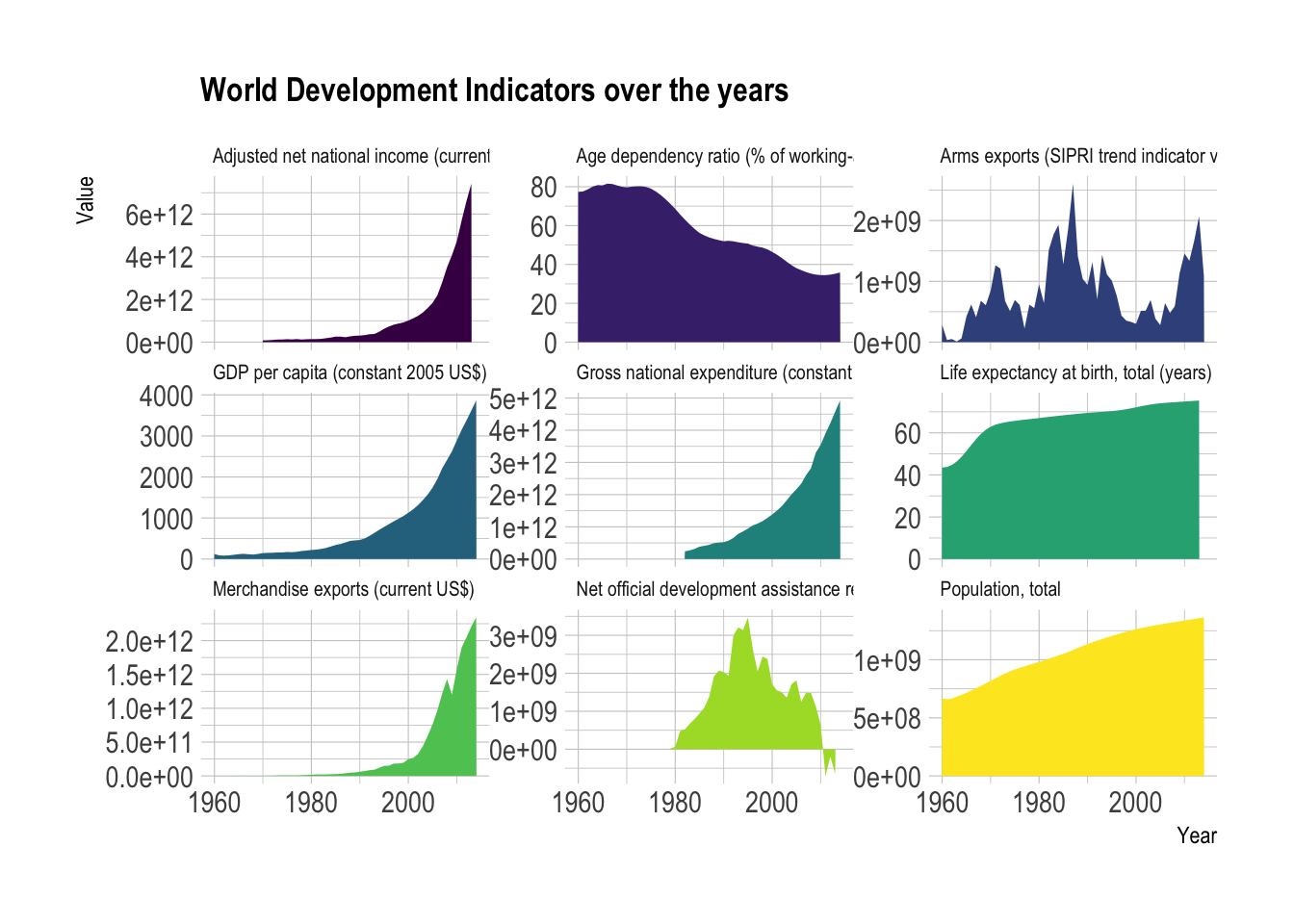
We have already mentioned that , user will be able to understand the correlation between wdi and life expectancy for the countries , so the user will be able to do that with the help of the scatter plot. We have grouped the countries based on their respective continent.
As the data is huge Visualization might not be very clear when trying to infer some information for a particular country. To further narrow down the analysis based on the country we can implement animations. I’ll try to implement those in the project. For now the data looks decent based on the continents.
Also, while trying to find some correlation between different world development indicators to life expectancy it becomes very challenging to visualize the entire data in single graph. Further analysis is required with additional data to obtain separate graphs for the correlation with life expectancy.