Rows: 48895 Columns: 16
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): name, host_name, neighbourhood_group, neighbourhood, room_type
dbl (10): id, host_id, latitude, longitude, price, minimum_nights, number_o...
date (1): last_review
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
head(Listings)
The dataset contains listing information for Airbnb properties in New York. It has 48895 observances (listings) and 16 variables. The variables include the location of the property (coordinates, neighborhood, and borough), room type, price, minimum number of nights, reviews (total reviews and reviews per month), host information (id, name, listing counts per host), and availability.
Tidy Data
In order to tidy the data, I first removed the variables that I consider unnecessary: host_id, host_name, last_review, and reviews per month. I also renamed the variables neighbourhood_group to borough and neighbourhood to neighborhood since these are more commonly used terms in the US. My next step is to determine if there is any missing data from this dataset.
##Determine is there is any missing data
colSums(is.na(Listings))
id name borough neighborhood
0 16 0 0
latitude longitude room_type price
0 0 0 0
minimum_nights number_of_reviews availability_365
0 0 0
There are 16 names missing from the dataset.
##Summary of the dataset
summary(Listings)
id name borough neighborhood
Min. : 2539 Length:48895 Length:48895 Length:48895
1st Qu.: 9471945 Class :character Class :character Class :character
Median :19677284 Mode :character Mode :character Mode :character
Mean :19017143
3rd Qu.:29152178
Max. :36487245
latitude longitude room_type price
Min. :40.50 Min. :-74.24 Length:48895 Min. : 0.0
1st Qu.:40.69 1st Qu.:-73.98 Class :character 1st Qu.: 69.0
Median :40.72 Median :-73.96 Mode :character Median : 106.0
Mean :40.73 Mean :-73.95 Mean : 152.7
3rd Qu.:40.76 3rd Qu.:-73.94 3rd Qu.: 175.0
Max. :40.91 Max. :-73.71 Max. :10000.0
minimum_nights number_of_reviews availability_365
Min. : 1.00 Min. : 0.00 Min. : 0.0
1st Qu.: 1.00 1st Qu.: 1.00 1st Qu.: 0.0
Median : 3.00 Median : 5.00 Median : 45.0
Mean : 7.03 Mean : 23.27 Mean :112.8
3rd Qu.: 5.00 3rd Qu.: 24.00 3rd Qu.:227.0
Max. :1250.00 Max. :629.00 Max. :365.0
After using the function summary(), I can determine that my dataset has extreme values that would make my graphs difficult to see. Therefore, I’ll filter the price between $50 and $500 per night.
##Filtering price per night and compare prices by borough
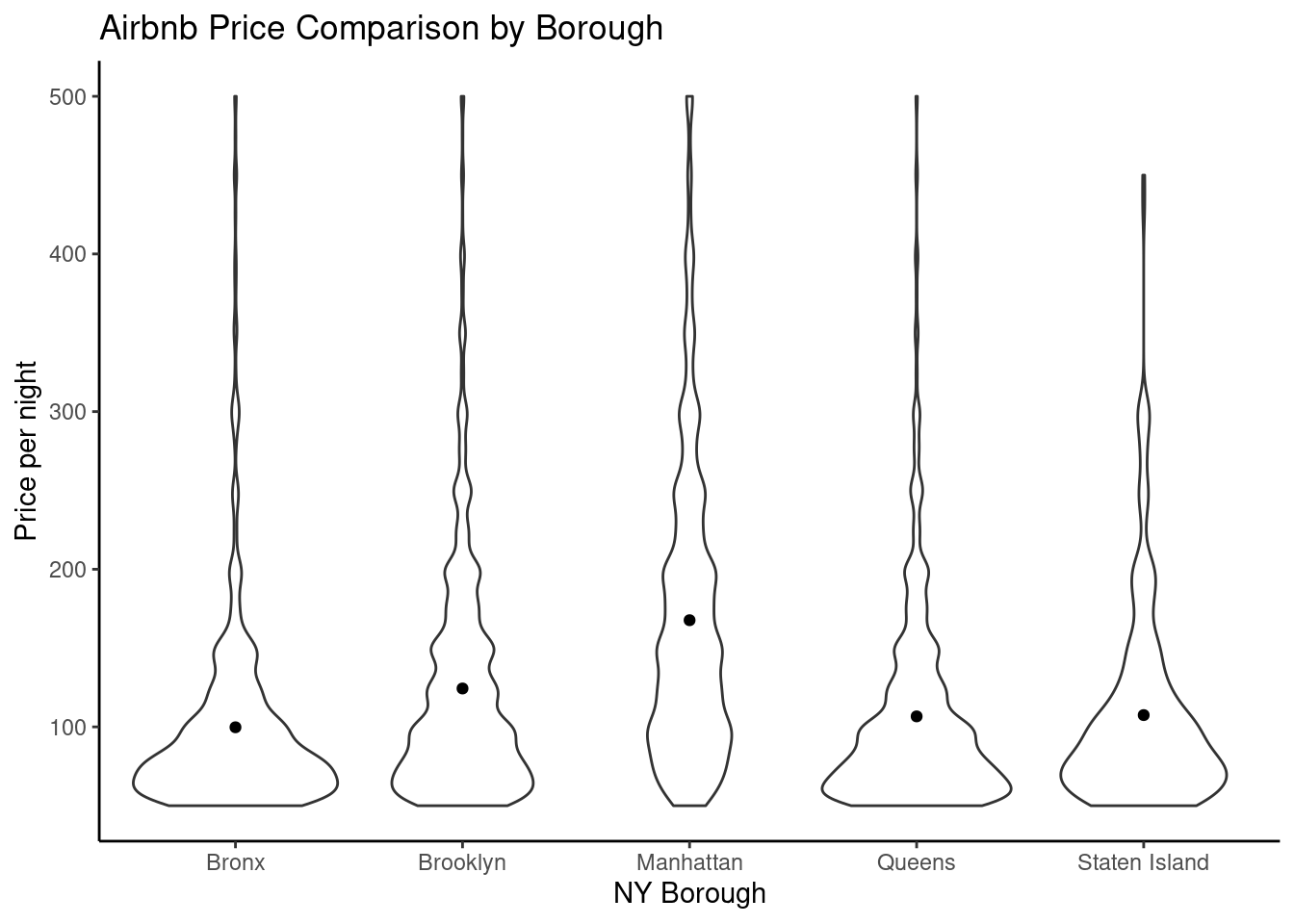
Listings %>%filter(price >=50& price <=500)%>%ggplot(aes(borough, price))+geom_violin()+theme_classic()+stat_summary(fun ="mean", geom ="point", color ="black")+labs(title ="Airbnb Price Comparison by Borough", y ="Price per night", x ="NY Borough")
By creating a violin plot I can determine the distribution of the prices for listings by borough. For this graph, I have set a point to represent the mean. Looking at the graph, I can observe that Manhattan has the highest prices for listings, followed by Brooklyn.
##Create a graph using to compare prices by room type
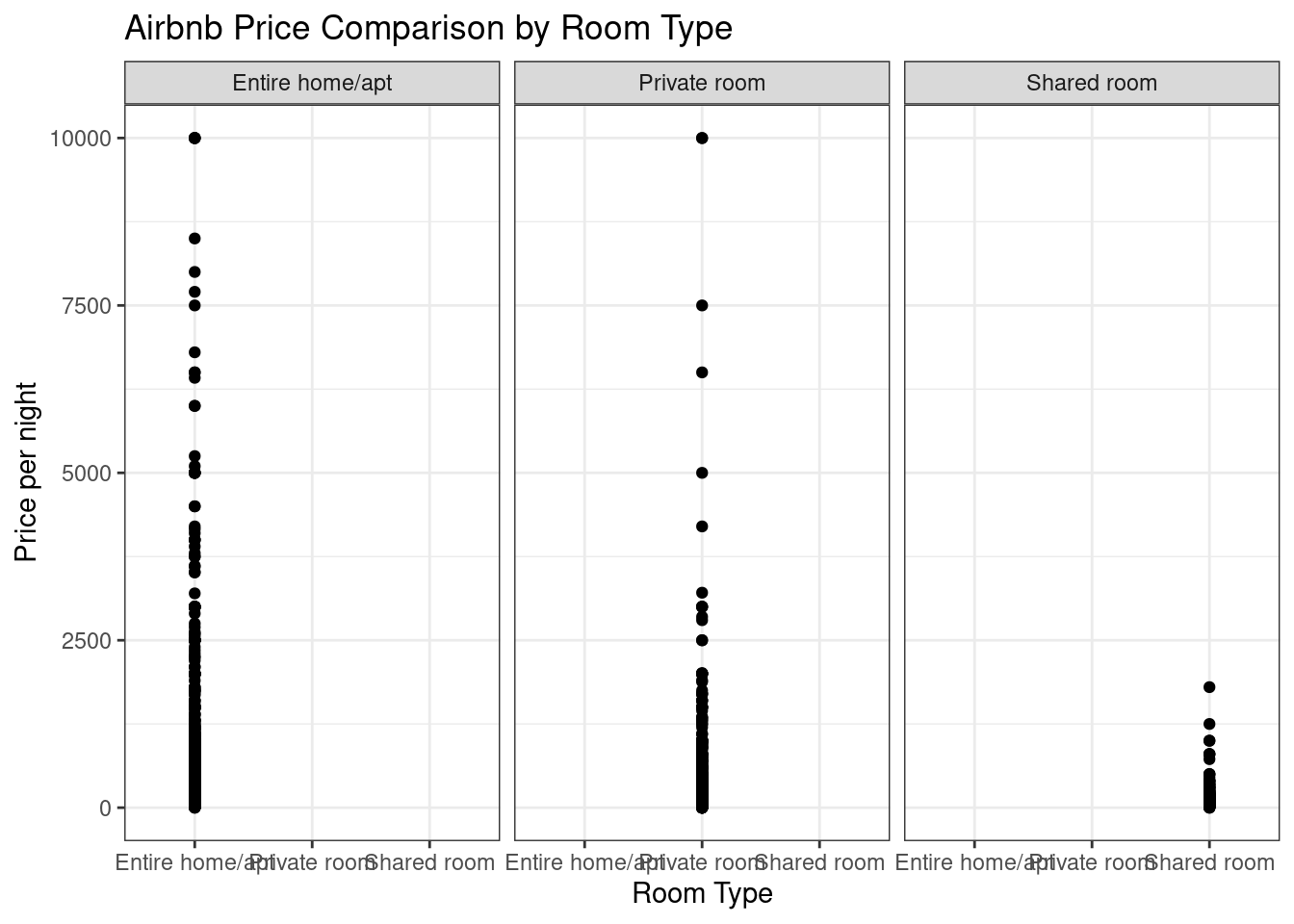
Listings%>%ggplot(aes(room_type, price)) +geom_point()+theme_bw()+labs(title ="Airbnb Price Comparison by Room Type", y ="Price per night", x ="Room Type")+facet_wrap(vars(room_type))
I also wanted to see and compare prices by room type. By using the function facet_wrap(), I was able to divide a geom_point by room type: entire home, private room, and shared room. Although there are some outliers, we can determine that the prices for the entire home are higher than the other type of rooms.
#Make proportional crosstabs for room_type and borough
By creating a proportional crosstabs for room_type and borough, I can determine that Manhattan has the most listings for entire home/apt with 27%, followed by Brooklyn with 19.5%. For private room, Brooklyn has the most listings with 21%. I can also determine from this crosstabs that there are is a small number of shared rooms compared to the other types of rooms and most of the shared rooms are in Manhattan. We can also notice that Staten Island has the least number of listings.