The data set contains 20 types of cereals and the amount of sodium and sugar in the cereals. It also contains another column named Type. This field has two values - A and C under it. After close inspection it looks like A stands for Adults and C for children (based on consumption).
Tidy Data (as needed)
The data is tidy. However, usage of A and C under ‘Type’ column is not very intuitive. Hence I will rename these to adults and children.
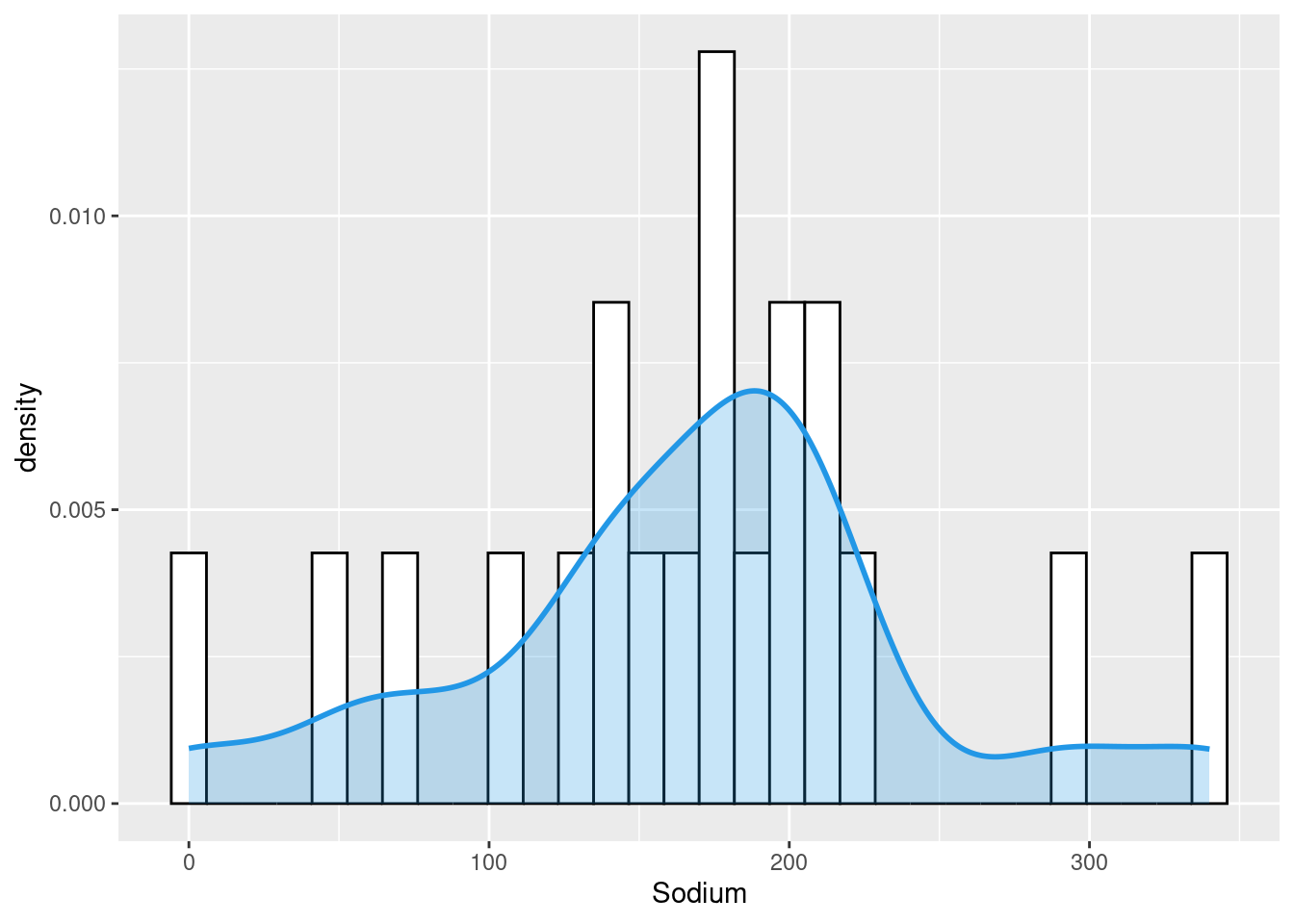
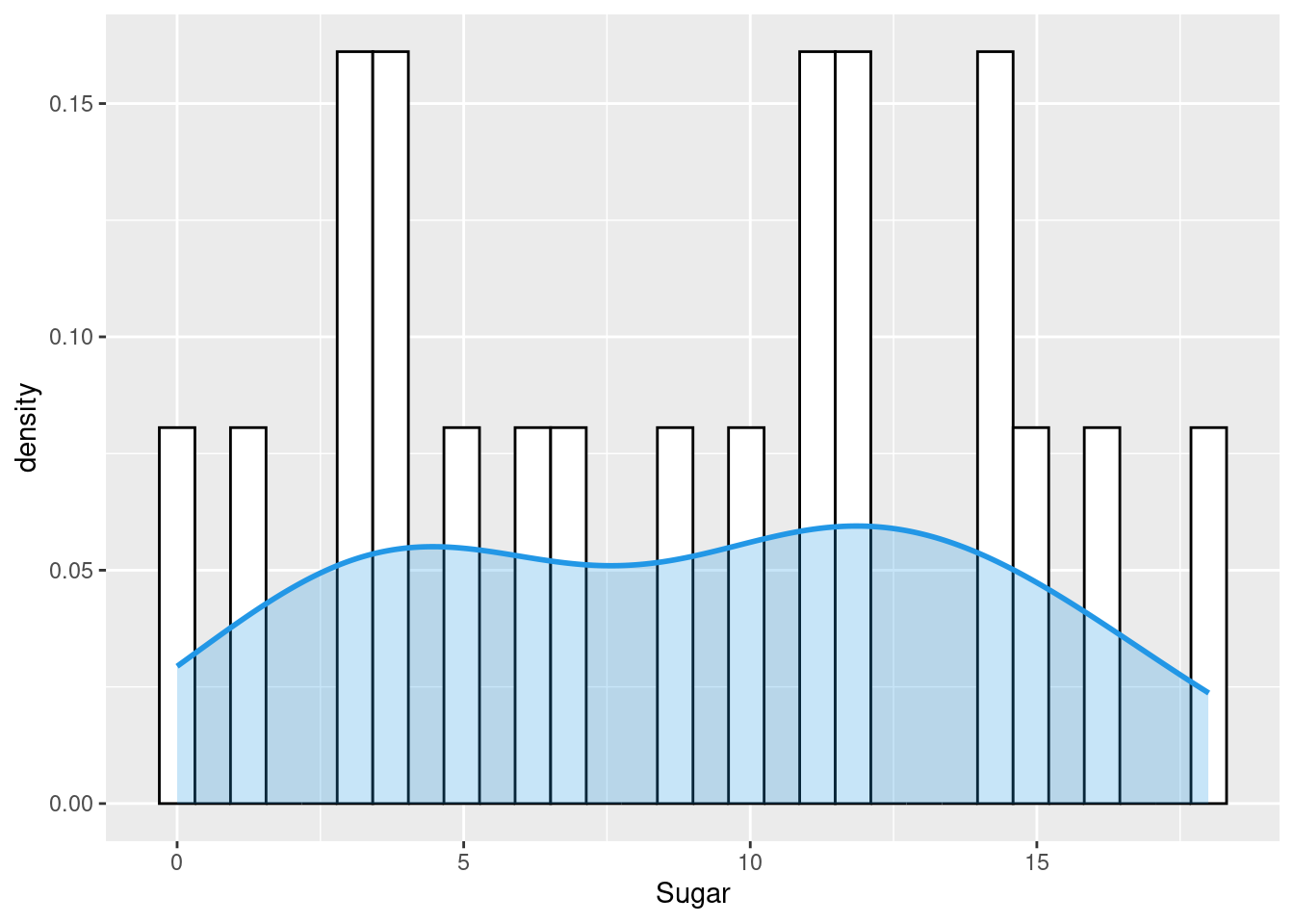
I chose to plot 3 histograms. The first plot shows the sodium count in different types of cereals. The next two graphs display a density plot between Sodium content/ Sugar content with different types of cereals. The below plots however excludes outliers in the data.
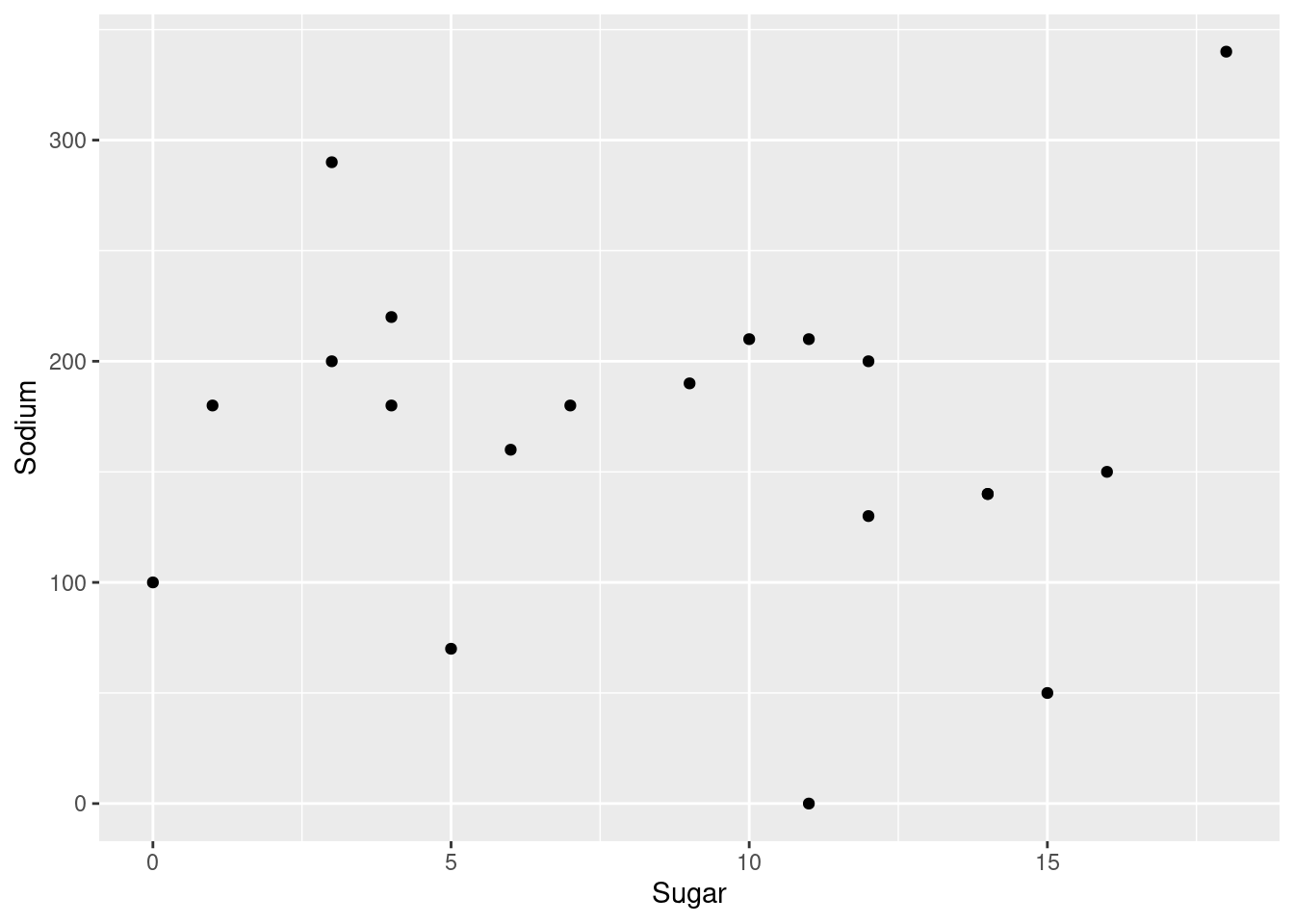
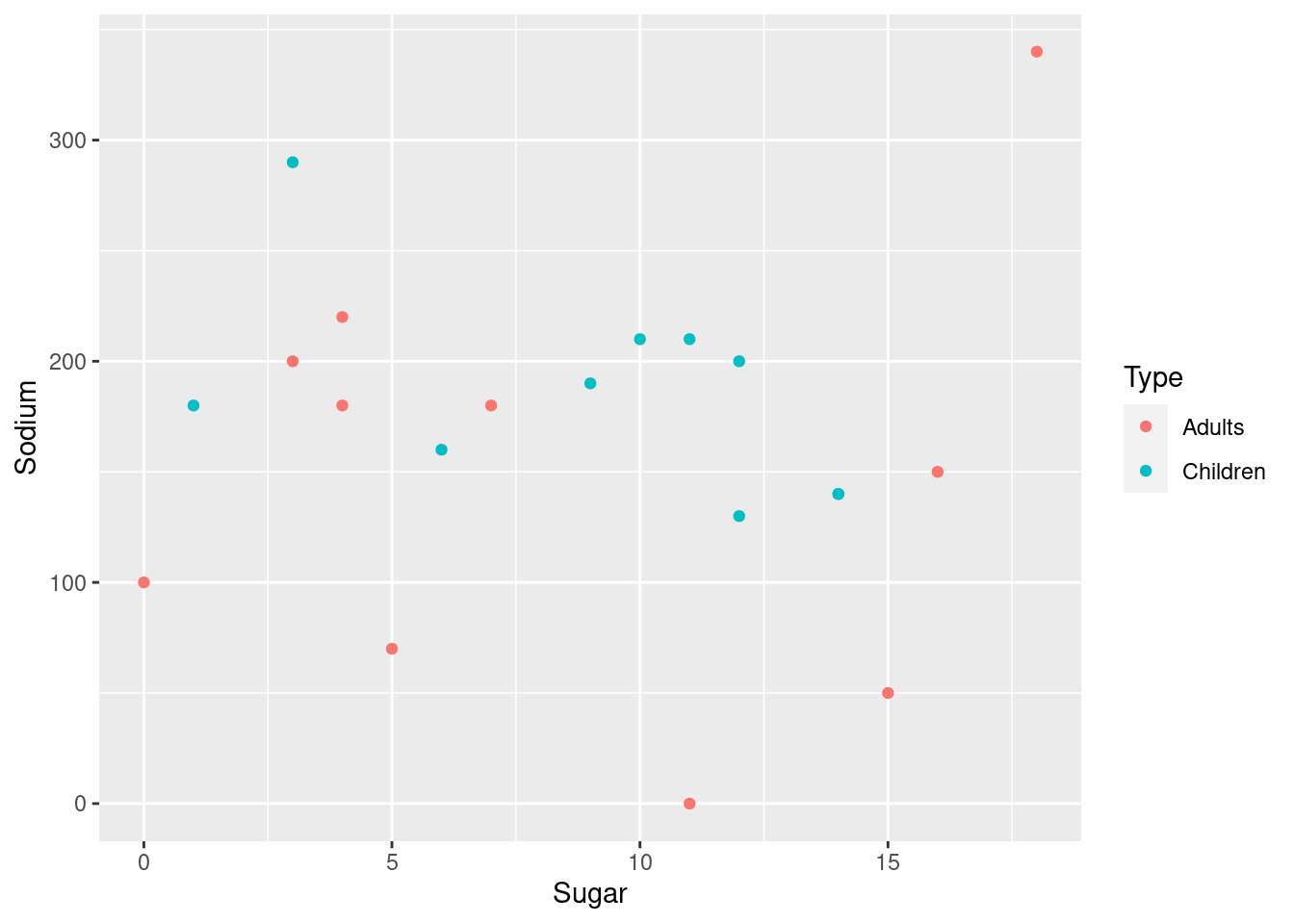
Below are two scatter plots to display the Sodium vs Sugar content of different types of cereals. We see that one cereal (Raisin Bran) has high content of both Sodium and Sugar.
From the above plots we see that there is no apparent/direct relationship between Sugar/Sodium content and the cereals based on type (Adult/Children).
Source Code
--- title: "Challenge 5" author: "Rishita Golla" description: "Introduction to Visualization" date: "1/12/2022" format: html: toc: true code-copy: true code-tools: true df-print: kable categories: - challenge_5 - cereal---```{r}#| label: setup#| warning: false#| message: falselibrary(tidyverse)library(ggplot2) knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```## Read in data```{r} data <-read_csv("_data/cereal.csv")view(data)```### Briefly describe the dataThe data set contains 20 types of cereals and the amount of sodium and sugar in the cereals. It also contains another column named Type. This field has two values - A and C under it. After close inspection it looks like A stands for Adults and C for children (based on consumption).## Tidy Data (as needed)The data is tidy. However, usage of A and C under 'Type' column is not very intuitive. Hence I will rename these to `adults` and `children`.```{r} cereal <-mutate(data, `Type`=recode(`Type`,"A"="Adults","C"="Children" ))```## Univariate VisualizationsI chose to plot 3 histograms. The first plot shows the sodium count in different types of cereals. The next two graphs display a density plot between Sodium content/ Sugar content with different types of cereals. The below plots however excludes outliers in the data.```{r}ggplot(cereal, aes(x=Sodium)) +geom_histogram(binwidth =10)``````{r}ggplot(cereal, aes(Sodium)) +geom_histogram(aes(y = ..density..), colour =1, fill ="white") +geom_density(lwd =1, colour =4,fill =4, alpha =0.25)labs(title ="Sodium Content by Cereal Brand", x ="Sodium")``````{r}ggplot(cereal, aes(Sugar)) +geom_histogram(aes(y = ..density..), colour =1, fill ="white") +geom_density(lwd =1, colour =4,fill =4, alpha =0.25)labs(title ="Sugar Content by Cereal Brand", x ="Sugar")```## Bivariate Visualization(s)Below are two scatter plots to display the Sodium vs Sugar content of different types of cereals. We see that one cereal (Raisin Bran) has high content of both Sodium and Sugar.```{r}ggplot(cereal, aes(x=Sugar, y=Sodium)) +geom_point()``````{r}ggplot(cereal,aes(x=Sugar,y=Sodium,col=Type))+geom_point()```From the above plots we see that there is no apparent/direct relationship between Sugar/Sodium content and the cereals based on type (Adult/Children).