Attaching package: 'psych'
The following objects are masked from 'package:ggplot2':
%+%, alpha
Code
library(readr)library(summarytools)
Warning: no DISPLAY variable so Tk is not available
system might not have X11 capabilities; in case of errors when using dfSummary(), set st_options(use.x11 = FALSE)
Attaching package: 'summarytools'
The following object is masked from 'package:tibble':
view
As we can see from the spec and head command outputs, this is the hotel booking data for 2 hotels over 3 years. We can also see that the dataset has 119390 total rows and 32 columns.
Looking at the data, we can see that there are 119390 rows and 32 columns in the dataset. Moreover, taking a look at the unique values of some columns, we observe that this booking data is collected from 2 hotels, over a period of three years, across various distribution channels. The other columns have values of either character or numerical types and The dataset contains all kinds of booking information regarding the hotels, ranging right from the arrival dates to the type of guests, the booking channel, agent, etc. to the demands of the guests and parking spaces, etc.
Cleaning and mutating the data
By looking at the top values in the dataset, character type columns with values such as NULL can be noticed. Also, 0 valued numerical columns can be seen in the dataset as well. It will be great to find out the percentage of these values in the columns and remove these columns if the percentages are high.
Code
# get zero percentage in datazero_percent <- (colSums(bookings ==0) /nrow(bookings)) *100# get null percent in datanull_percent <-sapply(bookings, function(x) sum(str_detect(x, "NULL")) /length(x))aggregated_df <-data.frame(null_percent = null_percent, zero_percent = zero_percent)arrange(aggregated_df, desc(null_percent), desc(zero_percent))
As we can see from the stats above, it is safe to remove columns company and babies due to the high percentage of insignificant "NULL" and 0 values. But before that, I will add the values in adults, children and babies columns to get the total number of guests and also calculate the total_stay_period for guests by adding stays_in_weekend_nights and stays_in_week_nights columns.
The method dfSummary provides us with the complete summary of the dataset, including the mean and median values, the range and the most important/frequent values of the columns.
From the above analysis, we can see that the City hotel is a bit expensive as compared to the Resort hotel and charges 10usd more per night. We also observe that City hotel had more successful bookings as compared to the Resourt hotel.
In terms of countries, Portugal is the most frequent source of origin for the customers as well as the most frequent source of cancellation as well.
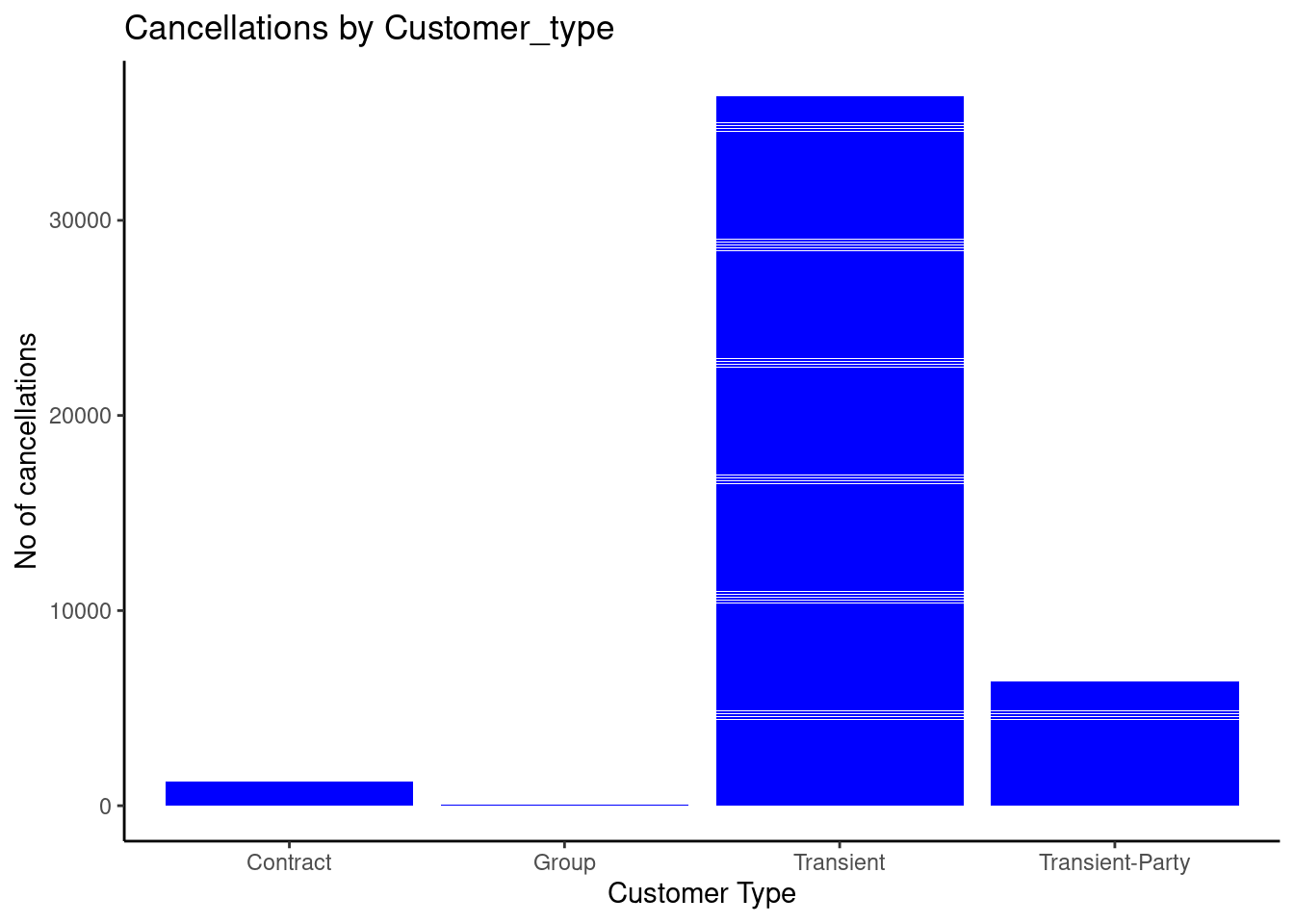
Let us deep dive more into cancellations and see which types of customers are likely to cancel more.
Code
ggplot(bookings, aes(x = customer_type, y = is_canceled))+geom_col(fill ="Blue")+theme_classic() +labs(title ="Cancellations by Customer_type",x ="Customer Type",y ="No of cancellations" )
We can observe from the graph above that the transient customers are more likely to cancel and the groups being the least.
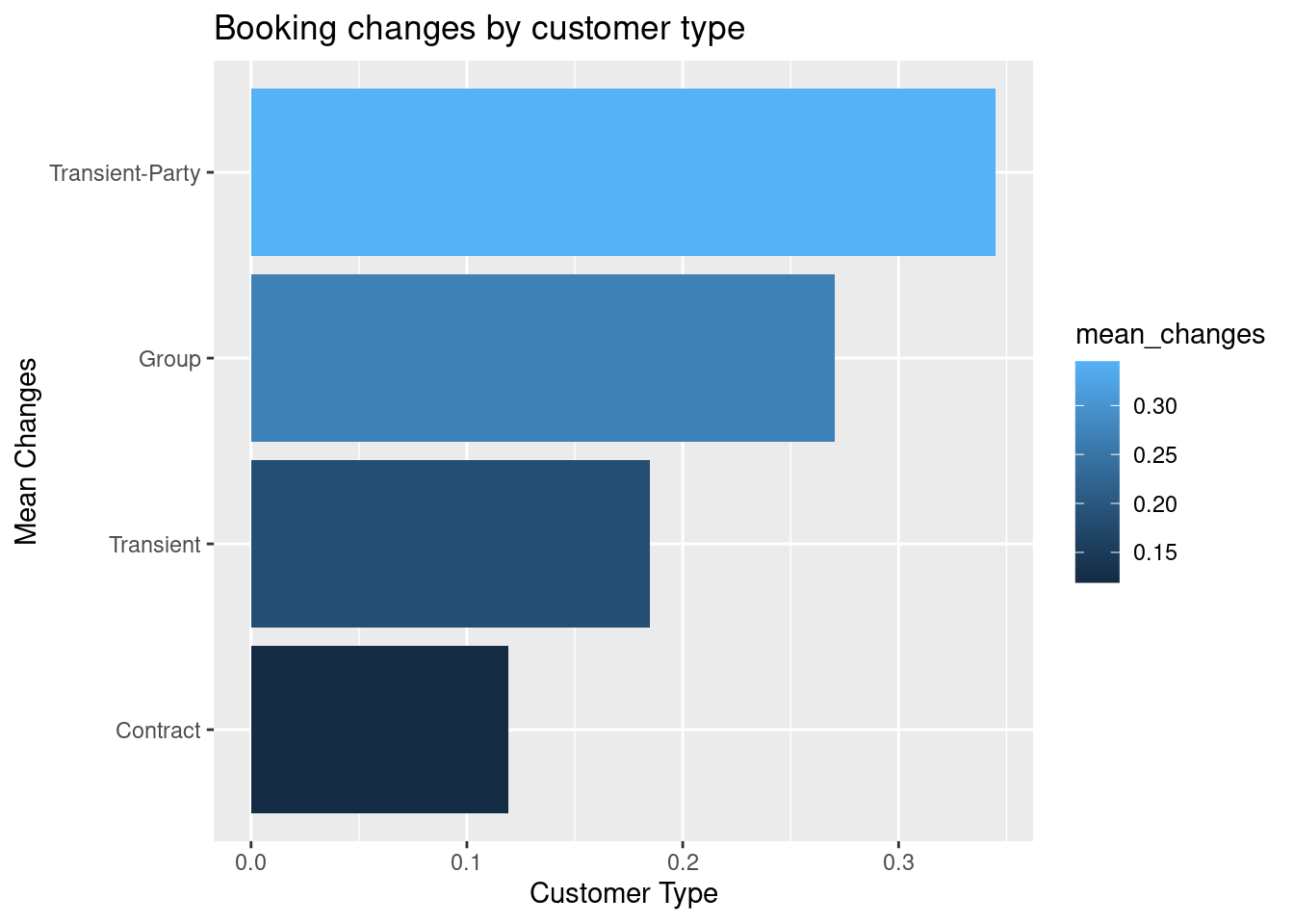
We can again see that the transient-party and group customers make the most changes to their bookings
Code
ggplot(data = bookings.changes_by_customer, mapping =aes(x = mean_changes, y =reorder(customer_type, mean_changes))) +geom_col(mapping =aes(fill = mean_changes)) +labs(x ="Customer Type", y ="Mean Changes", title ="Booking changes by customer type")
We can observe from the graph that the most number of changes are done by people from Transient Parties and Groups whereas the least changes are done by groups.
Source Code
---title: "Homework 3"author: "Siddharth Goel"date: "01/31/2023"format: html: toc: true code-fold: true code-copy: true code-tools: true df-print: pagedcategories: - hw3 - hotel_bookings---## Importing the libraries```{r}library(tidyverse)library(ggplot2)library(dplyr)library(psych)library(readr)library(summarytools)knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```## Reading the dataset```{r}bookings <- readr::read_csv("_data/hotel_bookings.csv")```## Taking an initial look into the data```{r}# looking at the dimensionsdim(bookings)# looking at the schemaspec(bookings)# looking at the data valueshead(bookings)```As we can see from the spec and head command outputs, this is the hotel booking data for 2 hotels over 3 years.We can also see that the dataset has `119390` total rows and `32` columns.## A bit detailed description about the datafinding the unique values for each column```{r}nrow(bookings)unique(bookings$hotel)unique(bookings$arrival_date_year)#unique(bookings$agent)#unique(bookings$company)unique(bookings$customer_type)```Looking at the data, we can see that there are 119390 rows and 32 columns in the dataset. Moreover, taking a look at the unique values of some columns, we observe that this booking data is collected from 2 hotels, over a period of three years, across various distribution channels. The other columns have values of either character or numerical types and The dataset contains all kinds of booking information regarding the hotels, ranging right from the arrival dates to the type of guests, the booking channel, agent, etc. to the demands of the guests and parking spaces, etc.## Cleaning and mutating the dataBy looking at the top values in the dataset, character type columns with values such as `NULL` can be noticed. Also, `0` valued numerical columns can be seen in the dataset as well. It will be great to find out the percentage of these values in the columns and remove these columns if the percentages are high. ```{r}# get zero percentage in datazero_percent <- (colSums(bookings ==0) /nrow(bookings)) *100# get null percent in datanull_percent <-sapply(bookings, function(x) sum(str_detect(x, "NULL")) /length(x))aggregated_df <-data.frame(null_percent = null_percent, zero_percent = zero_percent)arrange(aggregated_df, desc(null_percent), desc(zero_percent))```As we can see from the stats above, it is safe to remove columns `company` and `babies` due to the high percentage of insignificant `"NULL"` and `0` values. But before that, I will add the values in `adults`, `children` and `babies` columns to get the total number of guestsand also calculate the total_stay_period for guests by adding `stays_in_weekend_nights` and `stays_in_week_nights` columns.```{r}bookings <- bookings %>%mutate(total_guests = adults + babies + children,total_stay_period = stays_in_weekend_nights + stays_in_week_nights)bookings <- bookings %>%select(-company, -babies, -adults, -children, -stays_in_weekend_nights, -stays_in_week_nights)```## Getting the summary of the datasetThe method dfSummary provides us with the complete summary of the dataset, including the mean and median values, the range and the most important/frequent values of the columns.```{r}print(dfSummary( bookings, plain.ascii =FALSE, style ="grid", graph.magnif =0.75, valid.col =FALSE),method='render', table.classes='table-condensed' )```## Deep dive into the dataWe get a superficial idea about the data using the summary statistics, but we need to deep dive into it to know more.```{r}head(bookings)```As the column adr represents `Average Daily Rate`, it cannot have -ve values, so I will drop them. ```{r}bookings <- bookings %>%filter(adr >0)```Finding the mean adr for both the hotels```{r}bookings %>%group_by(hotel) %>%summarise(mean_adr =mean(adr))```Now, we will look at the top 5 countries by the number of bookings```{r}bookings.top_countries <- bookings %>%group_by(country) %>% count %>%arrange(desc(n))bookings.top_countries <-head(5)```Let us see which country has the highest cancellation percentage```{r}bookings.cancellation <- bookings %>%filter(country %in%c("PRT", "GBR", "ESP", "FRA", "DEU")) %>%select(country, is_canceled) %>%group_by(country) %>%summarise_if(is.numeric, mean, na.rm =TRUE) %>%arrange(desc(is_canceled))bookings.cancellation```We can see that the maximum number of bookings are cancelled by customers from Portugal.Let us see the number of successful bookings. i.e., the guests successfully checked out of the hotel.```{r}bookings.success <- bookings %>%filter(reservation_status =="Check-Out") ```Let us find the hotels with most successful bookings```{r}bookings.success %>%group_by(hotel) %>%summarise(total_guests =sum(total_guests)) %>%arrange(desc(total_guests)) %>%head(n=10)```Now, let us find the countries with most successful bookings```{r}bookings.success %>%group_by(country) %>%summarise(total_guests =sum(total_guests)) %>%arrange(desc(total_guests)) %>%head(n=10)```From the above analysis, we can see that the City hotel is a bit expensive as compared to the Resort hotel and charges 10usd more per night. We also observe that City hotel had more successful bookings as compared to the Resourt hotel.In terms of countries, Portugal is the most frequent source of origin for the customers as well as the most frequent source of cancellation as well.Let us deep dive more into cancellations and see which types of customers are likely to cancel more.```{r}ggplot(bookings, aes(x = customer_type, y = is_canceled))+geom_col(fill ="Blue")+theme_classic() +labs(title ="Cancellations by Customer_type",x ="Customer Type",y ="No of cancellations" ) ```We can observe from the graph above that the transient customers are more likely to cancel and the groups being the least. ```{r}bookings.changes_by_customer <- bookings %>%group_by(customer_type) %>%summarise(mean_changes =mean(booking_changes)) %>%arrange(desc(mean_changes)) %>%head(10)bookings.changes_by_customer```We can again see that the transient-party and group customers make the most changes to their bookings```{r}ggplot(data = bookings.changes_by_customer, mapping =aes(x = mean_changes, y =reorder(customer_type, mean_changes))) +geom_col(mapping =aes(fill = mean_changes)) +labs(x ="Customer Type", y ="Mean Changes", title ="Booking changes by customer type")```We can observe from the graph that the most number of changes are done by people from Transient Parties and Groups whereas the least changes are done by groups.