Code
library(tidyverse)
library(readr)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(readr)
knitr::opts_chunk$set(echo = TRUE)For this challenge I am using SNL dataset for my analysis. There are three data files: actors.csv, casts.csv and season.csv. actors file contains gender information regarding different types(“cast”, “guest”, “crew”, “unknown”) of actors, casts file contains information regarding which seasons the actor appeared in and how many episodes, and finally the seasons file has information about, what year the season of SNL happened and total number of episodes that season has.
actors <- read_csv("_data/snl_actors.csv", show_col_types = FALSE)
casts <- read_csv("_data/snl_casts.csv", show_col_types = FALSE)
seasons <- read_csv("_data/snl_seasons.csv", show_col_types = FALSE)actors# A tibble: 2,306 × 4
aid url type gender
<chr> <chr> <chr> <chr>
1 Kate McKinnon /Cast/?KaMc cast female
2 Alex Moffat /Cast/?AlMo cast male
3 Ego Nwodim /Cast/?EgNw cast unknown
4 Chris Redd /Cast/?ChRe cast male
5 Kenan Thompson /Cast/?KeTh cast male
6 Carey Mulligan /Guests/?3677 guest andy
7 Marcus Mumford /Guests/?3679 guest male
8 Aidy Bryant /Cast/?AiBr cast female
9 Steve Higgins /Crew/?StHi crew male
10 Mikey Day /Cast/?MiDa cast male
# … with 2,296 more rowscasts# A tibble: 614 × 8
aid sid featured first_epid last_epid update…¹ n_epi…² seaso…³
<chr> <dbl> <lgl> <dbl> <dbl> <lgl> <dbl> <dbl>
1 A. Whitney Brown 11 TRUE 19860222 NA FALSE 8 0.444
2 A. Whitney Brown 12 TRUE NA NA FALSE 20 1
3 A. Whitney Brown 13 TRUE NA NA FALSE 13 1
4 A. Whitney Brown 14 TRUE NA NA FALSE 20 1
5 A. Whitney Brown 15 TRUE NA NA FALSE 20 1
6 A. Whitney Brown 16 TRUE NA NA FALSE 20 1
7 Alan Zweibel 5 TRUE 19800409 NA FALSE 5 0.25
8 Sasheer Zamata 39 TRUE 20140118 NA FALSE 11 0.524
9 Sasheer Zamata 40 TRUE NA NA FALSE 21 1
10 Sasheer Zamata 41 FALSE NA NA FALSE 21 1
# … with 604 more rows, and abbreviated variable names ¹update_anchor,
# ²n_episodes, ³season_fractionseasons# A tibble: 46 × 5
sid year first_epid last_epid n_episodes
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1 1975 19751011 19760731 24
2 2 1976 19760918 19770521 22
3 3 1977 19770924 19780520 20
4 4 1978 19781007 19790526 20
5 5 1979 19791013 19800524 20
6 6 1980 19801115 19810411 13
7 7 1981 19811003 19820522 20
8 8 1982 19820925 19830514 20
9 9 1983 19831008 19840512 19
10 10 1984 19841006 19850413 17
# … with 36 more rowsLooking at the data, gender is one aspect we can see how the casts makeup changed with time. Since this is a known disparity in most of the industries including entertainment industry, this would be a good question to answer. For the analysis, instead of just comparing number of cast for each gender type in each season, to keep it fair I calculated the total number of episodes each gender appeared in each season. This metric seems better representation of how much each gender appeared on SNL
casts_gender_episodes_count <- casts %>%
left_join(filter(actors,type=="cast"),
by="aid") %>%
count(sid,gender, n_episodes) %>%
mutate(total_episodes = n_episodes*n) %>%
select(sid, gender, total_episodes) %>%
group_by(sid, gender) %>%
summarise(total = sum(total_episodes))%>%
ungroup() %>%
left_join(seasons)%>%
filter(!is.na(gender))%>%
select(sid, gender, year, total)`summarise()` has grouped output by 'sid'. You can override using the `.groups`
argument.
Joining with `by = join_by(sid)`casts_gender_episodes_count# A tibble: 95 × 4
sid gender year total
<dbl> <chr> <dbl> <dbl>
1 1 female 1975 72
2 1 male 1975 101
3 2 female 1976 66
4 2 male 1976 84
5 3 female 1977 60
6 3 male 1977 120
7 4 female 1978 60
8 4 male 1978 120
9 5 female 1979 60
10 5 male 1979 172
# … with 85 more rowsI have used “left_join” to join the casts and actors data since we are focusing our analysis on gender makeup of “casts”. After that, I counted the number of episodes each gender appeared in, using count function. I used “group_by” to sum over all the episodes all the actors of each gender appeared in. Finally, I have used “left_join” again to get year information of each season, which will help label the x-axis in visualization.
casts_gender_prop <- casts_gender_episodes_count %>%
group_by(sid) %>%
mutate(prop=total/sum(total)) %>%
ungroup() %>%
select(-total) %>%
pivot_wider(names_from = gender,
values_from = prop)%>%
mutate_at(-1, ~replace_na(., 0))%>%
pivot_longer(c(female,male,unknown),
values_to = "prop",
names_to = "gender")
casts_gender_prop# A tibble: 138 × 4
sid year gender prop
<dbl> <dbl> <chr> <dbl>
1 1 1975 female 0.416
2 1 1975 male 0.584
3 1 1975 unknown 0
4 2 1976 female 0.44
5 2 1976 male 0.56
6 2 1976 unknown 0
7 3 1977 female 0.333
8 3 1977 male 0.667
9 3 1977 unknown 0
10 4 1978 female 0.333
# … with 128 more rowsIn the next series of operations,I used “group_by” and “mutate” to compute the proportion of gender per season. Some seasons only have “male” and “female” as the unique genders, while others have “male”, “female”, “other”, and “NA”. To include all genders for each season, I used “pivot_wider”, “mutate_at” to ensure each level of gender is available for each season. In the last step, I have used pivot_longer() to get the data back in a format that will be helpful for visualization.
ggplot(casts_gender_prop,aes(year,prop,col=gender)) + theme(plot.title = element_text(hjust = 0.5)) +
geom_line(linewidth=1)+
labs(title = "Saturday Night Live - Gender Progression Analysis", x = "Year", y = "Proportion")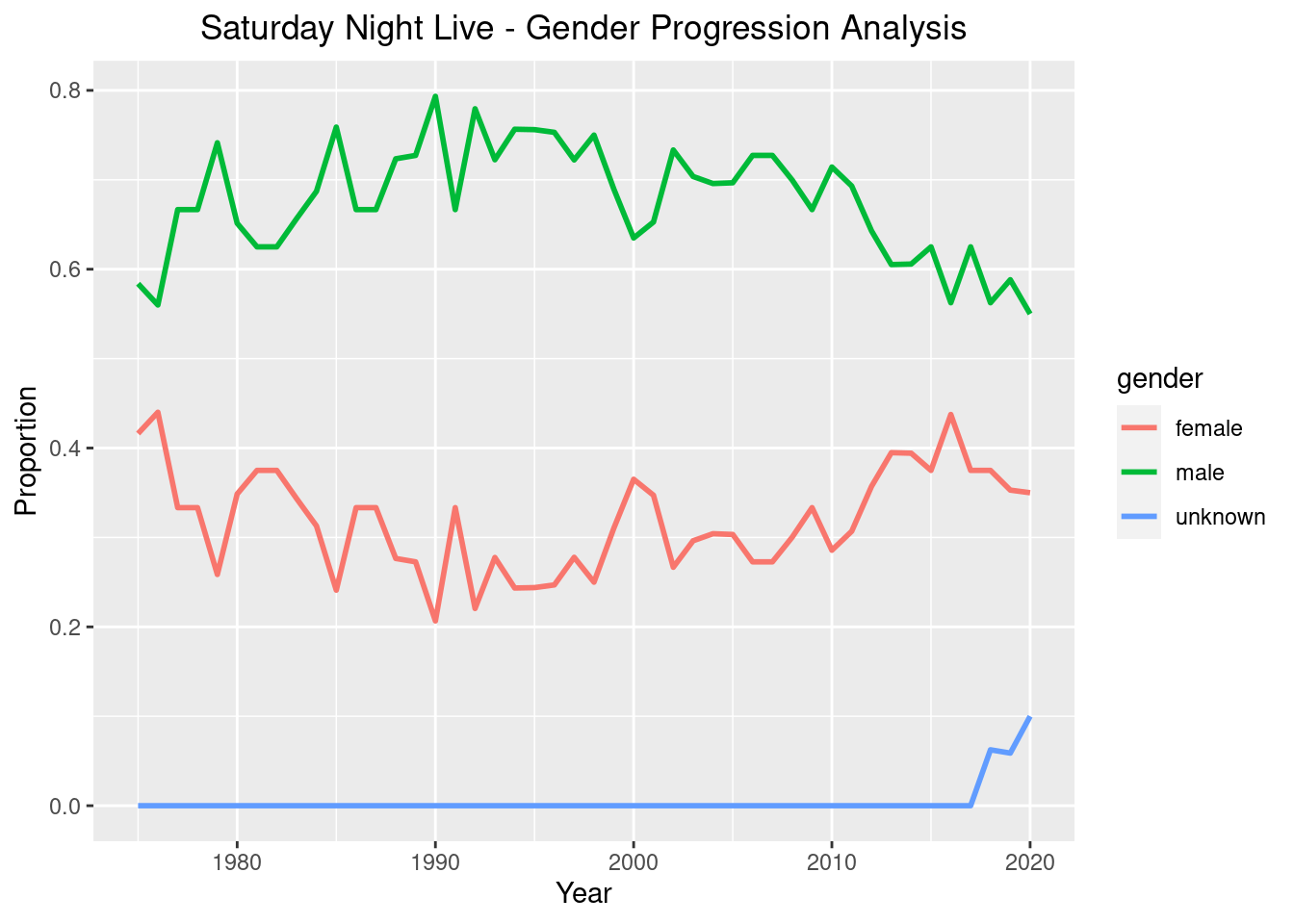
The gender makeup fluctuated a lot over the years slowly moving towards 0.5(equality) but far from it, still in 2020. With just the cast gender makeup and number of episodes they appeared in, the analysis I have presented is a simple one. A complex analysis will take into account how much time each gender spent in each episode doing multiple segments for example. Probably male gender could have done more segments compared to female gender and then the difference between the red and green lines will be even more than in the graph I have plotted above.
In terms of learning, this challenge helped me lot to learn join functions and what variables to consider in order to answer my research question