library(tidyverse)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 5
challenge_5
cereal
Introduction to Visualization
Read in data
Read in one (or more) of the following datasets, using the correct R package and command.
- cereal ⭐
- pathogen cost ⭐
- Australian Marriage ⭐⭐
- AB_NYC_2019.csv ⭐⭐⭐
- railroads ⭐⭐⭐
- Public School Characteristics ⭐⭐⭐⭐
- USA Households ⭐⭐⭐⭐⭐
set.seed(42)
# read in the data using readr
cereal <- read_csv("_data/cereal.csv")
head(cereal, 5)| Cereal | Sodium | Sugar | Type |
|---|---|---|---|
| Frosted Mini Wheats | 0 | 11 | A |
| Raisin Bran | 340 | 18 | A |
| All Bran | 70 | 5 | A |
| Apple Jacks | 140 | 14 | C |
| Captain Crunch | 200 | 12 | C |
Briefly describe the data
This data set contains four columns:
Cereal <chr>: The name of the cerealSodium <dbl>: The amount of sodium in a serving of the cerealSugar <dbl>: The amount of sugar in a serving of cerealType <chr>: The type of the cereal (Child or Adult)
Tidy Data (as needed)
Data is already tidy. Going to mutate Type for visualization reasons.
cereal <- mutate(cereal, `Type` = recode(`Type`,
"A" = "Adult",
"C" = "Child"
))
head(cereal, 5)| Cereal | Sodium | Sugar | Type |
|---|---|---|---|
| Frosted Mini Wheats | 0 | 11 | Adult |
| Raisin Bran | 340 | 18 | Adult |
| All Bran | 70 | 5 | Adult |
| Apple Jacks | 140 | 14 | Child |
| Captain Crunch | 200 | 12 | Child |
Univariate Visualizations
ggplot(cereal, aes(`Sodium`)) +
geom_histogram(binwidth = 100) +
facet_grid(vars(`Type`)) +
labs(title = "Distribution of Sodium based on Type")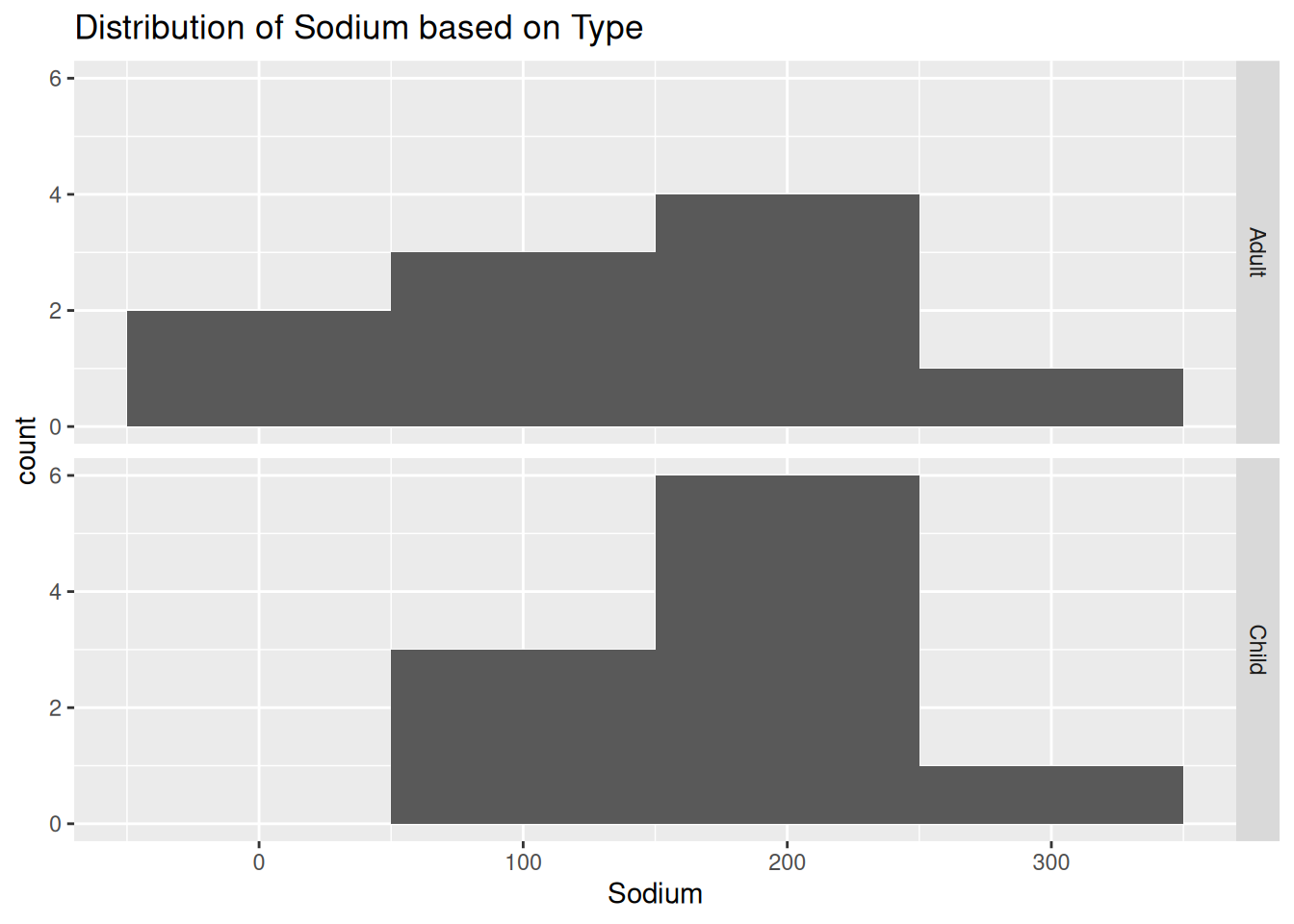
ggplot(cereal, aes(`Sugar`)) +
geom_histogram(binwidth = 5) +
facet_grid(vars(`Type`)) +
labs(title = "Distribution of Sugar based on Type")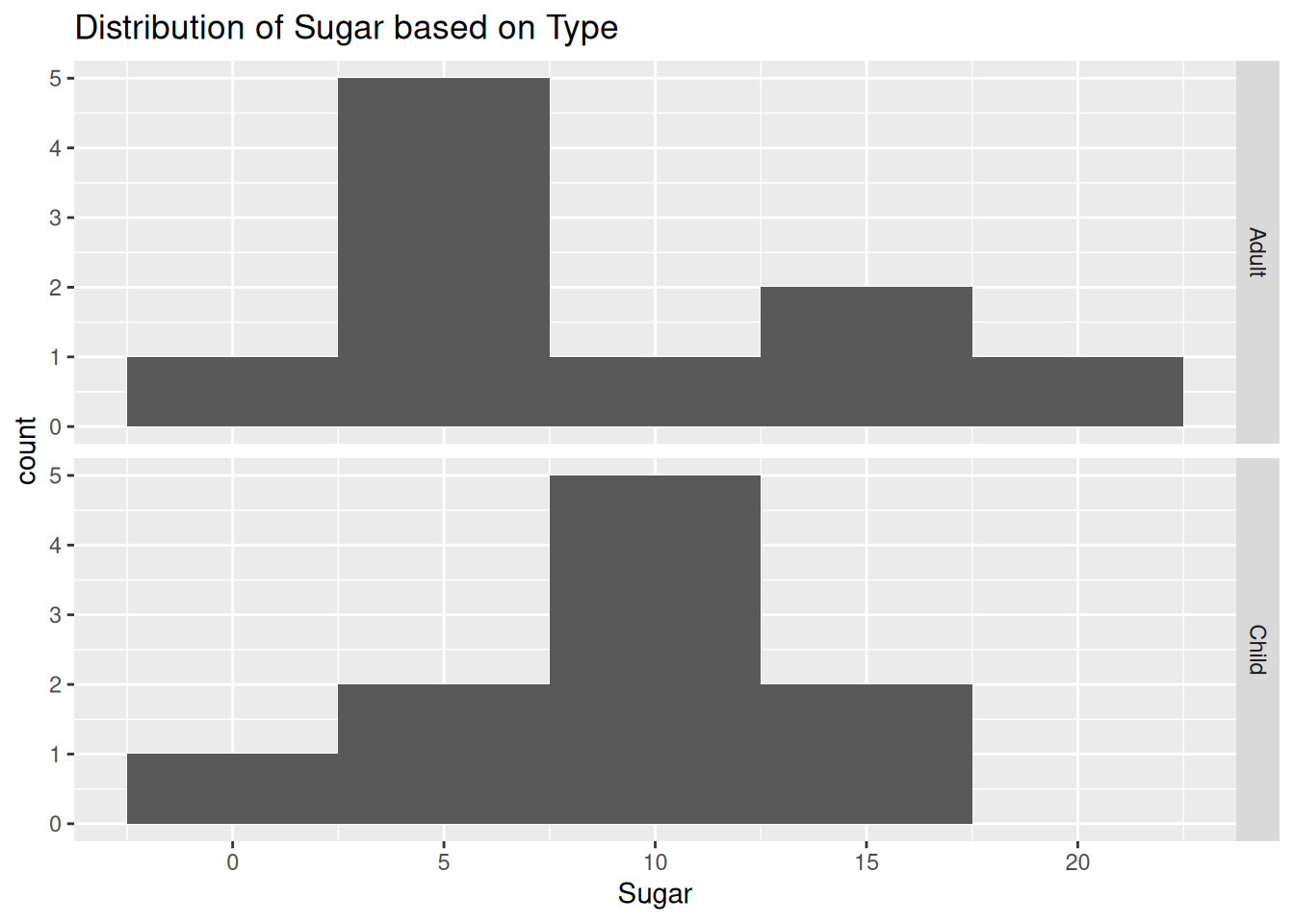
I chose histograms, since we are working with univariate, continuous data. I wanted to compare by type, so I applied a facet_grid.
Bivariate Visualization(s)
ggplot(cereal, aes(`Type`, `Sugar`)) +
geom_boxplot() +
labs(title = "Amount of Sugar in Cereal by Type")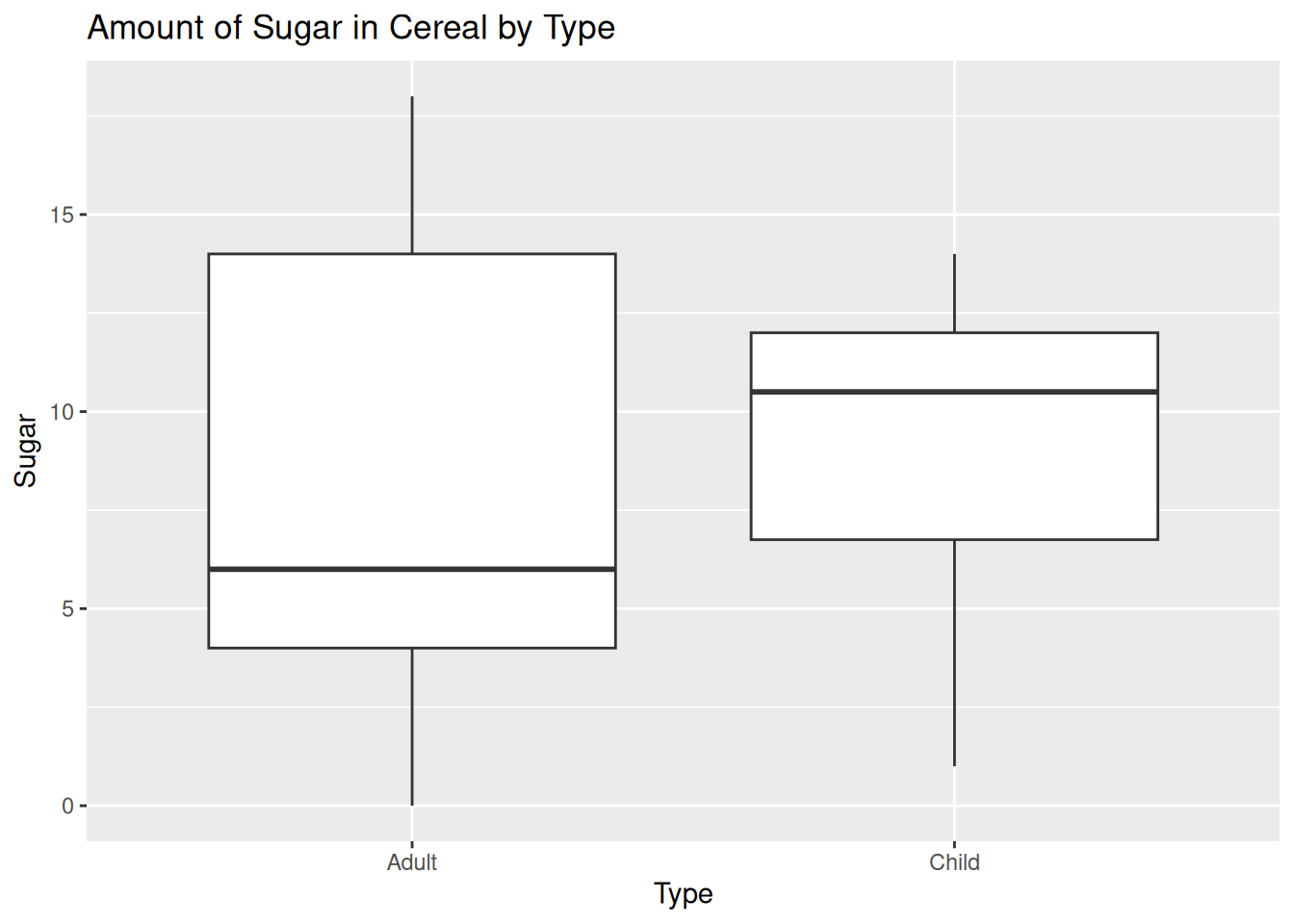
Here we can see that children’s cereal has more sugar in it than adult’s cereal, on average. I chose a box plot, since the data is very sparse. With only 20 points, we can only extrapolate so much.