Warning in fun(libname, pkgname): couldn't connect to display ":0"
system might not have X11 capabilities; in case of errors when using dfSummary(), set st_options(use.x11 = FALSE)
Attaching package: 'summarytools'
The following object is masked from 'package:tibble':
view
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
Code
library(GGally)
Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2
Code
knitr::opts_chunk$set(echo =TRUE)
Introduction
hotel_bookings.csv is a interesting dataset because it features a rich collection of Hotel Bookings data from across the European continent (Spoiler: mostly Portugal!). It contains data from the years 2015 to 2017. This dataset has classified the data into two types of hotels, “City Hotel” and “Resort Hotel”. There’s various information about the attributes of the hotel, booking information including the guest demographic information, and marketing information such as marketing segments, lead time, etc.
Code
data =read_csv("_data/hotel_bookings.csv")
Rows: 119390 Columns: 32
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (13): hotel, arrival_date_month, meal, country, market_segment, distrib...
dbl (18): is_canceled, lead_time, arrival_date_year, arrival_date_week_numb...
date (1): reservation_status_date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Code
# We inspect the columns in this dataset using the head commandhead(data)
Cleaning the data
The data seems relatively clean but for the purposes of analysis we can perform some baseline cleaning to the main dataset.
Just visual inspection using the head() command can tell us a few things. We look at the first few rows of the data to get a visual outline of the dataset and we observe that columns agent, company and country have a lot of NULL values. We can use the following to get a column-wise representation of all the garbage values.
Code
data %>%summarize_all(list(~sum(is.na(.))))
We observe that only children column has na values even our manual inspection told us a different story. Let’s dig in a bit more and identify why the code block above doesn’t give us the expected results.
We observe that the columns like agent and company have “NULL” values, but they don’t show up with the method above. The challenge here is that these values are still character data types and can’t be detected if we’re looking for na or nan values. We can simply use the stringr package and calculate the percentage of “NULL” strings each column has.
Code
# we use the stringr package for thislibrary(stringr)# get the null percentagesnull_percentages <-sapply(data, function(x) sum(str_detect(x, "NULL"))/length(x))# put it into a tibble and arrange itnull_percentages_tibble <-tibble(column =names(data), null_percentage = null_percentages)null_percentages_tibble %>%arrange(desc(null_percentage))
We can see that company, agent and country have “NULL” strings as values which are functionally equivalent to na / nan or garbage values. Additionally, children has some na values. We can replace these strings with meaningful values.
Code
replace_garbage <-c(country ="Unknown", agent =0, company =0)# find indices that have `na`na_indices <-which(is.na(data$children))data$children[na_indices] <-0.0# Use a for loop to replace missing values in each columnfor (col innames(replace_garbage)) { data[data[,col] =="NULL", col] <- replace_garbage[col]}head(data)
Code
dim(data) # 119390x32
[1] 119390 32
We can use hints from manual inspection and dig in a little more.
Code
data %>%count(meal) %>%arrange(-n)
according to the dataset description, Undefined/SC = no meal. So we can convert all the “Undefined” values to SC.
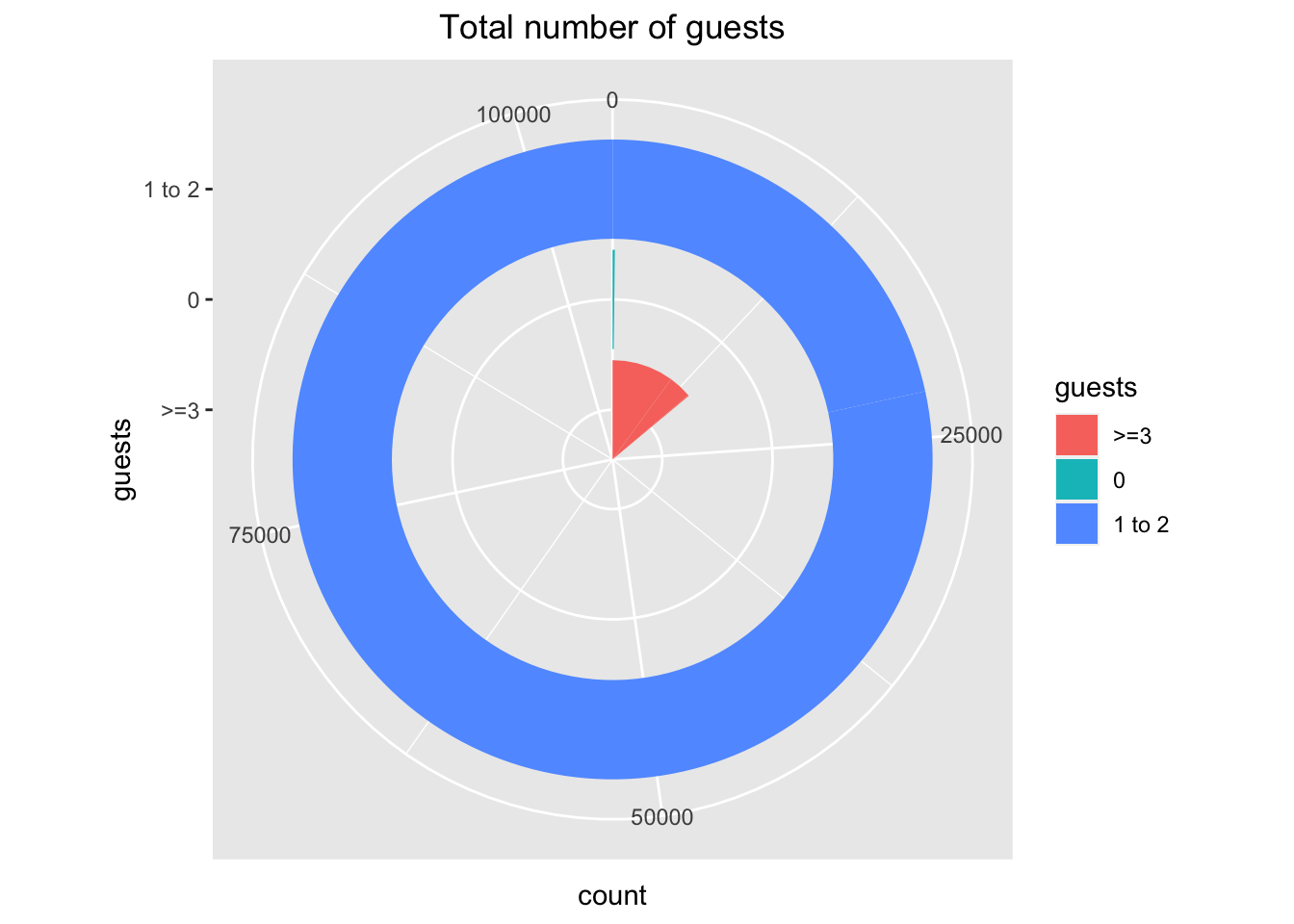
We can also look the # of guests in each room and see if we get some insight. Let’s plot them into three bins: <1, 1-2, and >=3. We’ll use a polar coordinate pie chart for this as it’s easy to show the relative differences in loose self-constructed bins that way.
Code
library(dplyr)data %>%group_by(guests = adults + children + babies) %>%summarize(count =n()) %>%mutate(guests =ifelse(guests ==0, "0", ifelse(guests <=2, "1 to 2", ">=3"))) %>%ggplot(aes(x = guests, y = count, fill = guests)) +geom_bar(stat ="identity") +ggtitle("Total number of guests") +theme(plot.title =element_text(hjust =0.5)) +coord_polar("y", start =0) +scale_fill_manual(values =c("#F8766D", "#00BFC4", "#619CFF"))
We observe that there are non-zero entries in the pie with # of adults + children + babies = 0. Let’s get rid of those rows.
Code
data <- data %>%filter(adults !=0| children !=0| babies !=0)data <- data %>%filter(adr>0)dim(data) # 117399 x 32
[1] 117399 32
EDA: Let’s explore the data a little more
Summary of the Dataset:
Let’s get a sneak peak into what the data actually looks like based on some summary statistics
Generated by summarytools 1.0.1 (R version 4.2.2) 2023-02-06
We can ask several questions right away, the most obvious ones are:
Where do the guests come from?
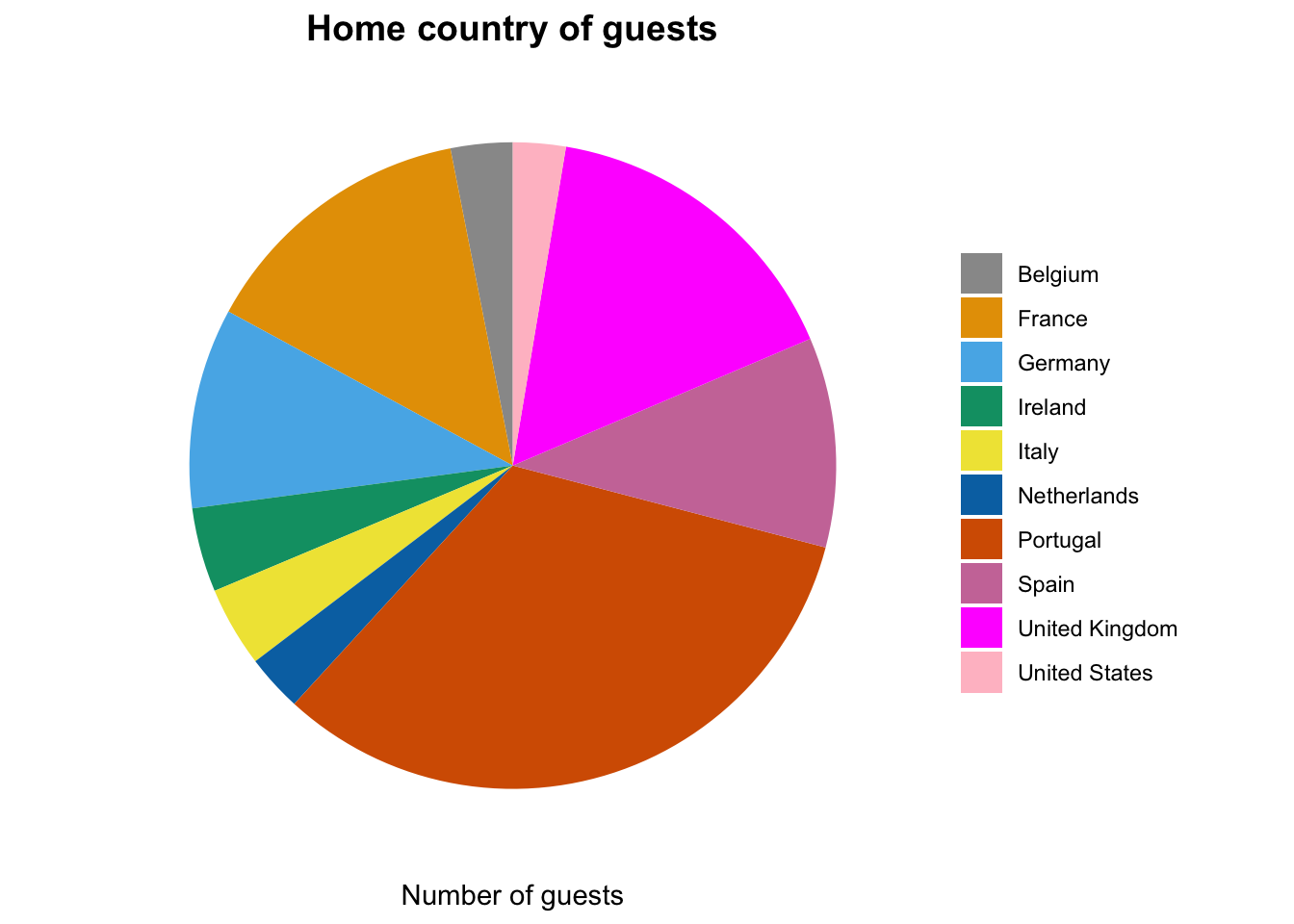
Since we don’t know where these hotels are located, we can try to get hints from the guests that visit these hotels. Let’s plot them on a pie chart and check what countries are represented in this data. We will filter out countries with less than 2% representation.
Code
# get number of guests by country who haven't cancelledcountry_data <- data %>%mutate(country =countrycode(country, origin ="iso3c", destination ="country.name", origin_regex =TRUE))%>%filter(is_canceled ==0) %>%group_by(country) %>%summarise(number_of_guests =n()) %>%ungroup()
Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: CN, TMP, UNKNOWN
Code
# calculate the percentage of guests by countrytotal_guests <-sum(country_data$number_of_guests)country_data$Guests_in_percent <-round(country_data$number_of_guests / total_guests *100, 2)# group countries with less representationcountry_data$country <-ifelse(country_data$Guests_in_percent <2, "Other", country_data$country)colors <-c("#999999", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7", "magenta", "pink")country_data %>%filter(country !="Other") %>%ggplot(aes(x ="", y = number_of_guests, fill = country)) +geom_bar(width =1, stat ="identity") +ggtitle("Home country of guests") +coord_polar(theta ="y") +scale_fill_manual(values = colors) +labs(x =NULL, y ="Number of guests") +theme_classic() +theme(legend.title =element_blank(),plot.title =element_text(hjust =0.5, size =14, face ="bold"),axis.text =element_blank(),axis.ticks =element_blank(),axis.line =element_blank(),plot.background =element_rect(fill ="white"),panel.grid =element_blank())
Code
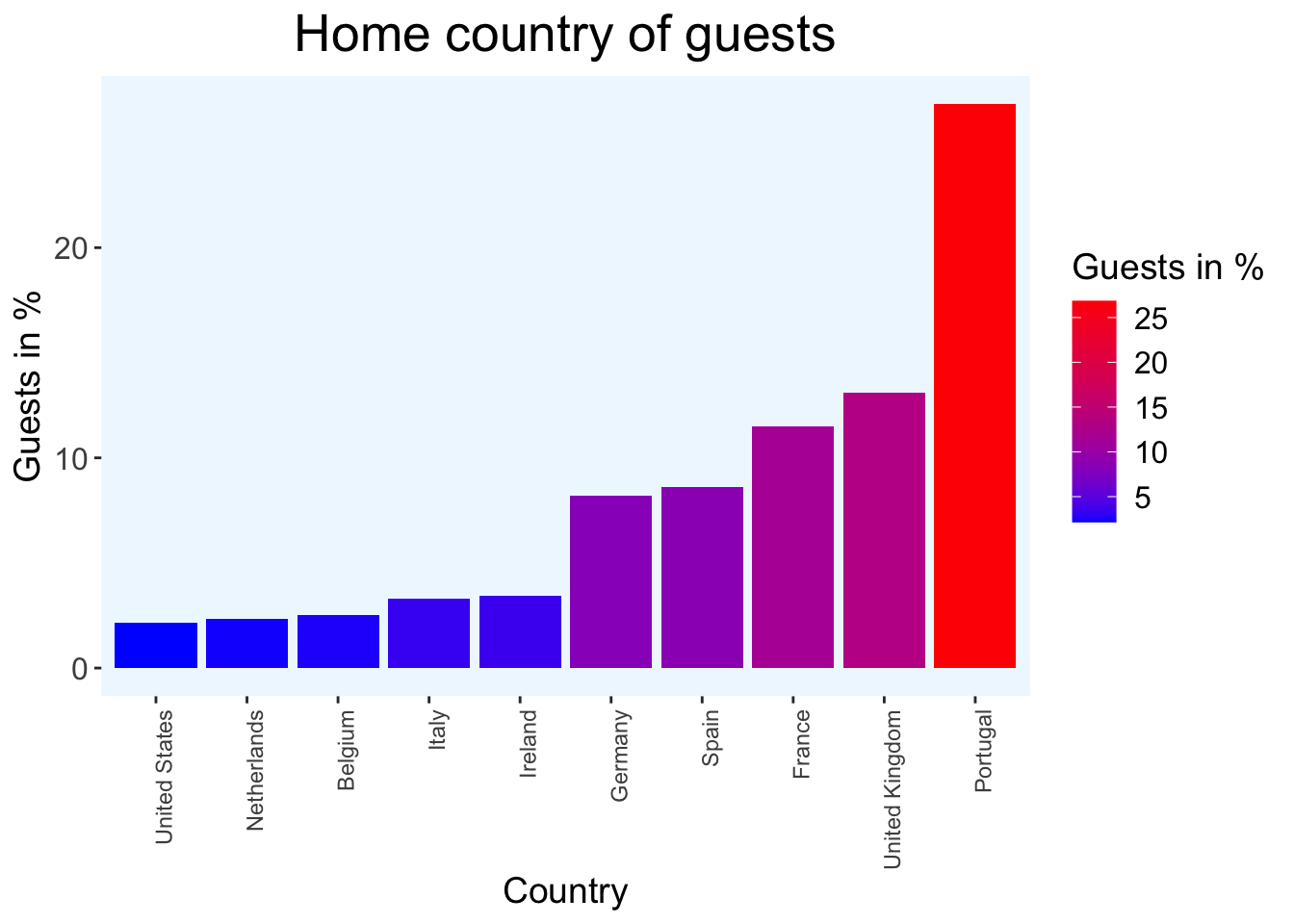
country_data %>%filter(country !="Other") %>%ggplot(aes(x =reorder(country, Guests_in_percent), y = Guests_in_percent, fill = Guests_in_percent)) +geom_bar(stat ="identity") +scale_fill_gradient(low ="blue", high ="red", name ="Guests in %") +theme(axis.text.x =element_text(angle =90, hjust =1),axis.title.x =element_text(size =14),axis.title.y =element_text(size =14),axis.text.y =element_text(size =12),plot.title =element_text(size =20, hjust =0.5),panel.grid =element_blank(),panel.background =element_rect(fill ="aliceblue"),legend.title =element_text(size =14),legend.text =element_text(size =12)) +labs(x ="Country", y ="Guests in %", title ="Home country of guests")
We observe that Portugal and the UK are the countries that are over represented in this data. Which could mean that the hotels are close to those two countries and likely in Europe. It’s a reasonable guess that hotels are from a chain that’s located in Portugal.
Let’s look at the dataset in detail and try to draw inferences from them.
Prices of Rooms per night: Analysis
Another question to ask is how much does it cost to stay in these hotels? Does it change by the type of hotel?
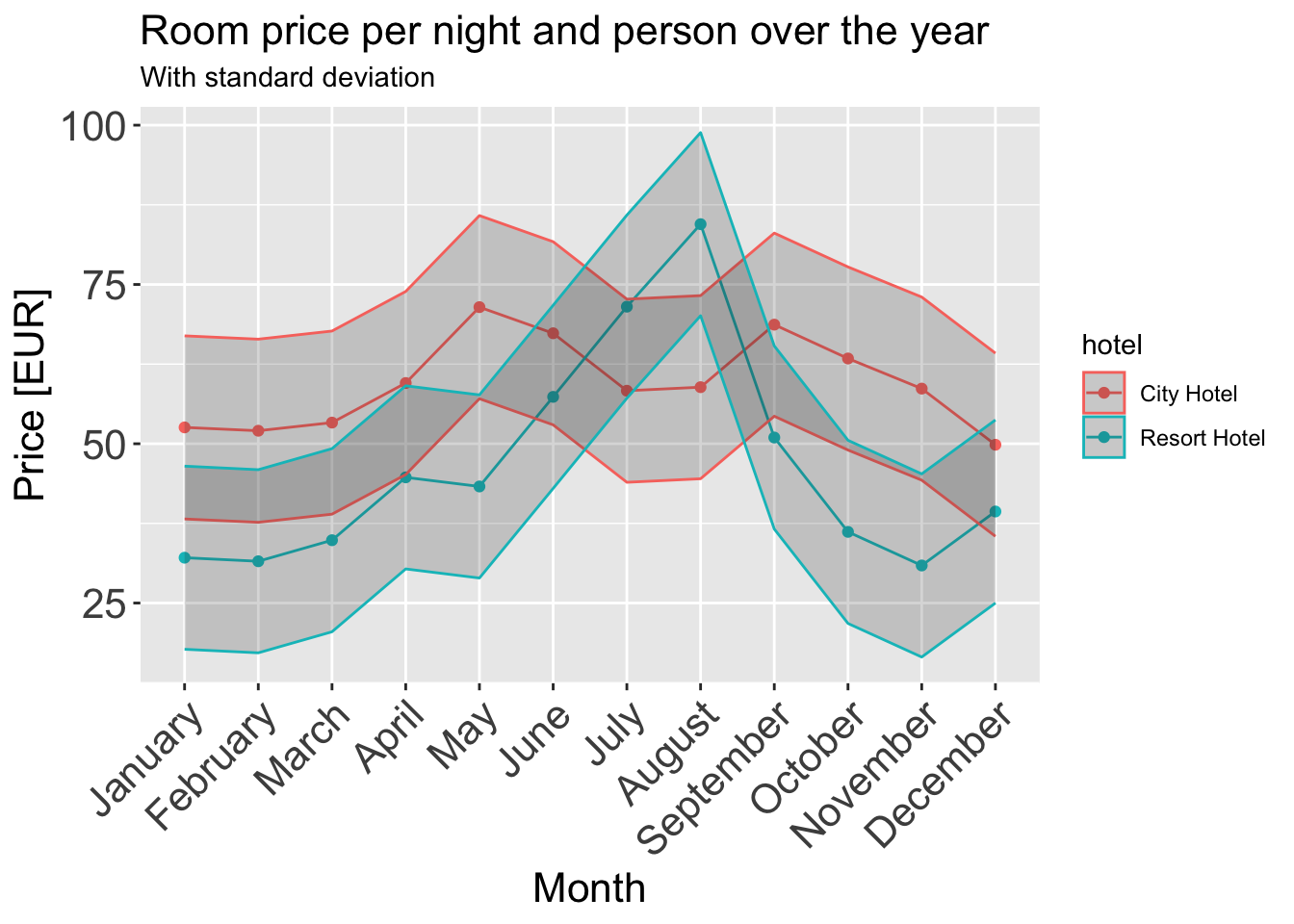
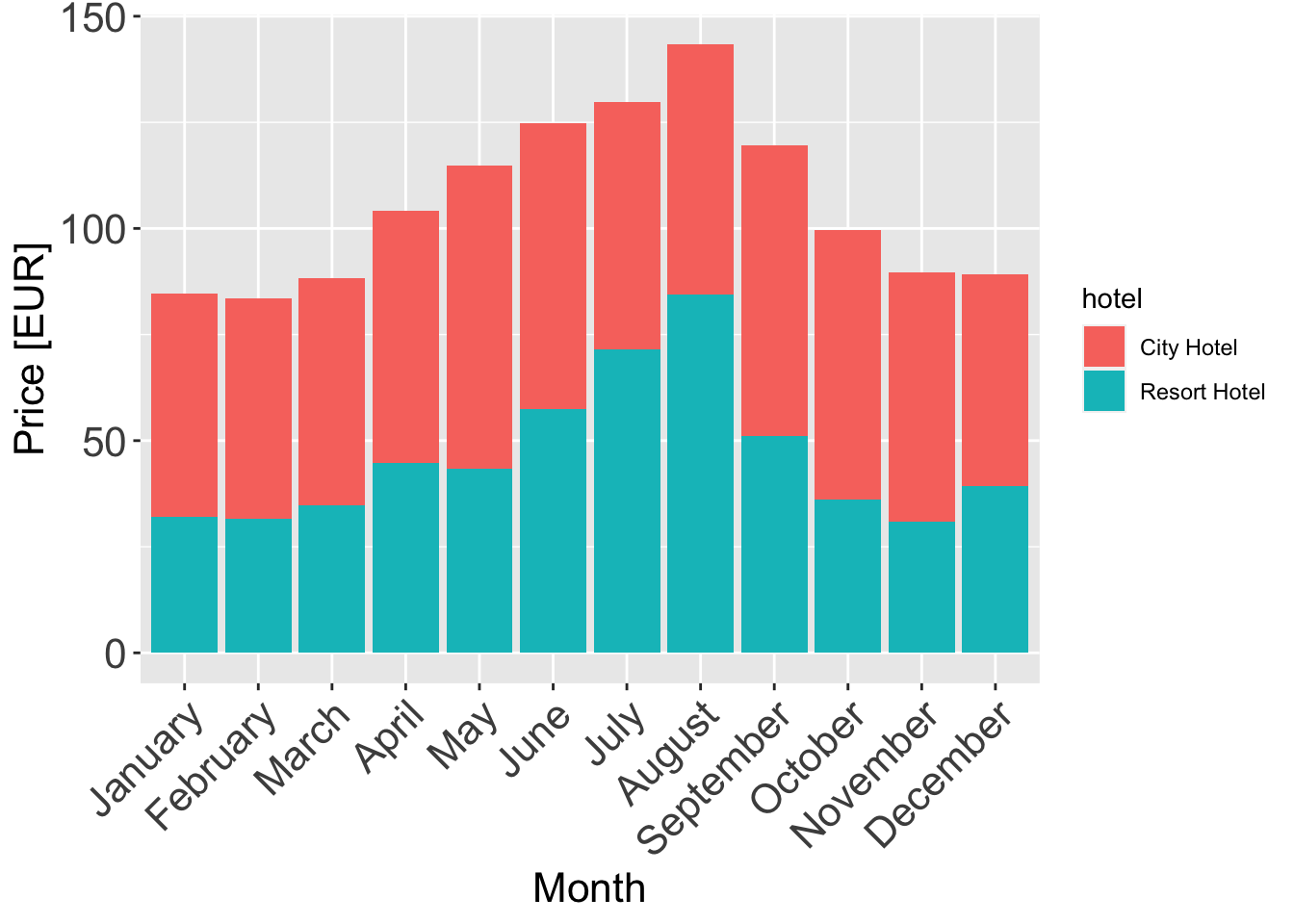
Let’s wrangle some data first. We normalize the adr i.e. the average daily rate such that we get adr_norm which is the daily rate per person.
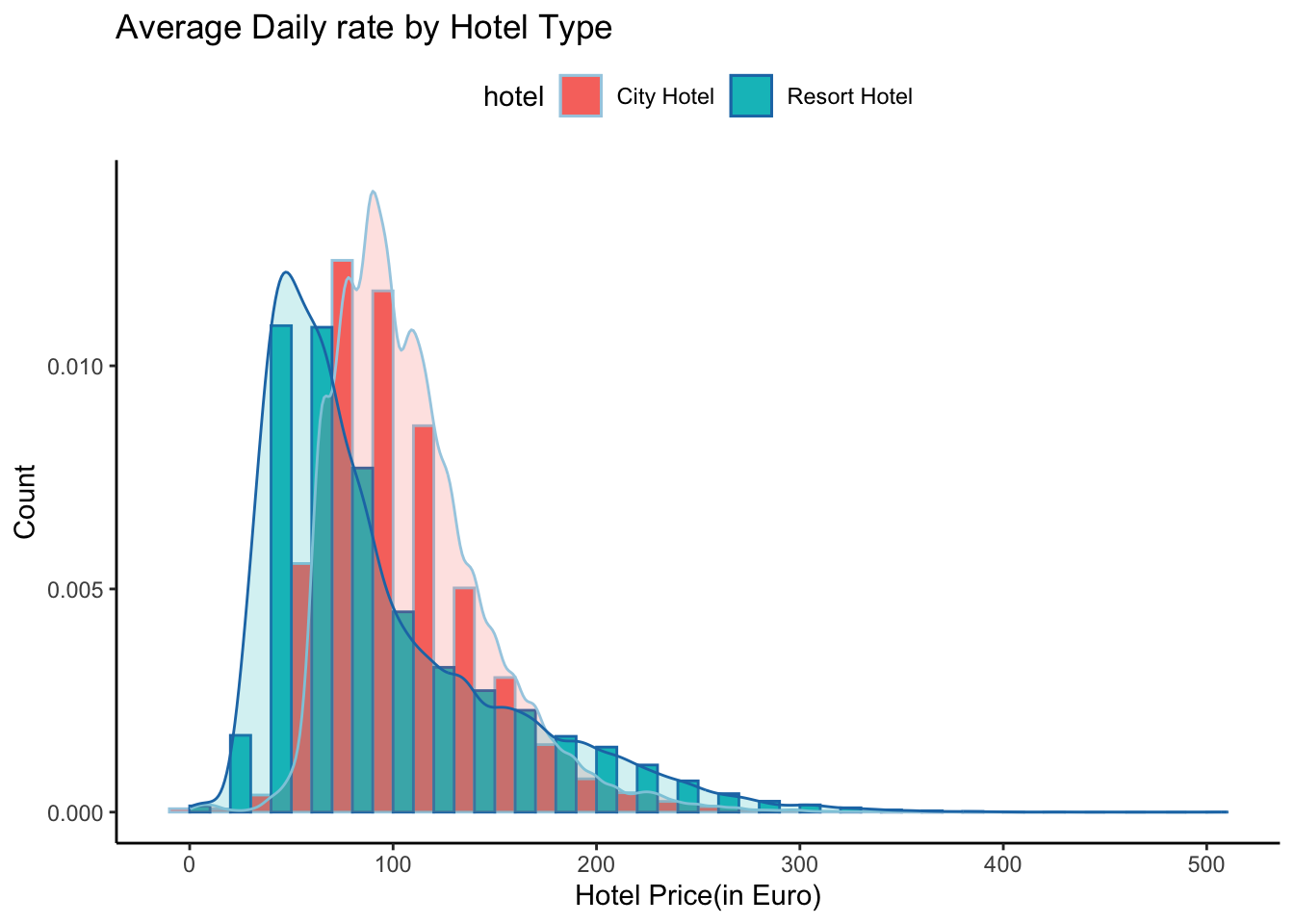
# Average daily rate by Hotel Typeggplot(data_uncancelled, aes(x = adr, fill = hotel, color = hotel)) +geom_histogram(aes(y =after_stat(density)), position =position_dodge(), binwidth =20 ) +geom_density(alpha =0.2) +labs(title ="Average Daily rate by Hotel Type",x ="Hotel Price(in Euro)",y ="Count") +scale_color_brewer(palette ="Paired") +theme_classic() +theme(legend.position ="top")
An interesting observation is that resorts tend to be expensive over the summers while hotels tend to be cheaper. This also makes sense intuitively. We also see that during the summers, resorts get more expensive as compared to the city hotels. This could be due to the demand for resorts and sea-side, leisurely locations during holidays, vacations or just because the guests want to enjoy the beautiful weather.
Room price per night and person by Room Type
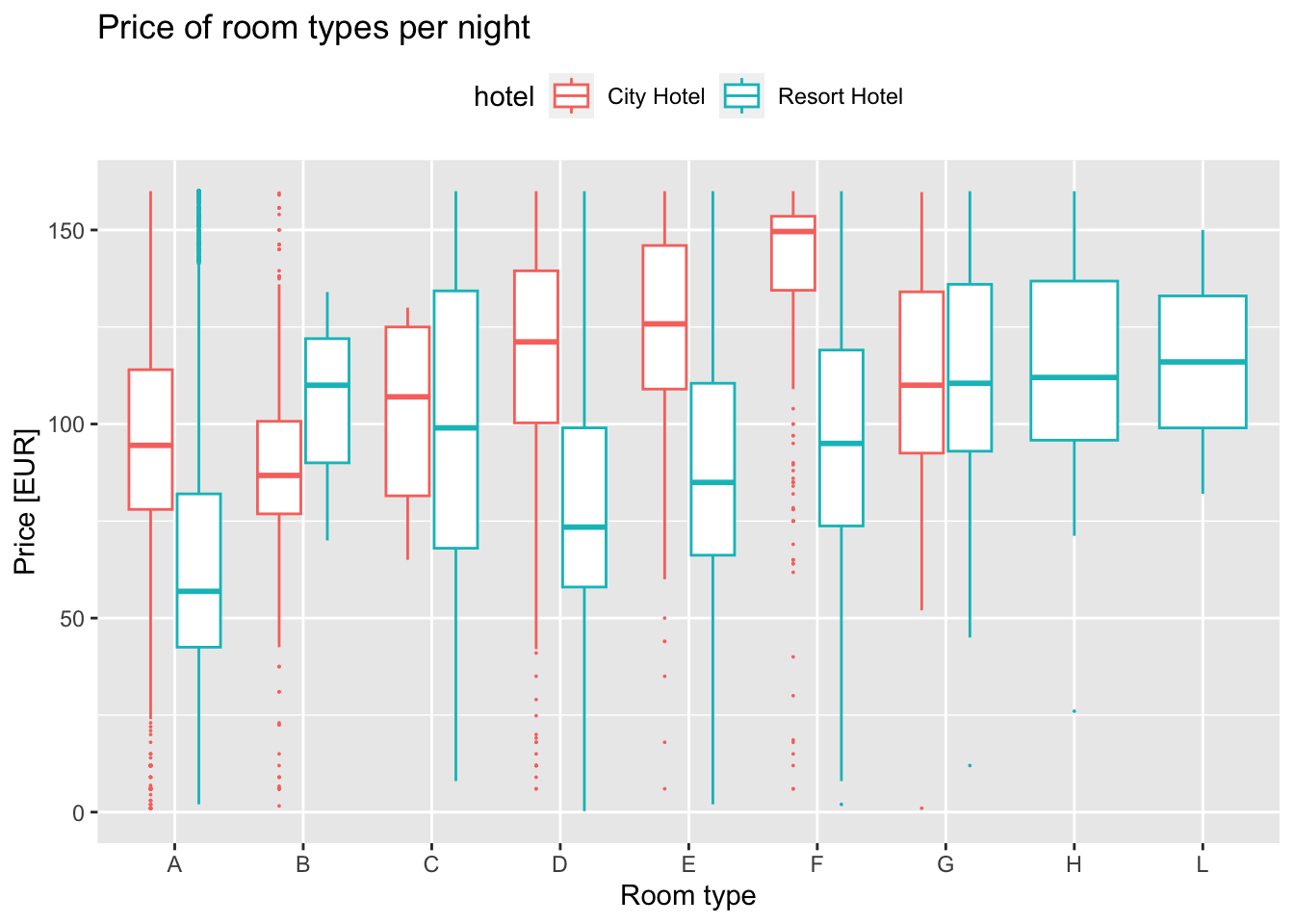
It’s another interesting question to ask, do the guests pay differently based on the types of the rooms they choose? For instance, rooms
Code
ggplot(room_prices, aes(x = reserved_room_type, y = adr, color = hotel)) +geom_boxplot(outlier.size =0) +scale_color_discrete(limits =c("City Hotel", "Resort Hotel")) +labs(title ="Price of room types per night",x ="Room type",y ="Price [EUR]") +theme(legend.position ="top") +scale_y_continuous(limits =c(0, 160))
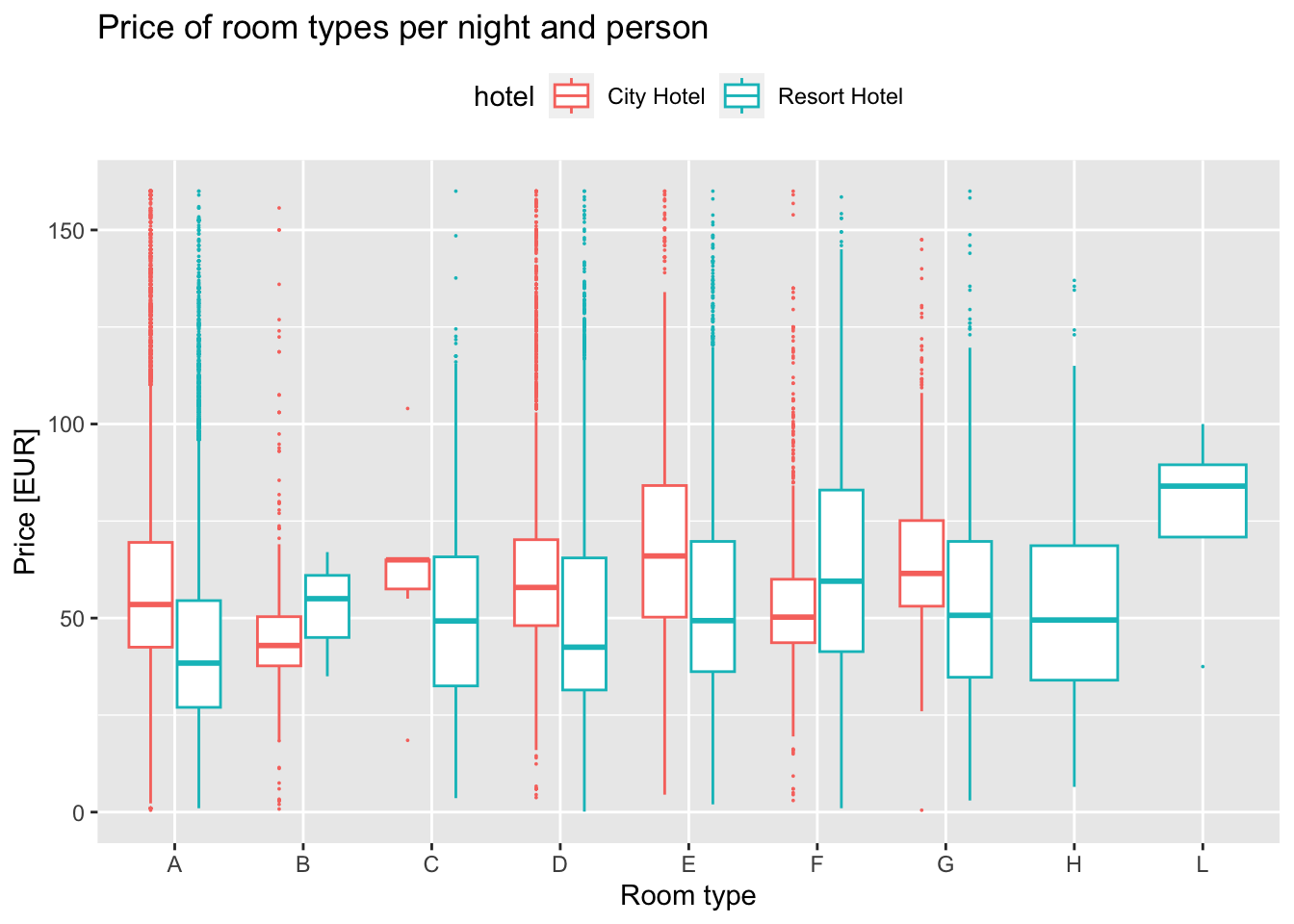
This plot tells us that the data might be such that the room types might not be same across each hotel when we look at the overall price of a room, but it looks to normalize when we adjust for the number of people staying in that room.
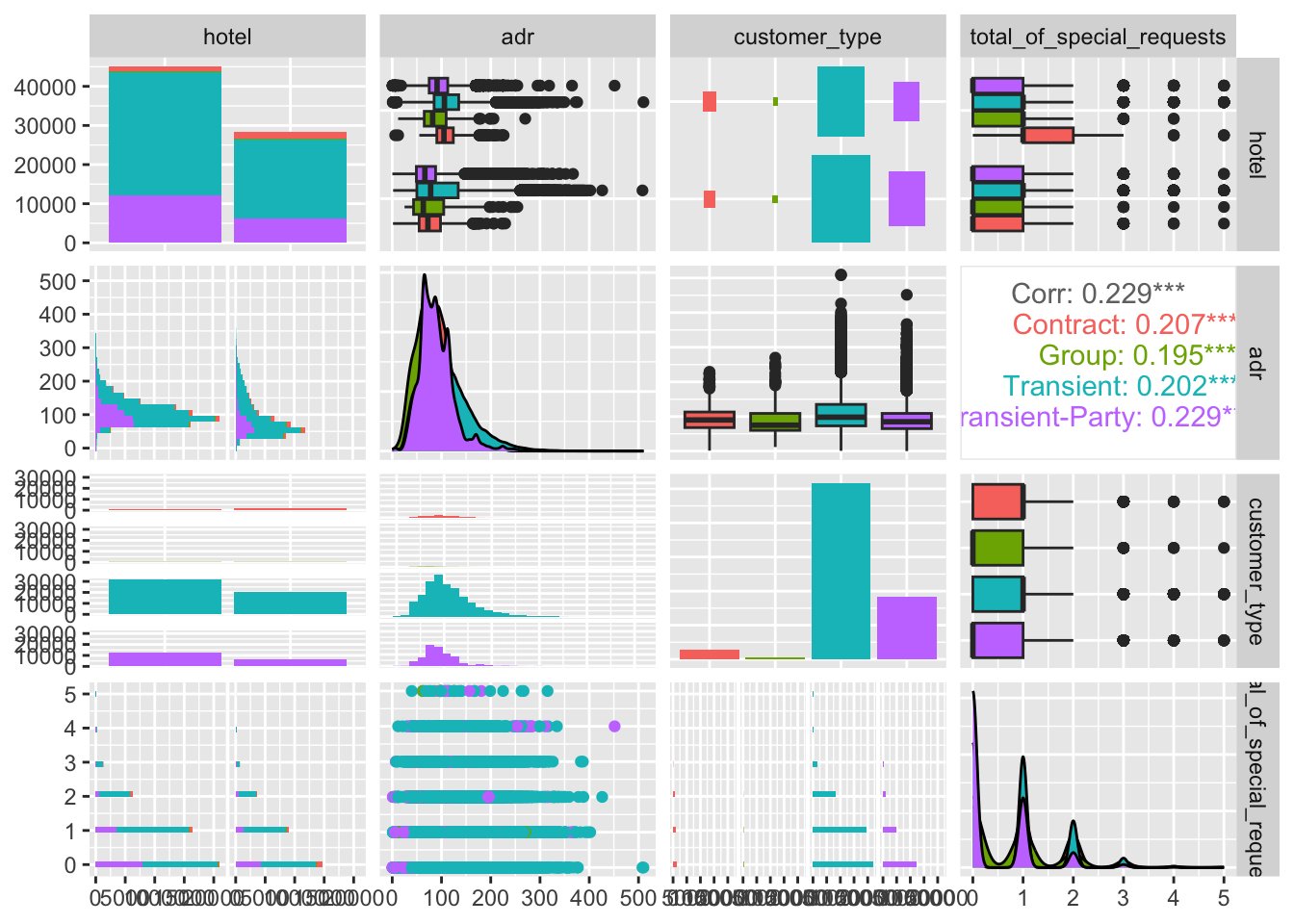
Room price based on the type of customer
Code
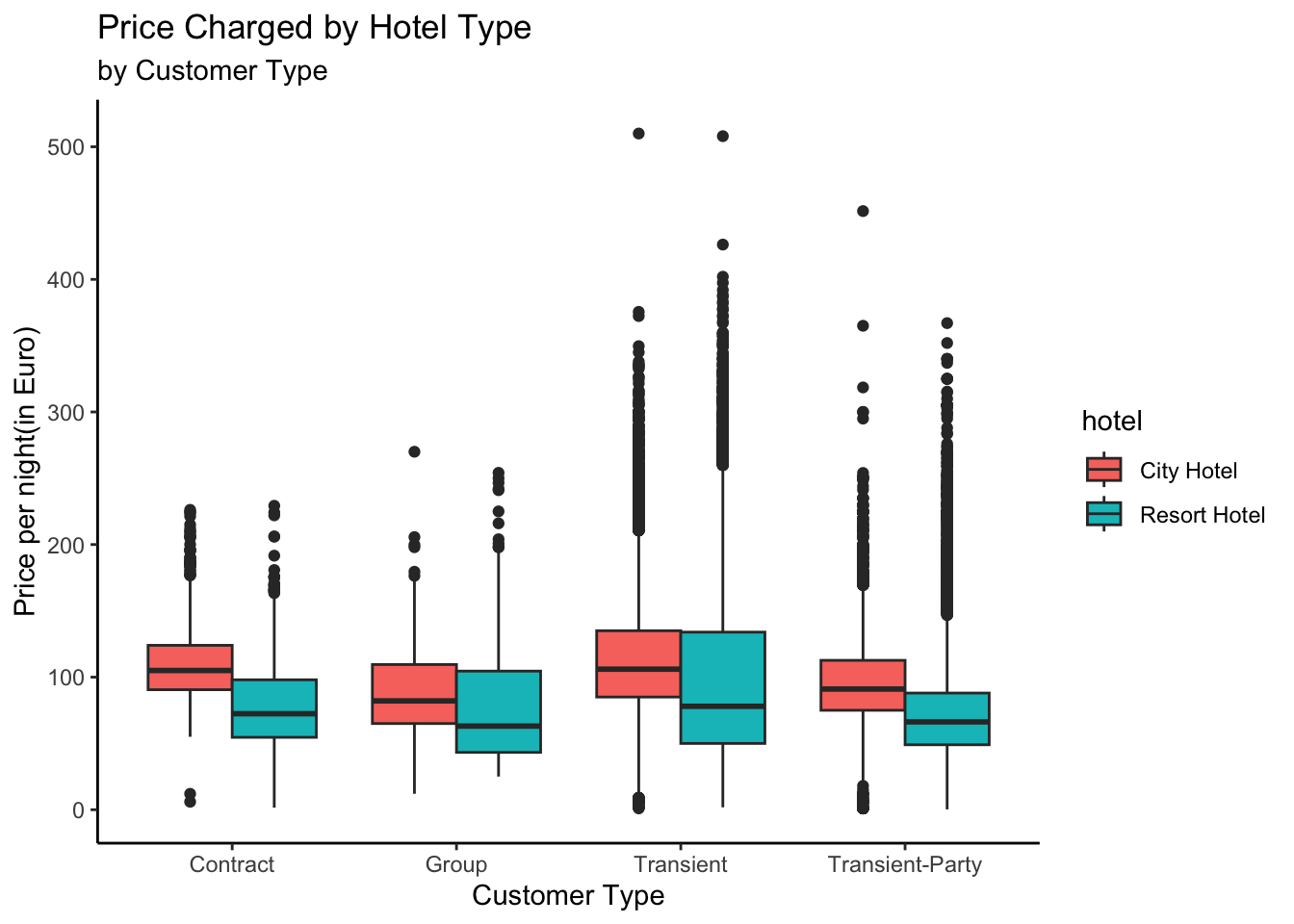
ggplot(data_uncancelled, aes(x = customer_type, y = adr, fill = hotel)) +geom_boxplot(position =position_dodge()) +labs(title ="Price Charged by Hotel Type",subtitle ="by Customer Type",x ="Customer Type",y ="Price per night(in Euro)") +theme_classic()
We can see that Contract and Group prices are more consolidated and generally lower than Transient and Transient-Party. This could be because contracts are pre-negotiated and Group bookings come with discounts.
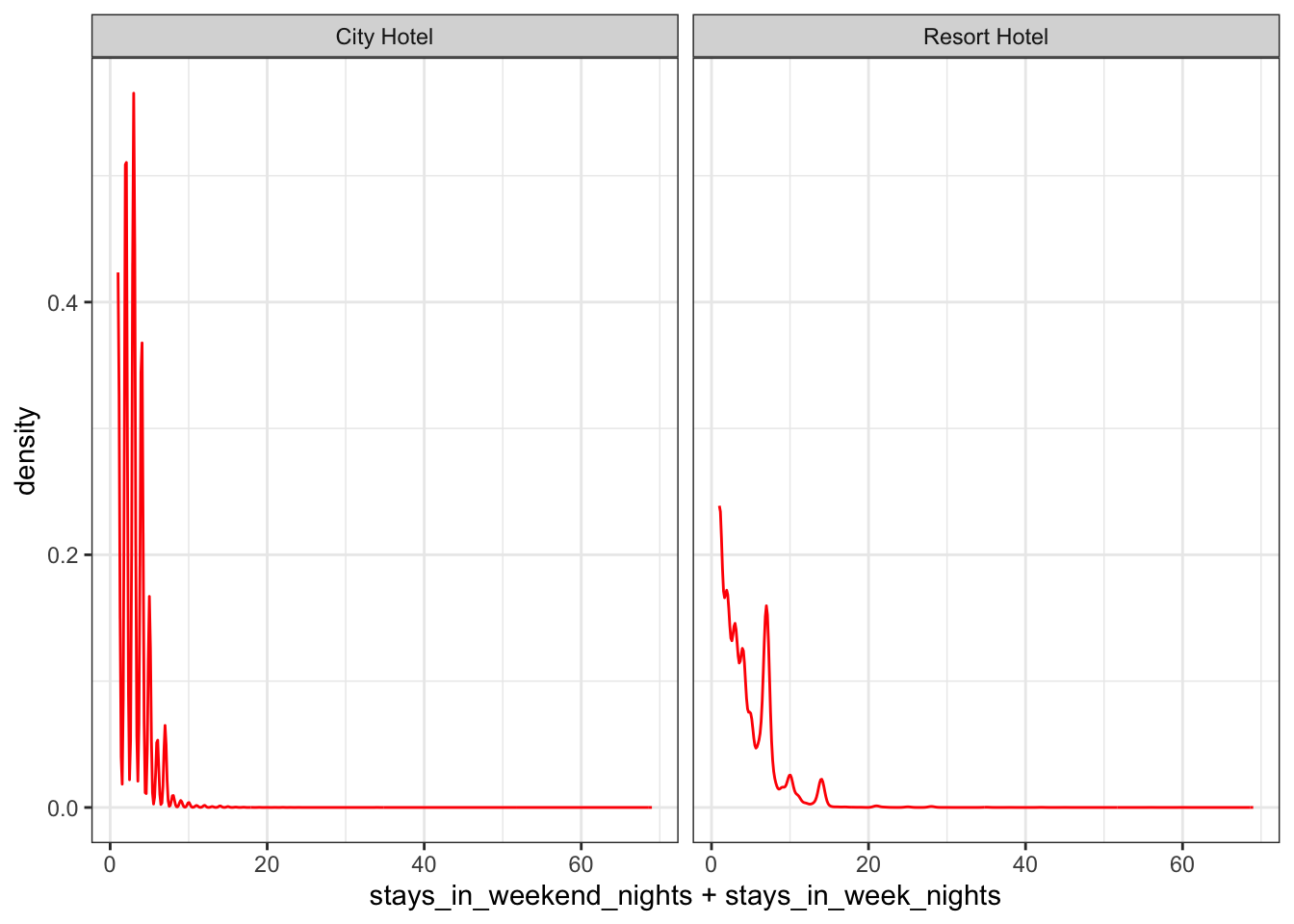
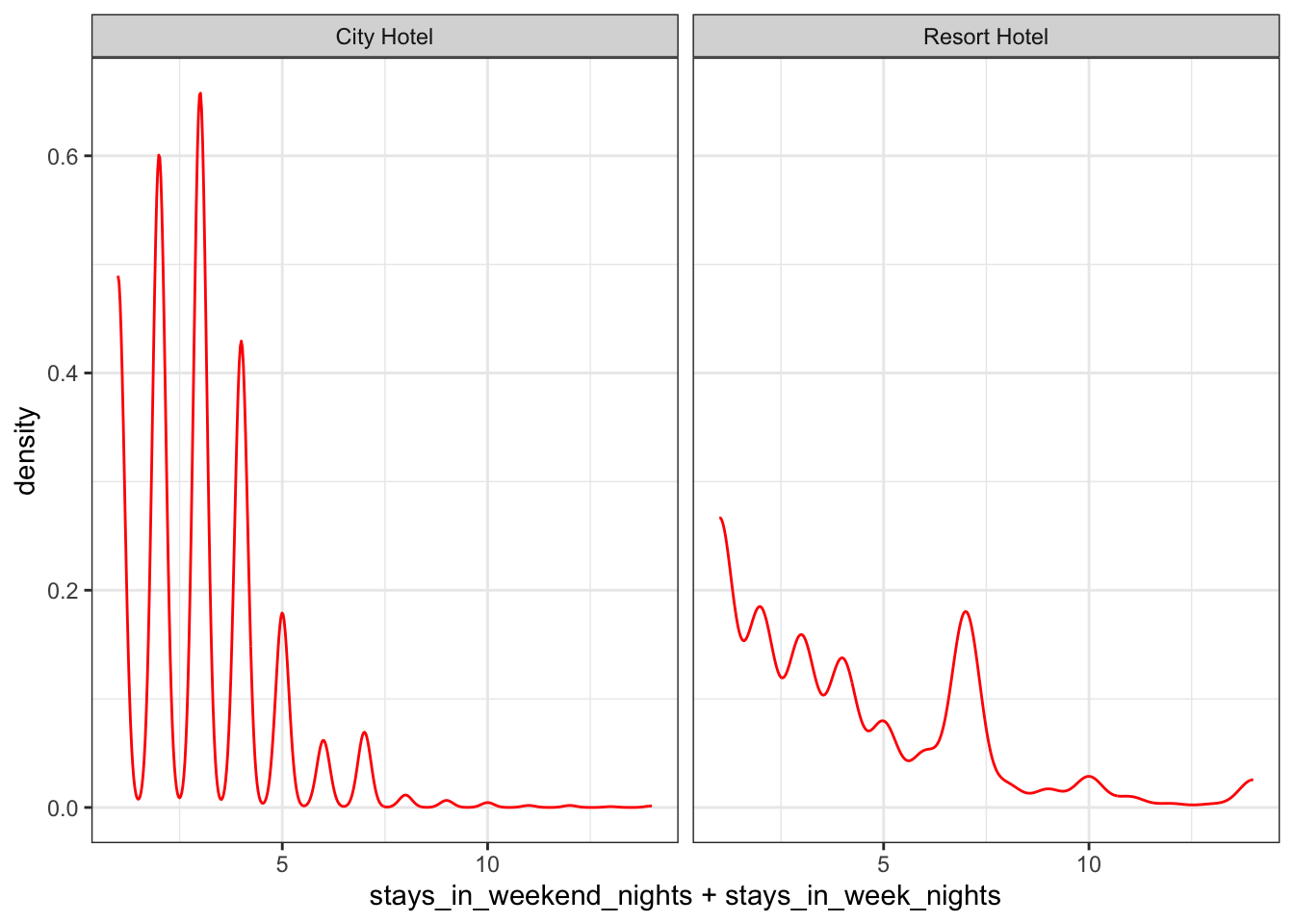
# A closer look after removing the outliersdata_uncancelled %>%filter(stays_in_weekend_nights + stays_in_week_nights <15) %>%ggplot(aes(stays_in_weekend_nights + stays_in_week_nights)) +geom_density(col ="red") +facet_wrap(~hotel) +theme_bw()
What type of customer prefers which kind of hotel?
Code
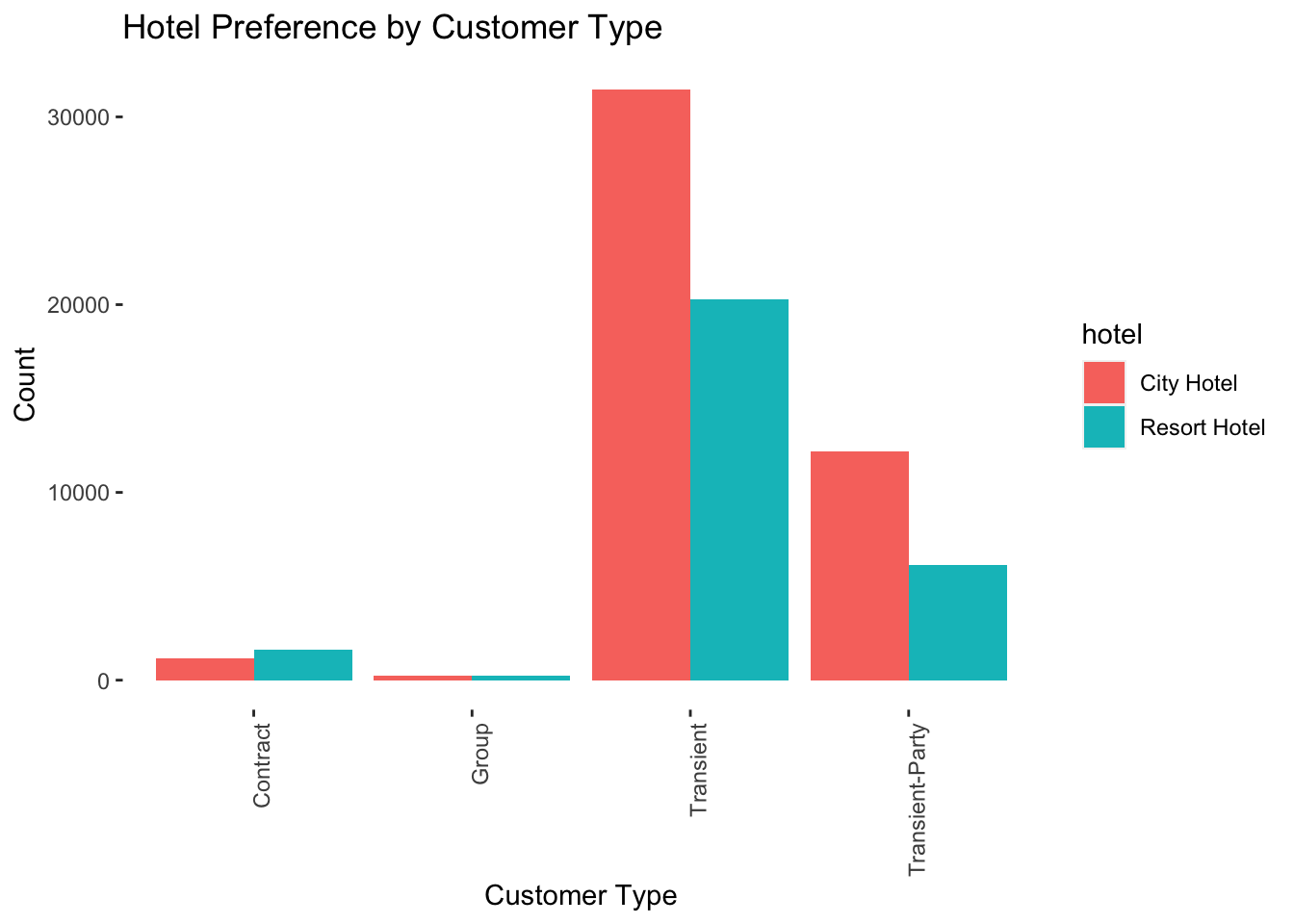
ggplot(data_uncancelled, aes(customer_type, fill = hotel)) +geom_bar(stat ="count", position =position_dodge()) +labs(title ="Hotel Preference by Customer Type",x ="Customer Type",y ="Count") +theme(axis.text.x =element_text(angle =90, hjust =1),panel.background =element_blank())
It’s interesting to see that Contract customers categorically prefer Resorts over City hotels, while transients prefer city hotels which makes sense.
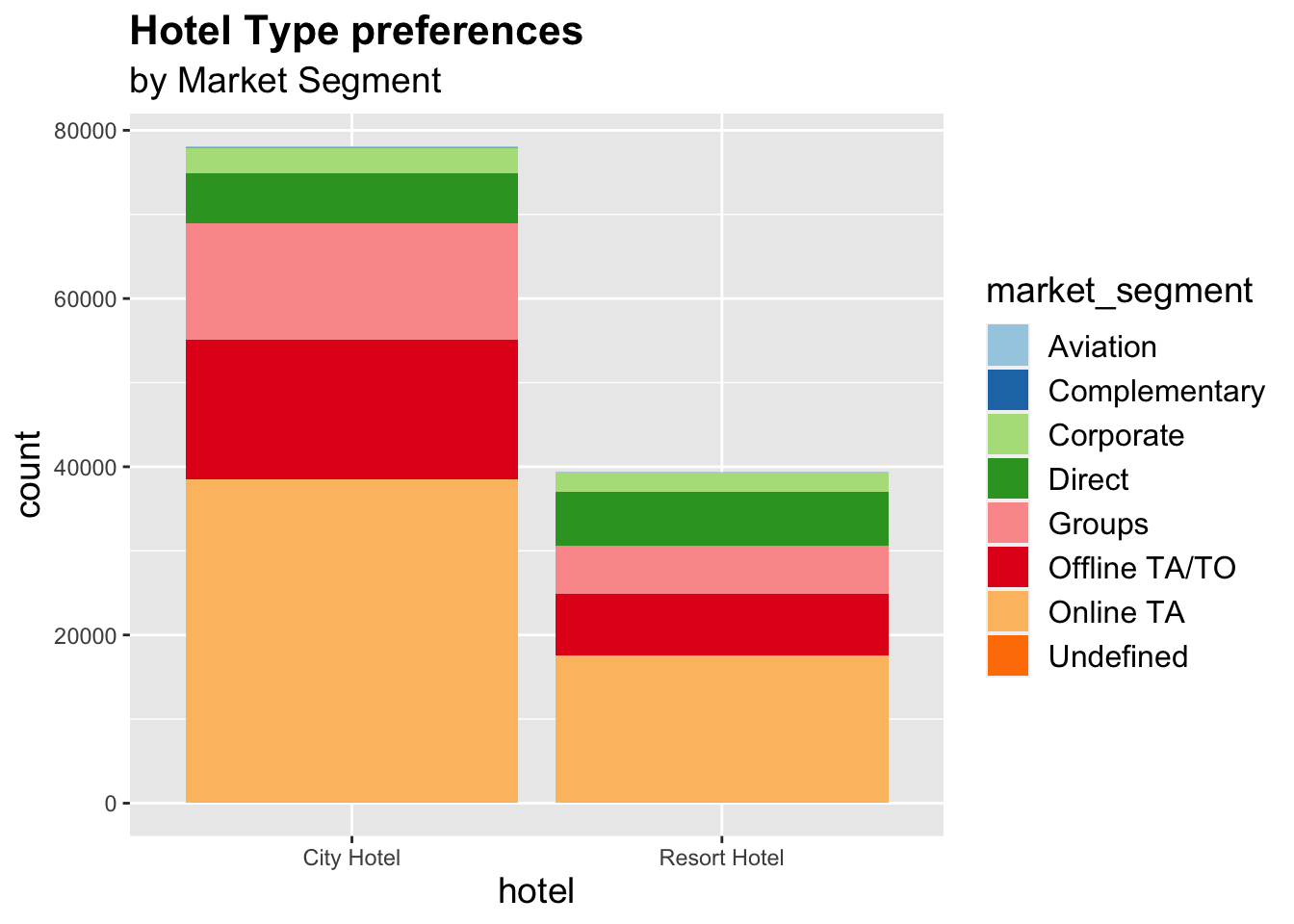
Analysis of the Marketing Data:
A good question to ask here would be, which market segment is popular and which group should the hotel focus on more?
Code
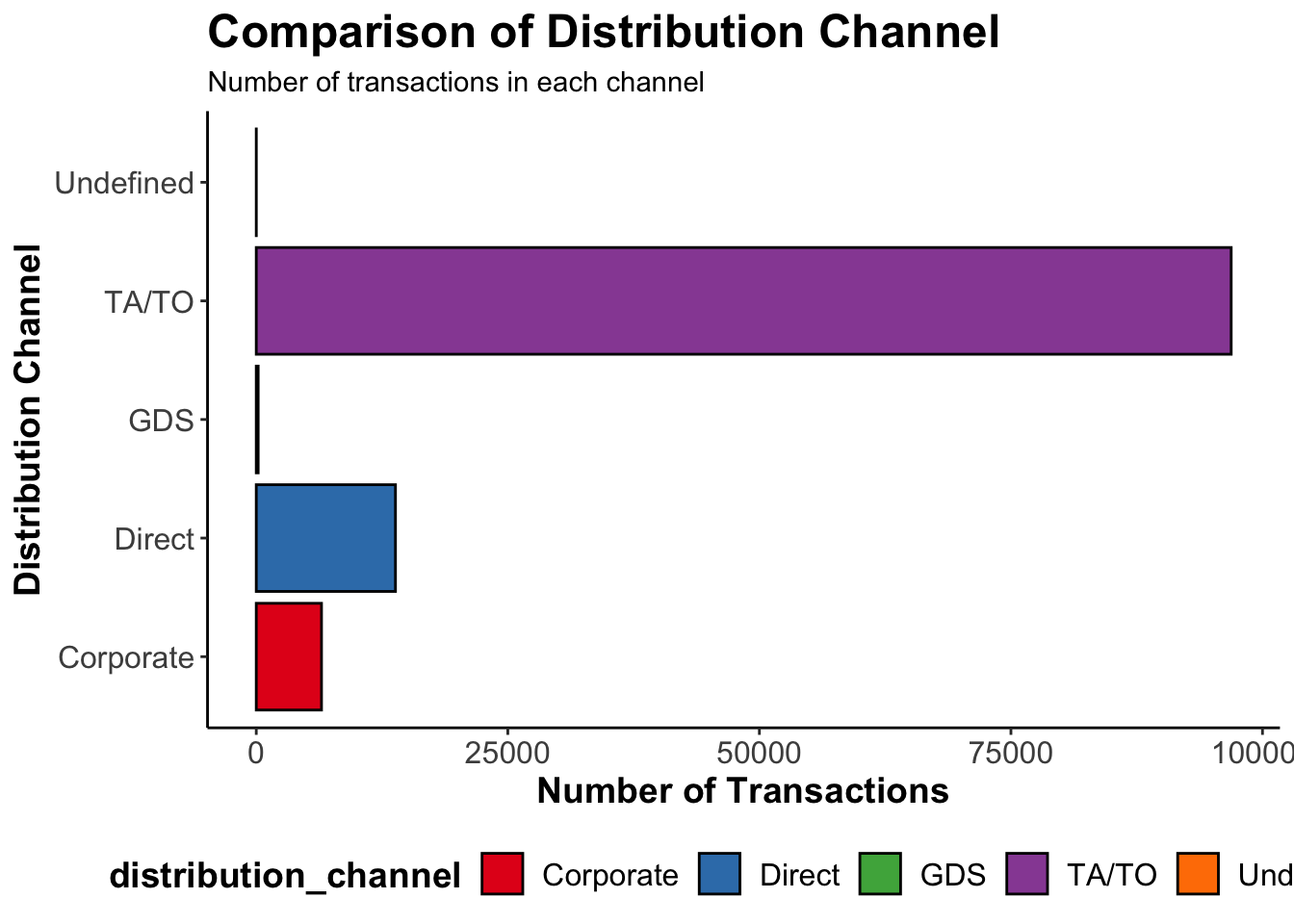
ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = distribution_channel), color ="black", stat ="count") +labs(title ="Comparison of Distribution Channel", subtitle ="Number of transactions in each channel", x ="Distribution Channel", y ="Number of Transactions") +scale_fill_brewer(type ="qual", palette ="Set1") +theme_classic() +theme(plot.title =element_text(size =18, face ="bold"),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12),legend.title =element_text(size =14, face ="bold"),legend.text =element_text(size =12),legend.position ="bottom") +coord_flip()
TA is the identifier for “Travel Agents” and TO for “Tour Operators” TA/TO gets the most number of bookings when compared to corporate, direct, and GDS.
Code
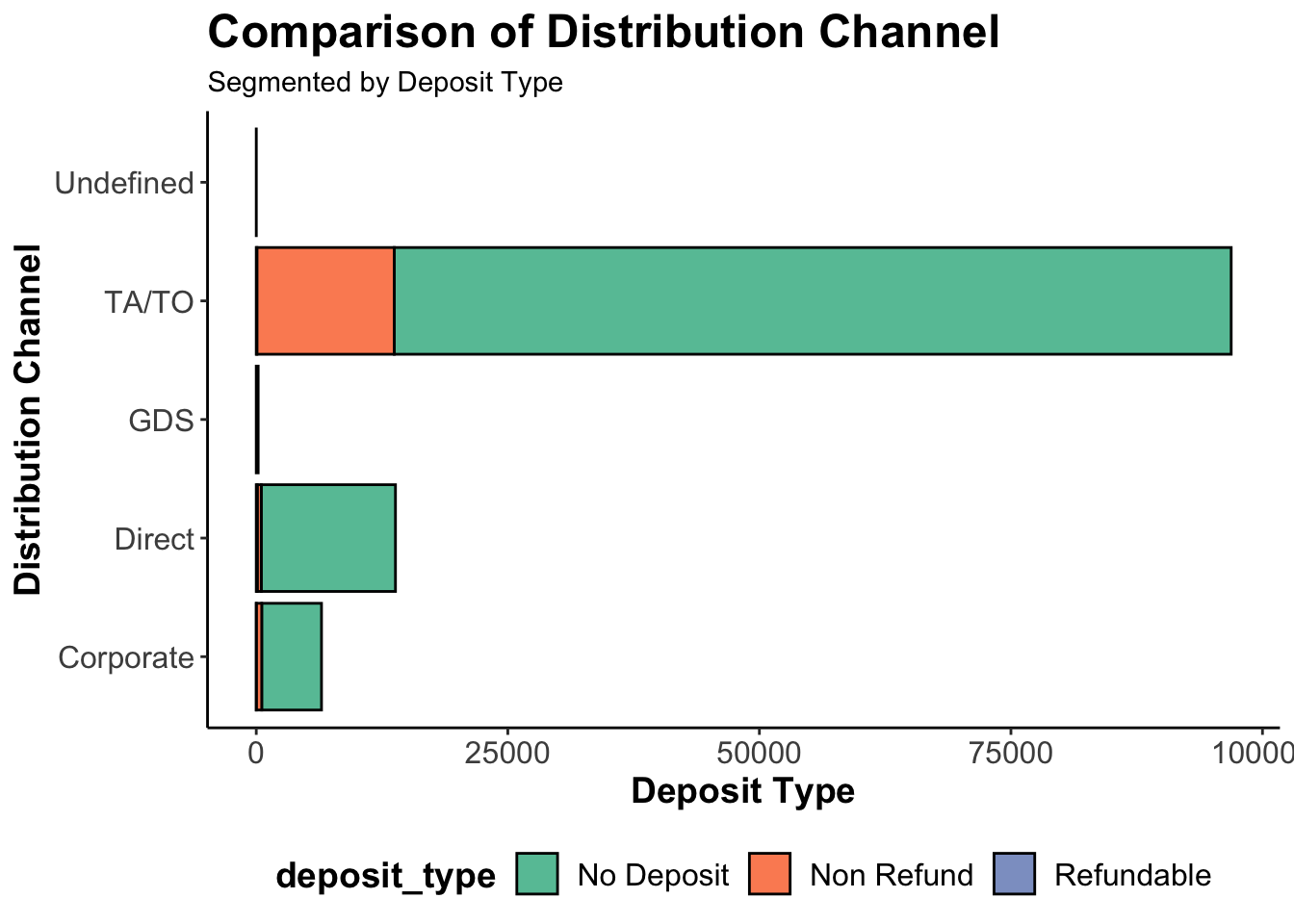
# Segment the bar chart group by "deposit_type"ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = deposit_type), color ="black", stat ="count") +labs(title ="Comparison of Distribution Channel", subtitle ="Segmented by Deposit Type", x ="Distribution Channel", y ="Deposit Type") +scale_fill_brewer(type ="qual", palette ="Set2") +theme_classic() +theme(plot.title =element_text(size =18, face ="bold"),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12),legend.title =element_text(size =14, face ="bold"),legend.text =element_text(size =12),legend.position ="bottom") +coord_flip()
Not many people prefer depositing money before booking across all of the distribution channels, and the highest numbers of booking come from the channel, TA/TO which refers to the Travel Agents.
We can now look at the relationship between market segment and the distribution channel to understand what segments are targeted by which channels
Code
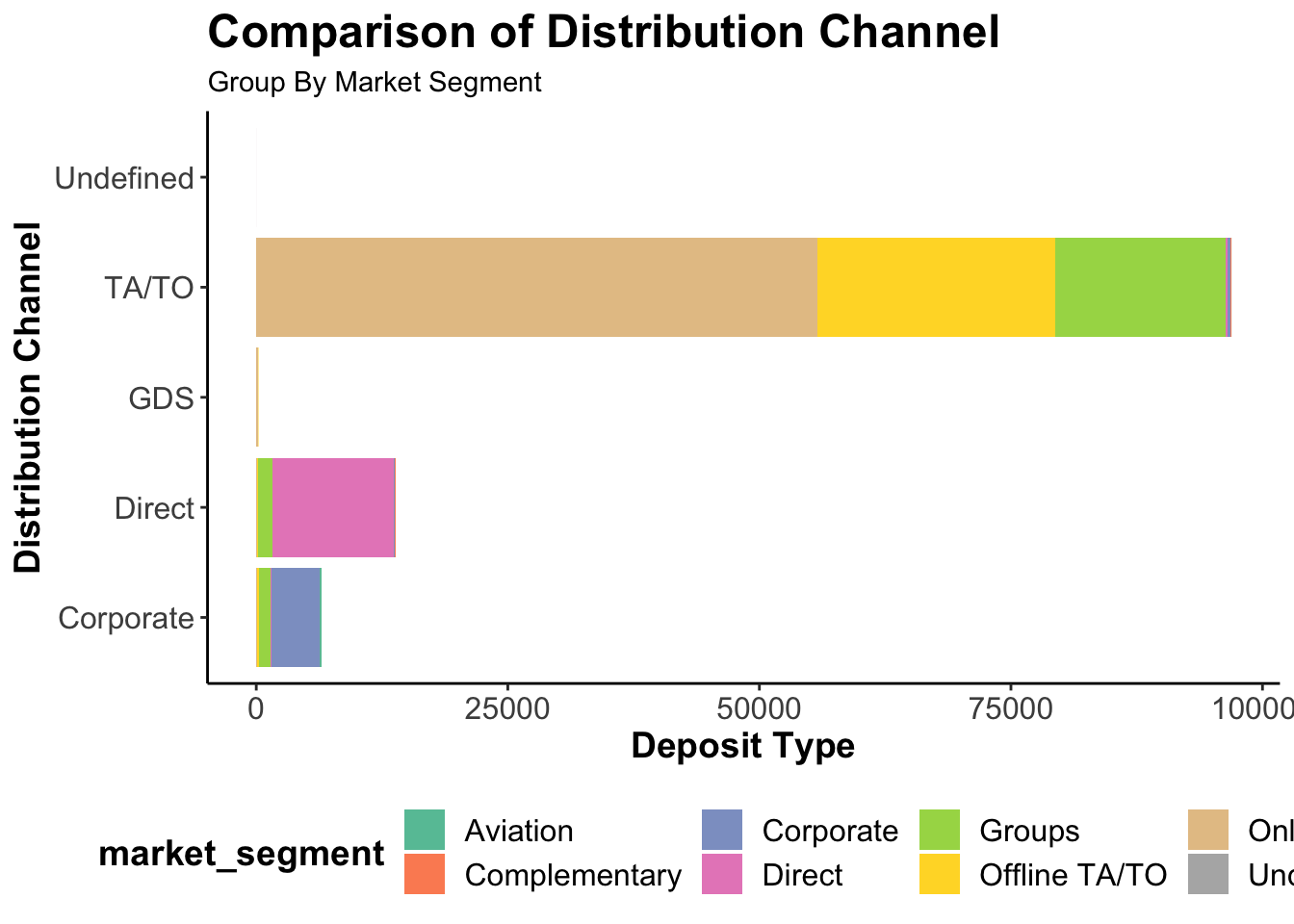
ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = market_segment)) +labs(title ="Comparison of Distribution Channel", subtitle ="Group By Market Segment", x ="Distribution Channel", y ="Deposit Type") +scale_fill_brewer(type ="qual", palette ="Set2") +theme_classic() +theme(plot.title =element_text(size =18, face ="bold"),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12),legend.title =element_text(size =14, face ="bold"),legend.text =element_text(size =12),legend.position ="bottom") +coord_flip()
Online Travel Agencies bring the most number of bookings follwed by offline, group bookings and direct bookings.
We can use facets to separate chart by deposit type and market segment to get a better understanding…
Code
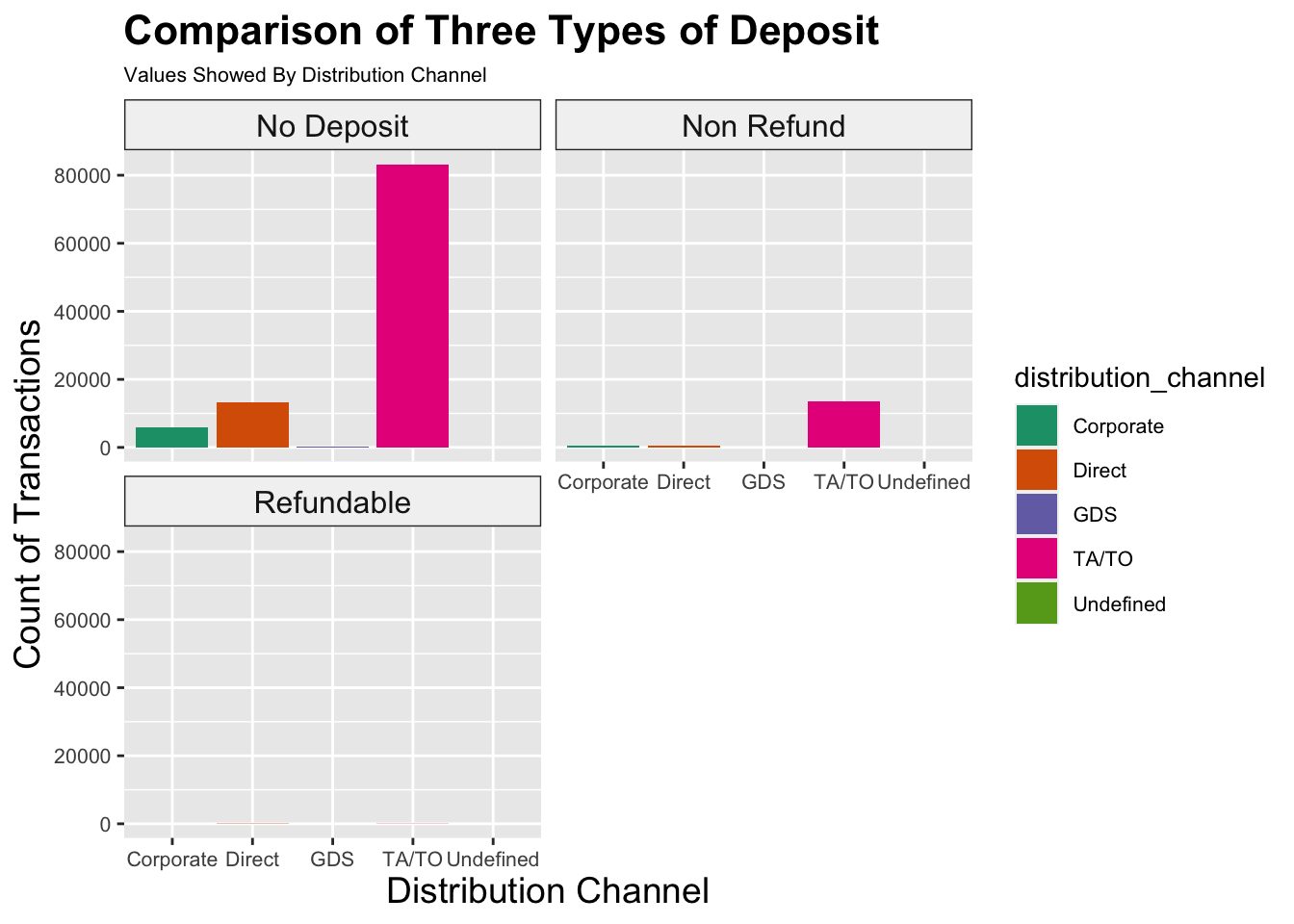
ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = distribution_channel), position ="dodge", stat ="count") +scale_fill_brewer(palette ="Dark2") +labs(title ="Comparison of Three Types of Deposit", subtitle ="Values Showed By Distribution Channel",x ="Distribution Channel",y ="Count of Transactions") +facet_wrap(~deposit_type, ncol =2) +theme(plot.title =element_text(size =16, face ="bold"),plot.subtitle =element_text(size =8),axis.title =element_text(size =14),axis.text =element_text(size =8),legend.text =element_text(size =8),strip.text =element_text(size =12),strip.background =element_rect(fill ="gray95", color ="gray20"))
Unfortunately, this chart doesn’t tell us much.
Effect of Family size on lead time:
Code
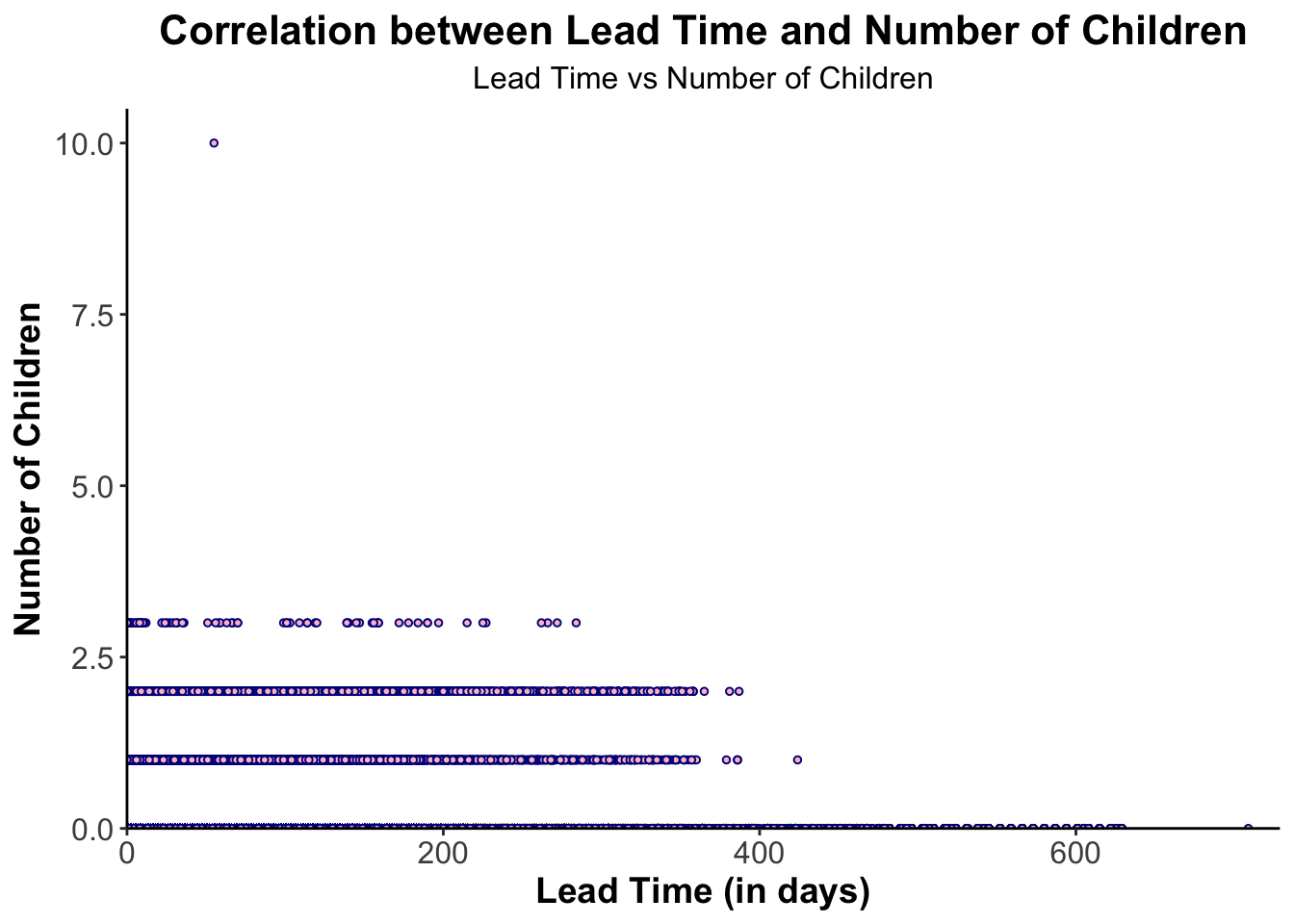
# Show the correlation between booking's lead time and guests who bring their childrenggplot(data = data, aes(x = lead_time, y = children)) +geom_point(shape =21, size =1, fill ="pink", color ="darkblue") +labs(title ="Correlation between Lead Time and Number of Children",subtitle ="Lead Time vs Number of Children",x ="Lead Time (in days)",y ="Number of Children") +scale_x_continuous(limits =c(0, max(data$lead_time) +20), expand =c(0,0)) +scale_y_continuous(limits =c(0, max(data$children) +0.5), expand =c(0,0)) +theme_classic() +theme(plot.title =element_text(size =16, hjust =0.5, face ="bold"),plot.subtitle =element_text(size =12, hjust =0.5),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12))
We see shorter lead times for guests with fewer children, it’s unclear as to why this would happen but I have a hypothesis that it’s harder to make plans when there are children involved since the schedules have to align with their school schedules. People without children might also be people who aren’t traveling for leisure so their bookings are well planned in advance.
Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: CN, TMP, UNKNOWN
Code
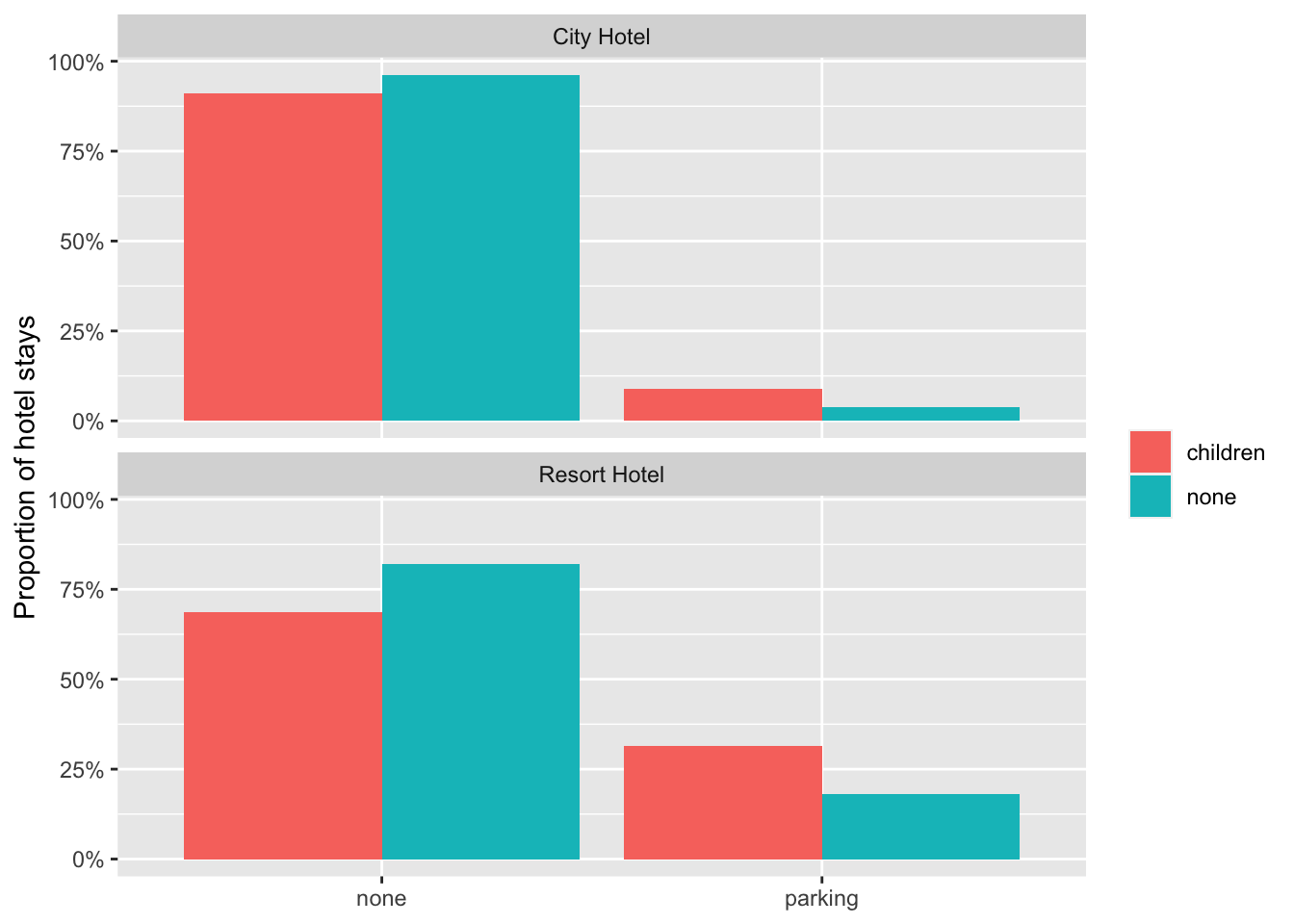
#select(-is_canceled, -reservation_status, -babies)hotel_stays %>%count(hotel, required_car_parking_spaces, children) %>%group_by(hotel, children) %>%mutate(proportion = n /sum(n)) %>%ggplot(aes(required_car_parking_spaces, proportion, fill = children)) +geom_col(position ="dodge") +scale_y_continuous(labels = scales::percent_format()) +facet_wrap(~hotel, nrow =2) +labs(x =NULL,y ="Proportion of hotel stays",fill =NULL )
It’s clear that across both the hotel types, guests with no children require less parking spots. Which means these two variables are tied closely.
Other Analysis
This part of the report contains plots for exploring all of the interesting variables to so that we have as much information as we can to draw the inferences at the end.
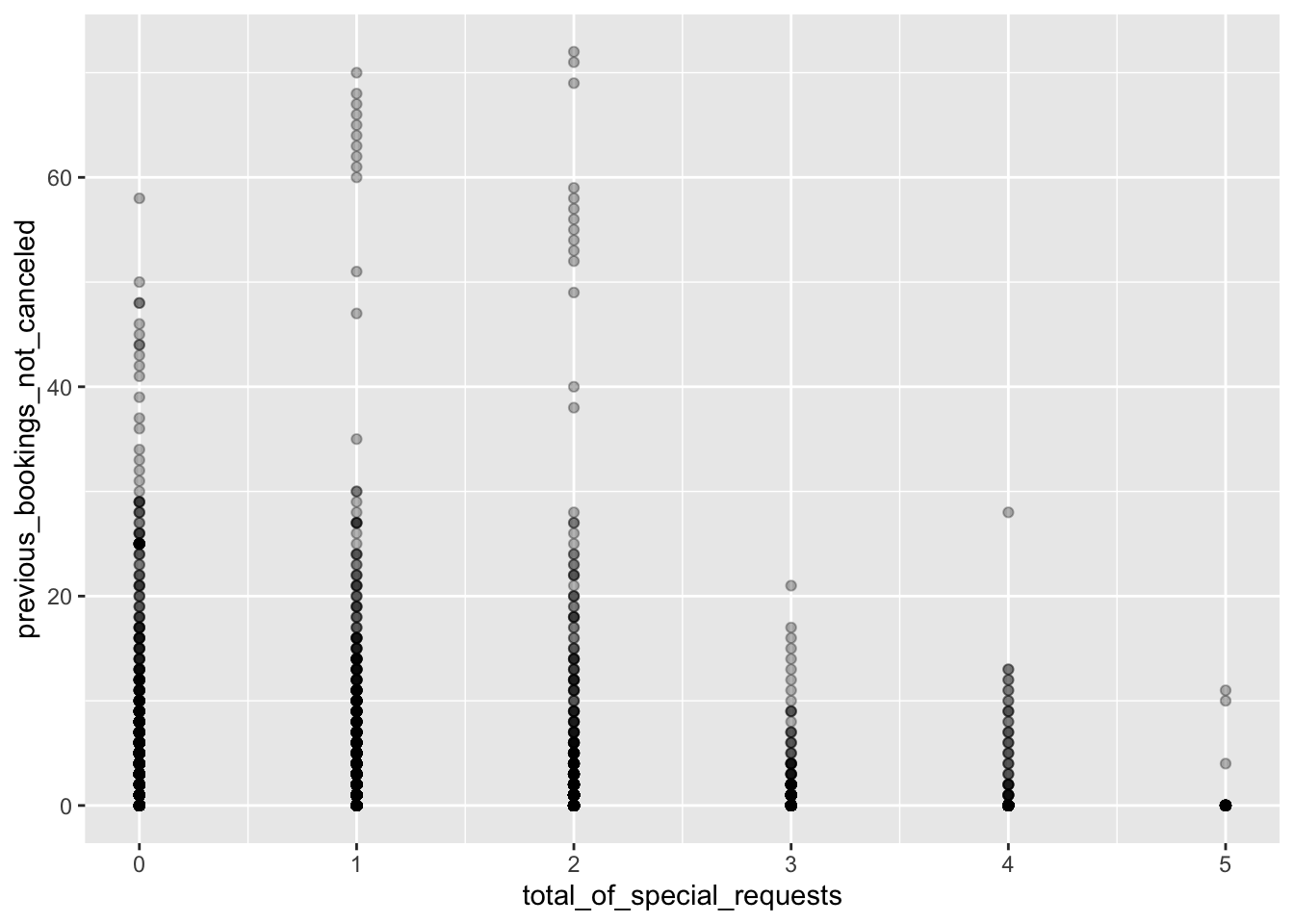
Special requests vs. Previous booking not cancelled: are people who cancel a lot more prone to making special requests?
Code
data %>%ggplot(aes(x = total_of_special_requests, y = previous_bookings_not_canceled)) +geom_point(alpha =0.3)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
We observe a weak correlation between these attributes, inconclusive.
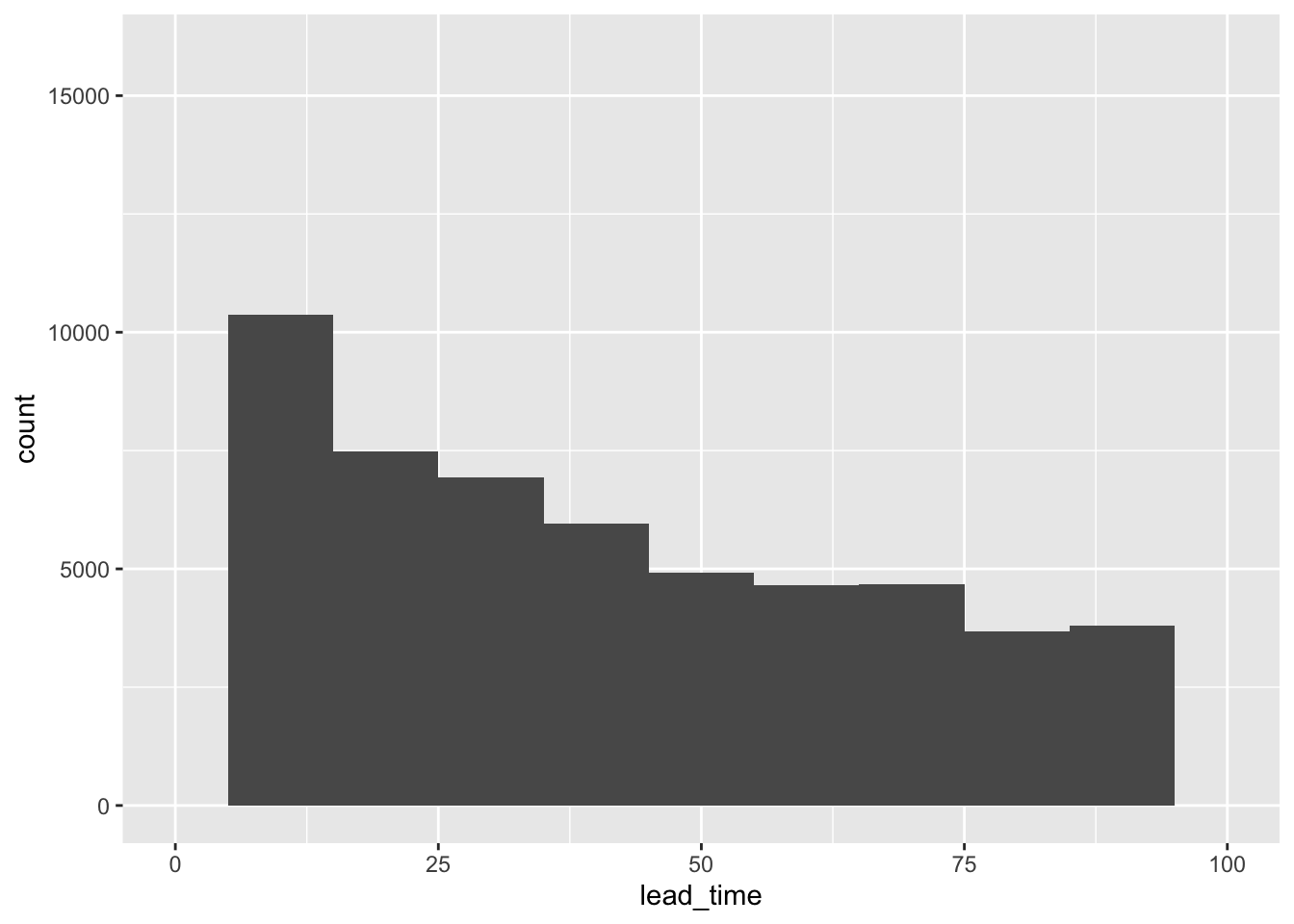
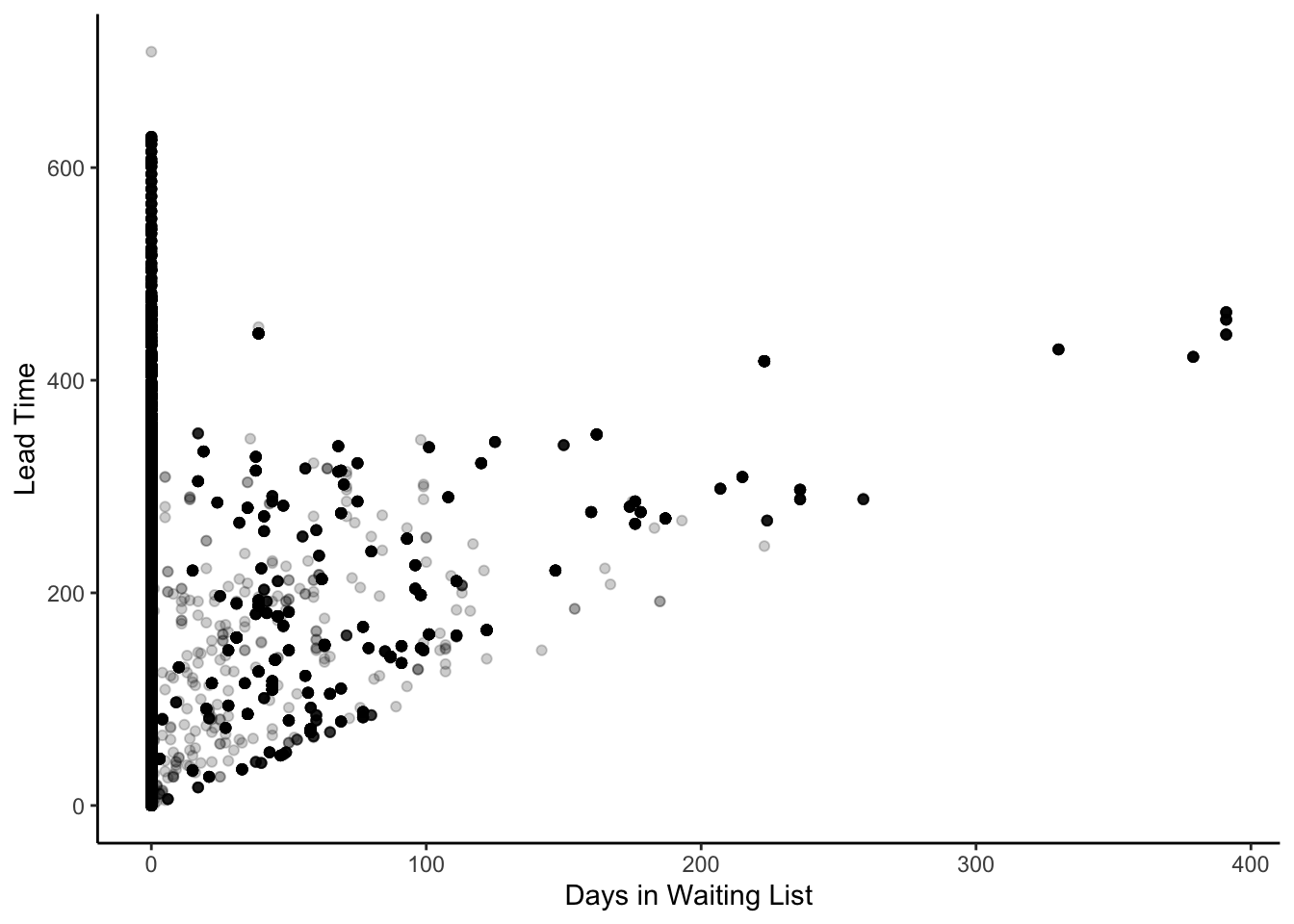
Days in waiting vs lead time: Any correlation between two quantities?
Code
ggplot(data, aes(x = days_in_waiting_list, y = lead_time)) +geom_point(alpha =0.2) +theme_classic() +labs(x ="Days in Waiting List", y ="Lead Time")
We see a roughly linear relationship between Lead Time and Days in the waiting list after a threshold of about 25 days in the waiting list. This could mean that lead time is a good predictor for wait times. Which is slightly unsettling.
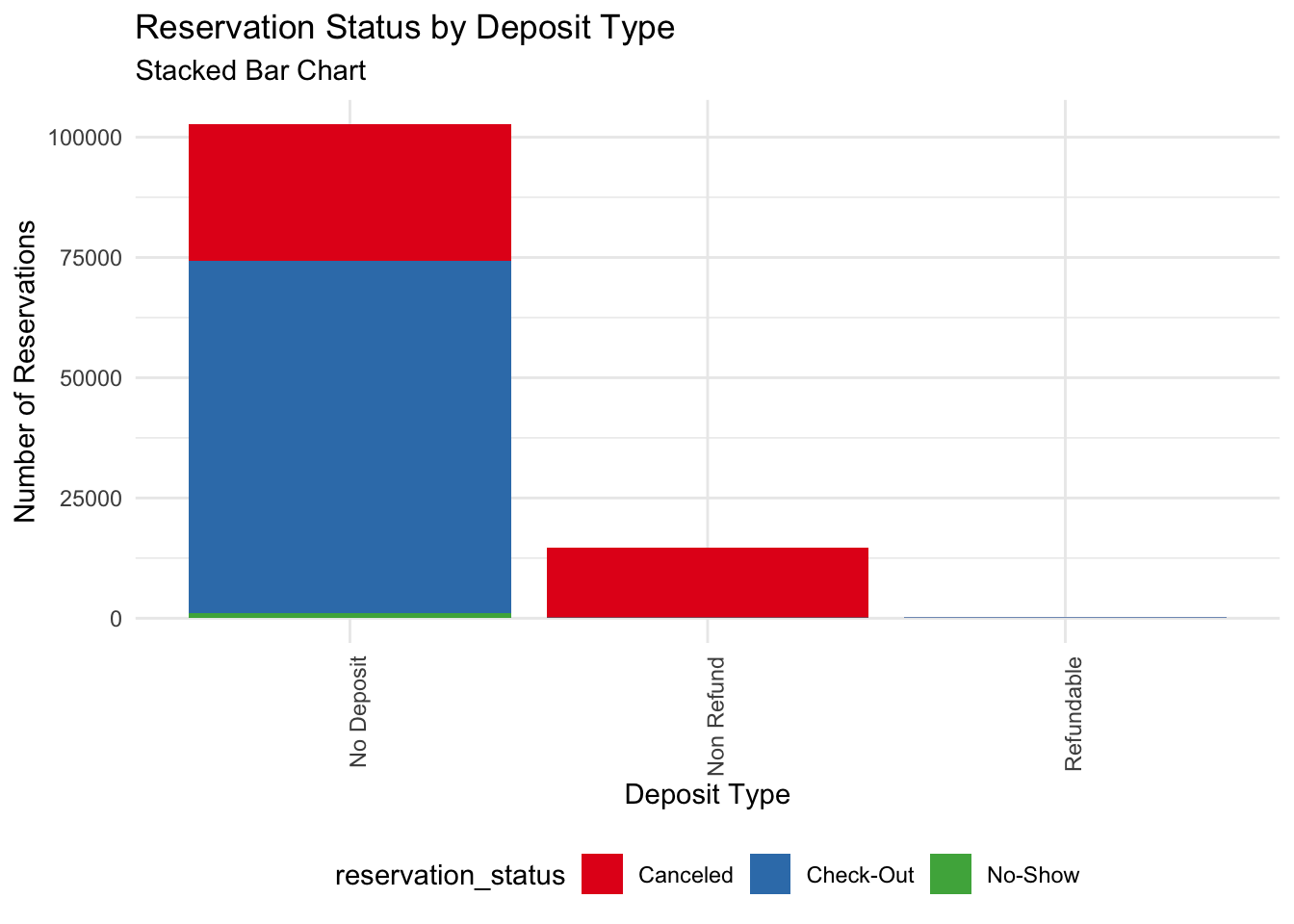
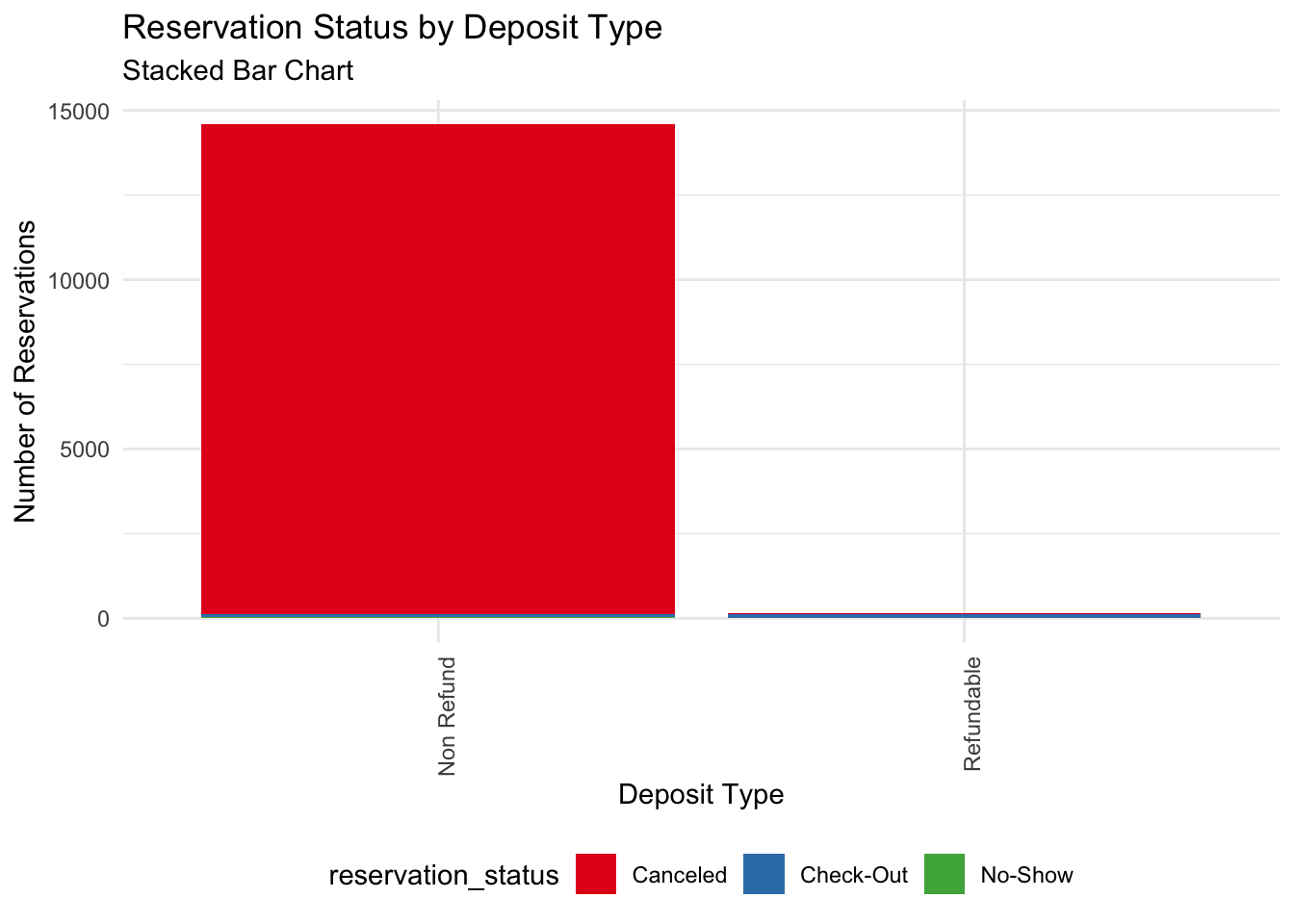
Reservation status by deposit type: Cancellations depend on refundable/non-refundable deposits?
Code
data%>%filter(arrival_date_year ==2016| arrival_date_year==2017| arrival_date_year==2015)%>%count(deposit_type, reservation_status) %>%ggplot(aes(x = deposit_type, y = n, fill = reservation_status)) +geom_col() +scale_fill_brewer(palette ="Set1") +labs(x ="Deposit Type", y ="Number of Reservations", title ="Reservation Status by Deposit Type", subtitle ="Stacked Bar Chart") +theme_minimal() +theme(axis.text.x =element_text(angle =90, hjust =1), legend.position ="bottom")
Code
data%>%filter(arrival_date_year ==2016| arrival_date_year==2017| arrival_date_year==2015)%>%filter(deposit_type !="No Deposit") %>%count(deposit_type, reservation_status) %>%ggplot(aes(x = deposit_type, y = n, fill = reservation_status)) +geom_col() +scale_fill_brewer(palette ="Set1") +labs(x ="Deposit Type", y ="Number of Reservations", title ="Reservation Status by Deposit Type", subtitle ="Stacked Bar Chart") +theme_minimal() +theme(axis.text.x =element_text(angle =90, hjust =1), legend.position ="bottom")
Inconclusive.
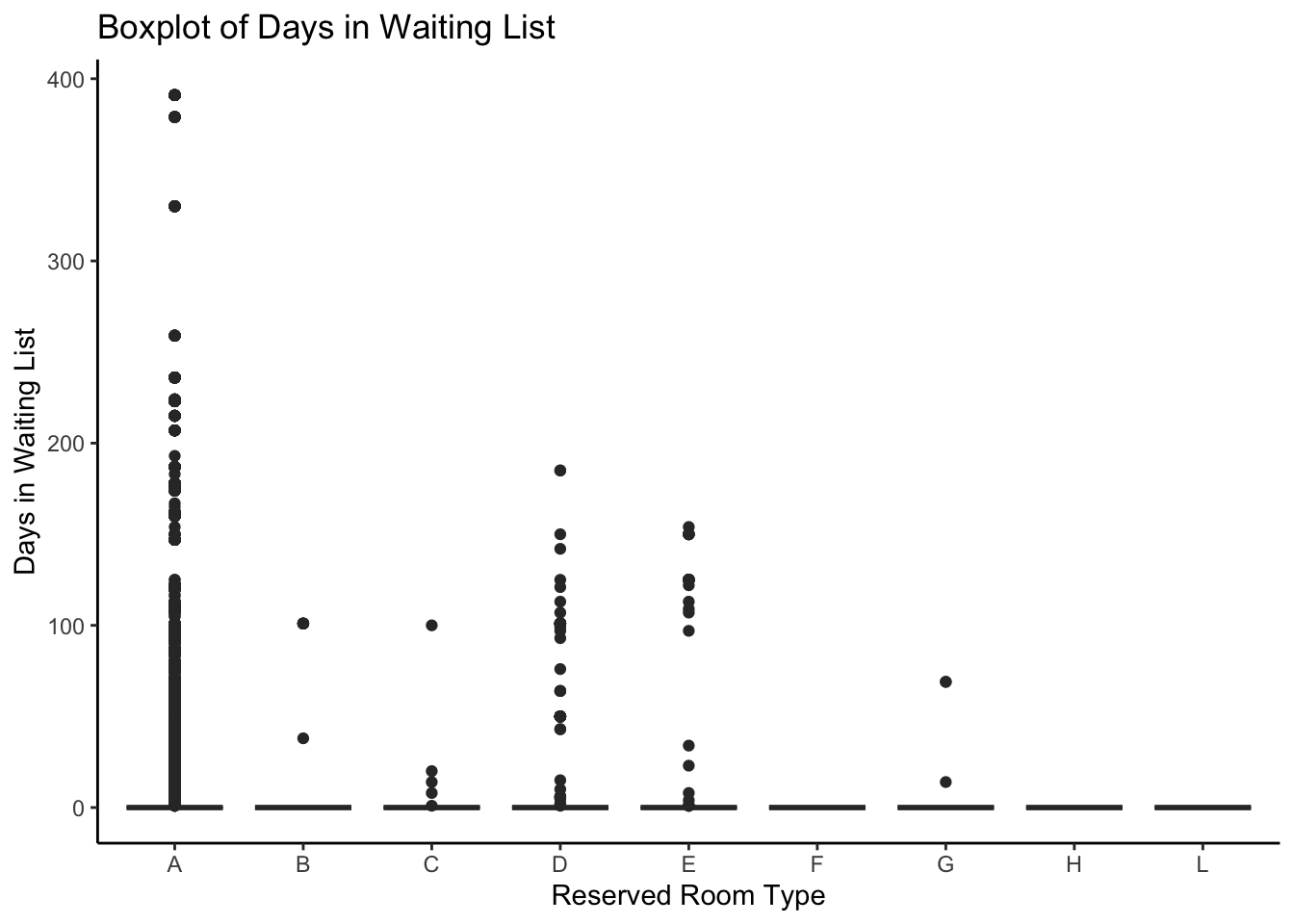
Days in the waiting list by Reserved Room type: Does the waiting time depend on the type of the room?
Code
data%>%filter(arrival_date_year ==2016| arrival_date_year==2017| arrival_date_year==2015) %>%ggplot(aes(x = reserved_room_type, y = days_in_waiting_list)) +geom_boxplot() +theme_classic() +labs(title ="Boxplot of Days in Waiting List", x ="Reserved Room Type", y ="Days in Waiting List")
We observe that room type A is the least available based on the waiting times.
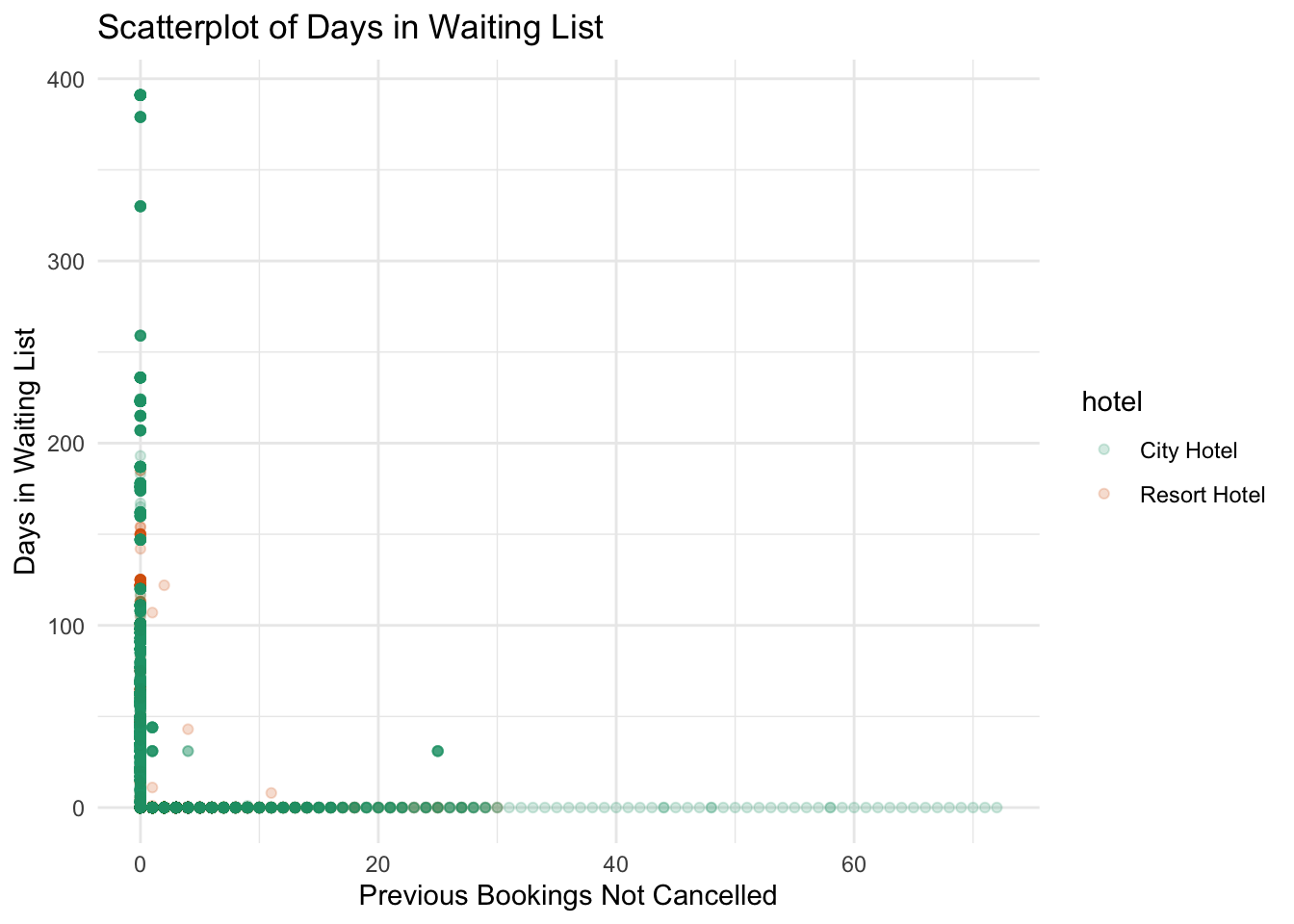
Days in waiting list vs Previous bookings not cancelled: Does a history of cancelling put you in the waiting list for longer?
Code
#Use color to add is_cancelled as a third variabledata %>%ggplot(aes(x = previous_bookings_not_canceled, y = days_in_waiting_list, color = hotel)) +geom_point(alpha =0.2) +scale_color_brewer(palette ="Dark2") +theme_minimal() +labs(title ="Scatterplot of Days in Waiting List", x ="Previous Bookings Not Cancelled", y ="Days in Waiting List")
We see that history of cancelling does put you in a position where you might have to wait longer. This could be due to the fact that availability changes as you cancel, which might put you in the waitlist for booking confirmation.
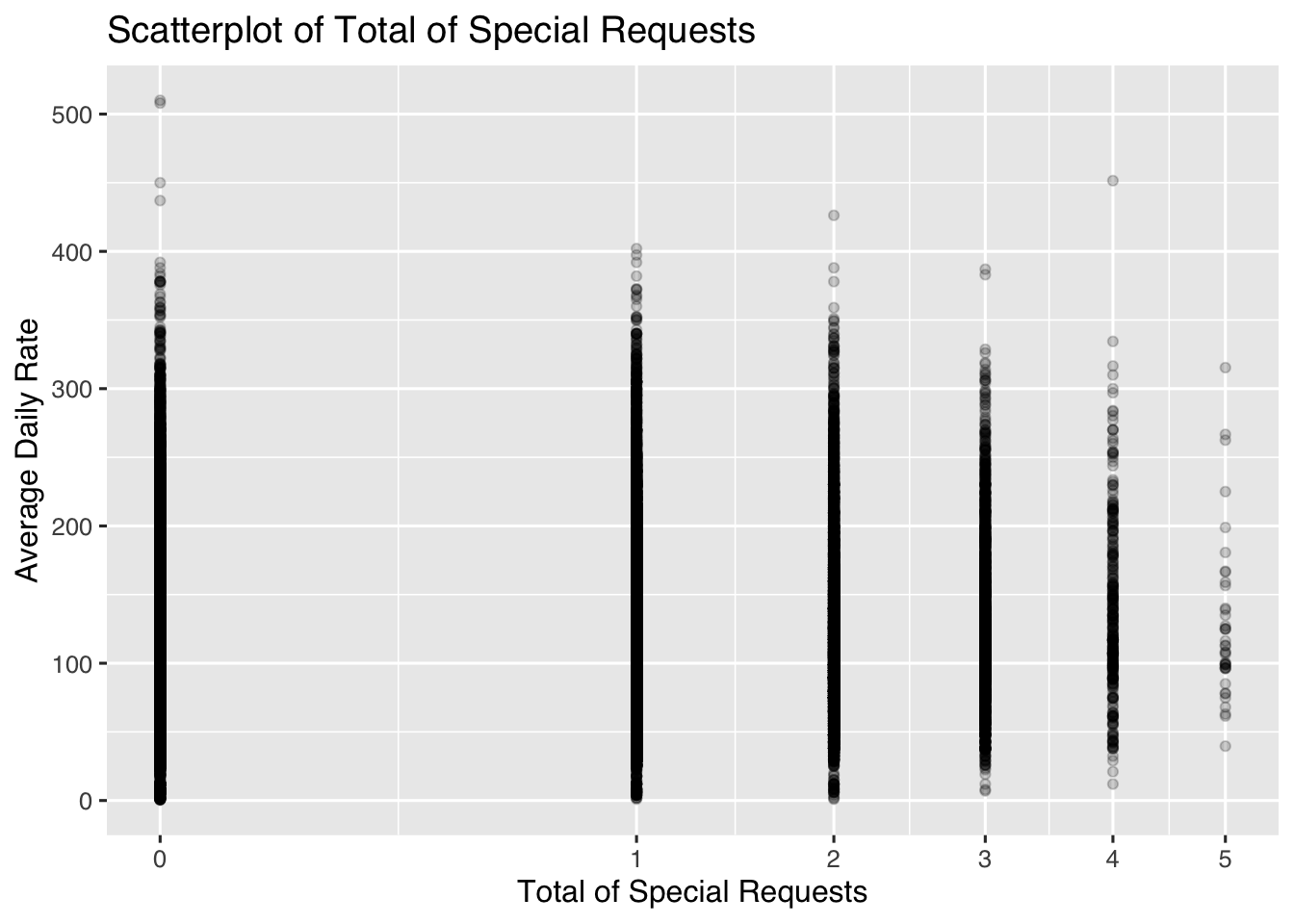
Daily Rate vs Special requests: Do people with cheaper rooms have more special requests?
Code
data %>%filter(adr<2000) %>%ggplot(aes(x = total_of_special_requests, y = adr)) +scale_x_sqrt() +geom_point(alpha =0.2) +theme_grey(base_family ="Helvetica", base_size =12) +labs(title ="Scatterplot of Total of Special Requests", x ="Total of Special Requests", y ="Average Daily Rate")
We do see a pattern that people with cheaper rooms tend to make more special requests. This could be due to inadequate facilities in their rooms and another interesting factor could be that people in more expensive rooms might be intimidated to make petty requests.
Discussion and Reflections
The hotel_bookings.csv dataset is an incredibly fun to work with dataset that is relatively pliable and it is simple to get insights from it. We saw that hotel bookings in Portugal are very dependent on the weather, and people like to travel to resorts during this time. We also saw that it’s mostly visitors in Europe that visit these hotels who tend to spend their holidays in these hotels. This also corroborates with the fact that most bookings come from travel agents and tour orders who usually book tours for holidays during the beautiful summer weather of Portugal. The marketing team should focus on business travel since that seems to be unrepresented in this data. Waiting times are very high for specific rooms like the Room A, the hotels should focus on adjusting the offerings in different types of these rooms based on the demand to minimize the waiting times. Marketing teams could charge extra for parking spots with spots that are popular for family holidays to increase revenue since there is a clear relationship between poeple traveling with kids and needing parking spots. Overall, reducing cancellations by asking for a small deposit or credit card on file, and efforts to accelerate growth across other distribution channels apart from TA/TO should be their top priorities.
I really enjoyed working with this dataset because it had a lot of entries and there are a lot of interesting relationships to observe. The data was also somewhat clean, apart from the fact that the NULL values aren’t standardized across the dataset which results in those values creeping in during analysis. Thank you!
Source Code
---title: "Final Project"author: "Tanmay Agrawal"desription: "Analyis of Hotel Bookings"date: "01/24/2023"format: html: toc: true code-fold: true code-copy: true code-tools: true df-print: pagedcategories: - final_project - hotel_bookings.csv---We first load the necessary libraries```{r}library(tidyverse)library(ggplot2)library(dplyr)library(summarytools)library(RColorBrewer)library(maps) # install.packages("maps")library(countrycode) # install.packages("countrycode")library(plotly)library(GGally)knitr::opts_chunk$set(echo =TRUE)```### Introduction`hotel_bookings.csv` is a interesting dataset because it features a rich collection of Hotel Bookings data from across the European continent (Spoiler: mostly Portugal!). It contains data from the years 2015 to 2017. This dataset has classified the data into two types of hotels, "City Hotel" and "Resort Hotel". There's various information about the attributes of the hotel, booking information including the guest demographic information, and marketing information such as marketing segments, lead time, etc.```{r}data =read_csv("_data/hotel_bookings.csv")# We inspect the columns in this dataset using the head commandhead(data)```### Cleaning the dataThe data seems relatively clean but for the purposes of analysis we can perform some baseline cleaning to the main dataset.Just visual inspection using the `head()` command can tell us a few things. We look at the first few rows of the data to get a visual outline of the dataset and we observe that columns `agent`, `company` and `country` have a lot of `NULL` values. We can use the following to get a column-wise representation of all the garbage values.```{r}data %>%summarize_all(list(~sum(is.na(.))))```We observe that only `children` column has `na` values even our manual inspection told us a different story. Let's dig in a bit more and identify why the code block above doesn't give us the expected results. We observe that the columns like `agent` and `company` have "NULL" values, but they don't show up with the method above. The challenge here is that these values are still character data types and can't be detected if we're looking for `na` or `nan` values. We can simply use the `stringr` package and calculate the percentage of "NULL" strings each column has.```{r}# we use the stringr package for thislibrary(stringr)# get the null percentagesnull_percentages <-sapply(data, function(x) sum(str_detect(x, "NULL"))/length(x))# put it into a tibble and arrange itnull_percentages_tibble <-tibble(column =names(data), null_percentage = null_percentages)null_percentages_tibble %>%arrange(desc(null_percentage))```We can see that `company`, `agent` and `country` have "NULL" strings as values which are functionally equivalent to `na` / `nan` or garbage values. Additionally, `children` has some `na` values. We can replace these strings with meaningful values.```{r}replace_garbage <-c(country ="Unknown", agent =0, company =0)# find indices that have `na`na_indices <-which(is.na(data$children))data$children[na_indices] <-0.0# Use a for loop to replace missing values in each columnfor (col innames(replace_garbage)) { data[data[,col] =="NULL", col] <- replace_garbage[col]}head(data)dim(data) # 119390x32```We can use hints from manual inspection and dig in a little more.```{r}data %>%count(meal) %>%arrange(-n)```according to the dataset description, Undefined/SC = no meal. So we can convert all the "Undefined" values to SC.```{r}data$meal <-replace(data$meal, data$meal =="Undefined", "SC")```We can also look the \# of guests in each room and see if we get some insight. Let's plot them into three bins: <1, 1-2, and >=3. We'll use a polar coordinate pie chart for this as it's easy to show the relative differences in loose self-constructed bins that way.```{r}library(dplyr)data %>%group_by(guests = adults + children + babies) %>%summarize(count =n()) %>%mutate(guests =ifelse(guests ==0, "0", ifelse(guests <=2, "1 to 2", ">=3"))) %>%ggplot(aes(x = guests, y = count, fill = guests)) +geom_bar(stat ="identity") +ggtitle("Total number of guests") +theme(plot.title =element_text(hjust =0.5)) +coord_polar("y", start =0) +scale_fill_manual(values =c("#F8766D", "#00BFC4", "#619CFF"))```We observe that there are non-zero entries in the pie with \# of `adults` + `children` + `babies` = 0. Let's get rid of those rows.```{r}data <- data %>%filter(adults !=0| children !=0| babies !=0)data <- data %>%filter(adr>0)dim(data) # 117399 x 32```### EDA: Let's explore the data a little more#### Summary of the Dataset:Let's get a sneak peak into what the data actually looks like based on some summary statistics```{r}print(dfSummary(data, style="grid", ),method ='render',table.classes ='table-condensed')```We can ask several questions right away, the most obvious ones are:#### Where do the guests come from?Since we don't know where these hotels are located, we can try to get hints from the guests that visit these hotels. Let's plot them on a pie chart and check what countries are represented in this data. We will filter out countries with less than 2% representation.```{r}# get number of guests by country who haven't cancelledcountry_data <- data %>%mutate(country =countrycode(country, origin ="iso3c", destination ="country.name", origin_regex =TRUE))%>%filter(is_canceled ==0) %>%group_by(country) %>%summarise(number_of_guests =n()) %>%ungroup()# calculate the percentage of guests by countrytotal_guests <-sum(country_data$number_of_guests)country_data$Guests_in_percent <-round(country_data$number_of_guests / total_guests *100, 2)# group countries with less representationcountry_data$country <-ifelse(country_data$Guests_in_percent <2, "Other", country_data$country)colors <-c("#999999", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7", "magenta", "pink")country_data %>%filter(country !="Other") %>%ggplot(aes(x ="", y = number_of_guests, fill = country)) +geom_bar(width =1, stat ="identity") +ggtitle("Home country of guests") +coord_polar(theta ="y") +scale_fill_manual(values = colors) +labs(x =NULL, y ="Number of guests") +theme_classic() +theme(legend.title =element_blank(),plot.title =element_text(hjust =0.5, size =14, face ="bold"),axis.text =element_blank(),axis.ticks =element_blank(),axis.line =element_blank(),plot.background =element_rect(fill ="white"),panel.grid =element_blank())country_data %>%filter(country !="Other") %>%ggplot(aes(x =reorder(country, Guests_in_percent), y = Guests_in_percent, fill = Guests_in_percent)) +geom_bar(stat ="identity") +scale_fill_gradient(low ="blue", high ="red", name ="Guests in %") +theme(axis.text.x =element_text(angle =90, hjust =1),axis.title.x =element_text(size =14),axis.title.y =element_text(size =14),axis.text.y =element_text(size =12),plot.title =element_text(size =20, hjust =0.5),panel.grid =element_blank(),panel.background =element_rect(fill ="aliceblue"),legend.title =element_text(size =14),legend.text =element_text(size =12)) +labs(x ="Country", y ="Guests in %", title ="Home country of guests")```We observe that Portugal and the UK are the countries that are over represented in this data. Which could mean that the hotels are close to those two countries and likely in Europe. It's a reasonable guess that hotels are from a chain that's located in Portugal.Let's look at the dataset in detail and try to draw inferences from them.### Prices of Rooms per night: AnalysisAnother question to ask is how much does it cost to stay in these hotels? Does it change by the type of hotel?Let's wrangle some data first. We normalize the `adr` i.e. the average daily rate such that we get `adr_norm` which is the daily rate per person.```{r}data$adr_norm <- data$adr / (data$adults + data$children)data_uncancelled <- data[data$is_canceled ==0, ] # the ones didn't cancelroom_prices <- data_uncancelled[, c("hotel", "reserved_room_type", "adr_norm", "adr")][order(data_uncancelled$reserved_room_type), ]```#### Room price per night and person over the year```{r}# grab data:room_prices_monthly <- data_uncancelled[c("hotel", "arrival_date_month", "adr_norm")][order(data_uncancelled$arrival_date_month),]# order by month:months <-c("January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December")room_prices_monthly$arrival_date_month <-factor(room_prices_monthly$arrival_date_month, levels=months, ordered=TRUE)room_prices_monthly_agg <- room_prices_monthly %>%group_by(hotel, arrival_date_month) %>%summarise(adr_norm =mean(adr_norm))ggplot(data = room_prices_monthly_agg, aes(x = arrival_date_month, y = adr_norm, color =`hotel`, group =`hotel`)) +geom_line() +geom_point() +geom_ribbon(aes(ymin = adr_norm -sd(adr_norm), ymax = adr_norm +sd(adr_norm)), alpha =0.2) +ggtitle("Room price per night and person over the year", subtitle ="With standard deviation") +xlab("Month") +ylab("Price [EUR]") +theme(axis.text.x =element_text(angle =45, hjust =1),plot.title =element_text(size =16), axis.text =element_text(size =16),axis.title =element_text(size =16))ggplot(data = room_prices_monthly_agg, aes(x = arrival_date_month, y = adr_norm, fill = hotel)) +geom_col() +xlab("Month") +ylab("Price [EUR]") +theme(axis.text.x =element_text(angle =45, hjust =1),plot.title =element_text(size =16), axis.text =element_text(size =16),axis.title =element_text(size =16))# Average daily rate by Hotel Typeggplot(data_uncancelled, aes(x = adr, fill = hotel, color = hotel)) +geom_histogram(aes(y =after_stat(density)), position =position_dodge(), binwidth =20 ) +geom_density(alpha =0.2) +labs(title ="Average Daily rate by Hotel Type",x ="Hotel Price(in Euro)",y ="Count") +scale_color_brewer(palette ="Paired") +theme_classic() +theme(legend.position ="top")```An interesting observation is that resorts tend to be expensive over the summers while hotels tend to be cheaper. This also makes sense intuitively. We also see that during the summers, resorts get more expensive as compared to the city hotels. This could be due to the demand for resorts and sea-side, leisurely locations during holidays, vacations or just because the guests want to enjoy the beautiful weather.#### Room price per night and person by Room TypeIt's another interesting question to ask, do the guests pay differently based on the types of the rooms they choose? For instance, rooms```{r}ggplot(room_prices, aes(x = reserved_room_type, y = adr, color = hotel)) +geom_boxplot(outlier.size =0) +scale_color_discrete(limits =c("City Hotel", "Resort Hotel")) +labs(title ="Price of room types per night",x ="Room type",y ="Price [EUR]") +theme(legend.position ="top") +scale_y_continuous(limits =c(0, 160))ggplot(room_prices, aes(x = reserved_room_type, y = adr_norm, color = hotel)) +geom_boxplot(outlier.size =0) +scale_color_discrete(limits =c("City Hotel", "Resort Hotel")) +labs(title ="Price of room types per night and person",x ="Room type",y ="Price [EUR]") +theme(legend.position ="top") +scale_y_continuous(limits =c(0, 160))```This plot tells us that the data might be such that the room types might not be same across each hotel when we look at the overall price of a room, but it looks to normalize when we adjust for the number of people staying in that room.#### Room price based on the type of customer```{r}ggplot(data_uncancelled, aes(x = customer_type, y = adr, fill = hotel)) +geom_boxplot(position =position_dodge()) +labs(title ="Price Charged by Hotel Type",subtitle ="by Customer Type",x ="Customer Type",y ="Price per night(in Euro)") +theme_classic()```We can see that Contract and Group prices are more consolidated and generally lower than Transient and Transient-Party. This could be because contracts are pre-negotiated and Group bookings come with discounts.### How long do the guests stay?```{r}# Total Stay Durationggplot(data_uncancelled, aes(stays_in_weekend_nights + stays_in_week_nights)) +geom_density(col ="red") +facet_wrap(~hotel) +theme_bw()# A closer look after removing the outliersdata_uncancelled %>%filter(stays_in_weekend_nights + stays_in_week_nights <15) %>%ggplot(aes(stays_in_weekend_nights + stays_in_week_nights)) +geom_density(col ="red") +facet_wrap(~hotel) +theme_bw()```### What type of customer prefers which kind of hotel?```{r}ggplot(data_uncancelled, aes(customer_type, fill = hotel)) +geom_bar(stat ="count", position =position_dodge()) +labs(title ="Hotel Preference by Customer Type",x ="Customer Type",y ="Count") +theme(axis.text.x =element_text(angle =90, hjust =1),panel.background =element_blank())```It's interesting to see that Contract customers categorically prefer Resorts over City hotels, while transients prefer city hotels which makes sense.### Analysis of the Marketing Data:A good question to ask here would be, which market segment is popular and which group should the hotel focus on more?```{r}ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = distribution_channel), color ="black", stat ="count") +labs(title ="Comparison of Distribution Channel", subtitle ="Number of transactions in each channel", x ="Distribution Channel", y ="Number of Transactions") +scale_fill_brewer(type ="qual", palette ="Set1") +theme_classic() +theme(plot.title =element_text(size =18, face ="bold"),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12),legend.title =element_text(size =14, face ="bold"),legend.text =element_text(size =12),legend.position ="bottom") +coord_flip()```TA is the identifier for "Travel Agents" and TO for "Tour Operators"TA/TO gets the most number of bookings when compared to corporate, direct, and GDS.```{r}# Segment the bar chart group by "deposit_type"ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = deposit_type), color ="black", stat ="count") +labs(title ="Comparison of Distribution Channel", subtitle ="Segmented by Deposit Type", x ="Distribution Channel", y ="Deposit Type") +scale_fill_brewer(type ="qual", palette ="Set2") +theme_classic() +theme(plot.title =element_text(size =18, face ="bold"),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12),legend.title =element_text(size =14, face ="bold"),legend.text =element_text(size =12),legend.position ="bottom") +coord_flip()```Not many people prefer depositing money before booking across all of the distribution channels, and the highest numbers of booking come from the channel, TA/TO which refers to the Travel Agents.We can now look at the relationship between market segment and the distribution channel to understand what segments are targeted by which channels```{r}ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = market_segment)) +labs(title ="Comparison of Distribution Channel", subtitle ="Group By Market Segment", x ="Distribution Channel", y ="Deposit Type") +scale_fill_brewer(type ="qual", palette ="Set2") +theme_classic() +theme(plot.title =element_text(size =18, face ="bold"),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12),legend.title =element_text(size =14, face ="bold"),legend.text =element_text(size =12),legend.position ="bottom") +coord_flip()```Online Travel Agencies bring the most number of bookings follwed by offline, group bookings and direct bookings.We can use facets to separate chart by deposit type and market segment to get a better understanding...```{r}ggplot(data = data) +geom_bar(mapping =aes(x = distribution_channel, fill = distribution_channel), position ="dodge", stat ="count") +scale_fill_brewer(palette ="Dark2") +labs(title ="Comparison of Three Types of Deposit", subtitle ="Values Showed By Distribution Channel",x ="Distribution Channel",y ="Count of Transactions") +facet_wrap(~deposit_type, ncol =2) +theme(plot.title =element_text(size =16, face ="bold"),plot.subtitle =element_text(size =8),axis.title =element_text(size =14),axis.text =element_text(size =8),legend.text =element_text(size =8),strip.text =element_text(size =12),strip.background =element_rect(fill ="gray95", color ="gray20"))```Unfortunately, this chart doesn't tell us much.### Effect of Family size on lead time:```{r}# Show the correlation between booking's lead time and guests who bring their childrenggplot(data = data, aes(x = lead_time, y = children)) +geom_point(shape =21, size =1, fill ="pink", color ="darkblue") +labs(title ="Correlation between Lead Time and Number of Children",subtitle ="Lead Time vs Number of Children",x ="Lead Time (in days)",y ="Number of Children") +scale_x_continuous(limits =c(0, max(data$lead_time) +20), expand =c(0,0)) +scale_y_continuous(limits =c(0, max(data$children) +0.5), expand =c(0,0)) +theme_classic() +theme(plot.title =element_text(size =16, hjust =0.5, face ="bold"),plot.subtitle =element_text(size =12, hjust =0.5),axis.title =element_text(size =14, face ="bold"),axis.text =element_text(size =12))```We see shorter lead times for guests with fewer children, it's unclear as to why this would happen but I have a hypothesis that it's harder to make plans when there are children involved since the schedules have to align with their school schedules. People without children might also be people who aren't traveling for leisure so their bookings are well planned in advance.```{r}ggplot(data = data) +geom_bar(mapping =aes(x = hotel, fill = market_segment)) +labs(title ="Hotel Type preferences", subtitle ="by Market Segment") +scale_fill_brewer(palette ="Paired") +theme(plot.title =element_text(size =16, face ="bold"),plot.subtitle =element_text(size =14),axis.title.x =element_text(size =14),axis.title.y =element_text(size =14),legend.title =element_text(size =14),legend.text =element_text(size =12))```At a glance, City Hotel is the most hotel type chosen by the guest and the Online Travel Agent is the biggest segment in both types of hotel.#### Relationship between parking spaces and Family size (multivariate analysis)```{r}hotel_stays <- data %>%mutate(country =countrycode(country, origin ="iso3c", destination ="country.name", origin_regex =TRUE))%>%filter(is_canceled ==0) %>%mutate(children =case_when( children + babies >0~"children",TRUE~"none" ),required_car_parking_spaces =case_when( required_car_parking_spaces >0~"parking",TRUE~"none" ) )#%>%#select(-is_canceled, -reservation_status, -babies)hotel_stays %>%count(hotel, required_car_parking_spaces, children) %>%group_by(hotel, children) %>%mutate(proportion = n /sum(n)) %>%ggplot(aes(required_car_parking_spaces, proportion, fill = children)) +geom_col(position ="dodge") +scale_y_continuous(labels = scales::percent_format()) +facet_wrap(~hotel, nrow =2) +labs(x =NULL,y ="Proportion of hotel stays",fill =NULL )```It's clear that across both the hotel types, guests with no children require less parking spots. Which means these two variables are tied closely.### Other AnalysisThis part of the report contains plots for exploring all of the interesting variables to so that we have as much information as we can to draw the inferences at the end.#### Special requests vs. Previous booking not cancelled: are people who cancel a lot more prone to making special requests?```{r}data %>%ggplot(aes(x = total_of_special_requests, y = previous_bookings_not_canceled)) +geom_point(alpha =0.3)```We don't see a clear pattern here.#### Histogram of lead time```{r}ggplot(data, aes(x = lead_time)) +geom_histogram(binwidth =10) +scale_x_continuous(limits =c(0, 100))```#### Relationship between customer type and how much they pay```{r}hotel_stays %>%select( hotel, adr, customer_type, total_of_special_requests ) %>%ggpairs(mapping =aes(color = customer_type))```We observe a weak correlation between these attributes, inconclusive.#### Days in waiting vs lead time: Any correlation between two quantities?```{r}ggplot(data, aes(x = days_in_waiting_list, y = lead_time)) +geom_point(alpha =0.2) +theme_classic() +labs(x ="Days in Waiting List", y ="Lead Time")```We see a roughly linear relationship between Lead Time and Days in the waiting list after a threshold of about 25 days in the waiting list. This could mean that lead time is a good predictor for wait times. Which is slightly unsettling.#### Reservation status by deposit type: Cancellations depend on refundable/non-refundable deposits?```{r}data%>%filter(arrival_date_year ==2016| arrival_date_year==2017| arrival_date_year==2015)%>%count(deposit_type, reservation_status) %>%ggplot(aes(x = deposit_type, y = n, fill = reservation_status)) +geom_col() +scale_fill_brewer(palette ="Set1") +labs(x ="Deposit Type", y ="Number of Reservations", title ="Reservation Status by Deposit Type", subtitle ="Stacked Bar Chart") +theme_minimal() +theme(axis.text.x =element_text(angle =90, hjust =1), legend.position ="bottom")data%>%filter(arrival_date_year ==2016| arrival_date_year==2017| arrival_date_year==2015)%>%filter(deposit_type !="No Deposit") %>%count(deposit_type, reservation_status) %>%ggplot(aes(x = deposit_type, y = n, fill = reservation_status)) +geom_col() +scale_fill_brewer(palette ="Set1") +labs(x ="Deposit Type", y ="Number of Reservations", title ="Reservation Status by Deposit Type", subtitle ="Stacked Bar Chart") +theme_minimal() +theme(axis.text.x =element_text(angle =90, hjust =1), legend.position ="bottom")```Inconclusive.#### Days in the waiting list by Reserved Room type: Does the waiting time depend on the type of the room?```{r}data%>%filter(arrival_date_year ==2016| arrival_date_year==2017| arrival_date_year==2015) %>%ggplot(aes(x = reserved_room_type, y = days_in_waiting_list)) +geom_boxplot() +theme_classic() +labs(title ="Boxplot of Days in Waiting List", x ="Reserved Room Type", y ="Days in Waiting List")```We observe that room type A is the least available based on the waiting times.#### Days in waiting list vs Previous bookings not cancelled: Does a history of cancelling put you in the waiting list for longer?```{r}#Use color to add is_cancelled as a third variabledata %>%ggplot(aes(x = previous_bookings_not_canceled, y = days_in_waiting_list, color = hotel)) +geom_point(alpha =0.2) +scale_color_brewer(palette ="Dark2") +theme_minimal() +labs(title ="Scatterplot of Days in Waiting List", x ="Previous Bookings Not Cancelled", y ="Days in Waiting List")```We see that history of cancelling does put you in a position where you might have to wait longer. This could be due to the fact that availability changes as you cancel, which might put you in the waitlist for booking confirmation.#### Daily Rate vs Special requests: Do people with cheaper rooms have more special requests?```{r}data %>%filter(adr<2000) %>%ggplot(aes(x = total_of_special_requests, y = adr)) +scale_x_sqrt() +geom_point(alpha =0.2) +theme_grey(base_family ="Helvetica", base_size =12) +labs(title ="Scatterplot of Total of Special Requests", x ="Total of Special Requests", y ="Average Daily Rate")```We do see a pattern that people with cheaper rooms tend to make more special requests. This could be due to inadequate facilities in their rooms and another interesting factor could be that people in more expensive rooms might be intimidated to make petty requests.### Discussion and ReflectionsThe `hotel_bookings.csv` dataset is an incredibly fun to work with dataset that is relatively pliable and it is simple to get insights from it. We saw that hotel bookings in Portugal are very dependent on the [weather](https://www.metoffice.gov.uk/weather/travel/holiday-weather/europe/portugal), and people like to travel to resorts during this time. We also saw that it's mostly visitors in Europe that visit these hotels who tend to spend their holidays in these hotels. This also corroborates with the fact that most bookings come from travel agents and tour orders who usually book tours for holidays during the beautiful summer weather of Portugal. The marketing team should focus on business travel since that seems to be unrepresented in this data. Waiting times are very high for specific rooms like the Room A, the hotels should focus on adjusting the offerings in different types of these rooms based on the demand to minimize the waiting times. Marketing teams could charge extra for parking spots with spots that are popular for family holidays to increase revenue since there is a clear relationship between poeple traveling with kids and needing parking spots. Overall, reducing cancellations by asking for a small deposit or credit card on file, and efforts to accelerate growth across other distribution channels apart from TA/TO should be their top priorities.I really enjoyed working with this dataset because it had a lot of entries and there are a lot of interesting relationships to observe. The data was also somewhat clean, apart from the fact that the NULL values aren't standardized across the dataset which results in those values creeping in during analysis. Thank you!