With climate change upsetting normal weather patterns, there has been exciting research into how precipitation shocks (flooding and drought events) impact health outcomes, (Rizmie, d., Preuz, L, Miraldo, M. & Atun, R. (2022); Tapak, L., Maryanaji, Z., Hamidi, O., Abbasi, H. & Najafi-Vosough, R. (2018); Trinh, T., Feeny, S. & Posso, A. (2018)). Alongside this train of thought, multiple research reports state that there is a relationship between re-hospitalization rates and social characteristics, such as demographic and economic identifiers, (Barnett, Hsu & McWilliams, 2015; Murray, Allen, Clark, Daly & Jacobs, 2021). Specifically, racial characteristics play a large role in predicting re-hospitalization in a population (Li, Cai & Glance, 2015). While some articles examine economic and health factors contributing to these disparities, very few dig deep into environmental factors that influence this phenomenon, (Spatz, Bernheim, Horwitz & Herrin, 2020). With your zipcode affecting up to 60% of your health outcomes, this research is relevant to better improving one of our most costly health expenditures: hospitalization. Therefore, this research report aims to integrate these two concepts, testing if precipitation shocks have a positive relationship on not just hospital admissions but also re-admissions.
Re-hospitalization is a substantially costlier expenditure, as readmitting a patient further increases costs – especially if the diagnosis was untreated, poorly treated, or incorrectly treated. Most inpatient episodes characterized as a re-hospitalization when the patient is readmitted to the hospital 60 days after discharge. If the cause is different, sometimes that is counted as a re-hospitalization; other times, not so much, (Bhosale, K., Nath, R., Pandit, N., Agarwal, P., Khairnar, S., Yadav, B. & Chandrakar, S., 2020).
Research Question
This paper aims to explore how precipitation shocks impact re-hospitalization rates on a county-by-county level. We will control for socio-demographic and economic variables. We will also stratify by rural/urban classification, to determine if counties above or below 250,000 population experience differences in re-hospitalization rates, dependent upon these explanatory variables. This is purely because literature shows that rural communities face more acute and poorer health outcomes.
The data-set chosen for this analysis is taken from the Agency for Healthcare Research and Quality, Social Determinants of Health (SDOH) Database. This data-set has over 1,400 variables to explore each SDOH domain: social context, economic context, education, healthcare, and the environment. We shall pull data from three of these five domains: social, economic, and environmental.
How re-hospitalization is measured is not clarified per this data-set’s codebook. However, the Center for Medicare and Medicaid (CMS) 30-day Risk-Standardized Readmission Rate (RSRR) measures re-hospitalization as an unplanned readmission to inpatient services. It does stratify and specify based upon diagnosis. As the AHRQ is a federal agency alongside CMS, it is likely that they are pulling from CMS for this measure and aggregating various diagnoses into one county rate.
Hypothesis
The hypothesis for this research report is:
Precipitation has a positive impact on re-hospitalization rates within rural counties.
Therefore, the null hypothesis is:
Precipitation does not have a positive impact on re-hospitalization rates within rural counties.
Various regression models shall be employed to determine the relationship – or lack thereof – between these variables.
First I’ll import the relevant librarie and set up a UMass color scheme for crimson and black.
Then I’ll import the dataset and view the first six rows.
Out of 1400+ variables, we’ve whittled them down to 20. Of those 20, we have four (4) that are unique identifiers (FIPS, State, County, and Rural-Urban Continuation Code), ten (10) socio-demographic, four (4) economic, one (1) for precipitation, and one (1) for re-hospitalization.
Before we launch into exploring these variables via descriptive statistics, first we need to determine where the NAs are and see if any of the variables will have a substantial amount of missing data.
Code
kable(colSums(is.na(df_new)))
x
COUNTYFIPS
0
STATE
0
COUNTY
0
AHRF_USDA_RUCC_2013
9
NOAAC_PRECIPITATION_AVG_YEARLY
123
ACS_PCT_MALE
8
ACS_PCT_FEMALE
8
ACS_PCT_AIAN
8
ACS_PCT_ASIAN
8
ACS_PCT_BLACK
8
ACS_PCT_HISPANIC
8
ACS_PCT_MULT_RACE
8
ACS_PCT_NHPI
8
ACS_PCT_OTHER_RACE
8
ACS_PCT_WHITE
8
SAIPE_MEDIAN_HH_INCOME
87
SAIPE_PCT_POV
87
ACS_PCT_COMMT_60MINUP
8
ACS_PCT_RENTER_HU_COST_50PCT
8
LTC_AVG_OBS_REHOSP_RATE
410
Plenty of variables with missing data. The most concerning is – of course – our outcome variable, Re-Hospitalization Rates. This is not ideal. However, 410 / 3229 (12.6%) is not bad. That still leaves us with plenty of counties to review.
This next step will conver the Rural-Urban Continuum Code to a binary Rural/Urban. If the county is coded as a four (4) or higher, then they are classified as rural, non-metro, having a population of less than 250,000 as defined by USDA as “Rural.”
For our preliminary analysis, we’re going to provide summary statistics analyzing the variables relevant to our research question, excluding the socio-demographic control variables, and a visualization for each.
Code
kable(describe(df_new))
vars
n
mean
sd
median
trimmed
mad
min
max
range
skew
kurtosis
se
COUNTYFIPS*
1
2814
1.407500e+03
8.124762e+02
1407.50000
1.407500e+03
1043.009100
1.000000e+00
2814.000
2.813000e+03
0.0000000
-1.2012794
15.3161135
STATE*
2
2814
2.442928e+01
1.359471e+01
23.00000
2.441874e+01
16.308600
1.000000e+00
48.000
4.700000e+01
0.0584273
-1.2662366
0.2562759
COUNTY*
3
2814
8.369058e+02
4.694846e+02
831.50000
8.339405e+02
584.885700
1.000000e+00
1674.000
1.673000e+03
0.0526568
-1.1127220
8.8503264
AHRF_USDA_RUCC_2013*
4
2814
4.772210e+00
2.619826e+00
6.00000
4.717140e+00
2.965200
1.000000e+00
9.000
8.000000e+00
0.0039932
-1.2985960
0.0493867
NOAAC_PRECIPITATION_AVG_YEARLY
5
2814
3.611196e+00
1.628908e+00
3.62375
3.638924e+00
1.887844
2.241667e-01
9.745
9.520833e+00
-0.0899446
-0.7490480
0.0307068
ACS_PCT_MALE
6
2814
4.994695e+01
2.242017e+00
49.57000
4.966734e+01
1.171254
4.319000e+01
69.540
2.635000e+01
2.8174177
14.3096504
0.0422646
ACS_PCT_FEMALE
7
2814
5.005306e+01
2.242020e+00
50.43000
5.033267e+01
1.171254
3.046000e+01
56.810
2.635000e+01
-2.8174100
14.3095899
0.0422647
ACS_PCT_AIAN
8
2814
1.396734e+00
5.115499e+00
0.32000
4.677753e-01
0.326172
0.000000e+00
76.740
7.674000e+01
9.0423583
99.6407741
0.0964331
ACS_PCT_ASIAN
9
2814
1.394538e+00
2.540860e+00
0.66000
8.754218e-01
0.652344
0.000000e+00
37.670
3.767000e+01
6.0286489
53.6120545
0.0478982
ACS_PCT_BLACK
10
2814
9.453362e+00
1.460088e+01
2.63000
6.009964e+00
3.350676
0.000000e+00
87.790
8.779000e+01
2.2444231
5.0398860
0.2752434
ACS_PCT_HISPANIC
11
2814
9.176947e+00
1.321884e+01
4.27500
6.063504e+00
3.669435
0.000000e+00
98.900
9.890000e+01
3.1611507
11.8393833
0.2491905
ACS_PCT_MULT_RACE
12
2814
3.413696e+00
2.268010e+00
2.85500
3.082020e+00
1.638273
0.000000e+00
18.860
1.886000e+01
1.7825475
4.7682557
0.0427546
ACS_PCT_NHPI
13
2814
7.894460e-02
1.933154e-01
0.02000
3.630110e-02
0.029652
0.000000e+00
3.820
3.820000e+00
7.0468064
84.3573375
0.0036442
ACS_PCT_OTHER_RACE
14
2814
2.127616e+00
3.404236e+00
1.05000
1.416137e+00
1.156428
0.000000e+00
43.910
4.391000e+01
4.7889038
34.3014627
0.0641738
ACS_PCT_WHITE
15
2814
8.213514e+01
1.606041e+01
88.06500
8.489697e+01
11.052783
1.114000e+01
99.150
8.801000e+01
-1.5233572
2.1283704
0.3027572
SAIPE_MEDIAN_HH_INCOME
16
2814
5.738628e+04
1.442985e+04
55107.00000
5.584910e+04
11735.520300
2.599700e+04
155362.000
1.293650e+05
1.4172637
3.6789671
272.0193680
SAIPE_PCT_POV
17
2814
1.371606e+01
5.320367e+00
12.80000
1.323637e+01
4.744320
3.000000e+00
39.600
3.660000e+01
1.0397109
1.6688697
0.1002951
ACS_PCT_COMMT_60MINUP
18
2814
8.155924e+00
4.864799e+00
6.85500
7.487016e+00
3.810282
0.000000e+00
35.910
3.591000e+01
1.5015546
3.0016425
0.0917071
ACS_PCT_RENTER_HU_COST_50PCT
19
2814
2.060974e+01
6.649144e+00
20.78000
2.057608e+01
6.093486
0.000000e+00
49.260
4.926000e+01
0.1136840
0.5492796
0.1253440
LTC_AVG_OBS_REHOSP_RATE
20
2814
1.449645e-01
8.432610e-02
0.14000
1.422425e-01
0.059304
0.000000e+00
1.000
1.000000e+00
1.6404370
12.5443704
0.0015896
Rurality*
21
2814
1.393390e+00
4.885890e-01
1.00000
1.366785e+00
0.000000
1.000000e+00
2.000
1.000000e+00
0.4362437
-1.8103344
0.0092105
Following this, we’re going to stratify each variable by rurality and determine either the difference in distribution (histogram) and/or central tendency (boxplot).
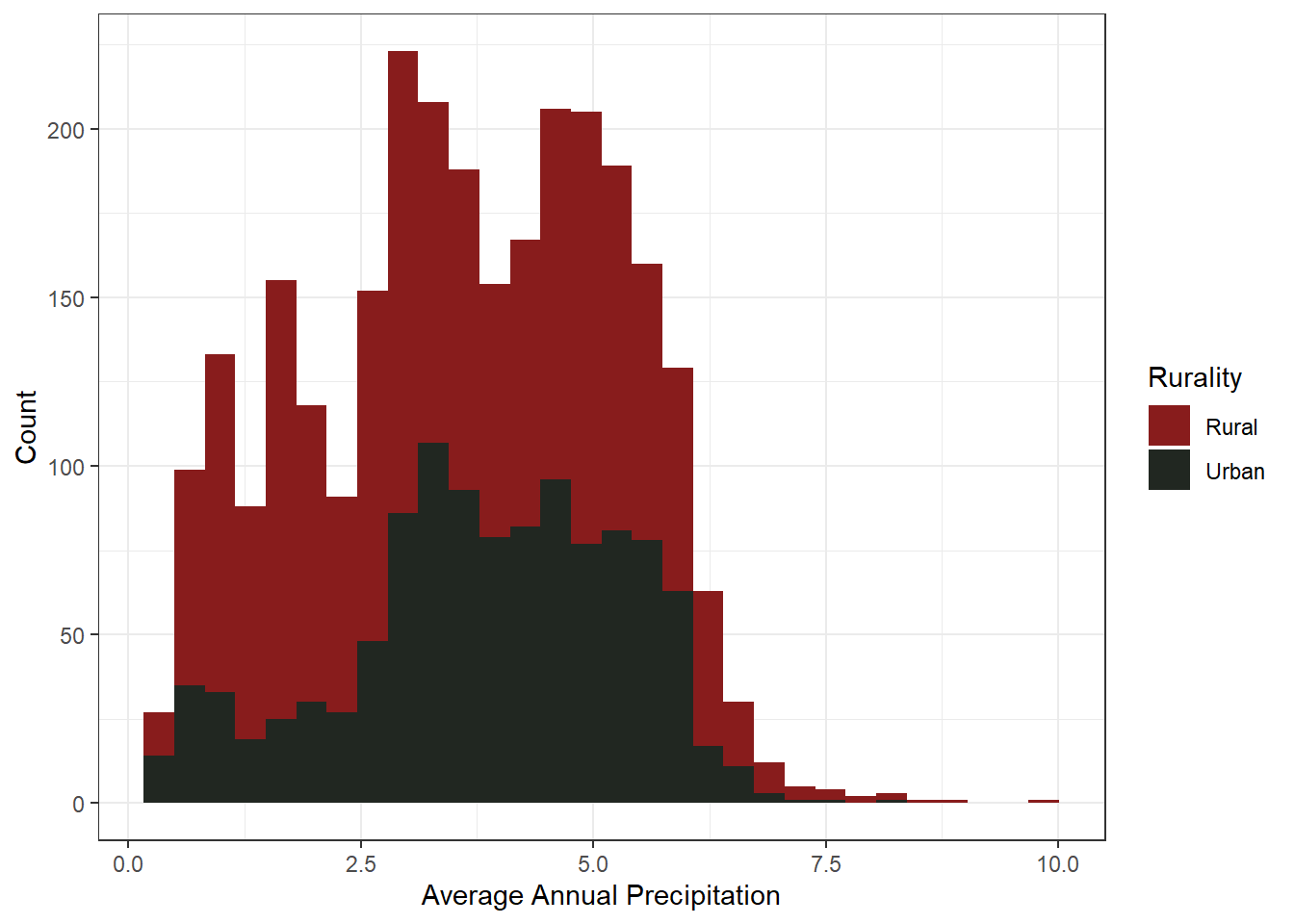
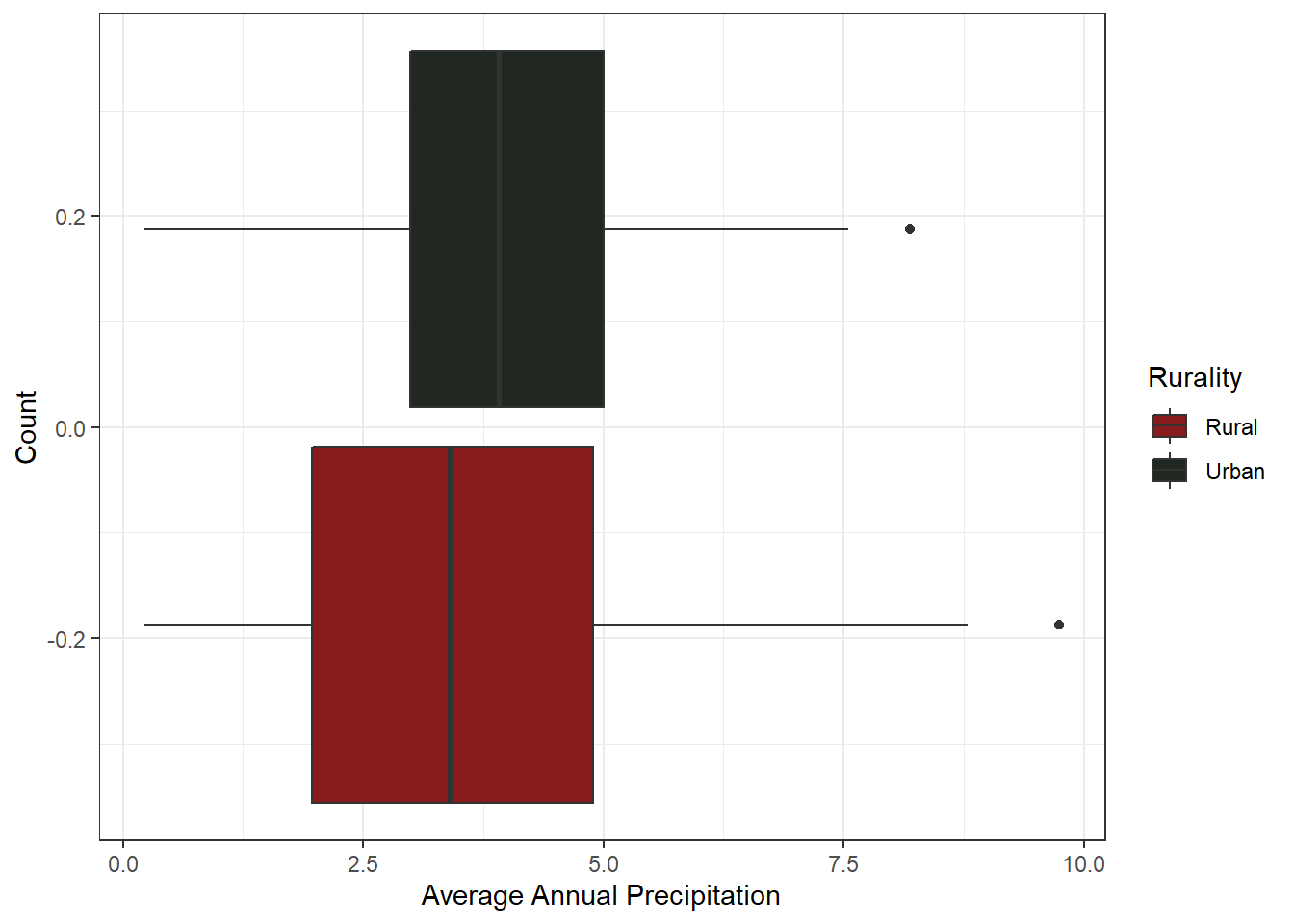
Average precipitation each month is fairly uniform, with the mean at 3.49 inches of rain, on average, each month. The mean does differ from Urban to Rural, with Rural counties being drier than their Urban counterparts, but not by much. This variable will most likely provide less variation in the analysis compared to others.
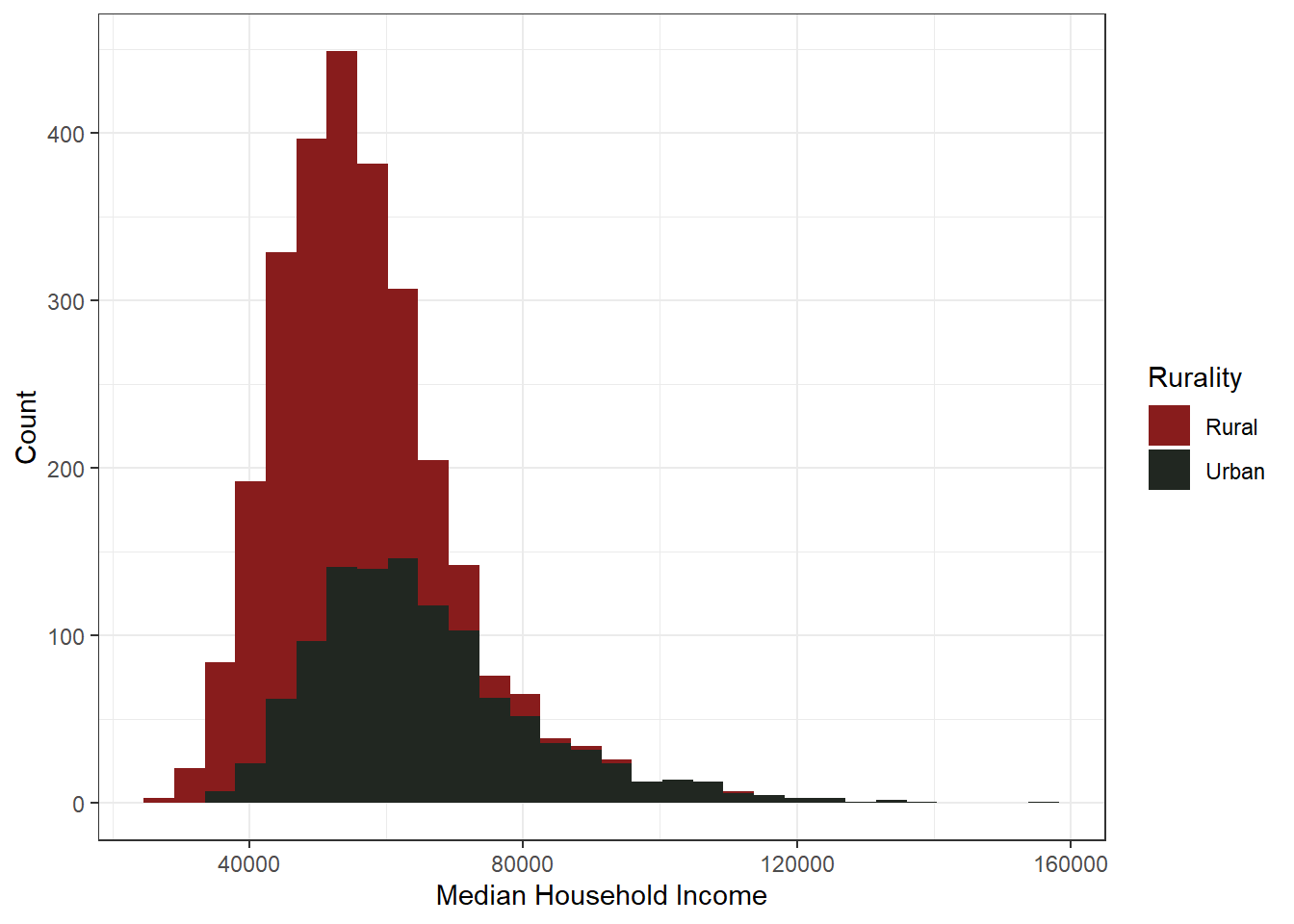
Very close to a normal distribution, if barely left-skewed. A couple of high out-liers, hovering around $90,000+ in median household income, but the mean holds at $57,465.
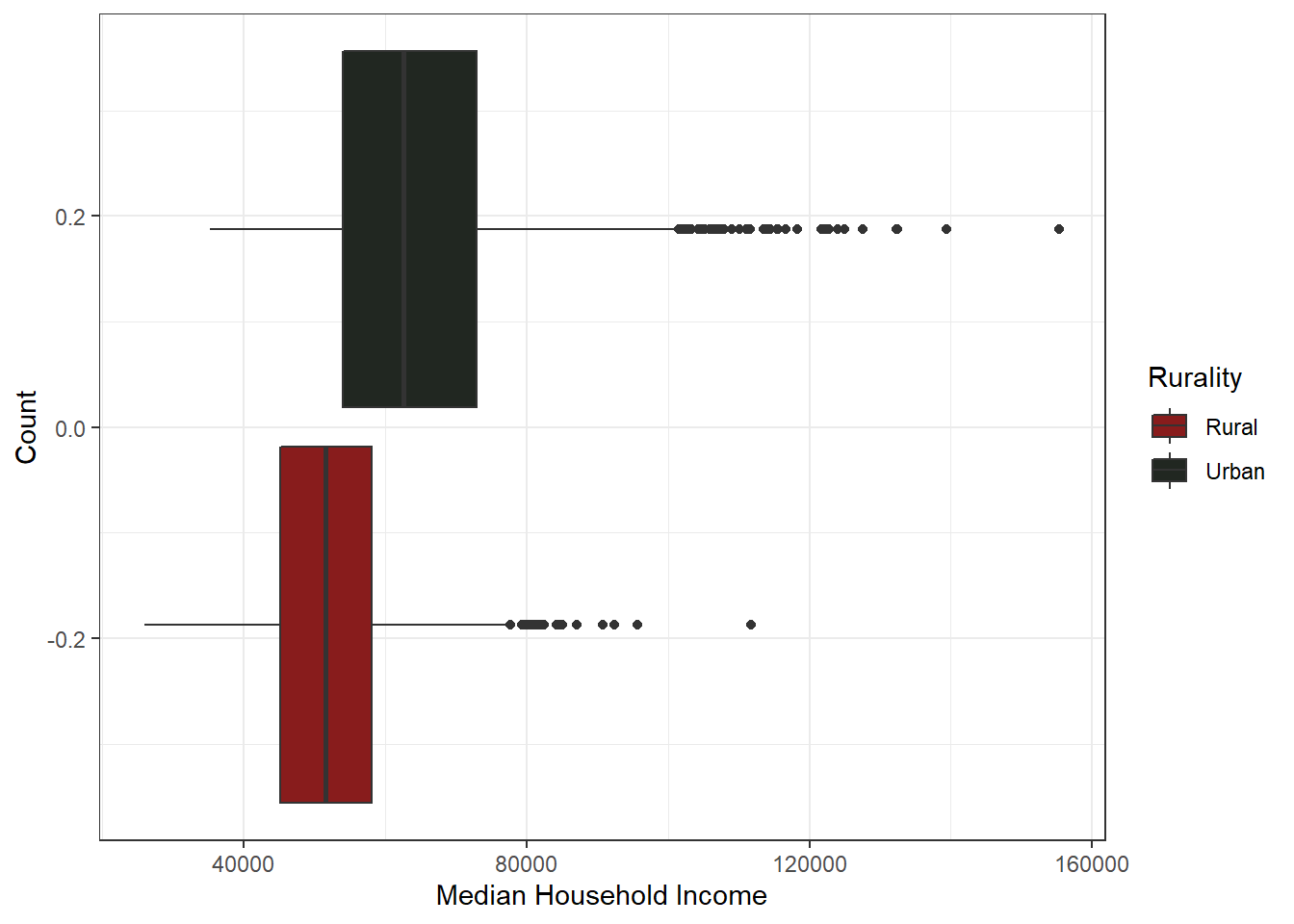
Rural Counties have substantially lower median household income, by roughly $10,ooo to $20,000. Urban counties also make up the bulk of out-liers.
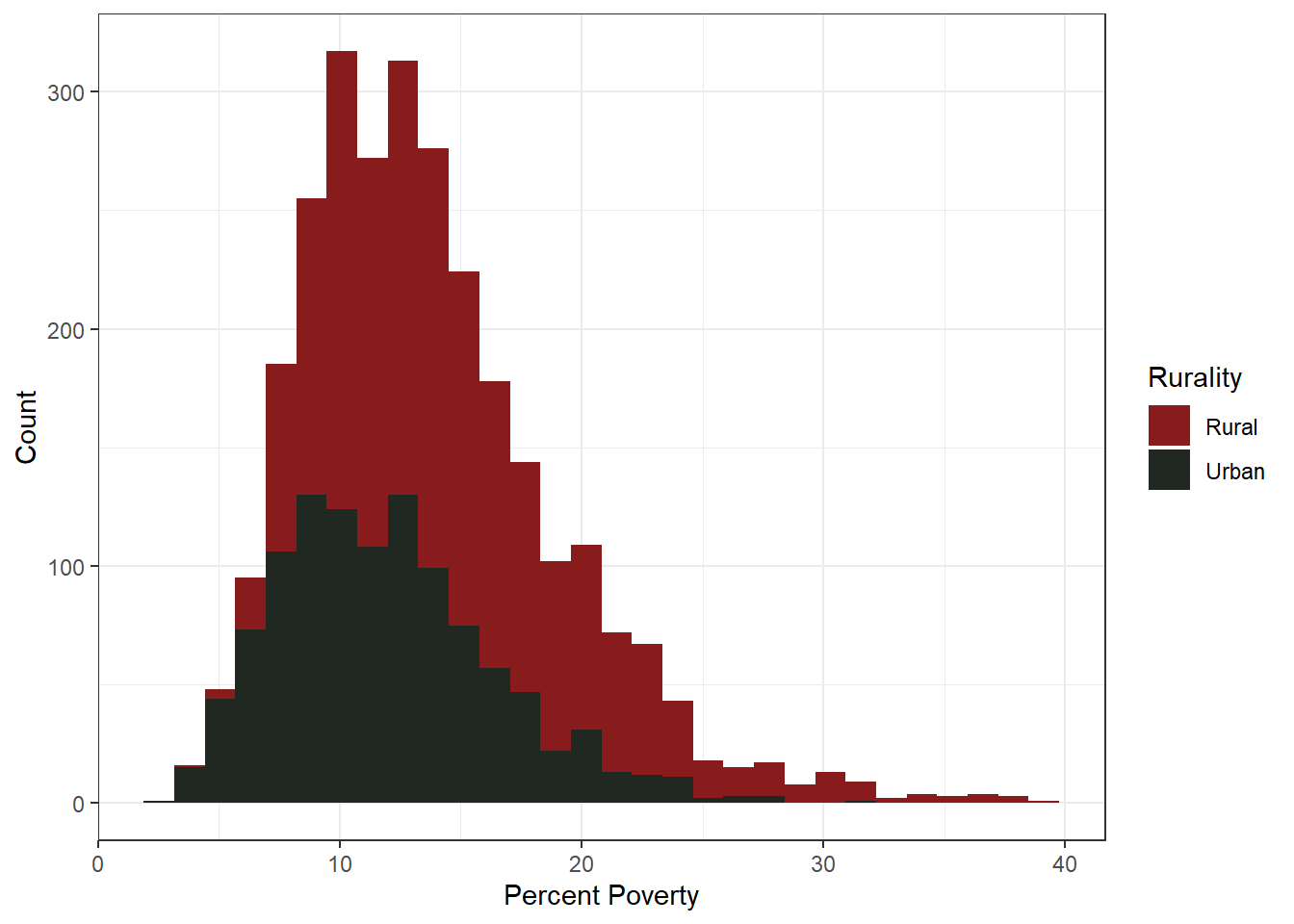
Another close to normal distribution. Most counties have poverty rates ranging from 10% to 20%. There are of course out-liers, especially a good number below 10%, but those are rare.
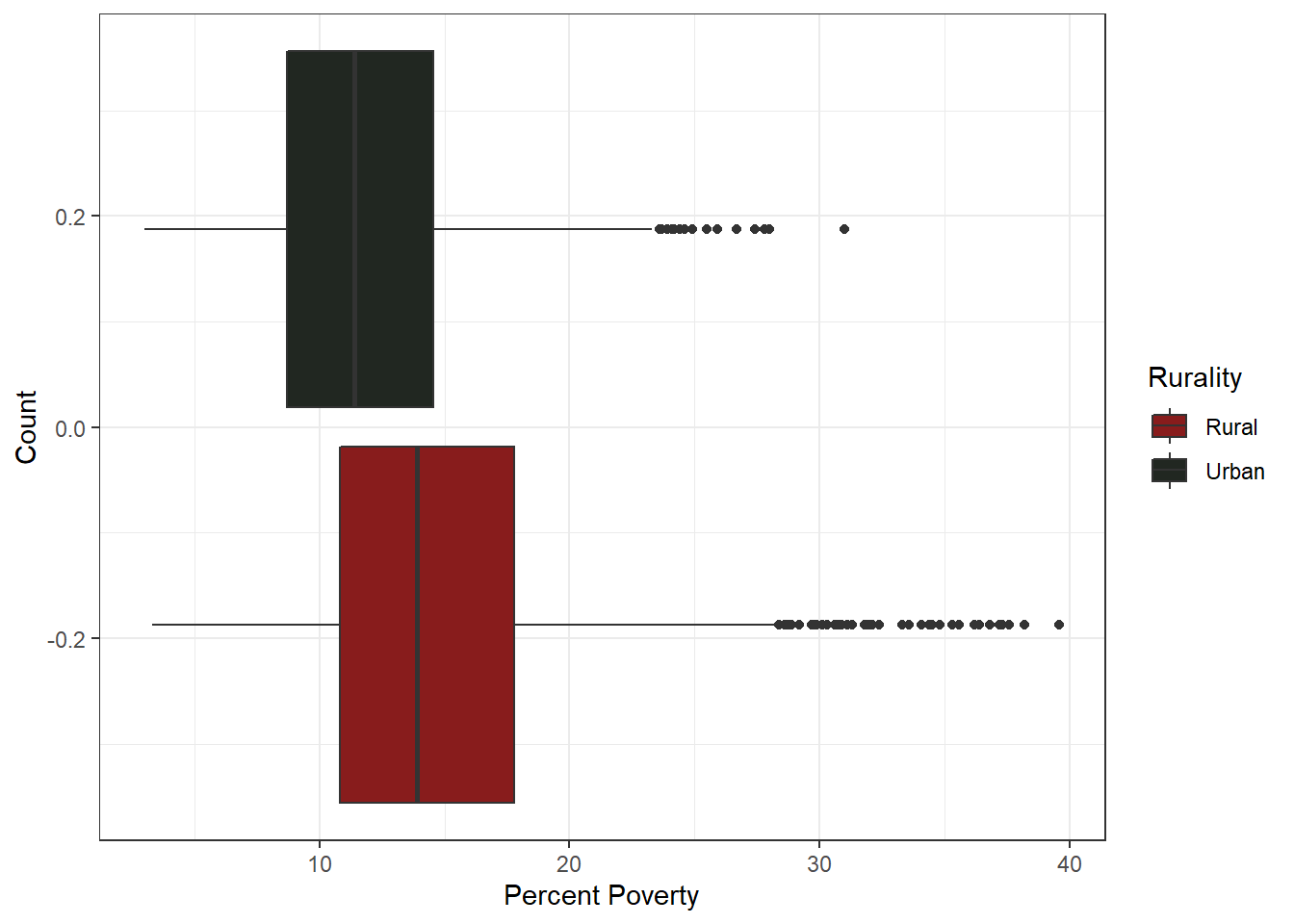
Urbanized counties have substantially less percentage poverty compared to their rural counterparts, and rural counties make up the bulk of outliers post-30%. Only one Urban county has a poverty rate higher than 30%.
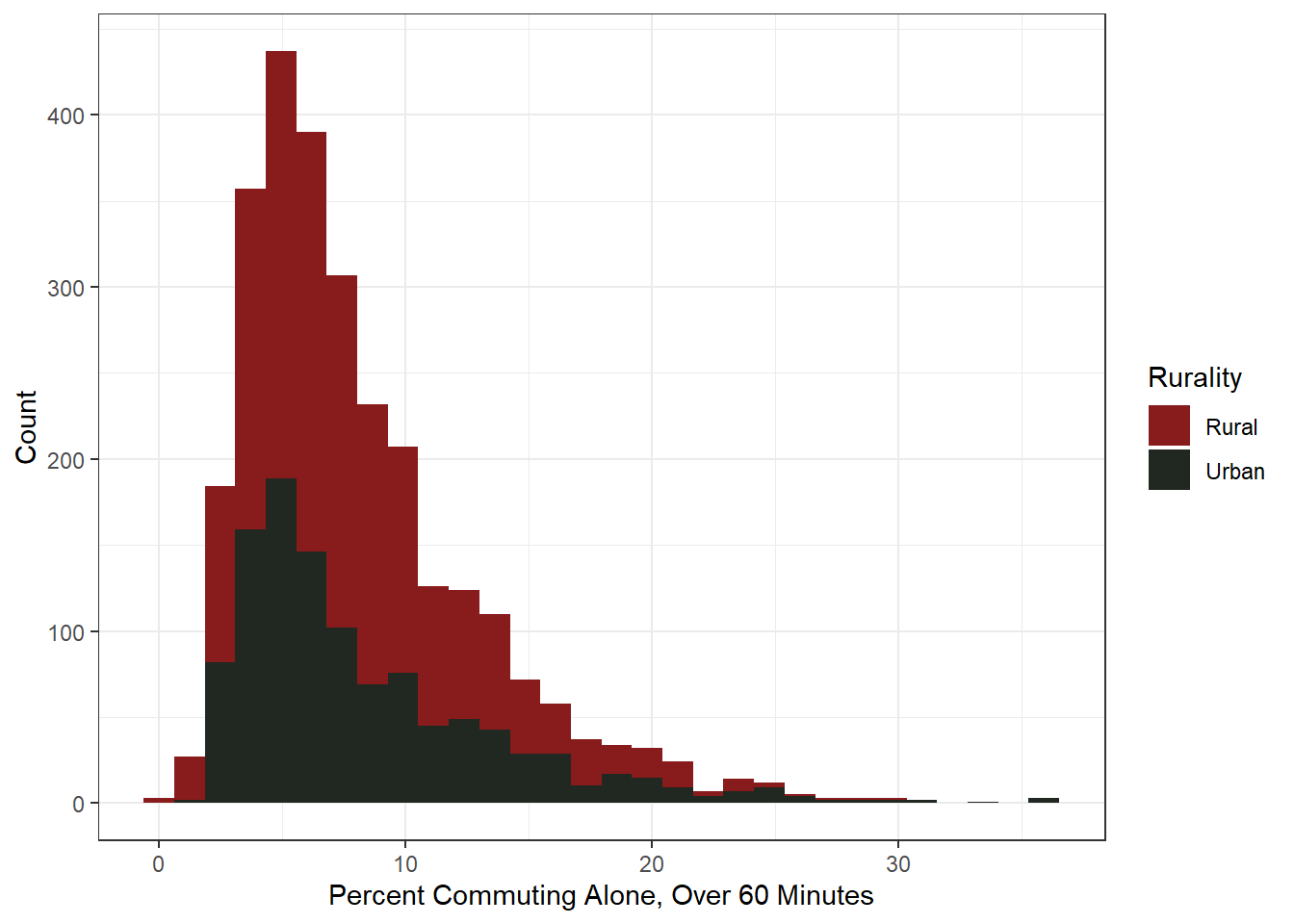
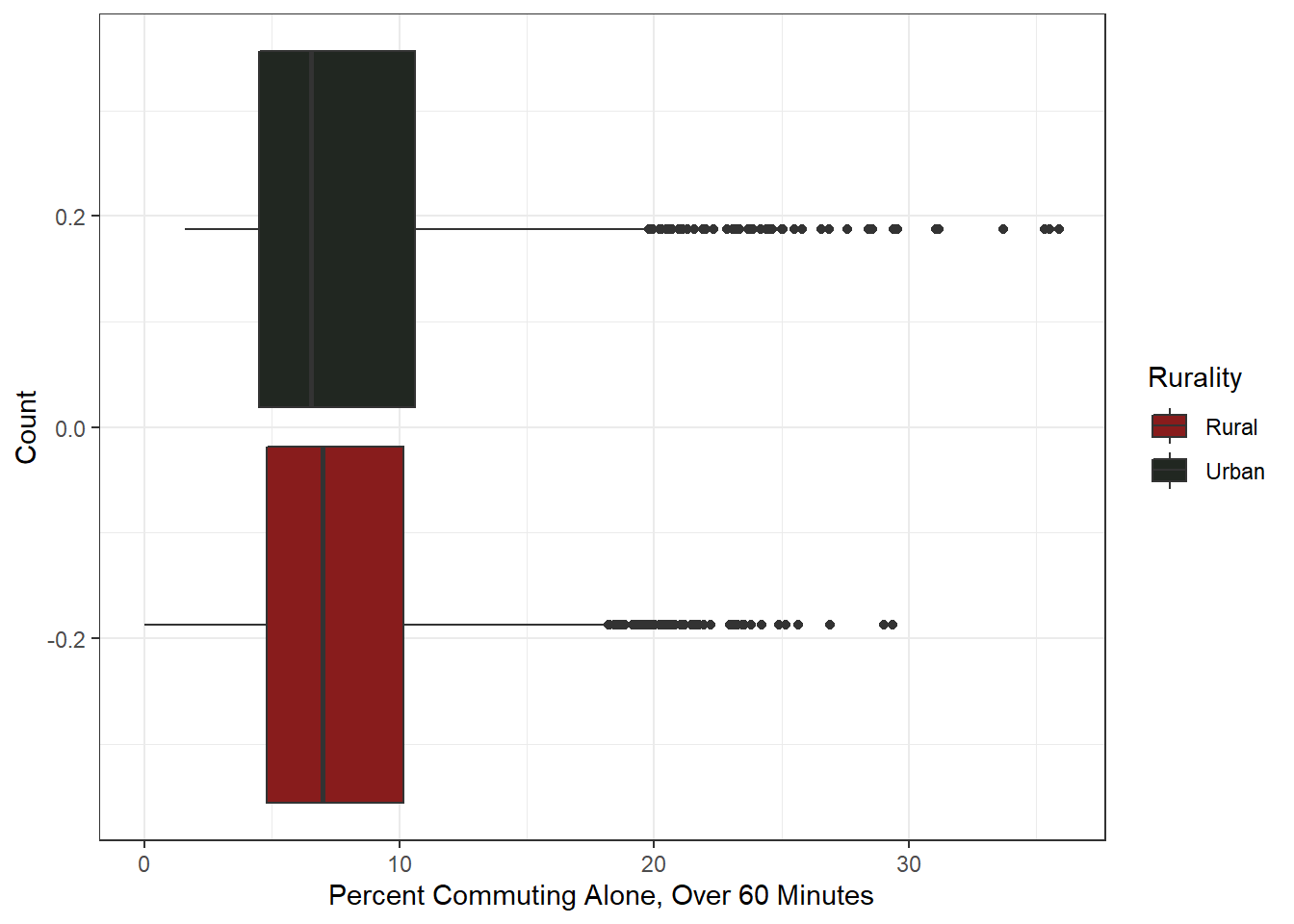
The majority of counties fall below 10% of their population commuting up to and more than 60 minutes for work. Very little variation between urban and rural counties here, which is surprising considering population density would lead one to believe rural counties travel longer on average. Perhaps the inverse is correct, in that highly remote communities means commutes are more local.
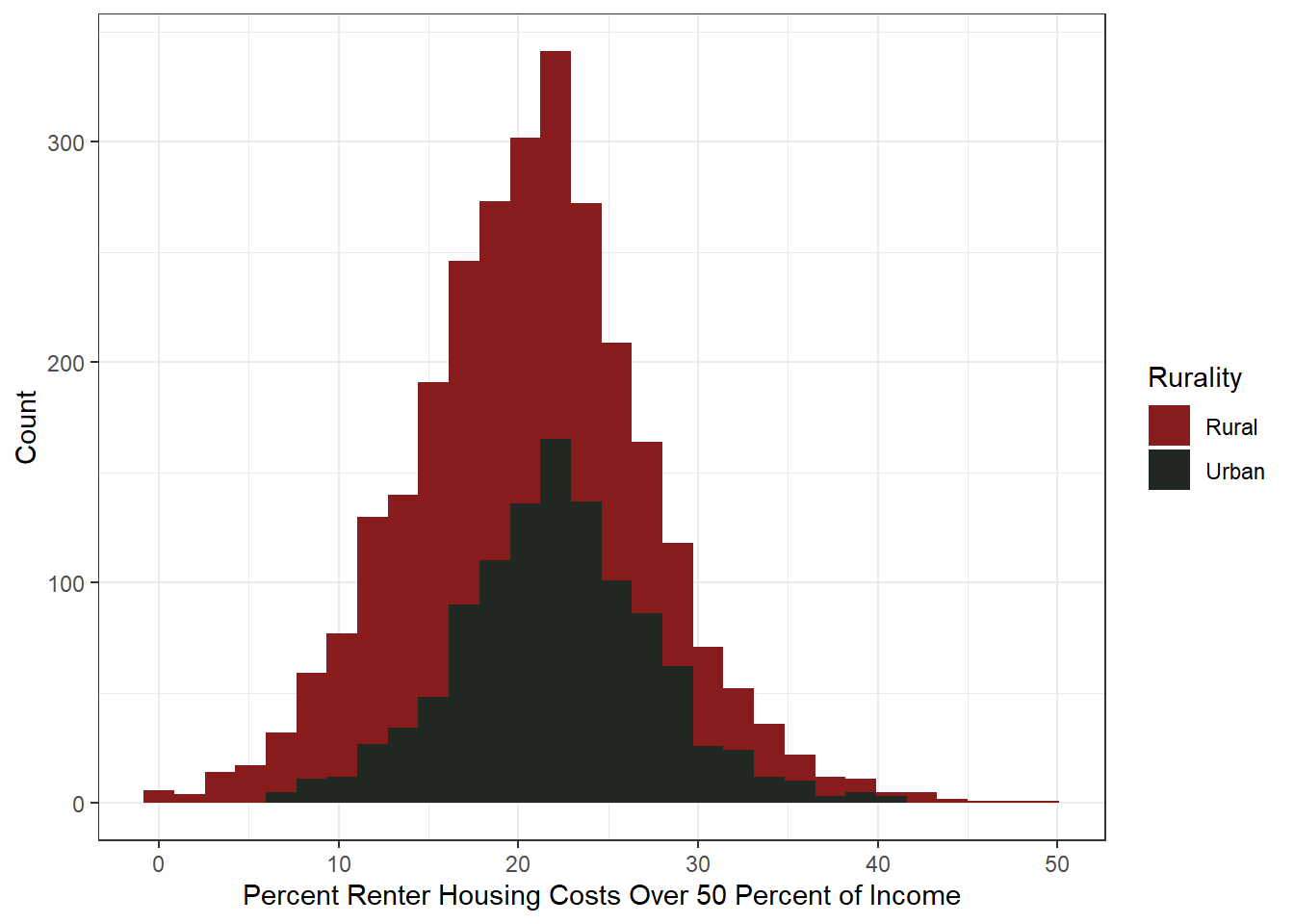
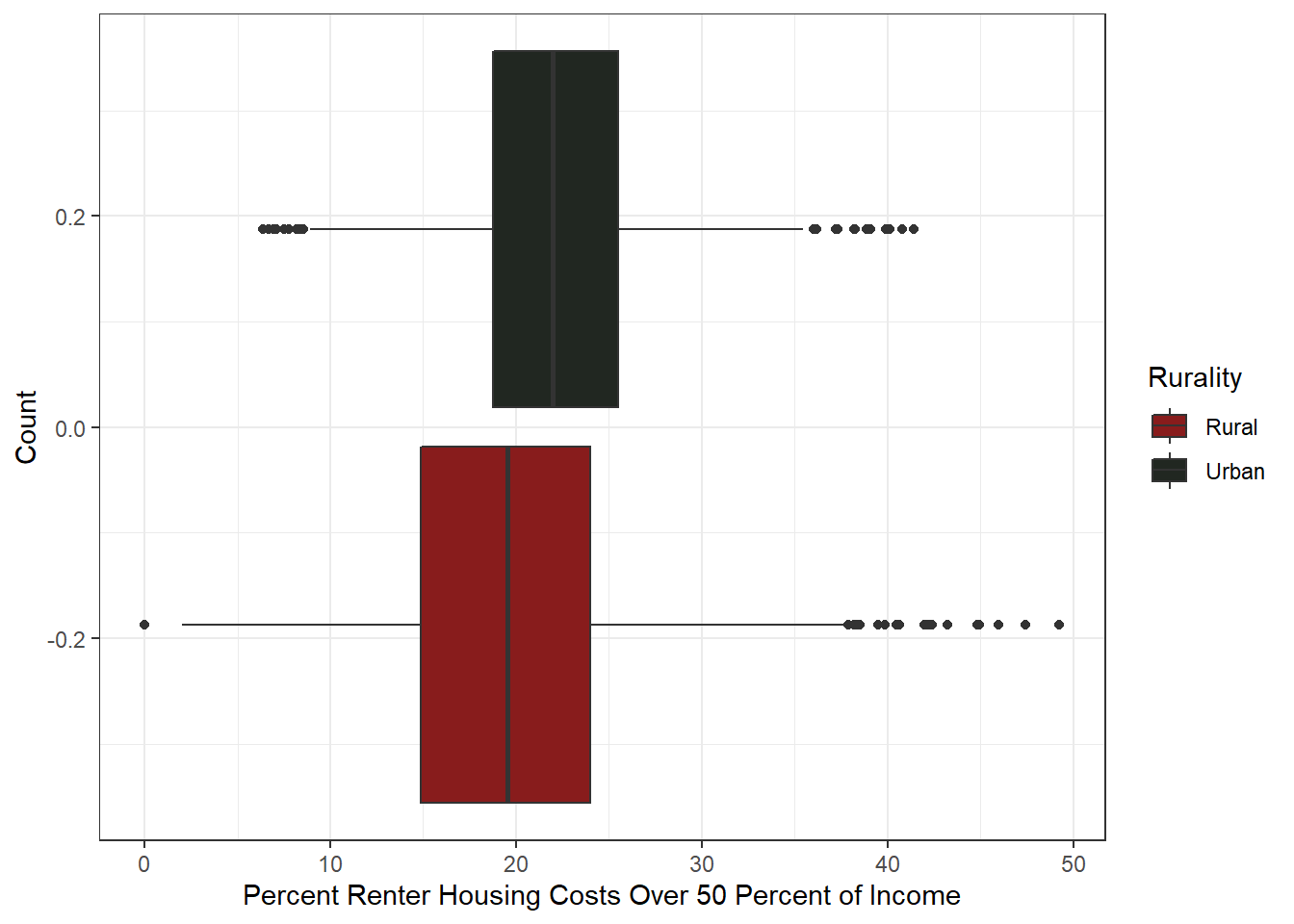
Percent Renter Housing Costs Over 50 Percent of Income
This is a startling figure. On average, 20% of counties have renters where 50% or more of their income goes toward housing costs. These leaves little to no room for other expenses and drives economic instability. The data is normally distributed and barely left-skewed – but still an item to consider with further analysis.
Urban counties also have a higher renter housing burden on average, with rural counties having more out-liers.
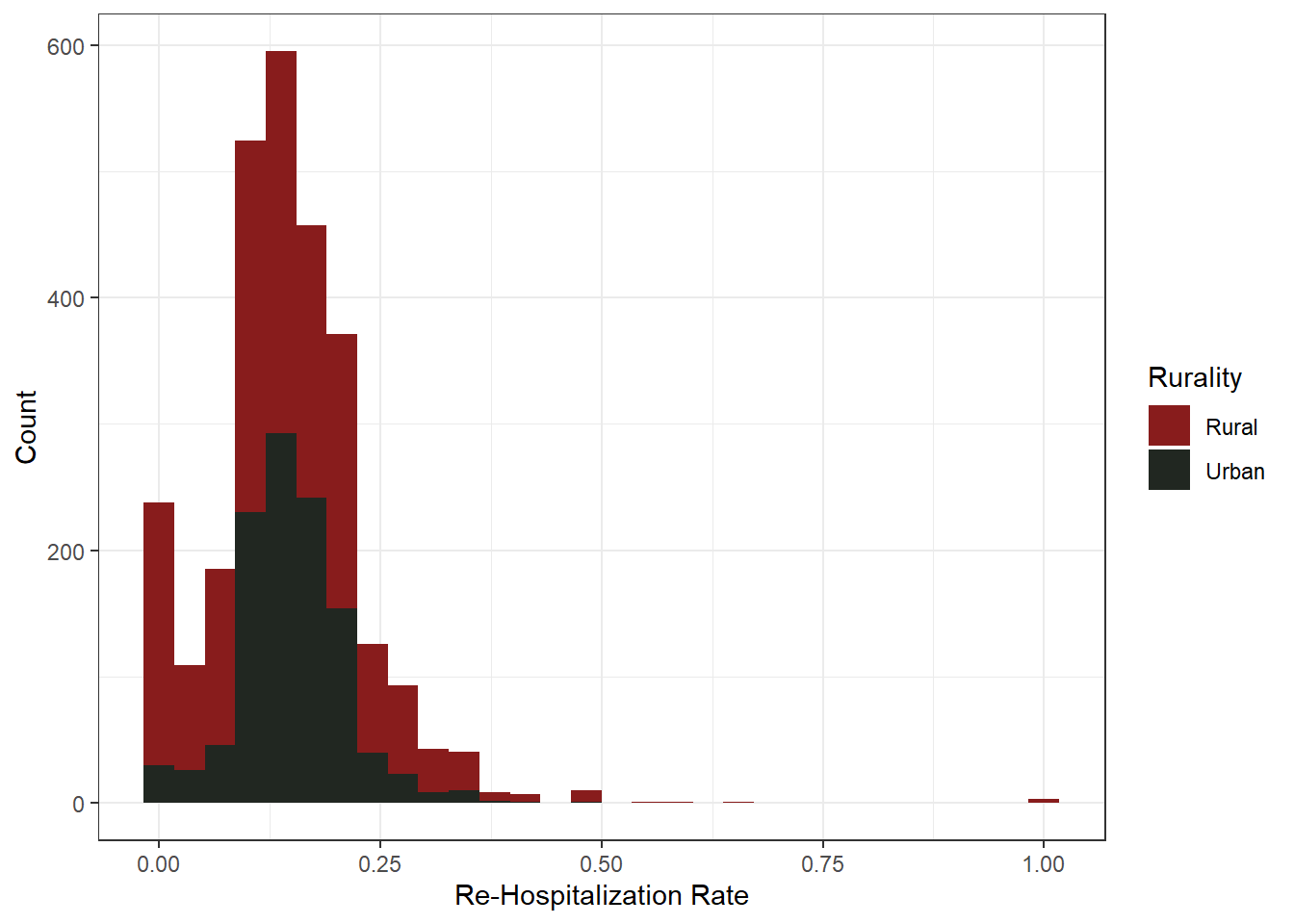
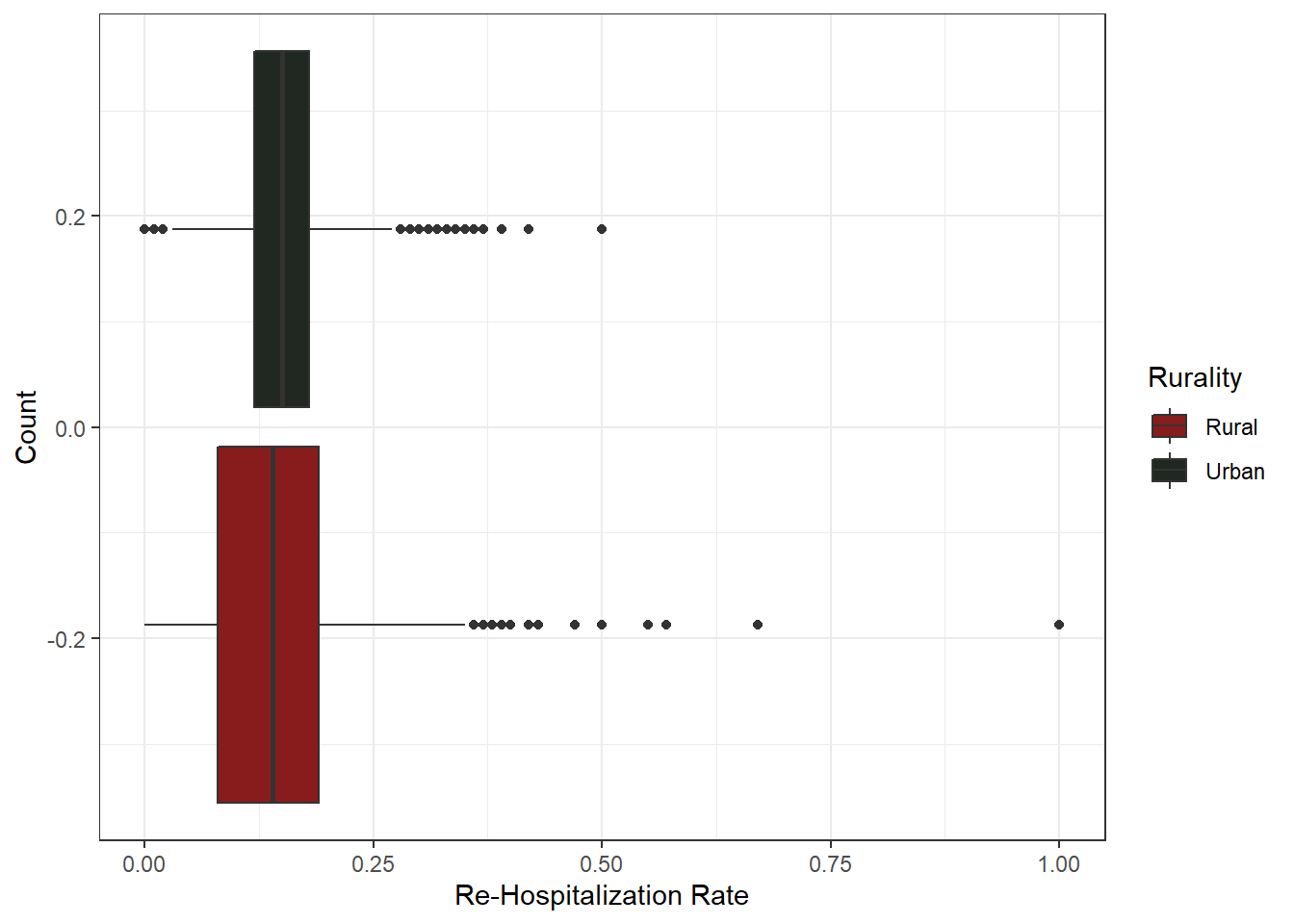
Another right skewed variable. Lots of counties with 0.00 rates of re-hospitalization, and few, if any, above 0.50 per 100,000 people. The same can be said when comparing urban vs. rural, as there seems to be little variation. Rural counties do have more out-liers, as to be expected with low access to healthcare and quality healthcare services.From a health perspective, this is good news! From a research perspective, that’s going to make analysis a little trickier. However, the somewhat normal and/or bimodal distribution should be fairly easy to work with. While needing some transformation for a linear regression, we can test multiple models per each variable to determine which amendment provides the most robust inference.
Analysis
Hypothesis Testing
Remember that the hypothesis for this research report is:
Precipitation has a positive impact on re-hospitalization rates within rural counties.
We have fifteen (15) explanatory variables to work with, so we can run different regressions to determine what variables influence re-hospitalization rates the most – if at all – and how they interact with other variables.
Reminder that the fifteen (15) explanatory and control variables are broken down into three domains: the primary independent and dependent variables, socio-demographic variables, and economic variables.
Independent and Dependent variables:
Average Annual Precipitation
Re-Hospitalization Rates
Socio-demographic variables:
Percent Male
Percent Female
Percent American Indian
Percent Asian
Percent Black
Percent Hispanic
Percent Multiple Races
Percent Other Race
Percent White
Economic variables:
Median Household Income
Percent Poverty
Percent Rental Housing Cost, over 50%
Percent Commuting Alone, over 60 minutes
We will run four models to test the hypothesis. They shall examine each environmental variable’s impact on the dependent variable, re-hospitalization rates. The control variables will be the socio-demographic and economic variables, thirteen (13) in total.
Model 1 will take just the independent and dependent variables by themselves.
Model 2 will add socio-demographic variables as control.
Model 3 will add economic variables as control.
Model 4 will add both socio-demographic and economic variables as control.
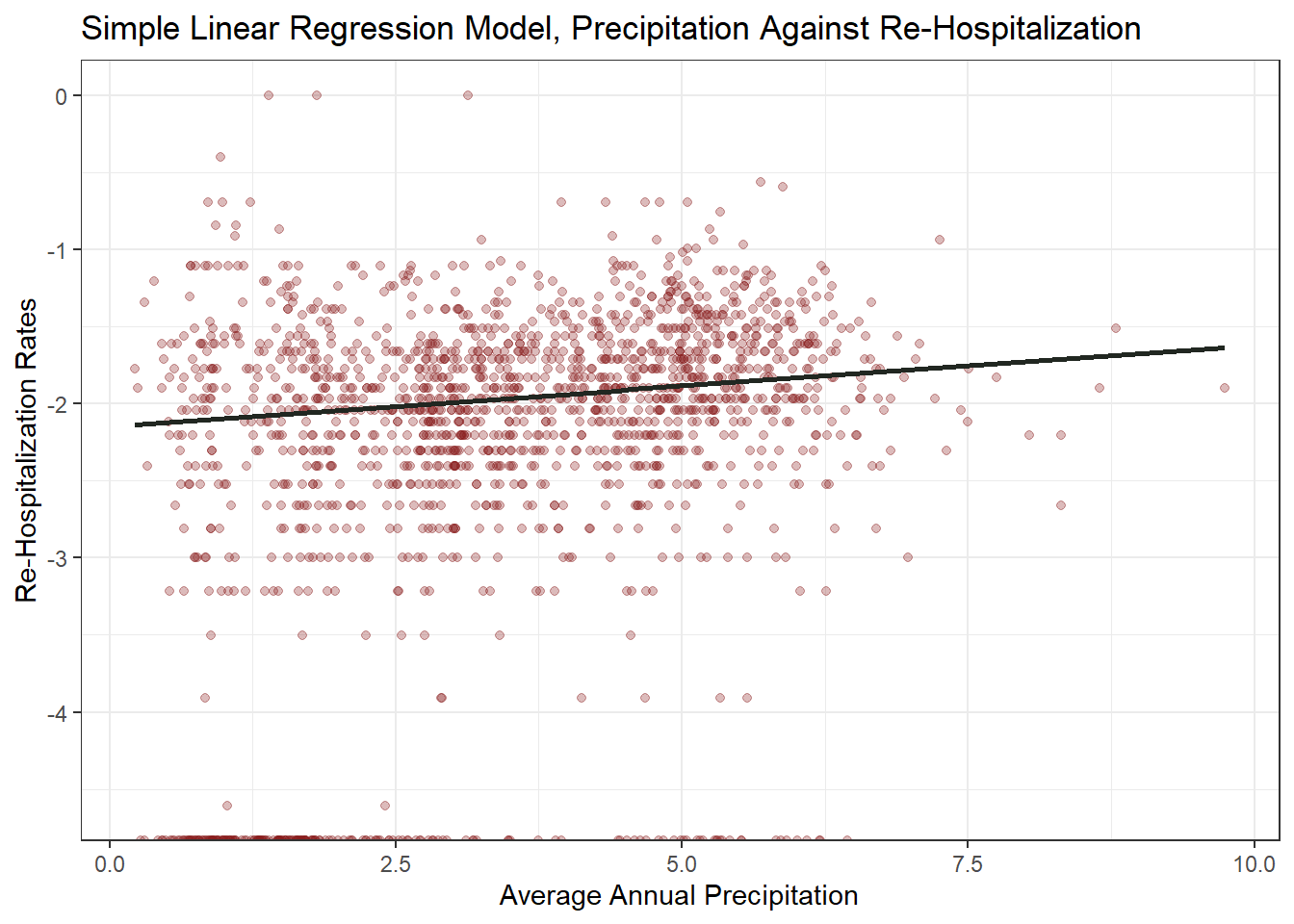
We will reject the null hypothesis. While it looks like, at first glance, that there is little positive relationship, we can at least note that there is some positive relationship. In the next two sections, we will dig deeper into each model, examining the p-value, R-Squared value, and PRESS statistic to see what level of relationship is present.
Model Comparisons
Now we will compare the four (4) models in more depth.
We want to look for two items in particular: 1) P-values that reach significant code of *** and 2) The highest Adjusted R-squared value.
Model 1’s Precipitation variable has the highest P-value compared to the other models, and the lowest Adjusted R-squared value.
Model 2’s significant variables are Precipitation and Hispanic Rate. However, the Hispanic Rate does not meet the significant code of ***. The Adjusted R-squared value is only slightly higher than Model 1.
Model 3’s significant variables are Precipitation,Percent Poverty, and Commuting. However, neither Percent Poverty nor Commuting meet ***. The Adjusted R-squared value is close to Model 4, so it appears that the economic variables have a higher impact over socio-demographic measures.
Model 4’s significant variables are Precipitation,Percent Poverty, and Commuting.Precipitation has the lowest P-value of the four models here, and Percent Poverty meets the significance threshold of ***. The Adjusted R-squared value is the highest here, though only at 0.076.
Finally, we’re going to calculate the PRESS statistic (Predicted Residual Sum of Squares) to best determine which model can predict the response variable based upon the explanatory variables.
Code
PRESS <-function(model) { i <-residuals(model)/(1-lm.influence(model)$hat)sum(i^2)}PRESS(model1)
[1] 15.25297
Code
PRESS(model2)
[1] Inf
Code
PRESS(model3)
[1] 15.05951
Code
PRESS(model4)
[1] Inf
Model 3 has the lowest PRESS score, though Model 4 is not being calculated for some reason. This is probably due to an error with a socio-demographic variable.
Due to a strong p-value, Adjusted R-squared value, and model fit compared to the other three models, Model 4 will be chosen as the final model for the diagnostic exploration.
Diagnostics
Finally, we’ll plot the diagnostics to best understand the model.
Code
par(mfrow =c(2,3));plot(model4, which =1:6) +theme_bw()
Warning: not plotting observations with leverage one:
44
Warning: not plotting observations with leverage one:
44
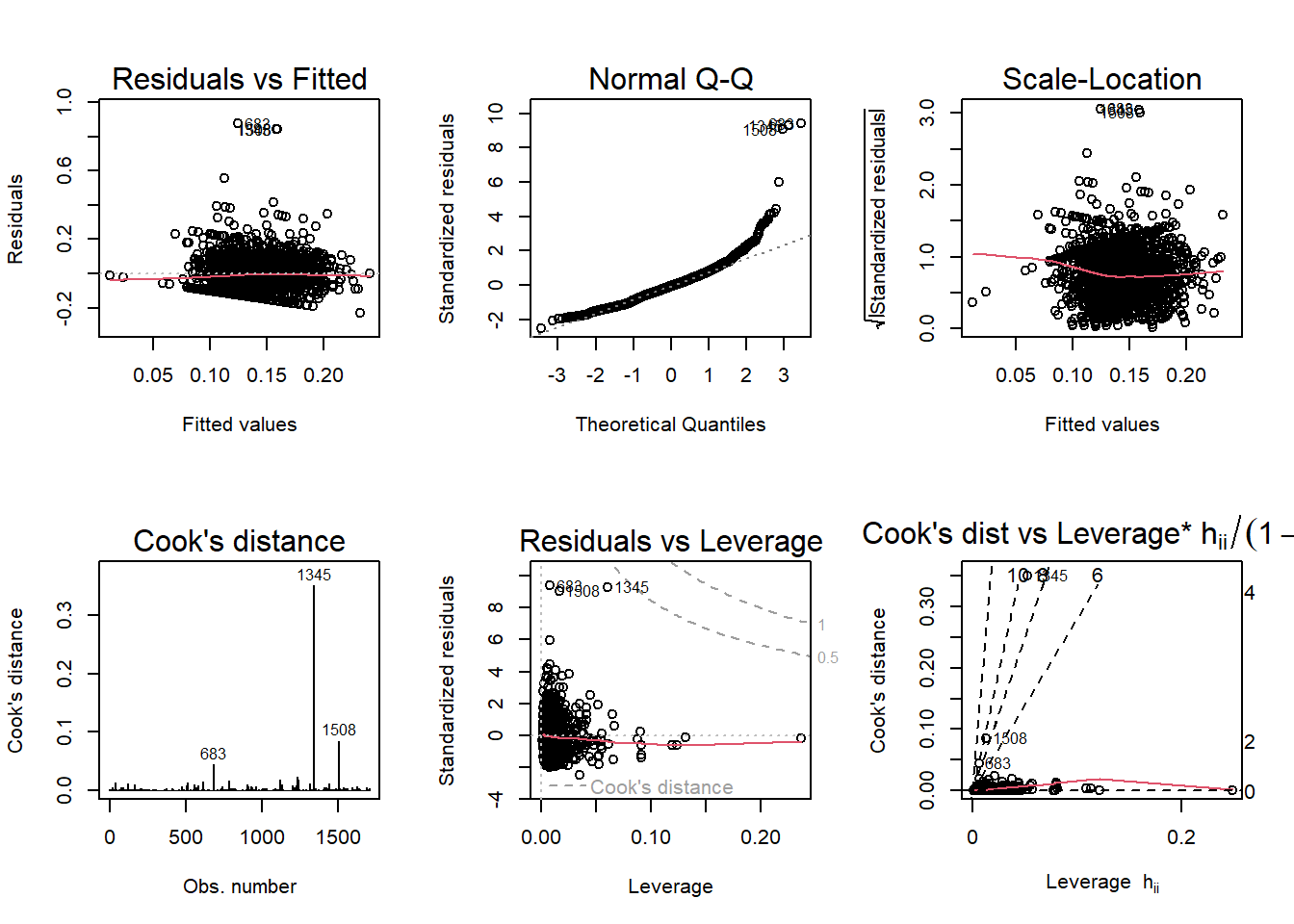
683 is Mackinac County, Michigan, one of the most remote areas in the Great Lakes, with a population of 10,906.
1345 is Mellette County, South Dakota, with a population of 1,908.
1508 is Real County, Texas, a county with only one incorporated area and a population of 2,826.
Otherwise, the plot looks good.
Normal Q-Q violates this test, as the points at the right tail of the plot do not generally fall along the line. This is very apparent for our three out-liers. Cook’s Distance vs. Leverage violates this test as well. The remaining plots do not violate their tested assumptions and further cement the model’s reliability.
Conclusion
This paper explored the relationship between re-hospitalization rates and precipitation, when controlling for common variables that regularly influence the dependent variable.
Four models were selected, one for each variable, to best determine which measure best impacted re-hospitalization rates. In all of the models, precipitation was statistically significant. While the adjusted R-squared value is negligible (0.076), there is a positive relationship that is statistically significant. Therein we see some form of an influence large amounts of annual precipitation has on re-hospitalization rates.
References
Barnett, M., Hsu, J. & McWilliams, M. (2015). “Patient Characteristics and Differences in Hospital Readmission Rates.” JAMA Intern Med., 175(11): 1803-1812.
Bhosale KH, Nath RK, Pandit N, Agarwal P, Khairnar S, Yadav B, & Chandrakar S. (2020). “Rate of Rehospitalization in 60 Days of Discharge and It’s Determinants in Patients with Heart Failure with Reduced Ejection Fraction in a Tertiary Care Centre in India.” Int J Heart Fail. 21;2(2):131-144.
Li, Y., Cai, X. & Glance, L. (2015). “Disparities in 30-day rehospitalization rates among Medicare skilled nursing facility residents by race and site of care.” Med Care, 53(12): 1058-1065.
Murray, F., Allen, M., Clark, C., Daly, C. & Jacobs, D. (2021). “Socio-demographic and -economic factors associated with 30-day readmission for conditions targeted by the hospital readmissions reduction program: a population-based study.” BMC Public Health, 21.
Rizmie, D., Preuz, L., Miraldo, M. & Atun, R. (2022). “Impact of extreme temperatures on emergency hospital admissions by age and socio-economic deprivation in England.” Social Science & Medicine, 308.
Tapak, L., Maryanaji, Z., Hamidi, O., Abbasi, H. & Najafi-Vosough, R. (2018). “Investigating the effect of climatic parameters on mental disorder admissions.” International Journal of Biometerology, 62, 2109-2118.
Trinh, T., Feeny, S. & Posso, A. (2018). “Rainfall shocks and child health: the role of parental mental health.” Climate and Development, 13(1), 34-48.
Spatz, E., Bernheim, S., Horwitz, L. & Herrin, J. (2020). Community factors and hospital wide readmission rates: Does context matter? PLoS One, 15(10).
Source Code
---title: "Final Part 3"author: "Caleb Hill"desription: "Part 3 of the Final Project"date: "12/11/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - finalpart3 - caleb.hill---## IntroductionWith climate change upsetting normal weather patterns, there has been exciting research into how precipitation shocks (flooding and drought events) impact health outcomes, (Rizmie, d., Preuz, L, Miraldo, M. & Atun, R. (2022); Tapak, L., Maryanaji, Z., Hamidi, O., Abbasi, H. & Najafi-Vosough, R. (2018); Trinh, T., Feeny, S. & Posso, A. (2018)). Alongside this train of thought, multiple research reports state that there is a relationship between re-hospitalization rates and social characteristics, such as demographic and economic identifiers, (Barnett, Hsu & McWilliams, 2015; Murray, Allen, Clark, Daly & Jacobs, 2021). Specifically, racial characteristics play a large role in predicting re-hospitalization in a population (Li, Cai & Glance, 2015). While some articles examine economic and health factors contributing to these disparities, very few dig deep into environmental factors that influence this phenomenon, (Spatz, Bernheim, Horwitz & Herrin, 2020). With your zipcode affecting up to 60% of your health outcomes, this research is relevant to better improving one of our most costly health expenditures: hospitalization. Therefore, this research report aims to integrate these two concepts, testing if precipitation shocks have a positive relationship on not just hospital admissions but also re-admissions.Re-hospitalization is a substantially costlier expenditure, as readmitting a patient further increases costs -- especially if the diagnosis was untreated, poorly treated, or incorrectly treated. Most inpatient episodes characterized as a re-hospitalization when the patient is readmitted to the hospital 60 days after discharge. If the cause is different, sometimes that is counted as a re-hospitalization; other times, not so much, (Bhosale, K., Nath, R., Pandit, N., Agarwal, P., Khairnar, S., Yadav, B. & Chandrakar, S., 2020).### Research QuestionThis paper aims to explore how precipitation shocks impact re-hospitalization rates on a county-by-county level. We will control for socio-demographic and economic variables. We will also stratify by rural/urban classification, to determine if counties above or below 250,000 population experience differences in re-hospitalization rates, dependent upon these explanatory variables. This is purely because literature shows that rural communities face more acute and poorer health outcomes.The data-set chosen for this analysis is taken from the Agency for Healthcare Research and Quality, Social Determinants of Health (SDOH) Database. This data-set has over 1,400 variables to explore each SDOH domain: social context, economic context, education, healthcare, and the environment. We shall pull data from three of these five domains: social, economic, and environmental.How re-hospitalization is measured is not clarified per this data-set's codebook. However, the Center for Medicare and Medicaid (CMS) 30-day Risk-Standardized Readmission Rate (RSRR) measures re-hospitalization as an unplanned readmission to inpatient services. It does stratify and specify based upon diagnosis. As the AHRQ is a federal agency alongside CMS, it is likely that they are pulling from CMS for this measure and aggregating various diagnoses into one county rate.### HypothesisThe hypothesis for this research report is:- Precipitation has a positive impact on re-hospitalization rates within rural counties.Therefore, the null hypothesis is:- Precipitation does not have a positive impact on re-hospitalization rates within rural counties.Various regression models shall be employed to determine the relationship -- or lack thereof -- between these variables.First I'll import the relevant librarie and set up a UMass color scheme for crimson and black.```{r, include = FALSE}#| label: setup#| warning: falselibrary(tidyverse)library(readxl)library(psych)library(knitr)library(corrplot)library(stargazer)theme_bw()umass_colors <-c("#881c1c", "#212721")knitr::opts_chunk$set(echo =TRUE)```Then I'll import the dataset and view the first six rows.```{r}df <- SDOH_2020_COUNTY_1_0 <-read_excel("_data/SDOH_2020_COUNTY_1_0.xlsx", sheet ="Data")head(df)```Next I want to verify the class is a dataframe. Otherwise, I'll need to transform the data to make it easier to work with.```{r}class(df)```All good here.Now on to data transformation. We will need to select only the relevant columns for this analysis.```{r}df_new <- df %>%select(COUNTYFIPS, STATE, COUNTY, AHRF_USDA_RUCC_2013, NOAAC_PRECIPITATION_AVG_YEARLY, ACS_PCT_MALE, ACS_PCT_FEMALE, ACS_PCT_AIAN, ACS_PCT_ASIAN, ACS_PCT_BLACK, ACS_PCT_HISPANIC, ACS_PCT_MULT_RACE, ACS_PCT_NHPI, ACS_PCT_OTHER_RACE, ACS_PCT_WHITE, SAIPE_MEDIAN_HH_INCOME, SAIPE_PCT_POV, ACS_PCT_COMMT_60MINUP, ACS_PCT_RENTER_HU_COST_50PCT, LTC_AVG_OBS_REHOSP_RATE) nrow(df_new)head(df_new)```Out of 1400+ variables, we've whittled them down to 20. Of those 20, we have four (4) that are unique identifiers (FIPS, State, County, and Rural-Urban Continuation Code), ten (10) socio-demographic, four (4) economic, one (1) for precipitation, and one (1) for re-hospitalization.Before we launch into exploring these variables via descriptive statistics, first we need to determine where the NAs are and see if any of the variables will have a substantial amount of missing data.```{r}kable(colSums(is.na(df_new)))```Plenty of variables with missing data. The most concerning is -- of course -- our outcome variable, Re-Hospitalization Rates. This is not ideal. However, 410 / 3229 (12.6%) is not bad. That still leaves us with plenty of counties to review.```{r}df_new <- df_new %>%drop_na() %>%print(nrow(df_new))```2,814 x 20 is a good place to start.This next step will conver the Rural-Urban Continuum Code to a binary Rural/Urban. If the county is coded as a four (4) or higher, then they are classified as rural, non-metro, having a population of less than 250,000 as defined by USDA as "Rural."```{r}df_new <- df_new %>%mutate(Rurality =if_else( AHRF_USDA_RUCC_2013 >=4, "Rural", "Urban") )head(df_new)```## Descriptive StatisticsFor our preliminary analysis, we're going to provide summary statistics analyzing the variables relevant to our research question, excluding the socio-demographic control variables, and a visualization for each.```{r}kable(describe(df_new))```Following this, we're going to stratify each variable by rurality and determine either the difference in distribution (histogram) and/or central tendency (boxplot).### Average Yearly Precipitation```{r}ggplot(df_new, aes(x = NOAAC_PRECIPITATION_AVG_YEARLY,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_histogram() +xlab("Average Annual Precipitation") +ylab("Count") +theme_bw()ggplot(df_new, aes(x = NOAAC_PRECIPITATION_AVG_YEARLY,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_boxplot() +xlab("Average Annual Precipitation") +ylab("Count") +theme_bw()```Average precipitation each month is fairly uniform, with the mean at 3.49 inches of rain, on average, each month. The mean does differ from Urban to Rural, with Rural counties being drier than their Urban counterparts, but not by much. This variable will most likely provide less variation in the analysis compared to others. ### Median Household Income```{r}ggplot(df_new, aes(x = SAIPE_MEDIAN_HH_INCOME,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_histogram() +xlab("Median Household Income") +ylab("Count") +theme_bw()ggplot(df_new, aes(x = SAIPE_MEDIAN_HH_INCOME,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_boxplot() +xlab("Median Household Income") +ylab("Count") +theme_bw()```Very close to a normal distribution, if barely left-skewed. A couple of high out-liers, hovering around \$90,000+ in median household income, but the mean holds at \$57,465.Rural Counties have substantially lower median household income, by roughly \$10,ooo to \$20,000. Urban counties also make up the bulk of out-liers.### Percent in Poverty```{r}ggplot(df_new, aes(x = SAIPE_PCT_POV,fill = Rurality)) +geom_histogram() +xlab("Percent Poverty") +ylab("Count") +scale_fill_manual(values = umass_colors) +theme_bw()ggplot(df_new, aes(x = SAIPE_PCT_POV,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_boxplot() +xlab("Percent Poverty") +ylab("Count") +theme_bw()```Another close to normal distribution. Most counties have poverty rates ranging from 10% to 20%. There are of course out-liers, especially a good number below 10%, but those are rare.Urbanized counties have substantially less percentage poverty compared to their rural counterparts, and rural counties make up the bulk of outliers post-30%. Only one Urban county has a poverty rate higher than 30%.### Percent Commuting Alone, Over 60 Minutes```{r}ggplot(df_new, aes(x = ACS_PCT_COMMT_60MINUP,fill = Rurality)) +geom_histogram() +xlab("Percent Commuting Alone, Over 60 Minutes") +ylab("Count") +scale_fill_manual(values = umass_colors) +theme_bw()ggplot(df_new, aes(x = ACS_PCT_COMMT_60MINUP,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_boxplot() +xlab("Percent Commuting Alone, Over 60 Minutes") +ylab("Count") +theme_bw()```The majority of counties fall below 10% of their population commuting up to and more than 60 minutes for work. Very little variation between urban and rural counties here, which is surprising considering population density would lead one to believe rural counties travel longer on average. Perhaps the inverse is correct, in that highly remote communities means commutes are more local.### Percent Renter Housing Costs Over 50 Percent of Income```{r}ggplot(df_new, aes(x = ACS_PCT_RENTER_HU_COST_50PCT,fill = Rurality)) +geom_histogram() +xlab("Percent Renter Housing Costs Over 50 Percent of Income") +ylab("Count") +scale_fill_manual(values = umass_colors) +theme_bw()ggplot(df_new, aes(x = ACS_PCT_RENTER_HU_COST_50PCT,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_boxplot() +xlab("Percent Renter Housing Costs Over 50 Percent of Income") +ylab("Count") +theme_bw()```This is a startling figure. On average, 20% of counties have renters where 50% or more of their income goes toward housing costs. These leaves little to no room for other expenses and drives economic instability. The data is normally distributed and barely left-skewed -- but still an item to consider with further analysis. Urban counties also have a higher renter housing burden on average, with rural counties having more out-liers.### Re-hospitalization Rate```{r}ggplot(df_new, aes(x = LTC_AVG_OBS_REHOSP_RATE,fill = Rurality)) +geom_histogram() +xlab("Re-Hospitalization Rate") +ylab("Count") +scale_fill_manual(values = umass_colors) +theme_bw()ggplot(df_new, aes(x = LTC_AVG_OBS_REHOSP_RATE,fill = Rurality)) +scale_fill_manual(values = umass_colors) +geom_boxplot() +xlab("Re-Hospitalization Rate") +ylab("Count") +theme_bw()```Another right skewed variable. Lots of counties with 0.00 rates of re-hospitalization, and few, if any, above 0.50 per 100,000 people. The same can be said when comparing urban vs. rural, as there seems to be little variation. Rural counties do have more out-liers, as to be expected with low access to healthcare and quality healthcare services.From a health perspective, this is good news! From a research perspective, that's going to make analysis a little trickier. However, the somewhat normal and/or bimodal distribution should be fairly easy to work with. While needing some transformation for a linear regression, we can test multiple models per each variable to determine which amendment provides the most robust inference.## Analysis### Hypothesis TestingRemember that the hypothesis for this research report is:- Precipitation has a positive impact on re-hospitalization rates within rural counties.We have fifteen (15) explanatory variables to work with, so we can run different regressions to determine what variables influence re-hospitalization rates the most -- if at all -- and how they interact with other variables.Reminder that the fifteen (15) explanatory and control variables are broken down into three domains: the primary independent and dependent variables, socio-demographic variables, and economic variables.Independent and Dependent variables:- Average Annual Precipitation- Re-Hospitalization RatesSocio-demographic variables:- Percent Male- Percent Female- Percent American Indian- Percent Asian- Percent Black- Percent Hispanic- Percent Multiple Races- Percent Other Race- Percent WhiteEconomic variables:- Median Household Income- Percent Poverty- Percent Rental Housing Cost, over 50%- Percent Commuting Alone, over 60 minutesWe will run four models to test the hypothesis. They shall examine each environmental variable's impact on the dependent variable, re-hospitalization rates. The control variables will be the socio-demographic and economic variables, thirteen (13) in total.Model 1 will take just the independent and dependent variables by themselves.Model 2 will add socio-demographic variables as control.Model 3 will add economic variables as control.Model 4 will add both socio-demographic and economic variables as control.```{r}df_new <- df_new %>%filter(Rurality =="Rural") model1 <-lm(LTC_AVG_OBS_REHOSP_RATE ~ NOAAC_PRECIPITATION_AVG_YEARLY, df_new)model2 <-lm(LTC_AVG_OBS_REHOSP_RATE ~ NOAAC_PRECIPITATION_AVG_YEARLY + ACS_PCT_MALE + ACS_PCT_FEMALE + ACS_PCT_AIAN + ACS_PCT_ASIAN + ACS_PCT_BLACK + ACS_PCT_HISPANIC + ACS_PCT_MULT_RACE + ACS_PCT_NHPI + ACS_PCT_OTHER_RACE + ACS_PCT_WHITE, df_new)model3 <-lm(LTC_AVG_OBS_REHOSP_RATE ~ NOAAC_PRECIPITATION_AVG_YEARLY + SAIPE_MEDIAN_HH_INCOME + SAIPE_PCT_POV + ACS_PCT_COMMT_60MINUP + ACS_PCT_RENTER_HU_COST_50PCT, df_new)model4 <-lm(LTC_AVG_OBS_REHOSP_RATE ~ NOAAC_PRECIPITATION_AVG_YEARLY + ACS_PCT_MALE + ACS_PCT_FEMALE + ACS_PCT_AIAN + ACS_PCT_ASIAN + ACS_PCT_BLACK + ACS_PCT_HISPANIC + ACS_PCT_MULT_RACE + ACS_PCT_NHPI + ACS_PCT_OTHER_RACE + ACS_PCT_WHITE + SAIPE_MEDIAN_HH_INCOME + SAIPE_PCT_POV + ACS_PCT_COMMT_60MINUP + ACS_PCT_RENTER_HU_COST_50PCT, df_new)```Let's plot this regression. We will employ log transformations for re-hospitalization rates, as it is skewed. ```{r}ggplot(df_new, aes(NOAAC_PRECIPITATION_AVG_YEARLY,log(LTC_AVG_OBS_REHOSP_RATE))) +geom_point(color ="#881c1c",alpha =0.3) +geom_smooth(method = lm,se =FALSE,fullrange =TRUE,color="#212721") +labs(title ="Simple Linear Regression Model, Precipitation Against Re-Hospitalization",x ="Average Annual Precipitation",y ="Re-Hospitalization Rates") +theme_bw()```We will reject the null hypothesis. While it looks like, at first glance, that there is little positive relationship, we can at least note that there is *some* positive relationship. In the next two sections, we will dig deeper into each model, examining the p-value, R-Squared value, and PRESS statistic to see what level of relationship is present.### Model ComparisonsNow we will compare the four (4) models in more depth.```{r}stargazer(model1, model2, model3, model4,type ="pdf",title ="Regression Results, Models 1 - 4",out ="models.pdf")summary(model1)summary(model2)summary(model3)summary(model4)```We want to look for two items in particular: 1) P-values that reach significant code of *** and 2) The highest Adjusted R-squared value.Model 1's `Precipitation` variable has the highest P-value compared to the other models, and the lowest Adjusted R-squared value.Model 2's significant variables are `Precipitation` and `Hispanic Rate.` However, the `Hispanic Rate` does not meet the significant code of ***. The Adjusted R-squared value is only slightly higher than Model 1.Model 3's significant variables are `Precipitation,``Percent Poverty,` and `Commuting.` However, neither `Percent Poverty` nor `Commuting` meet ***. The Adjusted R-squared value is close to Model 4, so it appears that the economic variables have a higher impact over socio-demographic measures.Model 4's significant variables are `Precipitation,``Percent Poverty,` and `Commuting.``Precipitation` has the lowest P-value of the four models here, and `Percent Poverty` meets the significance threshold of ***. The Adjusted R-squared value is the highest here, though only at 0.076.Finally, we're going to calculate the PRESS statistic (Predicted Residual Sum of Squares) to best determine which model can predict the response variable based upon the explanatory variables.```{r}PRESS <-function(model) { i <-residuals(model)/(1-lm.influence(model)$hat)sum(i^2)}PRESS(model1)PRESS(model2)PRESS(model3)PRESS(model4)```Model 3 has the lowest PRESS score, though Model 4 is not being calculated for some reason. This is probably due to an error with a socio-demographic variable.Due to a strong p-value, Adjusted R-squared value, and model fit compared to the other three models, Model 4 will be chosen as the final model for the diagnostic exploration. ### DiagnosticsFinally, we'll plot the diagnostics to best understand the model.```{r}par(mfrow =c(2,3));plot(model4, which =1:6) +theme_bw()ggsave("diagnostics.pdf",device ="pdf")```Of the six plots, Cook's distance is the most striking and relevant, as there are three out-liers: 683, 1345, and 1508.```{r}df_new %>%filter(COUNTYFIPS =="26097"| COUNTYFIPS =="46079"| COUNTYFIPS =="48385") %>%head()```683 is Mackinac County, Michigan, one of the most remote areas in the Great Lakes, with a population of 10,906.1345 is Mellette County, South Dakota, with a population of 1,908.1508 is Real County, Texas, a county with only one incorporated area and a population of 2,826.Otherwise, the plot looks good.Normal Q-Q violates this test, as the points at the right tail of the plot do not generally fall along the line. This is very apparent for our three out-liers. Cook's Distance vs. Leverage violates this test as well. The remaining plots do not violate their tested assumptions and further cement the model's reliability.## ConclusionThis paper explored the relationship between re-hospitalization rates and precipitation, when controlling for common variables that regularly influence the dependent variable.Four models were selected, one for each variable, to best determine which measure best impacted re-hospitalization rates. In all of the models, precipitation was statistically significant. While the adjusted R-squared value is negligible (0.076), there is a positive relationship that is statistically significant. Therein we see some form of an influence large amounts of annual precipitation has on re-hospitalization rates.## ReferencesBarnett, M., Hsu, J. & McWilliams, M. (2015). "Patient Characteristics and Differences in Hospital Readmission Rates." JAMA Intern Med., 175(11): 1803-1812.Bhosale KH, Nath RK, Pandit N, Agarwal P, Khairnar S, Yadav B, & Chandrakar S. (2020). "Rate of Rehospitalization in 60 Days of Discharge and It's Determinants in Patients with Heart Failure with Reduced Ejection Fraction in a Tertiary Care Centre in India." Int J Heart Fail. 21;2(2):131-144.Li, Y., Cai, X. & Glance, L. (2015). "Disparities in 30-day rehospitalization rates among Medicare skilled nursing facility residents by race and site of care." Med Care, 53(12): 1058-1065.Murray, F., Allen, M., Clark, C., Daly, C. & Jacobs, D. (2021). "Socio-demographic and -economic factors associated with 30-day readmission for conditions targeted by the hospital readmissions reduction program: a population-based study." BMC Public Health, 21.Rizmie, D., Preuz, L., Miraldo, M. & Atun, R. (2022). "Impact of extreme temperatures on emergency hospital admissions by age and socio-economic deprivation in England." Social Science & Medicine, 308.Tapak, L., Maryanaji, Z., Hamidi, O., Abbasi, H. & Najafi-Vosough, R. (2018). "Investigating the effect of climatic parameters on mental disorder admissions." International Journal of Biometerology, 62, 2109-2118.Trinh, T., Feeny, S. & Posso, A. (2018). "Rainfall shocks and child health: the role of parental mental health." Climate and Development, 13(1), 34-48.Spatz, E., Bernheim, S., Horwitz, L. & Herrin, J. (2020). Community factors and hospital wide readmission rates: Does context matter? PLoS One, 15(10).