#I have added my analyses on to my initial template from Part 1 - I hope this is what you had envisioned for this assignment
Research Question
Affective polarization describes a heightened state of animosity between partisans that has steadily grown from the 1970s to today (Iyengar et al., 2019). Identifying antecedents of affective polarization is essential to creating intervention strategies into this negative state of politics. Levendusky (2009) proposes a social model where individuals making sense of simplified elite cues enables people to understand the relevant identities of the political landscape, which may lead to downstream affective polarization. I intend to expand on this model, testing a construct of construal level, or the level of abstraction to concreteness (Trope & Liberman, 2010) with which partisans perceive partisan groups and group cues. This levels varies in how individuals describe different constructs as having more concrete or abstract characteristics, such as mentioning specific groups as opposed to vague ideological concepts (view the Appendix at the bottom for more information on how this was qualitatively coded). Prior studies suggest that lower construal may serve as an antecedent to affective polarization when partisans view issues in more concrete, group terms (Snyder, Unpublished). This study will expand these models into extant, large scale, political science datasets. Additionally, this project will employ supervised machine learning models to qualitatively code a large-n sample of free response questions.
Hypotheses
I hypothesize that partisans who are qualitatively coded as having a lower construal level will demonstrate higher levels of group/affective polarization, as measured on a feeling thermometer or measures of feelings about political groups - whichever is available in the datasets.
I hypothesize that using a sentiment analysis, these tendencies may be moderated by valence of their free response, with stronger valence enhancing the effect of construal level on affective polarization - valence being the psychological term for positive vs negative sentiment.
Datasets
I intend to use UMass Poll, ANES, and Polarization Research Lab datasets for my studies. UMass Poll data will be used for Study 1, which is shown in the initial analyses here. Studies 2 and 3 will include data (that will be collected later in November) obtained from an accepted application for survey space from Dartmouth’s Polarization Research Lab. ANES data, specifically the free response questions in 1992, will be used to compare the qualitative coding results of the free responses to Mason’s social sorting measures. I hope you will forgive me not having all of these results right now, as I will need to hand code 2000+ cases before these studies are over, and some of the data has not been collected yet, but should be before the Final Project is due.
#Analyses As mentioned in the previous section, initial analyses have been performed to test the first hypothesis. UMass Poll data has been qualitatively coded and analyzed for this purpose. In order to measure the effectiveness of the qualitative coding, multiple models and portions of variables were compared.
Rows: 815 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Response
dbl (4): Resp#, Who, How, model1
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Code
dCode <-read_csv("qualCodingCRTno99.csv")
New names:
Rows: 815 Columns: 6
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," chr
(1): Who, shows a concrete understanding of group information dbl (4):
respondent, Who, How, model1 lgl (1): ...5
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...5`
#Represents very high interrater reliability for bothplot(model1)
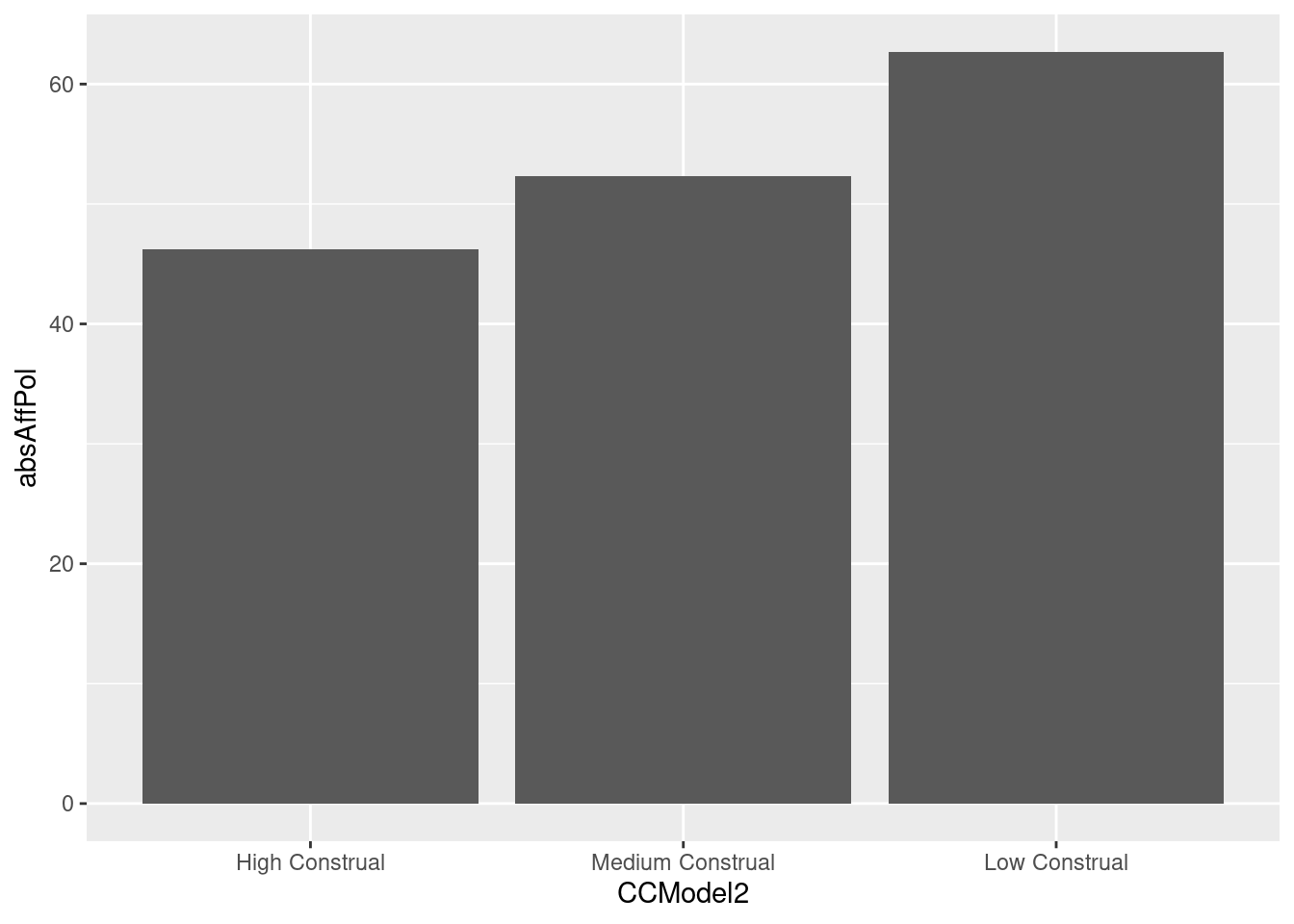
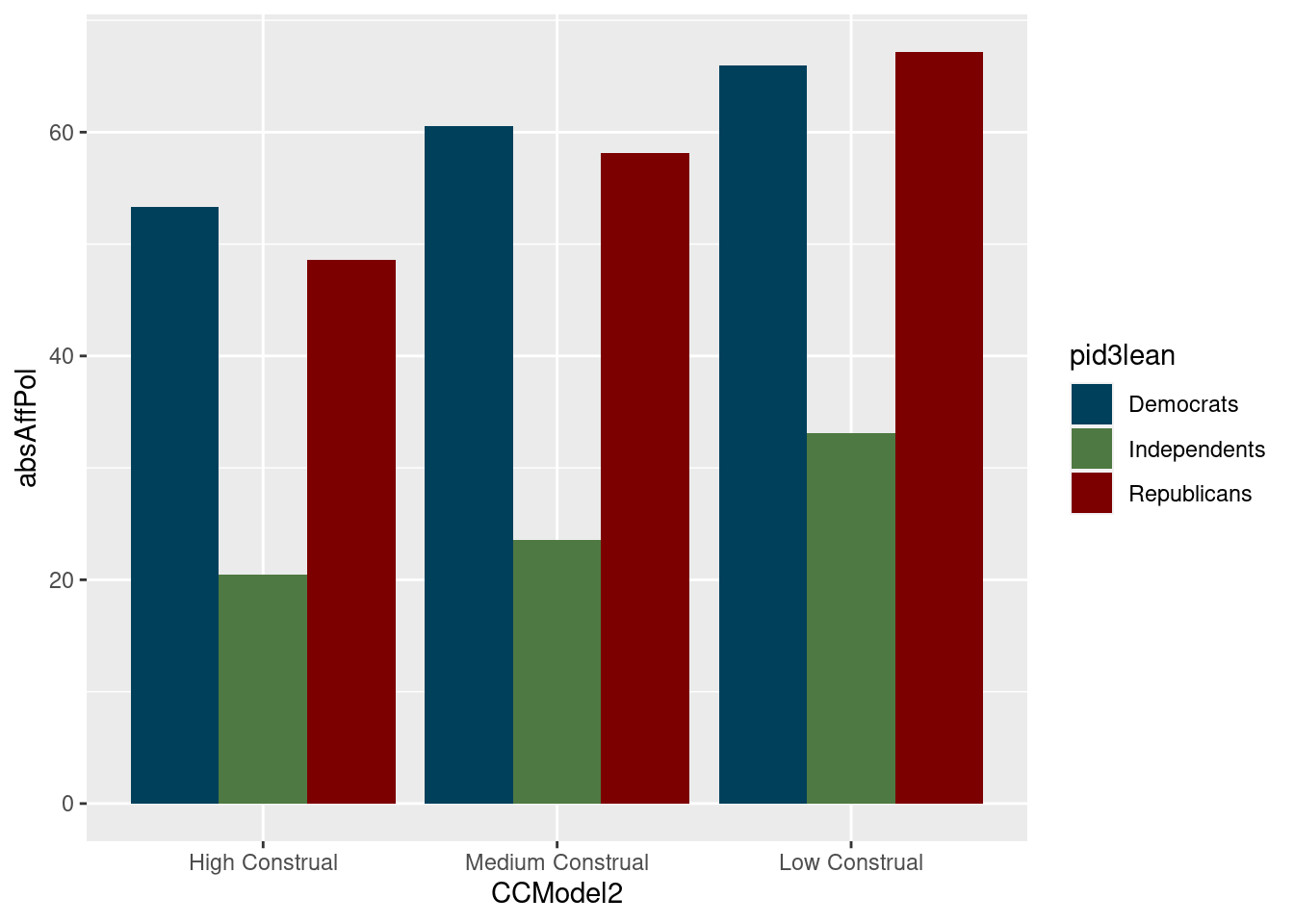
#Choosing the Final Model The Final model (model 1), was chosen because it represents the highest amount of explanatory power. CCModel represents a variable where the presence of one or the other (who or how variable) is categorically represented, CCModel2 is a numeric representation that includes the variance that both variables explain. It is important to note that in the code, low construal represents a higher number (2), medium construal represents a middle number (1), and high construal represents the lowest number (0). absAffectivePolarization acts as an affective polarization, subtracting the highest value of feeling thermometer rating from the lowest rating, putting democrat respondents and republican respondents on the same y axis. For affective polarization, the minimum value is 0, maximum value is 100. For CCModel, it is 0 or 1. For CCModel2 it is 0,1, or 2. Model 1 is the most significant of any of the variables, and this significance does not disappear when put into a multiple regression model with other explanatory variables, both of Affective Polarization and of other qualitative coding models/combinations. Both the “Who” and “How” aspects of the qualitative coding are shown to independently capture portions of what we operationalize as construal level, which is shown to relate to downstream affective polarization. In future studies, I will also test additional qualitative coding models, as this model is most applicable to the vague UMass Poll question of issue-oriented responses to critical race theory. In this first model, valence is partially coded for in the “how” term, which is why a sentiment analysis has not been performed yet for this Study. In subsequent models in Studies 2 and 3, this will be examined in tandem with an alternative potential coding scheme.
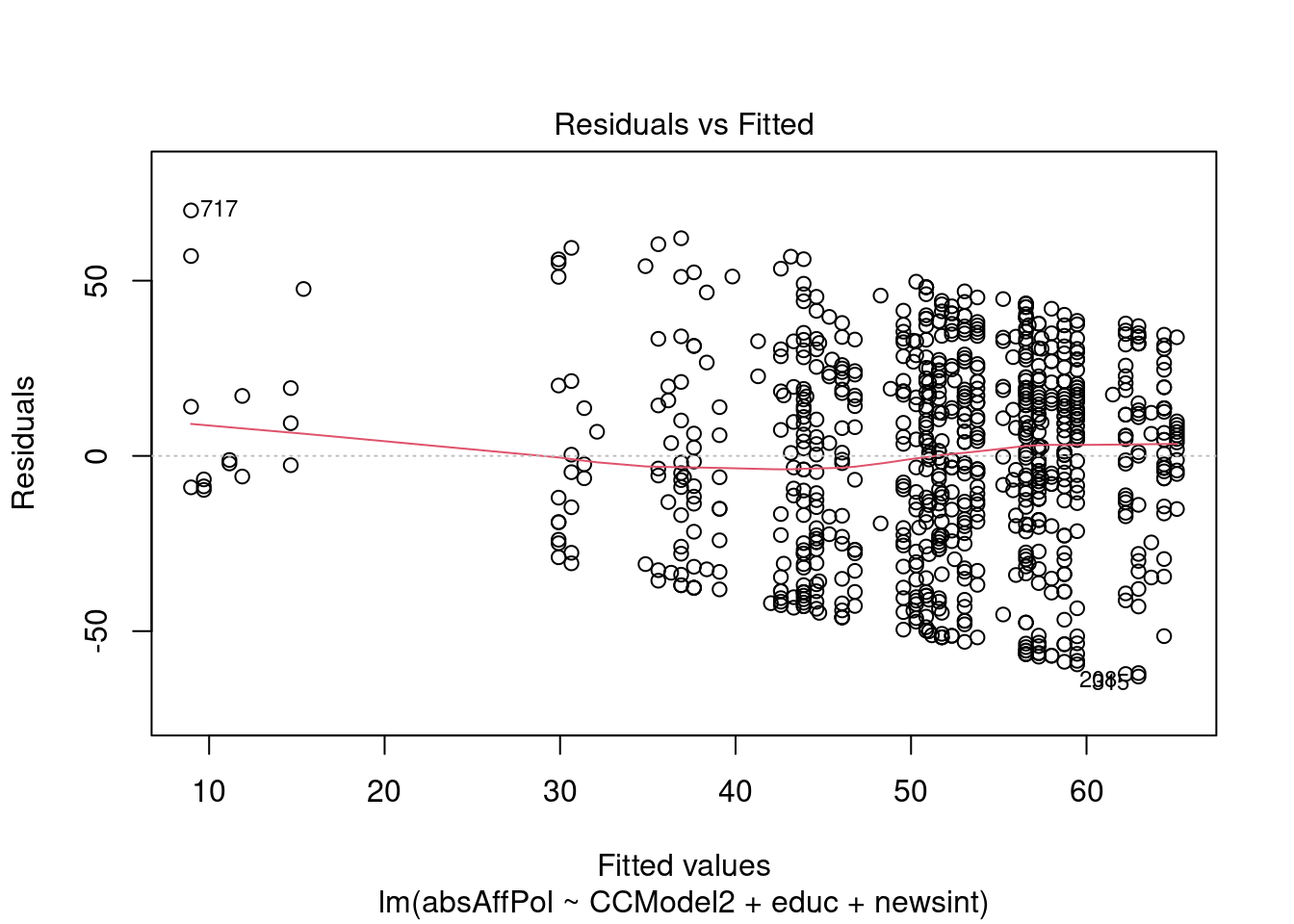
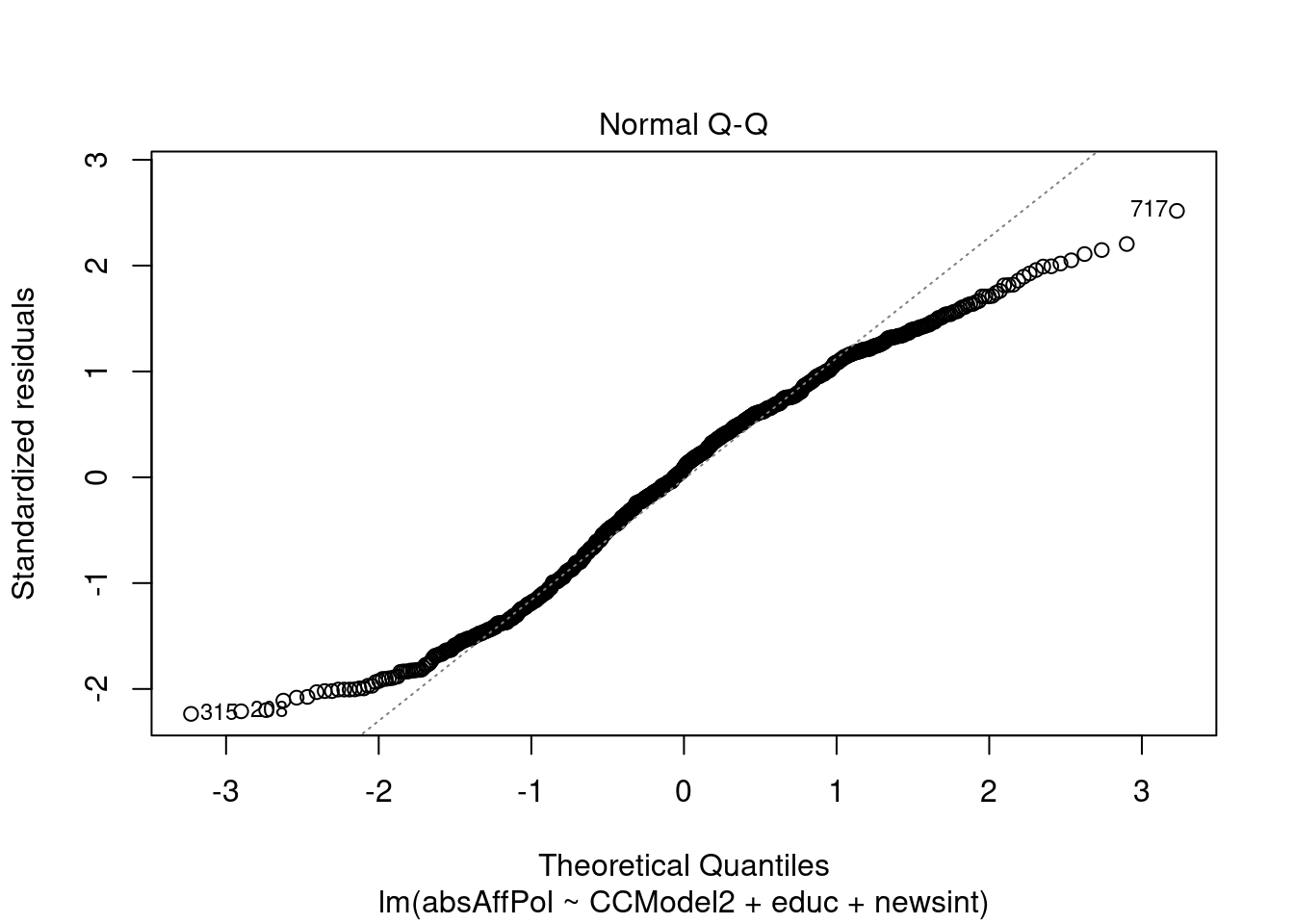
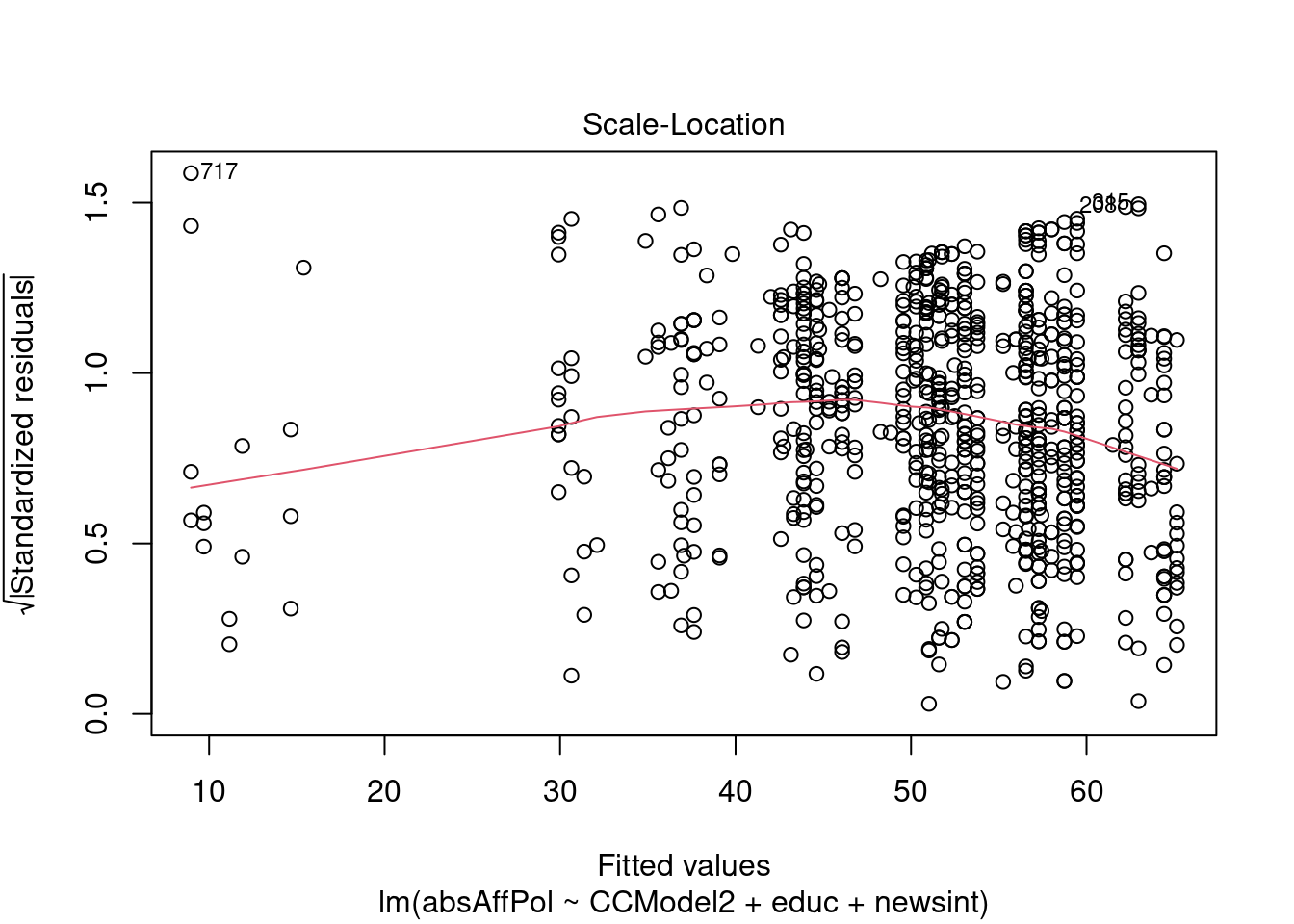
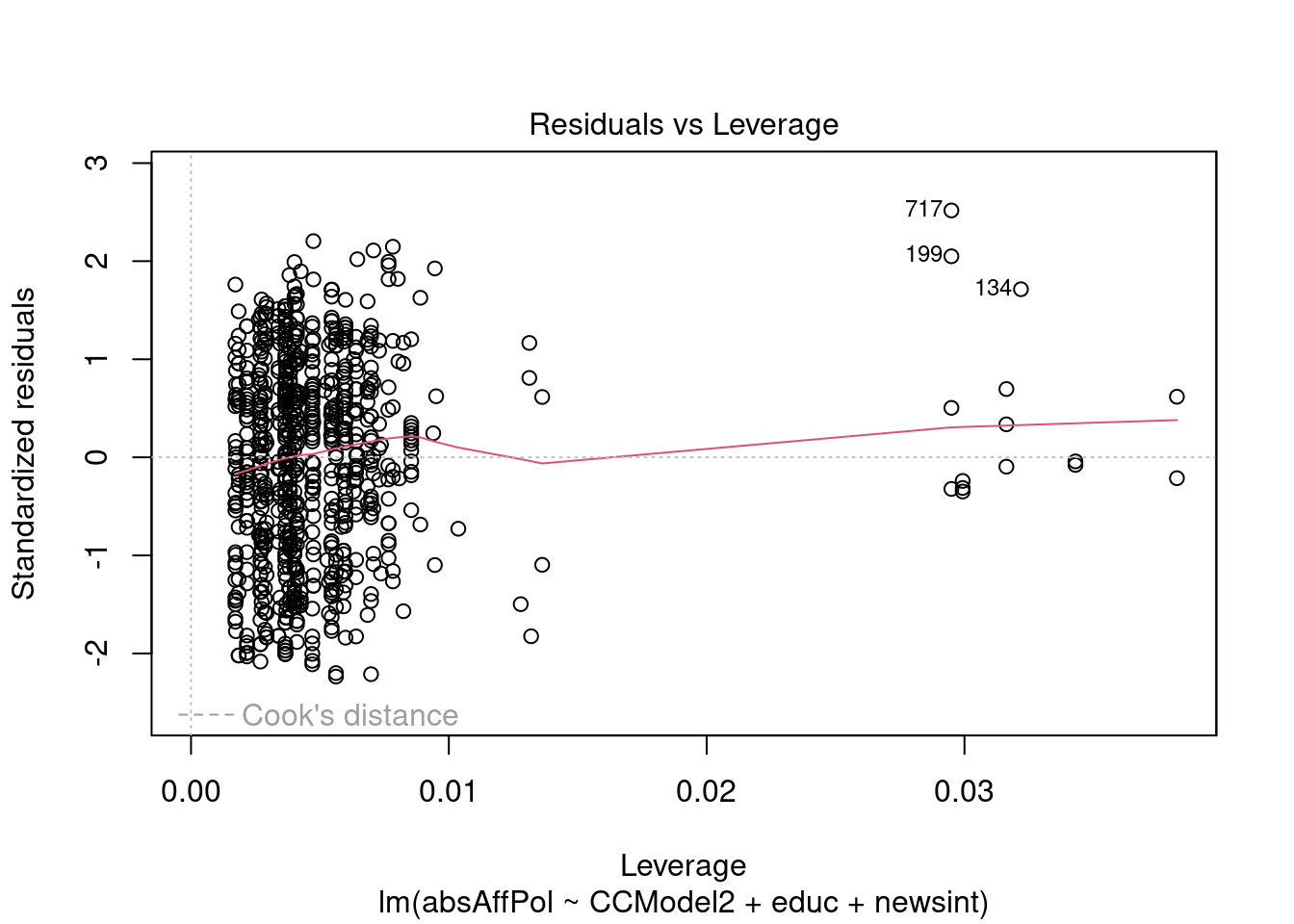
##Diagnostics Analyzing the plots, these diagnostics appear to make sense. Looking at the residuals vs fitted graph, the horizontal line without patterns indicates a linear relationship, which is a good result for our model. The Q-Q plot also tends to follow the dashed line, which means that the residuals are relatively normally distributed. The scale location plot suggests that most of the points are relatively equally spread, though there is perhaps a bit of negative skew. The residuals vs leverage plot is perhaps the most problematic plot, as there are some outliers that may be influencing the data, but it is not just one or two, more like several, and this may just be that the scale is rather small. Generally these diagnostics tend to show success with the model.
References
Iyengar, S., Lelkes, Y., Levendusky, M., Malhotra, N., & Westwood, S. J. (2019). The origins and consequences of affective polarization in the United States. Annual Review of Political Science, 22(1), 129-146. Levendusky, M. (2009). The partisan sort: How liberals became Democrats and conservatives became Republicans. University of Chicago Press. Snyder, D. (2022). Keep It Simple Stupid: How Individual Differences in Cue Construal Explain Variations in Affective Polarization. Unpublished Manuscript Trope, Y., & Liberman, N. (2010). Construal-level theory of psychological distance. Psychological review, 117(2), 440.
#Appendix: Qualitative Coding Instructions for Raters Construal Level Theory Qualitative Coding Key
The purpose of this task is to get an understanding of how clear respondents’ perceptions of the political landscape are, thorough the lens of how they interpret abstract issues. To operationalize this for the current task, you will be qualitatively coding along two dimensions – “Who” and “How”. Each of these dimensions will be coded as either a 1 or a 0. This is taken from the Critical Race Theory data, although the measurement does not apply to CRT in particular, it is somewhat unrelated.
“Who” Overview: The purpose of coding this “Who” construct is to understand how clearly people perceive the groups involved in political issues. A “1” for this will involve a specific group mentioned. A specific group involves a group name that cannot be interpreted in multiple ways. This includes any concrete demographic.
Who “1” examples: Mention of… “Democrats”, “Republicans”, “Marxists”, “Kids”, “Blacks”, “Whites”, “Teachers”… any other instances where it is expressly clear that they are referring to a specific group.
If there is even one occurrence of any of these in the free response, it should be coded as “1.”
Who “0” examples: No groups mentioned, or groups are only mentioned in the abstract. Examples of groups mentioned in the abstract: “People of Color”, “Certain groups of people.”
If there is no specific group information, or only abstract groups, or they respond “I don’t know”, “Who” should be coded as a “0.”
“How” Overview: The purpose of coding this “How” construct is to understand whether respondents will try to provide information about their own perspectives to the reader, despite this not being the purpose of the task, which was to “Define critical race theory.”
How “1” coding: If you code a response as a “1” for “How”, it should be from a “yes” answer to one or both of these two questions; 1. Does the respondent mention how they personally feel about the merit of Critical Race Theory? 2. Is the respondent trying to suggest to you how you should feel about the merit of Critical Race Theory? This includes both positive and negative perspectives about Critical Race Theory.
How “0” Coding: A “How” “0” should be a response that merely attempts to define, and not provide a description of how the respondent feels about critical race theory.
Source Code
---title: "Final Project Part 2"author: "Donny Snyder"desription: "Part 2 of Final Paper project"date: "12/20/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - finalpart2---```{r}library(ggplot2)library(haven)library(pollster)library(dplyr)library(knitr)library(foreign)library(scales)library(questionr)library(tidyverse)library(tibble)library(extrafont)library(tidyr)library(readr)library(irr)```#I have added my analyses on to my initial template from Part 1 - I hope this is what you had envisioned for this assignment## Research QuestionAffective polarization describes a heightened state of animosity between partisans that has steadily grown from the 1970s to today (Iyengar et al., 2019). Identifying antecedents of affective polarization is essential to creating intervention strategies into this negative state of politics. Levendusky (2009) proposes a social model where individuals making sense of simplified elite cues enables people to understand the relevant identities of the political landscape, which may lead to downstream affective polarization. I intend to expand on this model, testing a construct of construal level, or the level of abstraction to concreteness (Trope & Liberman, 2010) with which partisans perceive partisan groups and group cues. This levels varies in how individuals describe different constructs as having more concrete or abstract characteristics, such as mentioning specific groups as opposed to vague ideological concepts (view the Appendix at the bottom for more information on how this was qualitatively coded). Prior studies suggest that lower construal may serve as an antecedent to affective polarization when partisans view issues in more concrete, group terms (Snyder, Unpublished). This study will expand these models into extant, large scale, political science datasets. Additionally, this project will employ supervised machine learning models to qualitatively code a large-n sample of free response questions.## HypothesesI hypothesize that partisans who are qualitatively coded as having a lower construal level will demonstrate higher levels of group/affective polarization, as measured on a feeling thermometer or measures of feelings about political groups - whichever is available in the datasets.I hypothesize that using a sentiment analysis, these tendencies may be moderated by valence of their free response, with stronger valence enhancing the effect of construal level on affective polarization - valence being the psychological term for positive vs negative sentiment.## DatasetsI intend to use UMass Poll, ANES, and Polarization Research Lab datasets for my studies. UMass Poll data will be used for Study 1, which is shown in the initial analyses here. Studies 2 and 3 will include data (that will be collected later in November) obtained from an accepted application for survey space from Dartmouth's Polarization Research Lab. ANES data, specifically the free response questions in 1992, will be used to compare the qualitative coding results of the free responses to Mason's social sorting measures. I hope you will forgive me not having all of these results right now, as I will need to hand code 2000+ cases before these studies are over, and some of the data has not been collected yet, but should be before the Final Project is due.#AnalysesAs mentioned in the previous section, initial analyses have been performed to test the first hypothesis. UMass Poll data has been qualitatively coded and analyzed for this purpose. In order to measure the effectiveness of the qualitative coding, multiple models and portions of variables were compared.```{r}#Clean Datadoto <-read_sav("12_21_Data.sav")caitCode <-read_csv("CaitlynQualCodingCP.csv")dCode <-read_csv("qualCodingCRTno99.csv")doto <-subset(doto, doto$Q33_open !="__NA__")Rdoto <-subset(doto, doto$pid3lean =="Republicans")Ddoto <-subset(doto, doto$pid3lean =="Democrats")Idoto <-subset(doto, doto$pid3lean =="Independents")doto$affPol <- doto$Q10_democrats - doto$Q10_republicansdoto$CCModel2 <- caitCode$model1caitCode$whoOrHow <-recode(caitCode$model1, "0"="0", .default ="1")doto$CCModel <- caitCode$whoOrHowdoto$absAffPol <-abs(doto$affPol)doto$dummy <-rep("Dummy", 815)data <-aggregate(absAffPol ~ CCModel2, doto, mean)partyData <-aggregate(absAffPol ~ CCModel2 + pid3lean, doto, mean)partyData <- partyData[-(1:3),]data$CCModel2 <-recode(data$CCModel2, "2"="Low Construal", "1"="Medium Construal", "0"="High Construal")data$CCModel2 <-factor(data$CCModel2, levels =c("High Construal", "Medium Construal", "Low Construal"))partyData$CCModel2 <-recode(partyData$CCModel2, "2"="Low Construal", "1"="Medium Construal", "0"="High Construal")partyData$CCModel2 <-factor(partyData$CCModel2, levels =c("High Construal", "Medium Construal", "Low Construal"))#Plot Dataggplot(data = data, aes(x = CCModel2, y = absAffPol)) +geom_bar(stat ="identity")ggplot(data = partyData, aes(x = CCModel2, y = absAffPol, fill = pid3lean)) +geom_bar(stat ="identity", position ="dodge") +scale_fill_manual(values =c("Democrats"="#00405b", "Independents"="#4F7942", "Republicans"="#7d0000")) #comparison of regression models (1 is the best model)model1 <-lm(formula = absAffPol ~ CCModel2 + educ + newsint, data = doto)summary(model1)model2 <-lm(formula = absAffPol ~ CCModel2, data = doto)summary(model2)model3 <-lm(formula = absAffPol ~ CCModel, data = doto)summary(model3)model4 <-lm(formula = absAffPol ~ CCModel2 + CCModel, data = doto)summary(model4)#checking for interrater reliability of qualitative codingirrCheck <-cbind(caitCode$Who, caitCode$How, dCode$Who, dCode$How)irrCheck <-as.data.frame(irrCheck)kappa2(irrCheck[,c(1,3)], "unweighted")kappa2(irrCheck[,c(2,4)], "unweighted")#Represents very high interrater reliability for bothplot(model1)```#Choosing the Final ModelThe Final model (model 1), was chosen because it represents the highest amount of explanatory power. CCModel represents a variable where the presence of one or the other (who or how variable) is categorically represented, CCModel2 is a numeric representation that includes the variance that both variables explain. It is important to note that in the code, low construal represents a higher number (2), medium construal represents a middle number (1), and high construal represents the lowest number (0). absAffectivePolarization acts as an affective polarization, subtracting the highest value of feeling thermometer rating from the lowest rating, putting democrat respondents and republican respondents on the same y axis. For affective polarization, the minimum value is 0, maximum value is 100. For CCModel, it is 0 or 1. For CCModel2 it is 0,1, or 2. Model 1 is the most significant of any of the variables, and this significance does not disappear when put into a multiple regression model with other explanatory variables, both of Affective Polarization and of other qualitative coding models/combinations. Both the "Who" and "How" aspects of the qualitative coding are shown to independently capture portions of what we operationalize as construal level, which is shown to relate to downstream affective polarization. In future studies, I will also test additional qualitative coding models, as this model is most applicable to the vague UMass Poll question of issue-oriented responses to critical race theory. In this first model, valence is partially coded for in the "how" term, which is why a sentiment analysis has not been performed yet for this Study. In subsequent models in Studies 2 and 3, this will be examined in tandem with an alternative potential coding scheme. ##DiagnosticsAnalyzing the plots, these diagnostics appear to make sense. Looking at the residuals vs fitted graph, the horizontal line without patterns indicates a linear relationship, which is a good result for our model. The Q-Q plot also tends to follow the dashed line, which means that the residuals are relatively normally distributed. The scale location plot suggests that most of the points are relatively equally spread, though there is perhaps a bit of negative skew. The residuals vs leverage plot is perhaps the most problematic plot, as there are some outliers that may be influencing the data, but it is not just one or two, more like several, and this may just be that the scale is rather small. Generally these diagnostics tend to show success with the model.## ReferencesIyengar, S., Lelkes, Y., Levendusky, M., Malhotra, N., & Westwood, S. J. (2019). The origins and consequences of affective polarization in the United States. Annual Review of Political Science, 22(1), 129-146.Levendusky, M. (2009). The partisan sort: How liberals became Democrats and conservatives became Republicans. University of Chicago Press.Snyder, D. (2022). Keep It Simple Stupid: How Individual Differences in Cue Construal Explain Variations inAffective Polarization. Unpublished ManuscriptTrope, Y., & Liberman, N. (2010). Construal-level theory of psychological distance. Psychological review, 117(2), 440.#Appendix: Qualitative Coding Instructions for RatersConstrual Level Theory Qualitative Coding KeyThe purpose of this task is to get an understanding of how clear respondents’ perceptions of the political landscape are, thorough the lens of how they interpret abstract issues. To operationalize this for the current task, you will be qualitatively coding along two dimensions – “Who” and “How”. Each of these dimensions will be coded as either a 1 or a 0. This is taken from the Critical Race Theory data, although the measurement does not apply to CRT in particular, it is somewhat unrelated.“Who” Overview: The purpose of coding this “Who” construct is to understand how clearly people perceive the groups involved in political issues. A “1” for this will involve a specific group mentioned. A specific group involves a group name that cannot be interpreted in multiple ways. This includes any concrete demographic.Who “1” examples: Mention of… “Democrats”, “Republicans”, “Marxists”, “Kids”, “Blacks”, “Whites”, “Teachers”… any other instances where it is expressly clear that they are referring to a specific group.If there is even one occurrence of any of these in the free response, it should be coded as “1.”Who “0” examples: No groups mentioned, or groups are only mentioned in the abstract. Examples of groups mentioned in the abstract: “People of Color”, “Certain groups of people.”If there is no specific group information, or only abstract groups, or they respond “I don’t know”, “Who” should be coded as a “0.”“How” Overview: The purpose of coding this “How” construct is to understand whether respondents will try to provide information about their own perspectives to the reader, despite this not being the purpose of the task, which was to “Define critical race theory.”How “1” coding: If you code a response as a “1” for “How”, it should be from a “yes” answer to one or both of these two questions; 1. Does the respondent mention how they personally feel about the merit of Critical Race Theory? 2. Is the respondent trying to suggest to you how you should feel about the merit of Critical Race Theory? This includes both positive and negative perspectives about Critical Race Theory.How “0” Coding: A “How” “0” should be a response that merely attempts to define, and not provide a description of how the respondent feels about critical race theory.