Churning refers to a customer who leaves one company to go to another company. Customer churn introduces not only some loss in income but also other negative effects on the operation of companies. Churn management is the concept of identifying those customers who are intending to move their custom to a competing service provider.
Risselada et al. (2010) stated that churn management is becoming part of customer relationship management. It is important for companies to consider it as they try to establish long-term relationships with customers and maximize the value of their customer base.
Research Questions
A. Does churn-rate depend on the geographical factors(Customer’s location) of the customer?
B. Do non-active members are probable to churn or not?
This project will be useful to better understand more about the customer difficulties and factors and also give us a pretty good idea on the factors effecting the customers to exit and also about the dormant state of the customers.
Hypothesis
Customer churn analysis has become a major concern in almost every industry that offers products and services. The model developed will help banks identify clients who are likely to be churners and develop appropriate marketing actions to retain their valuable clients. And this model also supports information about similar customer group to consider which marketing reactions are to be provided. Thus, due to existing customers are retained, it will provide banks with increased profits and revenues. By the end of this project, let’s attempt to solve some of the key business challenges pertaining to customer attrition like say, (1) what is the likelihood of an active customer leaving an organization? (2) what are key indicators of a customer churn? (3) what retention strategies can be implemented based on the results to diminish prospective customer churn?
Given the above, we can frame our hypotheses as follows:
H0A
Customer’s location will not be able to predict the churn-rate.
H1A
Customer’s location will be able to predict the churn-rate.
I believe that the customer’s location have an effect on customer’s churn rate as based on location there is difference in customer’s salary and balance.
H0B
Inactive members will not churn.
H1B
Inactive members will churn.
I think that inactive members are more likely to exit rather than active members as there is a high chance of them churning out as they are are inactive for a longtime.
Rows: 10000 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Surname, Geography, Gender
dbl (11): RowNumber, CustomerId, CreditScore, Age, Tenure, Balance, NumOfPro...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Code
Churn
This data set is originated from a U.S. bank and is downloaded from kaggle. This data set includes 10k bank customer data records with 14 attributes including socio-demographic attributes, account level and behavioral attributes.
Attribute Description
Row Number- Number of customers
Customer ID- ID of customer 3.Surname- Customer name
Credit Score- Score of credit card usage
Geography- Location of customer
Gender- Customer gender
Age- Age of Customer
Tenure- The period of having the account in months
Balance- Customer main balance
NumOfProducts- No of products used by customer(No of accounts the customer have)
HasCrCard- If the customer has a credit card or not
IsActiveMember- Customer account is active or not(if he haven’t used his savings or current account for any transactions for over 1 year, then he is treated as inactive.)
Estimated Salary- Estimated salary of the customer.
Exited- Indicate churned or not, i.e, if the customer left the bank or not.
The response variable is Exited variable and the main explanatory variables are Geography and IsActiveMember. And the other explanatory variables are Credit Score, Gender, Age and Balance.
RowNumber CustomerId Surname CreditScore
Min. : 1 Min. :15565701 Length:10000 Min. :350.0
1st Qu.: 2501 1st Qu.:15628528 Class :character 1st Qu.:584.0
Median : 5000 Median :15690738 Mode :character Median :652.0
Mean : 5000 Mean :15690941 Mean :650.5
3rd Qu.: 7500 3rd Qu.:15753234 3rd Qu.:718.0
Max. :10000 Max. :15815690 Max. :850.0
Geography Gender Age Tenure
Length:10000 Length:10000 Min. :18.00 Min. : 0.000
Class :character Class :character 1st Qu.:32.00 1st Qu.: 3.000
Mode :character Mode :character Median :37.00 Median : 5.000
Mean :38.92 Mean : 5.013
3rd Qu.:44.00 3rd Qu.: 7.000
Max. :92.00 Max. :10.000
Balance NumOfProducts HasCrCard IsActiveMember
Min. : 0 Min. :1.00 Min. :0.0000 Min. :0.0000
1st Qu.: 0 1st Qu.:1.00 1st Qu.:0.0000 1st Qu.:0.0000
Median : 97199 Median :1.00 Median :1.0000 Median :1.0000
Mean : 76486 Mean :1.53 Mean :0.7055 Mean :0.5151
3rd Qu.:127644 3rd Qu.:2.00 3rd Qu.:1.0000 3rd Qu.:1.0000
Max. :250898 Max. :4.00 Max. :1.0000 Max. :1.0000
EstimatedSalary Exited
Min. : 11.58 Min. :0.0000
1st Qu.: 51002.11 1st Qu.:0.0000
Median :100193.91 Median :0.0000
Mean :100090.24 Mean :0.2037
3rd Qu.:149388.25 3rd Qu.:0.0000
Max. :199992.48 Max. :1.0000
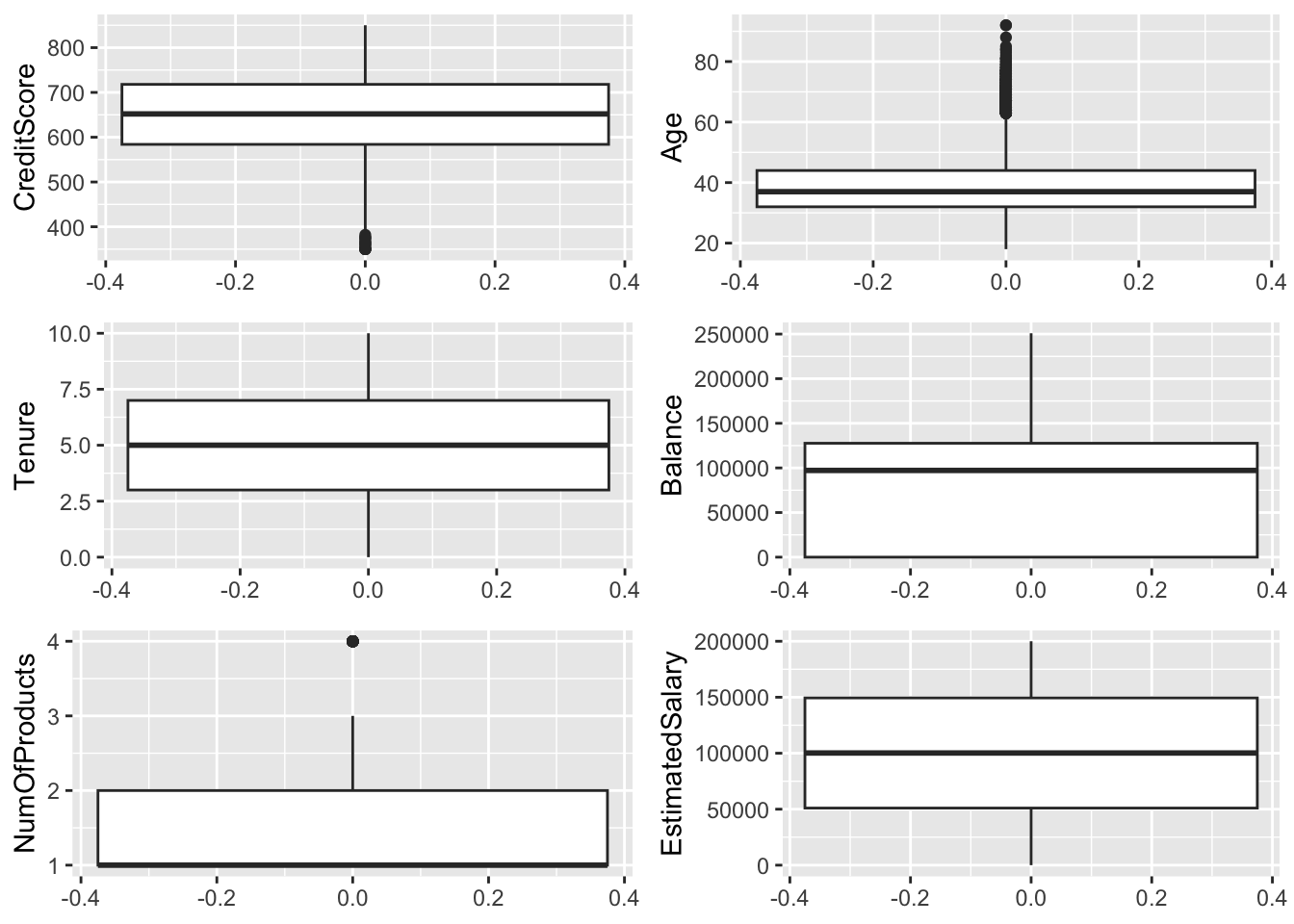
From above box plot, Credit score variable has few outliers, and Age variable has highest no of outliers (age above have 60 constitutes outliers), however these are only few outliers and they cannot potentially effect the data set. Tenure, Balance, NumofProducts and EstimatedSalary variables have no outliers.
Visualing and interpreting the variables
Code
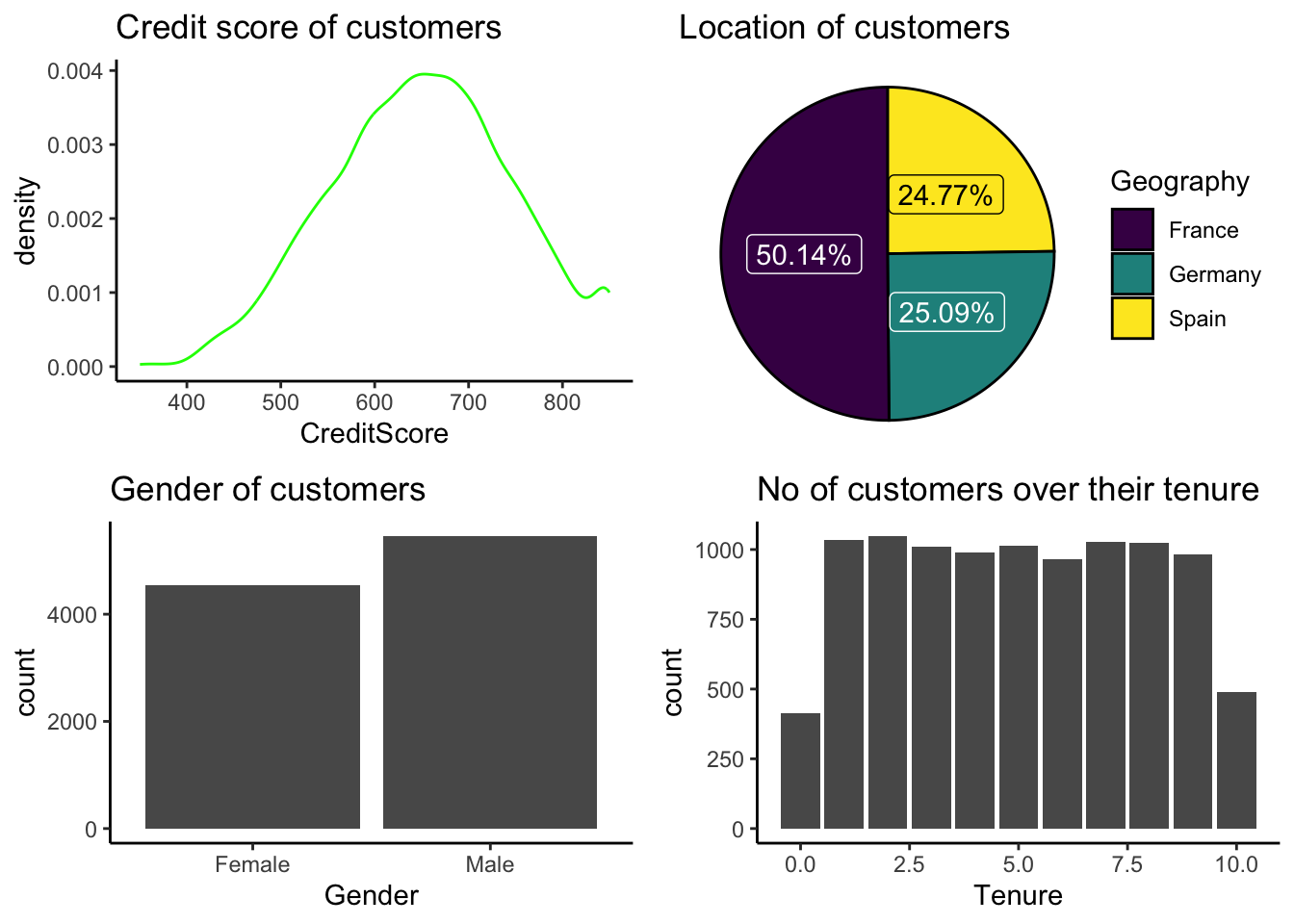
p1 <- Churn %>%ggplot(aes(CreditScore)) +geom_density(color="Green", alpha=0.8) +ggtitle("Credit score of customers") +theme_classic()p2 <- Churn %>%group_by(Geography) %>%# Variable to be transformedcount() %>%ungroup() %>%mutate(perc =`n`/sum(`n`)) %>%arrange(perc) %>%mutate(labels = scales::percent(perc)) %>%ggplot(aes(x ="", y = perc, fill = Geography)) +ggtitle("Location of customers") +geom_col(color ="black") +geom_label(aes(label = labels), color =c(1, "white", "white"),position =position_stack(vjust =0.5),show.legend =FALSE) +guides(fill =guide_legend(title ="Geography")) +scale_fill_viridis_d() +coord_polar(theta ="y") +theme_void()p3 <- Churn %>%ggplot() +geom_bar(aes(Gender)) +ggtitle("Gender of customers") +theme_classic()p4 <- Churn %>%ggplot() +geom_bar(aes(Tenure)) +theme_classic() +ggtitle("No of customers over their tenure")grid.arrange(arrangeGrob(p1, p2, ncol =2), arrangeGrob(p3, p4, ncol =2),nrow =2)
From the above plot, the credit score is looking to be normal with median in range of 650-700, and Geography variable consists of 3 values, i.e, France(50%), Germany(25%) and Spain(25%). The Gender variable consists of Male and Female values and male count(5457) is more than female count(4543). The tenure of all customers is between 0-10 years and is almost equal no of customers in each year.
Code
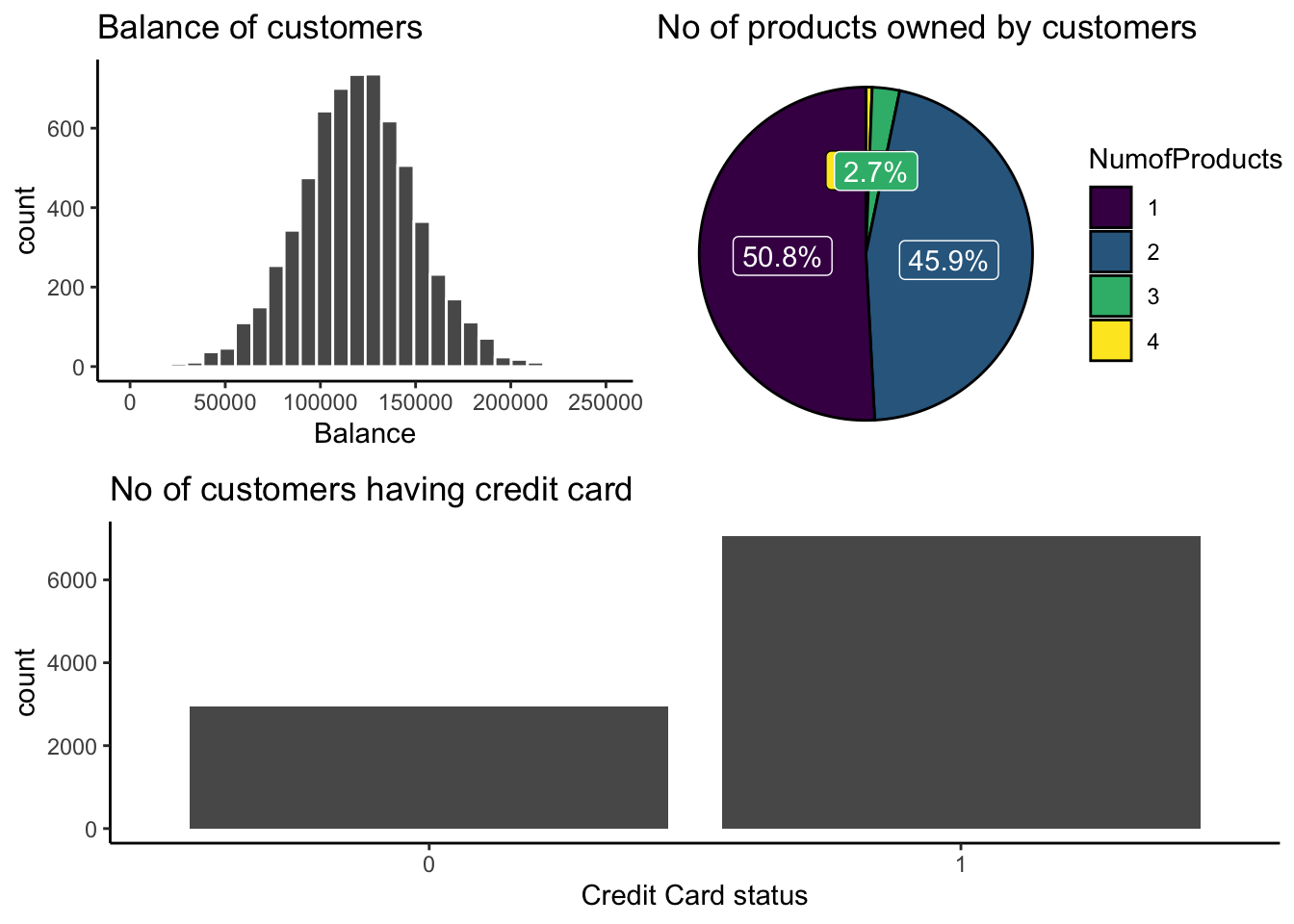
p5 <- Churn %>%filter(Balance !=0) %>%ggplot(aes(Balance)) +geom_histogram(col ="white", bins =30) +theme_classic() +ggtitle("Balance of customers")p6 <- Churn %>%group_by(NumOfProducts) %>%# Variable to be transformedcount() %>%ungroup() %>%mutate(perc =`n`/sum(`n`)) %>%arrange(perc) %>%mutate(labels = scales::percent(perc)) %>%ggplot(aes(x ="", y = perc, fill =as.factor(NumOfProducts))) +ggtitle("No of products owned by customers") +geom_col(color ="black") +geom_label(aes(label = labels), color =c(1, "white", "white", "white"),position =position_stack(vjust =0.5),show.legend =FALSE) +guides(fill =guide_legend(title ="NumofProducts")) +scale_fill_viridis_d() +coord_polar(theta ="y") +theme_void()p7 <- Churn %>%ggplot() +geom_bar(aes(as.factor(HasCrCard))) +ggtitle("No of customers having credit card") +xlab("Credit Card status") +theme_classic()grid.arrange(arrangeGrob(p5, p6, ncol =2), p7,nrow =2)
We have a lot of people with balance as zero but if we ignore as in the above plot that the other values form a normal at 120000 in median, and according to above plot, the maximum no of the products owned by customers is 1 and minimum is 4. Majority of customers own either 1 or 2 products. And according to bar graph, 7055 customers have credit card and 2945 customers does not have credit card.
Code
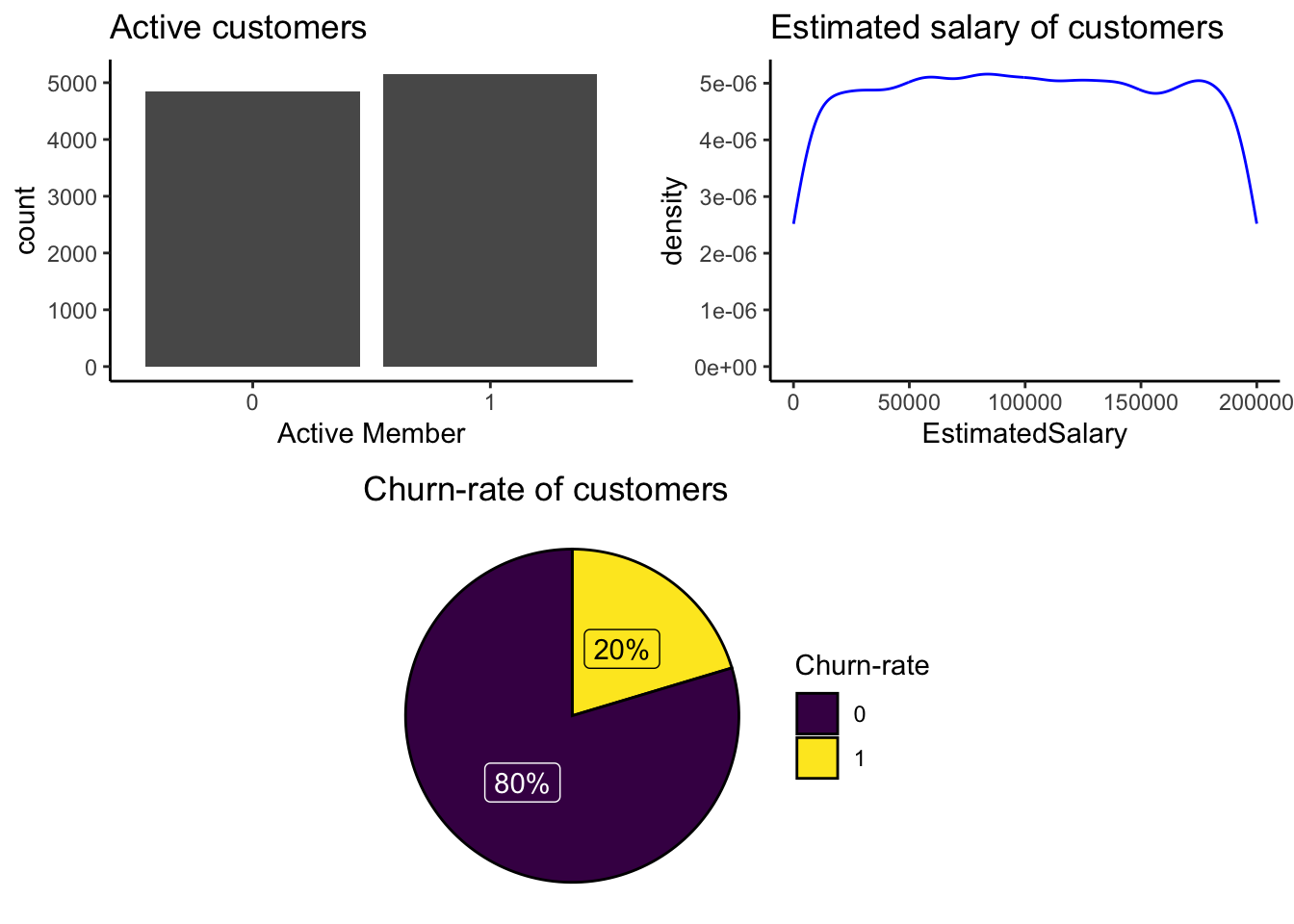
p8 <- Churn %>%ggplot() +geom_bar(aes(as.factor(IsActiveMember))) +ggtitle("Active customers") +xlab("Active Member") +theme_classic()p9 <- Churn %>%ggplot(aes(EstimatedSalary)) +geom_density(color="Blue", alpha=0.8) +ggtitle("Estimated salary of customers") +theme_classic()p10 <- Churn %>%group_by(Exited) %>%# Variable to be transformedcount() %>%ungroup() %>%mutate(perc =`n`/sum(`n`)) %>%arrange(perc) %>%mutate(labels = scales::percent(perc)) %>%ggplot(aes(x ="", y = perc, fill =as.factor(Exited))) +ggtitle("Churn-rate of customers") +geom_col(color ="black") +geom_label(aes(label = labels), color =c(1, "white"),position =position_stack(vjust =0.5),show.legend =FALSE) +guides(fill =guide_legend(title ="Churn-rate")) +scale_fill_viridis_d() +coord_polar(theta ="y") +theme_void()grid.arrange(arrangeGrob(p8, p9, ncol =2), p10,nrow =2)
Form the above plot, it looks like there are as many inactive members(4849) as active members(5151). And from above line graph, the data set contains the customers of all types of income from 0-200000. At last from the pie chart, 80% of customers are not churned and 20% have already exited.
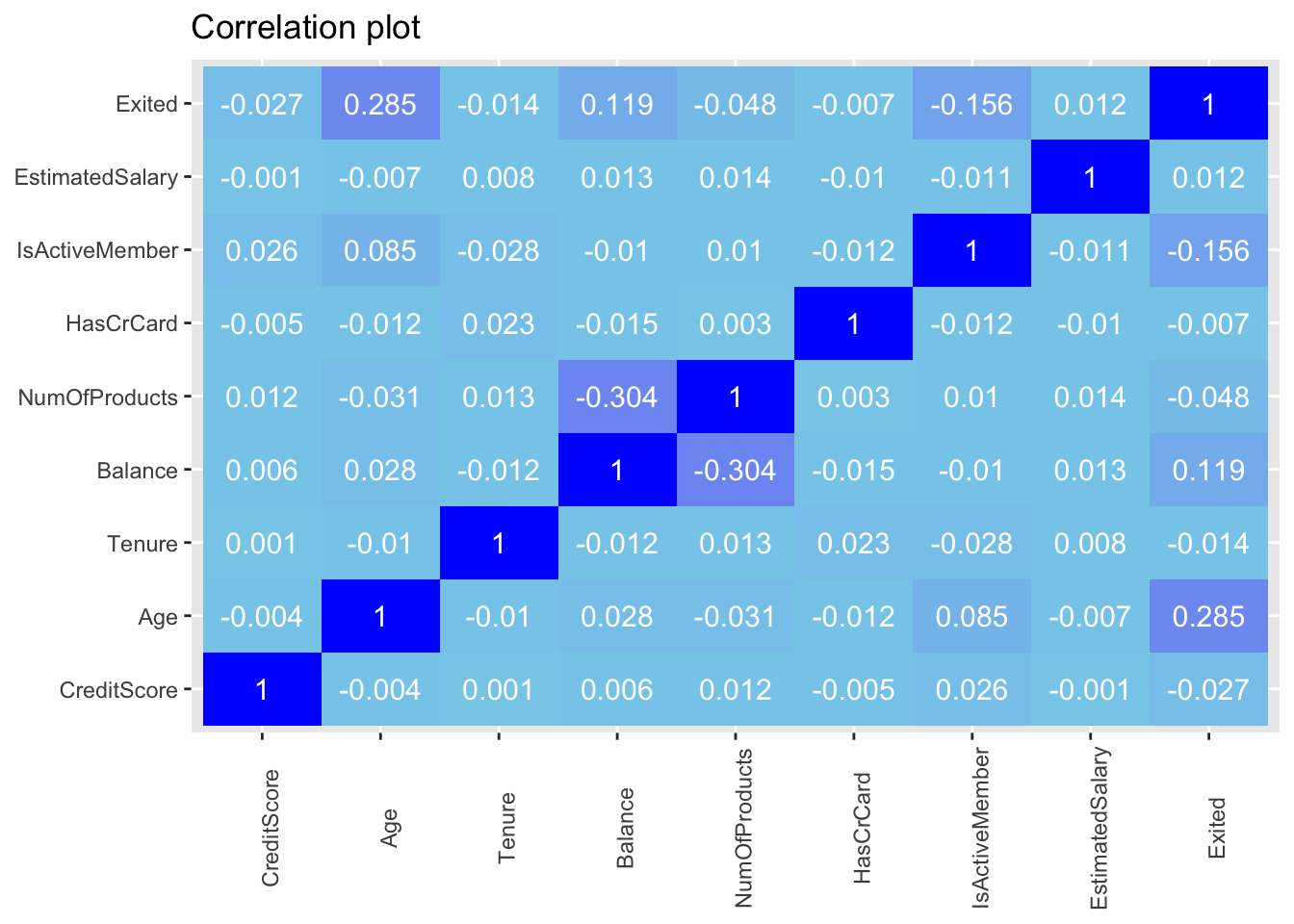
Churn has a positive correlation with age, balance and estimated salary. Generally the correlation coefficients are not so high.
Relationship between churn-rate and categorical variables
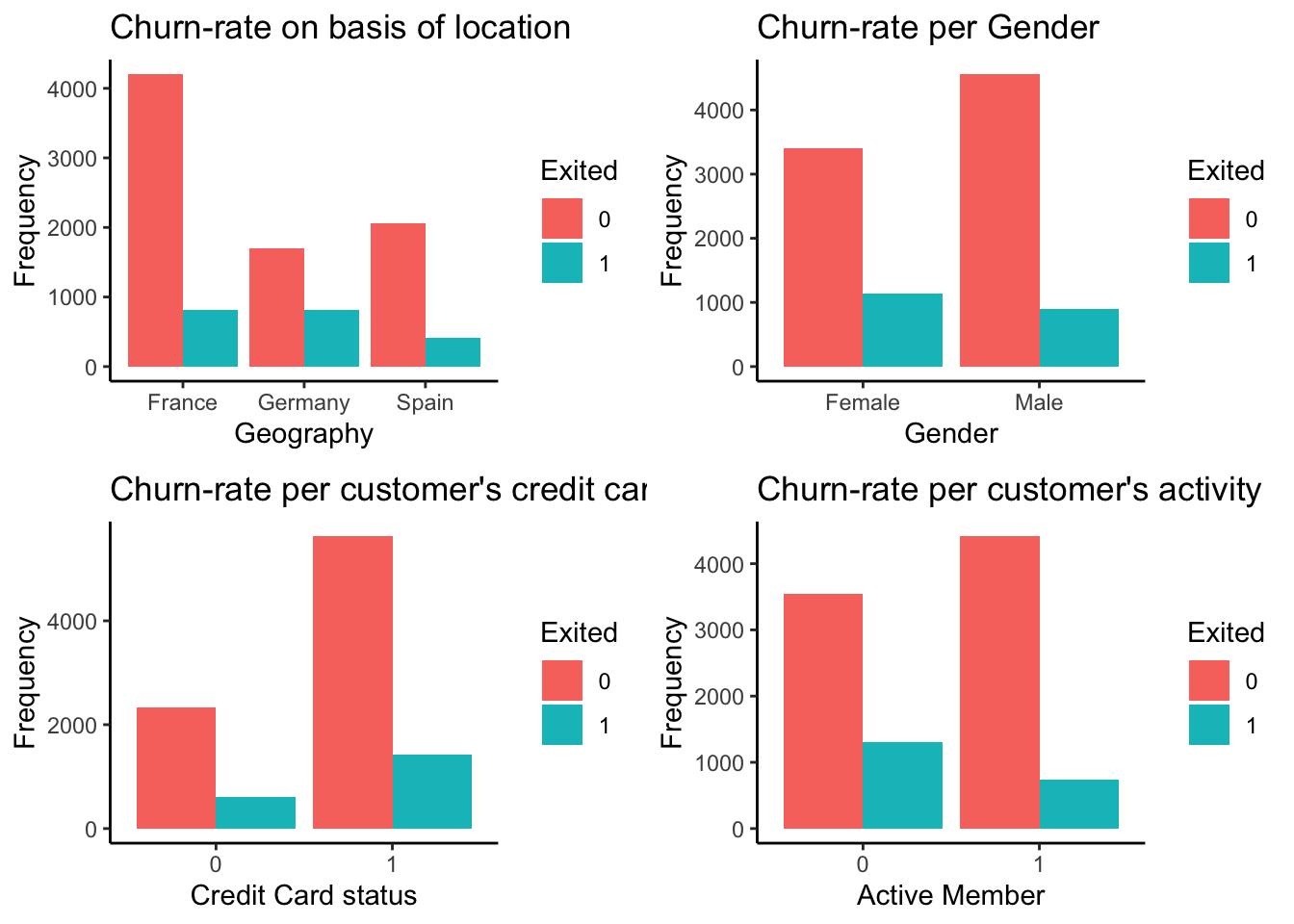
There are 4 categorical variables in the data set as follows:
Code
p1 <- Churn %>%group_by(Geography, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x = Geography)) +geom_bar(position ="dodge", stat ="identity") +labs(fill ="Exited") +ggtitle("Churn-rate on basis of location") +xlab("Geography") +ylab("Frequency") +theme_classic()p2 <- Churn %>%group_by(Gender, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x = Gender)) +geom_bar(position ="dodge", stat ="identity") +ggtitle("Churn-rate per Gender") +labs(fill ="Exited") +xlab("Gender") +ylab("Frequency") +theme_classic()p3 <- Churn %>%group_by(HasCrCard, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x =as.factor(HasCrCard))) +geom_bar(position ="dodge", stat ="identity") +ggtitle("Churn-rate per customer's credit card status") +labs(fill ="Exited") +xlab("Credit Card status") +ylab("Frequency") +theme_classic()p4 <- Churn %>%group_by(IsActiveMember, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x =as.factor(IsActiveMember))) +geom_bar(position ="dodge", stat ="identity") +ggtitle("Churn-rate per customer's activity") +labs(fill ="Exited") +xlab("Active Member") +ylab("Frequency") +theme_classic()grid.arrange(arrangeGrob(p1, p2, ncol =2),arrangeGrob(p3, p4, ncol =2),nrow =2)
Majority of the data is from people from France. However, the proportion of churned customers is with inversely related to the population of customers alluding to the bank possibly having a problem (maybe not enough customer service resources allocated) in the areas where it has fewer clients. Also from the above plot, the proportion of female customers churning is also greater than that of male customers and majority of the customers that churned are those with credit cards given that majority of the customers have credit cards could prove this to be just a coincidence. However, unsurprisingly the inactive members have a greater churn. Worryingly is that the overall proportion of inactive members is quite high suggesting that the bank may need a program implemented to turn this group to active customers as this will definately have a positive impact on the customer churn.
Relationship between churn-rate and continuous variables
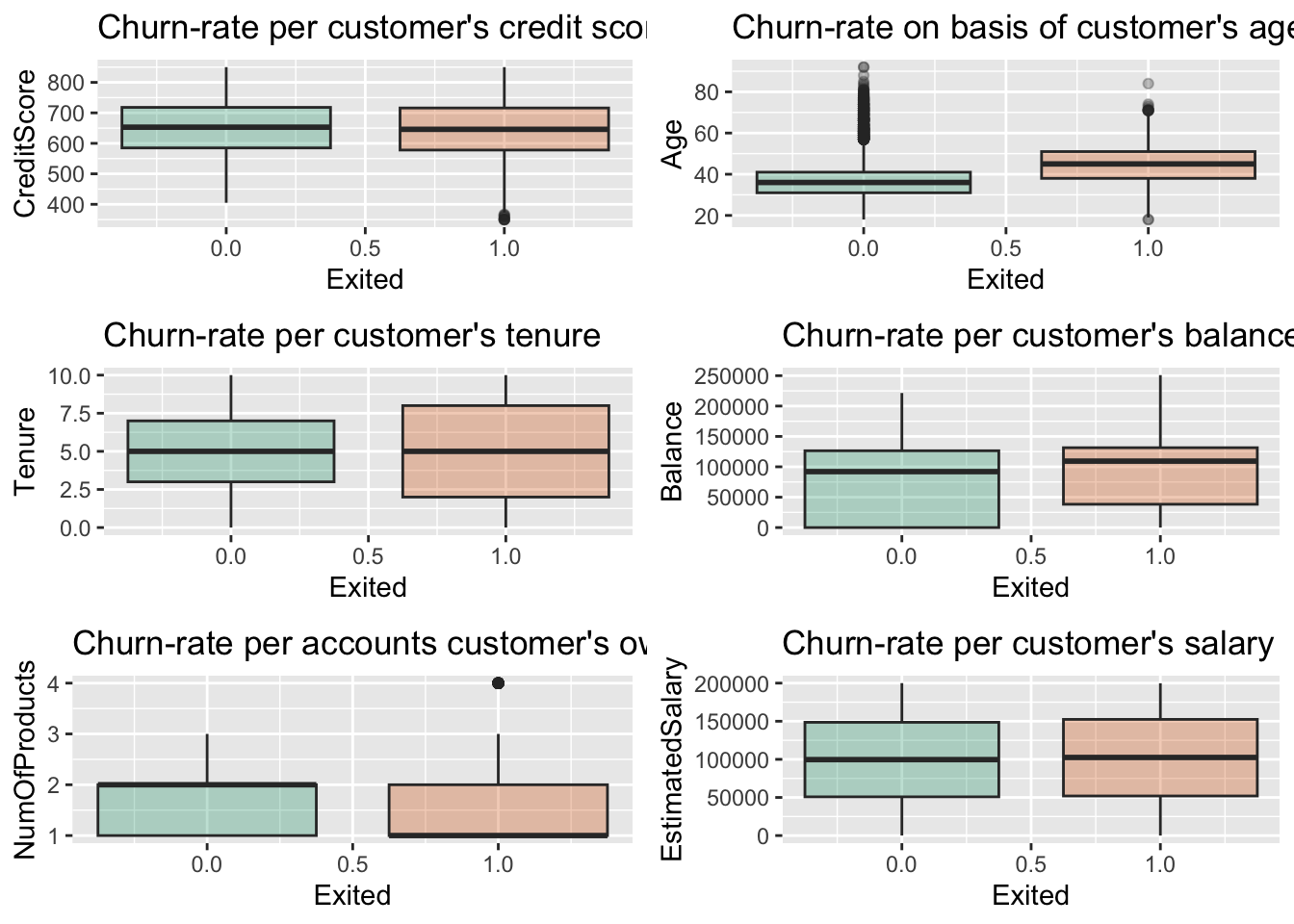
There are 6 continuous variables in the data set as follows:
Code
p1 <- Churn %>%ggplot(aes(x = Exited, y = CreditScore, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's credit score")p2 <- Churn %>%ggplot(aes(x = Exited, y = Age, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate on basis of customer's age")p3 <- Churn %>%ggplot(aes(x = Exited, y = Tenure, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's tenure")p4 <- Churn %>%ggplot(aes(x = Exited, y = Balance, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's balance")p5 <- Churn %>%ggplot(aes(x = Exited, y = NumOfProducts, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per accounts customer's own")p6 <- Churn %>%ggplot(aes(x = Exited, y = EstimatedSalary, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's salary")grid.arrange(arrangeGrob(p1, p2, ncol =2),arrangeGrob(p3, p4, ncol =2),arrangeGrob(p5, p6, ncol =2),nrow =3)
From the above plot, there is no significant difference in the credit score distribution between retained and churned customers. And also we can observe that the older customers are churning at more rate than the younger ones alluding to a difference in service preference in the age categories. The bank may need to review their target market or review the strategy for retention between the different age groups. With regard to the tenure, the clients on either extreme end (spent little time with the bank or a lot of time with the bank) are more likely to churn compared to those that are of average tenure. And also, the bank is losing customers with significant bank balances which is likely to hit their available capital for lending. And from the plot, it is clear that the no of products not has a significant effect on the likelihood to churn and also the Estimated salary not has a significant effect on the likelihood to churn.
Hypothesis Testing
Code
chisq.test(Churn$Exited,Churn$IsActiveMember)
Pearson's Chi-squared test with Yates' continuity correction
data: Churn$Exited and Churn$IsActiveMember
X-squared = 242.99, df = 1, p-value < 2.2e-16
We have a high X-squared value and a p-value of less than 0.05 significance level. So we can conclude that Exited and IsActiveMember have a significant relationship.
Code
chisq.test(Churn$Exited,Churn$Geography)
Pearson's Chi-squared test
data: Churn$Exited and Churn$Geography
X-squared = 301.26, df = 2, p-value < 2.2e-16
We have a high X-squared value more than the previous test and a p-value of less than 0.05 significance level. So we can conclude that Exited and Geography have a significant relationship.
Linear regression models
Code
model1 <-lm(Exited ~as.factor(IsActiveMember), data = Churn)summary(model1)
Call:
lm(formula = Exited ~ as.factor(IsActiveMember), data = Churn)
Residuals:
Min 1Q Median 3Q Max
-0.2685 -0.2685 -0.1427 -0.1427 0.8573
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.268509 0.005713 47.0 <2e-16 ***
as.factor(IsActiveMember)1 -0.125818 0.007961 -15.8 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3978 on 9998 degrees of freedom
Multiple R-squared: 0.02438, Adjusted R-squared: 0.02428
F-statistic: 249.8 on 1 and 9998 DF, p-value: < 2.2e-16
Code
model2 <-lm(Exited ~ ., data = Churn)summary(model2)
model3 <-lm(Exited ~ Geography, data = Churn)summary(model3)
Call:
lm(formula = Exited ~ Geography, data = Churn)
Residuals:
Min 1Q Median 3Q Max
-0.3244 -0.1667 -0.1615 -0.1615 0.8385
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.161548 0.005602 28.836 <2e-16 ***
GeographyGermany 0.162884 0.009701 16.791 <2e-16 ***
GeographySpain 0.005186 0.009743 0.532 0.595
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3967 on 9997 degrees of freedom
Multiple R-squared: 0.03013, Adjusted R-squared: 0.02993
F-statistic: 155.3 on 2 and 9997 DF, p-value: < 2.2e-16
Summarizing the above three models, the model1 describes the regression between Exited and Active member and second model predicts the churn rate based on all the variables and third model is analysis between exited and geography. And from model1 and model3, it seems that the variables Active member and Geography to be significant proving our hypothesis.
Code
model <-lm(Exited ~ . -Geography, data = Churn)summary(model)
From the above F-test, we can say the variable geography is significant as p-value is less than 0.05 significance level. But I will plot the diagonistic plots to further confirm my results.
Call:
lm(formula = Exited ~ . - Geography - HasCrCard - NumOfProducts -
EstimatedSalary - Tenure, data = Churn)
Residuals:
Min 1Q Median 3Q Max
-0.7805 -0.2361 -0.1251 0.0271 1.1939
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.144e-01 2.977e-02 -3.843 0.000122 ***
CreditScore -9.307e-05 3.877e-05 -2.401 0.016388 *
GenderMale -7.748e-02 7.529e-03 -10.291 < 2e-16 ***
Age 1.132e-02 3.588e-04 31.539 < 2e-16 ***
Balance 7.081e-07 6.007e-08 11.789 < 2e-16 ***
IsActiveMember -1.430e-01 7.528e-03 -18.999 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3746 on 9994 degrees of freedom
Multiple R-squared: 0.1356, Adjusted R-squared: 0.1352
F-statistic: 313.5 on 5 and 9994 DF, p-value: < 2.2e-16
In the model4, I have used backward elimination process by removing the highest p values to get a better model and it is best after removing above 5 variables removed in call.
Model Evaluation
Code
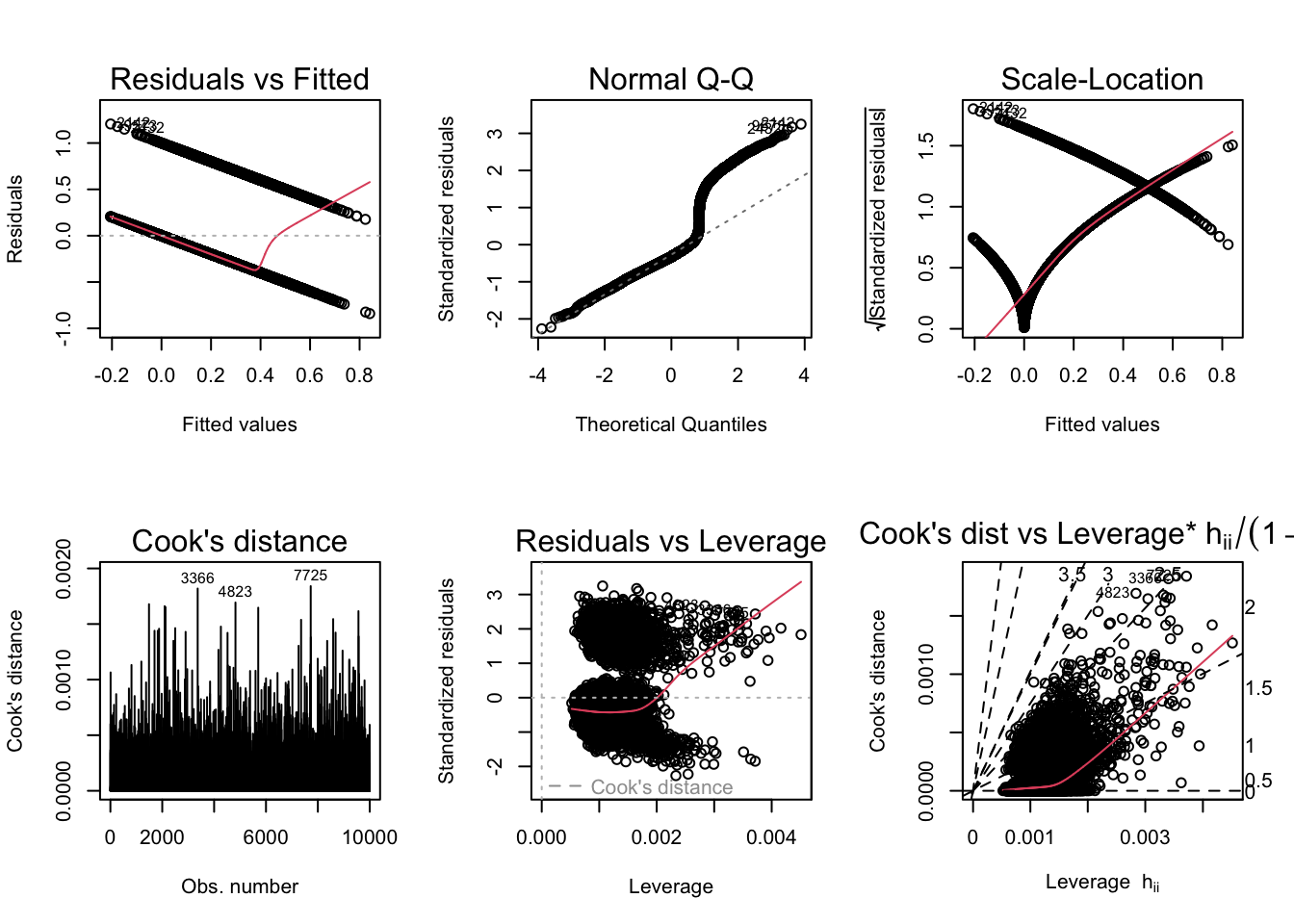
par(mfrow =c(2,3)); plot(model1, which =1:6)
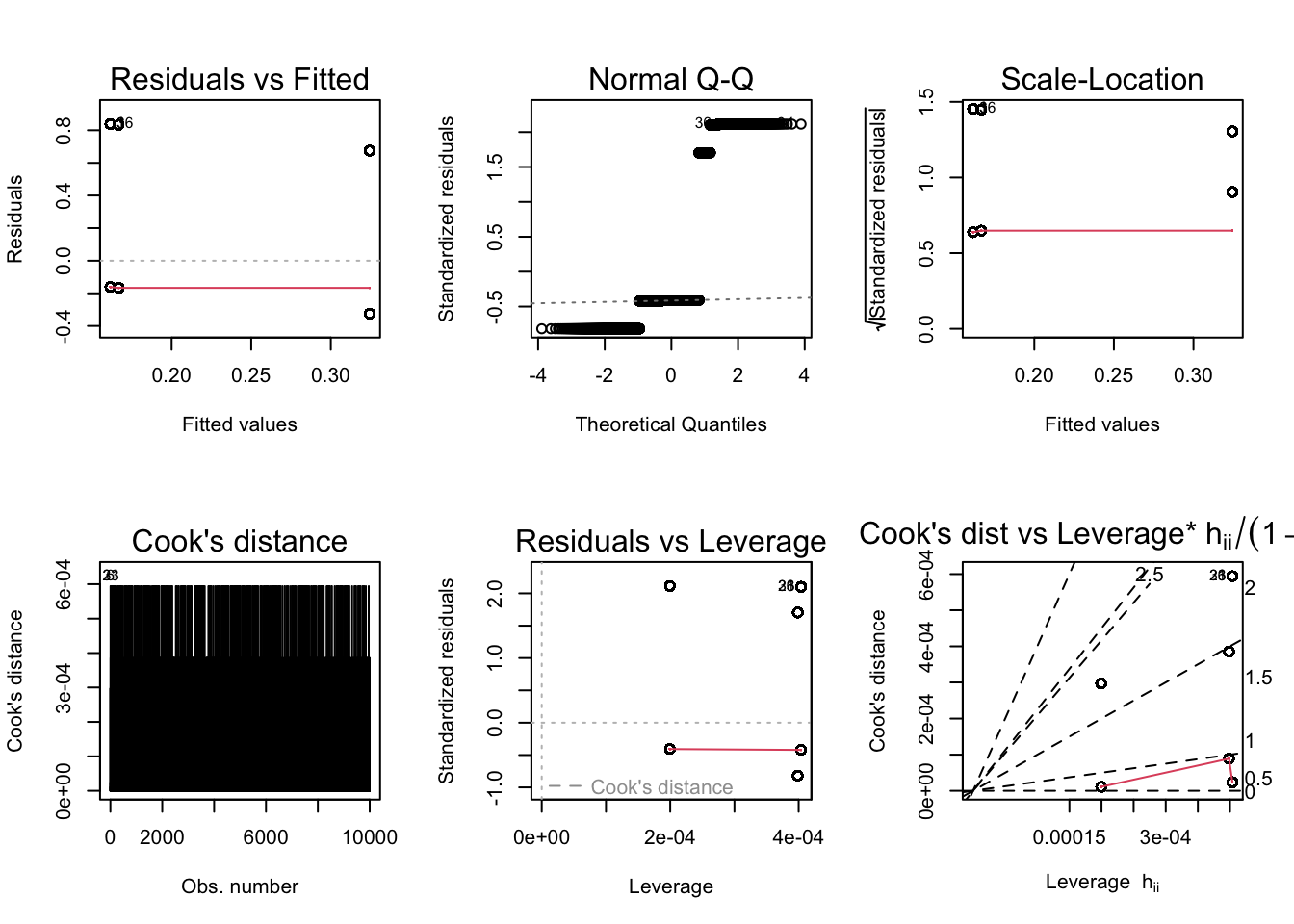
Code
par(mfrow =c(2,3)); plot(model2, which =1:6)
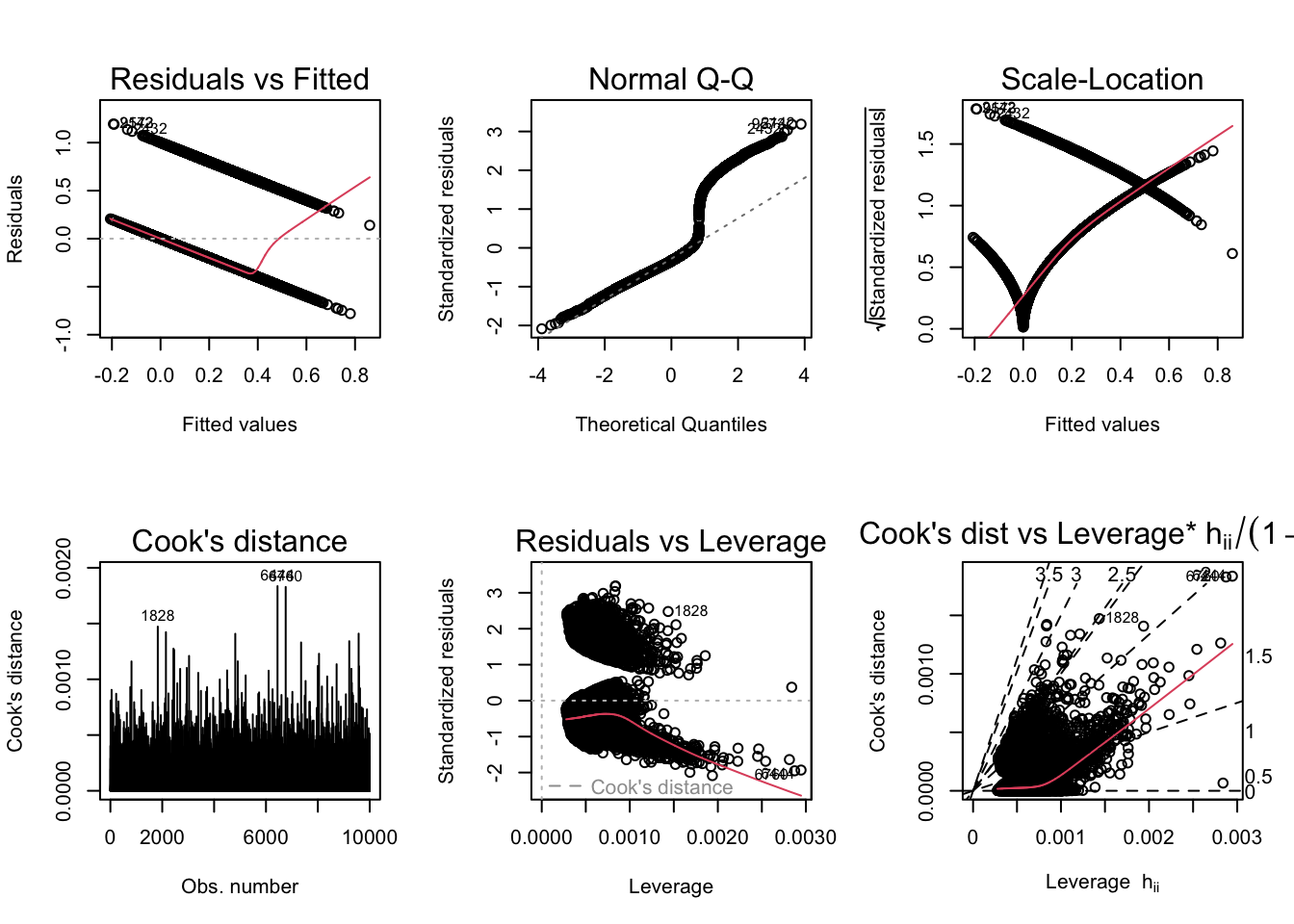
Code
par(mfrow =c(2,3)); plot(model3, which =1:6)
Code
par(mfrow =c(2,3)); plot(model4, which =1:6)
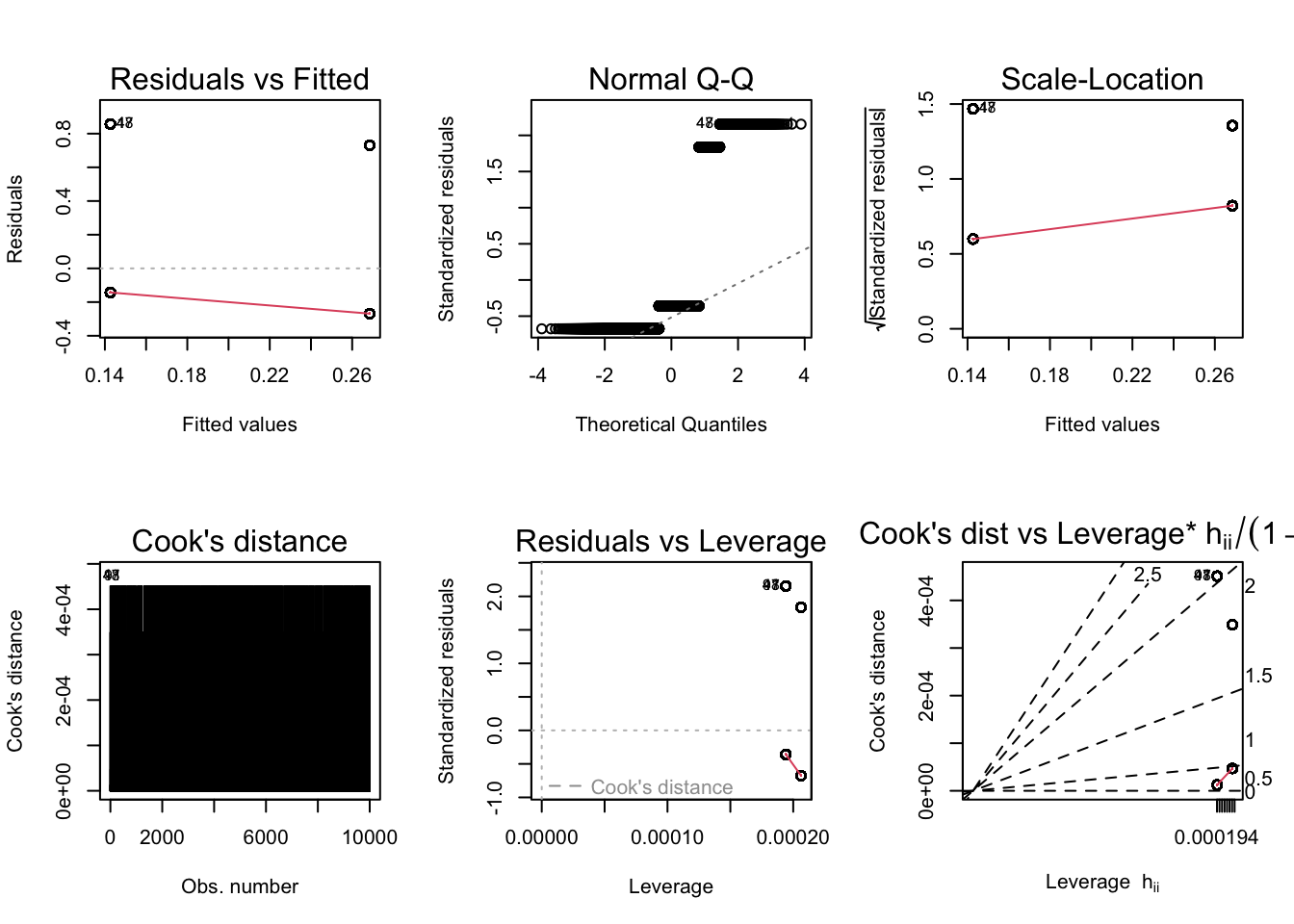
According to the diagnostic plots, none of the models seem to fit super well. There are violations of assumptions in models. In Residuals vs Fitted plot, some of the residuals seem to have a trend (higher fitted values have lower residuals). Same with the Q-Q, plot, lower theoretical quantiles gave significantly lower standardized residuals. The scale location graph has a negative trend, suggesting variance may not be constant. Cooks dist to leverage has a high cooks distance and leverage and likely has a large influence on the model. The other models display similar issues. So none of the plots are conclude to prove our hypothesis, so I will be doing logistic regression to get a better model and check the accuracy.
Logistic Regression
In the logistic regression, the coefficients table shows the beta coefficient estimates and their significance levels. Columns are:
Estimate: the intercept (b0) and the beta coefficient estimates associated to each predictor variable
Std.Error: the standard error of the coefficient estimates. This represents the accuracy of the coefficients. The larger the standard error, the less confident we are about the estimate.
z value: the z-statistic, which is the coefficient estimate (column 2) divided by the standard error of the estimate (column 3)
Pr(>|z|): The p-value corresponding to the z-statistic. The smaller the p-value, the more significant the estimate is.
Code
set.seed(1234)trainIndex <-sample(1:nrow(Churn), size =round(0.7*nrow(Churn)))ChurnTrain <- Churn[trainIndex,]ChurnTest <- Churn[-trainIndex,]cat(nrow(ChurnTrain), " observations are in the training set. \n")
7000 observations are in the training set.
Code
cat(nrow(ChurnTest), " observations are in the testing set. \n")
3000 observations are in the testing set.
Code
model5 <-glm(data = ChurnTrain, Exited ~ IsActiveMember, family ="binomial")summary(model5)
Call:
glm(formula = Exited ~ IsActiveMember, family = "binomial", data = ChurnTrain)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.8003 -0.8003 -0.5622 -0.5622 1.9610
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.97442 0.03871 -25.17 <2e-16 ***
IsActiveMember -0.79040 0.06080 -13.00 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7147.4 on 6999 degrees of freedom
Residual deviance: 6972.7 on 6998 degrees of freedom
AIC: 6976.7
Number of Fisher Scoring iterations: 4
Code
# predicting test data based on the modelChurnTest$pred_log <-predict(model5, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)
Code
auc <-auc(ChurnTest$Exited, ChurnTest$pred_log)
Setting levels: control = 0, case = 1
Setting direction: controls < cases
Code
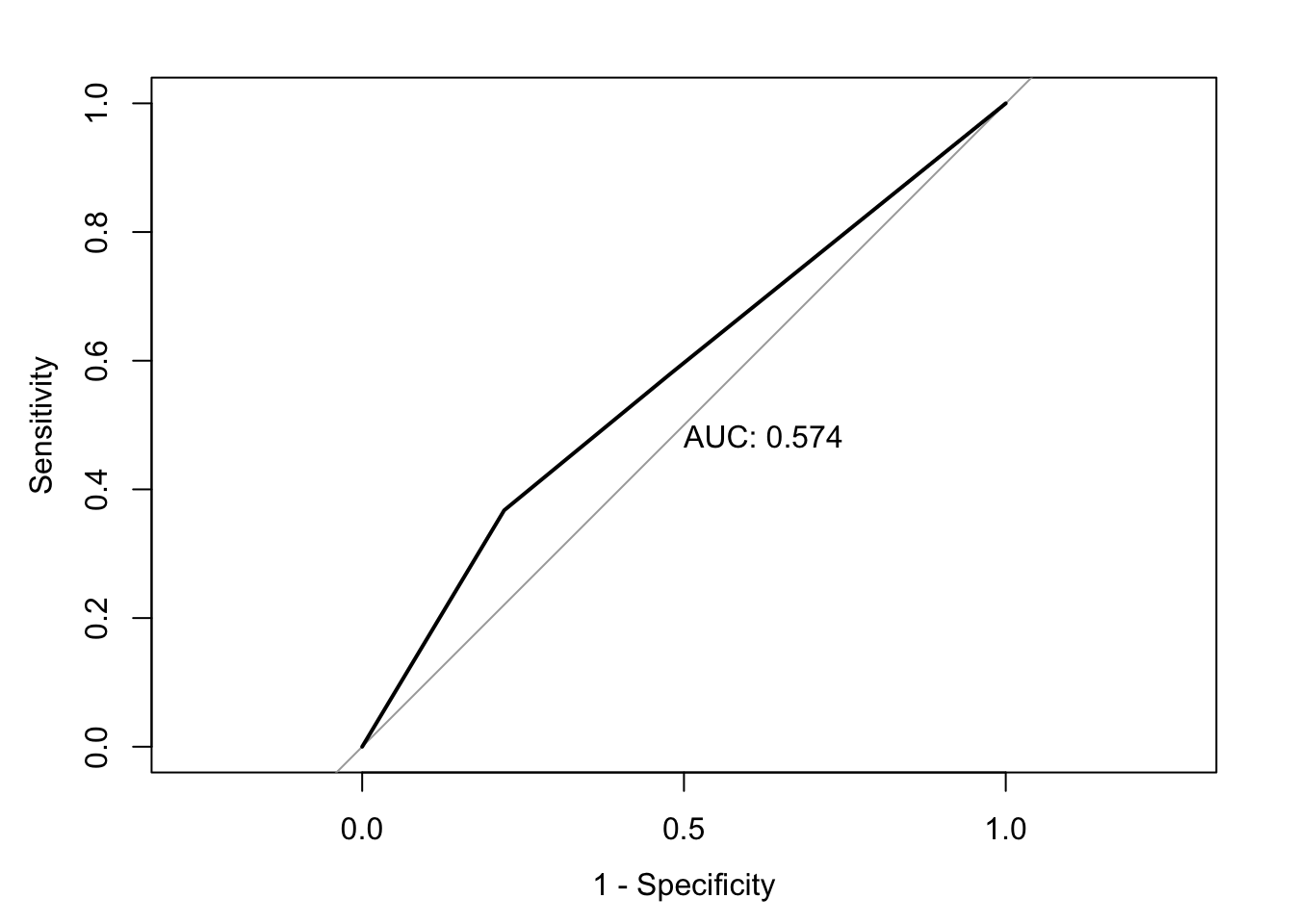
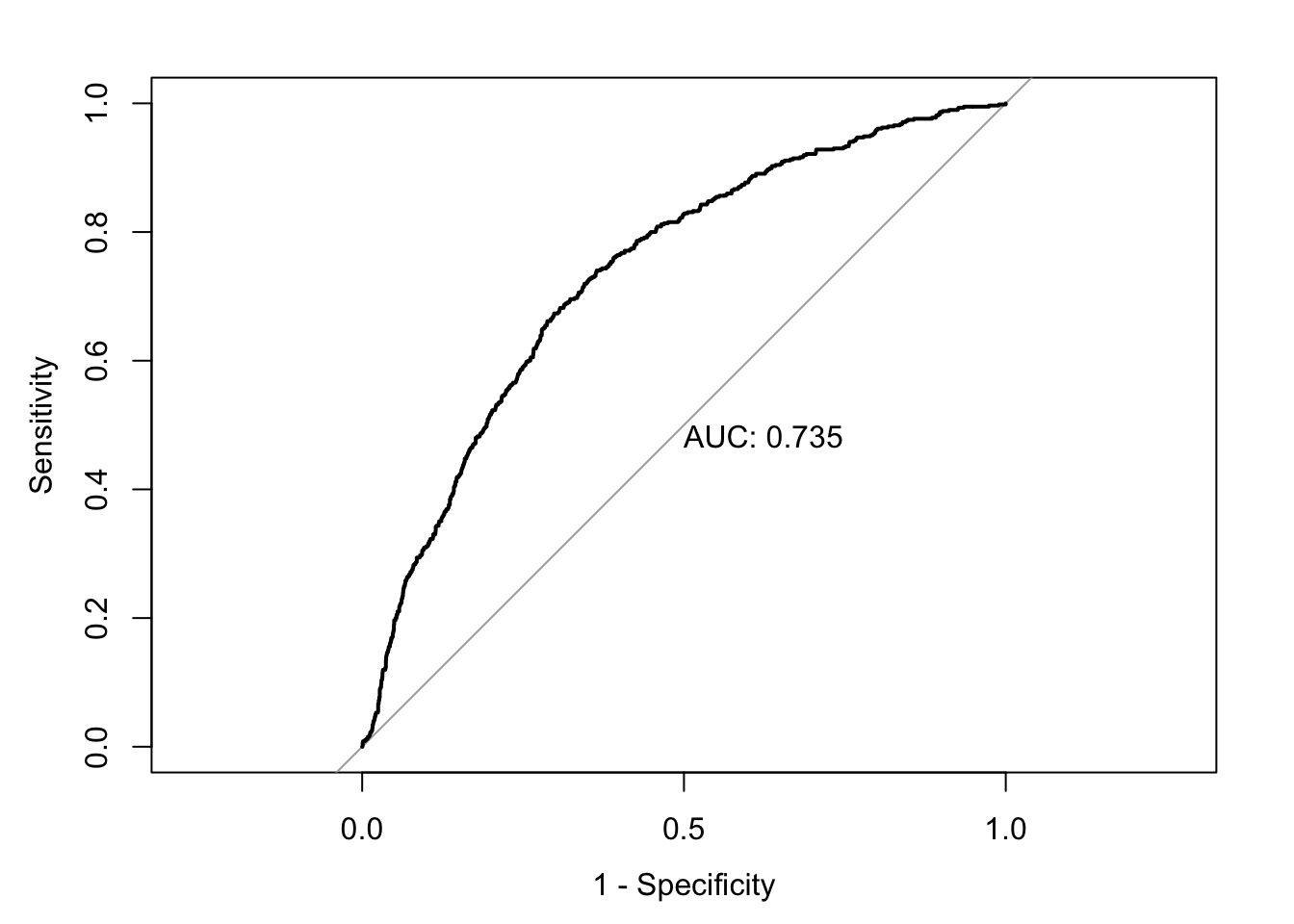
accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))
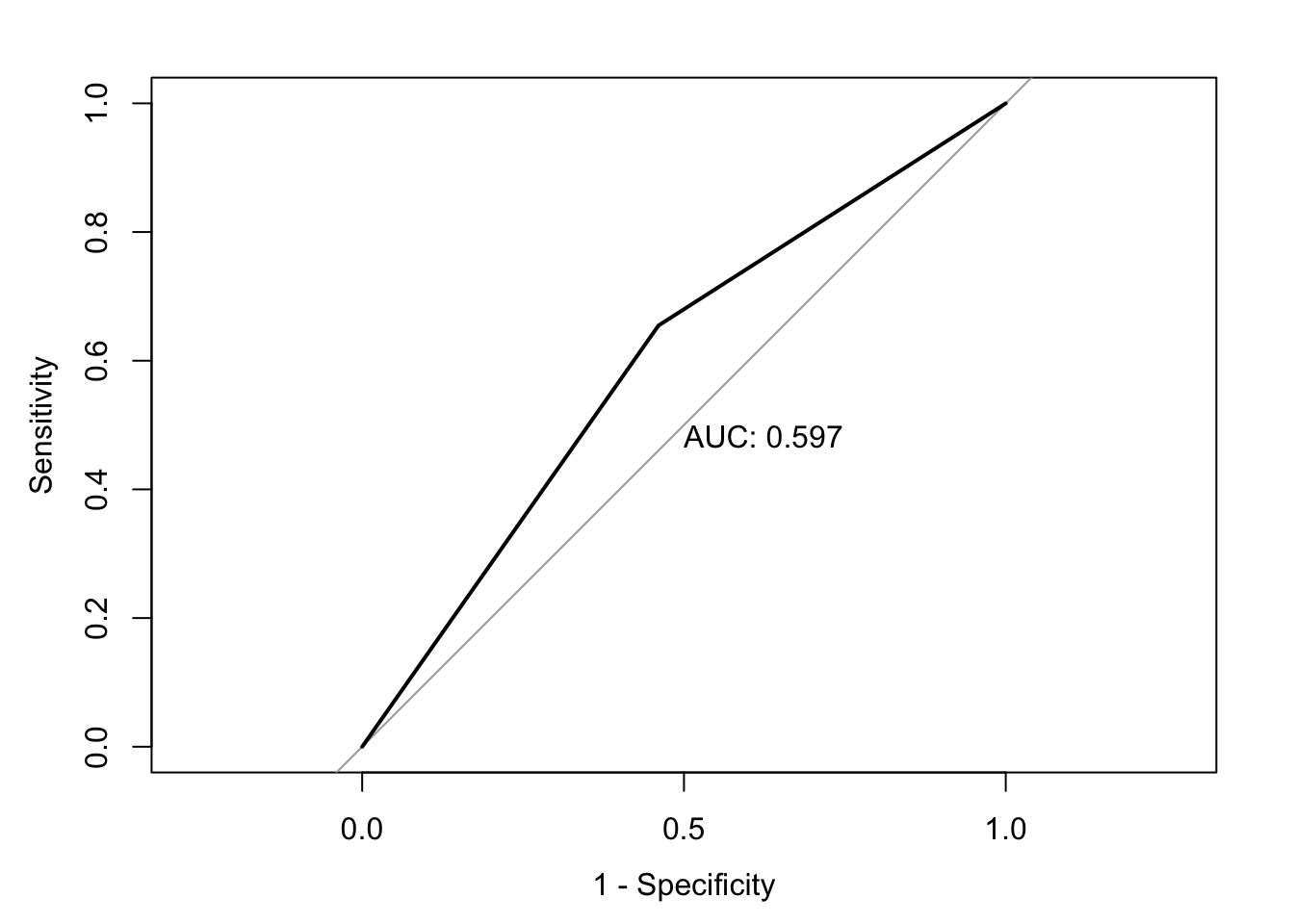
model6 <-glm(data = ChurnTrain, Exited ~ Geography, family ="binomial")summary(model6)
Call:
glm(formula = Exited ~ Geography, family = "binomial", data = ChurnTrain)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.9119 -0.6046 -0.5920 -0.5920 1.9121
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.65281 0.04596 -35.959 <2e-16 ***
GeographyGermany 0.99017 0.06814 14.532 <2e-16 ***
GeographySpain 0.04614 0.07916 0.583 0.56
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7147.4 on 6999 degrees of freedom
Residual deviance: 6913.2 on 6997 degrees of freedom
AIC: 6919.2
Number of Fisher Scoring iterations: 4
Code
# predicting test data based on the modelChurnTest$pred_log <-predict(model6, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)
Code
auc <-auc(ChurnTest$Exited, ChurnTest$pred_log)
Setting levels: control = 0, case = 1
Setting direction: controls < cases
Code
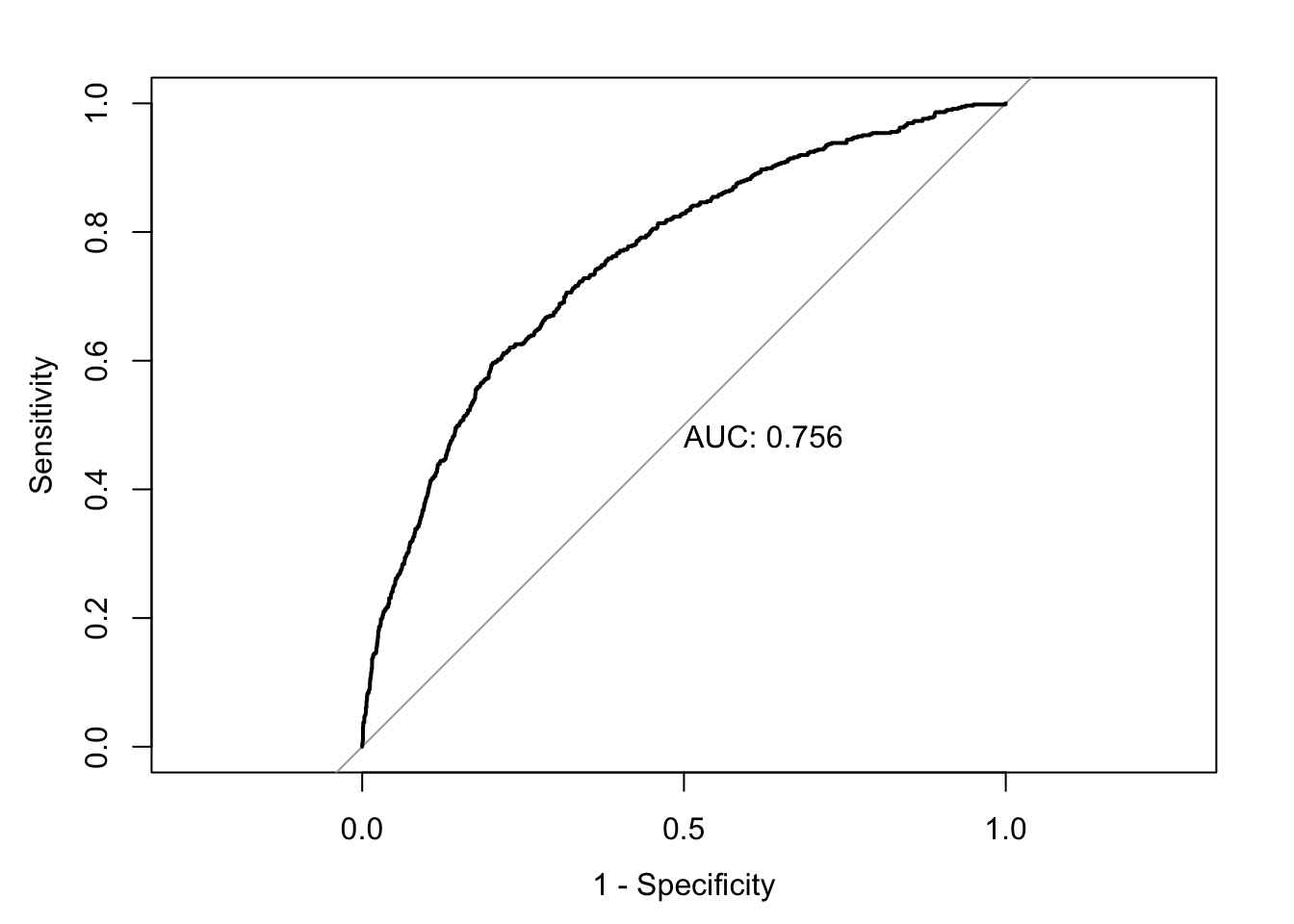
accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))
Call:
glm(formula = Exited ~ . - HasCrCard - NumOfProducts - EstimatedSalary -
Tenure, family = "binomial", data = ChurnTrain)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.3464 -0.6583 -0.4548 -0.2675 2.9388
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.700e+00 2.588e-01 -14.293 < 2e-16 ***
CreditScore -6.082e-04 3.355e-04 -1.813 0.0698 .
GeographyGermany 8.289e-01 7.961e-02 10.412 < 2e-16 ***
GeographySpain 5.604e-02 8.440e-02 0.664 0.5067
GenderMale -5.156e-01 6.491e-02 -7.943 1.98e-15 ***
Age 7.270e-02 3.072e-03 23.663 < 2e-16 ***
Balance 3.190e-06 5.885e-07 5.420 5.95e-08 ***
IsActiveMember -1.063e+00 6.833e-02 -15.554 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7147.4 on 6999 degrees of freedom
Residual deviance: 6027.0 on 6992 degrees of freedom
AIC: 6043
Number of Fisher Scoring iterations: 5
Code
# predicting test data based on the modelChurnTest$pred_log <-predict(model7, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)
Code
auc <-auc(ChurnTest$Exited, ChurnTest$pred_log)
Setting levels: control = 0, case = 1
Setting direction: controls < cases
Code
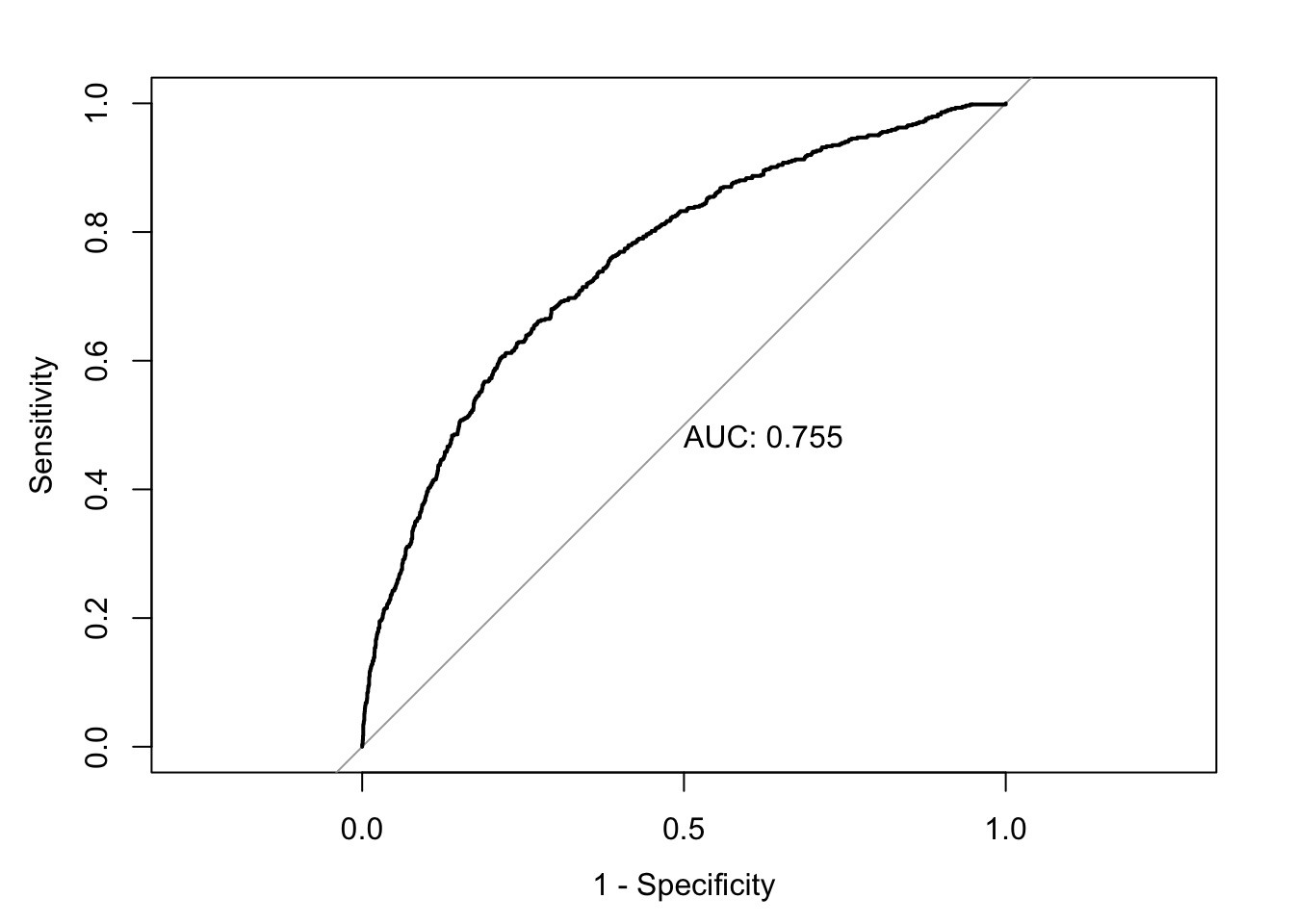
accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))
model8 <-glm(data = ChurnTrain, Exited ~ ., family ="binomial")summary(model8)
Call:
glm(formula = Exited ~ ., family = "binomial", data = ChurnTrain)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.3610 -0.6600 -0.4546 -0.2655 2.9196
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.401e+00 2.911e-01 -11.684 < 2e-16 ***
CreditScore -5.988e-04 3.358e-04 -1.783 0.07453 .
GeographyGermany 8.524e-01 8.013e-02 10.638 < 2e-16 ***
GeographySpain 5.861e-02 8.445e-02 0.694 0.48765
GenderMale -5.181e-01 6.499e-02 -7.971 1.57e-15 ***
Age 7.250e-02 3.074e-03 23.583 < 2e-16 ***
Tenure -1.581e-02 1.113e-02 -1.421 0.15533
Balance 2.784e-06 6.112e-07 4.555 5.25e-06 ***
NumOfProducts -1.457e-01 5.620e-02 -2.592 0.00954 **
HasCrCard 1.037e-02 7.116e-02 0.146 0.88413
IsActiveMember -1.063e+00 6.843e-02 -15.532 < 2e-16 ***
EstimatedSalary 2.108e-07 5.637e-07 0.374 0.70843
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7147.4 on 6999 degrees of freedom
Residual deviance: 6018.1 on 6988 degrees of freedom
AIC: 6042.1
Number of Fisher Scoring iterations: 5
Code
# predicting test data based on the modelChurnTest$pred_log <-predict(model8, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)
Code
auc <-auc(ChurnTest$Exited, ChurnTest$pred_log)
Setting levels: control = 0, case = 1
Setting direction: controls < cases
Code
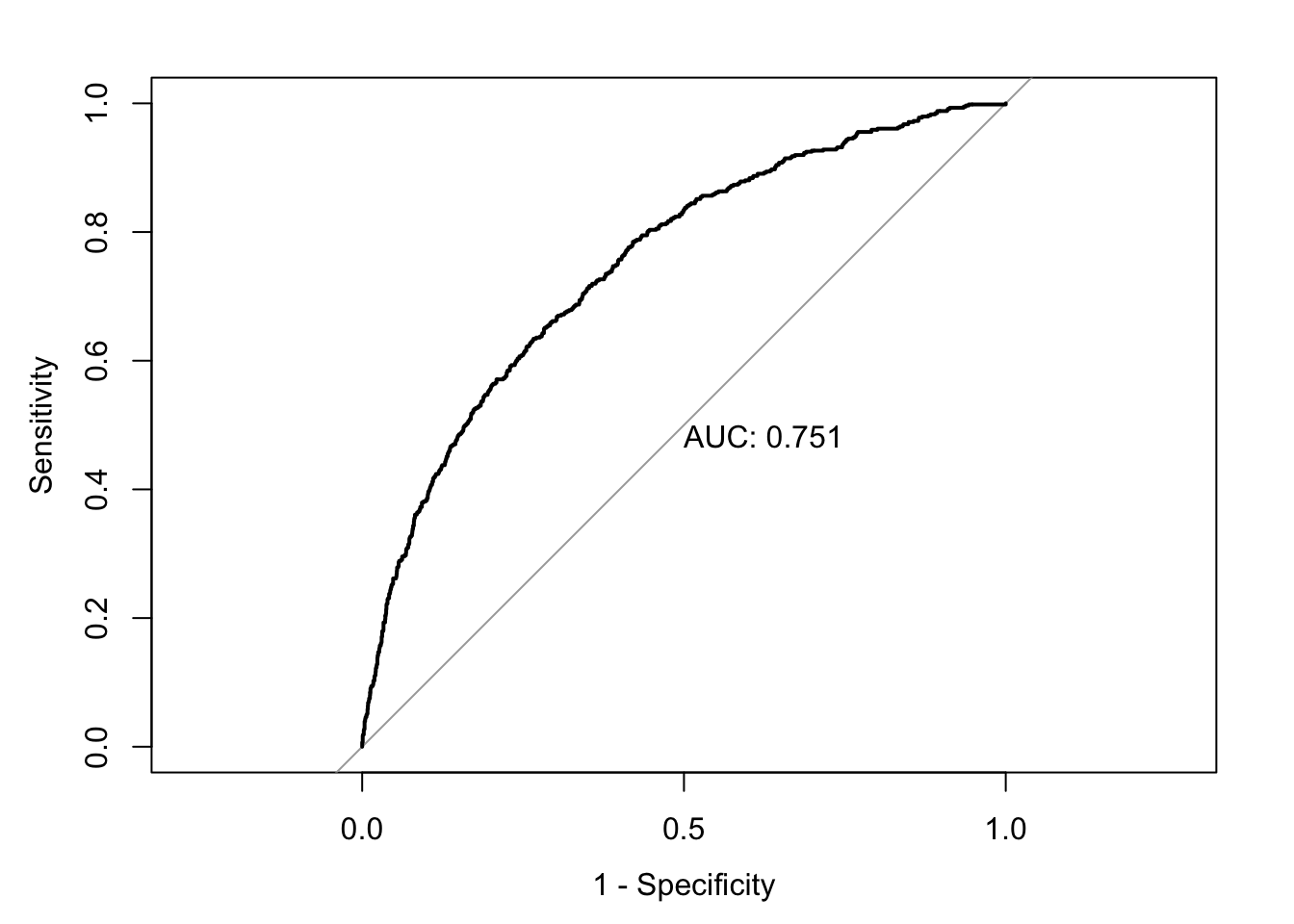
accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))
model9 <-glm(data = ChurnTrain, Exited ~ . -Geography, family ="binomial")summary(model9)
Call:
glm(formula = Exited ~ . - Geography, family = "binomial", data = ChurnTrain)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.1716 -0.6743 -0.4674 -0.2786 2.9375
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.441e+00 2.867e-01 -12.005 <2e-16 ***
CreditScore -6.131e-04 3.319e-04 -1.847 0.0647 .
GenderMale -5.370e-01 6.422e-02 -8.361 <2e-16 ***
Age 7.258e-02 3.039e-03 23.884 <2e-16 ***
Tenure -1.444e-02 1.101e-02 -1.311 0.1899
Balance 5.353e-06 5.477e-07 9.775 <2e-16 ***
NumOfProducts -7.644e-02 5.527e-02 -1.383 0.1666
HasCrCard 1.699e-02 7.032e-02 0.242 0.8091
IsActiveMember -1.071e+00 6.773e-02 -15.807 <2e-16 ***
EstimatedSalary 2.304e-07 5.579e-07 0.413 0.6796
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7147.4 on 6999 degrees of freedom
Residual deviance: 6142.2 on 6990 degrees of freedom
AIC: 6162.2
Number of Fisher Scoring iterations: 5
Code
# predicting test data based on the modelChurnTest$pred_log <-predict(model9, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)
Code
auc <-auc(ChurnTest$Exited, ChurnTest$pred_log)
Setting levels: control = 0, case = 1
Setting direction: controls < cases
Code
accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))
model10 <-glm(data = ChurnTrain, Exited ~ . -IsActiveMember, family ="binomial")summary(model10)
Call:
glm(formula = Exited ~ . - IsActiveMember, family = "binomial",
data = ChurnTrain)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.0778 -0.6598 -0.4909 -0.3345 2.6453
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.432e+00 2.841e-01 -12.081 < 2e-16 ***
CreditScore -7.424e-04 3.284e-04 -2.261 0.02376 *
GeographyGermany 8.619e-01 7.827e-02 11.012 < 2e-16 ***
GeographySpain 5.187e-02 8.326e-02 0.623 0.53333
GenderMale -5.430e-01 6.363e-02 -8.533 < 2e-16 ***
Age 6.354e-02 2.896e-03 21.941 < 2e-16 ***
Tenure -9.572e-03 1.089e-02 -0.879 0.37932
Balance 2.609e-06 6.041e-07 4.318 1.57e-05 ***
NumOfProducts -1.608e-01 5.540e-02 -2.903 0.00369 **
HasCrCard 3.528e-02 6.981e-02 0.505 0.61334
EstimatedSalary 2.807e-07 5.511e-07 0.509 0.61049
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 7147.4 on 6999 degrees of freedom
Residual deviance: 6275.8 on 6989 degrees of freedom
AIC: 6297.8
Number of Fisher Scoring iterations: 4
Code
# predicting test data based on the modelChurnTest$pred_log <-predict(model10, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)
Code
auc <-auc(ChurnTest$Exited, ChurnTest$pred_log)
Setting levels: control = 0, case = 1
Setting direction: controls < cases
Code
accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))
A logistic regression is said to provide a better fit to the data if it demonstrates an improvement over a model with fewer predictors. This is performed using the likelihood ratio test, which compares the likelihood of the data under the full model against the likelihood of the data under a model with fewer predictors. Removing predictor variables from a model will almost always make the model fit less well (i.e. a model will have a lower log likelihood), but it is necessary to test whether the observed difference in model fit is statistically significant. Given that H0 holds that the reduced model is true, a p-value for the overall model fit statistic that is less than 0.05 would compel us to reject the null hypothesis. It would provide evidence against the reduced model in favor of the current model. The likelihood ratio test can be performed in R using the lrtest() function from the lmtest package.
Code
lrtest(model10, model8)
From the above likelihood ratio test, we can say that as p-value is less than 0.05, our variable active member is significant, so we can reject the null hypothesis and confirm that there is a significant relationship between active member and churn rate. And we can conclude that there is a high possibility of inactive members to churn.
Code
lrtest(model9, model8)
From the above likelihood ratio test, we can say that as p-value is less than 0.05, our variable Geography is significant, so we can reject the null hypothesis and confirm that there is a significant relationship between Geography and churn rate. And we can conclude that there is a high possibility of predicting the churn-rate on basis of Geography.
Conclusion
From the hypothesis testing, logistic regression and likelihood ratio test we can conclude the following:
We observe from likelihood ratio test that overall Geography variable is significant, so we can reject the null hypothesis and confirm that there is a significant relationship between Geography and churn rate. And we can also conclude that there is a high probability of customers churning when it comes to Germany, but when we look at Spain, the probable churn-rate will be less when compared to Germany as it is not significant and churn-rate will be similar to the France based on the coefficient value.
We can observe that there is a significant, but negative relationship between the active member variable and churn-rate based on the p-value and coefficient value, so we can conclude that there is a significant relationship between the churn rate of a customer and their active status and conclude that the inactive members are more likely to churn than the active members.
Further Study
I would like to look into more models using logistic regression to further improve my accuracy and also would like to try random forest and decision tree algorithms and check them.
Bibliography
Chicco, D. & Jurman, G., 2020. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC genomics, 21(1), pp. 6-13.
Colgate, M., Stewart, K. & Kinsella, R., 1996. Customer Defection: A study of the student market in Ireland. International Journal of Bank Marketing, 14(3), pp. 23-29.
De Caigny, A., Coussement, K. & De Bock, K. W., 2018. A new hybrid classification algorithm for customer churn prediction based on logistic regression and decision trees. European Journal of Operational Research, 269(2), pp. 760-772.
Delgado, R. & Tibau, X. 2019. Why Cohen’s Kappa should be avoided as performance measure in classification, PLOS ONE, 14(9), pp. e0222916.
Ganesh, J., Arnold, M. J. & Reynolds, K. E., 2000. Understanding the Customer Base of Service Providers: An Examination of the Differences between Switchers and Stayers. Journal of Marketing, 64(3), pp. 65-87.
Gorodkin, J., 2004. Comparing two K-category assignments by a K-category correlation coefficient. Computational Biology and Chemistry, 28(5), pp. 367-374.
Hair, J. F., Black, J. W. C., Babin, B. J. & Anderson, R. E., 2014. Multivariate Data Analysis. 7th ed. Harlow: Pearson international edn.
Hastie, T., Tibshirani, R. & Friedman, J., 2009. The Elements of Statistical Learning: data mining, inference, and prediction. 2nd ed. New York, NY: Springer New York.
Hosmer, D. W., Lemeshow, S. & Sturdivant, R. X., 2013. Applied logistic regression, 3rd ed. New Jersey, NJ: Wiley.
James, G., Witten, D., Hastie, T. & Tibshirani, R., 2013. An Introduction to Statistical Learning: with Applications in R. New York, NY: Springer New York.
McHugh, M. L., 2012. Interrater reliability: the Kappa Statistic. Biochemia Medica, 22(3), pp. 276-282.
The Economist, 2019. A Whole New World: How technology is driving the evolution of intelligent banking, London: The Economist Intelligence Unit (EIU).
Verbeke, W. et al., 2012. New insights into churn prediction in the Telecommunication Sector: A profit driven data mining approach. European Journal of Operational Research, 218(1), pp. 211-
Source Code
---title: "Final project"author: "Mani Shanker Kamarapu"description: "The final part of final project"date: "12/15/2022"format: html: df-print: paged css: styles.css toc: true code-fold: true code-copy: true code-tools: truecategories: - final - Bank Customer Churn Prediction - Mani Shanker Kamarapu---## IntroductionChurning refers to a customer who leaves one company to go to another company. Customer churn introduces not only some loss in income but also other negative effects on the operation of companies. Churn management is the concept of identifying those customers who are intending to move their custom to a competing service provider.Risselada et al. (2010) stated that churn management is becoming part of customer relationship management. It is important for companies to consider it as they try to establish long-term relationships with customers and maximize the value of their customer base.::: callout-important## Research QuestionsA. Does churn-rate depend on the geographical factors(Customer's location) of the customer?B. Do non-active members are probable to churn or not?:::This project will be useful to better understand more about the customer difficulties and factors and also give us a pretty good idea on the factors effecting the customers to exit and also about the dormant state of the customers.## HypothesisCustomer churn analysis has become a major concern in almost every industry that offers products and services. The model developed will help banks identify clients who are likely to be churners and develop appropriate marketing actions to retain their valuable clients. And this model also supports information about similar customer group to consider which marketing reactions are to be provided. Thus, due to existing customers are retained, it will provide banks with increased profits and revenues. By the end of this project, let’s attempt to solve some of the key business challenges pertaining to customer attrition like say, (1) what is the likelihood of an active customer leaving an organization? (2) what are key indicators of a customer churn? (3) what retention strategies can be implemented based on the results to diminish prospective customer churn?Given the above, we can frame our hypotheses as follows:::: callout-tip## H~0A~Customer's location [will not]{.underline} be able to predict the churn-rate.:::::: callout-tip## H~1A~Customer's location [will]{.underline} be able to predict the churn-rate.:::I believe that the customer's location have an effect on customer's churn rate as based on location there is difference in customer's salary and balance.::: callout-tip## H~0B~Inactive members [will not]{.underline} churn.:::::: callout-tip## H~1B~Inactive members [will]{.underline} churn.:::I think that inactive members are more likely to exit rather than active members as there is a high chance of them churning out as they are are inactive for a longtime.## Loading libraries```{r}#| label: setup#| warning: falselibrary(tidyverse)library(ggplot2)library(stats)library(reshape2)library(gridExtra)library(broom)library(Metrics)library(skimr)library(pROC)library(interactions)library(lmtest)library(sandwich)library(stargazer)library(plotly)knitr::opts_chunk$set(echo =TRUE)```## Reading the data set```{r}Churn <-read_csv("_data/Churn_Modelling.csv")Churn```This data set is originated from a U.S. bank and is downloaded from kaggle. This data set includes 10k bank customer data records with 14 attributes including socio-demographic attributes, account level and behavioral attributes.### Attribute Description1. Row Number- Number of customers 2. Customer ID- ID of customer 3.Surname- Customer name 4. Credit Score- Score of credit card usage 5. Geography- Location of customer 6. Gender- Customer gender 7. Age- Age of Customer 8. Tenure- The period of having the account in months 9. Balance- Customer main balance 10. NumOfProducts- No of products used by customer(No of accounts the customer have)11. HasCrCard- If the customer has a credit card or not 12. IsActiveMember- Customer account is active or not(if he haven't used his savings or current account for any transactions for over 1 year, then he is treated as inactive.) 13. Estimated Salary- Estimated salary of the customer. 14. Exited- Indicate churned or not, i.e, if the customer left the bank or not.The response variable is `Exited` variable and the main explanatory variables are `Geography` and `IsActiveMember`. And the other explanatory variables are Credit Score, Gender, Age and Balance. ```{r}str(Churn)```## Descriptive statistics```{r}summary(Churn)```## Tidying the data```{r}Churn <- Churn %>%select(-c(RowNumber, CustomerId, Surname))Churn```Dimensions of the data set```{r}dim(Churn)```The data set has 10000 rows and 11 columns now after removing the first 3 columns which are not necessary for analysis and will not effect the model.Checking for Null values```{r}apply(is.na(Churn), MARGIN =2, FUN = sum)```### Detecting the outliers```{r}p1 <- Churn %>%ggplot(aes(CreditScore)) +geom_boxplot() +coord_flip()p2 <- Churn %>%ggplot(aes(Age)) +geom_boxplot() +coord_flip()p3 <- Churn %>%ggplot(aes(Tenure)) +geom_boxplot() +coord_flip()p4 <- Churn %>%ggplot(aes(Balance)) +geom_boxplot() +coord_flip()p5 <- Churn %>%ggplot(aes(NumOfProducts)) +geom_boxplot() +coord_flip()p6 <- Churn %>%ggplot(aes(EstimatedSalary)) +geom_boxplot() +coord_flip()grid.arrange(arrangeGrob(p1, p2, ncol =2), arrangeGrob(p3, p4, ncol =2),arrangeGrob(p5, p6, ncol =2),nrow =3)```From above box plot, Credit score variable has few outliers, and Age variable has highest no of outliers (age above have 60 constitutes outliers), however these are only few outliers and they cannot potentially effect the data set. Tenure, Balance, NumofProducts and EstimatedSalary variables have no outliers.## Visualing and interpreting the variables```{r}p1 <- Churn %>%ggplot(aes(CreditScore)) +geom_density(color="Green", alpha=0.8) +ggtitle("Credit score of customers") +theme_classic()p2 <- Churn %>%group_by(Geography) %>%# Variable to be transformedcount() %>%ungroup() %>%mutate(perc =`n`/sum(`n`)) %>%arrange(perc) %>%mutate(labels = scales::percent(perc)) %>%ggplot(aes(x ="", y = perc, fill = Geography)) +ggtitle("Location of customers") +geom_col(color ="black") +geom_label(aes(label = labels), color =c(1, "white", "white"),position =position_stack(vjust =0.5),show.legend =FALSE) +guides(fill =guide_legend(title ="Geography")) +scale_fill_viridis_d() +coord_polar(theta ="y") +theme_void()p3 <- Churn %>%ggplot() +geom_bar(aes(Gender)) +ggtitle("Gender of customers") +theme_classic()p4 <- Churn %>%ggplot() +geom_bar(aes(Tenure)) +theme_classic() +ggtitle("No of customers over their tenure")grid.arrange(arrangeGrob(p1, p2, ncol =2), arrangeGrob(p3, p4, ncol =2),nrow =2)```From the above plot, the credit score is looking to be normal with median in range of 650-700, and Geography variable consists of 3 values, i.e, France(50%), Germany(25%) and Spain(25%). The Gender variable consists of Male and Female values and male count(5457) is more than female count(4543). The tenure of all customers is between 0-10 years and is almost equal no of customers in each year. ```{r}p5 <- Churn %>%filter(Balance !=0) %>%ggplot(aes(Balance)) +geom_histogram(col ="white", bins =30) +theme_classic() +ggtitle("Balance of customers")p6 <- Churn %>%group_by(NumOfProducts) %>%# Variable to be transformedcount() %>%ungroup() %>%mutate(perc =`n`/sum(`n`)) %>%arrange(perc) %>%mutate(labels = scales::percent(perc)) %>%ggplot(aes(x ="", y = perc, fill =as.factor(NumOfProducts))) +ggtitle("No of products owned by customers") +geom_col(color ="black") +geom_label(aes(label = labels), color =c(1, "white", "white", "white"),position =position_stack(vjust =0.5),show.legend =FALSE) +guides(fill =guide_legend(title ="NumofProducts")) +scale_fill_viridis_d() +coord_polar(theta ="y") +theme_void()p7 <- Churn %>%ggplot() +geom_bar(aes(as.factor(HasCrCard))) +ggtitle("No of customers having credit card") +xlab("Credit Card status") +theme_classic()grid.arrange(arrangeGrob(p5, p6, ncol =2), p7,nrow =2)```We have a lot of people with balance as zero but if we ignore as in the above plot that the other values form a normal at 120000 in median, and according to above plot, the maximum no of the products owned by customers is 1 and minimum is 4. Majority of customers own either 1 or 2 products. And according to bar graph, 7055 customers have credit card and 2945 customers does not have credit card. ```{r}p8 <- Churn %>%ggplot() +geom_bar(aes(as.factor(IsActiveMember))) +ggtitle("Active customers") +xlab("Active Member") +theme_classic()p9 <- Churn %>%ggplot(aes(EstimatedSalary)) +geom_density(color="Blue", alpha=0.8) +ggtitle("Estimated salary of customers") +theme_classic()p10 <- Churn %>%group_by(Exited) %>%# Variable to be transformedcount() %>%ungroup() %>%mutate(perc =`n`/sum(`n`)) %>%arrange(perc) %>%mutate(labels = scales::percent(perc)) %>%ggplot(aes(x ="", y = perc, fill =as.factor(Exited))) +ggtitle("Churn-rate of customers") +geom_col(color ="black") +geom_label(aes(label = labels), color =c(1, "white"),position =position_stack(vjust =0.5),show.legend =FALSE) +guides(fill =guide_legend(title ="Churn-rate")) +scale_fill_viridis_d() +coord_polar(theta ="y") +theme_void()grid.arrange(arrangeGrob(p8, p9, ncol =2), p10,nrow =2)```Form the above plot, it looks like there are as many inactive members(4849) as active members(5151). And from above line graph, the data set contains the customers of all types of income from 0-200000. At last from the pie chart, 80% of customers are not churned and 20% have already exited.## Relationship between the variables```{r}temp <- Churn %>%select(-c(Geography, Gender))round(cor(temp),3) %>%melt() %>%ggplot(aes(x=Var1, y=Var2, fill=abs(value))) +geom_tile() +scale_fill_continuous(type="gradient", low ="skyblue", high ="blue", breaks =c(0,1,0.025)) +geom_text(aes(Var2, Var1, label = value), color ="white", size =4) +labs(x =NULL, y =NULL) +theme(legend.position="none") +ggtitle("Correlation plot") +theme(axis.text.x =element_text(angle =90))```Churn has a positive correlation with age, balance and estimated salary. Generally the correlation coefficients are not so high.### Relationship between churn-rate and categorical variablesThere are 4 categorical variables in the data set as follows:```{r}p1 <- Churn %>%group_by(Geography, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x = Geography)) +geom_bar(position ="dodge", stat ="identity") +labs(fill ="Exited") +ggtitle("Churn-rate on basis of location") +xlab("Geography") +ylab("Frequency") +theme_classic()p2 <- Churn %>%group_by(Gender, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x = Gender)) +geom_bar(position ="dodge", stat ="identity") +ggtitle("Churn-rate per Gender") +labs(fill ="Exited") +xlab("Gender") +ylab("Frequency") +theme_classic()p3 <- Churn %>%group_by(HasCrCard, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x =as.factor(HasCrCard))) +geom_bar(position ="dodge", stat ="identity") +ggtitle("Churn-rate per customer's credit card status") +labs(fill ="Exited") +xlab("Credit Card status") +ylab("Frequency") +theme_classic()p4 <- Churn %>%group_by(IsActiveMember, Exited) %>%count() %>%ggplot(aes(fill =as.factor(Exited), y = n, x =as.factor(IsActiveMember))) +geom_bar(position ="dodge", stat ="identity") +ggtitle("Churn-rate per customer's activity") +labs(fill ="Exited") +xlab("Active Member") +ylab("Frequency") +theme_classic()grid.arrange(arrangeGrob(p1, p2, ncol =2),arrangeGrob(p3, p4, ncol =2),nrow =2)```Majority of the data is from people from France. However, the proportion of churned customers is with inversely related to the population of customers alluding to the bank possibly having a problem (maybe not enough customer service resources allocated) in the areas where it has fewer clients. Also from the above plot, the proportion of female customers churning is also greater than that of male customers and majority of the customers that churned are those with credit cards given that majority of the customers have credit cards could prove this to be just a coincidence. However, unsurprisingly the inactive members have a greater churn. Worryingly is that the overall proportion of inactive members is quite high suggesting that the bank may need a program implemented to turn this group to active customers as this will definately have a positive impact on the customer churn.### Relationship between churn-rate and continuous variablesThere are 6 continuous variables in the data set as follows:```{r}p1 <- Churn %>%ggplot(aes(x = Exited, y = CreditScore, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's credit score")p2 <- Churn %>%ggplot(aes(x = Exited, y = Age, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate on basis of customer's age")p3 <- Churn %>%ggplot(aes(x = Exited, y = Tenure, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's tenure")p4 <- Churn %>%ggplot(aes(x = Exited, y = Balance, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's balance")p5 <- Churn %>%ggplot(aes(x = Exited, y = NumOfProducts, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per accounts customer's own")p6 <- Churn %>%ggplot(aes(x = Exited, y = EstimatedSalary, fill =as.factor(Exited))) +geom_boxplot(alpha=0.3) +theme(legend.position="none") +scale_fill_brewer(palette="Dark2") +ggtitle("Churn-rate per customer's salary")grid.arrange(arrangeGrob(p1, p2, ncol =2),arrangeGrob(p3, p4, ncol =2),arrangeGrob(p5, p6, ncol =2),nrow =3)```From the above plot, there is no significant difference in the credit score distribution between retained and churned customers. And also we can observe that the older customers are churning at more rate than the younger ones alluding to a difference in service preference in the age categories. The bank may need to review their target market or review the strategy for retention between the different age groups. With regard to the tenure, the clients on either extreme end (spent little time with the bank or a lot of time with the bank) are more likely to churn compared to those that are of average tenure. And also, the bank is losing customers with significant bank balances which is likely to hit their available capital for lending. And from the plot, it is clear that the no of products not has a significant effect on the likelihood to churn and also the Estimated salary not has a significant effect on the likelihood to churn.## Hypothesis Testing```{r}chisq.test(Churn$Exited,Churn$IsActiveMember)```We have a high X-squared value and a p-value of less than 0.05 significance level. So we can conclude that Exited and IsActiveMember have a significant relationship.```{r}chisq.test(Churn$Exited,Churn$Geography)```We have a high X-squared value more than the previous test and a p-value of less than 0.05 significance level. So we can conclude that Exited and Geography have a significant relationship.## Linear regression models```{r}model1 <-lm(Exited ~as.factor(IsActiveMember), data = Churn)summary(model1)``````{r}model2 <-lm(Exited ~ ., data = Churn)summary(model2)``````{r}model3 <-lm(Exited ~ Geography, data = Churn)summary(model3)```Summarizing the above three models, the model1 describes the regression between Exited and Active member and second model predicts the churn rate based on all the variables and third model is analysis between exited and geography. And from model1 and model3, it seems that the variables Active member and Geography to be significant proving our hypothesis.```{r}model <-lm(Exited ~ . -Geography, data = Churn)summary(model)``````{r}anova(model, model2)```From the above F-test, we can say the variable geography is significant as p-value is less than 0.05 significance level. But I will plot the diagonistic plots to further confirm my results.### Backward Elimination```{r}model4 <-lm(Exited ~ . -Geography -HasCrCard -NumOfProducts -EstimatedSalary -Tenure, data = Churn)summary(model4)```In the model4, I have used backward elimination process by removing the highest p values to get a better model and it is best after removing above 5 variables removed in call.### Model Evaluation```{r}par(mfrow =c(2,3)); plot(model1, which =1:6)par(mfrow =c(2,3)); plot(model2, which =1:6)par(mfrow =c(2,3)); plot(model3, which =1:6)par(mfrow =c(2,3)); plot(model4, which =1:6)```According to the diagnostic plots, none of the models seem to fit super well. There are violations of assumptions in models. In Residuals vs Fitted plot, some of the residuals seem to have a trend (higher fitted values have lower residuals). Same with the Q-Q, plot, lower theoretical quantiles gave significantly lower standardized residuals. The scale location graph has a negative trend, suggesting variance may not be constant. Cooks dist to leverage has a high cooks distance and leverage and likely has a large influence on the model. The other models display similar issues. So none of the plots are conclude to prove our hypothesis, so I will be doing logistic regression to get a better model and check the accuracy.## Logistic RegressionIn the logistic regression, the coefficients table shows the beta coefficient estimates and their significance levels. Columns are:Estimate: the intercept (b0) and the beta coefficient estimates associated to each predictor variableStd.Error: the standard error of the coefficient estimates. This represents the accuracy of the coefficients. The larger the standard error, the less confident we are about the estimate.z value: the z-statistic, which is the coefficient estimate (column 2) divided by the standard error of the estimate (column 3)Pr(>|z|): The p-value corresponding to the z-statistic. The smaller the p-value, the more significant the estimate is.```{r}set.seed(1234)trainIndex <-sample(1:nrow(Churn), size =round(0.7*nrow(Churn)))ChurnTrain <- Churn[trainIndex,]ChurnTest <- Churn[-trainIndex,]cat(nrow(ChurnTrain), " observations are in the training set. \n")cat(nrow(ChurnTest), " observations are in the testing set. \n")``````{r}model5 <-glm(data = ChurnTrain, Exited ~ IsActiveMember, family ="binomial")summary(model5)``````{r}# predicting test data based on the modelChurnTest$pred_log <-predict(model5, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)``````{r}auc <-auc(ChurnTest$Exited, ChurnTest$pred_log) accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))print(paste("Accuracy=", accuracy))print(paste("Classification Error=", classification_error))# confusion matrixtable(ChurnTest$Exited, ChurnTest$pred_churn, dnn=c("True Status", "Predicted Status")) # confusion matrix``````{r}plot(roc(ChurnTest$Exited ~ ChurnTest$pred_log), print.auc =TRUE, legacy.axes=T)``````{r}model6 <-glm(data = ChurnTrain, Exited ~ Geography, family ="binomial")summary(model6)``````{r}# predicting test data based on the modelChurnTest$pred_log <-predict(model6, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)``````{r}auc <-auc(ChurnTest$Exited, ChurnTest$pred_log) accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))print(paste("Accuracy=", accuracy))print(paste("Classification Error=", classification_error))# confusion matrixtable(ChurnTest$Exited, ChurnTest$pred_churn, dnn=c("True Status", "Predicted Status")) # confusion matrix``````{r}plot(roc(ChurnTest$Exited ~ ChurnTest$pred_log), print.auc =TRUE, legacy.axes=T)``````{r}model7 <-glm(data = ChurnTrain, Exited ~ . -HasCrCard -NumOfProducts -EstimatedSalary -Tenure, family ="binomial")summary(model7)``````{r}#| warning: false# predicting test data based on the modelChurnTest$pred_log <-predict(model7, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)``````{r}auc <-auc(ChurnTest$Exited, ChurnTest$pred_log) accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))print(paste("Accuracy=", accuracy))print(paste("Classification Error=", classification_error))# confusion matrixtable(ChurnTest$Exited, ChurnTest$pred_churn, dnn=c("True Status", "Predicted Status")) # confusion matrix``````{r}plot(roc(ChurnTest$Exited ~ ChurnTest$pred_log), print.auc =TRUE, legacy.axes=T)``````{r}model8 <-glm(data = ChurnTrain, Exited ~ ., family ="binomial")summary(model8)``````{r}#| warning: false# predicting test data based on the modelChurnTest$pred_log <-predict(model8, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)``````{r}auc <-auc(ChurnTest$Exited, ChurnTest$pred_log) accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))print(paste("Accuracy=", accuracy))print(paste("Classification Error=", classification_error))# confusion matrixtable(ChurnTest$Exited, ChurnTest$pred_churn, dnn=c("True Status", "Predicted Status")) # confusion matrix``````{r}plot(roc(ChurnTest$Exited ~ ChurnTest$pred_log), print.auc =TRUE, legacy.axes=T)``````{r}model9 <-glm(data = ChurnTrain, Exited ~ . -Geography, family ="binomial")summary(model9)``````{r}#| warning: false# predicting test data based on the modelChurnTest$pred_log <-predict(model9, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)``````{r}auc <-auc(ChurnTest$Exited, ChurnTest$pred_log) accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))print(paste("Accuracy=", accuracy))print(paste("Classification Error=", classification_error))# confusion matrixtable(ChurnTest$Exited, ChurnTest$pred_churn, dnn=c("True Status", "Predicted Status")) # confusion matrix``````{r}plot(roc(ChurnTest$Exited ~ ChurnTest$pred_log), print.auc =TRUE, legacy.axes=T)``````{r}model10 <-glm(data = ChurnTrain, Exited ~ . -IsActiveMember, family ="binomial")summary(model10)``````{r}#| warning: false# predicting test data based on the modelChurnTest$pred_log <-predict(model10, newdata = ChurnTest, type ="response")# Changing probabilitiesChurnTest$pred_churn <-ifelse(ChurnTest$pred_log >0.5, 1, 0)``````{r}auc <-auc(ChurnTest$Exited, ChurnTest$pred_log) accuracy <-accuracy(ChurnTest$Exited, ChurnTest$pred_churn)classification_error <-ce(ChurnTest$Exited, ChurnTest$pred_churn) # print out the metrics on to screenprint(paste("AUC=", auc))print(paste("Accuracy=", accuracy))print(paste("Classification Error=", classification_error))# confusion matrixtable(ChurnTest$Exited, ChurnTest$pred_churn, dnn=c("True Status", "Predicted Status")) # confusion matrix``````{r}plot(roc(ChurnTest$Exited ~ ChurnTest$pred_log), print.auc =TRUE, legacy.axes=T)```### Likelihood ratio testA logistic regression is said to provide a better fit to the data if it demonstrates an improvement over a model with fewer predictors. This is performed using the likelihood ratio test, which compares the likelihood of the data under the full model against the likelihood of the data under a model with fewer predictors. Removing predictor variables from a model will almost always make the model fit less well (i.e. a model will have a lower log likelihood), but it is necessary to test whether the observed difference in model fit is statistically significant. Given that H0 holds that the reduced model is true, a p-value for the overall model fit statistic that is less than 0.05 would compel us to reject the null hypothesis. It would provide evidence against the reduced model in favor of the current model. The likelihood ratio test can be performed in R using the lrtest() function from the lmtest package.```{r}lrtest(model10, model8)```From the above likelihood ratio test, we can say that as p-value is less than 0.05, our variable active member is significant, so we can reject the null hypothesis and confirm that there is a significant relationship between active member and churn rate. And we can conclude that there is a high possibility of inactive members to churn.```{r}lrtest(model9, model8)```From the above likelihood ratio test, we can say that as p-value is less than 0.05, our variable Geography is significant, so we can reject the null hypothesis and confirm that there is a significant relationship between Geography and churn rate. And we can conclude that there is a high possibility of predicting the churn-rate on basis of Geography.## ConclusionFrom the hypothesis testing, logistic regression and likelihood ratio test we can conclude the following:- We observe from likelihood ratio test that overall Geography variable is significant, so we can reject the null hypothesis and confirm that there is a significant relationship between Geography and churn rate. And we can also conclude that there is a high probability of customers churning when it comes to Germany, but when we look at Spain, the probable churn-rate will be less when compared to Germany as it is not significant and churn-rate will be similar to the France based on the coefficient value.- We can observe that there is a significant, but negative relationship between the active member variable and churn-rate based on the p-value and coefficient value, so we can conclude that there is a significant relationship between the churn rate of a customer and their active status and conclude that the inactive members are more likely to churn than the active members.## Further StudyI would like to look into more models using logistic regression to further improve my accuracy and also would like to try random forest and decision tree algorithms and check them.## Bibliography- Chicco, D. & Jurman, G., 2020. The advantages of the Matthews correlation coefficient (MCC)over F1 score and accuracy in binary classification evaluation. BMC genomics, 21(1), pp. 6-13.- Colgate, M., Stewart, K. & Kinsella, R., 1996. Customer Defection: A study of the student marketin Ireland. International Journal of Bank Marketing, 14(3), pp. 23-29.- De Caigny, A., Coussement, K. & De Bock, K. W., 2018. A new hybrid classification algorithmfor customer churn prediction based on logistic regression and decision trees. European Journalof Operational Research, 269(2), pp. 760-772.- Delgado, R. & Tibau, X. 2019. Why Cohen's Kappa should be avoided as performance measurein classification, PLOS ONE, 14(9), pp. e0222916.- Ganesh, J., Arnold, M. J. & Reynolds, K. E., 2000. Understanding the Customer Base of ServiceProviders: An Examination of the Differences between Switchers and Stayers. Journal ofMarketing, 64(3), pp. 65-87.- Gorodkin, J., 2004. Comparing two K-category assignments by a K-category correlationcoefficient. Computational Biology and Chemistry, 28(5), pp. 367-374.- Hair, J. F., Black, J. W. C., Babin, B. J. & Anderson, R. E., 2014. Multivariate Data Analysis. 7th ed. Harlow: Pearson international edn.- Hastie, T., Tibshirani, R. & Friedman, J., 2009. The Elements of Statistical Learning: data mining, inference, and prediction. 2nd ed. New York, NY: Springer New York.- Hosmer, D. W., Lemeshow, S. & Sturdivant, R. X., 2013. Applied logistic regression, 3rd ed. NewJersey, NJ: Wiley.- James, G., Witten, D., Hastie, T. & Tibshirani, R., 2013. An Introduction to Statistical Learning: with Applications in R. New York, NY: Springer New York.- McHugh, M. L., 2012. Interrater reliability: the Kappa Statistic. Biochemia Medica, 22(3), pp.276-282.- The Economist, 2019. A Whole New World: How technology is driving the evolution of intelligentbanking, London: The Economist Intelligence Unit (EIU).- Verbeke, W. et al., 2012. New insights into churn prediction in the Telecommunication Sector: Aprofit driven data mining approach. European Journal of Operational Research, 218(1), pp. 211-229.