Code
library(tidyverse)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
knitr::opts_chunk$set(echo = TRUE)##Read in data from Excel file
library(readxl)
LungCapData <- read_excel('_data/LungCapData.xls')hist(LungCapData$LungCap, freq = FALSE)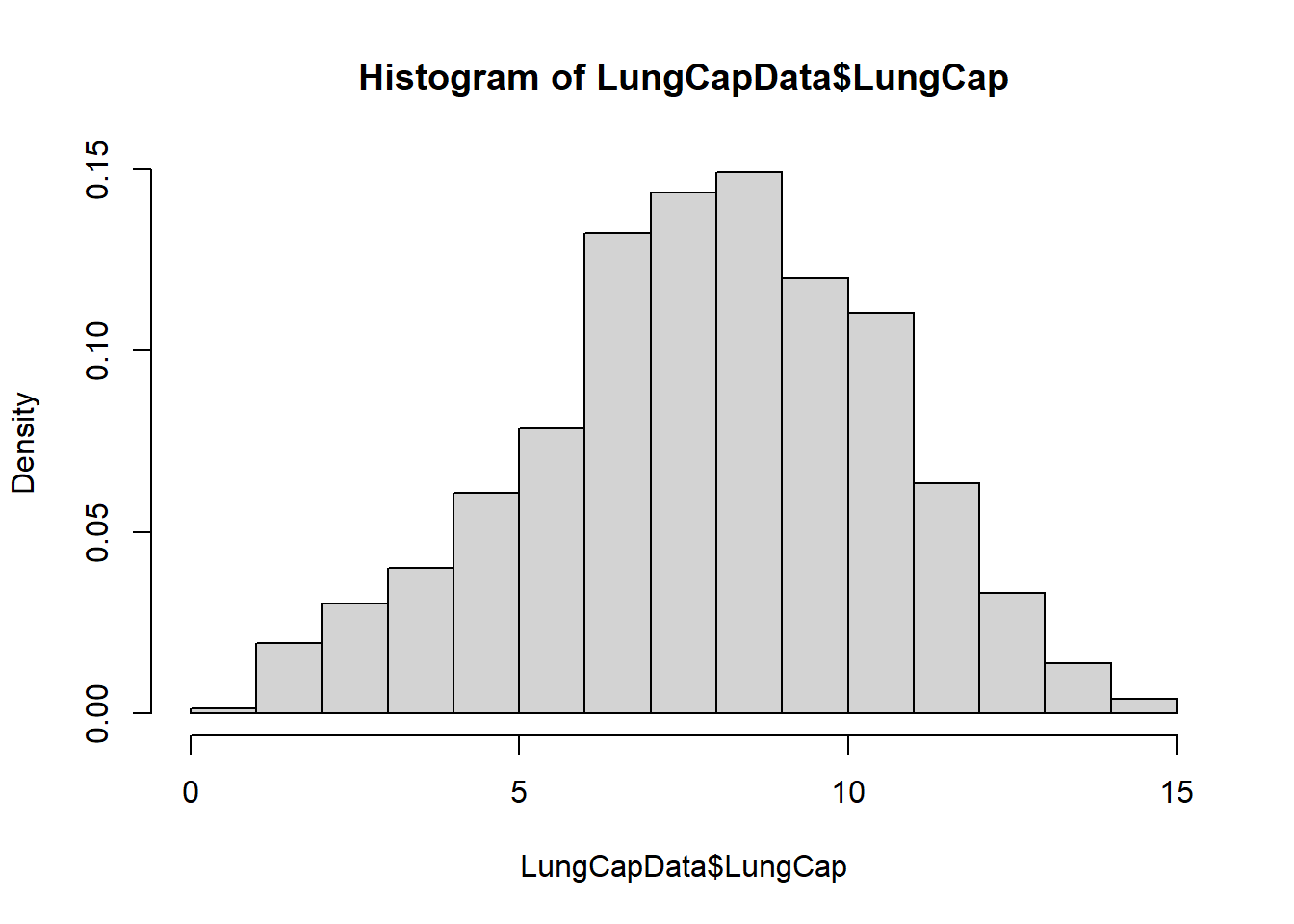
The histogram suggests that the distribution is close to a normal distribution - most of the observations are close to the mean, with very few close to the margins (0 and 15).
boxplot(LungCap ~ Gender, data = LungCapData, horizontal = TRUE)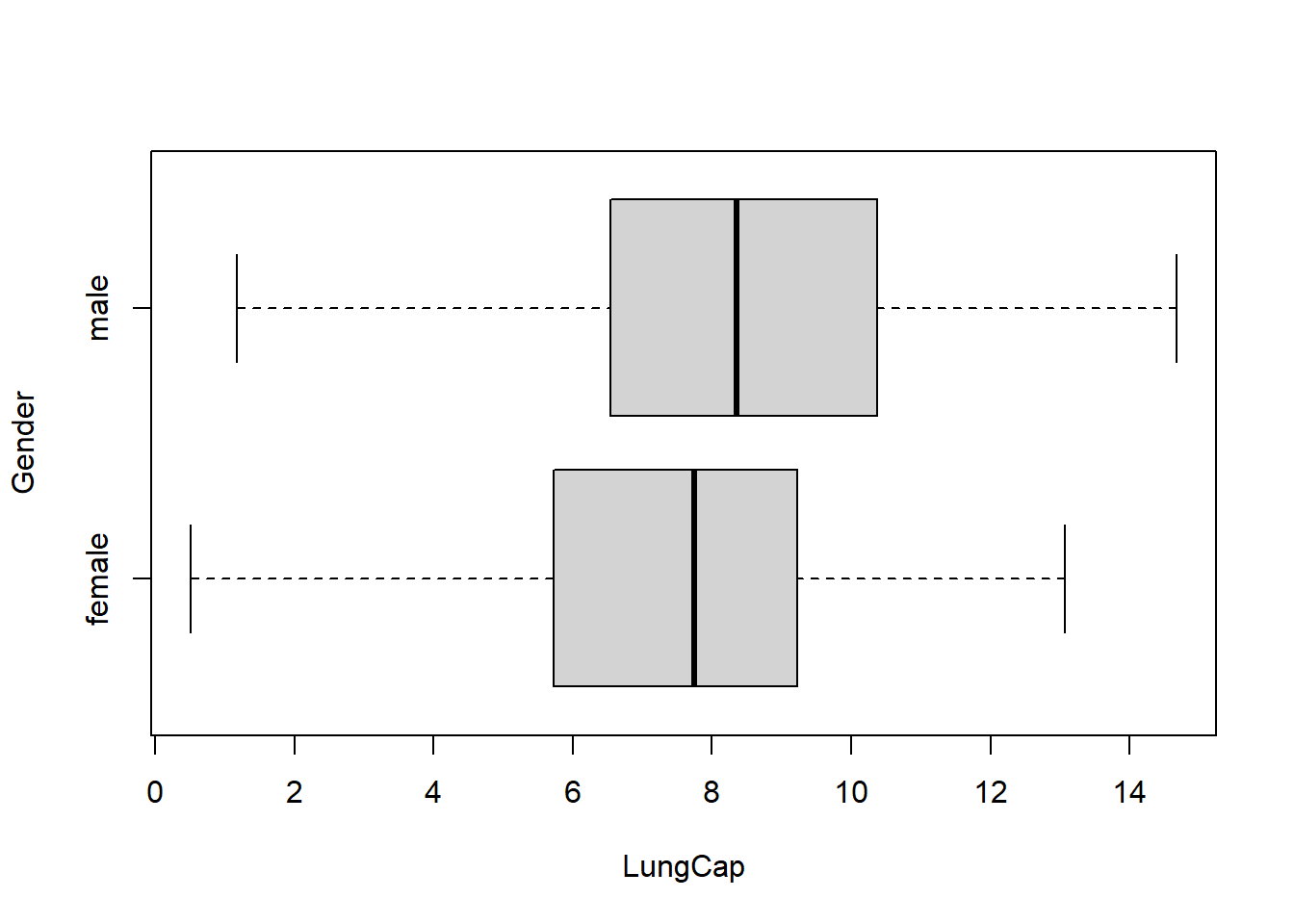
The boxplots show that male lung capacity has a wider range than that of females; however, the minimum, median, and maximum values are all higher than those of females. This implies that, as a group, men are likely to have higher lung capacity than women.
library(dplyr)
LungCapData %>%
group_by(Smoke) %>%
summarize(mean = mean(LungCap), n = n())# A tibble: 2 × 3
Smoke mean n
<chr> <dbl> <int>
1 no 7.77 648
2 yes 8.65 77In this dataset, the mean lung capacity of smokers is actually higher than that of non-smokers. Since this is counter to what would be expected, there is likely another variable exerting a confounding effect on lung capacity.
LungCapData_AgeGroups <- LungCapData %>%
mutate(AgeGroup = case_when(Age <= 13 ~ "less than or equal to 13",
Age == 14 | Age == 15 ~ "14 to 15",
Age == 16 | Age == 17 ~ "16 to 17",
Age >= 18 ~ "greater than or equal to 18"))LungCapData_AgeGroups %>%
group_by(AgeGroup, Smoke) %>%
summarize(MeanLungCap = mean(LungCap), n = n())`summarise()` has grouped output by 'AgeGroup'. You can override using the
`.groups` argument.# A tibble: 8 × 4
# Groups: AgeGroup [4]
AgeGroup Smoke MeanLungCap n
<chr> <chr> <dbl> <int>
1 14 to 15 no 9.14 105
2 14 to 15 yes 8.39 15
3 16 to 17 no 10.5 77
4 16 to 17 yes 9.38 20
5 greater than or equal to 18 no 11.1 65
6 greater than or equal to 18 yes 10.5 15
7 less than or equal to 13 no 6.36 401
8 less than or equal to 13 yes 7.20 27When lung capacity data is further broken down by age group, the lung capacities of smokers and non-smokers appear to be more in line with expectations. The one exception is the 13 and under age category - here, mean lung capacity is actually higher for smokers. This anomaly could be due to the fact that the number of observations is significantly higher for this age group than any of the others, likely resulting in a wider range of lung capacities. Also, this age category, which includes ages 3 through 13, covers a broader scope of ages than any of the other categories, likely producing the paradox of a smaller number of smokers exhibiting higher lung capacities than their cohorts simply because they are older.
cor(LungCapData$LungCap, LungCapData$Age)[1] 0.8196749cov(LungCapData$LungCap, LungCapData$Age)[1] 8.738289Since the correlation coefficient is close to 1, there is a high degree of correlation between lung capacity and age. The covariance of 8.7, being a positive number, indicates that as age increases, lung capacity increases.
PriorConv <- c(0,1,2,3,4)
Freq <- c(128,434,160,64,24)
PrisonerData <- data.frame (PriorConv, Freq)
PrisonerData PriorConv Freq
1 0 128
2 1 434
3 2 160
4 3 64
5 4 24probability = frequency/n
160/810[1] 0.1975309probability = frequency(0)/n + frequency(1)/n
(128/810) + (434/810)[1] 0.6938272probability = frequency(0)/n + frequency(1)/n + frequency(2)/n
(128/810) + (434/810) + (160/810)[1] 0.891358probability = frequency(3)/n + frequency(4)/n
(64/810) + (24/810)[1] 0.108642PriorConv <- c(0,1,2,3,4)
Probs <- c(0.1580247, 0.5358025, 0.1975309, 0.07901235, 0.02962963)c(PriorConv %*% Probs)[1] 1.28642var(PriorConv)[1] 2.5sd(PriorConv)[1] 1.581139sqrt(var(PriorConv)) == sd(PriorConv)[1] TRUE