Code
library(tidyverse)
library(dplyr)
library(readxl)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(dplyr)
library(readxl)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE)##1. Use the LungCapData to answer the following questions. (Hint: Using dplyr, especiallygroup_by() and summarize() can help you answer the following questions relatively efficiently.)
df<- read_excel("_data/LungCapData.xls")
head(df)# A tibble: 6 × 6
LungCap Age Height Smoke Gender Caesarean
<dbl> <dbl> <dbl> <chr> <chr> <chr>
1 6.48 6 62.1 no male no
2 10.1 18 74.7 yes female no
3 9.55 16 69.7 no female yes
4 11.1 14 71 no male no
5 4.8 5 56.9 no male no
6 6.22 11 58.7 no female no #Summarize
summary(df) LungCap Age Height Smoke
Min. : 0.507 Min. : 3.00 Min. :45.30 Length:725
1st Qu.: 6.150 1st Qu.: 9.00 1st Qu.:59.90 Class :character
Median : 8.000 Median :13.00 Median :65.40 Mode :character
Mean : 7.863 Mean :12.33 Mean :64.84
3rd Qu.: 9.800 3rd Qu.:15.00 3rd Qu.:70.30
Max. :14.675 Max. :19.00 Max. :81.80
Gender Caesarean
Length:725 Length:725
Class :character Class :character
Mode :character Mode :character
mean(df$LungCap)[1] 7.863148median(df$LungCap)[1] 8var(df$LungCap)[1] 7.086288sd(df$LungCap)[1] 2.662008min(df$LungCap)[1] 0.507max(df$LungCap)[1] 14.675#a. What does the distribution of LungCap look like? (Hint: Plot a histogram with probability density on the y axis)
ggplot(df, aes(x=LungCap)) +
geom_histogram(binwidth=0.5,col='black',fill='gray')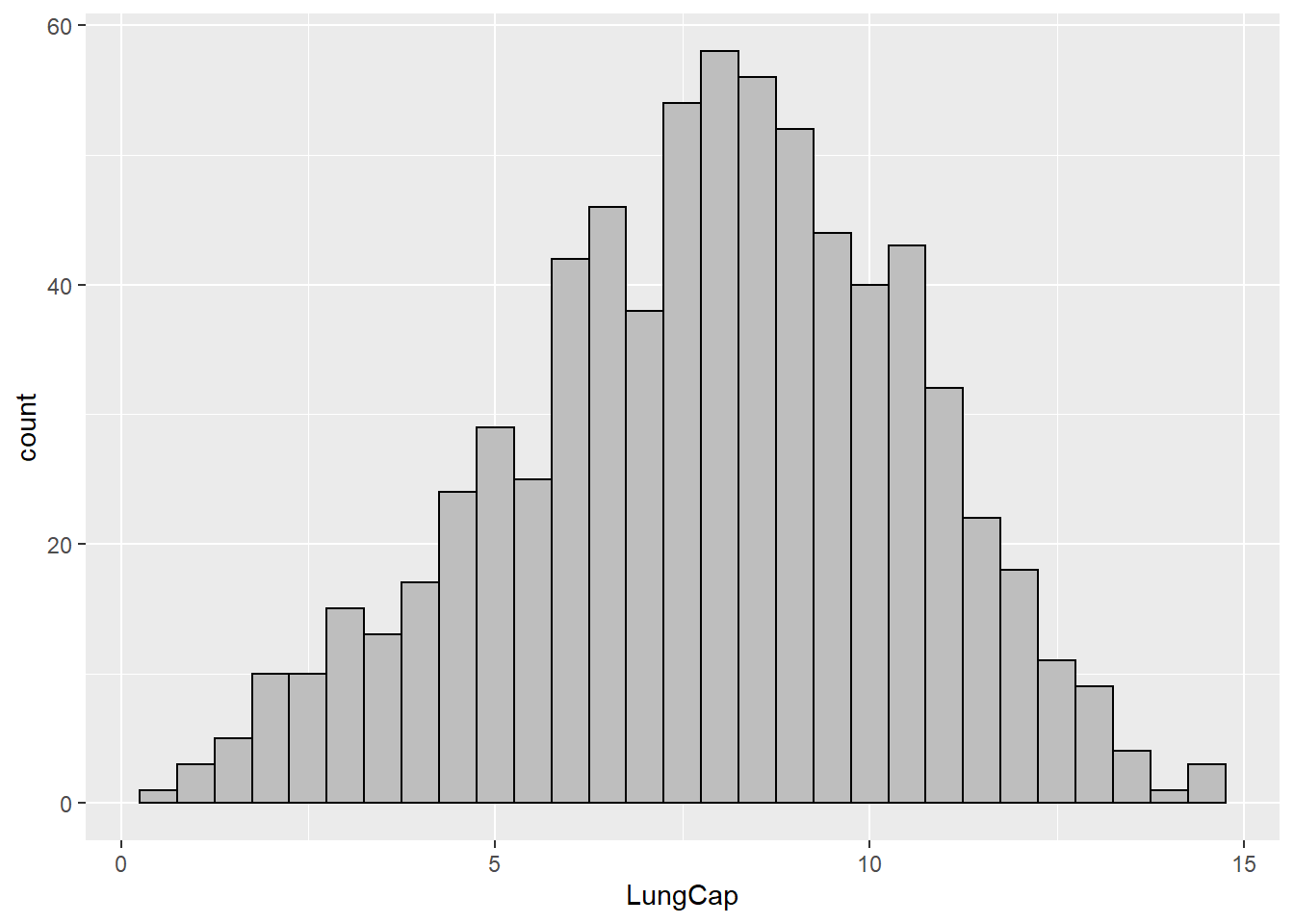
The histogram follows a distribution close to normal distibution. In fact, if we change binwidth slightly, it appears even closer to normal distribution.
ggplot(df, aes(x=LungCap)) +
geom_histogram(binwidth=1,col='black',fill='gray')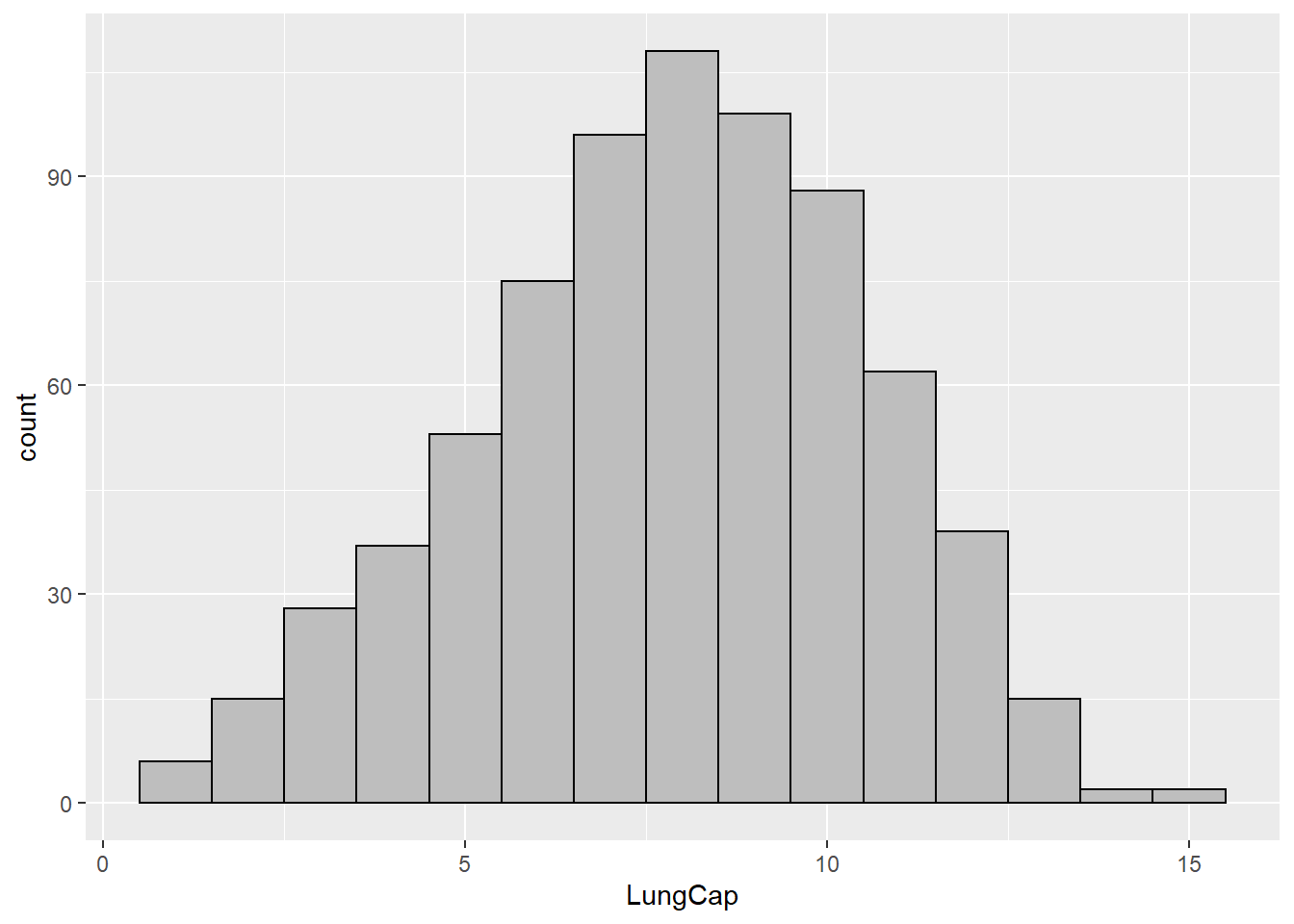
This helps illustrate the importance of binwidth and what it can do to our visualization interpretations.
#b. Compare the probability distribution of the LungCap with respect to Males and Females? (Hint: make boxplots separated by gender using the boxplot() function)
ggplot(df, aes(x = LungCap, y = Gender)) +
geom_boxplot()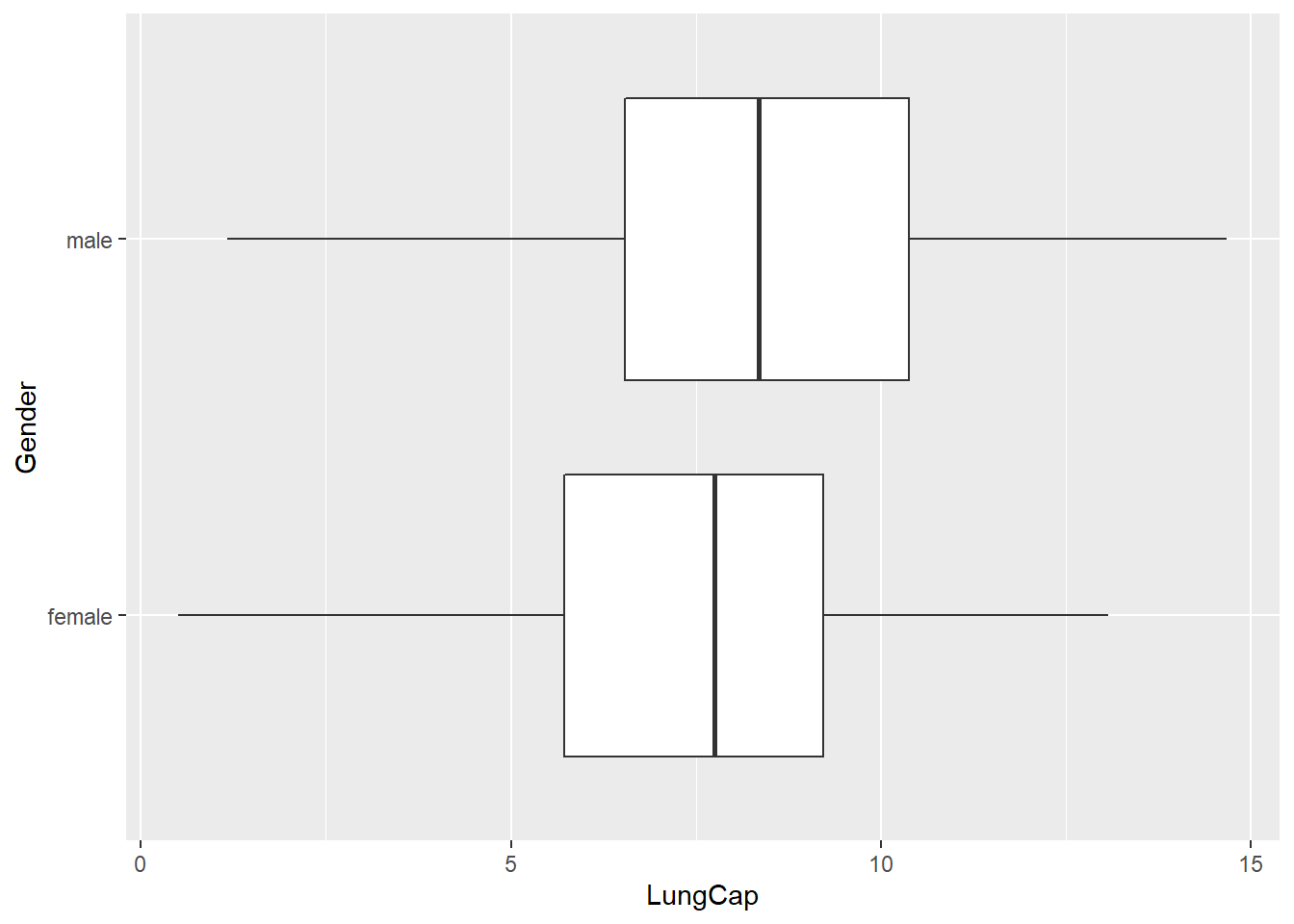
The distribution of male lung capacity is larger and longer than females’.
#c. Compare the mean lung capacities for smokers and non-smokers. Does it make sense?
df %>%
filter(Smoke == 'yes') %>%
pull(LungCap) %>%
mean() [1] 8.645455df %>%
filter(Smoke == 'no') %>%
pull(LungCap) %>%
mean()[1] 7.770188It does not make sense at face value. In this sample, smokers have a higher mean lung capacity than non-smokers. Let’s check how big each subsample is.
length(which(df$Smoke == 'yes'))[1] 77length(which(df$Smoke == 'no'))[1] 648As suspected, there are far more, almost 10 times as many, non-smokers. If we could gather data from all the smokers, perhaps our means would look a lot different. Maybe our sample was taken from young people whose lungs have not been long affected by the smoking.
df %>%
filter(Smoke == 'yes') %>%
pull(Age) %>%
median() [1] 15Again, as suspected, our sample of smokers is a young age. Therefore, the lack of difference in lung capacity between smokers and non-smokers is not too surprising.
#d. Examine the relationship between Smoking and Lung Capacity within age groups: “less than or equal to 13”, “14 to 15”, “16 to 17”, and “greater than or equal to 18”.
#Create age groups
df <- df %>%
mutate(agegroup = case_when(
Age <= 13 ~ "less than or equal to 13",
Age >= 14 & Age <= 15 ~ "14 to 15",
Age >= 16 & Age <= 17 ~ "16 TO 17",
Age >= 18 ~ "greater than or equal to 18"))
table(df$agegroup)
14 to 15 16 TO 17
120 97
greater than or equal to 18 less than or equal to 13
80 428 df %>%
filter(Smoke == 'yes') %>%
ggplot(aes(x=LungCap)) +
geom_histogram(binwidth=1,col='black',fill='gray')+
facet_wrap(~agegroup)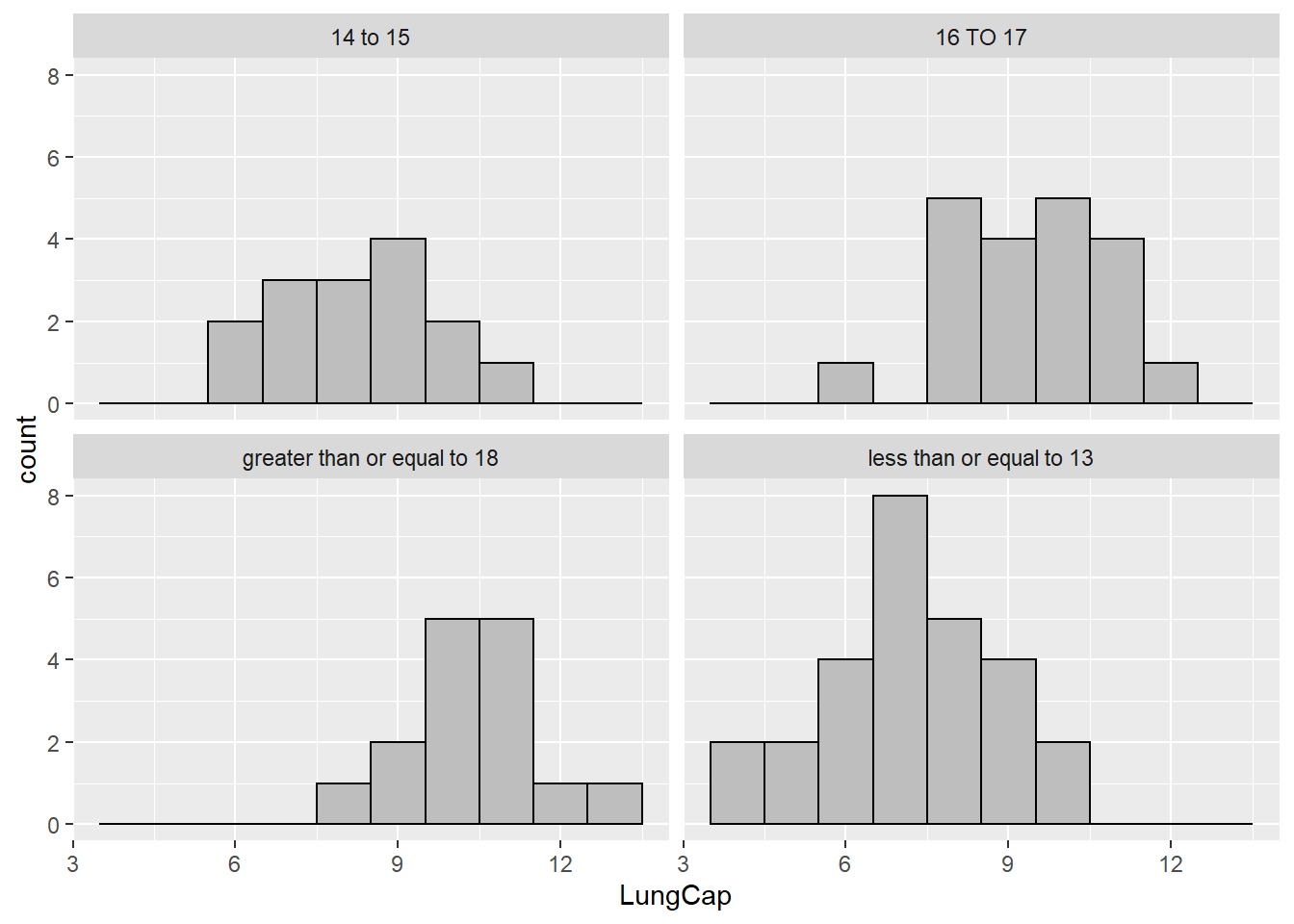
These histograms suggest that participants 13 or younger have smaller lung capacity. The Lung capacity seems to generally increase with age as children grow.
#e. Compare the lung capacities for smokers and non-smokers within each age group. Is your answer different from the one in part c. What could possibly be going on here?
ggplot(df, aes(x = LungCap,
fill = agegroup)) +
geom_density(alpha = 0.4)+
facet_wrap(~Smoke)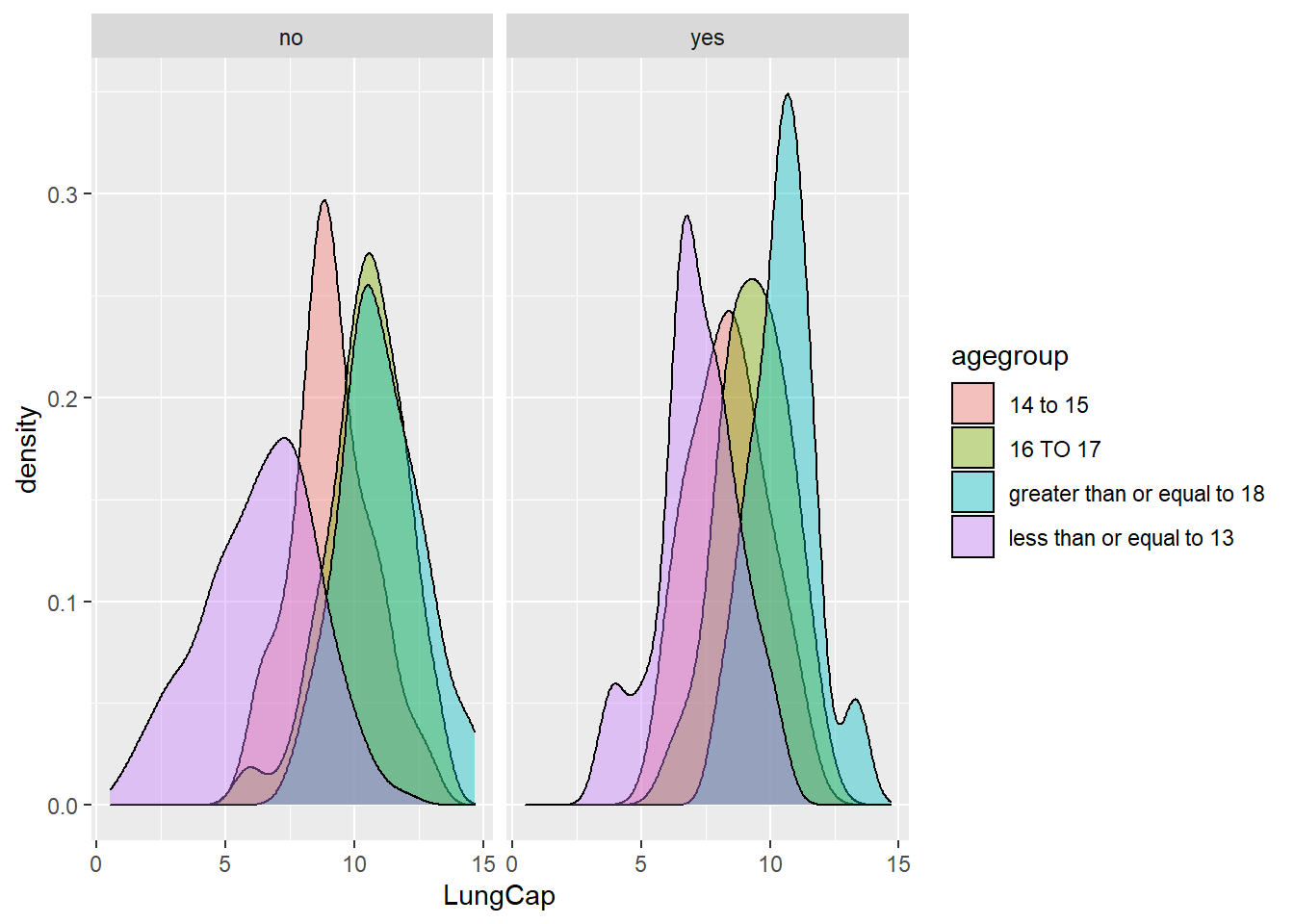
This visualization starts to explain furthermore why there is an unexpected result for lung capacity in smokers vs. non-smokers. As we have deducted, lung capacity generally improves with age (in growing years). However, teenagers approaching adulthood are also a group more likely to have access or influence to smoking cigarettes. It is likely that our smokers account for some of the older participants, who happen to be closer to normal smoking age.
#f. Calculate the correlation and covariance between Lung Capacity and Age. (use the cov() and cor() functions in R). Interpret your results.
cov(df$LungCap, df$Age) #calculate covariance[1] 8.738289cor(df$LungCap, df$Age) #calculate correlation[1] 0.8196749A positive coraviance (8.74) indicates lung capacity and age tend to increase together. The positive correlation relatively close to 1 (0.82) indicates there is a fairly strong correlation between the variables.
##2. Let X = number of prior convictions for prisoners at a state prison at which there are 810 prisoners.
#create the sample
x<-rep(c(0,1,2,3,4),times=c(128, 434, 160, 64, 24))
sample(x, 10) [1] 2 1 1 0 1 1 2 1 0 1#Verify n of sample
sum(128, 434, 160, 64, 24)[1] 810#Calculate the mean
mean(x)[1] 1.28642#Verify the mean
sample_mean <- (((128*0)+(434*1)+(160*2)+(64*3)+(24*4))/810)
print(sample_mean)[1] 1.28642#Calculate the sd
sd(x)[1] 0.9259016#a. What is the probability that a randomly selected inmate has exactly 2 prior convictions?
#probability of 2 convictions?
dnorm.convict <- dnorm(2, mean(x), sd(x))
print(dnorm.convict)[1] 0.3201613The probability of 2 convications in 0.32.
#b. What is the probability that a randomly selected inmate has fewer than 2 prior convictions?
#probability of <2 convictions
less.than <- pnorm(2, mean(x), sd(x)) - dnorm.convict
print(less.than)[1] 0.4593924The probability of <2 convictions is 0.46.
#c. What is the probability that a randomly selected inmate has 2 or fewer prior convictions?
#probability of =<2 convictions?
pnorm.convict <- pnorm(2, mean(x), sd(x))
print(pnorm.convict)[1] 0.7795537The probability of less than or equal to 2 convictions is 0.78.
#d. What is the probability that a randomly selected inmate has more than 2 prior convictions?
#probability of >2 convictions?
greater.than <- 1 - pnorm.convict
print(greater.than)[1] 0.2204463The probability of greater than 2 convictions is 0.22.
#Verify all probabilities add to 1
less.than + dnorm.convict + greater.than[1] 1#e. What is the expected value for the number of prior convictions?
# Expected value of a probability distribution can be found with μ = Σx * P(x), where x = data value and P(x) = probability of data.
#Calculate probabilities of data
p0 <- dnorm(0, mean(x), sd(x))
p0[1] 0.1641252p1 <- dnorm(1, mean(x), sd(x))
p1[1] 0.410739p2 <- dnorm(2, mean(x), sd(x))
p2[1] 0.3201613p3 <- dnorm(3, mean(x), sd(x))
p3[1] 0.07772916p4 <- dnorm(4, mean(x), sd(x))
p4[1] 0.005877753#Calculate expected value
ev <- sum((0*p0), (1*p1), (2*p2), (3*p3), (4*p4))
ev[1] 1.30776#The expected value should be close to the mean in a normal distribution
mean(x)[1] 1.28642The expected value is 1.31.
#f. Calculate the variance and the standard deviation for the Prior Convictions.
#Calculate variance
var(x)[1] 0.8572937#Calculate the sd
sd(x)[1] 0.9259016