Code
library(readxl)
df <- read_excel("_data/LungCapData.xls")First, let’s read in the data from the Excel file:
library(readxl)
df <- read_excel("_data/LungCapData.xls")The distribution of LungCap looks as follows:
hist(df$LungCap)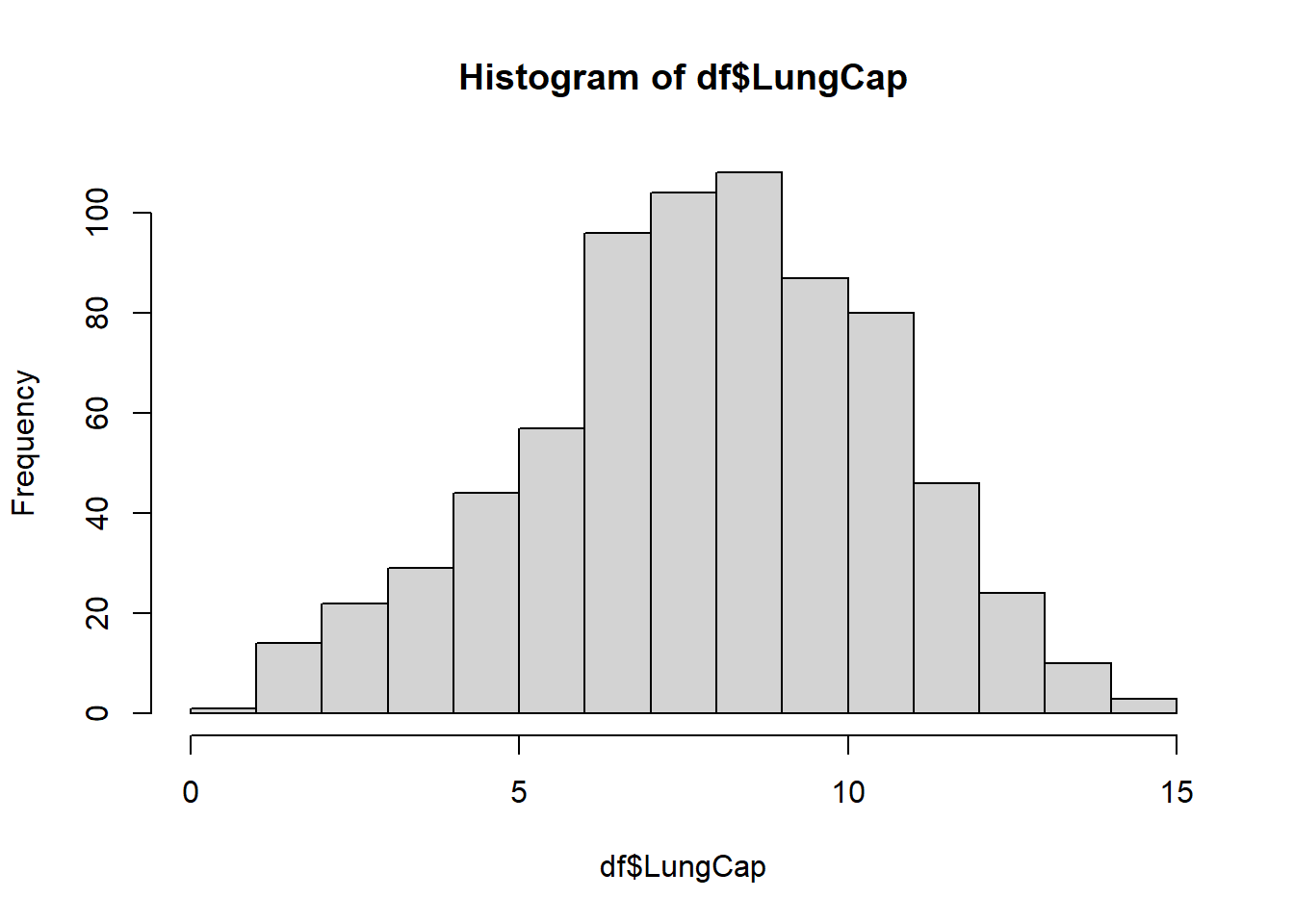
The histogram suggests that the distribution is close to a normal distribution. Most of the observations are close to the mean. Very few observations are close to the margins (0 and 15).
##b
library(ggplot2)
ggplot(df, aes(x = Gender, y = LungCap)) + geom_boxplot()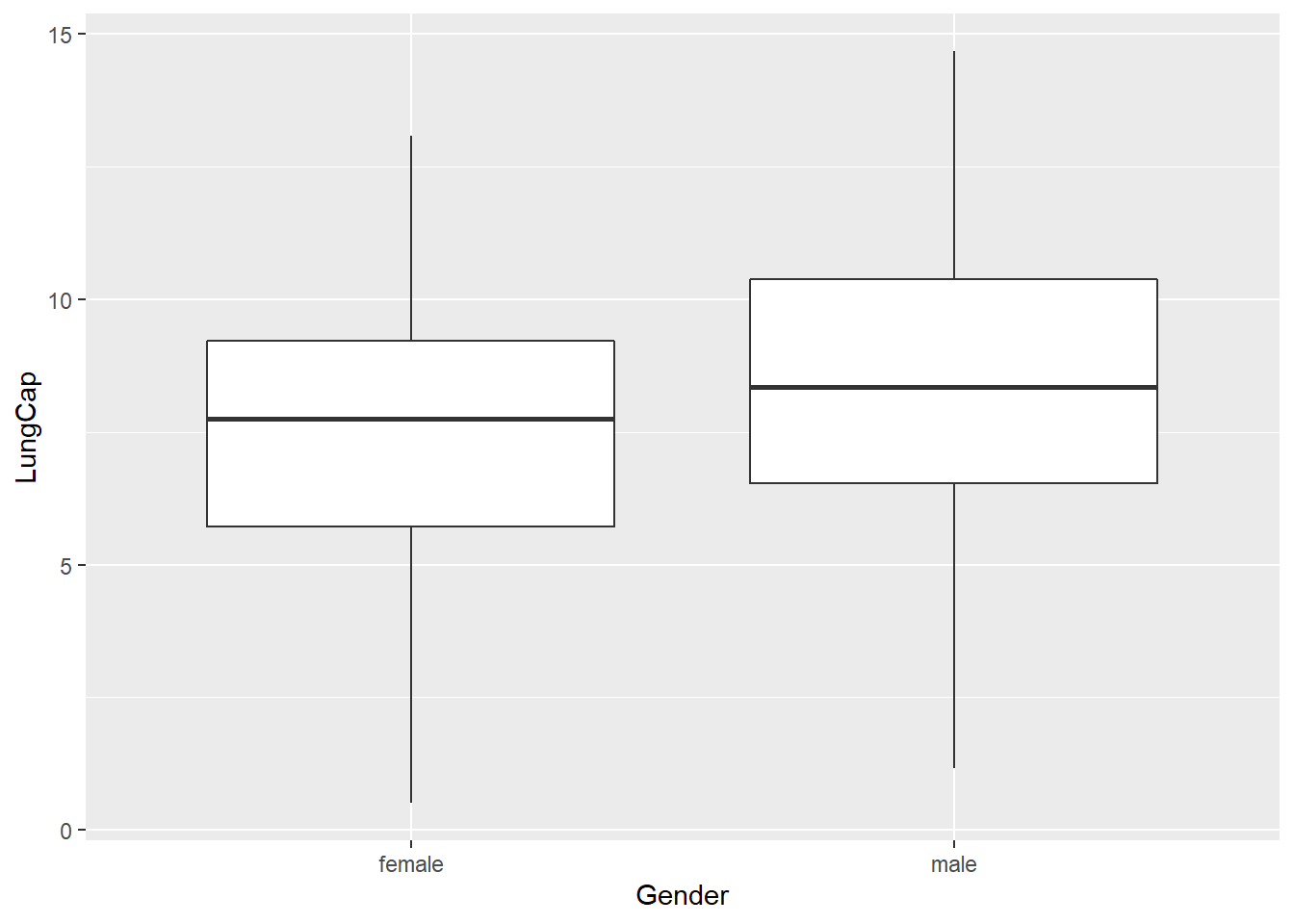
The probability distribution suggests that the lung capacity of males tends to be higher.
##c
aggregate(data = df, LungCap~Smoke, mean) Smoke LungCap
1 no 7.770188
2 yes 8.645455The mean lung capacity of smokers vs nonsmokers appears to be higher for smokers. This doesn’t really make sense because I’ve been taught to think smokers tend to have reduced lung capacity.
##d and e
x=1
df$AgeGroup <- rep(c("NA"),times=725)
while(x <= 725){
if(df$Age[x] <= 13){
df$AgeGroup[x] = "less than or equal to 13"
}
else if((df$Age[x] >= 14)&&(df$Age[x] <= 15)){
df$AgeGroup[x] = "14 to 15"
}
else if((df$Age[x] >= 16)&&(df$Age[x] <= 17)){
df$AgeGroup[x] = "16 to 17"
}
else if(df$Age[x] >= 18){
df$AgeGroup[x] = "greater than 18"
}
x = x + 1
}
aggregate(data = df, LungCap~AgeGroup+Smoke, mean) AgeGroup Smoke LungCap
1 14 to 15 no 9.138810
2 16 to 17 no 10.469805
3 greater than 18 no 11.068846
4 less than or equal to 13 no 6.358746
5 14 to 15 yes 8.391667
6 16 to 17 yes 9.383750
7 greater than 18 yes 10.513333
8 less than or equal to 13 yes 7.201852aggregate(data = df,LungCap~AgeGroup+Smoke,length) AgeGroup Smoke LungCap
1 14 to 15 no 105
2 16 to 17 no 77
3 greater than 18 no 65
4 less than or equal to 13 no 401
5 14 to 15 yes 15
6 16 to 17 yes 20
7 greater than 18 yes 15
8 less than or equal to 13 yes 27aggregate(data = df,Age~Smoke,mean) Smoke Age
1 no 12.03549
2 yes 14.77922It seems like people tend to have a lung capacity that increases with age. However, nonsmokers have a higher lung capacity for each age break down besides less than or equal to 13. It seems like smokers just might tend to be older. I confirmed this by looking at the length and mean ages per group, where you can see a majority of smokers are older, whereas non smokers tend to be younger. The mean age for smokers also tends to be older.
##f
cor(x= df$LungCap, y = df$Age)[1] 0.8196749cov(x= df$LungCap, y = df$Age)[1] 8.738289Lung capacity appears to be quite correlated with age. This means that Lung capacity tends to go up as age goes up, and vice versa. This is confirmed also by the covariance.
#Question 2
##a
print((160/810) * 100)[1] 19.75309The probability is 19.75309% that a randomly selected inmate has exactly 2 prior convictions.
##b
print(((434+128)/810) * 100)[1] 69.38272The probability is 69.38272% that a randomly selected inmate has fewer than 2 prior convictions.
##c
print(((160+434+128)/810) * 100)[1] 89.1358The probability is 89.1358% that a randomly selected inmate has 2 or fewer prior convictions.
##d
print(((64+24)/810) * 100)[1] 10.8642The probability is 10.8642% that a randomly selected inmate has more than 2 prior convictions.
##e
newDf <- NA
newDf[1:128] <- 0
newDf[129:562] <- 1
newDf[563:722] <- 2
newDf[723:786] <- 3
newDf[787:810] <- 4
newDf <- as.data.frame(newDf)
mean(newDf$newDf)[1] 1.28642The expected value, known as the “mean” when it deals in data that are not probability distributions, is 1.28642. Because I created a vector here, I took the mean, though I also could have calculated the expected value by multiplying the probabilities by the numbers. They are both the same value in this case.
##f
sd(newDf$newDf)[1] 0.9259016var(newDf$newDf)[1] 0.8572937The variance of prior convictions is 0.8572937, the standard deviation of prior convictions is 0.9259016.