Loading required package: car
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
Loading required package: effects
lattice theme set by effectsTheme()
See ?effectsTheme for details.
Code
library(smss)
Warning: package 'smss' was built under R version 4.2.2
Code
knitr::opts_chunk$set(echo=TRUE, warning=FALSE)
Question 1
A
With backward elimination, the variable ‘Beds’ would be deleted first as it has the largest p-value (0.487) and is therefore the weakest indicator of house price.
B
With forward selection, the variable ‘Size’ would be added first as it has the least p-value (0) and is therefore the strongest indicator of house price.
C
Beds has a substantial correlation with not only Price but also Size (which is a statistically significant predictor of house price). This suggests that the variables Beds and Size maybe multicollinear owing to the large p-value for the variables Beds.
D
Code
data(house.selling.price.2)m1 <-lm(P ~ S, data = house.selling.price.2)m2 <-lm(P ~ S + New, data = house.selling.price.2)m3 <-lm(P ~ . -Be, data = house.selling.price.2)m4 <-lm(P ~ ., data = house.selling.price.2)
a. R^2
Code
summary(m1)$r.squared
[1] 0.807866
Code
summary(m2)$r.squared
[1] 0.8483699
Code
summary(m3)$r.squared
[1] 0.8681361
Code
summary(m4)$r.squared
[1] 0.868863
The model using all the variables (m4), since it has the highest R^2
b. Adjusted R^2
Code
summary(m1)$adj.r.squared
[1] 0.8057546
Code
summary(m2)$adj.r.squared
[1] 0.8450003
Code
summary(m3)$adj.r.squared
[1] 0.8636912
Code
summary(m4)$adj.r.squared
[1] 0.8629022
The model using all the variables except Beds (m3), since it has the highest adjusted R^2
c. PRESS
Used the code from this discussion on Stack Exchange: https://stats.stackexchange.com/questions/248603/how-can-one-compute-the-press-diagnostic
The model using all the variables except Beds (m3), since it has the least error
d. AIC
Code
AIC(m1)
[1] 820.1439
Code
AIC(m2)
[1] 800.1262
Code
AIC(m3)
[1] 789.1366
Code
AIC(m4)
[1] 790.6225
The model using all the variables except Beds (m3), since it has the least AIC, meaning it’s a better fit
d. BIC
Code
BIC(m1)
[1] 827.7417
Code
BIC(m2)
[1] 810.2566
Code
BIC(m3)
[1] 801.7996
Code
BIC(m4)
[1] 805.8181
The model using all the variables except Beds (m3), since it has the least BIC, meaning it’s a better fit
E
I would prefer the model using all the variables except Beds (m3) because the other criterion estimate the fit better than R^2 (we know that using R^2, the value increases with the number of variables even though they are not necessarily good predictors).
Question 2
A
Code
data("trees")model <-lm(Volume ~ Girth + Height, data = trees)summary(model)
Call:
lm(formula = Volume ~ Girth + Height, data = trees)
Residuals:
Min 1Q Median 3Q Max
-6.4065 -2.6493 -0.2876 2.2003 8.4847
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -57.9877 8.6382 -6.713 2.75e-07 ***
Girth 4.7082 0.2643 17.816 < 2e-16 ***
Height 0.3393 0.1302 2.607 0.0145 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.882 on 28 degrees of freedom
Multiple R-squared: 0.948, Adjusted R-squared: 0.9442
F-statistic: 255 on 2 and 28 DF, p-value: < 2.2e-16
B
Code
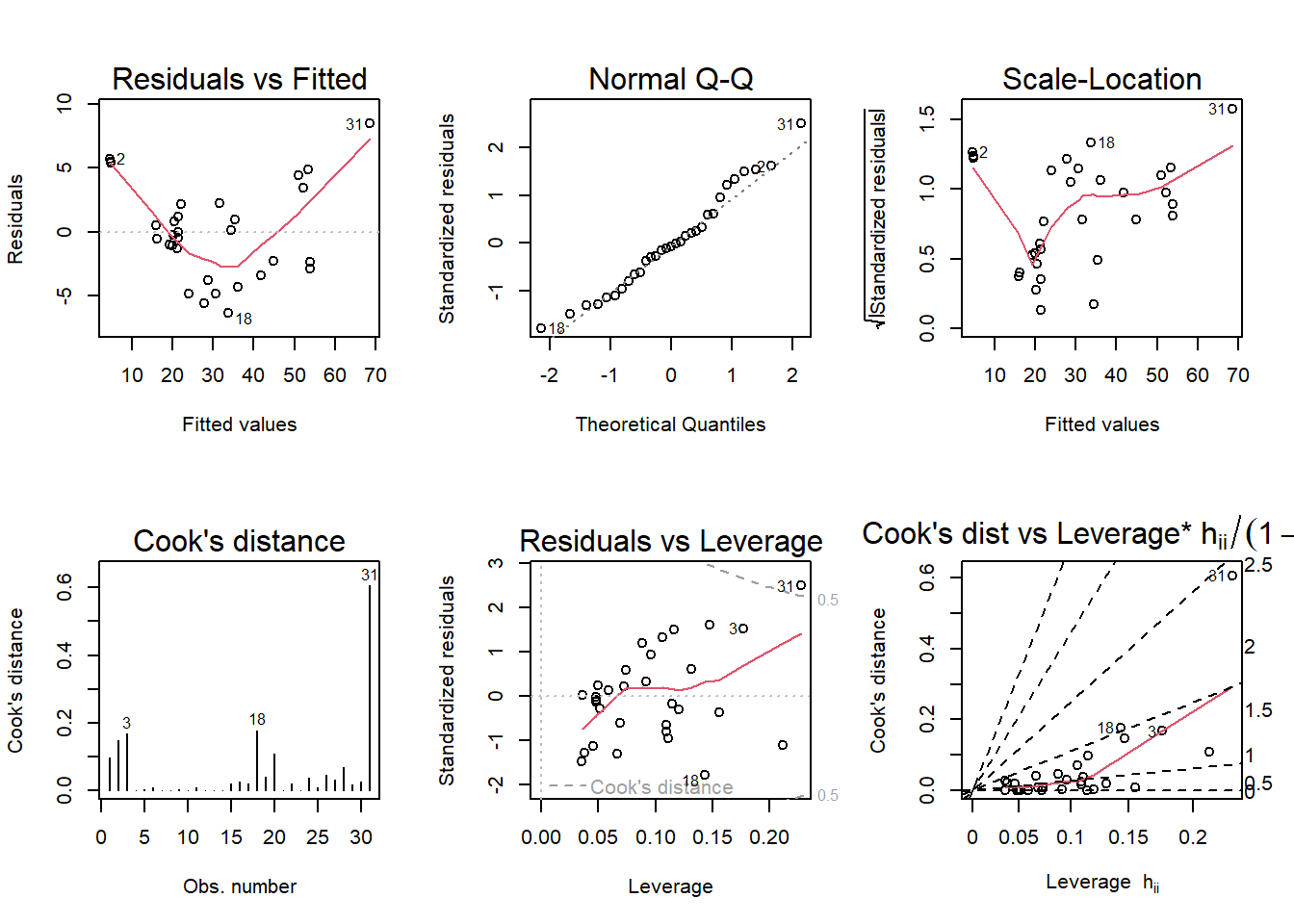
par(mfrow =c(2, 3)); plot(model, which =1:6)
Residuals vs Fitted: We can see that it’s not a horizontal line (has distinct U-shaped pattern) which is a good indication for a non-linear relationship. So we can say that the ‘Linearity’ assumption is violated.
Normal Q-Q: Most of the residuals seem to be following the straight dashed line, which means that the data is normally distributed.
Scale-Location: A horizontal line with equally spread points is a good indication of homoscedasticity but this is not the case with our data, so we can say that the ‘Homoscedasticity’ assumption is violated.
Residuals vs Leverage: For it to have a linear relationship (between the predictors and the outcome variables), the red line must be approximately horizontal to zero. Also, the observations 31, 3 and 18 are outside of the dotted line which means they influence the results of the regression (outliers).
Question 3
A
Code
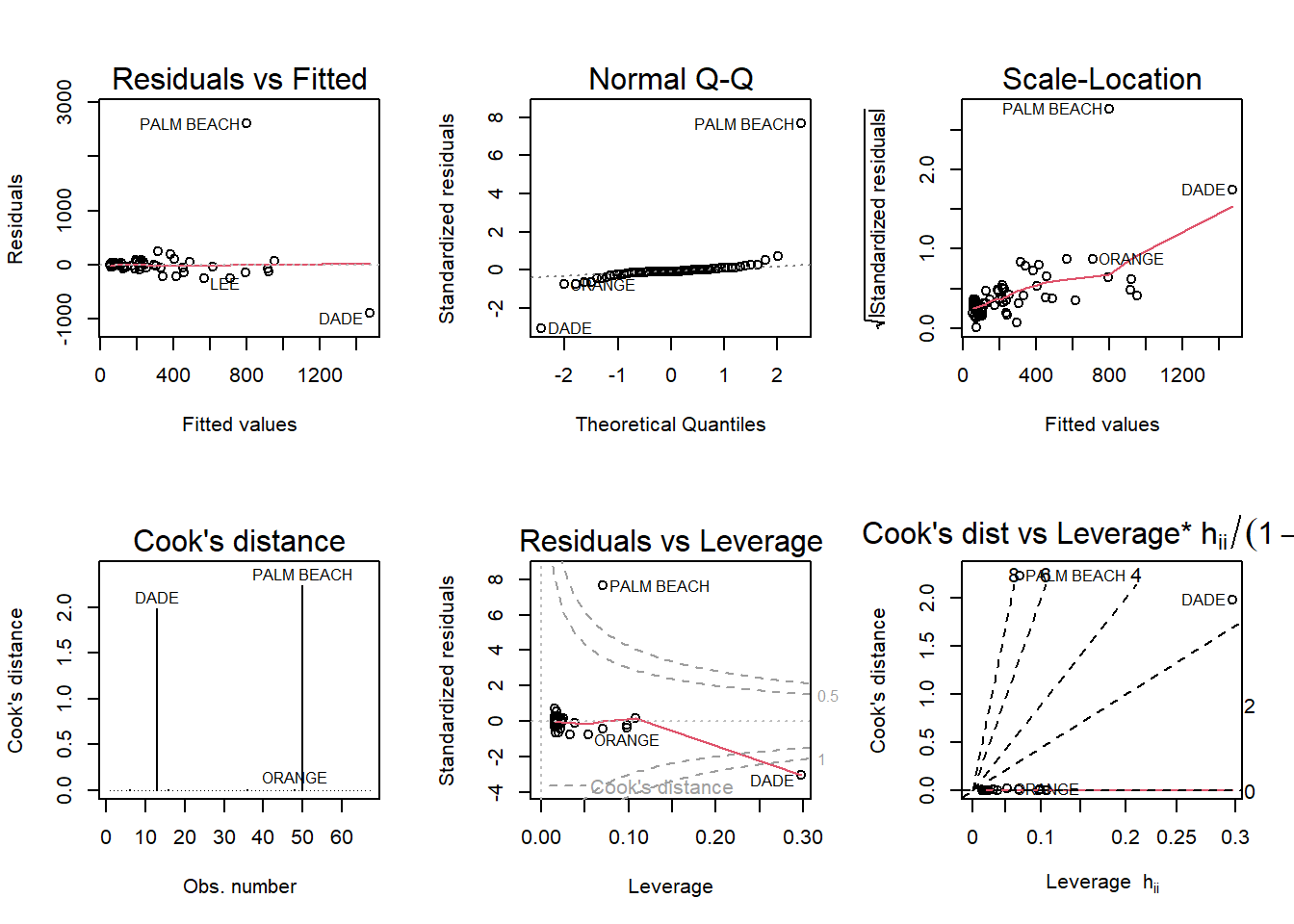
data(florida)model <-lm(Buchanan ~ Bush, data = florida)par(mfrow =c(2, 3)); plot(model, which =1:6)
Yes, Palm Beach County is outside the dotted line in all the plots so I think it is an outlier.
B
Code
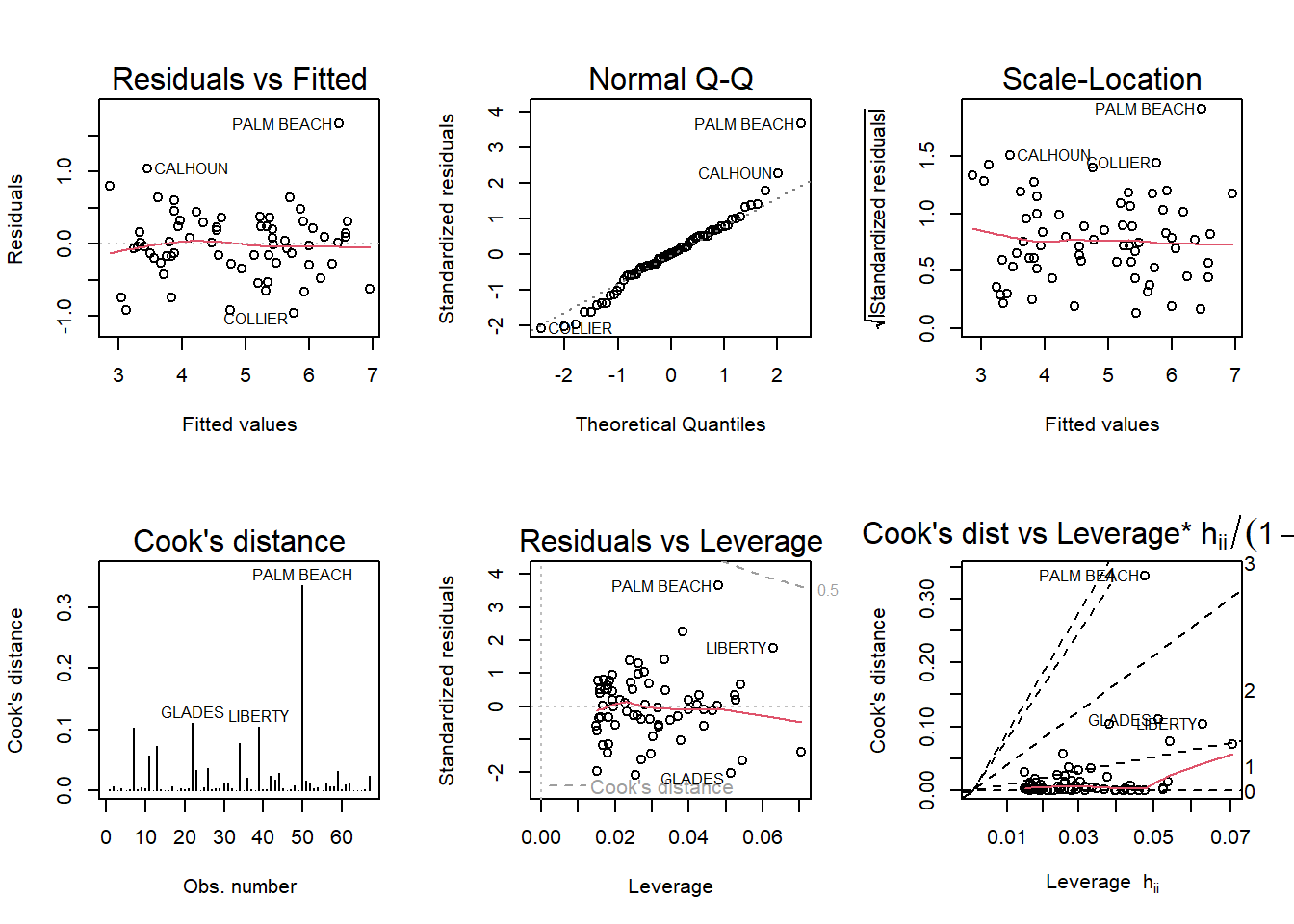
model <-lm(log(Buchanan) ~log(Bush), data = florida)par(mfrow =c(2, 3)); plot(model, which =1:6)
No, Palm Beach County is still an outlier but the Scale-Location and the Residuals vs Leverage plots look better (horizontal line) than in the earlier model.
Source Code
---title: "Homework 5 - Prahitha Movva"author: "Prahitha Movva"description: "The fifth homework"date: "12/08/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - hw5 - model selection - regression - transformation---```{r}library(tidyverse)library(alr4)library(smss)knitr::opts_chunk$set(echo=TRUE, warning=FALSE)```## Question 1### AWith backward elimination, the variable 'Beds' would be deleted first as it has the largest p-value (0.487) and is therefore the weakest indicator of house price.### BWith forward selection, the variable 'Size' would be added first as it has the least p-value (0) and is therefore the strongest indicator of house price.### CBeds has a substantial correlation with not only Price but also Size (which is a statistically significant predictor of house price). This suggests that the variables Beds and Size maybe multicollinear owing to the large p-value for the variables Beds.### D```{r}data(house.selling.price.2)m1 <-lm(P ~ S, data = house.selling.price.2)m2 <-lm(P ~ S + New, data = house.selling.price.2)m3 <-lm(P ~ . -Be, data = house.selling.price.2)m4 <-lm(P ~ ., data = house.selling.price.2)```#### a. R^2```{r}summary(m1)$r.squaredsummary(m2)$r.squaredsummary(m3)$r.squaredsummary(m4)$r.squared```The model using all the variables (m4), since it has the highest R^2#### b. Adjusted R^2```{r}summary(m1)$adj.r.squaredsummary(m2)$adj.r.squaredsummary(m3)$adj.r.squaredsummary(m4)$adj.r.squared```The model using all the variables except Beds (m3), since it has the highest adjusted R^2#### c. PRESSUsed the code from this discussion on Stack Exchange: https://stats.stackexchange.com/questions/248603/how-can-one-compute-the-press-diagnostic```{r}PRESS <-function(linear.model) { pr <-residuals(linear.model)/(1-lm.influence(linear.model)$hat)sum(pr^2)}PRESS(m1)PRESS(m2)PRESS(m3)PRESS(m4)```The model using all the variables except Beds (m3), since it has the least error#### d. AIC```{r}AIC(m1)AIC(m2)AIC(m3)AIC(m4)```The model using all the variables except Beds (m3), since it has the least AIC, meaning it's a better fit#### d. BIC```{r}BIC(m1)BIC(m2)BIC(m3)BIC(m4)```The model using all the variables except Beds (m3), since it has the least BIC, meaning it's a better fit### EI would prefer the model using all the variables except Beds (m3) because the other criterion estimate the fit better than R^2 (we know that using R^2, the value increases with the number of variables even though they are not necessarily good predictors).## Question 2### A```{r}data("trees")model <-lm(Volume ~ Girth + Height, data = trees)summary(model)```### B```{r}par(mfrow =c(2, 3)); plot(model, which =1:6)```Residuals vs Fitted: We can see that it's not a horizontal line (has distinct U-shaped pattern) which is a good indication for a non-linear relationship. So we can say that the 'Linearity' assumption is violated.Normal Q-Q: Most of the residuals seem to be following the straight dashed line, which means that the data is normally distributed.Scale-Location: A horizontal line with equally spread points is a good indication of homoscedasticity but this is not the case with our data, so we can say that the 'Homoscedasticity' assumption is violated.Residuals vs Leverage: For it to have a linear relationship (between the predictors and the outcome variables), the red line must be approximately horizontal to zero. Also, the observations 31, 3 and 18 are outside of the dotted line which means they influence the results of the regression (outliers).## Question 3## A```{r}data(florida)model <-lm(Buchanan ~ Bush, data = florida)par(mfrow =c(2, 3)); plot(model, which =1:6)```Yes, Palm Beach County is outside the dotted line in all the plots so I think it is an outlier.## B```{r}model <-lm(log(Buchanan) ~log(Bush), data = florida)par(mfrow =c(2, 3)); plot(model, which =1:6)```No, Palm Beach County is still an outlier but the Scale-Location and the Residuals vs Leverage plots look better (horizontal line) than in the earlier model.