Code
library(tidyverse)
library(smss)
library(alr4)
library(stargazer)Error in library(stargazer): there is no package called 'stargazer'Code
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(smss)
library(alr4)
library(stargazer)Error in library(stargazer): there is no package called 'stargazer'knitr::opts_chunk$set(echo = TRUE)Based off the equation given in the question, the predicted value is $107,296 for a home with the parameters given.
val1 <- -10536 + (53.8*1240) + (2.84*18000)
val1[1] 107296The residual is 37,704.
145000 - 107296[1] 37704It’s hard to analyze a single residual, but it seems like the number is off by more than it should. There isn’t enough data to make a concrete conclusion.
The house size is predicted to increase by $53.80 for each square foot increase of the house because of the 53.8 variable.
I’m going to use the equation from before, but increase the square foot by 1.
val <- -10536 + (53.8*1241) + (2.84*18000)
val[1] 107349.8val-val1[1] 53.8Lot size would need to increase by 53.8.
data("salary")It appears the mean salary for men is about $3,000 more than the mean salary of women, indicating sex does play a factor in salary. The mean salary is not the same for both men and women. Even with a boxplot, it’s easy to observe the difference in salary across both genders.
t.test(salary$salary ~ salary$sex, mu = 0, alternative = "two.sided")
Welch Two Sample t-test
data: salary$salary by salary$sex
t = 1.7744, df = 21.591, p-value = 0.09009
alternative hypothesis: true difference in means between group Male and group Female is not equal to 0
95 percent confidence interval:
-567.8539 7247.1471
sample estimates:
mean in group Male mean in group Female
24696.79 21357.14 salary %>%
ggplot(aes(x = sex, y = salary))+
geom_boxplot()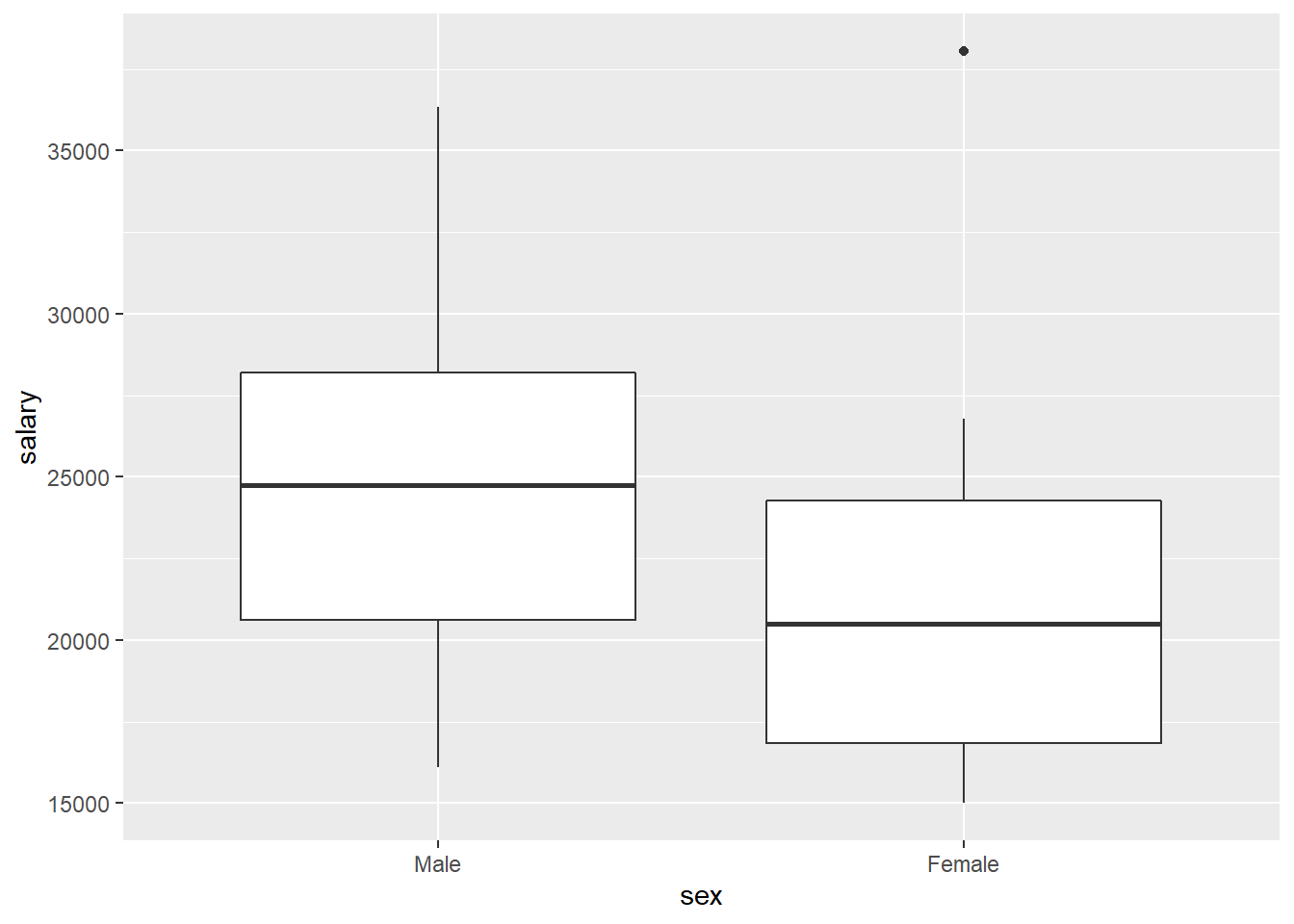
In the summary, since there is no code next to the sexFemale variable, we can see that it has not met a significant threshold. This shows we did obtain a 95% confidence interval.
fit <- summary(lm(salary ~ ., data = salary))
fit
Call:
lm(formula = salary ~ ., data = salary)
Residuals:
Min 1Q Median 3Q Max
-4045.2 -1094.7 -361.5 813.2 9193.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15746.05 800.18 19.678 < 2e-16 ***
degreePhD 1388.61 1018.75 1.363 0.180
rankAssoc 5292.36 1145.40 4.621 3.22e-05 ***
rankProf 11118.76 1351.77 8.225 1.62e-10 ***
sexFemale 1166.37 925.57 1.260 0.214
year 476.31 94.91 5.018 8.65e-06 ***
ysdeg -124.57 77.49 -1.608 0.115
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2398 on 45 degrees of freedom
Multiple R-squared: 0.855, Adjusted R-squared: 0.8357
F-statistic: 44.24 on 6 and 45 DF, p-value: < 2.2e-16Degree does not appear to be significant when it comes to the outcome of salary. The R squared is actually a negative number so it really is not an appropriate measure of salary.
m1 <- summary(lm(salary ~ degree, data = salary))
m1
Call:
lm(formula = salary ~ degree, data = salary)
Residuals:
Min 1Q Median 3Q Max
-8500.4 -5253.6 -640.2 3758.1 14544.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 23500.4 1022.4 22.985 <2e-16 ***
degreePhD 858.9 1737.8 0.494 0.623
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5962 on 50 degrees of freedom
Multiple R-squared: 0.004862, Adjusted R-squared: -0.01504
F-statistic: 0.2443 on 1 and 50 DF, p-value: 0.6233Rank actually does have significance in the outcome of salary. Both Assoc and Prof have significant p values and the R squared is about 0.74 which indicates some level of significance. In this model, I can assume that if you are a professor, you can observe an increase in $11,890.
m2 <- summary(lm(salary ~ rank, data = salary))
m2
Call:
lm(formula = salary ~ rank, data = salary)
Residuals:
Min 1Q Median 3Q Max
-5209.0 -1819.2 -417.8 1586.6 8386.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17768.7 705.5 25.19 < 2e-16 ***
rankAssoc 5407.3 1066.6 5.07 6.09e-06 ***
rankProf 11890.3 972.4 12.23 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2993 on 49 degrees of freedom
Multiple R-squared: 0.7542, Adjusted R-squared: 0.7442
F-statistic: 75.17 on 2 and 49 DF, p-value: 1.174e-15According to this model, sex is not relevant when it comes to the outcome variable, containing a low R squared and an insignificant p value.
m3 <- summary(lm(salary ~ sex, data = salary))
m3
Call:
lm(formula = salary ~ sex, data = salary)
Residuals:
Min 1Q Median 3Q Max
-8602.8 -4296.6 -100.8 3513.1 16687.9
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24697 938 26.330 <2e-16 ***
sexFemale -3340 1808 -1.847 0.0706 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5782 on 50 degrees of freedom
Multiple R-squared: 0.0639, Adjusted R-squared: 0.04518
F-statistic: 3.413 on 1 and 50 DF, p-value: 0.0706The years someone has been in their position does have a significant impact on their salary, which makes sense because, usually, the longer someone is in a job, the more opportunities they will have for a promotion.
m4 <- summary(lm(salary ~ year, data = salary))
m4
Call:
lm(formula = salary ~ year, data = salary)
Residuals:
Min 1Q Median 3Q Max
-11035.9 -3172.4 -561.7 3185.8 13856.5
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 18166.1 1003.7 18.100 < 2e-16 ***
year 752.8 108.4 6.944 7.34e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4264 on 50 degrees of freedom
Multiple R-squared: 0.4909, Adjusted R-squared: 0.4808
F-statistic: 48.22 on 1 and 50 DF, p-value: 7.341e-09I think years since highest degree earned falls under the same logic as the years column since, presummably, many of the years spent in the job were years also in the ysdeg column. I expect that with every 1 year increase in years after highest degree, there will be a $390 increase in salary.
m5 <- summary(lm(salary ~ ysdeg, data = salary))
m5
Call:
lm(formula = salary ~ ysdeg, data = salary)
Residuals:
Min 1Q Median 3Q Max
-9703.5 -2319.5 -437.1 2631.8 11167.3
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17502.26 1149.70 15.223 < 2e-16 ***
ysdeg 390.65 60.41 6.466 4.1e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4410 on 50 degrees of freedom
Multiple R-squared: 0.4554, Adjusted R-squared: 0.4445
F-statistic: 41.82 on 1 and 50 DF, p-value: 4.102e-08I may want to use the par function but I cannot find the proper way to type it out. Will revisit.
#rank <- relevel(rank)
relevel_mod <- lm(salary ~ rank, data = salary)
summary(relevel_mod)
Call:
lm(formula = salary ~ rank, data = salary)
Residuals:
Min 1Q Median 3Q Max
-5209.0 -1819.2 -417.8 1586.6 8386.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17768.7 705.5 25.19 < 2e-16 ***
rankAssoc 5407.3 1066.6 5.07 6.09e-06 ***
rankProf 11890.3 972.4 12.23 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2993 on 49 degrees of freedom
Multiple R-squared: 0.7542, Adjusted R-squared: 0.7442
F-statistic: 75.17 on 2 and 49 DF, p-value: 1.174e-15If you compare this model with models that contain the rank variable, you’ll see that rank actually does play a significant role in salary. Rank always has a p value worth noting as seen with the significance codes. The adjusted R squared is also much lower in this model than any model containing rank as an explanatory variable.
summary(lm(salary ~ degree + sex + year + ysdeg, data = salary))
Call:
lm(formula = salary ~ degree + sex + year + ysdeg, data = salary)
Residuals:
Min 1Q Median 3Q Max
-8146.9 -2186.9 -491.5 2279.1 11186.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17183.57 1147.94 14.969 < 2e-16 ***
degreePhD -3299.35 1302.52 -2.533 0.014704 *
sexFemale -1286.54 1313.09 -0.980 0.332209
year 351.97 142.48 2.470 0.017185 *
ysdeg 339.40 80.62 4.210 0.000114 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3744 on 47 degrees of freedom
Multiple R-squared: 0.6312, Adjusted R-squared: 0.5998
F-statistic: 20.11 on 4 and 47 DF, p-value: 1.048e-09I’m trying to make a new column for someone hired within the 15 year period of the new Dean. Now the new column should have a 1 if the person was hired with 15 years or less from earning their highest degree and people will have a -1 if its more. The 1 will indicate if they have been hired by the new dean and we may see an increase in salary for those people.
salary <- salary %>%
mutate(hired_by_new_dean = case_when(
ysdeg <= 15 ~ 1,
T ~ -1
))summary(lm(salary ~ ysdeg*hired_by_new_dean, data = salary))
Call:
lm(formula = salary ~ ysdeg * hired_by_new_dean, data = salary)
Residuals:
Min 1Q Median 3Q Max
-8251.2 -2619.1 -317.1 1428.3 10592.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 21206.7 1966.3 10.785 2.01e-14 ***
ysdeg 312.5 106.0 2.947 0.00494 **
hired_by_new_dean -5618.2 1966.3 -2.857 0.00630 **
ysdeg:hired_by_new_dean 286.3 106.0 2.701 0.00954 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4150 on 48 degrees of freedom
Multiple R-squared: 0.5372, Adjusted R-squared: 0.5082
F-statistic: 18.57 on 3 and 48 DF, p-value: 3.909e-08summary(lm(salary ~ ysdeg, data = salary))
Call:
lm(formula = salary ~ ysdeg, data = salary)
Residuals:
Min 1Q Median 3Q Max
-9703.5 -2319.5 -437.1 2631.8 11167.3
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17502.26 1149.70 15.223 < 2e-16 ***
ysdeg 390.65 60.41 6.466 4.1e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4410 on 50 degrees of freedom
Multiple R-squared: 0.4554, Adjusted R-squared: 0.4445
F-statistic: 41.82 on 1 and 50 DF, p-value: 4.102e-08With an interaction between ysdeg and the new column I created to separate people hired by the new dean, I can see the first model is slightly a better fit with an R squared of 0.5 and all significantly low p values. We can conclude that if you were hired by the new dean, you are more likely to have a higher salary. I avoided multicollinearity by putting an interaction symbol for ysdeg and hired_by_new_dean. I’d be worried about ysdeg and hired_by_new interacting with each other to cause multicollinearity.
data("house.selling.price")Both size and whether the house is new or not are statistically significant as per the significance codes related to the p values. The adjusted R squared is also pretty high which indicates this model is a good fit. Going by the significance codes, Size is more important when it comes to the model compared to the New variable.
model <-lm(Price ~ Size + New, data = house.selling.price)
summary(model)
Call:
lm(formula = Price ~ Size + New, data = house.selling.price)
Residuals:
Min 1Q Median 3Q Max
-205102 -34374 -5778 18929 163866
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -40230.867 14696.140 -2.738 0.00737 **
Size 116.132 8.795 13.204 < 2e-16 ***
New 57736.283 18653.041 3.095 0.00257 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 53880 on 97 degrees of freedom
Multiple R-squared: 0.7226, Adjusted R-squared: 0.7169
F-statistic: 126.3 on 2 and 97 DF, p-value: < 2.2e-16According to my prediction model, the mean for both actual price and predicted price are exactly the same, which I find odd because would there not be some variation? I used the predict function on the model then added them together so the data was easier to work with. I suppose I could have created a test set and a training set, but I think that was outside the scope of the homework.
pred <- predict(model)
pred 1 2 3 4 5 6 7 8
197606.63 65681.14 151850.78 199929.26 131295.49 383668.32 117127.44 258478.46
9 10 11 12 13 14 15 16
423134.17 94481.78 101449.67 156031.52 120030.73 144418.36 81707.30 49190.46
17 18 19 20 21 22 23 24
123514.67 82868.62 110740.20 133966.52 54997.04 476109.06 95643.09 133966.52
25 26 27 28 29 30 31 32
283776.27 79384.67 104933.62 164160.73 139773.10 89836.51 192032.31 116546.78
33 34 35 36 37 38 39 40
231187.54 251259.42 378674.66 164160.73 158354.15 88675.20 117708.09 104933.62
41 42 43 44 45 46 47 48
104933.62 131643.89 136289.15 194354.94 77062.04 150224.94 68932.83 143257.04
49 50 51 52 53 54 55 56
59642.30 124675.99 107256.25 73578.09 226871.79 125837.31 120030.73 103772.30
57 58 59 60 61 62 63 64
89836.51 89836.51 180419.15 241968.90 85191.25 116546.78 159515.47 430102.07
65 66 67 68 69 70 71 72
133966.52 259504.76 263704.39 336286.63 136289.15 108417.57 147902.31 136289.15
73 74 75 76 77 78 79 80
195516.26 121192.04 178096.52 295505.56 115385.46 68932.83 27125.45 123514.67
81 82 83 84 85 86 87 88
93320.46 120030.73 188218.85 202154.64 156863.32 182741.78 209452.05 215258.63
89 90 91 92 93 94 95 96
59642.30 102610.99 92159.14 325254.13 82868.62 165322.05 175773.89 82868.62
97 98 99 100
160676.78 118869.41 140934.41 115385.46 new.house.selling.price <- cbind(house.selling.price, pred)new.house.selling.price %>%
group_by(New) %>%
summarize(Price_actual = mean(Price), Price_prediction = mean(pred))# A tibble: 2 × 3
New Price_actual Price_prediction
<int> <dbl> <dbl>
1 0 138567. 138567.
2 1 290964. 290964.variable1 <- data.frame(Size = 3000, New = 1)
predict(model, newdata = variable1) 1
365900.2 variable2 <- data.frame(Size = 3000, New = 0)
predict(model, newdata = variable2) 1
308163.9 The interaction between New and Size actually is more significant than New solely alone. Overall, the model is a pretty good fit since its R squared is 0.73.
mod <- lm(Price ~ Size*New, data = house.selling.price)
summary(mod)
Call:
lm(formula = Price ~ Size * New, data = house.selling.price)
Residuals:
Min 1Q Median 3Q Max
-175748 -28979 -6260 14693 192519
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -22227.808 15521.110 -1.432 0.15536
Size 104.438 9.424 11.082 < 2e-16 ***
New -78527.502 51007.642 -1.540 0.12697
Size:New 61.916 21.686 2.855 0.00527 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 52000 on 96 degrees of freedom
Multiple R-squared: 0.7443, Adjusted R-squared: 0.7363
F-statistic: 93.15 on 3 and 96 DF, p-value: < 2.2e-16New home price = -22228 + 104 + -78527 + 62 Old home price = -22228 + 104
I included the last two numbers in the first equation because those are the interaction terms.
Repeat question
The whether the home is new or not impacts the price of the house in a pretty significant way. About a $60,000 difference in price is not something to dismiss. With the same lot size, a home that is new will fetch significantly more money than the same home, but old.
var3 <- data.frame(Size = 1500, New = 0)
var4 <- data.frame(Size = 1500, New = 1)House is new.
predict(model, newdata = var4) 1
191702.8 House is old.
predict(model, newdata = var3) 1
133966.5 I prefer the model with interaction between size and new because its adjusted R squared is slightly higher than that of the model without interaction. Be it only 0.02 points, it still shows a better fit compared to the other model. The p value for the interaction between new and old is also labeled as significant in the interaction model. They are so similar, but again I would choose the interaction model because the adjusted R squared is slightly higher.