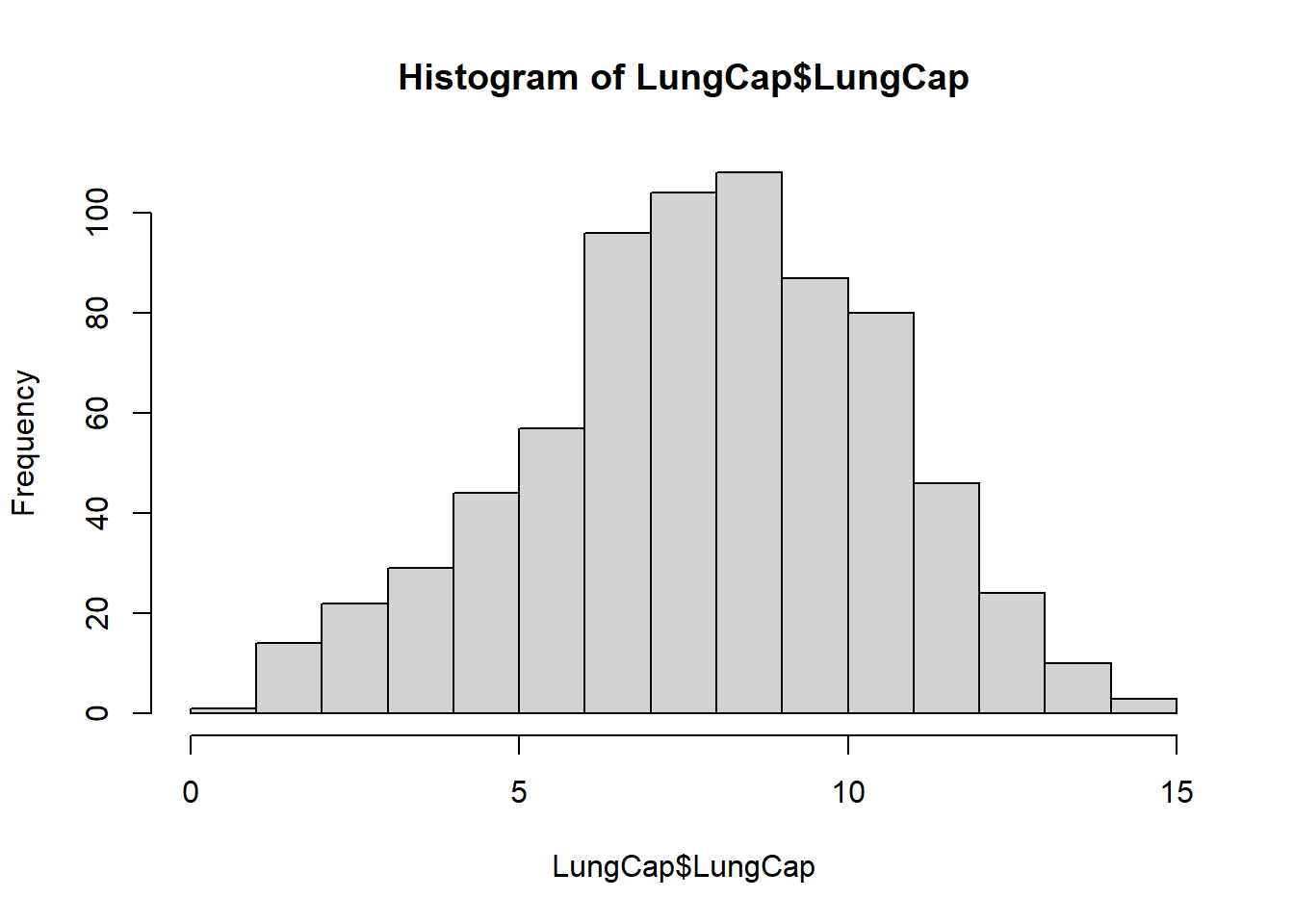
# A tibble: 6 × 6
LungCap Age Height Smoke Gender Caesarean
<dbl> <dbl> <dbl> <chr> <chr> <chr>
1 6.48 6 62.1 no male no
2 10.1 18 74.7 yes female no
3 9.55 16 69.7 no female yes
4 11.1 14 71 no male no
5 4.8 5 56.9 no male no
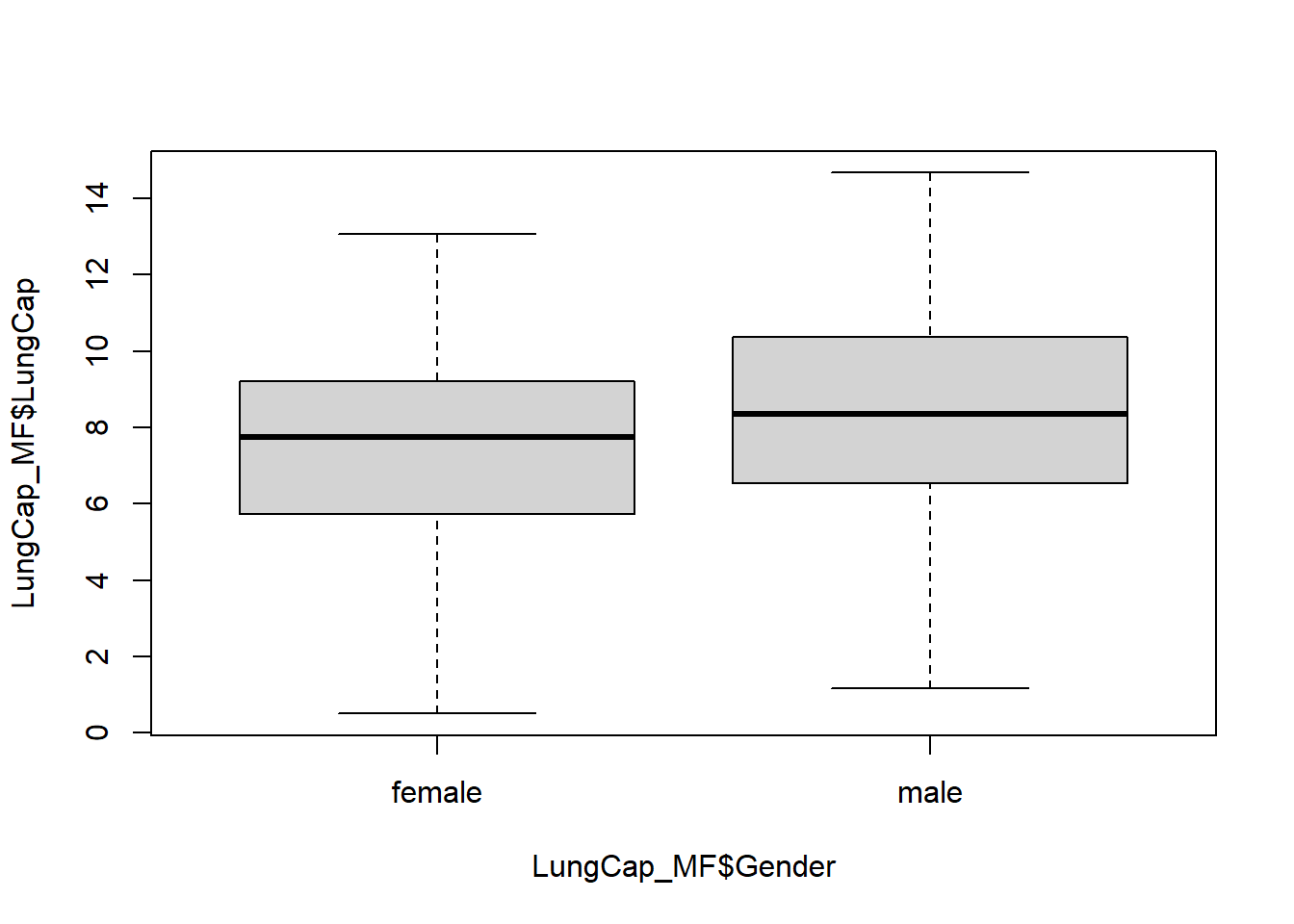
6 6.22 11 58.7 no female no
#I wanted to change the axis labels to "Gender" (x) and "Lung Capacity" (y), but after an hour and a half of trying to no avail, I had to call it for my own sanity.
Error in select(., LungCap, Smoke): object 'LungCapData' not found
head(LungCap_smoke)
Error in head(LungCap_smoke): object 'LungCap_smoke' not found
summarise(LungCap_smoke, mean(LungCap))
Error in summarise(LungCap_smoke, mean(LungCap)): object 'LungCap_smoke' not found
#The mean lung capacities for non-smokers and smokers is 7.77 and 8.65 respectively. Does this make sense? No. One would expect that the mean lung capacity for non-smokers would be higher, but that is not the case here. Let's do some digging to see what the range of values for smokers' and non-smokers' lung capacity. I also want to look at how many people voted "yes" or "no"; it could be that fewer people (with higher lung capacity) voted "yes," contributing to the higher mean.
LCS2 <- LungCap_smoke %>%filter(Smoke =="yes")
Error in filter(., Smoke == "yes"): object 'LungCap_smoke' not found
range(LCS2$LungCap)
Error in eval(expr, envir, enclos): object 'LCS2' not found
LCS2 <- LungCap_smoke %>%filter(Smoke =="no")
Error in filter(., Smoke == "no"): object 'LungCap_smoke' not found
range(LCS2$LungCap)
Error in eval(expr, envir, enclos): object 'LCS2' not found
##Lung capacity for smokers ranges from 3.850 to 13.325, while the range for non-smokers is 0.507 to 14.675. Right off the bat, smokers have a higher minimum value, which prevents the mean from being dragged down during calculation. Non-smokers' minimum value is 0.507, an outlier which does seem to have an effect on this category's mean.
LungCap_smoke %>%count(Smoke)
Error in count(., Smoke): object 'LungCap_smoke' not found
#Out of 725 respondents only 77 voted yes and 648 voted no, so I was right with my guess as to what caused the difference in mean lung capacity between smokers and non-smokers.
1d. Examine the relationship between Smoking and Lung Capacity within age groups: “less than or equal to 13”, “14 to 15”, “16 to 17”, and “greater than or equal to 18”.
#To start, I'm going to calculate the range and mean of each of the above age groups, as well as a tally of how many are and aren't smokers.#a) Less than or equal to 13LC_Age13 <- LungCap %>%select(LungCap, Age, Smoke) %>%filter(Age <=13)range(LC_Age13$LungCap)
[1] 0.507 12.050
#The range of lung capacity values for children under the age of 13 is 0.507 to 12.050. The mean is 6.412.
summarise(LC_Age13, mean(LungCap))
# A tibble: 1 × 1
`mean(LungCap)`
<dbl>
1 6.41
LC_Age13 %>%count(Smoke)
# A tibble: 2 × 2
Smoke n
<chr> <int>
1 no 401
2 yes 27
#401 individuals 13 and under responded that they don't smoke, while 27 said they do. Compared to the initial calculations for the whole survey, the mean value is slightly lower, which is likely indicative of the fact that children have smaller lungs than adults and therefore have less lung capacity. Something important to note, however, is that this age group accounts for 428 of the total 725 responses (about 59%).
Warning in Age == 14:15: longer object length is not a multiple of shorter
object length
range(LC_Age145$LungCap)
[1] 5.625 12.900
#The minimum and maximum lung capacity values for individuals aged 14-15 are 5.625 and 12.900. The mean is 8.842.
summarise(LC_Age145, mean(LungCap))
# A tibble: 1 × 1
`mean(LungCap)`
<dbl>
1 8.84
LC_Age145 %>%count(Smoke)
# A tibble: 2 × 2
Smoke n
<chr> <int>
1 no 44
2 yes 8
#Out of the 52 respondents in this age group, 44 stated that they don't smoke and 8 said that they do. The 14-15y/o age group is MUCH smaller than the "13 and under" one (it makes up only 12% of total responses). The percentage of smokers to non-smokers in each of the above age groups,is 7% and 18% respectively. If you were to take these percentages at face value without taking sample size into account, it would look as if the 14-15 y/o age group makes up 18% of the total 725 responses. In reality, this sample accounts for 6% of the total, making its impact relatively low.
Warning in Age == 16:17: longer object length is not a multiple of shorter
object length
range(LC_Age167$LungCap)
[1] 5.675 13.375
#The minimum and maximum lung capacity values for individuals ages 16 to 17 are 5.675 and 13.375. The mean is 10.058.
summarise(LC_Age167, mean(LungCap))
# A tibble: 1 × 1
`mean(LungCap)`
<dbl>
1 10.1
LC_Age167 %>%count(Smoke)
# A tibble: 2 × 2
Smoke n
<chr> <int>
1 no 40
2 yes 8
#This sample is similar in size to the previous (14-15 year olds) with only 48 responses, and smokers make up 20% of the responses. Now lets discuss the other figures. #The mean lung capacity for 16-17 year olds is 10.058, 1.216 units higher than the previous age group, and 3.646 units higher than the "13 and under" age group. As of this point in my calculations, the only relationship seems to be between age and lung capacity rather than smoking and lung capacity; this is due to the facts that: 1) not that many people ages 0-17 smoke, and 2) the sample sizes for the 14-17 age group is 100 compared to the 428 responses in the "13 and under" group.
#The minimum and maximum range values for the 18+ age group are 7.750 and 14.675. The mean is 10.965.
summarise(LC_Age18p, mean(LungCap))
# A tibble: 1 × 1
`mean(LungCap)`
<dbl>
1 11.0
LC_Age18p %>%count(Smoke)
# A tibble: 2 × 2
Smoke n
<chr> <int>
1 no 65
2 yes 15
#Ok so what we've learned here is that this survey was HEAVILY focused on kids 13 and younger; although the sample for this age group is larger than the previous 2, it's still only 80 out of 725 responses (about 11% of total respondents). The mean lung capacity for this group is the highest of all of them at 10.965, but this still doesn't seem to show a relationship between smoking and lung capacity. Rather, at least to me, it shows a relationship between age and lung capacity (i.e. stage of lung development and lung capacity).
##1e. Compare the lung capacities for smokers and non-smokers within each age group. Is your answer different from the one in part d. What could possibly be going on here?
#I will place a comparison of all values produced by the following calculations at the bottom. (I will go through the smoker and non-smoker calculations first)LCu13 <- LC_Age13 %>%filter(Smoke =="yes")range(LCu13$LungCap)
#Comparison!! # 13 and under smokers: range = 3.850 to 10.275, mean = 7.202# 13 and under non-smokers: range = 0.507 and 12.050, mean = 6.359 # 14-15 smokers: range = 6.225 and 11.025, mean = 8.359# 14-15 non-smokers: range = 5.625 and 12.900, mean = 8.930 # 16-17 smokers: range = 7.550 and 11.775, mean = 9.063# 16-17 non-smokers: range = 5.675 and 13.375, mean = 10.257 # 18+ smokers: range = 8.200 and 13.325,mean = 10.513 # 18+ non-smokers: range = 7.750 and 14.675, mean = 10.965
#The answers I got for smokers vs. non-smokers are obviously different, but I wouldn't say they necessarily convey something different to what I interpreted from 1d. I don't see a relationship between smoking and lung capacity, and I certainly don't see a massive difference in the values comparing the lung capacity of smokers and non-smokers.
1f. Calculate the correlation and covariance between Lung Capacity and Age. (use the cov() and cor() functions in R). Interpret your results.
cov(LungCap$LungCap, LungCap$Age)
[1] 8.738289
cor(LungCap$LungCap, LungCap$Age)
[1] 0.8196749
#Covariance between lung capacity and age: 8.738. #Correlation between lung capacity and age: 0.820 #I'm not totally confident in my understanding of covariance yet, but from what I know, it's the positive or negative relationship between two variables and the further the value is from 0, the stronger the relationship is. And the covariance between lung capacity and age is 8.738. Correlation gets stronger the closer the value gets to 1 or -1; the correlation between lung capacity and age for 'LungCap' dataset is 0.820, a figure relatively close to 1, so I would say there is a moderate to strong correlation between the two variables in question here.
#Question 2
###Let X=number of prior convictions for prisoners at a state prison at which there are 810 inmates.
2a. What is the probability that a randomly selected inmate has fewer than 2 prior convictions?
#To start I just wanted to present a visualization of the frequency of each categorical variable. # 0 prior convictions = 128 # 1 prior conviction = 434 # 2 prior convictions = 160 # 3 prior convictions = 64 # 4 prior convictions = 24
prop.table(table(conrange))[0:2]
conrange
0 1
0.1580247 0.5358025
#By combining the probability values for 0 and 1, we can see that the probability of a randomly selected inmate having fewer than 2 prior convictions is 0.694.
2b. What is the probability that a randomly selected inmate has 2 or fewer prior convictions?
prop.table(table(conrange))[0:3]
conrange
0 1 2
0.1580247 0.5358025 0.1975309
#By using the same math above, the probability that a randomly selected inmate has 2 or fewer prior convictions is 0.891.
2c. What is the probability that a randomly selected inmate has more than 2 prior convictions?
prop.table(table(conrange))[4:5]
conrange
3 4
0.07901235 0.02962963
#The probability that a randomly selected inmate has more than 2 prior convictions is 0.108.
2d. What is the expected value for the number of prior convictions?