lattice theme set by effectsTheme()
See ?effectsTheme for details.
library(smss)
Warning: package 'smss' was built under R version 4.2.2
library(dplyr)
Attaching package: 'dplyr'
The following object is masked from 'package:car':
recode
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(stats)library(ggplot2)
Question 1
United Nations (Data file: UN11 in alr4) The data in the file UN11 contains several variables, including ppgdp, the gross national product per person in U.S. dollars, and fertility, the birth rate per 1000 females, both from the year 2009. The data are for 199 localities, mostly UN member countries, but also other areas such as Hong Kong that are not independent countries. The data were collected from the United Nations (2011). We will study the dependence of fertility on ppgdp.
1.1. Identify the predictor and the response.
Predictor: ppgdp
Response: fertility
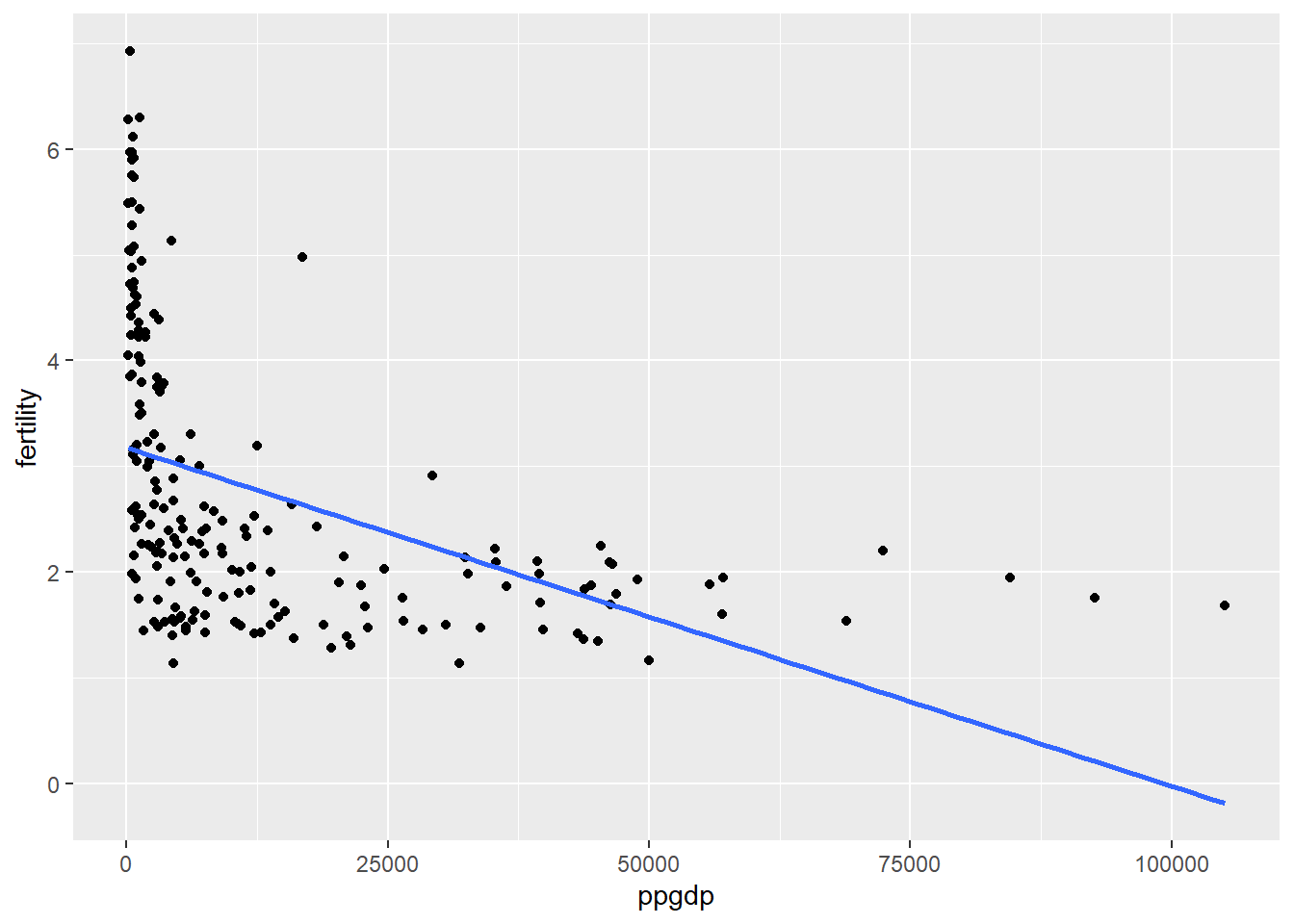
1.2 Draw the scatterplot of fertility on the vertical axis versus ppgdp on the horizontal axis and summarize the information in this graph. Does a straight-line mean function seem to be plausible for a summary of this graph?
A straight-line mean function would not be plausible here as the data is not presented linearly
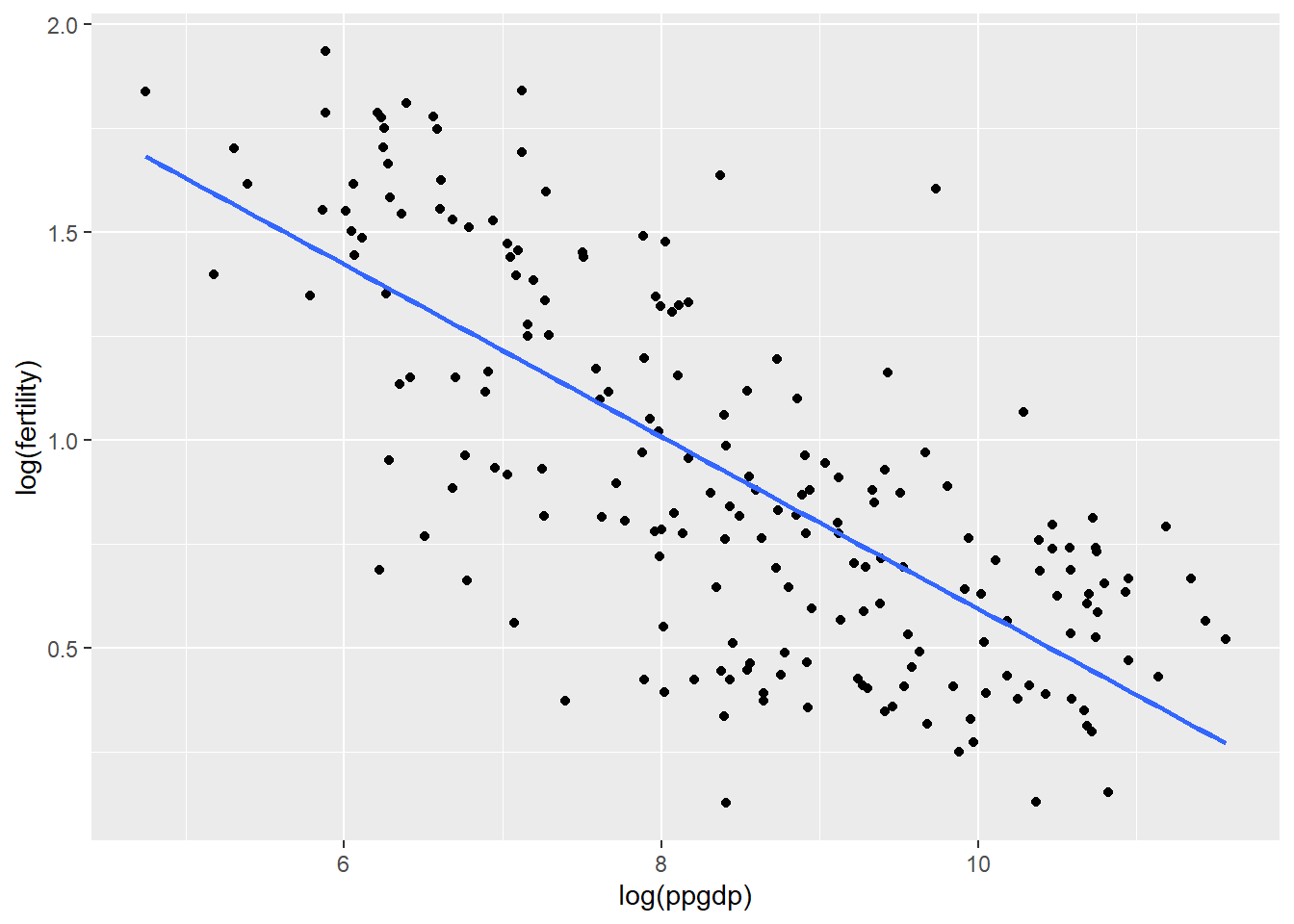
1.3 Draw the scatterplot of log(fertility) versus log(ppgdp) using natural logarithms. Does the simple linear regression model seem plausible for a summary of this graph? If you use a different base of logarithms, the shape of the graph won’t change, but the values on the axes will change
A simple linear regression model would be much more appropriate
Question 2
Annual income, in dollars, is an explanatory variable in a regression analysis. For a British version of the report on the analysis, all responses are converted to British pounds sterling (1 pound equals about 1.33 dollars, as of 2016).
2.1 How, if at all, does the slope of the prediction equation change?
To account for the conversion rate from USD to GBP, the response and the slope must be divided by 1.33
2.2 How, if at all, does the correlation change?
Correlation wouldn’t change in this scenario since it isn’t affected by units of measurement
Question 3
Water runoff in the Sierras (Data file: water in alr4) Can Southern California’s water supply in future years be predicted from past data? One factor affecting water availability is stream runoff. If runoff could be predicted, engineers, planners, and policy makers could do their jobs more efficiently. The data file contains 43 years’ worth of precipitation measurements taken at six sites in the Sierra Nevada mountains (labeled APMAM, APSAB, APSLAKE, OPBPC, OPRC, and OPSLAKE) and stream runoff volume at a site near Bishop, California, labeled BSAAM. Draw the scatterplot matrix for these data and summarize the information available from these plots. (Hint: Use the pairs() function.)
data(water)pairs(water)
The following variables appear to be correlated with each other: OPBPC, OPRC, OPSLAKE. All parts of the matrix with 2 of these variables exhibit a dependence among themselves that is not present between OPBPC, OPRC, and OPSLAKE and APMAM, APSAB, APSLAKE. That being said, though, there also appears to be a correlation among APMAM, APSAB, APSLAKE.
BSAAM is more closely related to OPBPC, OPRC, and OPSLAKE than to APMAM, APSAB, APSLAKE.
Question 4
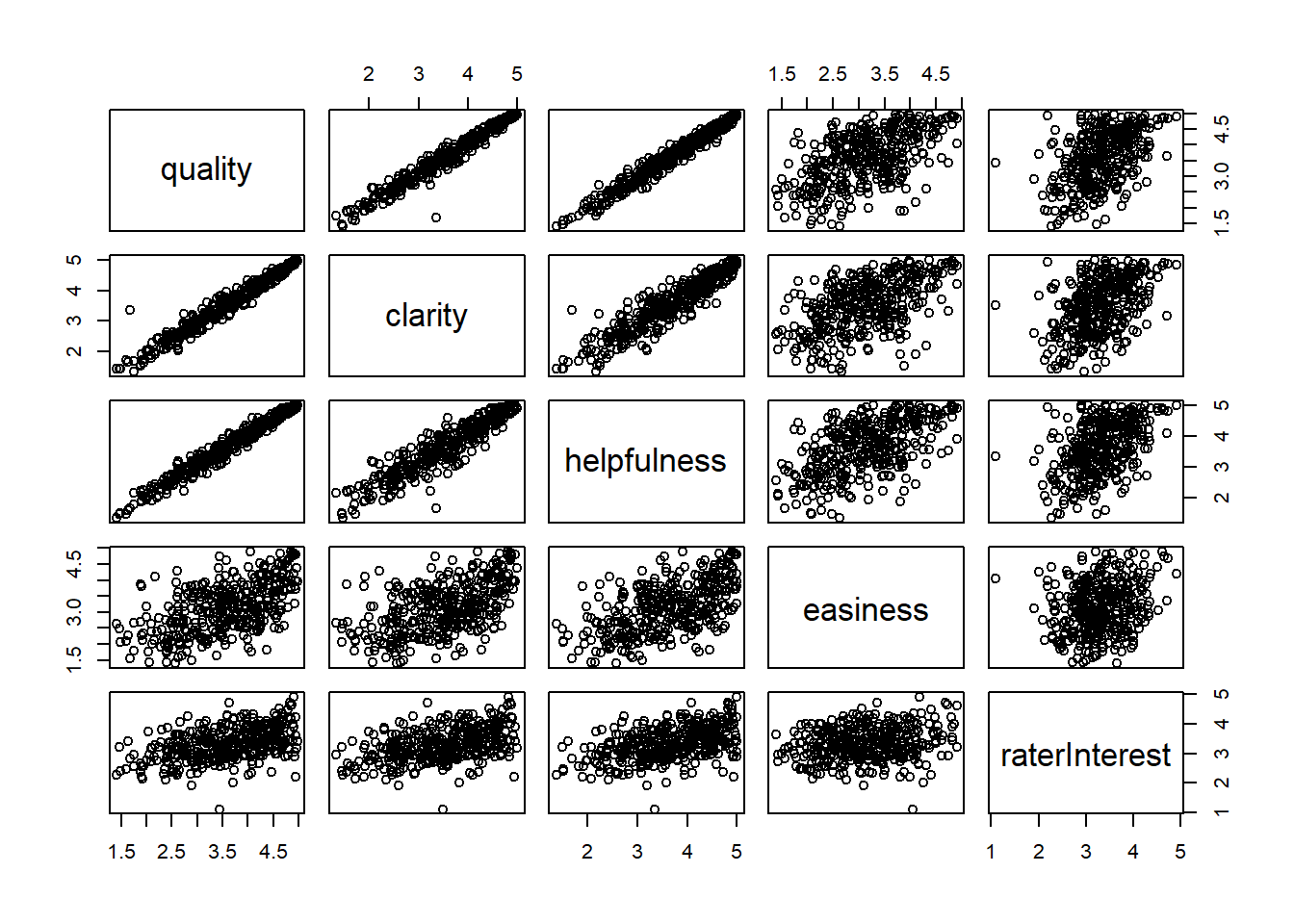
Professor ratings (Data file: Rateprof in alr4) In the website and online forum RateMyProfessors.com, students rate and comment on their instructors. Launched in 1999, the site includes millions of ratings on thousands of instructors. The data file includes the summaries of the ratings of 364 instructors at a large campus in the Midwest (Bleske-Rechek and Fritsch, 2011). Each instructor included in the data had at least 10 ratings over a several year period. Students provided ratings of 1–5 on quality, helpfulness, clarity, easiness of instructor’s courses, and raterInterest in the subject matter covered in the instructor’s courses. The data file provides the averages of these five ratings. Create a scatterplot matrix of these five variables. Provide a brief description of the relationships between the five ratings.
There is a strong positive relationship among the variables “quality”, “clarity”, and “helpfulness.” There appears to be some correlation between “helpfulness” and “easiness”, but the data is more dispersed.
Question 5
For the student.survey data file in the smss package, conduct regression analyses relating (by convention, y denotes the outcome variable, x denotes the explanatory variable). (You can use ?student.survey in the R console, after loading the package, to see what each variable means.)
(i) y = political ideology and x = religiosity
(ii) y = high school GPA and x = hours of TV watching
5.1 Graphically portray how the explanatory variable relates to the outcome variable in each of the two cases
5.2 Summarize and interpret results of inferential analyses
As per the question, I will be focusing on the following variables: “re” (religiosity) and “pi” (political ideology) for subsection i, and “hi” (high school GPA) and “tv” (hours watching TV) for subsection ii.
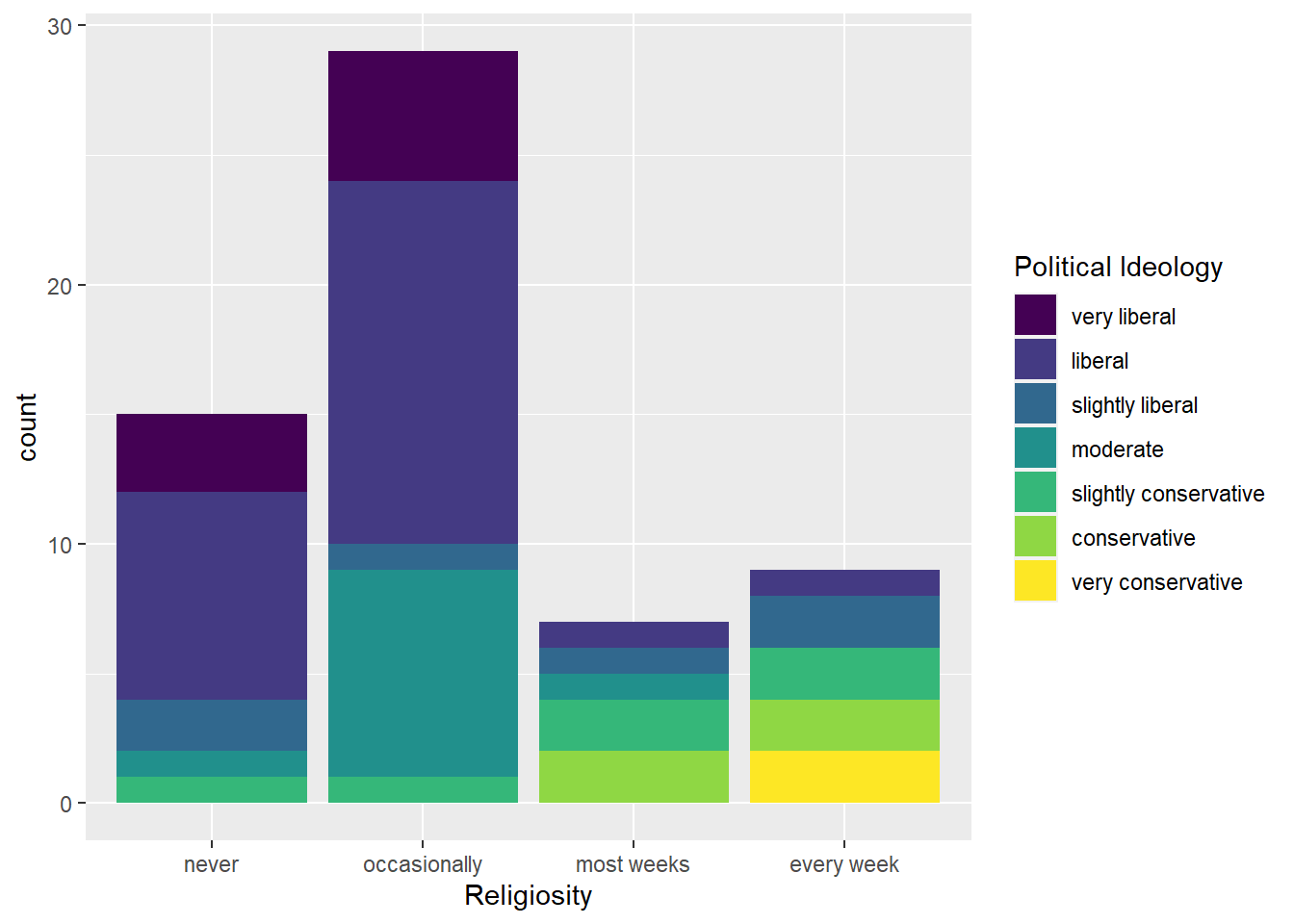
#subsection iggplot(data=student.survey,aes(x=re,fill=pi))+geom_bar() +labs(x="Religiosity", fill ="Political Ideology")
The above graph is one of several that could have been used; I just used a bar graph with fill colors since it was simple and suited my purposes. I didn’t know how to get additional information about what the variables actually mean, but I’m assuming “religiosity” refers to how often respondents attend religious services or practice their religion. Based on this graph, as “religiousness” increases, conservatism does as well. While not a majority by any means, it is still significant to note that those who identify as very conservative only appear in the bar labelled “every week,” whereas those who identify as very liberal are not even present on the graph to the right of “occasionally.” This, therefore, indicates that those who are heavily liberal-leaning in political ideology are far less likely to go to church/temple/mosque/etc. regularly/frequently than those who are more conservative.
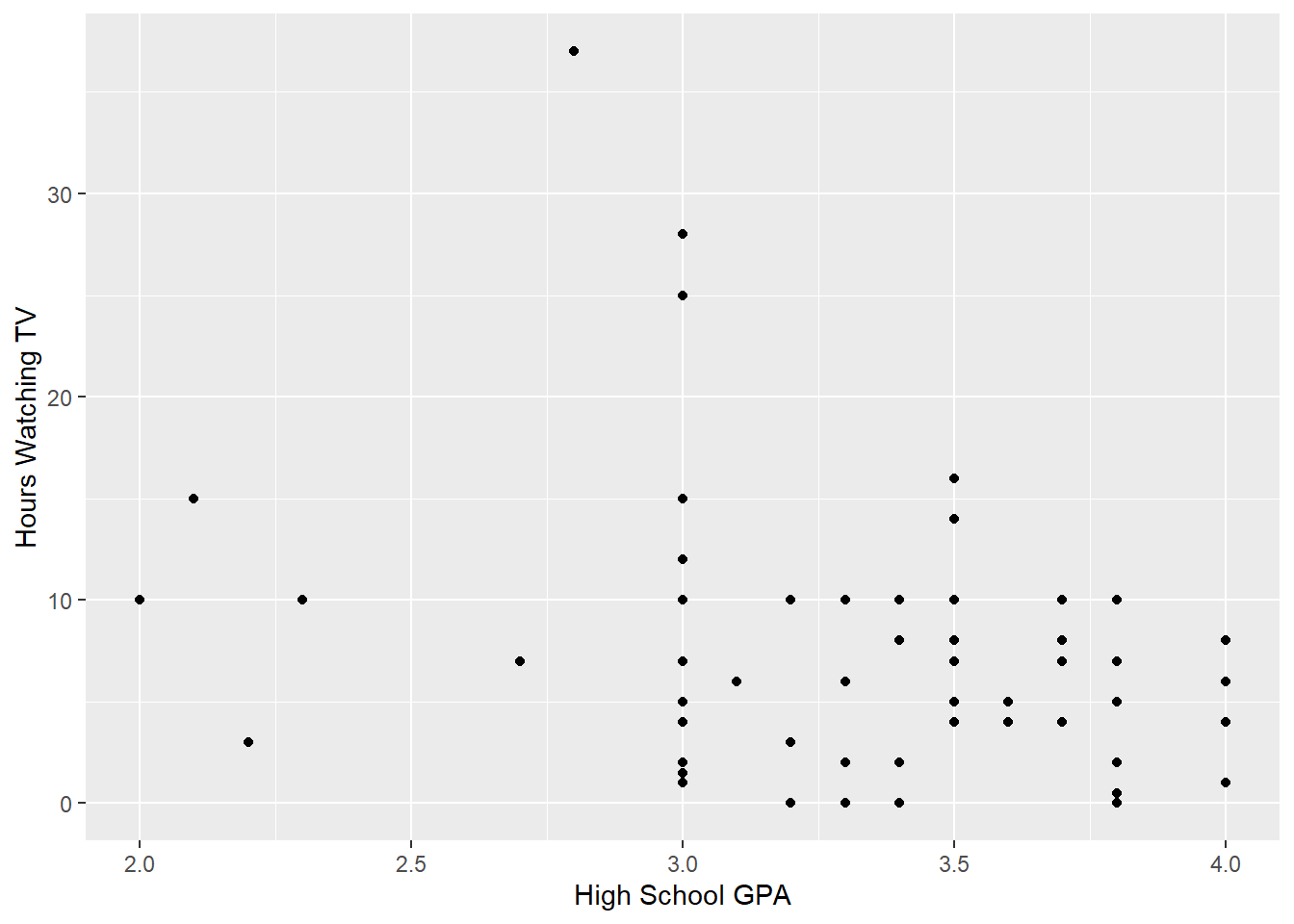
#subsection iiggplot(data=student.survey,aes(x=hi, y=tv)) +geom_point() +labs(x="High School GPA", y="Hours Watching TV")
Once again, this graph is just one of several visualizations that could be used. I chose a scatterplot to reflect individual responses and lessen the visual impact of outliers. While this graph does not show a linear relationship between the two variables, there is a higher concentration of responses with higher GPA’s and lower # of hours watching TV. I will conduct a simple regression model to test whether a linear relationship exists.
pi re hi tv
very liberal : 8 never :15 Min. :2.000 Min. : 0.000
liberal :24 occasionally:29 1st Qu.:3.000 1st Qu.: 3.000
slightly liberal : 6 most weeks : 7 Median :3.350 Median : 6.000
moderate :10 every week : 9 Mean :3.308 Mean : 7.267
slightly conservative: 6 3rd Qu.:3.625 3rd Qu.:10.000
conservative : 4 Max. :4.000 Max. :37.000
very conservative : 2