Code
library(tidyverse)
library(haven)
library(labelled)
library(crosstable)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(haven)
library(labelled)
library(crosstable)
knitr::opts_chunk$set(echo = TRUE)In 2001, Google piloted a program to boost profits, which were sinking as the “dot-com bubble” burst, by collecting data generated from users’ search queries and using it to sell precisely targeted advertising. The company’s ad revenues grew so quickly that they expanded their data collection tools with tracking “cookies” and predictive algorithms. Other technology firms took notice of Google’s soaring profits, and the sale of passively-collected data from people’s online activities soon became the predominant business model of the internet economy (Zuboff, 2015).
As the data-collection practices of “Big Tech” firms, including Google, Amazon, Facebook (Meta), Apple, and Microsoft, have gradually been exposed, the public is now aware that the “free” platforms that have become essential to daily life are actually harvesting personal information as payment. Despite consumers being essentially extorted into accepting this arrangement, regulatory intervention into “surveillance capitalism” has remained limited.
Over the two decades since passive data collection began commercializing the internet, survey research has shown the American public’s increasing concern over the dominance Big Tech has been allowed to exert. A 2019 study conducted by Pew Research Center found that 81% of Democrats and 70% of Republicans think there should be more government regulation of corporate data-use practices (Pew Research Center, 2019). It is very unusual to find majorities of both Republicans and Democrats agreeing on any policy position, since party affiliation is known to be a main predictor of any political stance, especially in the current polarized climate. The natural question that arises, then, is what other factors might predict support for increased regulation of data-collection practices?
Although few studies have directly examined the mechanisms behind public support for regulation of passive data collection, a good amount of research has been done on factors influencing individual adoption of privacy protection measures (Barth et al., 2019; Boerman et al., 2021; Turow et al., 2015). It seems a reasonable extrapolation that these factors would similarly influence support for additional data privacy regulation, leading to these hypotheses:
A higher level of awareness of data collection issues predicts support for increased Big Tech regulation.
Greater understanding of how companies use passively collected data predicts support for increased regulation.
The feeling of having no personal control over online tracking predicts support for increased regulation.
Feeling that it is impossible to protect oneself from online tracking, referred to as “digital resignation”, likely does not predict support for increased regulation, due to lack of faith in government’s ability to regulate Big Tech.
Certain demographic traits (age group, education level, and political ideology) have some relationship with attitudes toward Big Tech regulation.
Since there are currently dozens of data privacy bills pending in Congress, pinpointing the forces driving support for this type of legislation can help with both shaping the regulatory framework needed and appealing for broader support from voters.
Pew Research Center’s American Trends Panel (Wave 49) data set can provide insight into which of these factors are predictive of support for greater regulation of technology company data practices. In June 2019, an online survey covering a wide variety of topics was conducted and 4,272 separate observations for 144 variables were collected from adults age 18 and over. The margin of error (at the 95% confidence level) is given as +/- 1.87 percentage points.
The data set was compiled in SPSS and all pertinent variables are categorical.
#read in data from SPSS file
wav49 <- read_sav("_data/ATPW49.sav")Since the data set covers a wide variety of topics, selecting the variables of interest into a subset data frame makes it easier to manage.
sel_vars <- c('PRIVACYNEWS1_W49', 'CONTROLCO_W49', 'UNDERSTANDCO_W49', 'ANONYMOUS1CO_W49', 'GOVREGV1_W49', 'F_AGECAT', 'F_EDUCCAT', 'F_PARTYSUM_FINAL', 'F_IDEO')
wav49_selected <- wav49[sel_vars]Subset variables are renamed for clarity and to align with the operationalized concepts.
wav49_sel_clean <- rename(wav49_selected, AWARENESS = PRIVACYNEWS1_W49, CONTROL = CONTROLCO_W49, UNDERSTANDING = UNDERSTANDCO_W49, RESIGNATION = ANONYMOUS1CO_W49, GovtReg = GOVREGV1_W49, Age = F_AGECAT, Education = F_EDUCCAT, Party = F_PARTYSUM_FINAL, Ideology = F_IDEO)Following is a list of all the variables included in this analysis (variable names are designated by $).
Also shown are variable labels, which contain the full text of the survey question asked:
#summary of $variable names and their [labels]
var_label(wav49_sel_clean)$AWARENESS
[1] "PRIVACYNEWS1. How closely, if at all, do you follow news about privacy issues?"
$CONTROL
[1] "CONTROLCO. How much control do you think you have over the data that companies collect about you?"
$UNDERSTANDING
[1] "UNDERSTANDCO. How much do you feel you understand what companies are doing with the data they collect about you?"
$RESIGNATION
[1] "ANONYMOUS1CO. Do you think it is possible to go about daily life today without having companies collect data about you?"
$GovtReg
[1] "GOVREGV1. How much government regulation of what companies can do with their customers’ personal information do you think there should be?"
$Age
[1] "Age category"
$Education
[1] "Education level category"
$Party
[1] "Party summary"
$Ideology
[1] "Ideology"Because the data set is made up of categorical variables, some transformation and cleaning is required before computing any statistics, including conversion to factor variables and removal of user-defined missing values.
#convert all variables to factors
wav49_factored <- wav49_sel_clean %>%
mutate_all(as_factor)
#set 'Refused' and 'Don't Know" values to NA
levels(wav49_factored$AWARENESS)[levels(wav49_factored$AWARENESS)=="Refused"]<-NA
levels(wav49_factored$CONTROL)[levels(wav49_factored$CONTROL)=="Refused"]<-NA
levels(wav49_factored$UNDERSTANDING)[levels(wav49_factored$UNDERSTANDING)=="Refused"]<-NA
levels(wav49_factored$RESIGNATION)[levels(wav49_factored$RESIGNATION)=="Refused"]<-NA
levels(wav49_factored$GovtReg)[levels(wav49_factored$GovtReg)=="Refused"]<-NA
levels(wav49_factored$Age)[levels(wav49_factored$Age)=="DK/REF"]<-NA
levels(wav49_factored$Education)[levels(wav49_factored$Education)=="Don't know/Refused"]<-NA
levels(wav49_factored$Party)[levels(wav49_factored$Party)=="DK/Refused/No lean"]<-NA
levels(wav49_factored$Ideology)[levels(wav49_factored$Ideology)=="Refused"]<-NA
#remove NA values
wav49_factored <- na.omit(wav49_factored)Finally, since the trait of interest is support for government regulation of online data collection, collapsing the factor levels of the outcome variable GovtReg to two values - “More regulation” and “Not More regulation” - helps clarify the construct of “support”.
wav49_factored <- wav49_factored %>%
mutate(GovtReg = fct_collapse(GovtReg, "Not More regulation" = c("Less regulation", "About the same amount")))The data set is now primed for analysis.
As an initial assessment, a summary of response frequencies gives a good overview of trends surrounding the issues represented by the variables.
summary(wav49_factored) AWARENESS CONTROL UNDERSTANDING
Very closely :228 A great deal of control: 60 A great deal:122
Somewhat closely :996 Some control : 277 Some :676
Not too closely :635 Very little control :1075 Very little :972
Not at all closely:134 No control : 581 Nothing :223
RESIGNATION GovtReg Age
Yes, it is possible : 717 More regulation :1558 18-29:317
No, it is not possible:1276 Not More regulation: 435 30-49:613
50-64:607
65+ :456
Education Party Ideology
College graduate+ :777 Rep/Lean Rep: 877 Very conservative:175
Some College :552 Dem/Lean Dem:1116 Conservative :470
H.S. graduate or less:664 Moderate :757
Liberal :403
Very liberal :188 Cross tabulation of the variables can also help identify possible predictors.
table <- crosstable(wav49_factored, cols = everything(), by = "GovtReg")
as_flextable(table)label | variable | GOVREGV1. How much government regulation of what companies can do with their customers’ personal information do you think there should be? | |
|---|---|---|---|
More regulation | Not More regulation | ||
PRIVACYNEWS1. How closely, if at all, do you follow news about privacy issues? | Very closely | 189 (82.89%) | 39 (17.11%) |
Somewhat closely | 814 (81.73%) | 182 (18.27%) | |
Not too closely | 473 (74.49%) | 162 (25.51%) | |
Not at all closely | 82 (61.19%) | 52 (38.81%) | |
CONTROLCO. How much control do you think you have over the data that companies collect about you? | A great deal of control | 45 (75.00%) | 15 (25.00%) |
Some control | 186 (67.15%) | 91 (32.85%) | |
Very little control | 868 (80.74%) | 207 (19.26%) | |
No control | 459 (79.00%) | 122 (21.00%) | |
UNDERSTANDCO. How much do you feel you understand what companies are doing with the data they collect about you? | A great deal | 97 (79.51%) | 25 (20.49%) |
Some | 516 (76.33%) | 160 (23.67%) | |
Very little | 789 (81.17%) | 183 (18.83%) | |
Nothing | 156 (69.96%) | 67 (30.04%) | |
ANONYMOUS1CO. Do you think it is possible to go about daily life today without having companies collect data about you? | Yes, it is possible | 520 (72.52%) | 197 (27.48%) |
No, it is not possible | 1038 (81.35%) | 238 (18.65%) | |
Age category | 18-29 | 232 (73.19%) | 85 (26.81%) |
30-49 | 463 (75.53%) | 150 (24.47%) | |
50-64 | 489 (80.56%) | 118 (19.44%) | |
65+ | 374 (82.02%) | 82 (17.98%) | |
Education level category | College graduate+ | 633 (81.47%) | 144 (18.53%) |
Some College | 432 (78.26%) | 120 (21.74%) | |
H.S. graduate or less | 493 (74.25%) | 171 (25.75%) | |
Party summary | Rep/Lean Rep | 628 (71.61%) | 249 (28.39%) |
Dem/Lean Dem | 930 (83.33%) | 186 (16.67%) | |
Ideology | Very conservative | 106 (60.57%) | 69 (39.43%) |
Conservative | 352 (74.89%) | 118 (25.11%) | |
Moderate | 590 (77.94%) | 167 (22.06%) | |
Liberal | 344 (85.36%) | 59 (14.64%) | |
Very liberal | 166 (88.30%) | 22 (11.70%) | |
The contingency table of this data, however, reveals no clear relationship between any of these subgroups and opinion on regulation of Big Tech.
The next step, then, is visualization - bar charts can make basic patterns in categorical data easier to spot.
#base support for government regulation
ggplot(data = wav49_factored, aes(x = GovtReg)) +
geom_bar() 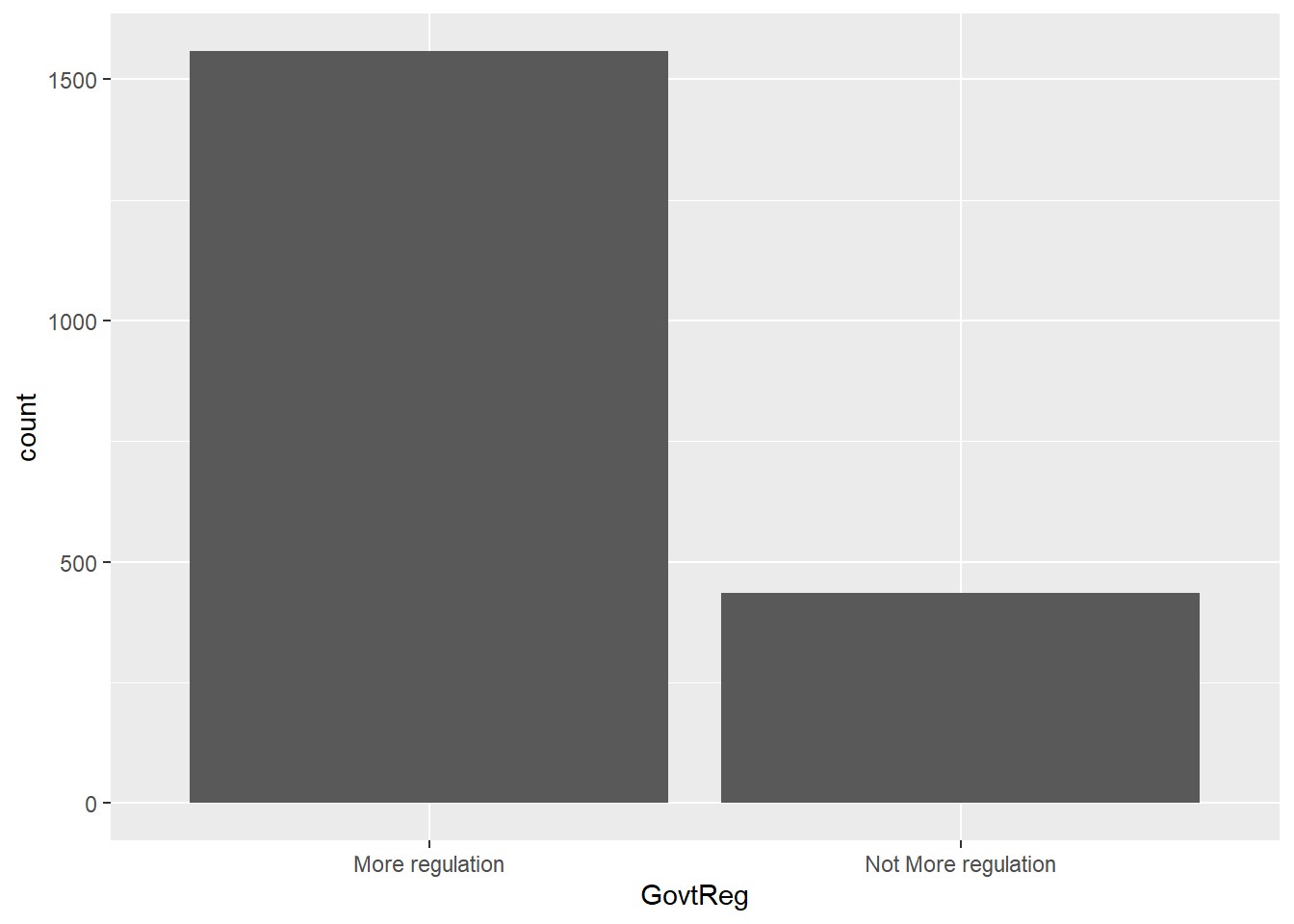
#govtreg grouped by party affiliation
ggplot(data = wav49_factored, aes(x = GovtReg, fill = Party)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1")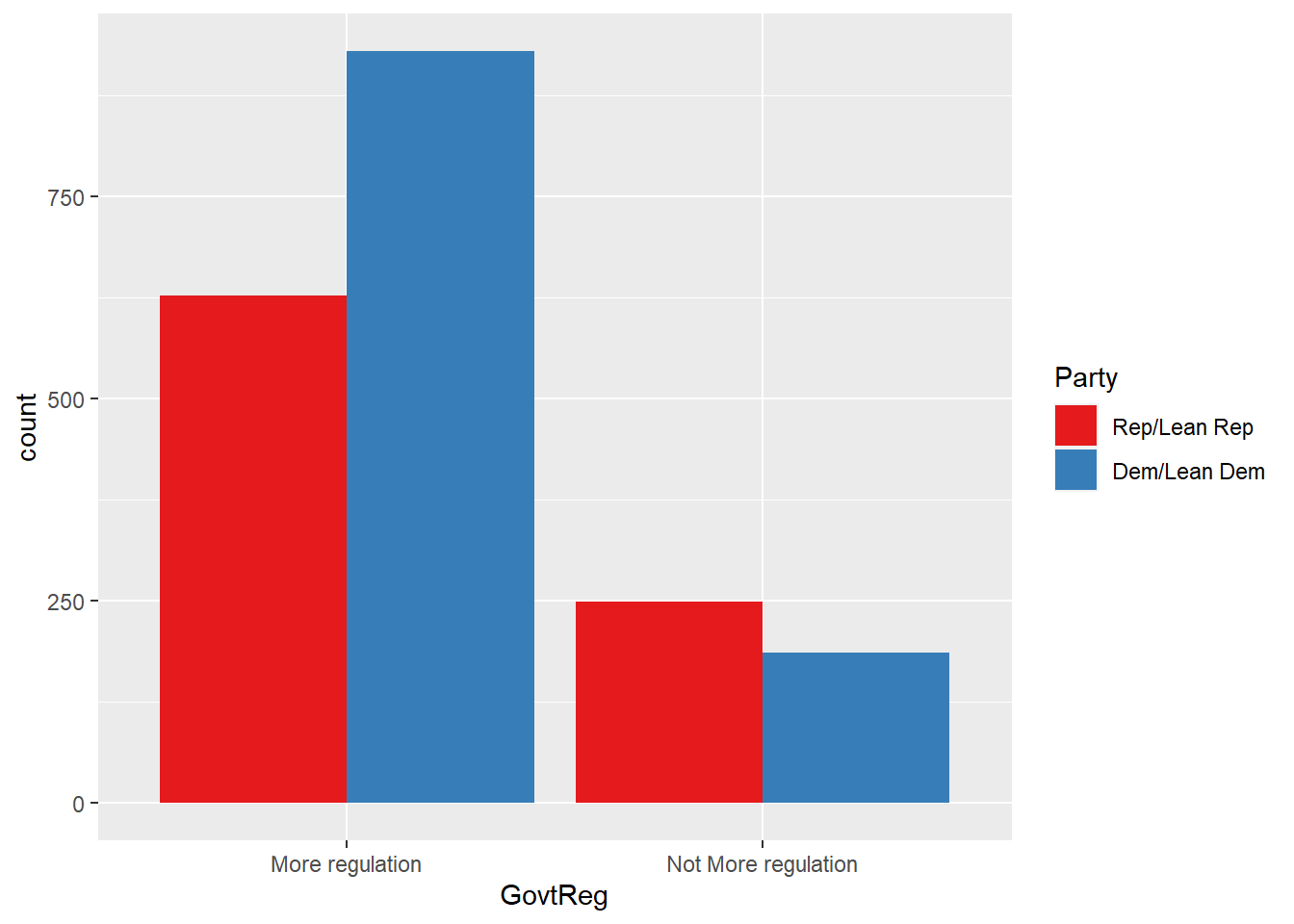
#govtreg grouped by ideology
ggplot(data = wav49_factored, aes(x = GovtReg, fill = Ideology)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1")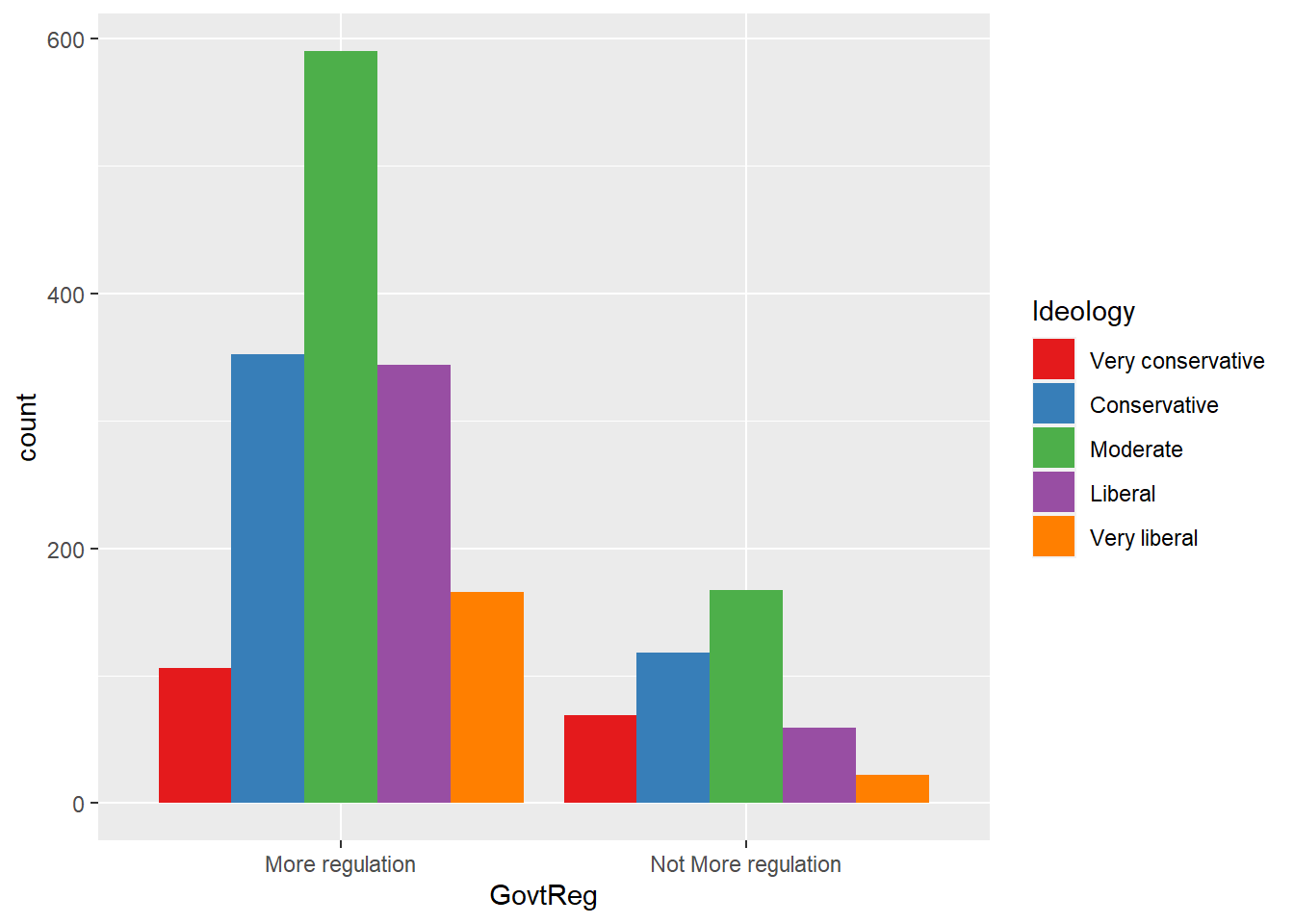
#govtreg grouped by education
ggplot(data = wav49_factored, aes(x = GovtReg, fill = Education)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1", direction = -1)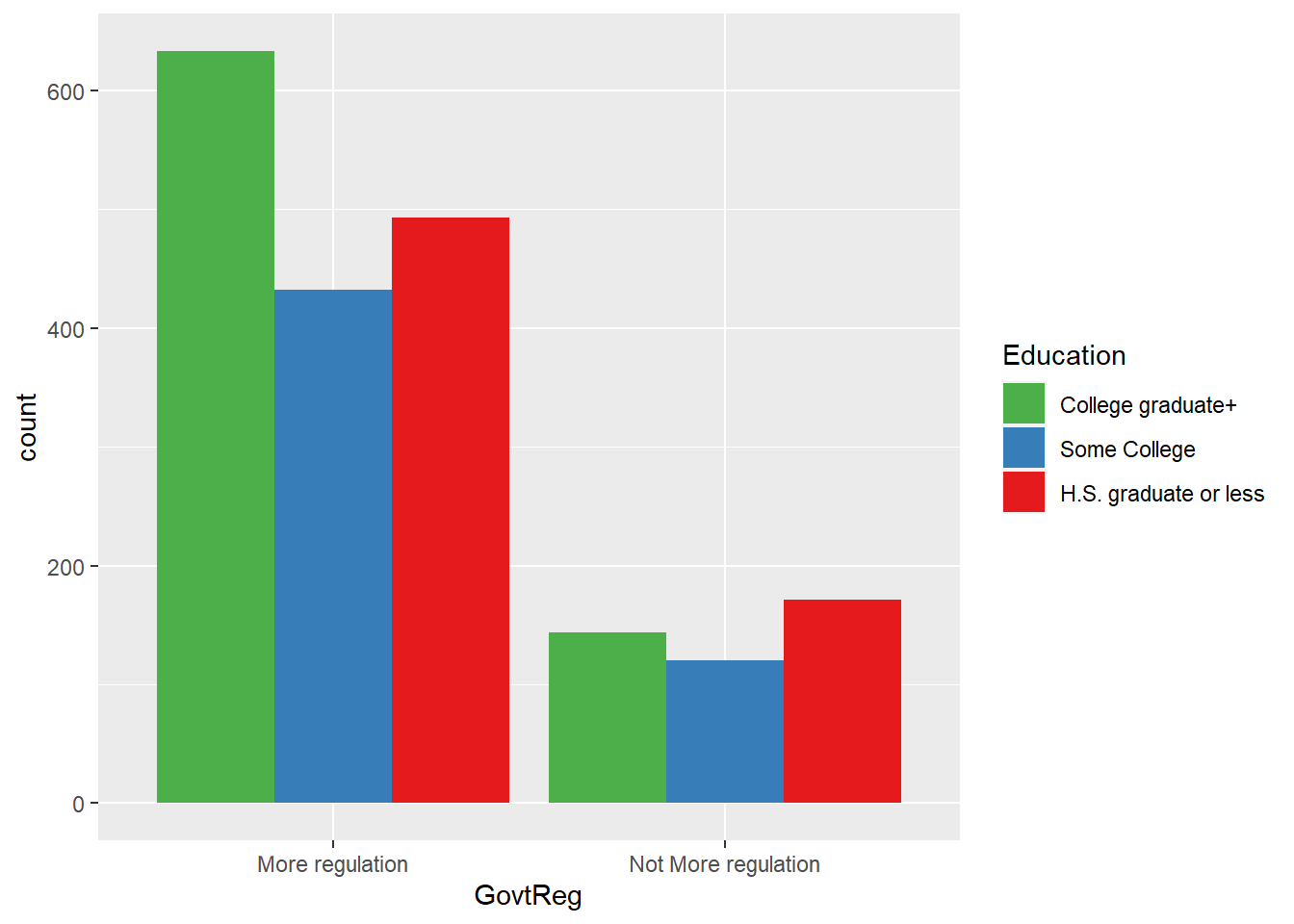
#govtreg grouped by age
ggplot(data = wav49_factored, aes(x = GovtReg, fill = Age)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1", direction = -1)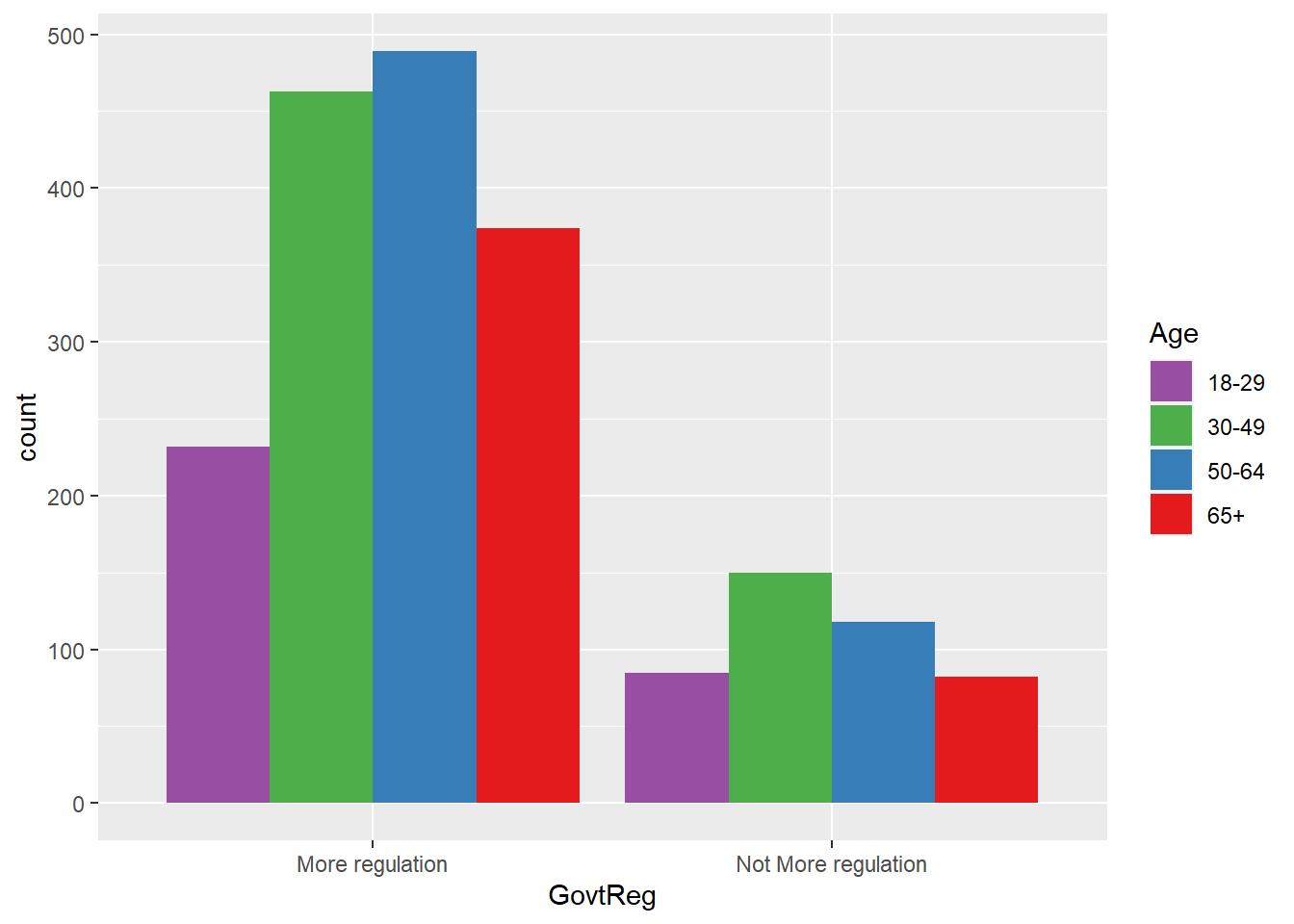
#govtreg grouped by resignation
ggplot(data = wav49_factored, aes(x = GovtReg, fill = RESIGNATION)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1", direction = -1)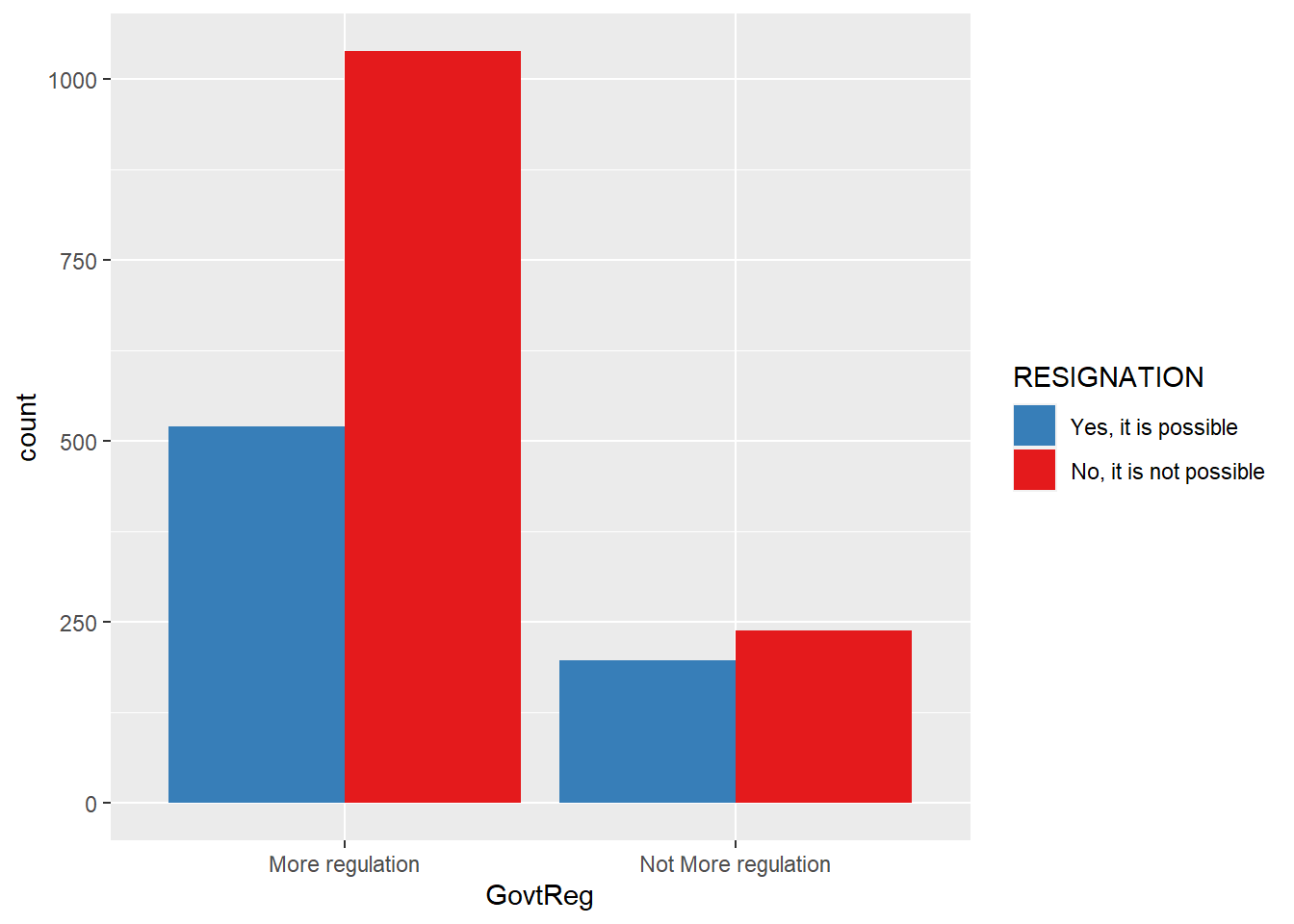
#govtreg grouped by understanding
ggplot(data = wav49_factored, aes(x = GovtReg, fill = UNDERSTANDING)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1", direction = -1)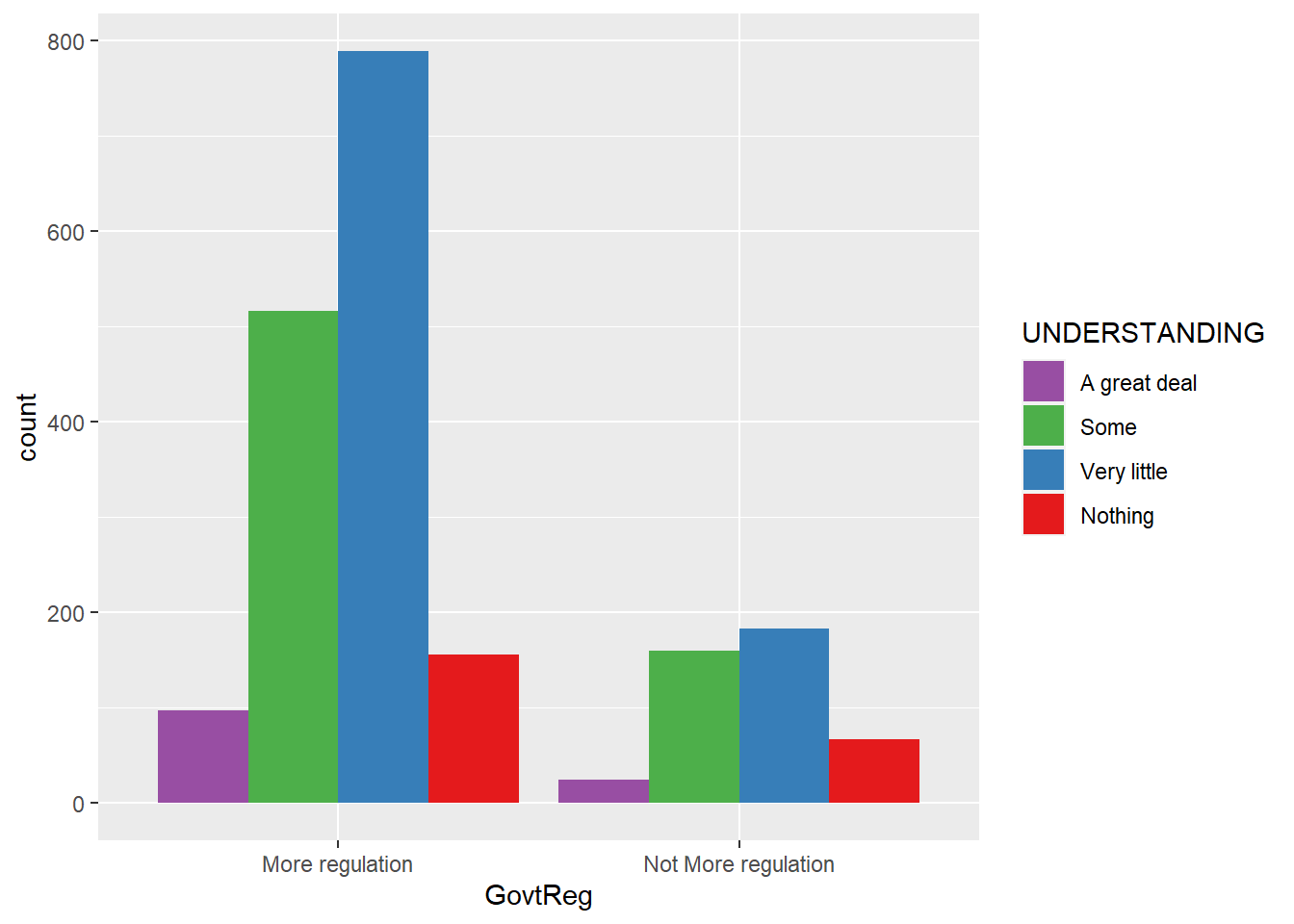
#govtreg grouped by control
ggplot(data = wav49_factored, aes(x = GovtReg, fill = CONTROL)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1", direction = -1)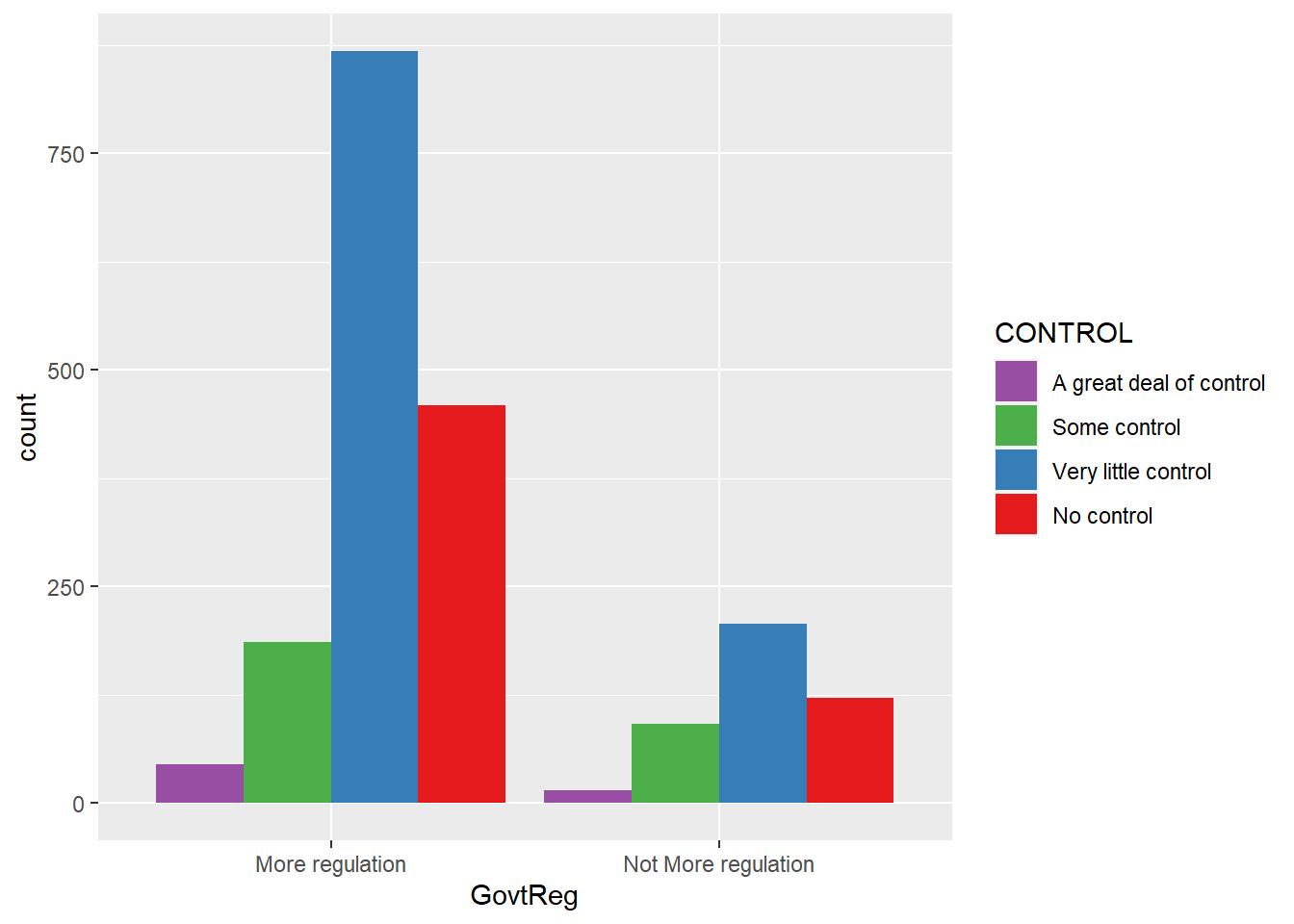
#govtreg grouped by awareness
ggplot(data = wav49_factored, aes(x = GovtReg, fill = AWARENESS)) +
geom_bar(position = "dodge") +
scale_fill_brewer(palette = "Set1", direction = -1)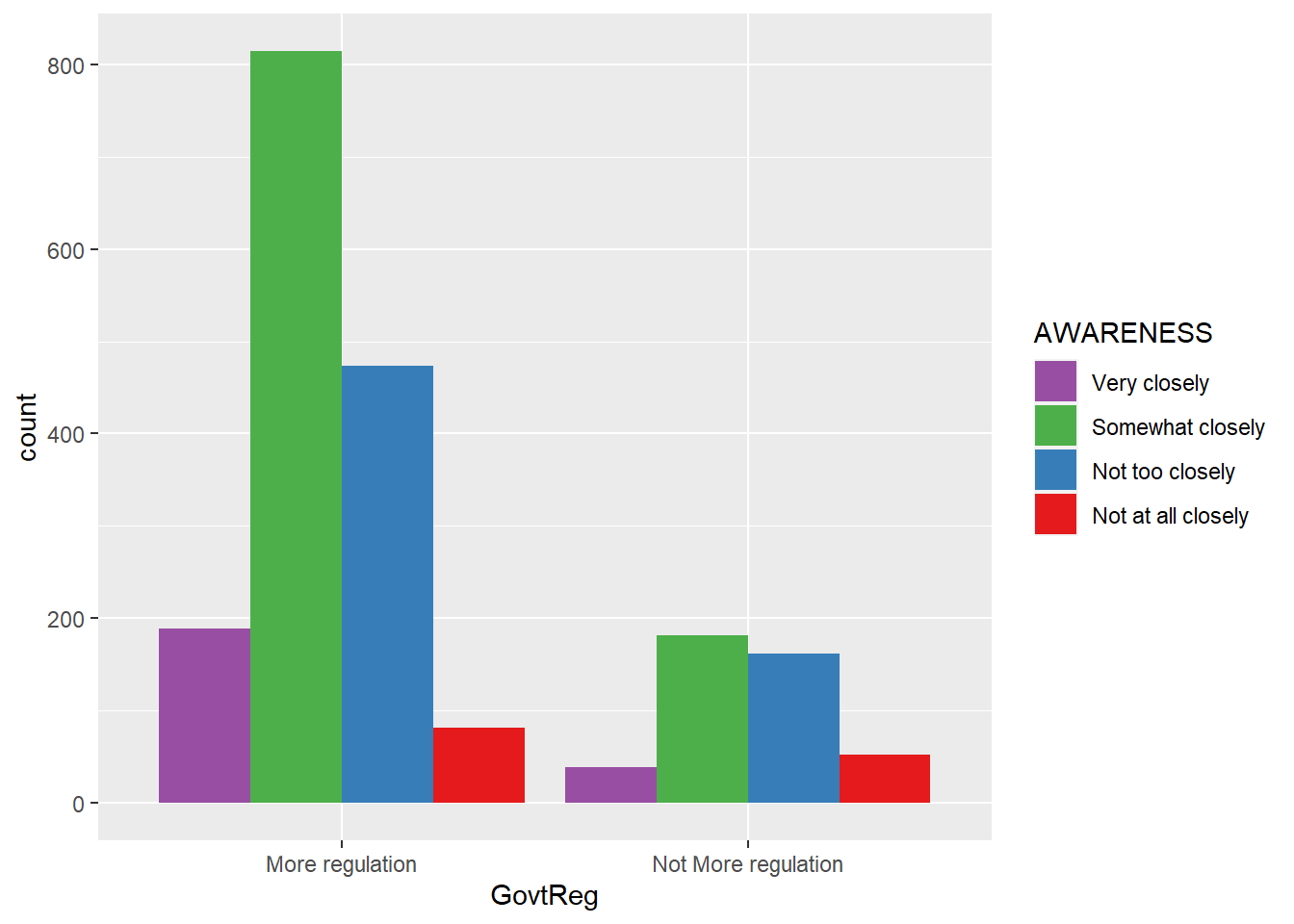
The visualizations suggest that having little understanding of the mechanisms of data monetization, feeling resigned to the inevitability of personal data collection, and being middle-aged may each predict support for government regulation of Big Tech to some degree.
Because all of the variables of interest in the data set are categorical, the chi-squared test of independence is used to determine if there is indeed a statistically significant association between the selected explanatory variables and the outcome variable of opinion on government regulation.
#create separate contingency tables for each explanatory variable
#tblawareness = table(wav49_factored$awareness, wav49_factored$govtreg)
#tblcontrol = table(wav49_factored$control, wav49_factored$govtreg)
#tblunderstanding = table(wav49_factored$understanding, wav49_factored$govtreg)
#tblresignation = table(wav49_factored$resignation, wav49_factored$govtreg)
#tblage = table(wav49_factored$age, wav49_factored$govtreg)
#tbleducation = table(wav49_factored$education, wav49_factored$govtreg)
#tblparty = table(wav49_factored$party, wav49_factored$govtreg)
#tblideology = table(wav49_factored$ideology, wav49_factored$govtreg)
#run chi-squared tests on each table
#chisq.test(tblawareness)
#chisq.test(tblcontrol)
#chisq.test(tblunderstanding)
#chisq.test(tblresignation)
#chisq.test(tblage)
#chisq.test(tbleducation)
#chisq.test(tblparty)
#chisq.test(tblideology)The test results show that all of the selected variables are significantly correlated with GovtReg, with p-values well below the .05 threshhold. The null hypothesis can be rejected, as there is evidence supporting the alternative - that these variables have an effect on support for government regulation of Big Tech’s use of passively-collected personal data.
The first step of model fitting with this data set is to create a data frame of the variables with numeric values.
#convert variables to numeric and remove user-defined missing values
#wav49_sel_clean[wav49_sel_clean == 99] <- NA
#wav49_sel_clean <- zap_missing(wav49_sel_clean)
#wav49_numeric <- wav49_sel_clean %>%
# mutate_at(c(1:9), as.numeric)
#head(wav49_numeric)The first model contains all of the selected variables as explanatory variables for the outcome variable GovtReg.
#model_full <- lm(GovtReg ~ ., data = wav49_numeric)
#summary(model_full)The full model shows that AWARENESS, RESIGNATION, Age, and Ideology all have significant effects on GovtReg, with AWARENESS and Ideology having very small p-values. The residuals are also quite small, indicating that the model is appropriate. The Adjusted \(R^{2}\), however, shows that even the full model explains less than 1% of the variance in GovtReg.
Building another model with only the variables shown to be significant could improve the fit.
#model_alt <- lm(GovtReg ~ AWARENESS + RESIGNATION + Age + Ideology, data = #wav49_numeric)
#summary(model_alt)The alternative model improves the Adjusted \(R^{2}\) very slightly, and lowers the p-values of all the explanatory variables.
It is feasible that changes in the level of issue awareness cause changes in whether or not one feels “digital resignation”. Therefore, it could be worthwhile to build a model that accounts for this potential interaction.
#model_int <- lm(GovtReg ~ AWARENESS*RESIGNATION + Age + Ideology, data = #wav49_numeric)
#summary(model_int)This model does not seem to be an improvement on the others, as the interaction variable is not statistically significant, and the Adjusted \(R^{2}\) is not improved.
Of these, the best model is likely the second one tested - the alternative model.
#generate diagnostic plots for the alternative model
#plot(model_alt)The Residuals vs. Fitted Values plot indicates possible violations, as the residuals are not randomly distributed around the 0 line, although they do seem to form a somewhat horizontal pattern, and there appear to be no outliers.
The QQ-Plot shows definite violation of the assumption of normality, as the points are far off the line.
The Scale-Location plot shows violation of the constant variance assumption, as there are clear increasing and decreasing trends.
Finally, the Residuals vs. Leverage plot also seems to indicate violation, as there are many points outside of the lines.
The fact that so many assumptions are violated by the regression model indicates that logistic regression would be more appropriate for this data set of categorical variables, and likely yield better results.
Because the dependent variable of interest, GovtReg, is binary, and the explanatory variables are categorical, it is most appropriate to fit a binary logistic regression model.
#binary logistic regression model
fit <- glm(GovtReg ~ ., data = wav49_factored, family = binomial)
summary(fit)
Call:
glm(formula = GovtReg ~ ., family = binomial, data = wav49_factored)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.4938 -0.7160 -0.5554 -0.3805 2.3144
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.205172 0.443932 -0.462 0.643960
AWARENESSSomewhat closely 0.061310 0.202003 0.304 0.761501
AWARENESSNot too closely 0.442466 0.208913 2.118 0.034180 *
AWARENESSNot at all closely 0.884973 0.263338 3.361 0.000778 ***
CONTROLSome control 0.486782 0.343348 1.418 0.156264
CONTROLVery little control -0.103716 0.329329 -0.315 0.752814
CONTROLNo control -0.179759 0.339988 -0.529 0.596999
UNDERSTANDINGSome 0.173156 0.256164 0.676 0.499069
UNDERSTANDINGVery little -0.071266 0.255856 -0.279 0.780598
UNDERSTANDINGNothing 0.436160 0.291258 1.498 0.134263
RESIGNATIONNo, it is not possible -0.353115 0.117886 -2.995 0.002741 **
Age30-49 -0.178430 0.166871 -1.069 0.284948
Age50-64 -0.485602 0.175617 -2.765 0.005690 **
Age65+ -0.509737 0.190230 -2.680 0.007371 **
EducationSome College -0.003026 0.145763 -0.021 0.983435
EducationH.S. graduate or less 0.178005 0.137290 1.297 0.194783
PartyDem/Lean Dem -0.406697 0.143123 -2.842 0.004489 **
IdeologyConservative -0.648848 0.194398 -3.338 0.000845 ***
IdeologyModerate -0.684972 0.197165 -3.474 0.000513 ***
IdeologyLiberal -1.042692 0.249333 -4.182 2.89e-05 ***
IdeologyVery liberal -1.266658 0.309318 -4.095 4.22e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 2091.5 on 1992 degrees of freedom
Residual deviance: 1937.5 on 1972 degrees of freedom
AIC: 1979.5
Number of Fisher Scoring iterations: 4The logistic regression model output shows that AWARENESS, RESIGNATION, Age, political Party, and political Ideology have statistically significant effects on support for government regulation of Big Tech’s use of personal data.
Surprisingly, only issue AWARENESS has a positive effect on GovtReg.
Digital RESIGNATION, Age, political Party, and politcal Ideology all have negative effects on GovtReg.
The fact that the Residual Deviance is less than the Null Deviance indicates that the model explains more of the variation in support for government regulation than a model with only the intercept.
These results suggest that support for increased government regulation of Big Tech’s data collection policies is likely spread across more subgroups and in less predictable ways than is ordinarily expected for policy issues.
Barth, S., de Jong, M. D. T., Junger, M., Hartel, P. H. & Roppelt, J. C. (2019). Putting the privacy paradox to the test: Online privacy and security behaviors among users with technical knowledge, privacy awareness, and financial resources. Telematics and Informatics, 41, 55–69. doi:10.1016/j.tele.2019.03.003
Boerman, S. C., Kruikemeier, S., & Zuiderveen Borgesius, F. J. (2021). Exploring Motivations for Online Privacy Protection Behavior: Insights From Panel Data. Communication Research, 48(7), 953–977. https://doi.org/10.1177/0093650218800915
Pew Research Center. (2019). Americans and privacy: Concerned, confused and feeling lack of control over their personal information. https://www.pewresearch.org/internet/2019/11/15/americans-and-privacy-concerned-confused-and- feeling-lack-of-control-over-their-personal-information/
Pew Research Center. (2020). Wave 49 American trends panel [Data set]. https://www.pewresearch.org/internet/dataset/american-trends-panel-wave-49/
Turow, J., Hennessy, M. & Draper, N. (2015). The tradeoff fallacy – How marketers are misrepresenting American consumers and opening them up to exploitation. Annenberg School for Communication.
Zuboff, S. (2015). Big other: Surveillance capitalism and the prospects of an information civilization. Journal of Information Technology, 30(1), 75–89. doi:10.1057/jit.2015.5