Code
library(tidyverse)
library(smss)
library(alr4)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(smss)
library(alr4)
knitr::opts_chunk$set(echo = TRUE)Of all the four predictors listed, Beds would be deleted first because it has the highest p-value
For forward elimination, we would add Size to the model first. Since Size and New have similar p-values, the correlation matrix reinforces the selection of Size first since it has a higher correlation to price compared to New.
I think that Beds has such a large p-value in the regression model because it is somewhat redundant information. Size its capturing the overall size of the house, including bedrooms,meaning Beds isn’t really adding anything new to the model. Beds could be highly correlated with price since more beds means larger size, but we already have Size accounting for a large portion of the variation.
library(smss)
data("house.selling.price.2")
reg <- house.selling.price.2
hw1_lm_full <- lm(P ~ S + Be + Ba + New, data=reg)
model_terms <- c('New', 'Ba', 'Be', 'S', 'Be + Ba + New', 'S + Be + New', 'S + Ba + New', 'S + Be + Ba', 'Ba + New', 'Be + New', 'Be + Ba', 'S + New', 'S + Be', 'S + Ba', 'S + Be + Ba + New')
hw1_model_stats <- data.frame(model = character(),
r2 = numeric(),
adj_r2 = numeric(),
PRESS = numeric(),
AIC = numeric(),
BIC = numeric(),
stringsAsFactors = FALSE)
PRESS <- function(model) {
i <- residuals(model)/(1 - lm.influence(model)$hat)
sum(i^2)
} attach(hw1)Error in attach(hw1): object 'hw1' not found for(i in 1:length(model_terms)){
lm.i <- lm(paste("P ~ ", model_terms[i], sep = ""))
sul = summary(lm.i)
rowsss <- c(model_terms[i],
signif(sul$r.squared, 4),
signif(sul$adj.r.squared, 4),
signif(PRESS(lm.i), 4),
signif(AIC(lm.i), 4),
signif(BIC(lm.i))
)
hw1_model_stats <- rbind(hw1_model_stats, rowsss)
}Error in eval(predvars, data, env): object 'P' not found colnames(hw1_model_stats)<-c("Model", "R2", "Adj R2", "PRESS", "AIC", "BIC")
kbl <- knitr::kable(hw1_model_stats)R2 - In terms of R2, using all the predictors wins out by a slim margin (.8681)
Adjusted R2 - In terms of Adjusted R2, using Size, Baths, and New wins out.
PRESS - In terms of using PRESS, again, using Size, Baths, and New wins out.
AIC - In terms of using AIC, again, using Size, Baths, and New wins out.
BIC - In terms of using BIC, again, again,using Size, Baths, and New wins out.
Based off the five criterion listed in the previous question, the model that uses (size, baths, new) as predictors won out on four of the five criteria, thus I would use this model.
black_cherry <- trees
black_cherry_lm <- lm(Volume ~ Height + Girth, data = black_cherry)
par(mfrow = c(2,3)); plot(black_cherry_lm, which = 1:6)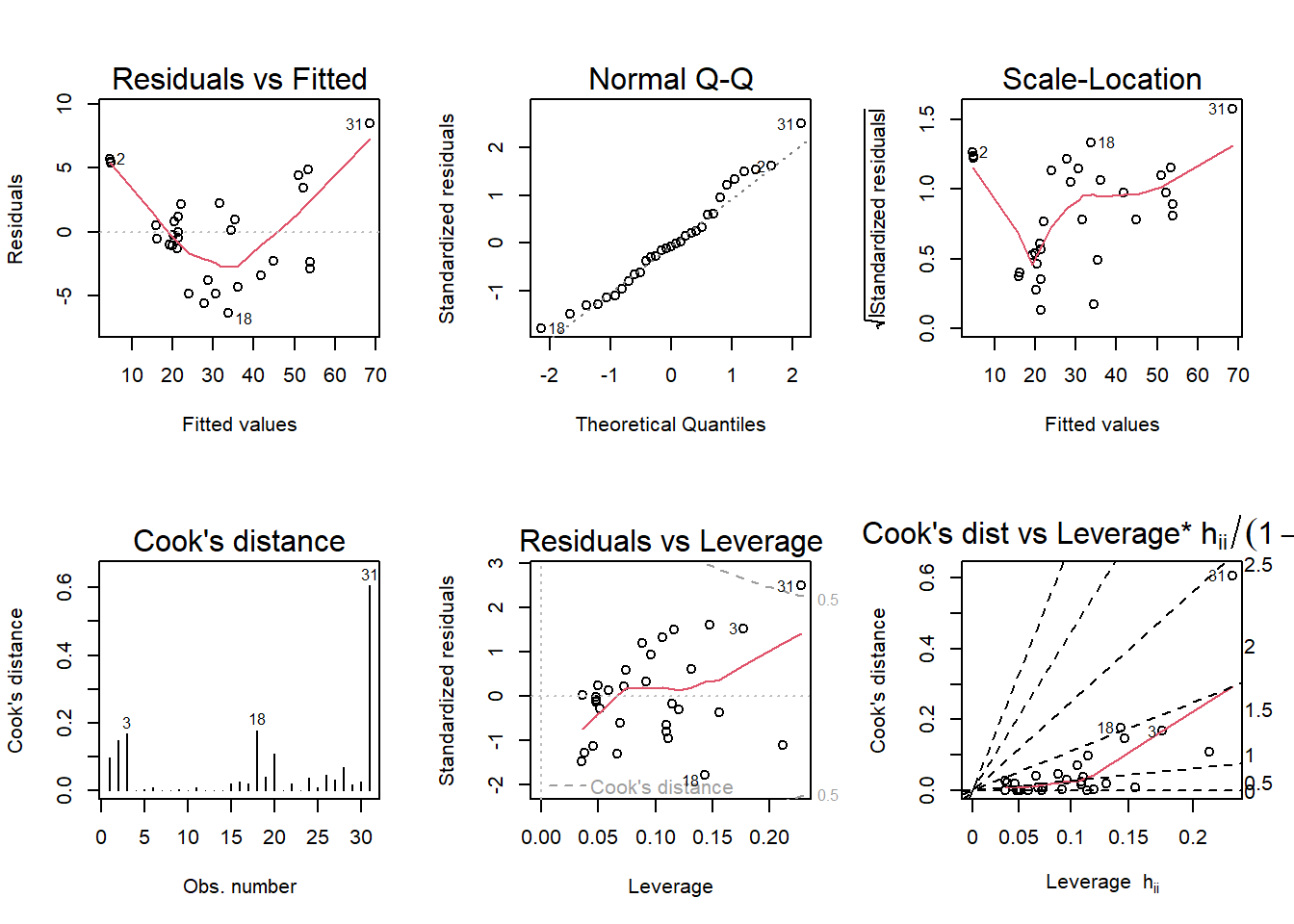
The following regression assumptions are being violated:
Homoskedasticity - According the the residuals vs fitted plot, the residuals seemed to be grouped at various spots within the plot. This seems to suggest some heteroskedasticity going on.
Independence of Errors - Judging by the Cook’s Distance and Residuals vs Leverage plots, observation 31 seems to be unusually influential. Given its distance from observations, as well as the observation falling outside of the bound in the Residuals vs Leverage plot, it be said that due to this observation, this assumption is being violated.
vt <- lm(Buchanan ~ Bush, data=florida)
par(mfrow = c(2,3)); plot(vt, which = 1:6)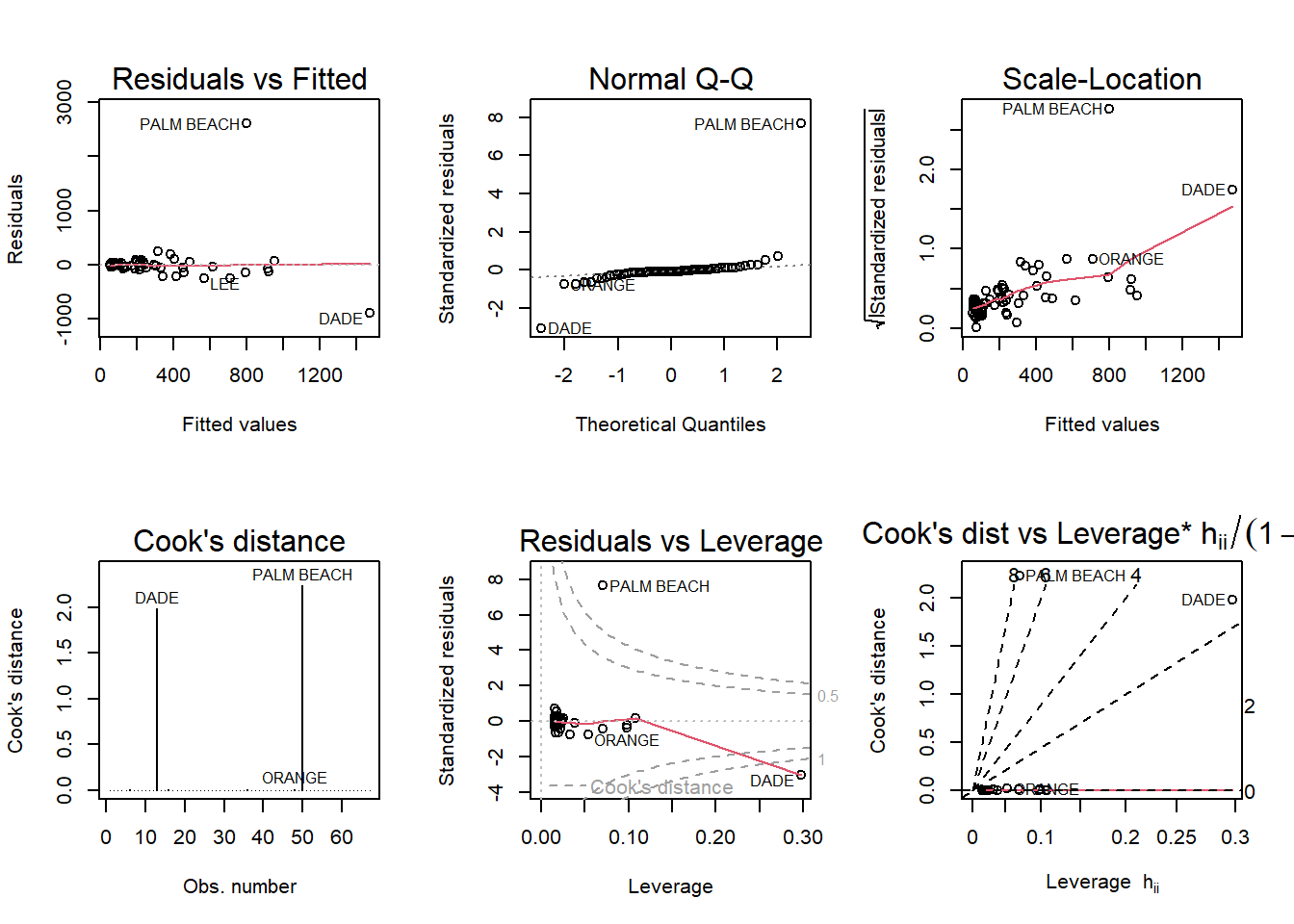
I would absolutely classify Palm Beach County as an outlier considering for a majority of the graphs, it is well outside of the rest of the observations. Palm Beach County as a single observation cannot be reasonably grouped with any of the other observations.