Code
library(tidyverse)
library(readxl)
library(ggplot2)
library(stats)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(readxl)
library(ggplot2)
library(stats)
knitr::opts_chunk$set(echo = TRUE)lung <- read_excel("C:/Users/gunde/Downloads/LungCapData.xls")
lungThe Lung Capacity data contains 725 rows and 6 columns that determine age, height etc., The key classification parameter is based on smoker vs non-smoker.
The distribution of LungCap looks as follows:
lung %>%
ggplot(aes(LungCap, ..density..)) +
geom_histogram(bins= 40, color = "red") +
geom_density(color = "green") +
theme_classic() +
labs(title = "LungCap Probability Distribution", x = "Lung Capcity", y = "Probability Density")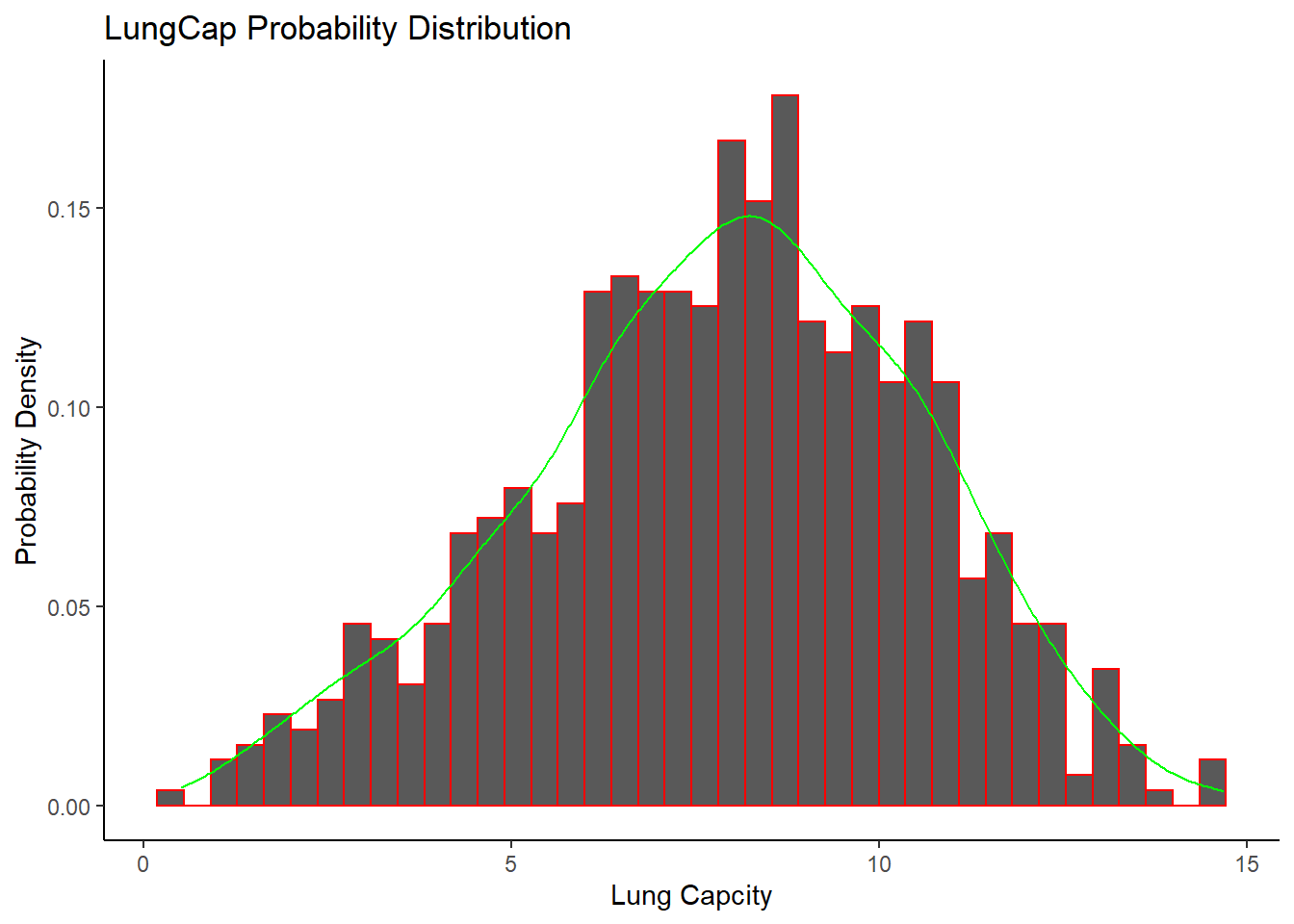
The observations plotted by histogram are closer to mean which suggests that it is a normal distribution.
The distribution of LungCap on basis of gender looks as follows:
lung %>%
ggplot(aes(y = dnorm(LungCap), color = Gender)) +
geom_boxplot() +
theme_classic() +
labs(title = "LungCap Probability Distribution based on gender", y = "Probability Density")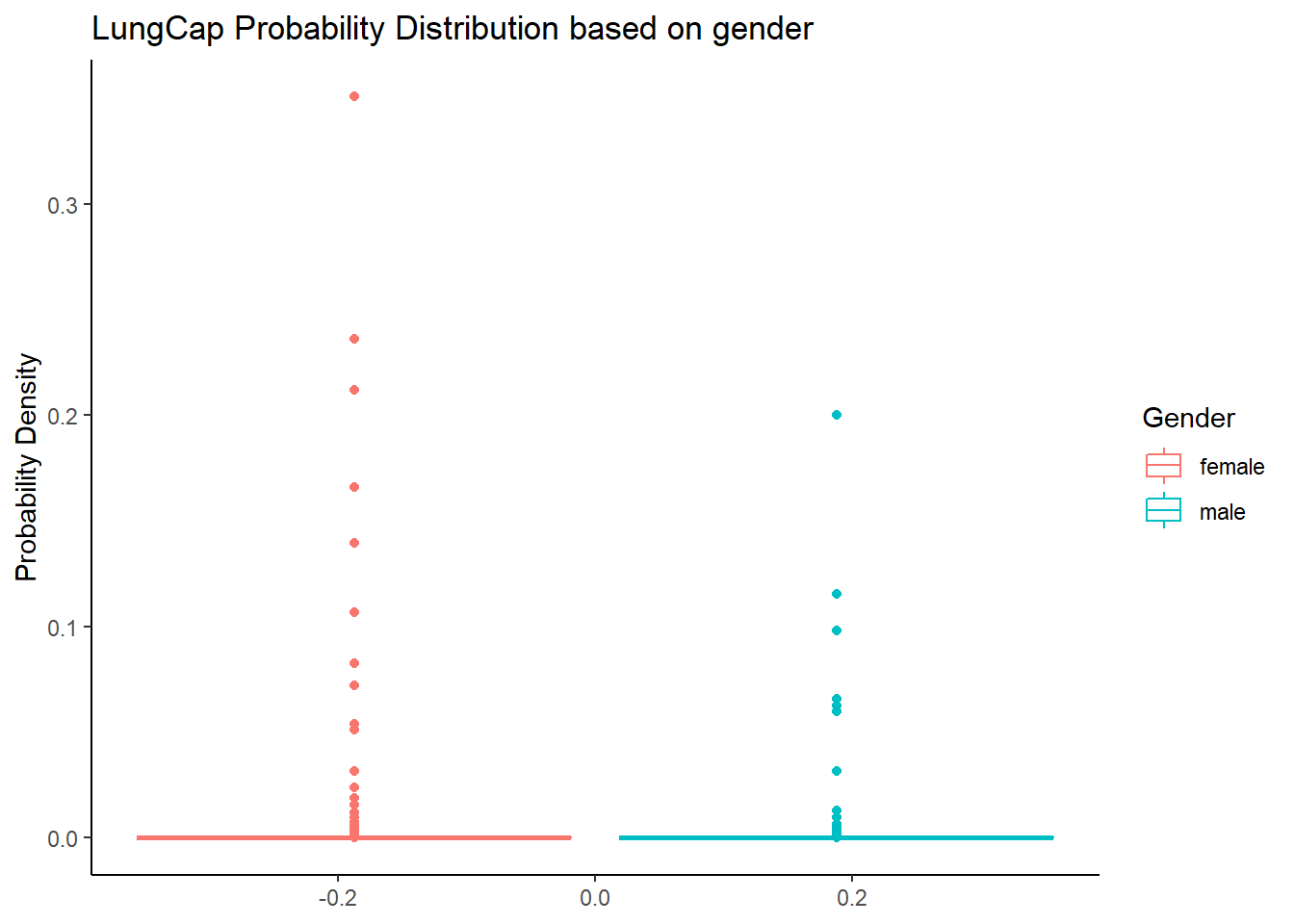
The box plot shows that the probability density of the male < female.
Comparison of mean lung capacities between smokers and non-smokers:
Mean_smoke <- lung %>%
group_by(Smoke) %>%
summarise(mean = mean(LungCap))
Mean_smokeThe table contains the mean lung capacity. The observations suggest that the mean value is higher for smokers than non-smokers. This isn’t entirely correct as the individual biological factors plays a main role. So the data is inadequate to form an opinion.
Relationship between Smoke and Lung capacity on basis of given age categories:
lung <- mutate(lung, AgeGrp = case_when(Age <= 13 ~ "less than or equal to 13",
Age == 14 | Age == 15 ~ "14 to 15",
Age == 16 | Age == 17 ~ "16 to 17",
Age >= 18 ~ "greater than or equal to 18"))
lung %>%
ggplot(aes(y = LungCap, color = Smoke)) +
geom_histogram(bins = 40) +
facet_wrap(vars(AgeGrp)) +
theme_classic() +
labs(title = "Relationship of LungCap and Smoke based on age categories", y = "Lung Capacity", x = "Frequency")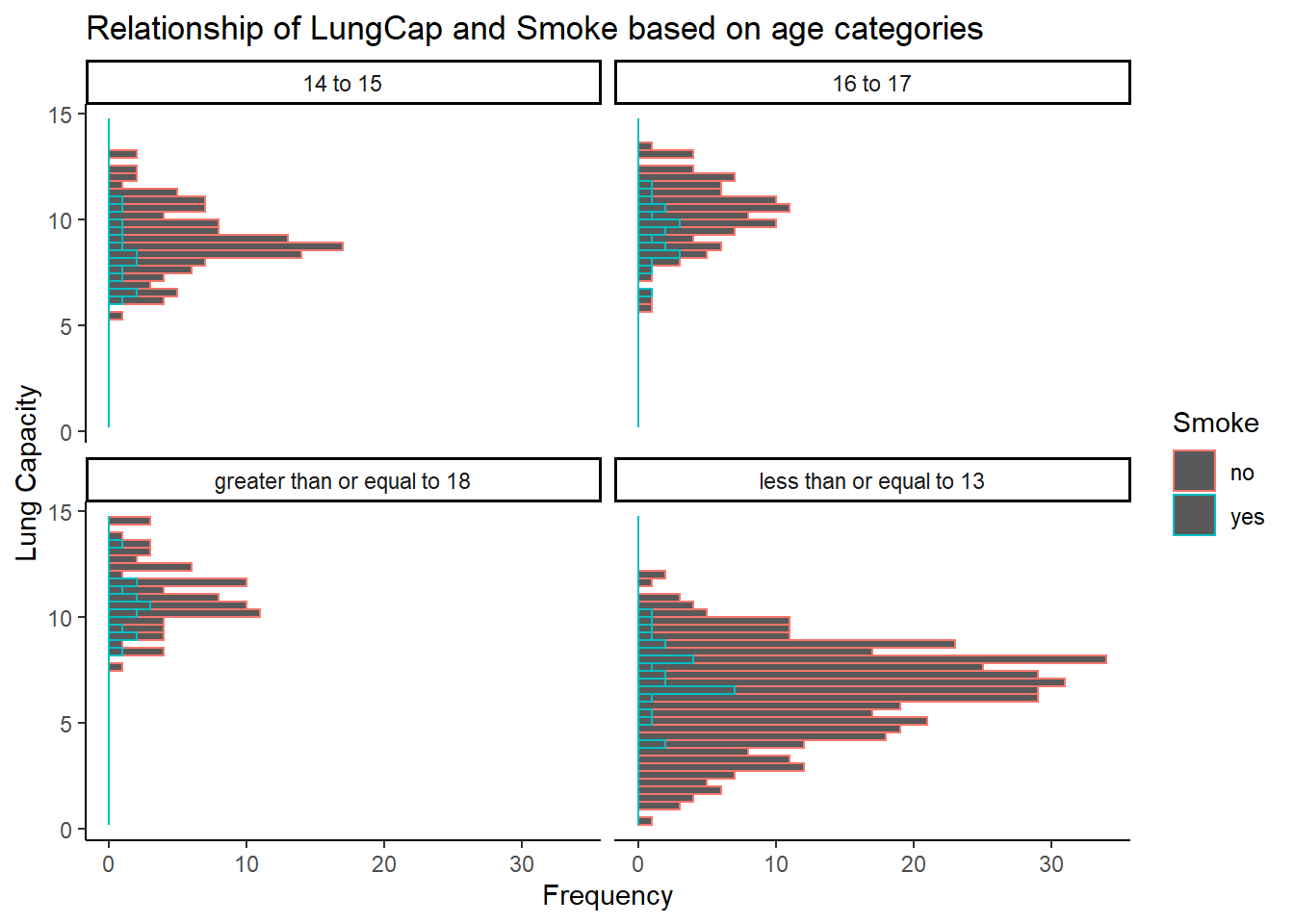
From the above plot, we can derive two important observations: 1. The lung capacity of non-smokers is more than smokers. 2. The people who smoke are less in age group of “less than or equal to 13”. So as the result as age increases the lung capacity decreases.
Relationship between Smoke and Lung capacity on basis of age:
lung %>%
ggplot(aes(x = Age, y = LungCap, color = Smoke)) +
geom_line() +
theme_classic() +
facet_wrap(vars(Smoke)) +
labs(title = "Relationship of LungCap and Smoke based on age", y = "Lung Capacity", x = "Age")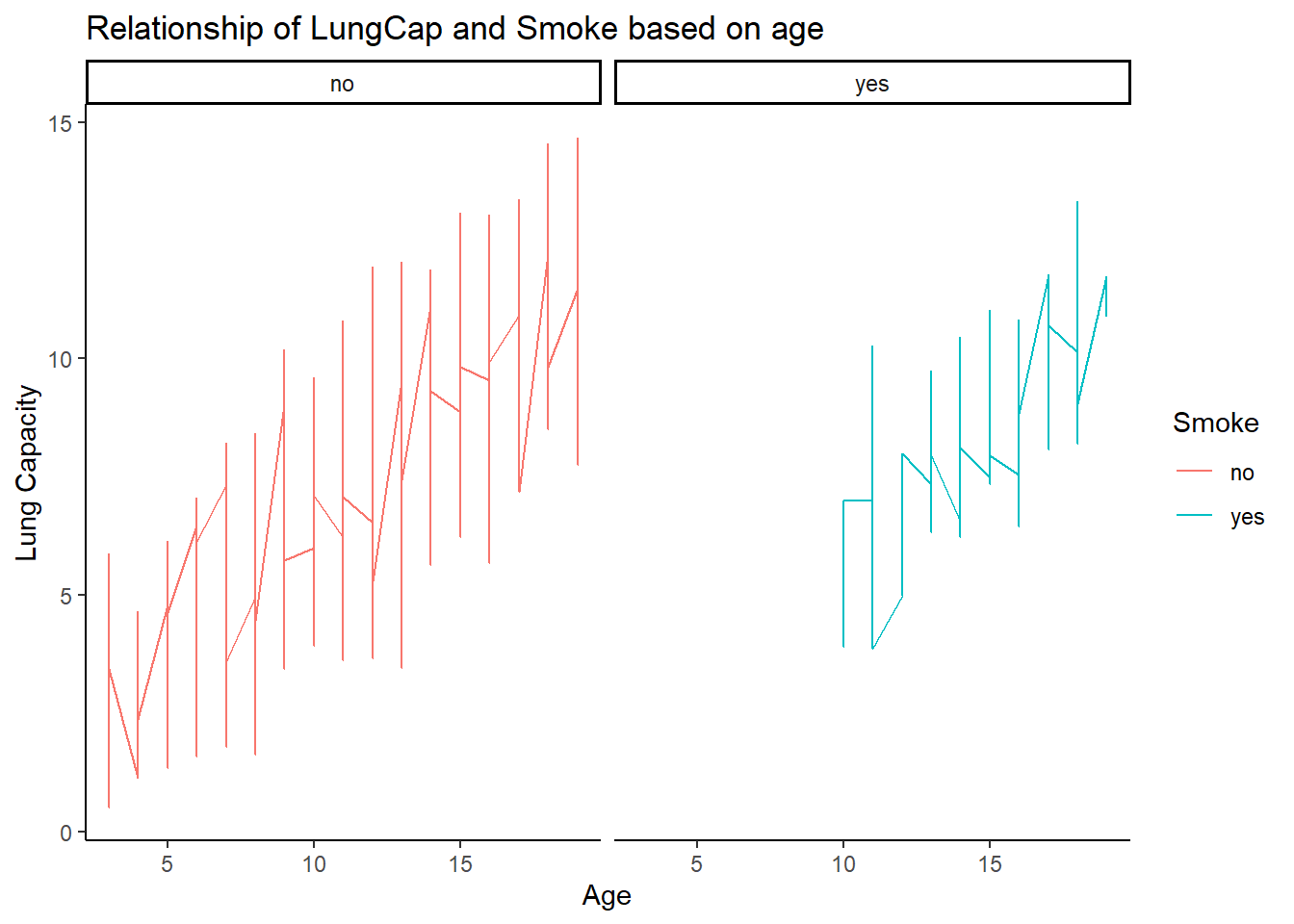
Comparing 1_D and 1_E we can find similarity which points that only 10 and above age group smoke.
Calculating the correlation and covariance between Lung Capacity and Age:
Covariance <- cov(lung$LungCap, lung$Age)
Correlation <- cor(lung$LungCap, lung$Age)
Covariance[1] 8.738289Correlation[1] 0.8196749The comparison shows that the covariance is positive, indicating that lung capacity and age have a direct relationship. As a result, they are moving in the same direction due to the positive correlation as well. This means that as age increases, lung capacity increases as well, which means they are directly proportional.
Prior_convitions <- c(0:4)
Inmate_count <- c(128, 434, 160, 64, 24)
prior <- data_frame(Prior_convitions, Inmate_count)Warning: `data_frame()` was deprecated in tibble 1.1.0.
Please use `tibble()` instead.
This warning is displayed once every 8 hours.
Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.priorprior <- mutate(prior, Probability = Inmate_count/sum(Inmate_count))
priorProbability that a randomly selected inmate has exactly 2 prior convictions:
prior %>%
filter(Prior_convitions == 2) %>%
select(Probability)Probability that a randomly selected inmate has fewer than 2 convictions:
random <- prior %>%
filter(Prior_convitions < 2)
sum(random$Probability)[1] 0.6938272Probability that a randomly selected inmate has 2 or fewer prior convictions:
random <- prior %>%
filter(Prior_convitions <= 2)
sum(random$Probability)[1] 0.891358Probability that a randomly selected inmate has more than 2 prior convictions:
random <- prior %>%
filter(Prior_convitions > 2)
sum(random$Probability)[1] 0.108642Expected value for the number of prior convictions:
prior <- mutate(prior, Wm = Prior_convitions*Probability)
ev <- sum(prior$Wm)
ev[1] 1.28642Variance for the Prior Convictions:
variance <-sum(((prior$Prior_convitions-ev)^2)*prior$Probability)
variance[1] 0.8562353standard deviation for the Prior Convictions:
sqrt(variance)[1] 0.9253298