Code
library(tidyverse)
library(ggplot2)
library(summarytools)
library(interactions)
library(lmtest)
library(sandwich)
library(stargazer)
library(gridExtra)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(ggplot2)
library(summarytools)
library(interactions)
library(lmtest)
library(sandwich)
library(stargazer)
library(gridExtra)
knitr::opts_chunk$set(echo = TRUE)Prior research literature in the social sciences has continually stressed the need for more research on the Global South. However, few papers actually focus on it. Hence, I am interested to learn more about this region.
I am specifically interested in understanding what drives perceived well-being. It is interpreted via happiness and life satisfaction, measured separately (Addai et al., 2013).
A. What predicts perceived well-being in the Global South?
B. Do predictors of perceived well-being differ between the Global North and South?
This project will be useful to better understand motivations and desires in the Global South, reduce inter-cultural tensions and enhance cross-cultural cohesion. Governments can also benefit from this research in terms of policy prioritization to maximize citizens’ well-being.
Past researchers have studied perceived well-being in the Global South via the World Values Survey (Addai et al., 2013; Ngamaba, 2016). The studies focused on Ghana and Rwanda respectively. The common predictors across both countries were satisfaction with health and income.
Alba (2019) found that happiness was generally greater in the Global North than the Global South, and indicated that future research should attempt to cover the factors behind this, which gave me the impetus for this project.
I refer to Maslow’s theory, where physical and safety needs come first (Maslow, 1943). My thinking is that happiness and well-being in the Global North may depend on more subjective measures, given that health and income-related problems should be relatively more accounted for.
Given the above, we can frame our hypotheses as follows:
Perceived health and financial satisfaction will not positively predict perceived well-being in the Global South.
Perceived health and financial satisfaction will positively predict perceived well-being in the Global South.
Perceived health and financial satisfaction will not have a greater impact on perceived well-being in the Global South than the Global North.
Perceived health and financial satisfaction will have a greater impact on perceived well-being in the Global South than the Global North.
I will be working with the most recent wave of the World Values Survey, Wave 7, which was conducted from 2017 to 2022. The data is freely available for non-profit purposes. It must be cited properly and not re-distributed (Haerpfer et al., 2022).
Representative samples of the population aged 18 and above were collected from 59 countries. Data was mostly collected by interviewing respondents at their homes (“WVS Database”, 2022).
I am using the version of Wave 7 released in May 2022.
I will indicate my comments in each code chunk to keep track of my progress.
# read in dataset.
wvs <- read_csv("~/Desktop/2022_Fall/DACSS 603/General/Final Project/WVS/4. Data/WVS_Cross-National_Wave_7_csv_v4_0.csv", show_col_types = FALSE) %>% select("B_COUNTRY_ALPHA", "G_TOWNSIZE", "H_SETTLEMENT", "H_URBRURAL", "O1_LONGITUDE", "O2_LATITUDE", "Q1", "Q2", "Q3", "Q6", "Q46", "Q47", "Q48", "Q49", "Q50", "Q57", "Q171", "Q260", "Q262", "Q263", "Q269", "Q270", "Q271", "Q273", "Q274", "Q275", "Q279", "Q287", "Q288R", "Q289", "I_WOMJOB", "I_WOMPOL", "I_WOMEDU", "Q182", "Q184")The data set originally had 552 columns. I have selected a subset of columns based on variables used in past papers, as well as some variables I am interested to examine. These include place/area of residence, demographics, importance of various social aspects, happiness and well-being indicators, trust, religiosity, equality of gender/sexual orientation and abortion attitudes.
I will first create a dummy variable for Global North/South. The Global South comprises low- and lower-middle income countries, as defined by the World Bank (Clarke, 2018; “World Bank Country and Lending Groups”, 2022). Global South countries surveyed include Ethiopia, Philippines, Indonesia, Bangladesh, Iran, Kenya, Bolivia, Kyrgyzstan, Lebanon, Tajikistan, Tunisia, Ukraine, Mongolia, Morocco, Egypt, Myanmar, Vietnam, Nicaragua, Zimbabwe, Nigeria and Pakistan.
# create dummy.
wvs <- mutate(wvs, NS = case_when(B_COUNTRY_ALPHA == "ETH" | B_COUNTRY_ALPHA == "PHL" | B_COUNTRY_ALPHA == "IDN" | B_COUNTRY_ALPHA == "BGD" | B_COUNTRY_ALPHA == "IRN" | B_COUNTRY_ALPHA == "KEN" | B_COUNTRY_ALPHA == "BOL" | B_COUNTRY_ALPHA == "KGZ" | B_COUNTRY_ALPHA == "LBN" | B_COUNTRY_ALPHA == "TJK" | B_COUNTRY_ALPHA == "TUN" | B_COUNTRY_ALPHA == "MOR" | B_COUNTRY_ALPHA == "UKR" | B_COUNTRY_ALPHA == "MNG" | B_COUNTRY_ALPHA == "EGY" | B_COUNTRY_ALPHA == "MMR" | B_COUNTRY_ALPHA == "VNM" | B_COUNTRY_ALPHA == "NIC" | B_COUNTRY_ALPHA == "ZWE" | B_COUNTRY_ALPHA == "NGA" | B_COUNTRY_ALPHA == "PAK" ~ "1"))
# replace "NA" with "O" (for Global North).
wvs$NS <- replace_na(wvs$NS, "0")
# change to factor.
wvs$NS <- as.factor(wvs$NS)
# check counts of levels.
wvs %>% select(NS) %>% summary() NS
0:59178
1:28644 # sanity check.
wvs %>% filter(B_COUNTRY_ALPHA == "ETH" | B_COUNTRY_ALPHA == "PHL" | B_COUNTRY_ALPHA == "IDN" | B_COUNTRY_ALPHA == "BGD" | B_COUNTRY_ALPHA == "IRN" | B_COUNTRY_ALPHA == "KEN" | B_COUNTRY_ALPHA == "BOL" | B_COUNTRY_ALPHA == "KGZ" | B_COUNTRY_ALPHA == "LBN" | B_COUNTRY_ALPHA == "TJK" | B_COUNTRY_ALPHA == "TUN" | B_COUNTRY_ALPHA == "MOR" | B_COUNTRY_ALPHA == "UKR" | B_COUNTRY_ALPHA == "MNG" | B_COUNTRY_ALPHA == "EGY" | B_COUNTRY_ALPHA == "MMR" | B_COUNTRY_ALPHA == "VNM" | B_COUNTRY_ALPHA == "NIC" | B_COUNTRY_ALPHA == "ZWE" | B_COUNTRY_ALPHA == "NGA" | B_COUNTRY_ALPHA == "PAK") %>% nrow()[1] 28644# rename columns.
names(wvs) <- c("B_COUNTRY_ALPHA", "G_TOWNSIZE", "H_SETTLEMENT", "H_URBRURAL", "Long", "Lat", "FamImpt", "FriendsImpt", "LeisureImpt", "ReligionImpt", "Happiness", "PerceivedHealth", "FOC", "LS", "FS", "Trust", "AttendReligious", "Sex", "Age", "Immigrant", "Citizen", "HHSize", "Parents", "Married", "Kids", "Edu", "Job", "SocialClass", "Income", "Religion", "I_WOMJOB", "I_WOMPOL", "I_WOMEDU", "homolib", "abortlib", "NS")The sanity check shows that the creation of the dummy was successful, with 28,644 data points from the Global South.
print(dfSummary(wvs, varnumbers = FALSE, plain.ascii = FALSE, graph.magnif = 0.30, style = "grid", valid.col = FALSE), method = 'render', table.classes = 'table-condensed')| Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B_COUNTRY_ALPHA [character] |
|
|
 |
0 (0.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| G_TOWNSIZE [numeric] |
|
|
 |
1274 (1.5%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| H_SETTLEMENT [numeric] |
|
|
 |
207 (0.2%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| H_URBRURAL [numeric] |
|
|
 |
32 (0.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Long [numeric] |
|
5482 distinct values |  |
27098 (30.9%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Lat [numeric] |
|
3911 distinct values |  |
27094 (30.9%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| FamImpt [numeric] |
|
|
 |
146 (0.2%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| FriendsImpt [numeric] |
|
|
 |
289 (0.3%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LeisureImpt [numeric] |
|
|
 |
473 (0.5%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ReligionImpt [numeric] |
|
|
 |
831 (0.9%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Happiness [numeric] |
|
|
 |
574 (0.7%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PerceivedHealth [numeric] |
|
|
 |
254 (0.3%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| FOC [numeric] |
|
|
 |
800 (0.9%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LS [numeric] |
|
|
 |
393 (0.4%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| FS [numeric] |
|
|
 |
545 (0.6%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Trust [numeric] |
|
|
 |
1198 (1.4%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AttendReligious [numeric] |
|
|
 |
1034 (1.2%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sex [numeric] |
|
|
 |
62 (0.1%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Age [numeric] |
|
85 distinct values |  |
339 (0.4%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Immigrant [numeric] |
|
|
 |
344 (0.4%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Citizen [numeric] |
|
|
 |
5164 (5.9%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HHSize [numeric] |
|
33 distinct values |  |
852 (1.0%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Parents [numeric] |
|
|
 |
1438 (1.6%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Married [numeric] |
|
|
 |
504 (0.6%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Kids [numeric] |
|
23 distinct values |  |
1201 (1.4%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Edu [numeric] |
|
|
 |
818 (0.9%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Job [numeric] |
|
|
 |
1143 (1.3%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SocialClass [numeric] |
|
|
 |
2302 (2.6%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Income [numeric] |
|
|
 |
2330 (2.7%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Religion [numeric] |
|
|
 |
2485 (2.8%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I_WOMJOB [numeric] |
|
5 distinct values |  |
648 (0.7%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I_WOMPOL [numeric] |
|
4 distinct values |  |
2222 (2.5%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I_WOMEDU [numeric] |
|
4 distinct values |  |
1250 (1.4%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| homolib [numeric] |
|
|
 |
5691 (6.5%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| abortlib [numeric] |
|
|
 |
1979 (2.3%) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| NS [factor] |
|
|
 |
0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.2)
2022-12-17
The dataset has 87,822 rows, each representing one participant, and 36 columns.
The summary statistics for the predictors and outcomes of interest are as follows:
66.2% perceived their health to be good (option 1 ‘Very Good’ and option 2 ‘Good’ for PerceivedHealth).
61.6% were satisfied with their household’s finances (option 6 to 10 for FS, where 10 is ‘satisfied’).
85.5% were happy (option 1 ‘Very Happy’ and option 2 ‘Quite Happy’ for Happiness).
75.5% were satisfied with their lives (options 6 to 10 for LS, where 10 is ‘satisfied’).
67.4% of respondents were from the Global North (NS).
Other noteworthy descriptives:
Respondents tended to come from more urban settings (H_URBRURAL).
On average, family was more likely to be perceived as important than friends, leisure time and religion (FamImpt, FriendsImpt, LeisureImpt, ReligionImpt).
People tended to err on the side of caution when it came to trusting others (Trust).
Households had 4 people on average, with maximum household size being 63 (HHSize)!
For the survey variables (FamImpt to abortlib), missing data ranged from 0.1% to 6.5%, which is acceptable.
Let’s check if life satisfaction and happiness differ between the Global North and South.
t.test(Happiness ~ NS, wvs)
Welch Two Sample t-test
data: Happiness by NS
t = 4.1272, df = 49878, p-value = 3.677e-05
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
0.01164249 0.03270103
sample estimates:
mean in group 0 mean in group 1
1.863945 1.841774 t.test(LS ~ NS, wvs)
Welch Two Sample t-test
data: LS by NS
t = 13.283, df = 47990, p-value < 2.2e-16
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
0.1962795 0.2642322
sample estimates:
mean in group 0 mean in group 1
7.117885 6.887629 The Welch’s two-sample t-tests show that there is a significant difference in happiness and life satisfaction between the Global North and South, where the former has higher mean values for both, p < .001. This echoes Alba (2019)’s finding on happiness, and adds new knowledge to the literature regarding life satisfaction.
We can also create a graph to visualize the latitude and longitude of countries in the Global North and Global South.
ggplot(wvs) + geom_bin2d(mapping = aes(x = Long, y = Lat)) + facet_wrap(vars(NS))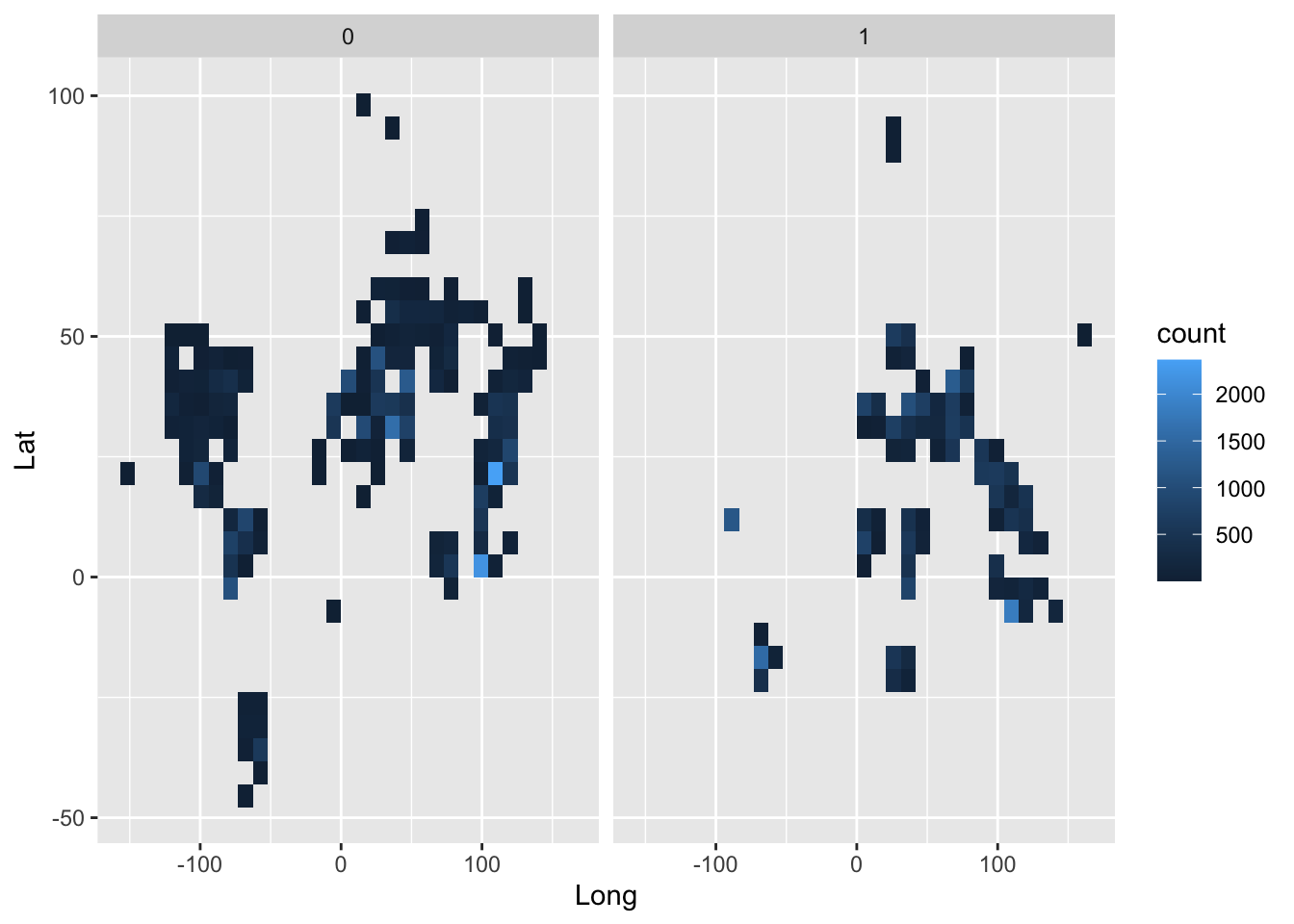
The graph above shows that the Global North (“0”) and South (“1”) are not neatly divided by physical location, due to the existence of higher-income countries physically located in the South (e.g., South Korea) and lower-income countries physically located in the North (e.g., Ukraine).
NS cannot be transformed, since it is categorical. If required, log/quadratic transformations can be done for PerceivedHealth or FS.
Since each row represents 1 participant, the unit of analysis is at the participant level. The NS dummy refers to where the participant comes from, either the Global North or the Global South.
I will be treating FamImpt, FriendsImpt, LeisureImpt, ReligionImpt and Happiness as continuous. I will check that this is appropriate by running two regression models with FamImpt as categorical vs. continuous (see sections on RQ B).
I will complete cleaning the data set (changing some variables to factors and reverse coding others) below, before commencing analysis.
# change the following variables to factor type.
wvs <- wvs %>% mutate(across(c(B_COUNTRY_ALPHA,H_SETTLEMENT,H_URBRURAL,Trust,Sex,Immigrant,Citizen,Parents,Married,Job,Religion), as.factor))
# reverse code the following variables, such that the largest number reflects agreement.
wvs$FamImpt <- 5-wvs$FamImpt
wvs$FriendsImpt <- 5-wvs$FriendsImpt
wvs$LeisureImpt <- 5-wvs$LeisureImpt
wvs$ReligionImpt <- 5-wvs$ReligionImpt
wvs$Happiness <- 5-wvs$Happiness
wvs$PerceivedHealth <- 6-wvs$PerceivedHealth
wvs$AttendReligious <-8-wvs$AttendReligious
wvs$SocialClass <- 6-wvs$SocialClassPerceived health and financial satisfaction will positively predict perceived well-being in the Global South.
To test this hypothesis, I will:
Filter the dataset to only include observations from the Global South.
Create plots of perceived health and financial satisfaction against happiness and life satisfaction.
Run a regression model with these variables. Previous papers did not test an interaction between the variables, so I will not do so. There also does not seem to be a meaningful theoretical reason to do so.
# create subset of dataset.
subset <- wvs %>% filter(NS == "1")
# generate boxplots.
b1 <- subset %>% filter(!is.na(PerceivedHealth)) %>%
ggplot(aes(x=as.factor(PerceivedHealth), y=LS)) +
geom_boxplot(varwidth=TRUE,color="chocolate2", fill="bisque",alpha=0.5) +
theme_minimal() +
xlab("PH (Global South)") +
ylab("Life Satisfaction (Global South)") +
theme(text=element_text(family="serif", size=12))
b2 <- subset %>% filter(!is.na(FS)) %>%
ggplot(aes(x=as.factor(FS), y=LS)) +
geom_boxplot(varwidth=TRUE,color="chocolate2", fill="bisque",alpha=0.5) +
theme_minimal() +
xlab("FS (Global South)") +
ylab("Life Satisfaction (Global South)") +
theme(text=element_text(family="serif", size=12))
b3 <- subset %>% filter(!is.na(PerceivedHealth)) %>%
ggplot(aes(x=as.factor(PerceivedHealth), y=Happiness)) +
geom_boxplot(varwidth=TRUE,color="chocolate2", fill="bisque",alpha=0.5) +
theme_minimal() +
xlab("PH (Global South)") +
ylab("Happiness (Global South)") +
theme(text=element_text(family="serif", size=12))
b4 <- subset %>% filter(!is.na(FS)) %>%
ggplot(aes(x=as.factor(FS), y=Happiness)) +
geom_boxplot(varwidth=TRUE,color="chocolate2", fill="bisque",alpha=0.5) +
theme_minimal() +
xlab("FS (Global South)") +
ylab("Happiness (Global South)") +
theme(text=element_text(family="serif", size=12))
grid.arrange(b1, b2, b3, b4, nrow = 2, ncol = 2)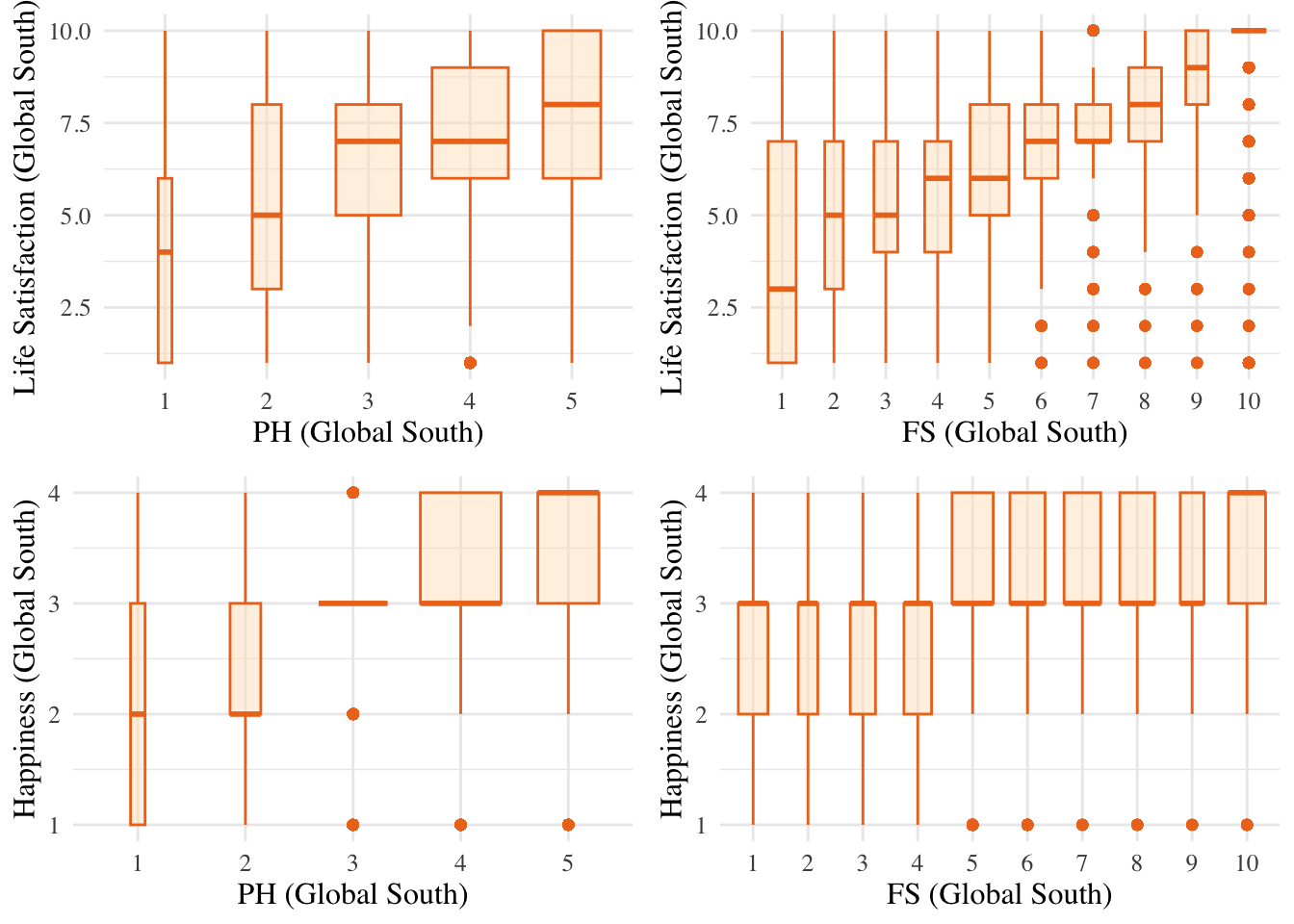
Looking at the boxplots, there seems to be a roughly linear positive relationship between all 4 variables. No transformations should be required to run the regression models.
# run regression model for Happiness.
ModelA_H <- lm(Happiness ~ PerceivedHealth + FS, subset)
# run regression model for Happiness with demographic controls.
ModelA_H_controls <- lm(Happiness ~ PerceivedHealth + FS + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion, subset)
# run regression model for LS. for whatever reason, logging PerceivedHealth produced a slightly higher adjusted R^2, but i did not include that because (1) it did not improve the diagnostic plots and (2) PerceivedHealth is not count data (e.g., population/income) that traditionally improves with logging.
ModelA_LS <- lm(LS ~ PerceivedHealth + FS, subset)
# run regression model for LS with demographic controls.
ModelA_LS_controls <- lm(LS ~ PerceivedHealth + FS + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion, subset)
# create comparison table.
stargazer(ModelA_H, ModelA_H_controls, type = "text")
============================================================================
Dependent variable:
--------------------------------------------------------
Happiness
(1) (2)
----------------------------------------------------------------------------
PerceivedHealth 0.263*** 0.261***
(0.005) (0.005)
FS 0.077*** 0.075***
(0.002) (0.002)
Sex2 0.081***
(0.010)
Age -0.00004
(0.0004)
Immigrant2 0.053
(0.058)
Citizen2 -0.084
(0.086)
HHSize 0.007***
(0.002)
Parents2 0.006
(0.013)
Parents3 0.025
(0.019)
Parents4 -0.072
(0.057)
Married2 -0.023
(0.019)
Married3 -0.188***
(0.030)
Married4 -0.199***
(0.035)
Married5 -0.106***
(0.021)
Married6 -0.071***
(0.015)
Kids 0.004
(0.003)
Edu -0.014***
(0.002)
Job2 -0.003
(0.016)
Job3 -0.019
(0.012)
Job4 0.030
(0.022)
Job5 -0.085***
(0.015)
Job6 -0.022
(0.021)
Job7 -0.058***
(0.016)
Job8 -0.037
(0.043)
SocialClass 0.032***
(0.005)
Income 0.006
(0.008)
Religion1 0.070***
(0.017)
Religion2 0.076***
(0.021)
Religion3 -0.018
(0.023)
Religion4 -0.158*
(0.084)
Religion5 0.013
(0.015)
Religion6 -0.033
(0.047)
Religion7 -0.012
(0.021)
Religion8 0.110***
(0.026)
Religion9 0.037
(0.040)
Constant 1.702*** 1.623***
(0.018) (0.036)
----------------------------------------------------------------------------
Observations 28,502 26,943
R2 0.202 0.212
Adjusted R2 0.202 0.211
Residual Std. Error 0.694 (df = 28499) 0.690 (df = 26907)
F Statistic 3,617.923*** (df = 2; 28499) 206.551*** (df = 35; 26907)
============================================================================
Note: *p<0.1; **p<0.05; ***p<0.01stargazer(ModelA_LS, ModelA_LS_controls, type = "text")
============================================================================
Dependent variable:
--------------------------------------------------------
LS
(1) (2)
----------------------------------------------------------------------------
PerceivedHealth 0.339*** 0.375***
(0.014) (0.015)
FS 0.516*** 0.501***
(0.005) (0.005)
Sex2 0.111***
(0.029)
Age 0.005***
(0.001)
Immigrant2 0.025
(0.173)
Citizen2 0.010
(0.257)
HHSize -0.004
(0.006)
Parents2 0.138***
(0.038)
Parents3 0.128**
(0.056)
Parents4 -0.179
(0.169)
Married2 0.039
(0.057)
Married3 -0.283***
(0.088)
Married4 -0.364***
(0.105)
Married5 -0.138**
(0.063)
Married6 -0.235***
(0.044)
Kids 0.004
(0.009)
Edu -0.010
(0.007)
Job2 0.125**
(0.049)
Job3 -0.062*
(0.037)
Job4 -0.043
(0.066)
Job5 -0.108**
(0.045)
Job6 -0.098
(0.062)
Job7 -0.220***
(0.048)
Job8 0.375***
(0.129)
SocialClass 0.003
(0.014)
Income 0.085***
(0.024)
Religion1 0.153***
(0.052)
Religion2 -0.324***
(0.062)
Religion3 -0.406***
(0.067)
Religion4 -0.217
(0.251)
Religion5 -0.038
(0.046)
Religion6 0.238*
(0.139)
Religion7 0.022
(0.062)
Religion8 0.397***
(0.076)
Religion9 0.442***
(0.120)
Constant 2.515*** 2.194***
(0.055) (0.106)
----------------------------------------------------------------------------
Observations 28,512 26,952
R2 0.340 0.348
Adjusted R2 0.340 0.347
Residual Std. Error 2.064 (df = 28509) 2.052 (df = 26916)
F Statistic 7,329.341*** (df = 2; 28509) 409.604*** (df = 35; 26916)
============================================================================
Note: *p<0.1; **p<0.05; ***p<0.01To summarize, I ran 4 regression models above. For Happiness, I ran 1 model with just the main predictors (FS and PerceivedHealth), and 1 with demographic controls as well. I then repeated this process for LS. In all 4 models, even with the addition of demographic control variables, PerceivedHealth and FS positively predict Happiness and LS in the Global South, p < .01. The addition of demographic controls also did not improve adjusted R2 by much, just ~0.01. For RQ A, we can reject the null hypothesis.
# diagnostic plots for the models above.
par(mfrow = c(2,3)); plot(ModelA_H_controls, which = 1:6)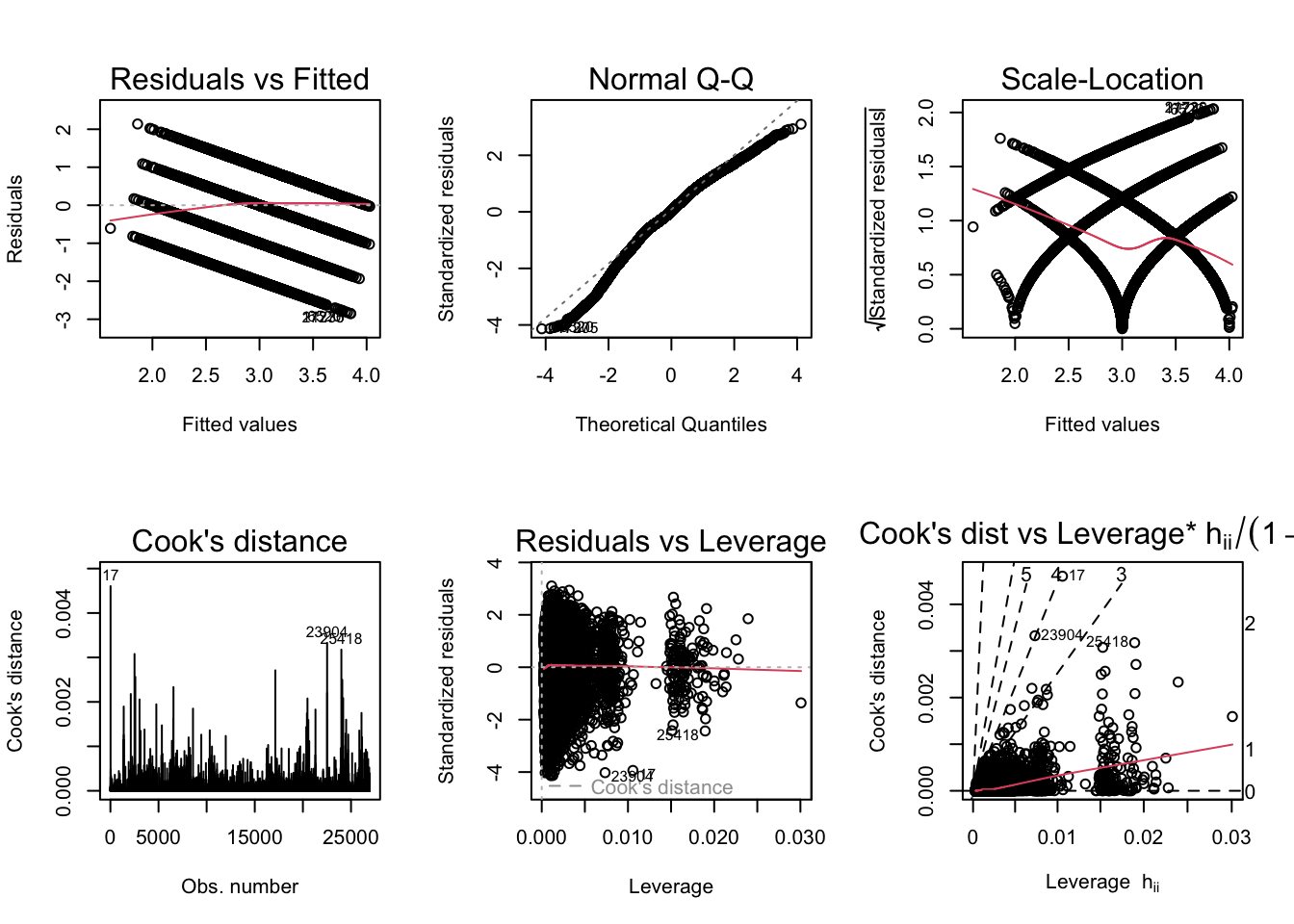
bptest(ModelA_H_controls)
studentized Breusch-Pagan test
data: ModelA_H_controls
BP = 1109.2, df = 35, p-value < 2.2e-16par(mfrow = c(2,3)); plot(ModelA_LS_controls, which = 1:6)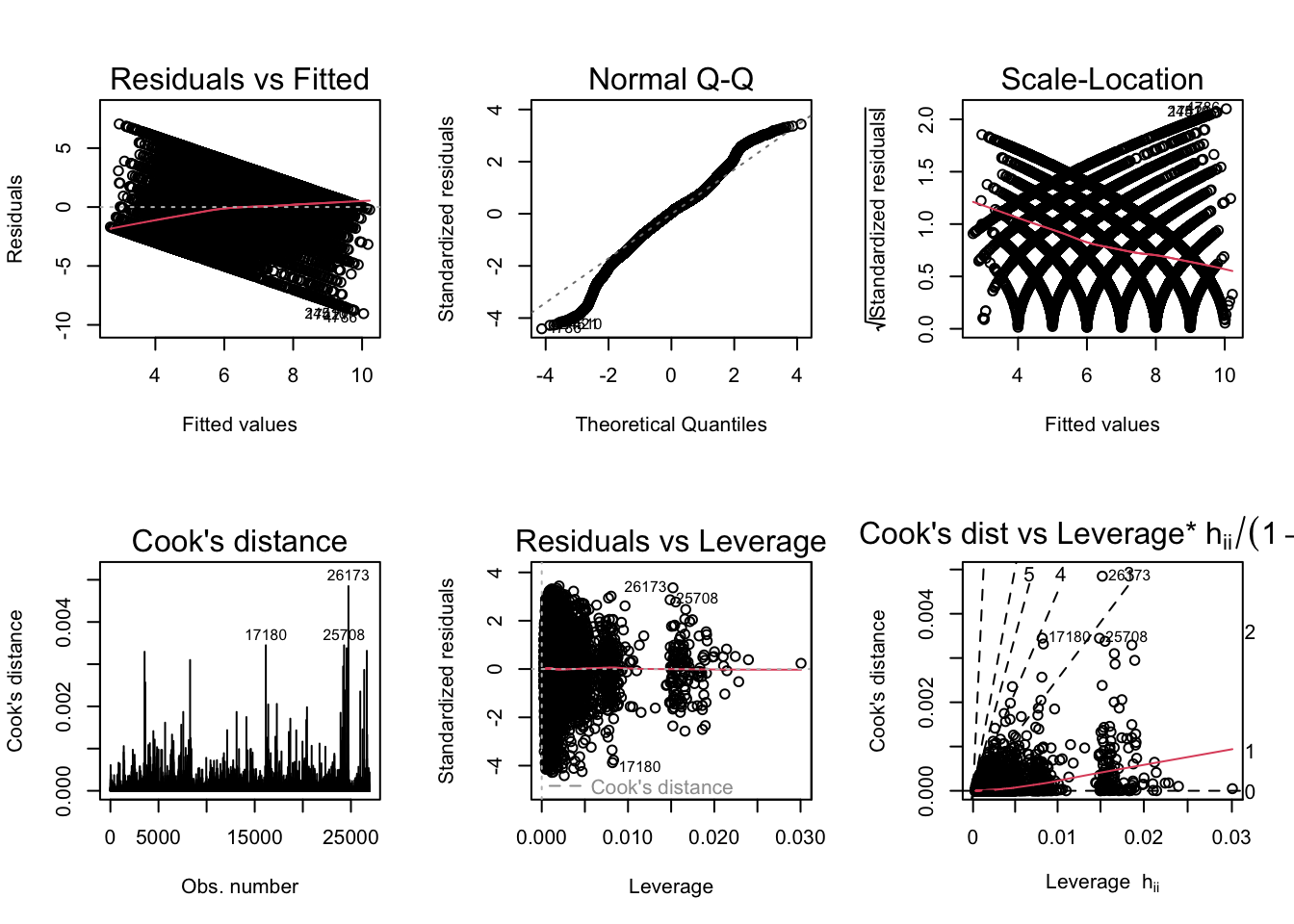
bptest(ModelA_LS_controls)
studentized Breusch-Pagan test
data: ModelA_LS_controls
BP = 1721.9, df = 35, p-value < 2.2e-16The diagnostic plots generally seem fine except the scale-location plot, which indicates heteroskedasticity. The Breusch-Pagan test helps to confirm this. One way to correct this would be to use robust standard errors.
# generate model with robust standard errors, and put it side by side with the original model.
covah <- vcovHC(ModelA_H_controls, type = "HC1")
robustah <- sqrt(diag(covah))
stargazer(ModelA_H_controls, ModelA_H_controls, type = "text", se = list(NULL, robustah))
=============================================================
Dependent variable:
----------------------------
Happiness
(1) (2)
-------------------------------------------------------------
PerceivedHealth 0.261*** 0.261***
(0.005) (0.006)
FS 0.075*** 0.075***
(0.002) (0.002)
Sex2 0.081*** 0.081***
(0.010) (0.010)
Age -0.00004 -0.00004
(0.0004) (0.0004)
Immigrant2 0.053 0.053
(0.058) (0.058)
Citizen2 -0.084 -0.084
(0.086) (0.081)
HHSize 0.007*** 0.007***
(0.002) (0.002)
Parents2 0.006 0.006
(0.013) (0.013)
Parents3 0.025 0.025
(0.019) (0.018)
Parents4 -0.072 -0.072
(0.057) (0.062)
Married2 -0.023 -0.023
(0.019) (0.020)
Married3 -0.188*** -0.188***
(0.030) (0.032)
Married4 -0.199*** -0.199***
(0.035) (0.042)
Married5 -0.106*** -0.106***
(0.021) (0.022)
Married6 -0.071*** -0.071***
(0.015) (0.015)
Kids 0.004 0.004
(0.003) (0.003)
Edu -0.014*** -0.014***
(0.002) (0.002)
Job2 -0.003 -0.003
(0.016) (0.016)
Job3 -0.019 -0.019
(0.012) (0.012)
Job4 0.030 0.030
(0.022) (0.022)
Job5 -0.085*** -0.085***
(0.015) (0.015)
Job6 -0.022 -0.022
(0.021) (0.021)
Job7 -0.058*** -0.058***
(0.016) (0.017)
Job8 -0.037 -0.037
(0.043) (0.050)
SocialClass 0.032*** 0.032***
(0.005) (0.005)
Income 0.006 0.006
(0.008) (0.008)
Religion1 0.070*** 0.070***
(0.017) (0.018)
Religion2 0.076*** 0.076***
(0.021) (0.023)
Religion3 -0.018 -0.018
(0.023) (0.022)
Religion4 -0.158* -0.158*
(0.084) (0.088)
Religion5 0.013 0.013
(0.015) (0.015)
Religion6 -0.033 -0.033
(0.047) (0.038)
Religion7 -0.012 -0.012
(0.021) (0.021)
Religion8 0.110*** 0.110***
(0.026) (0.026)
Religion9 0.037 0.037
(0.040) (0.043)
Constant 1.623*** 1.623***
(0.036) (0.038)
-------------------------------------------------------------
Observations 26,943 26,943
R2 0.212 0.212
Adjusted R2 0.211 0.211
Residual Std. Error (df = 26907) 0.690 0.690
F Statistic (df = 35; 26907) 206.551*** 206.551***
=============================================================
Note: *p<0.1; **p<0.05; ***p<0.01# do the same for the model with life satisfaction as the dv.
covals <- vcovHC(ModelA_LS_controls, type = "HC1")
robustals <- sqrt(diag(covals))
stargazer(ModelA_LS_controls, ModelA_LS_controls, type = "text", se = list(NULL, robustals))
=============================================================
Dependent variable:
----------------------------
LS
(1) (2)
-------------------------------------------------------------
PerceivedHealth 0.375*** 0.375***
(0.015) (0.016)
FS 0.501*** 0.501***
(0.005) (0.006)
Sex2 0.111*** 0.111***
(0.029) (0.029)
Age 0.005*** 0.005***
(0.001) (0.001)
Immigrant2 0.025 0.025
(0.173) (0.178)
Citizen2 0.010 0.010
(0.257) (0.274)
HHSize -0.004 -0.004
(0.006) (0.007)
Parents2 0.138*** 0.138***
(0.038) (0.039)
Parents3 0.128** 0.128**
(0.056) (0.056)
Parents4 -0.179 -0.179
(0.169) (0.160)
Married2 0.039 0.039
(0.057) (0.059)
Married3 -0.283*** -0.283***
(0.088) (0.098)
Married4 -0.364*** -0.364***
(0.105) (0.114)
Married5 -0.138** -0.138**
(0.063) (0.065)
Married6 -0.235*** -0.235***
(0.044) (0.045)
Kids 0.004 0.004
(0.009) (0.010)
Edu -0.010 -0.010
(0.007) (0.007)
Job2 0.125** 0.125***
(0.049) (0.048)
Job3 -0.062* -0.062*
(0.037) (0.036)
Job4 -0.043 -0.043
(0.066) (0.065)
Job5 -0.108** -0.108**
(0.045) (0.044)
Job6 -0.098 -0.098*
(0.062) (0.059)
Job7 -0.220*** -0.220***
(0.048) (0.051)
Job8 0.375*** 0.375**
(0.129) (0.147)
SocialClass 0.003 0.003
(0.014) (0.015)
Income 0.085*** 0.085***
(0.024) (0.026)
Religion1 0.153*** 0.153***
(0.052) (0.050)
Religion2 -0.324*** -0.324***
(0.062) (0.065)
Religion3 -0.406*** -0.406***
(0.067) (0.066)
Religion4 -0.217 -0.217
(0.251) (0.286)
Religion5 -0.038 -0.038
(0.046) (0.041)
Religion6 0.238* 0.238**
(0.139) (0.111)
Religion7 0.022 0.022
(0.062) (0.058)
Religion8 0.397*** 0.397***
(0.076) (0.074)
Religion9 0.442*** 0.442***
(0.120) (0.104)
Constant 2.194*** 2.194***
(0.106) (0.110)
-------------------------------------------------------------
Observations 26,952 26,952
R2 0.348 0.348
Adjusted R2 0.347 0.347
Residual Std. Error (df = 26916) 2.052 2.052
F Statistic (df = 35; 26916) 409.604*** 409.604***
=============================================================
Note: *p<0.1; **p<0.05; ***p<0.01# create PRESS function.
PRESS <- function(linear.model) {
pr <- residuals(linear.model)/(1-lm.influence(linear.model)$hat)
PRESS <- sum(pr^2)
return(PRESS)
}
# calculate PRESS.
PRESS(ModelA_H)[1] 13746.01PRESS(ModelA_H_controls)[1] 12845.62PRESS(ModelA_LS)[1] 121514.4PRESS(ModelA_LS_controls)[1] 113701.3I generated robust standard errors for the models above, where both predictors are still positive and significant, p < .01. Hence, we can still reject the null hypothesis.
I also generated the PRESS statistic to demonstrate that if we had to choose, the models with controls would be better, due to the lower PRESS statistic.
Perceived health and financial satisfaction will have a greater impact on perceived well-being in the Global South than the Global North.
I will first run a correlation matrix with all potential numeric variables that might be relevant.
# run correlations for numeric variables (except DVs, which are Happiness and LS).
matrix <- wvs %>% select(PerceivedHealth, FS, G_TOWNSIZE, FamImpt, FriendsImpt, LeisureImpt, ReligionImpt, FOC, AttendReligious, Age, HHSize, Kids, Edu, SocialClass, Income, I_WOMJOB, I_WOMPOL, I_WOMEDU, homolib, abortlib)
corr <- cor(matrix, use="complete.obs")In the correlation matrix, I am concerned about correlations where r ≥ 0.5 (more conservative than a cut-off of r ≥ 0.7). This is observed between AttendReligious and ReligionImpt; and homolib and abortlib. I will try a few different models to figure out which combination of variables might work best.
I will also be testing two interactions - PerceivedHealth * NS and FS * NS. I am not testing a three-way interaction, as there is no meaningful reason why PerceivedHealth and FS would interact (as discussed for RQ A).
# try model with "AttendReligious" and "abortlib".
testb1 <- lm(Happiness ~ PerceivedHealth*NS + FS*NS + G_TOWNSIZE + H_URBRURAL + FamImpt + FriendsImpt + LeisureImpt + AttendReligious + FOC + Trust + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion + I_WOMJOB + I_WOMPOL + I_WOMEDU + abortlib, wvs)
# try model with "ReligionImpt" and "abortlib".
ModelB_H <- lm(Happiness ~ PerceivedHealth*NS + FS*NS + G_TOWNSIZE + H_URBRURAL + FamImpt + FriendsImpt + LeisureImpt + ReligionImpt + FOC + Trust + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion + I_WOMJOB + I_WOMPOL + I_WOMEDU + abortlib, wvs)
# run model with "FamImpt" as categorical.
testb2 <- lm(Happiness ~ PerceivedHealth*NS + FS*NS + G_TOWNSIZE + H_URBRURAL + as.factor(FamImpt) + FriendsImpt + LeisureImpt + ReligionImpt + FOC + Trust + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion + I_WOMJOB + I_WOMPOL + I_WOMEDU + abortlib, wvs)
# try model with "ReligionImpt" and "homolib": adjusted R^2 was lower, so i'm sticking to ModelB_H. significance of main predictors doesn't change either.
testb3 <- lm(Happiness ~ PerceivedHealth*NS + FS*NS + G_TOWNSIZE + H_URBRURAL + FamImpt + FriendsImpt + LeisureImpt + ReligionImpt + FOC + Trust + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion + I_WOMJOB + I_WOMPOL + I_WOMEDU + homolib, wvs)
# put in table.
stargazer(testb1, ModelB_H, testb2, testb3, type = "text")
===================================================================================================================================
Dependent variable:
---------------------------------------------------------------------------------------------------------------
Happiness
(1) (2) (3) (4)
-----------------------------------------------------------------------------------------------------------------------------------
PerceivedHealth 0.217*** 0.218*** 0.218*** 0.216***
(0.004) (0.004) (0.004) (0.004)
NS1 -0.138*** -0.144*** -0.144*** -0.134***
(0.023) (0.023) (0.023) (0.024)
FS 0.059*** 0.059*** 0.059*** 0.060***
(0.001) (0.001) (0.001) (0.001)
G_TOWNSIZE -0.011*** -0.010*** -0.010*** -0.007***
(0.001) (0.001) (0.001) (0.001)
H_URBRURAL2 0.039*** 0.040*** 0.040*** 0.044***
(0.007) (0.007) (0.007) (0.007)
FamImpt 0.120*** 0.113*** 0.117***
(0.007) (0.007) (0.007)
as.factor(FamImpt)2 0.064
(0.060)
as.factor(FamImpt)3 0.205***
(0.055)
as.factor(FamImpt)4 0.315***
(0.055)
FriendsImpt 0.025*** 0.024*** 0.024*** 0.022***
(0.003) (0.003) (0.003) (0.003)
LeisureImpt 0.024*** 0.022*** 0.022*** 0.020***
(0.003) (0.003) (0.003) (0.003)
AttendReligious 0.008***
(0.001)
ReligionImpt 0.036*** 0.036*** 0.045***
(0.003) (0.003) (0.003)
FOC 0.032*** 0.032*** 0.032*** 0.032***
(0.001) (0.001) (0.001) (0.001)
Trust2 -0.024*** -0.029*** -0.029*** -0.019***
(0.006) (0.006) (0.006) (0.006)
Sex2 0.045*** 0.041*** 0.041*** 0.036***
(0.005) (0.005) (0.005) (0.005)
Age -0.0003 -0.0003 -0.0003 -0.001***
(0.0002) (0.0002) (0.0002) (0.0002)
Immigrant2 0.005 0.007 0.007 0.008
(0.012) (0.012) (0.012) (0.012)
Citizen2 0.035* 0.039* 0.039* 0.039**
(0.020) (0.020) (0.020) (0.020)
HHSize 0.005*** 0.005*** 0.005*** 0.003*
(0.001) (0.001) (0.001) (0.001)
Parents2 -0.008 -0.009 -0.009 -0.006
(0.007) (0.007) (0.007) (0.008)
Parents3 0.027** 0.021* 0.021* 0.030**
(0.012) (0.012) (0.012) (0.012)
Parents4 -0.024 -0.030 -0.029 -0.027
(0.032) (0.031) (0.031) (0.032)
Married2 0.040*** 0.040*** 0.040*** 0.035***
(0.009) (0.009) (0.009) (0.009)
Married3 -0.108*** -0.114*** -0.114*** -0.109***
(0.013) (0.013) (0.013) (0.013)
Married4 -0.076*** -0.080*** -0.080*** -0.077***
(0.017) (0.017) (0.017) (0.017)
Married5 -0.068*** -0.069*** -0.069*** -0.072***
(0.012) (0.012) (0.012) (0.012)
Married6 -0.047*** -0.049*** -0.049*** -0.054***
(0.008) (0.008) (0.008) (0.008)
Kids 0.010*** 0.010*** 0.010*** 0.010***
(0.002) (0.002) (0.002) (0.002)
Edu -0.005*** -0.004*** -0.004*** -0.006***
(0.001) (0.001) (0.001) (0.001)
Job2 0.032*** 0.030*** 0.030*** 0.039***
(0.009) (0.009) (0.009) (0.010)
Job3 0.007 0.006 0.006 0.013*
(0.008) (0.008) (0.008) (0.008)
Job4 0.039*** 0.036*** 0.036*** 0.036***
(0.010) (0.010) (0.010) (0.010)
Job5 0.032*** 0.027*** 0.027*** 0.035***
(0.009) (0.009) (0.009) (0.009)
Job6 0.024** 0.025** 0.025** 0.024**
(0.012) (0.012) (0.012) (0.012)
Job7 -0.010 -0.014 -0.014 -0.025**
(0.010) (0.010) (0.010) (0.010)
Job8 0.034 0.026 0.026 0.029
(0.024) (0.024) (0.024) (0.025)
SocialClass 0.032*** 0.033*** 0.033*** 0.030***
(0.003) (0.003) (0.003) (0.003)
Income 0.008 0.007 0.007 0.008
(0.005) (0.005) (0.005) (0.005)
Religion1 0.051*** 0.035*** 0.035*** 0.038***
(0.008) (0.008) (0.008) (0.009)
Religion2 0.006 -0.013 -0.013 -0.014
(0.011) (0.011) (0.011) (0.011)
Religion3 -0.072*** -0.094*** -0.094*** -0.095***
(0.011) (0.011) (0.011) (0.011)
Religion4 -0.120*** -0.139*** -0.139*** -0.144***
(0.046) (0.046) (0.046) (0.046)
Religion5 -0.083*** -0.112*** -0.112*** -0.115***
(0.008) (0.009) (0.009) (0.009)
Religion6 -0.057* -0.080*** -0.080*** -0.080***
(0.029) (0.029) (0.029) (0.029)
Religion7 -0.030*** -0.046*** -0.046*** -0.042***
(0.011) (0.011) (0.011) (0.011)
Religion8 0.061*** 0.041*** 0.041*** 0.045***
(0.015) (0.015) (0.015) (0.016)
Religion9 0.027* 0.013 0.013 0.019
(0.016) (0.016) (0.016) (0.016)
I_WOMJOB 0.018* 0.020** 0.020** 0.007
(0.009) (0.009) (0.009) (0.009)
I_WOMPOL -0.008 -0.007 -0.007 -0.012
(0.009) (0.009) (0.009) (0.010)
I_WOMEDU -0.074*** -0.073*** -0.073*** -0.069***
(0.009) (0.009) (0.009) (0.010)
abortlib -0.009*** -0.008*** -0.008***
(0.001) (0.001) (0.001)
homolib 0.0002
(0.001)
PerceivedHealth:NS1 0.027*** 0.027*** 0.027*** 0.031***
(0.006) (0.006) (0.006) (0.006)
NS1:FS 0.009*** 0.009*** 0.009*** 0.005**
(0.002) (0.002) (0.002) (0.002)
Constant 1.089*** 1.053*** 1.190*** 1.019***
(0.038) (0.038) (0.061) (0.039)
-----------------------------------------------------------------------------------------------------------------------------------
Observations 68,445 68,570 68,570 65,381
R2 0.233 0.235 0.235 0.230
Adjusted R2 0.233 0.234 0.234 0.229
Residual Std. Error 0.623 (df = 68394) 0.623 (df = 68519) 0.623 (df = 68517) 0.623 (df = 65330)
F Statistic 416.261*** (df = 50; 68394) 420.745*** (df = 50; 68519) 404.583*** (df = 52; 68517) 389.864*** (df = 50; 65330)
===================================================================================================================================
Note: *p<0.1; **p<0.05; ***p<0.01Looking at adjusted R2 and the F-statistic, ReligionImpt is preferable to AttendReligious, and abortlib is preferable to homolib.
I also ran another model to see how things change when FamImpt is treated as categorical: adjusted R2 remained the same, but the standard errors for that variable rose. Hence, I will treat it as continuous (as well as the other ordered variables with 4 levels).
Additionally, in past papers, adjusted R2 ranged between 0.15 to 0.3 for happiness. Ours is in the higher part of that range (adjusted R2 = 0.23).
For the final model I settled on (labelled ModelB_H above), both two-way interactions were significant, p < .01. I will plot this graphically.
h1 <- interact_plot(ModelB_H, pred = PerceivedHealth, modx = NS, colors=c("darkorange1","darkorange4"), x.label = "PH", modx.labels=c("North", "South"))
h2 <- interact_plot(ModelB_H, pred = FS, modx = NS, colors=c("darkorange1","darkorange4"), x.label = "FS", modx.labels=c("North","South"))
grid.arrange(h1, h2)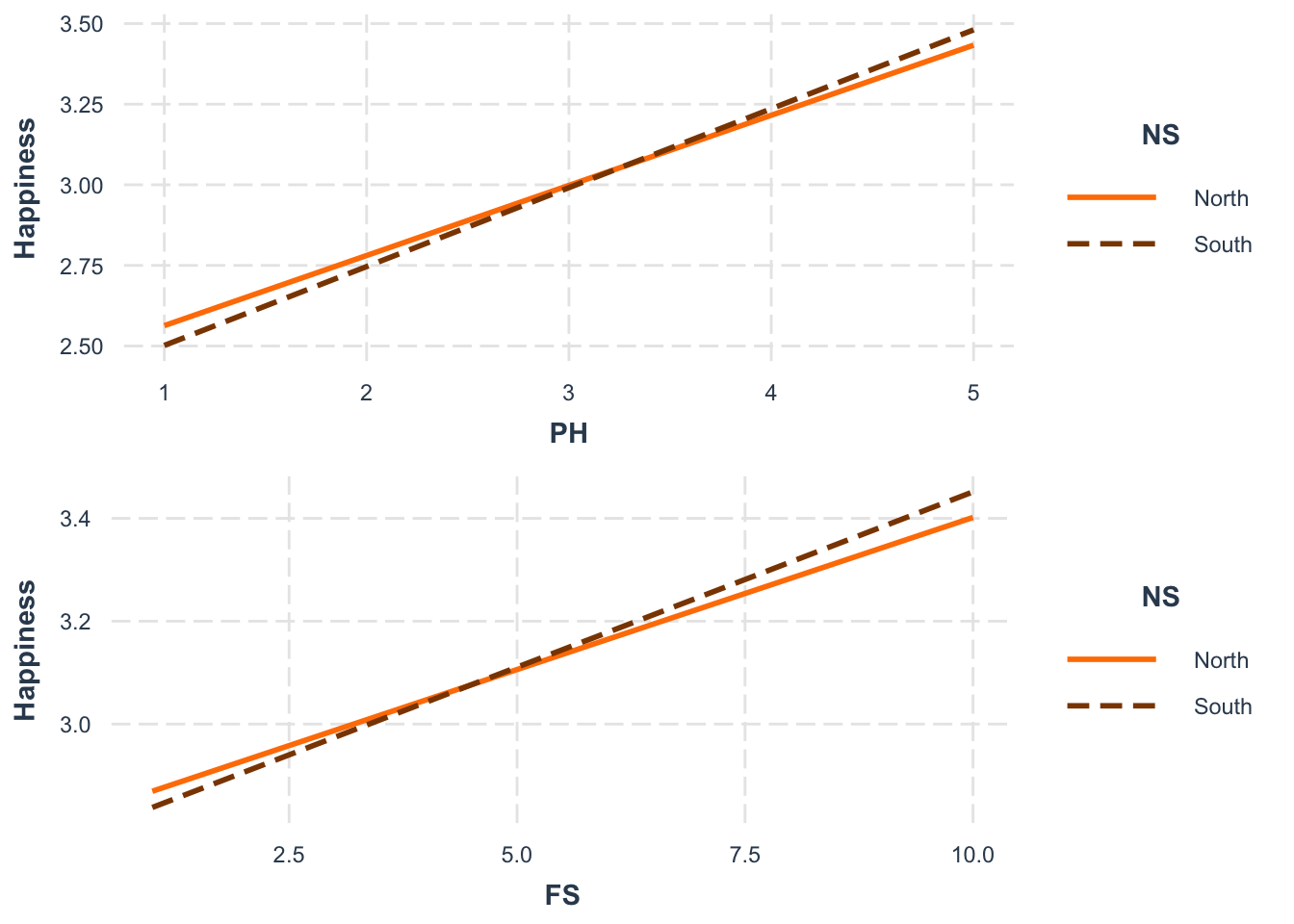
The interaction plots show that PerceivedHealth and FS have a greater impact on happiness in the Global South (NS = 1) than in the Global North.
To fully answer the RQ, I now need to re-run the same model with LS as the DV.
ModelB_LS <- lm(LS ~ PerceivedHealth*NS + FS*NS + G_TOWNSIZE + H_URBRURAL + FamImpt + FriendsImpt + LeisureImpt + ReligionImpt + FOC + Trust + Sex + Age + Immigrant + Citizen + HHSize + Parents + Married + Kids + Edu + Job + SocialClass + Income + Religion + I_WOMJOB + I_WOMPOL + I_WOMEDU + abortlib, wvs)
stargazer(ModelB_LS, type = "text")
===============================================
Dependent variable:
---------------------------
LS
-----------------------------------------------
PerceivedHealth 0.358***
(0.011)
NS1 -0.256***
(0.065)
FS 0.388***
(0.004)
G_TOWNSIZE -0.024***
(0.004)
H_URBRURAL2 -0.030
(0.020)
FamImpt 0.166***
(0.020)
FriendsImpt -0.017*
(0.009)
LeisureImpt 0.018**
(0.009)
ReligionImpt 0.057***
(0.009)
FOC 0.241***
(0.003)
Trust2 0.031*
(0.017)
Sex2 0.056***
(0.015)
Age 0.004***
(0.001)
Immigrant2 0.048
(0.034)
Citizen2 -0.005
(0.055)
HHSize -0.012***
(0.004)
Parents2 0.006
(0.021)
Parents3 0.025
(0.033)
Parents4 -0.238***
(0.088)
Married2 0.213***
(0.026)
Married3 -0.133***
(0.036)
Married4 -0.109**
(0.046)
Married5 -0.100***
(0.033)
Married6 -0.101***
(0.023)
Kids 0.020***
(0.005)
Edu -0.012***
(0.004)
Job2 0.095***
(0.026)
Job3 -0.027
(0.021)
Job4 0.066**
(0.028)
Job5 0.054**
(0.024)
Job6 0.053
(0.032)
Job7 -0.114***
(0.027)
Job8 0.119*
(0.068)
SocialClass 0.020**
(0.008)
Income 0.027*
(0.014)
Religion1 0.112***
(0.024)
Religion2 -0.151***
(0.030)
Religion3 -0.268***
(0.030)
Religion4 -0.298**
(0.128)
Religion5 -0.314***
(0.025)
Religion6 -0.043
(0.082)
Religion7 -0.145***
(0.032)
Religion8 0.233***
(0.043)
Religion9 -0.002
(0.044)
I_WOMJOB 0.032
(0.025)
I_WOMPOL 0.080***
(0.026)
I_WOMEDU 0.037
(0.026)
abortlib -0.025***
(0.003)
PerceivedHealth:NS1 -0.046***
(0.016)
NS1:FS 0.068***
(0.006)
Constant 0.687***
(0.106)
-----------------------------------------------
Observations 68,676
R2 0.410
Adjusted R2 0.410
Residual Std. Error 1.738 (df = 68625)
F Statistic 954.281*** (df = 50; 68625)
===============================================
Note: *p<0.1; **p<0.05; ***p<0.01For the model with LS as the DV, the adjusted R2 of 0.41 is in line with past papers (range: 0.16 - 0.5). Both two-way interactions are also significant, p < .01.
ls1 <- interact_plot(ModelB_LS, pred = PerceivedHealth, modx = NS, colors = c("darkorange1", "darkorange4"), x.label = "PH", modx.labels=c("North","South"))
ls2 <- interact_plot(ModelB_LS, pred = FS, modx = NS, colors = c("darkorange1","darkorange4"), x.label= "FS", modx.labels=c("North","South"))
grid.arrange(ls1, ls2)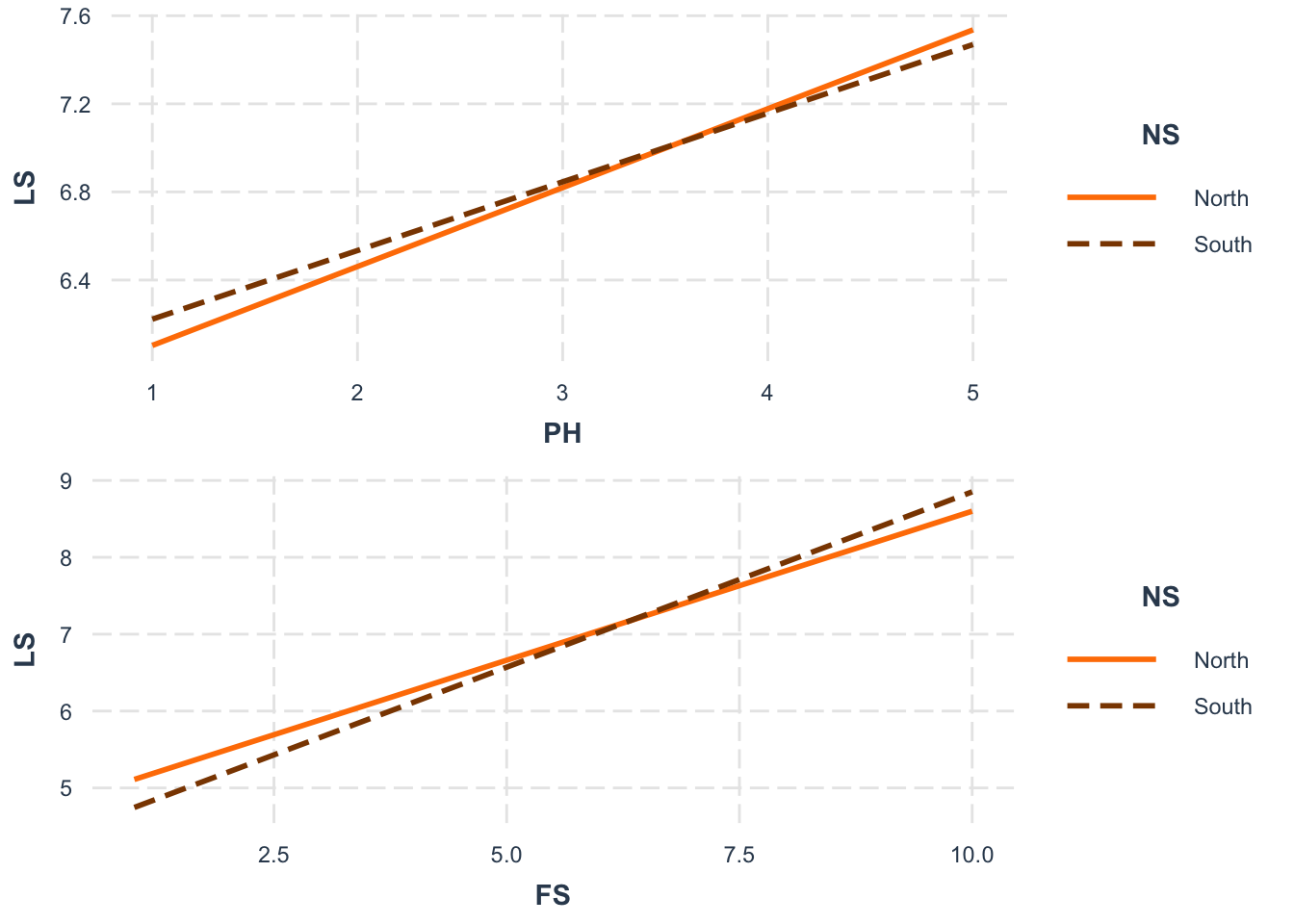
PerceivedHealth*NS: PerceivedHealth has a stronger effect on LS in the Global North than the Global South, demonstrated by the steeper curve for the former (as well as the negative coefficient for the interaction in the model summary) - we cannot reject the null for RQ B.
FS*NS: There is a stronger effect of FS on LS for the Global South than the Global North.
I will now generate the diagnostic plots for ModelB_H and ModelB_LS.
par(mfrow = c(2,3)); plot(ModelB_H, which = 1:6)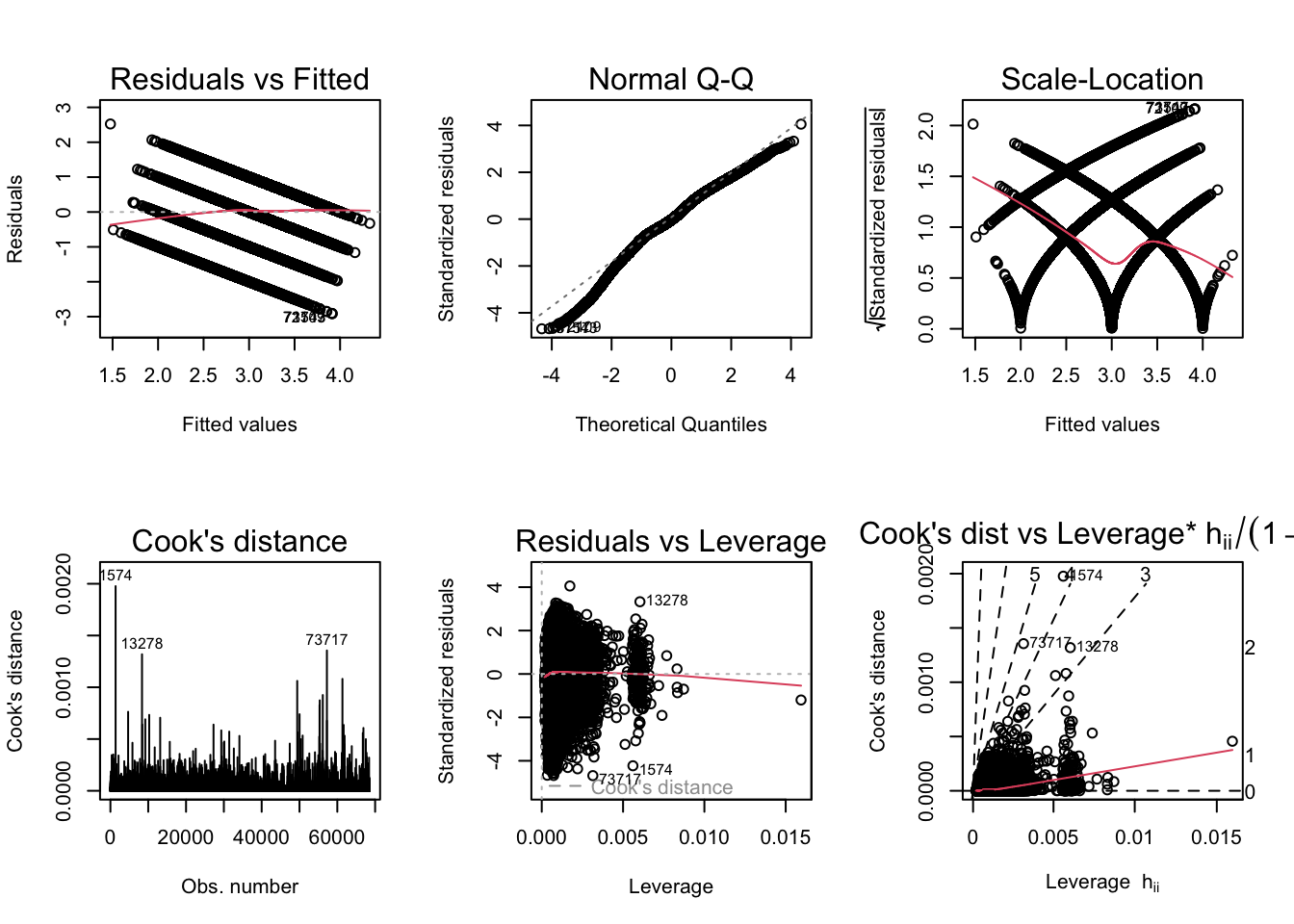
bptest(ModelB_H)
studentized Breusch-Pagan test
data: ModelB_H
BP = 3569.5, df = 50, p-value < 2.2e-16par(mfrow = c(2,3)); plot(ModelB_LS, which = 1:6)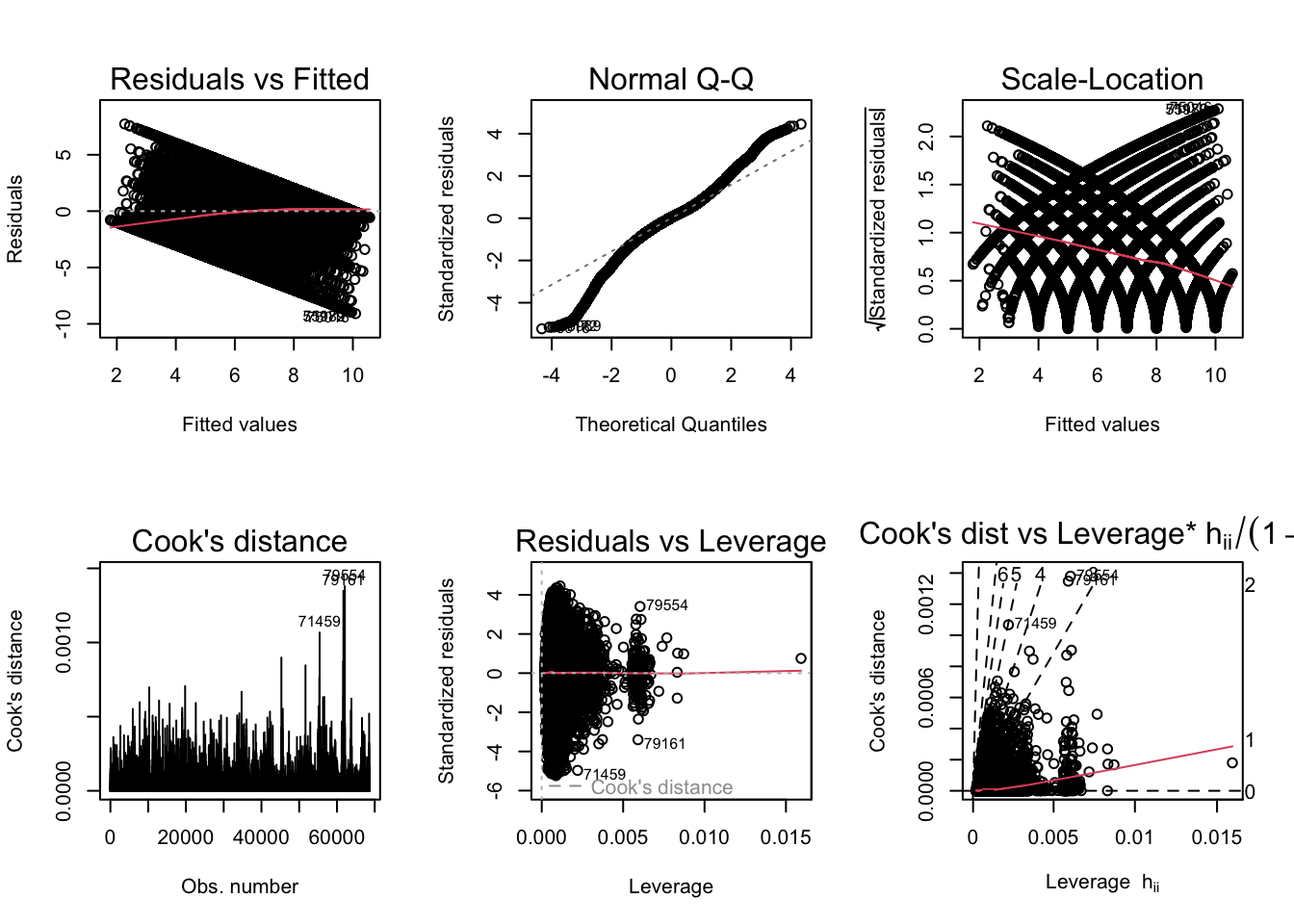
bptest(ModelB_LS)
studentized Breusch-Pagan test
data: ModelB_LS
BP = 6048, df = 50, p-value < 2.2e-16Similar to what was observed for RQ A, the scale-location plot indicates heteroskedasticity (confirmed by the Breusch-Pagan test). I will generate robust standard errors for both models.
The diagnostic plots also indicate some outliers, but this is likely a minor issue given the large size of the sample. They need not be removed.
# generate model with robust standard errors, and put it side by side with the original model.
covbh <- vcovHC(ModelB_H, type = "HC1")
robustbh <- sqrt(diag(covbh))
stargazer(ModelB_H, ModelB_H, type = "text", se = list(NULL, robustbh))
=============================================================
Dependent variable:
----------------------------
Happiness
(1) (2)
-------------------------------------------------------------
PerceivedHealth 0.218*** 0.218***
(0.004) (0.004)
NS1 -0.144*** -0.144***
(0.023) (0.027)
FS 0.059*** 0.059***
(0.001) (0.002)
G_TOWNSIZE -0.010*** -0.010***
(0.001) (0.001)
H_URBRURAL2 0.040*** 0.040***
(0.007) (0.007)
FamImpt 0.113*** 0.113***
(0.007) (0.007)
FriendsImpt 0.024*** 0.024***
(0.003) (0.004)
LeisureImpt 0.022*** 0.022***
(0.003) (0.003)
ReligionImpt 0.036*** 0.036***
(0.003) (0.003)
FOC 0.032*** 0.032***
(0.001) (0.001)
Trust2 -0.029*** -0.029***
(0.006) (0.006)
Sex2 0.041*** 0.041***
(0.005) (0.005)
Age -0.0003 -0.0003
(0.0002) (0.0002)
Immigrant2 0.007 0.007
(0.012) (0.011)
Citizen2 0.039* 0.039**
(0.020) (0.018)
HHSize 0.005*** 0.005***
(0.001) (0.002)
Parents2 -0.009 -0.009
(0.007) (0.008)
Parents3 0.021* 0.021*
(0.012) (0.012)
Parents4 -0.030 -0.030
(0.031) (0.035)
Married2 0.040*** 0.040***
(0.009) (0.010)
Married3 -0.114*** -0.114***
(0.013) (0.013)
Married4 -0.080*** -0.080***
(0.017) (0.019)
Married5 -0.069*** -0.069***
(0.012) (0.013)
Married6 -0.049*** -0.049***
(0.008) (0.008)
Kids 0.010*** 0.010***
(0.002) (0.002)
Edu -0.004*** -0.004***
(0.001) (0.001)
Job2 0.030*** 0.030***
(0.009) (0.009)
Job3 0.006 0.006
(0.008) (0.008)
Job4 0.036*** 0.036***
(0.010) (0.010)
Job5 0.027*** 0.027***
(0.009) (0.009)
Job6 0.025** 0.025**
(0.012) (0.011)
Job7 -0.014 -0.014
(0.010) (0.011)
Job8 0.026 0.026
(0.024) (0.027)
SocialClass 0.033*** 0.033***
(0.003) (0.003)
Income 0.007 0.007
(0.005) (0.005)
Religion1 0.035*** 0.035***
(0.008) (0.008)
Religion2 -0.013 -0.013
(0.011) (0.011)
Religion3 -0.094*** -0.094***
(0.011) (0.011)
Religion4 -0.139*** -0.139***
(0.046) (0.045)
Religion5 -0.112*** -0.112***
(0.009) (0.009)
Religion6 -0.080*** -0.080***
(0.029) (0.027)
Religion7 -0.046*** -0.046***
(0.011) (0.011)
Religion8 0.041*** 0.041***
(0.015) (0.016)
Religion9 0.013 0.013
(0.016) (0.015)
I_WOMJOB 0.020** 0.020**
(0.009) (0.010)
I_WOMPOL -0.007 -0.007
(0.009) (0.010)
I_WOMEDU -0.073*** -0.073***
(0.009) (0.010)
abortlib -0.008*** -0.008***
(0.001) (0.001)
PerceivedHealth:NS1 0.027*** 0.027***
(0.006) (0.007)
NS1:FS 0.009*** 0.009***
(0.002) (0.002)
Constant 1.053*** 1.053***
(0.038) (0.040)
-------------------------------------------------------------
Observations 68,570 68,570
R2 0.235 0.235
Adjusted R2 0.234 0.234
Residual Std. Error (df = 68519) 0.623 0.623
F Statistic (df = 50; 68519) 420.745*** 420.745***
=============================================================
Note: *p<0.1; **p<0.05; ***p<0.01# do the same for the model with life satisfaction as the dv.
covbls <- vcovHC(ModelB_LS, type = "HC1")
robustbls <- sqrt(diag(covbls))
stargazer(ModelB_LS, ModelB_LS, type = "text", se = list(NULL, robustbls))
=============================================================
Dependent variable:
----------------------------
LS
(1) (2)
-------------------------------------------------------------
PerceivedHealth 0.358*** 0.358***
(0.011) (0.011)
NS1 -0.256*** -0.256***
(0.065) (0.077)
FS 0.388*** 0.388***
(0.004) (0.005)
G_TOWNSIZE -0.024*** -0.024***
(0.004) (0.004)
H_URBRURAL2 -0.030 -0.030
(0.020) (0.021)
FamImpt 0.166*** 0.166***
(0.020) (0.021)
FriendsImpt -0.017* -0.017*
(0.009) (0.010)
LeisureImpt 0.018** 0.018*
(0.009) (0.010)
ReligionImpt 0.057*** 0.057***
(0.009) (0.009)
FOC 0.241*** 0.241***
(0.003) (0.004)
Trust2 0.031* 0.031**
(0.017) (0.016)
Sex2 0.056*** 0.056***
(0.015) (0.015)
Age 0.004*** 0.004***
(0.001) (0.001)
Immigrant2 0.048 0.048*
(0.034) (0.028)
Citizen2 -0.005 -0.005
(0.055) (0.046)
HHSize -0.012*** -0.012***
(0.004) (0.004)
Parents2 0.006 0.006
(0.021) (0.021)
Parents3 0.025 0.025
(0.033) (0.035)
Parents4 -0.238*** -0.238***
(0.088) (0.084)
Married2 0.213*** 0.213***
(0.026) (0.026)
Married3 -0.133*** -0.133***
(0.036) (0.036)
Married4 -0.109** -0.109**
(0.046) (0.049)
Married5 -0.100*** -0.100***
(0.033) (0.036)
Married6 -0.101*** -0.101***
(0.023) (0.023)
Kids 0.020*** 0.020***
(0.005) (0.006)
Edu -0.012*** -0.012***
(0.004) (0.004)
Job2 0.095*** 0.095***
(0.026) (0.026)
Job3 -0.027 -0.027
(0.021) (0.022)
Job4 0.066** 0.066**
(0.028) (0.026)
Job5 0.054** 0.054**
(0.024) (0.024)
Job6 0.053 0.053*
(0.032) (0.031)
Job7 -0.114*** -0.114***
(0.027) (0.031)
Job8 0.119* 0.119*
(0.068) (0.072)
SocialClass 0.020** 0.020**
(0.008) (0.009)
Income 0.027* 0.027*
(0.014) (0.015)
Religion1 0.112*** 0.112***
(0.024) (0.023)
Religion2 -0.151*** -0.151***
(0.030) (0.030)
Religion3 -0.268*** -0.268***
(0.030) (0.030)
Religion4 -0.298** -0.298**
(0.128) (0.121)
Religion5 -0.314*** -0.314***
(0.025) (0.025)
Religion6 -0.043 -0.043
(0.082) (0.070)
Religion7 -0.145*** -0.145***
(0.032) (0.029)
Religion8 0.233*** 0.233***
(0.043) (0.044)
Religion9 -0.002 -0.002
(0.044) (0.039)
I_WOMJOB 0.032 0.032
(0.025) (0.027)
I_WOMPOL 0.080*** 0.080***
(0.026) (0.029)
I_WOMEDU 0.037 0.037
(0.026) (0.029)
abortlib -0.025*** -0.025***
(0.003) (0.003)
PerceivedHealth:NS1 -0.046*** -0.046**
(0.016) (0.019)
NS1:FS 0.068*** 0.068***
(0.006) (0.008)
Constant 0.687*** 0.687***
(0.106) (0.108)
-------------------------------------------------------------
Observations 68,676 68,676
R2 0.410 0.410
Adjusted R2 0.410 0.410
Residual Std. Error (df = 68625) 1.738 1.738
F Statistic (df = 50; 68625) 954.281*** 954.281***
=============================================================
Note: *p<0.1; **p<0.05; ***p<0.01For ModelB_H, both interactions remain significant, p < .01.
For ModelB_LS, both interactions remain significant, p < .05 for PerceivedHealth*NS and p < .01 for FS*NS.
In RQ A, when we only examined the Global South, perceived health and financial satisfaction positively predicted perceived well-being. We rejected the null.
RQ B further showed that financial satisfaction had a greater impact on perceived well-being (recall: both happiness and life satisfaction) in the Global South than in the Global North.
However, perceived health had a greater impact on life satisfaction in the Global North. Even though perceived health had a greater impact on happiness in the Global South, this makes us unable to reject the null for RQ B.
These findings could signal to governments in the Global North to prioritize health-related welfare, while those in the Global South may first want to focus on monetary policies.
Financial satisfaction and perceived health are subjective self-assessments that reflect individual satisfaction with health/wealth, and not actual health/wealth.
Future research should definitely continue studying desires, motives and needs in the Global South. Practical ways to improve perceived well-being would be especially useful. Another interesting aspect to explore would be qualitative research with citizens on the ground. This has the ability to elicit rich insights that can boost quantitative studies.
Addai, I., Opoku-Agyeman, C., & Amanfu, S. (2013). Exploring Predictors of Subjective Well-Being in Ghana: A Micro-Level Study. Journal Of Happiness Studies, 15(4), 869-890.
Alba, C. (2019). A Data Analysis of the World Happiness Index and its Relation to the North-South Divide. Undergraduate Economic Review, 16(1).
Clarke, M. (2018). Global South: what does it mean and why use the term? Global South Political Commentaries. Retrieved from https://onlineacademiccommunity.uvic.ca/globalsouthpolitics/2018/08/08/global-south-what-does-it-mean-and-why-use-the-term/
Haerpfer, C., Inglehart, R., Moreno, A., Welzel, C., Kizilova, K., Diez-Medrano J., M. Lagos, P. Norris, E. Ponarin & B. Puranen (eds.). 2022. World Values Survey: Round Seven - Country-Pooled Datafile Version 4.0. Madrid, Spain & Vienna, Austria: JD Systems Institute & WVSA Secretariat.
Maslow, A. H. (1943). A theory of human motivation. Psychological Review, 50(4), 370–396.
Ngamaba, K. (2016). Happiness and life satisfaction in Rwanda. Journal Of Psychology In Africa, 26(5), 407-414.
World Bank Country and Lending Groups. World Bank Data Help Desk. (2022). Retrieved from https://datahelpdesk.worldbank.org/knowledgebase/articles/906519-world-bank-country-and-lending-groups.
WVS Database. World Values Survey. (2022). Retrieved from https://www.worldvaluessurvey.org/WVSDocumentationWV7.jsp.