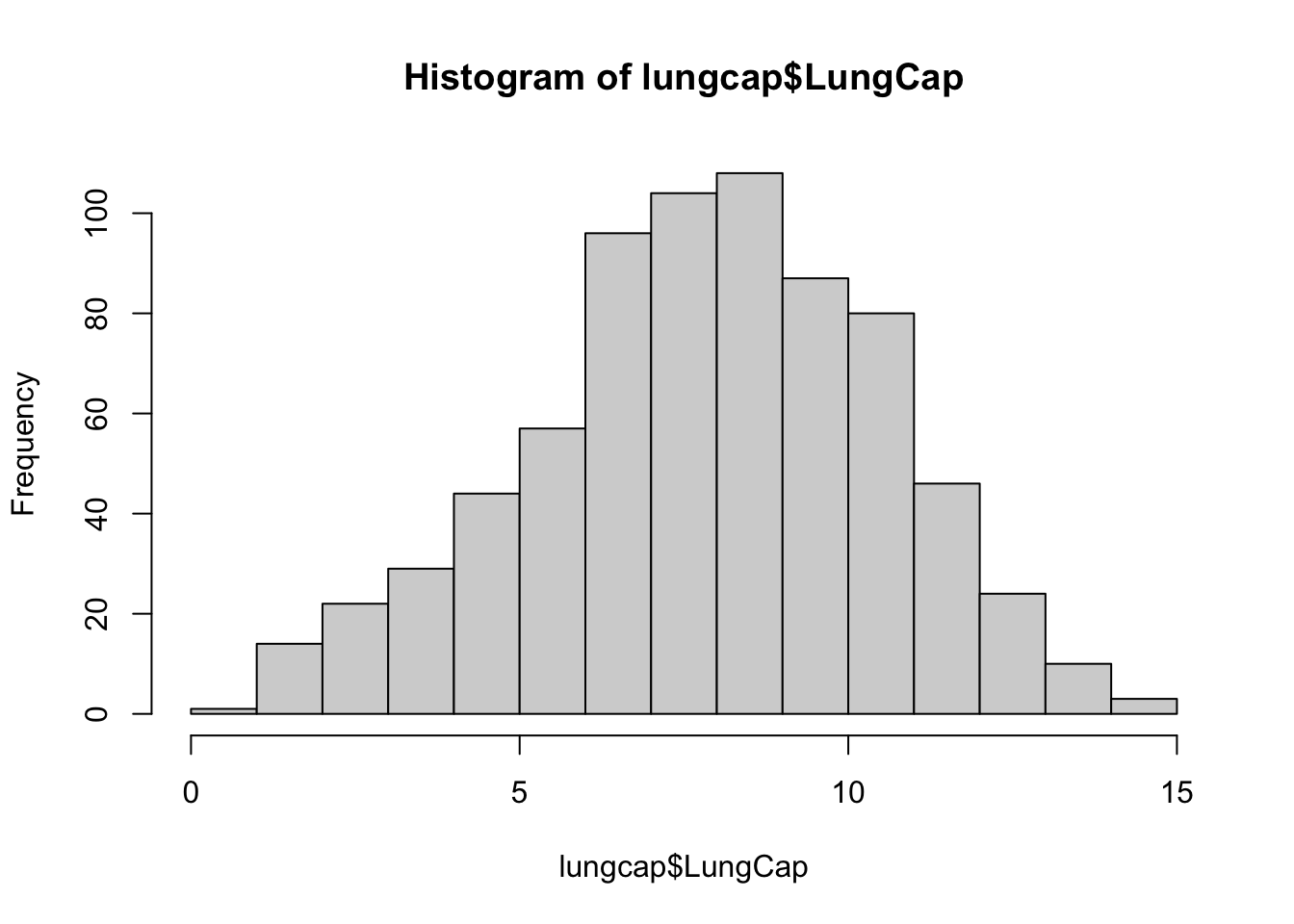
The histogram suggests that the distribution is close to a normal distribution. Most of the observations are close to the mean. Very few observations are close to the margins (0 and 15).
b
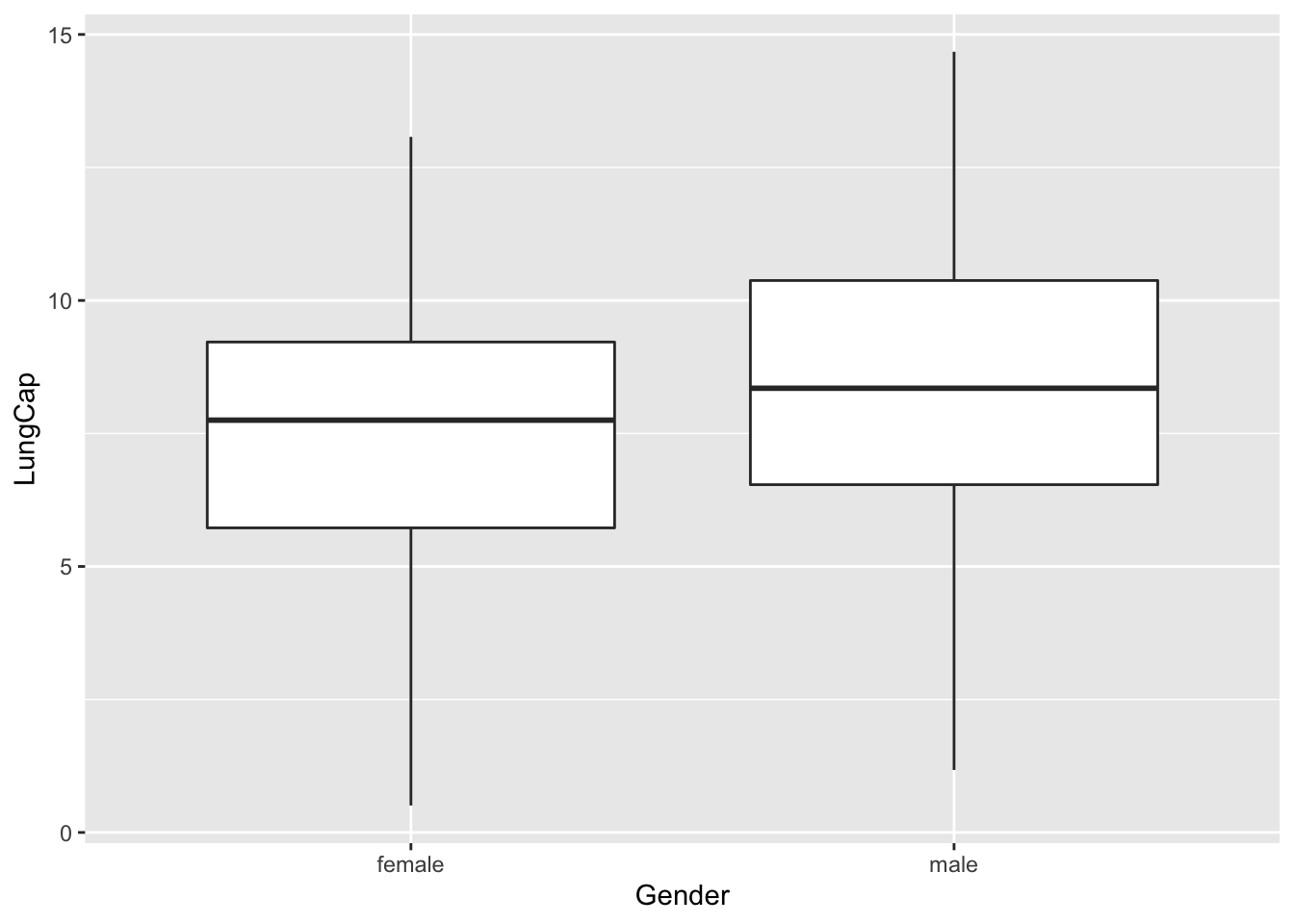
These are the boxplots of the distributions for the lung capacity of males and females in the sample:
According to these boxplots, it appears that males and females have similar median lung capacities, but that males may be more likely to have a higher lung capacity than females.
# A tibble: 2 × 2
Smoke mean_lungcap
<chr> <dbl>
1 no 7.77
2 yes 8.65
According to this sample, it would appear that smokers have a higher lung capacity than non-smokers. This would appear to be counter-intuitive, as one would likely expect smoking to reduce lung functionality and, by extension, capacity.
d
In order to complete this examination by group, we must create a new nominal variable that groups observations by age; this can be accomplished fairly simply using the mutate() and case_when() functions:
Code
lungcap_age <- lungcap %>%mutate(age_group =case_when( Age <=13~"13 and under", Age ==14| Age ==15~"14 to 15", Age ==16| Age ==17~"16 to 17", Age >=18~"18 and older" ))
With this new dataframe, we can use the group_by() function to calculate mean lung capacity by age group and smoker status:
# A tibble: 8 × 3
# Groups: age_group [4]
age_group Smoke `mean(LungCap)`
<chr> <chr> <dbl>
1 13 and under no 6.36
2 13 and under yes 7.20
3 14 to 15 no 9.14
4 14 to 15 yes 8.39
5 16 to 17 no 10.5
6 16 to 17 yes 9.38
7 18 and older no 11.1
8 18 and older yes 10.5
According to these data, it appears that lung capacity generally increases with age. Interestingly, lung capacity is worse for smokers than it is for non-smokers in every age group except for “13 and under”. This is surprising on the surface, given that, when the data are ungrouped, smokers have a higher lung capacity than non-smokers (see part c). However, this begins to make more sense when we see how much better the “13 and under” group is represented compared to the others in this dataset:
Code
lungcap_age %>%group_by(age_group) %>%count()
# A tibble: 4 × 2
# Groups: age_group [4]
age_group n
<chr> <int>
1 13 and under 428
2 14 to 15 120
3 16 to 17 97
4 18 and older 80
This high number of observations compared to other age groups likely plays a significant role in skewing the mean of the entire dataset.
e
It is not clear to me how this part is different from part d; from what I do understand, I believe the question being asked here is addressed in that part.
f
Code
cov(lungcap$LungCap, lungcap$Age)
[1] 8.738289
Code
cor(lungcap$LungCap, lungcap$Age)
[1] 0.8196749
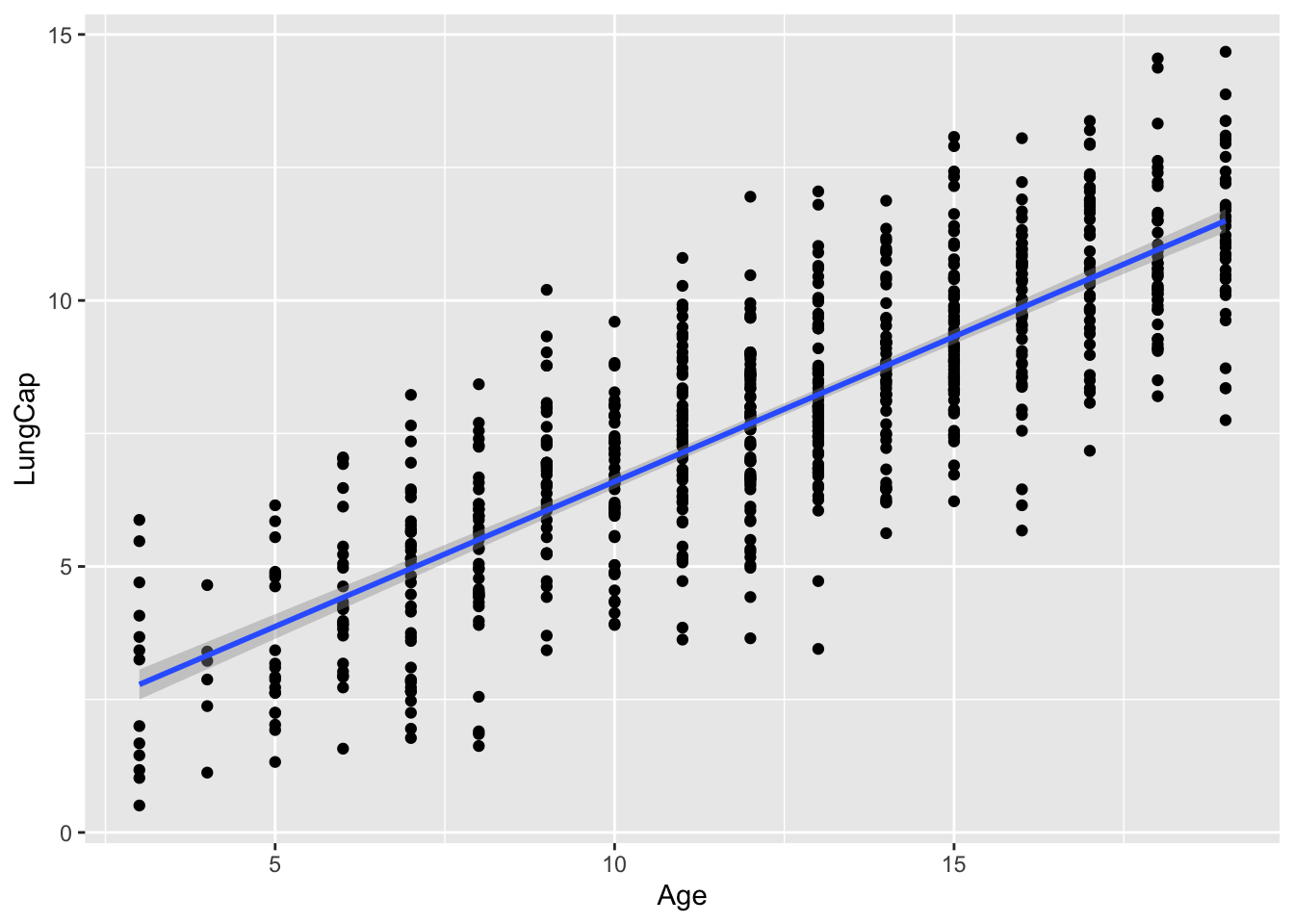
It would appear that lung capacity and age covary together positively, such that a higher age means a higher lung capacity. We can confirm this with a simple visualization:
The expected value for the number of prior convictions is about 1.29 priors.
EDIT: There is a much simpler way to compute this! Rather than using the dataframe I created, storing values and their frequencies, I can create one vector that stores each value a certain number of times, according to the given frequencies:
Because each value now appears as frequently as its “probability” of appearing, taking the mean of this vector also provides the correct expected value.
Code
mean(prisoners_full)
[1] 1.28642
f
Creating this numerical vector also makes the standard deviation calculation extremely simple in R.
Code
sd(prisoners_full)
[1] 0.9259016
Source Code
---title: "Homework 1"author: "Nick Boonstra"description: "The first homework on descriptive statistics and probability"date: "10/05/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - hw1 - desriptive statistics - probability - nboonstra---```{r setup}library(tidyverse)library(readxl)knitr::opts_chunk$set(echo =TRUE, warning=FALSE, message=FALSE)```# Question 1## aFirst, let's read in the data from the Excel file:```{r readin}library(readxl)lungcap <-read_excel("_data/LungCapData.xls")```The distribution of LungCap looks as follows:```{r hist}hist(lungcap$LungCap)```The histogram suggests that the distribution is close to a normal distribution. Most of the observations are close to the mean. Very few observations are close to the margins (0 and 15).## bThese are the boxplots of the distributions for the lung capacity of males and females in the sample:```{r boxplot}lungcap %>%ggplot(aes(x=Gender,y=LungCap)) +geom_boxplot()```According to these boxplots, it appears that males and females have similar median lung capacities, but that males may be more likely to have a higher lung capacity than females.## c```{r lungcap by smoke}lungcap %>%group_by(Smoke) %>%summarise(mean_lungcap=mean(LungCap))```According to this sample, it would appear that smokers have a higher lung capacity than non-smokers. This would appear to be counter-intuitive, as one would likely expect smoking to reduce lung functionality and, by extension, capacity.## dIn order to complete this examination by group, we must create a new nominal variable that groups observations by age; this can be accomplished fairly simply using the `mutate()` and `case_when()` functions:```{r age_group}lungcap_age <- lungcap %>%mutate(age_group =case_when( Age <=13~"13 and under", Age ==14| Age ==15~"14 to 15", Age ==16| Age ==17~"16 to 17", Age >=18~"18 and older" ))```With this new dataframe, we can use the `group_by()` function to calculate mean lung capacity by age group and smoker status:```{r age_group and smoke}lungcap_age %>%group_by(age_group,Smoke) %>%summarise(mean(LungCap))```According to these data, it appears that lung capacity generally increases with age. Interestingly, lung capacity is worse for smokers than it is for non-smokers in every age group except for "13 and under". This is surprising on the surface, given that, when the data are ungrouped, smokers have a higher lung capacity than non-smokers (see part c). However, this begins to make more sense when we see how much better the "13 and under" group is represented compared to the others in this dataset:```{r count age group}lungcap_age %>%group_by(age_group) %>%count()```This high number of observations compared to other age groups likely plays a significant role in skewing the mean of the entire dataset.## eIt is not clear to me how this part is different from part d; from what I do understand, I believe the question being asked here is addressed in that part.## f```{r cov corr}cov(lungcap$LungCap, lungcap$Age)cor(lungcap$LungCap, lungcap$Age)```It would appear that lung capacity and age covary together positively, such that a higher age means a higher lung capacity. We can confirm this with a simple visualization:```{r corr viz}lungcap %>%ggplot(aes(x=Age,y=LungCap)) +geom_point() +geom_smooth(method='lm')```# Question 2Before we begin answering the parts of this question, we must create a dataframe in R that represents the necessary data.```{r q2_df}priors <-c(0,1,2,3,4)freq <-c(128,434,160,64,24)prisoners <-data.frame(priors,freq)prisoners```## aThe probability that a randomly selected inmate has exactly 2 prior convictions is 160 / 810 = `r 160 / 810`.## bThe probability that a randomly selected inmate has less than 2 prior convictions is (128+434) / 810 = `r (128+434) / 810`.## cThe probability that a randomly selected inmate has 2 or fewer prior convictions is (128+434+160) / 810 = `r (128+434+160) / 810`.## dThe probability that a randomly selected inmate has more than 2 prior convictions is (64+24) / 810 = `r (64+24)/810`.## eBefore calculating expected value, we should put together a probability mass function for the `prisoners` data.```{r pmf}prisoners <- prisoners %>%mutate(prob=freq/810) %>%mutate(expect=prob*priors)prisoners %>%summarise(sum(expect))```The expected value for the number of prior convictions is about 1.29 priors.EDIT: There is a much simpler way to compute this! Rather than using the dataframe I created, storing values and their frequencies, I can create one vector that stores each value a certain number of times, according to the given frequencies:```{r prisoners full}prisoners_full <-rep(c(0,1,2,3,4),times=c(128,434,160,64,24))prisoners_full```Because each value now appears as frequently as its "probability" of appearing, taking the mean of this vector also provides the correct expected value.```{r simple mean}mean(prisoners_full)```## fCreating this numerical vector also makes the standard deviation calculation extremely simple in R.```{r sd}sd(prisoners_full)```