Loading required package: car
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
Loading required package: effects
lattice theme set by effectsTheme()
See ?effectsTheme for details.
library(smss)
Warning: package 'smss' was built under R version 4.2.2
# A tibble: 20 × 6
region group fertility ppgdp lifeExpF pctUrban
<fct> <fct> <dbl> <dbl> <dbl> <dbl>
1 Asia other 5.97 499 49.5 23
2 Europe other 1.52 3677. 80.4 53
3 Africa africa 2.14 4473 75 67
4 Africa africa 5.14 4322. 53.2 59
5 Caribbean other 2 13750. 81.1 100
6 Latin Amer other 2.17 9162. 79.9 93
7 Asia other 1.74 3031. 77.3 64
8 Caribbean other 1.67 22852. 77.8 47
9 Oceania oecd 1.95 57119. 84.3 89
10 Europe oecd 1.35 45159. 83.6 68
11 Asia other 2.15 5638. 73.7 52
12 Caribbean other 1.88 22462. 78.8 84
13 Asia other 2.43 18184. 76.1 89
14 Asia other 2.16 670. 70.2 29
15 Caribbean other 1.58 14497. 80.3 45
16 Europe other 1.48 5702 76.4 75
17 Europe oecd 1.84 43815. 82.8 97
18 Latin Amer other 2.68 4496. 77.8 53
19 Africa africa 5.08 741. 58.7 42
20 Caribbean other 1.76 92625. 82.3 100
summary(un11)
region group fertility ppgdp
Africa :53 oecd : 31 Min. :1.134 Min. : 114.8
Asia :50 other :115 1st Qu.:1.754 1st Qu.: 1283.0
Europe :39 africa: 53 Median :2.262 Median : 4684.5
Latin Amer:20 Mean :2.761 Mean : 13012.0
Caribbean :17 3rd Qu.:3.545 3rd Qu.: 15520.5
Oceania :17 Max. :6.925 Max. :105095.4
(Other) : 3
lifeExpF pctUrban
Min. :48.11 Min. : 11.00
1st Qu.:65.66 1st Qu.: 39.00
Median :75.89 Median : 59.00
Mean :72.29 Mean : 57.93
3rd Qu.:79.58 3rd Qu.: 75.00
Max. :87.12 Max. :100.00
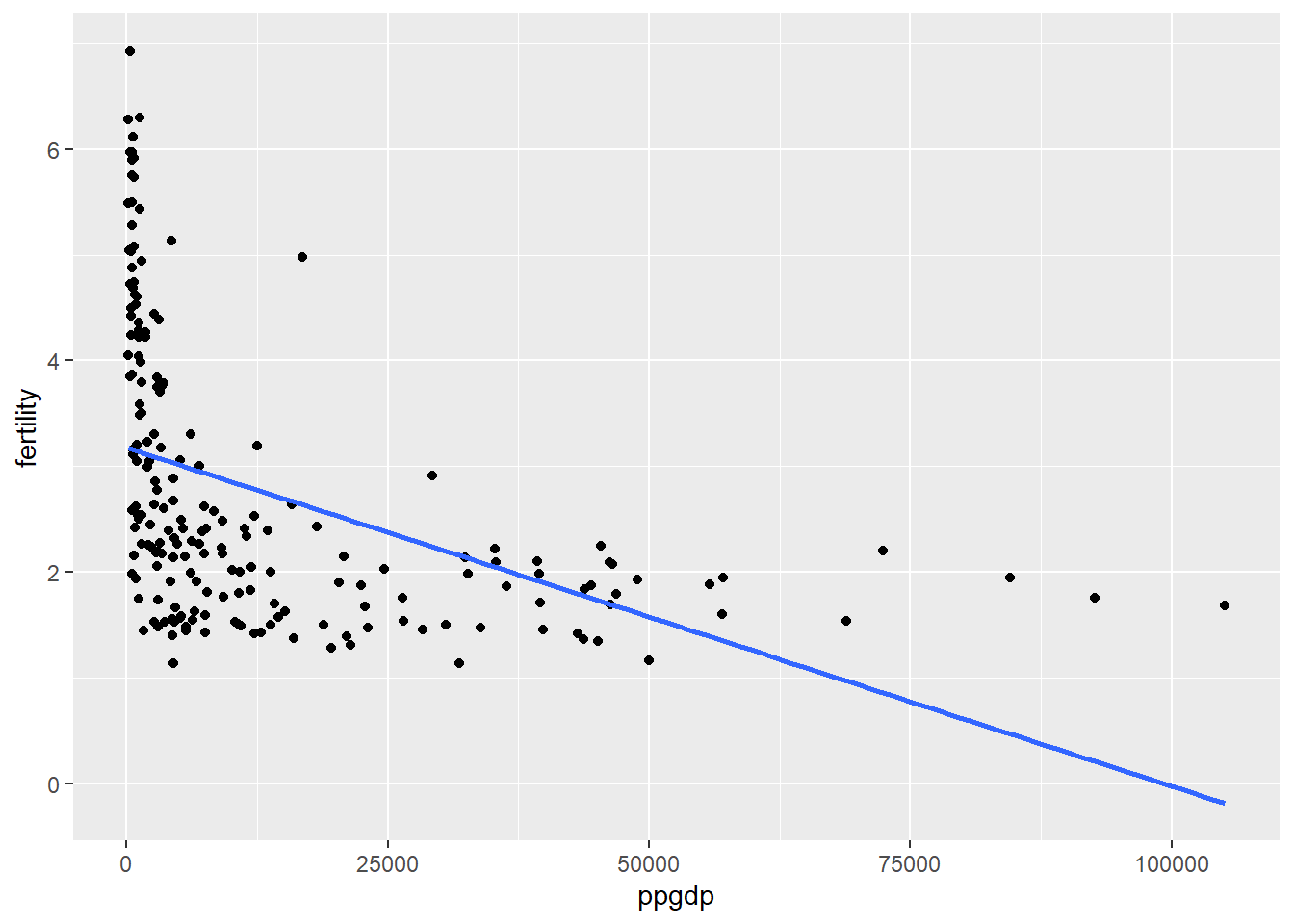
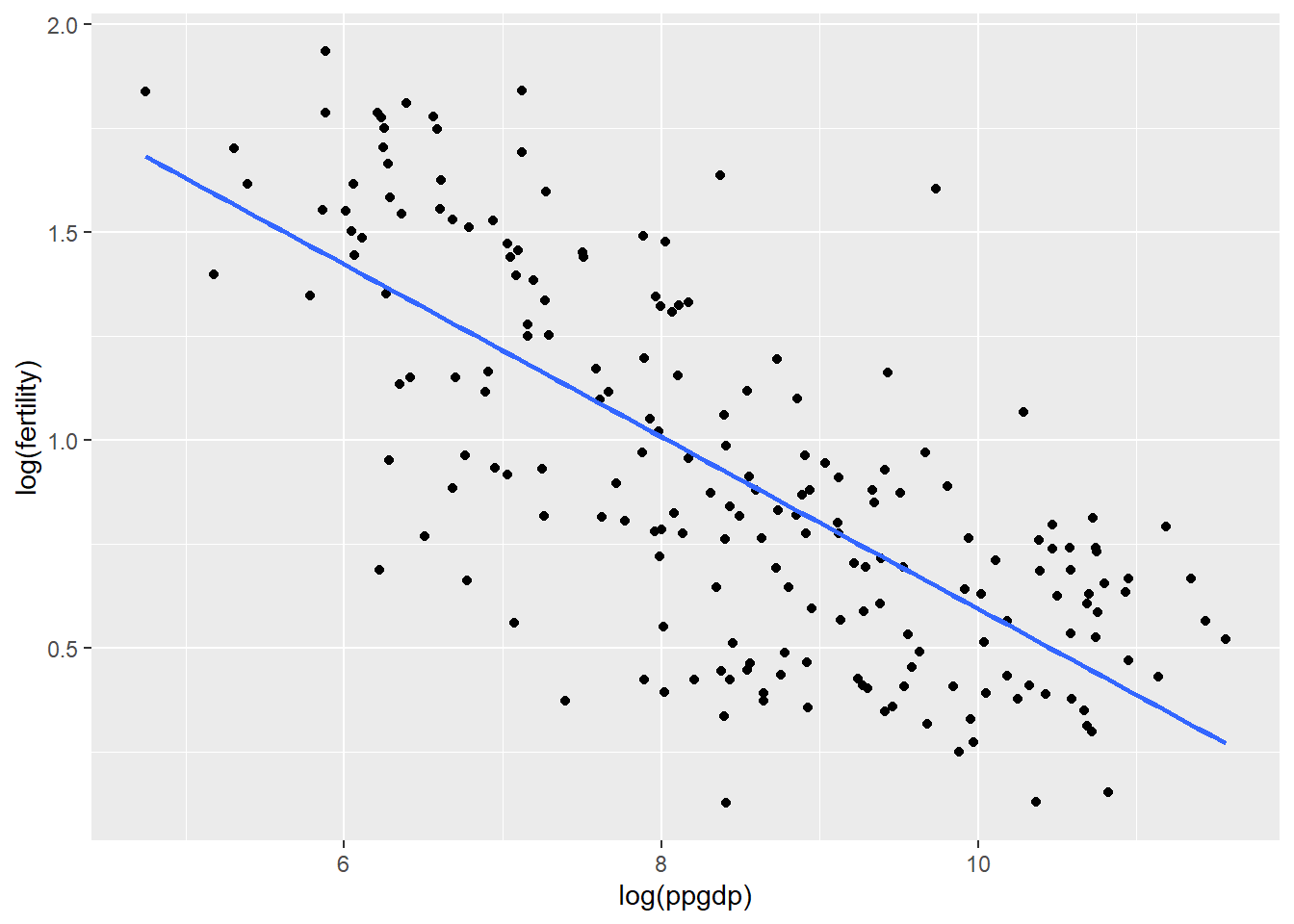
This question involves using United Nations data to “study the dependence of fertility on ppgdp” (the dependence of births per 1000 females on GDP in U.S. dollars per person).
1.1.1
In this model, ppgdp would be the predictor variable, and fertility would be the response variable.
A linear OLS regression of a linear-linear model of the data does not seem to fit the data very well. While the regression does capture the general downward trend of the data, it is plain to see in the above visualization that it is not a good fit, particularly for larger values of the response variable (ppgdp).
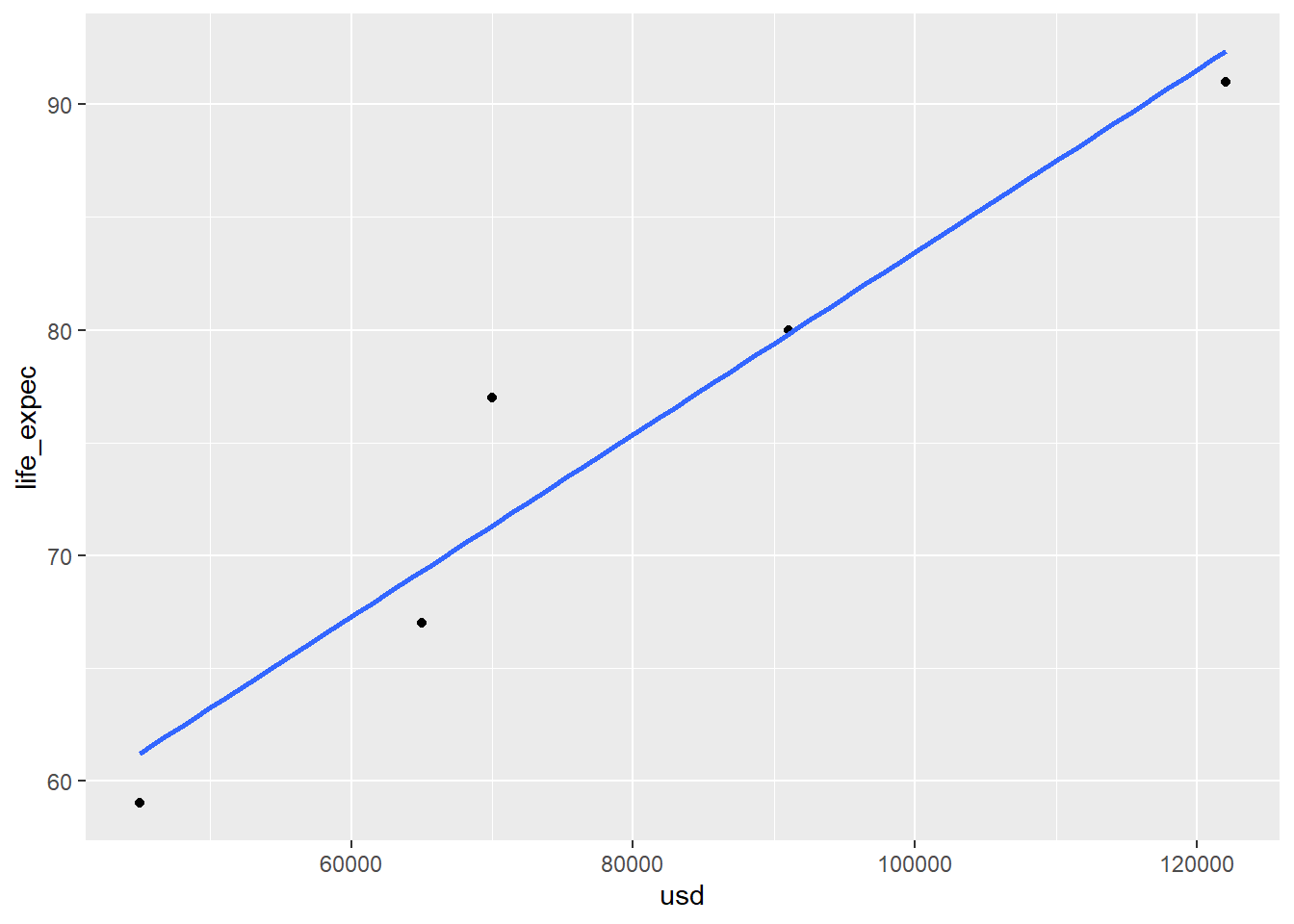
Call:
lm(formula = life_expec ~ usd, data = q2)
Residuals:
1 2 3 4 5
5.6790 0.1838 -2.2984 -2.2078 -1.3567
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.300e+01 5.438e+00 7.908 0.00422 **
usd 4.045e-04 6.565e-05 6.162 0.00860 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.842 on 3 degrees of freedom
Multiple R-squared: 0.9268, Adjusted R-squared: 0.9024
F-statistic: 37.97 on 1 and 3 DF, p-value: 0.008601
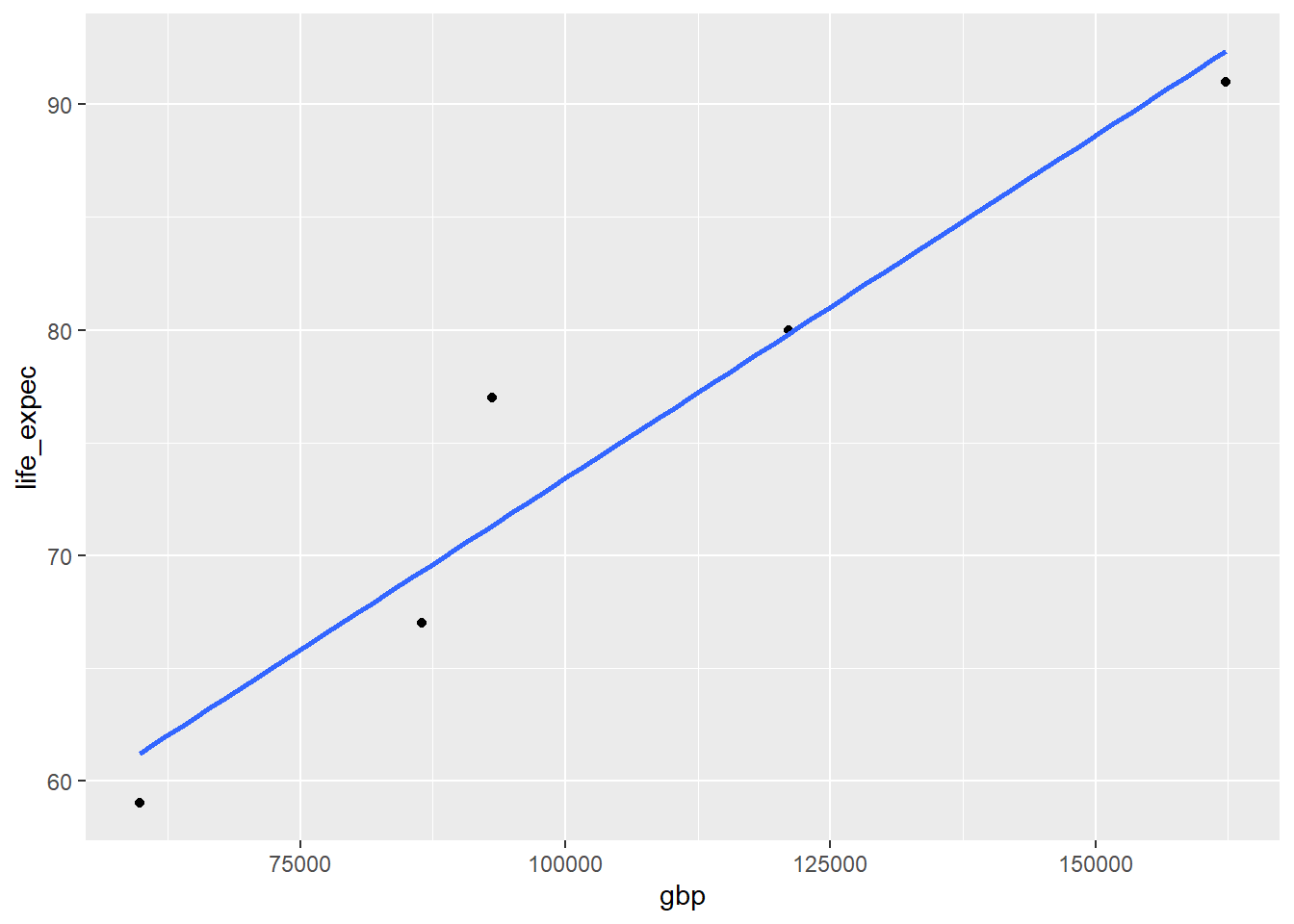
summary(lm(life_expec ~ gbp, data = q2))
Call:
lm(formula = life_expec ~ gbp, data = q2)
Residuals:
1 2 3 4 5
5.6790 0.1838 -2.2984 -2.2078 -1.3567
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.300e+01 5.438e+00 7.908 0.00422 **
gbp 3.042e-04 4.936e-05 6.162 0.00860 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.842 on 3 degrees of freedom
Multiple R-squared: 0.9268, Adjusted R-squared: 0.9024
F-statistic: 37.97 on 1 and 3 DF, p-value: 0.008601
As can be seen by this example data, transforming a dataset between USD and GBP (that is, adding a linear coefficient to a variable) does change the slope coefficient of the prediction equation (corresponding to the ratio of the value of the two currencies), but it does not alter the overall correlation between the two variables.
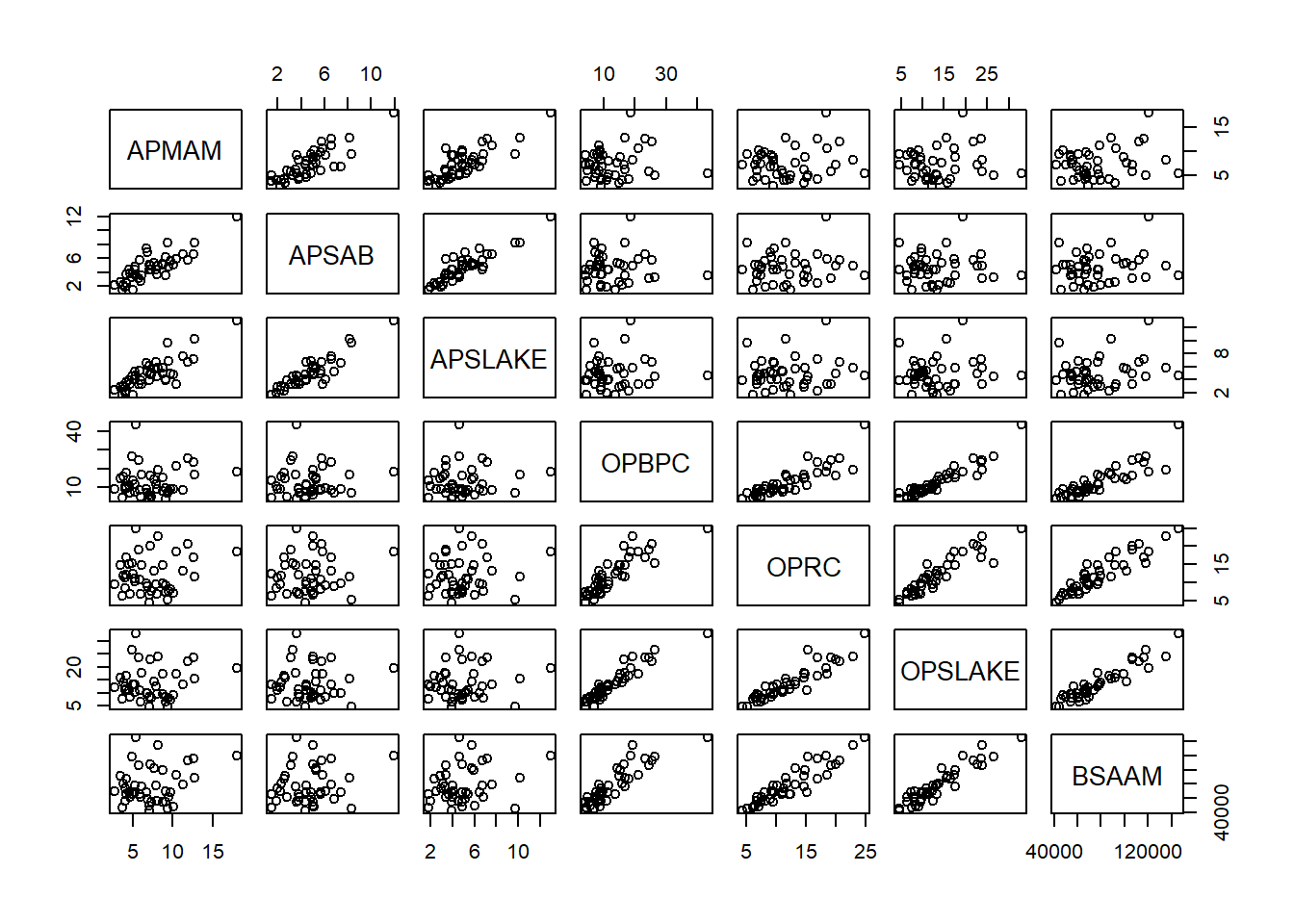
The correlation between stream runoff near Bishop, CA and rainfall at these six sites in the Sierra Nevada mountains can be interpreted from the scatterplots along the bottom row or the right-most column in the scatterplot matrix (they are both the same information). From this scatterplot matrix, it would appear that correlation between Bishop, CA runoff and Sierra Nevada rainfall is strongest for the OPSLAKE, OPRC, and OPBPC variables. In these plots, the data most clearly follow a linear trend, and the data are mostly staying close to a fit line.
Question 4
rateprof <-tibble(Rateprof)head(rateprof,10)
# A tibble: 10 × 17
gender numYears numRat…¹ numCo…² pepper disci…³ dept quality helpf…⁴ clarity
<fct> <int> <int> <int> <fct> <fct> <fct> <dbl> <dbl> <dbl>
1 male 7 11 5 no Hum Engl… 4.64 4.64 4.64
2 male 6 11 5 no Hum Reli… 4.32 4.55 4.09
3 male 10 43 2 no Hum Art 4.79 4.72 4.86
4 male 11 24 5 no Hum Engl… 4.25 4.46 4.04
5 male 11 19 7 no Hum Span… 4.68 4.68 4.68
6 male 10 15 9 no Hum Span… 4.23 4.27 4.2
7 male 7 17 3 no Hum Span… 4.38 4.35 4.41
8 male 11 16 3 no Hum Engl… 2.06 2.06 2.06
9 male 11 12 4 no Hum Music 2.04 2.17 2
10 male 7 18 4 no Hum Engl… 4.11 4.22 4
# … with 7 more variables: easiness <dbl>, raterInterest <dbl>,
# sdQuality <dbl>, sdHelpfulness <dbl>, sdClarity <dbl>, sdEasiness <dbl>,
# sdRaterInterest <dbl>, and abbreviated variable names ¹numRaters,
# ²numCourses, ³discipline, ⁴helpfulness
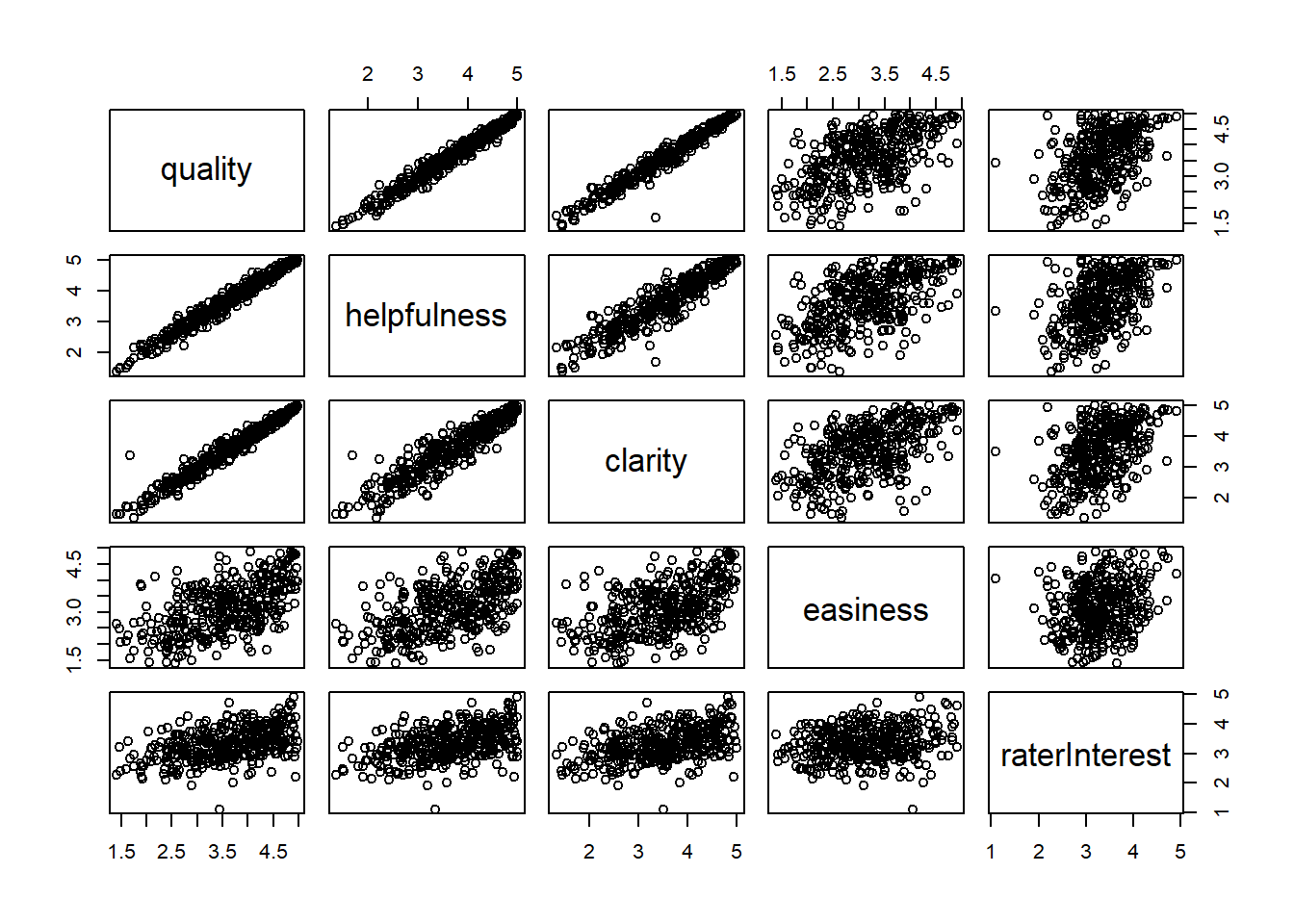
pairs(rateprof[,8:12])
There is a strong positive correlation between quality, helpfulness, and clarity; besides that, the trend seems to be upward for all other pairs, but the correlation is not as strong.
Question 5
data(student.survey)summary(student.survey)
subj ge ag hi co
Min. : 1.00 f:31 Min. :22.00 Min. :2.000 Min. :2.600
1st Qu.:15.75 m:29 1st Qu.:24.00 1st Qu.:3.000 1st Qu.:3.175
Median :30.50 Median :26.50 Median :3.350 Median :3.500
Mean :30.50 Mean :29.17 Mean :3.308 Mean :3.453
3rd Qu.:45.25 3rd Qu.:31.00 3rd Qu.:3.625 3rd Qu.:3.725
Max. :60.00 Max. :71.00 Max. :4.000 Max. :4.000
dh dr tv sp
Min. : 0 Min. : 0.200 Min. : 0.000 Min. : 0.000
1st Qu.: 205 1st Qu.: 1.450 1st Qu.: 3.000 1st Qu.: 3.000
Median : 640 Median : 2.000 Median : 6.000 Median : 5.000
Mean :1232 Mean : 3.818 Mean : 7.267 Mean : 5.483
3rd Qu.:1350 3rd Qu.: 5.000 3rd Qu.:10.000 3rd Qu.: 7.000
Max. :8000 Max. :20.000 Max. :37.000 Max. :16.000
ne ah ve pa
Min. : 0.000 Min. : 0.000 Mode :logical d:21
1st Qu.: 2.000 1st Qu.: 0.000 FALSE:60 i:24
Median : 3.000 Median : 0.500 r:15
Mean : 4.083 Mean : 1.433
3rd Qu.: 5.250 3rd Qu.: 2.000
Max. :14.000 Max. :11.000
pi re ab aa
very liberal : 8 never :15 Mode :logical Mode :logical
liberal :24 occasionally:29 FALSE:60 FALSE:59
slightly liberal : 6 most weeks : 7 NA's :1
moderate :10 every week : 9
slightly conservative: 6
conservative : 4
very conservative : 2
ld
Mode :logical
FALSE:44
NA's :16
Some of the variables in question for the analysis will need to be recoded to ordinal variables before a proper regression analysis can be performed.
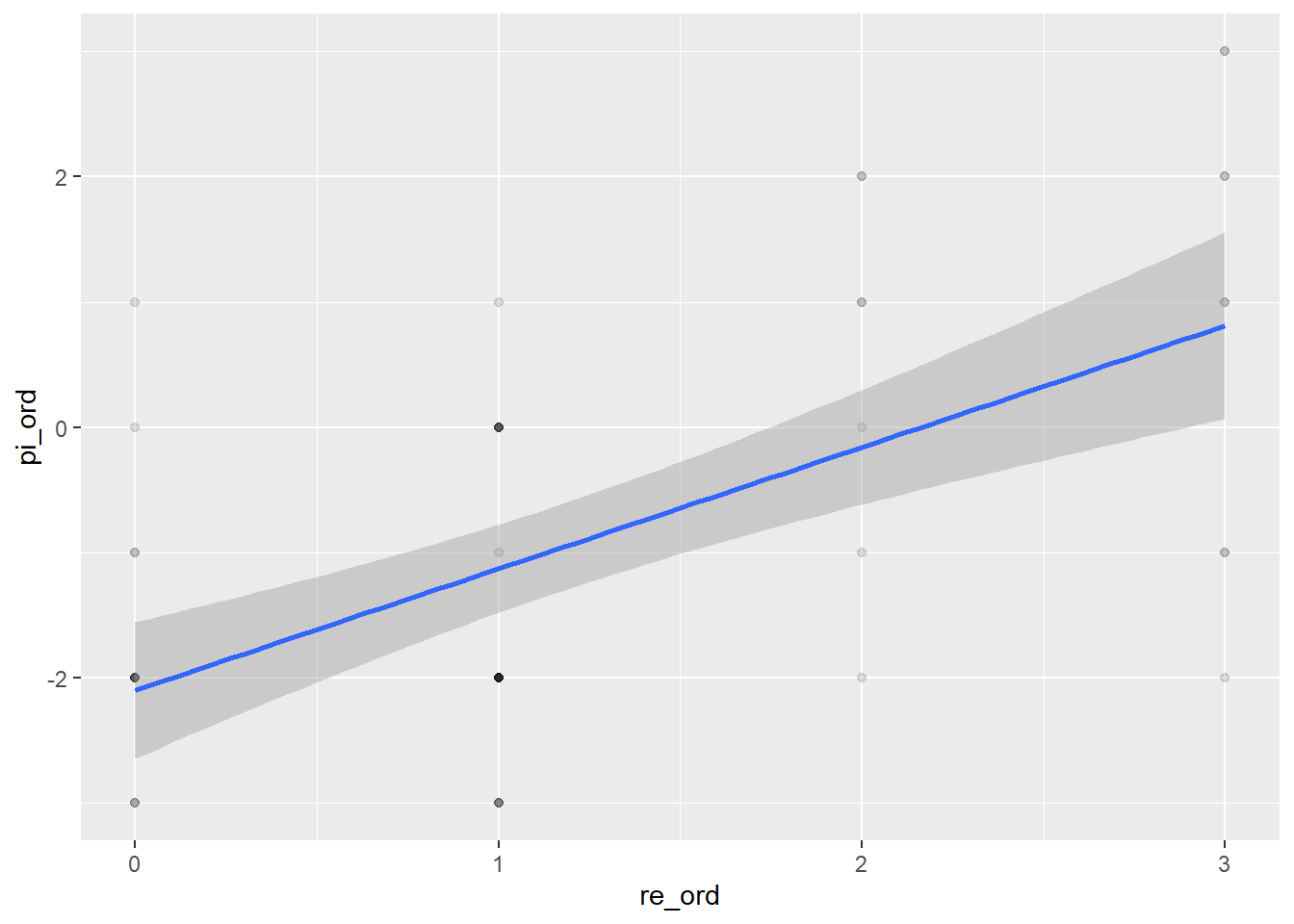
student_survey <- student.survey %>%mutate(pi_ord =case_when( pi =="very liberal"~-3, pi =="liberal"~-2, pi =="slightly liberal"~-1, pi =="moderate"~0, pi =="slightly conservative"~1, pi =="conservative"~2, pi =="very conservative"~3 )) %>%mutate(re_ord =case_when( re =="never"~0, re =="occasionally"~1, re =="most weeks"~2, re =="every week"~3 ))
summary(lm(pi_ord ~ re_ord, data = student_survey))
Call:
lm(formula = pi_ord ~ re_ord, data = student_survey)
Residuals:
Min 1Q Median 3Q Max
-2.81243 -0.87160 0.09882 1.12840 3.09882
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.0988 0.2717 -7.724 1.78e-10 ***
re_ord 0.9704 0.1792 5.416 1.22e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.345 on 58 degrees of freedom
Multiple R-squared: 0.3359, Adjusted R-squared: 0.3244
F-statistic: 29.34 on 1 and 58 DF, p-value: 1.221e-06
A one-point ordinal increase in church attendance, based upon this response scale, corresponds to nearly a one-point ordinal increase in conservative ideology, with zero church attendance (“Never”) corresponding to a “Liberal” ideology, all to a strong level of statistical significance.
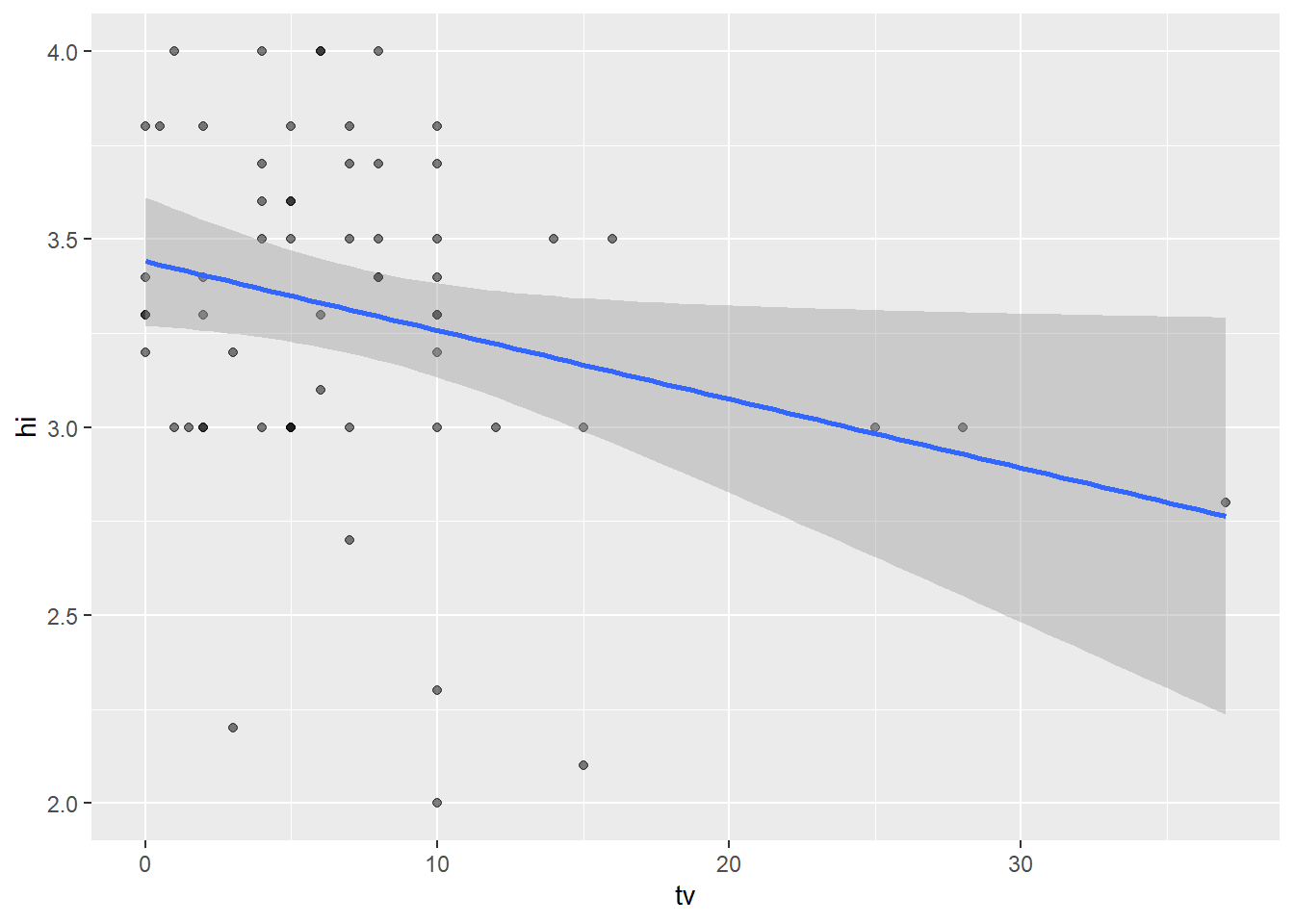
summary(lm(hi ~ tv, data = student_survey))
Call:
lm(formula = hi ~ tv, data = student_survey)
Residuals:
Min 1Q Median 3Q Max
-1.2583 -0.2456 0.0417 0.3368 0.7051
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.441353 0.085345 40.323 <2e-16 ***
tv -0.018305 0.008658 -2.114 0.0388 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4467 on 58 degrees of freedom
Multiple R-squared: 0.07156, Adjusted R-squared: 0.05555
F-statistic: 4.471 on 1 and 58 DF, p-value: 0.03879
Each additional hour of TV watched corresponds to a roughly 0.02 point decrease in a student’s high school GPA. However, there are a few outliers, particularly along the predictor variable, that may skew this result.