1.) Using LungCapData, answer descriptive questions about the data and its distributions.
2.) Use the given distribution to answer questions about the probability of discrete events.
Task 1 - LungCapData
Loading the Data
Code
#| include: false#| label: Loading in LungCap og_lungcap <- readxl::read_xls("_data/LungCapData.xls")# Quick look at dataset# glimpse(og_lungcap)# Variables - 3<dbl> ratio 3<char> (can coerce to logical if needed), # length(which(is.na(og_lungcap)))# No missing values to consider# Descriptive# summarytools::dfSummary(og_lungcap)
LungCapData: Describes the lung capacity of a population of 725 children aged 3 - 19. It further categorizes the subjects by height, sex, smoking habits, and whether they were birthed using the Caesarean section technique.
In the following sections, we’ll use select(), group_by(), filter(), and summarize() to further explore the data and find important relations between variables.
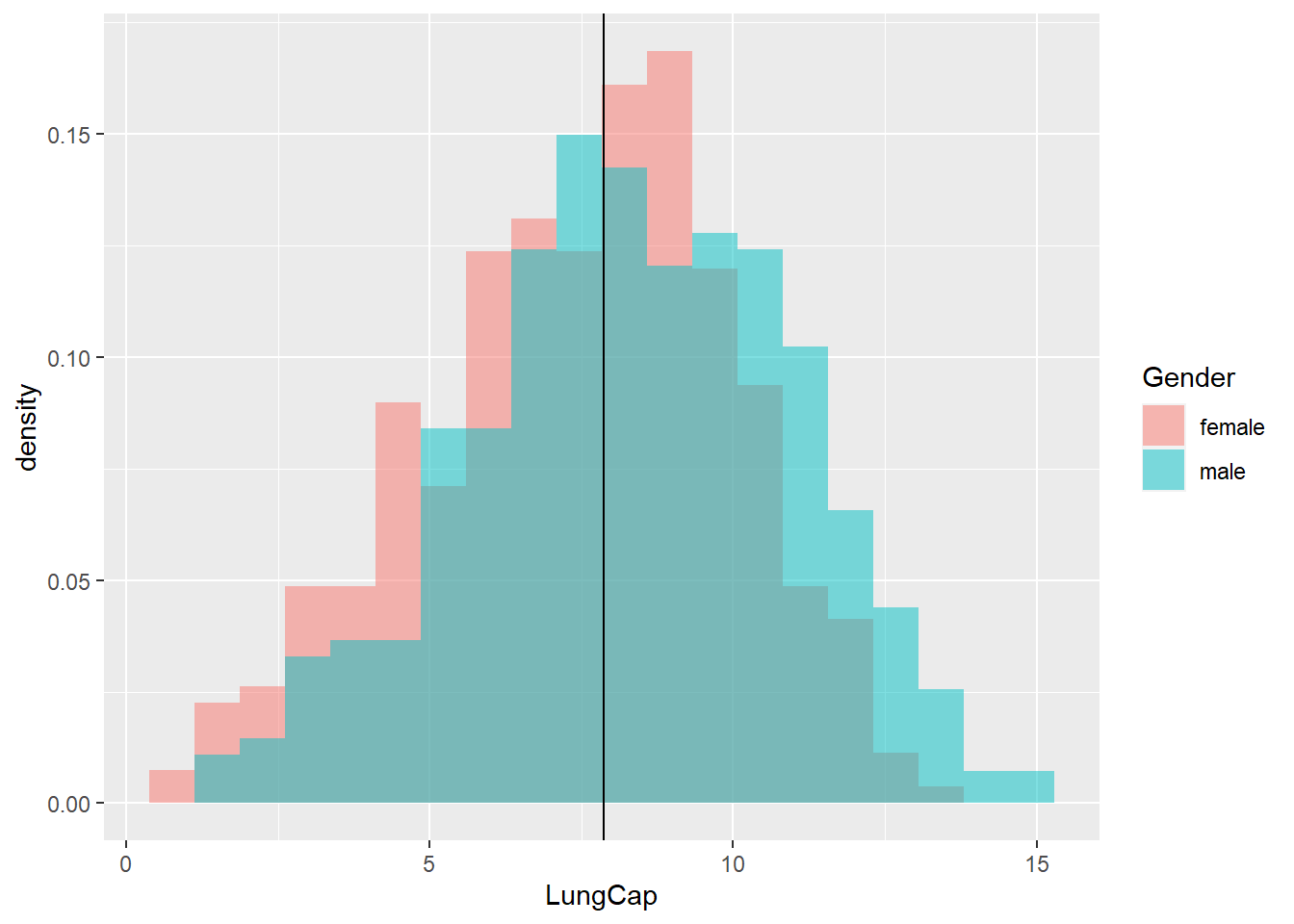
a) LungCap Histogram
LungCap looks to be approximately normally distributed (unimodal, symmetric) with most observations centered around the mean (7.86).
Package ggplot2 functions ggplot() and geom_histogram() are used to display the LungCap distribution filled by the Gender variable. Both density plots center on the mean, indicating both male and female lung capacity observations are highly concentrated around the mean. The male distribution is shifted slightly to the right of the female distribution, meaning male observations had a higher upper range value than female observations. Males had more observations concentrated to the right of the mean, and the female distribution reciprocated this effect to the left of the mean.
# A tibble: 2 × 2
Smoke `mean(LungCap)`
<chr> <dbl>
1 no 7.77
2 yes 8.65
After creating a new dataset smokers by using group_by() on our original data, smokers is piped into a summarize() call. The results surprisingly show that the smoking group had a higher mean lung capacity than the nonsmoking group. This is likely due to a mean age difference within the groups.
d) e) Smoking and Lung Capacity: Within Age Groupings
Code
# Creating Age Groups Using Case Whensmokers_age <- smokers %>%mutate(AgeGroup =case_when(Age >=18~"18+", Age ==16| Age ==17~"16-17", Age ==14| Age ==15~"14-15", Age <=13~"Under 13"))# Mean LungCap by Age and Smoke# Must regroup by Smoke againsmokers_age %>%group_by(AgeGroup, Smoke) %>%summarize(mean(LungCap))
# A tibble: 8 × 3
# Groups: AgeGroup [4]
AgeGroup Smoke `mean(LungCap)`
<chr> <chr> <dbl>
1 14-15 no 9.14
2 14-15 yes 8.39
3 16-17 no 10.5
4 16-17 yes 9.38
5 18+ no 11.1
6 18+ yes 10.5
7 Under 13 no 6.36
8 Under 13 yes 7.20
After using mutate() to add a column AgeGroup to a copy of smokers, group_by() groups the new dataset by AgeGroup and Smoke before piping it into a summarize() command to find the grouped means of LungCap by AgeGroupandSmoke.
The results show that for children above the age of 13, smokers had a lower mean lung capacity than non-smokers. However, for the 13 and under group, we again see results that imply smokers have greater lung capacity than nonsmokers. Let’s investigate further into the relationship between age and lung capacity to explain this quizzical result.
f) Lung Capacity and Age
Code
cov(og_lungcap$Age, og_lungcap$LungCap)
[1] 8.738289
Code
cor(og_lungcap$Age, og_lungcap$LungCap)
[1] 0.8196749
Code
#GGPlot of Age vs Lungggplot(og_lungcap, aes(x=Age, y=LungCap)) +geom_point()
Age and LungCap have a high covariance which leads to a high correlation (p=0.82). This strong positive value (-1<p<1) indicates these variables “vary greatly” together: when Age is high in the data, so is LungCap. We cannot say that an increase in Age causes an increase Lung capacity without first showing this through regression; however, our results show the variables are highly correlated.
We can use knowledge of the human body to infer that as our body ages, our lungs mature. The ages of smokers of the Under 13 group are likely highly left skewed, as I don’t expect many children under 10 to be smoking. This underlying age distribution explains our puzzling results from the previous section.
# Finding probability of inmate having exactly 2 prior convictions#Column Index is 3 as the first column is 0#Surely there is a cleaner way to do this using tidyverse functions rather than base?# aa <- xdist['prob',3] a
prob
0.1975309
b) P(X<2)
Code
#bb <-sum(xdist['prob',1:2])b
[1] 0.6938272
c) P(x<=2)
Code
# cc <- a + bc
prob
0.891358
d) P(x>2)
Code
#dd <-1- cd
prob
0.108642
e) E(X)
[1] 1.28642
f) Variance and SD
Variance
Code
# Var= E(X^2) - E(X)^2# Again using brute force because cannot use var() function on the object xdist correctlyvar_x <-sum((x_val^2)*prob) - ex^2var_x
[1] 0.8562353
Standard Deviation
[1] 0.9253298
Source Code
---title: "Homework 1 Solution"author: "Dane Shelton"description: "Intro to Quant Analysis Homework 1"date: "10/1/22"editor: visualformat: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - hw1 - shelton---# Homework 1 Tasks:1.) Using LungCapData, answer descriptive questions about the data and its distributions.2.) Use the given distribution to answer questions about the probability of discrete events.```{r}#| label: Setup#| include: false#Loading Librarieslibrary(tidyverse)library(summarytools)```## Task 1 - LungCapData### Loading the Data```{r}#| include: false#| label: Loading in LungCap og_lungcap <- readxl::read_xls("_data/LungCapData.xls")# Quick look at dataset# glimpse(og_lungcap)# Variables - 3<dbl> ratio 3<char> (can coerce to logical if needed), # length(which(is.na(og_lungcap)))# No missing values to consider# Descriptive# summarytools::dfSummary(og_lungcap)```LungCapData: Describes the lung capacity of a population of 725 children aged 3 - 19. It further categorizes the subjects by height, sex, smoking habits, and whether they were birthed using the Caesarean section technique.In the following sections, we'll use `select()`, `group_by()`, `filter()`, and `summarize()` to further explore the data and find important relations between variables.### a) LungCap Histogram```{r}#| label: Histogram of LungCap#| echo: false#| output: true# Using GGPLOT to plot a histogram of variable - LungCapggplot(og_lungcap, aes(x=LungCap, y=..density..)) +geom_histogram(bins=20) +geom_vline(aes(xintercept=mean(LungCap)))````LungCap` looks to be approximately normally distributed (unimodal, symmetric) with most observations centered around the mean (7.86).### b) LungCap Histogram: by Gender```{r}#| label: Histogram by Gender#| include: truehist_gender <-ggplot(og_lungcap, aes(x=LungCap, y=..density.., fill=Gender)) +geom_histogram(alpha=.5, position="identity", bins=20)+geom_vline(aes(xintercept=mean(LungCap)))hist_gender```Package ggplot2 functions `ggplot()` and `geom_histogram()` are used to display the `LungCap` distribution filled by the `Gender` variable. Both density plots center on the mean, indicating both male and female lung capacity observations are highly concentrated around the mean. The male distribution is shifted slightly to the right of the female distribution, meaning male observations had a higher upper range value than female observations. Males had more observations concentrated to the right of the mean, and the female distribution reciprocated this effect to the left of the mean.### c) Smoking and Lung Capacity```{r}#| label: Smoker v Non Smoker group_by#| output: truesmokers <-group_by(og_lungcap, Smoke)smokers %>%summarize(mean(LungCap))```After creating a new dataset `smokers` by using `group_by()` on our original data, `smokers` is piped into a `summarize()` call. The results surprisingly show that the smoking group had a higher mean lung capacity than the nonsmoking group. This is likely due to a mean age difference within the groups.### d) e) Smoking and Lung Capacity: Within Age Groupings```{r}#| label: Age Groupings#| include: true#| warning: false# Creating Age Groups Using Case Whensmokers_age <- smokers %>%mutate(AgeGroup =case_when(Age >=18~"18+", Age ==16| Age ==17~"16-17", Age ==14| Age ==15~"14-15", Age <=13~"Under 13"))# Mean LungCap by Age and Smoke# Must regroup by Smoke againsmokers_age %>%group_by(AgeGroup, Smoke) %>%summarize(mean(LungCap))```After using `mutate()` to add a column `AgeGroup` to a copy of `smokers`, `group_by()` groups the new dataset by `AgeGroup` and `Smoke` before piping it into a `summarize()` command to find the grouped means of `LungCap` by `AgeGroup` *and* `Smoke`.The results show that for children above the age of 13, smokers had a lower mean lung capacity than non-smokers. However, for the 13 and under group, we again see results that imply smokers have greater lung capacity than nonsmokers. Let's investigate further into the relationship between age and lung capacity to explain this quizzical result.### f) Lung Capacity and Age```{r}#| label: Corr()and Cov() of Lung Capacity and Age#| output: truecov(og_lungcap$Age, og_lungcap$LungCap)cor(og_lungcap$Age, og_lungcap$LungCap)#GGPlot of Age vs Lungggplot(og_lungcap, aes(x=Age, y=LungCap)) +geom_point()```Age and LungCap have a high covariance which leads to a high correlation (p=0.82). This strong positive value (-1\<p\<1) indicates these variables "vary greatly" together: when Age is high in the data, so is LungCap. We cannot say that an increase in Age causes an increase Lung capacity without first showing this through regression; however, our results show the variables are highly correlated.We can use knowledge of the human body to infer that as our body ages, our lungs mature. The ages of smokers of the Under 13 group are likely highly left skewed, as I don't expect many children under 10 to be smoking. This underlying age distribution explains our puzzling results from the previous section.```{r}#| label: Age Means withing Aged Smoking Groups#| output: truesmokers_age%>%group_by(AgeGroup, Smoke) %>%summarize(mean(Age))```## Task 2 - Probability DistributionFirst, let's create two vectors: x_val and freq. Then, we'll use rbind() to create a table.```{r}#| label: Creating Vectors and Binding#| output: truex_val <-c(0,1,2,3,4)freq <-c(128,434,160,64,24)prob <- freq/sum(freq)xdist <-rbind(x_val,prob)xdist```### a) P(x=2)```{r}#| label: a) P(x=2)#| output: true#| warning: false# Finding probability of inmate having exactly 2 prior convictions#Column Index is 3 as the first column is 0#Surely there is a cleaner way to do this using tidyverse functions rather than base?# aa <- xdist['prob',3] a```### b) P(X\<2)```{r}#| label: b) P(x<2)#| output: true#| warning: false#bb <-sum(xdist['prob',1:2])b```### c) P(x\<=2)```{r}#| label: c) P(x<=2)#| output: true#| warning: false# cc <- a + bc```### d) P(x\>2)```{r}#| label: d) P(x>2)#| output: true#| warning: false#dd <-1- cd```### e) E(X)```{r}#| label: E(X)#| output: true#| echo: falseex <-sum(x_val*prob)ex```### f) Variance and SD#### Variance```{r}#| label: Var#| output: true#| echo: true# Var= E(X^2) - E(X)^2# Again using brute force because cannot use var() function on the object xdist correctlyvar_x <-sum((x_val^2)*prob) - ex^2var_x```#### Standard Deviation```{r}#| label: std#| output: true#| echo: false# SD = sqrt(var)sd <-sqrt(var_x)sd```

and Cov() of Lung Capacity and Age-1.png)