County Year Homeless (Count) Population
Length:201 Min. :2018 Min. : 0.0 Min. : 8367
Class :character 1st Qu.:2018 1st Qu.: 11.0 1st Qu.: 28089
Mode :character Median :2019 Median : 151.0 Median : 130642
Mean :2019 Mean : 427.8 Mean : 317746
3rd Qu.:2020 3rd Qu.: 563.0 3rd Qu.: 367471
Max. :2020 Max. :3516.0 Max. :2864600
Unemployment Rate Median Inc Incarceration (Rateper1000) Poverty (Count)
Min. : 2.100 Min. :34583 Min. : 0.60 Min. : 906
1st Qu.: 3.400 1st Qu.:41401 1st Qu.: 2.50 1st Qu.: 4901
Median : 4.000 Median :50640 Median : 3.40 Median : 16210
Mean : 4.697 Mean :51116 Mean : 3.84 Mean : 42922
3rd Qu.: 5.600 3rd Qu.:58093 3rd Qu.: 4.50 3rd Qu.: 46034
Max. :13.500 Max. :83803 Max. :18.60 Max. :482656
Drug Arrests (Count) Relocated (Rate) Sub Abuse Enrollment (Count)
Min. : 13 Min. : 4.689 Min. : 5.0
1st Qu.: 225 1st Qu.:11.244 1st Qu.: 76.0
Median : 729 Median :12.700 Median : 250.0
Mean : 1558 Mean :13.288 Mean : 877.6
3rd Qu.: 1903 3rd Qu.:14.544 3rd Qu.:1030.0
Max. :13038 Max. :22.553 Max. :6272.0
Adult Psych Beds (Count) Severe Housing Problems (Rate) Forcible Sex (Count)
Min. : 0.00 Min. : 9.6 Min. : 0.0
1st Qu.: 0.00 1st Qu.:13.3 1st Qu.: 14.0
Median : 0.00 Median :15.4 Median : 45.0
Mean : 66.26 Mean :15.8 Mean : 170.5
3rd Qu.: 84.00 3rd Qu.:17.3 3rd Qu.: 225.0
Max. :778.00 Max. :29.8 Max. :1408.0
NA's :134
Foster Care (Count)
Min. : 3.0
1st Qu.: 33.0
Median : 153.0
Mean : 326.1
3rd Qu.: 353.0
Max. :2289.0
Final Project: Part 2 (Update)
Florida Homelessness by County 2018-2020
finalpart2
shelton
homelessness
Homelessness in Florida
Homelessness is a complex living situation with several qualifying conditions; at its most simple state, the U.S Dept. of Housing and Urban Development defines it as lacking a fixed, regular nighttime residence (not a shelter) or having a nighttime residence not designed for human accommodation1.
On a single night in 2020, over 500,0002 people experienced homelessness in the United States. Florida, with the third largest state population , had the fourth largest homeless population of 2020 with 27,4872.
Florida counties represent a large age range and varying demographic profiles; the state is a hub to a variety of industries including tourism, defense, agriculture, and information technology. Investigating homelessness in Florida counties with robust data can lead to several conclusions about who is being impacted where, and how state policy is failing groups of a diverse population.
Carole Zugazaga’s 2004 study of 54 single homeless men, 54 single homeless women, and 54 homeless women with children in the Central Florida area investigated stressful life events common among homeless people. The interviews revealed that women were more likely to have been sexually or physically assaulted, while men were more likely to have been incarcerated or abuse drugs/alcohol. Homeless women with children were more likely to be in foster care as a youth.
Nearly a decade later,county-level data can be used to investigate the relationship between Zugazaga’s reported stressful life events (incarceration, drug arrests, poverty, forcible sex…)3 and homelessness counts.
Homelessness is not a new issue in the United States, yet homeless policy targets elimination via criminalization rather than prevention. Despite state and federal governments being aware of the circumstances that increase vulnerability to homelessness for decades, I anticipate all of the variables to remain significant in a model relating stressors to Florida homelessness counts 2018-2020.
The data florida_1820.csv4 describes population, homelessness counts, poverty counts and several other demographic indicators3 at the county level for 2018-2020. All 67 Florida counties have observations for the 3 years giving us 201 observations of 15 variables. Each observation provides a count of each variables from a single county for a year within 2018-2020.
The data were collected from the Florida Department of Health. Variable names3 were used as search indicators to produce counts for Florida counties. Unfortunately, we cannot accurately analyze the effect of COVID-19 as data is incomplete for the majority of counties in 2021.
Expanding Intro to Data exposes summary statistics including mean, range, quantiles, and standard deviation for all 15 variables. The table below the summaries provides arranged figures for basic parameters of interest grouped by county.
LATER: Plots, Isolate more variables of interest with grouping, group by year?
on Assumption of Validity
While over 10 variables are predicting Homeless (Rate) across Florida counties, there are still limitations when attempting to comment on the magnitude of an individual stressor. Stressors influence homelessness by driving those in severe situations out of their home or away from their place of origin. Homeless (Rate) is not an ideal measure of magnitude as the homeless population migrating to escape or avoid certain stressors would result in counties with low stressor values having a higher homeless population; this effect is left unexplained by the following models.
The variable
Relocated (Rate)is included as an attempt to control for new movement, however this doesn’t completely capture county-to-county migration.FL Charts has data that records Population Who Lived in a Different County One Year Earlier, however with the data spanning 2009-2014, using values recorded 4 years prior to our data isn’t desirable either.
The most appropriate data to accurately capture county-to-county migration is here via the US Census Bureau. The
-In, -Out, -Net...spreadsheet provides totals for each county in the United States and movement to all other US counties; unfortunately, this data is too complex to wrangle into the simple data setflorida_1820.csv.
on Assumption of Linearity
Code
# Fit 1: A Linear Regression Model With All Vars
# Checking Linearity of variables not supported by our literature
florida_matrix <- florida_og_rates %>%
select(-c('County',
'Year',
'Poverty (Rate)',
'Severe Housing Problems (Rate)',
'Sub Abuse Enrollment (Rate)',
'Drug Arrests (Rate)',
'Adult Psych Beds (Rate)',
'Foster Care (Rate)',
'Forcible Sex (Rate)' ))%>%
pairs()
Code
florida_matrixNULLA quick look at variables with a relationship to homelessness not mentioned in Zugazaga’s study, or those that needed further investigation are shown here to confirm that while the associations are weak, a linear approximation is appropriate.
Linear Regression Models
Fit 1: Diagnostics
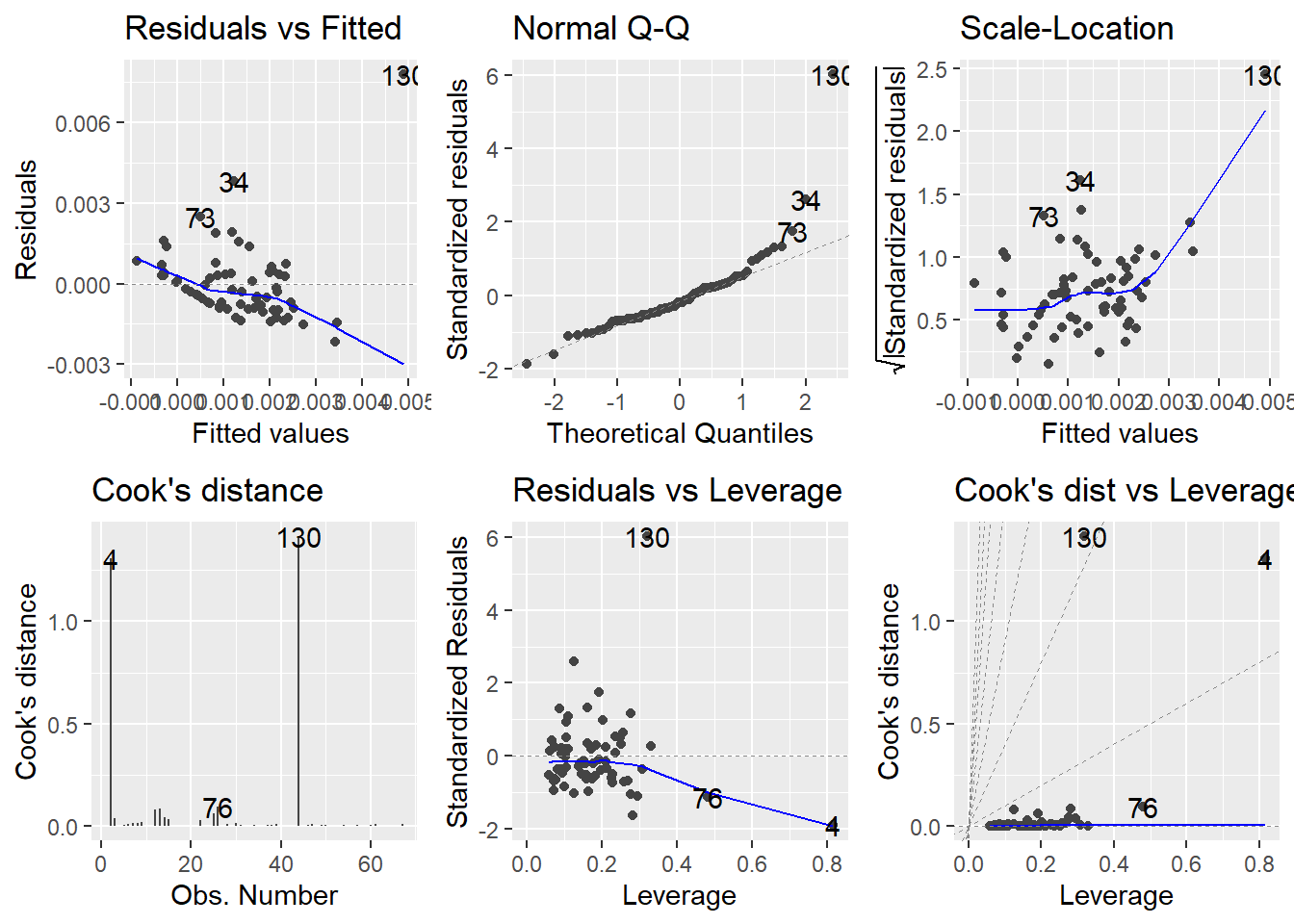
Fit 1does a poor job of obeying the assumptions regarding residuals of linear regression.Residuals vs Fittedshows the residuals increasing in size the greater the fitted value is, violating the linearity and independence assumption.As for residuals following an approximately normal distribution, the
Q-Q Plotshows a noticeable deviation from the diagonal.There are several points that could be considered outliers due to their residual or leverage value, how greatly they influence the points around them in the model.
Observations 16, 37, and 154 represent Miami-Dade and Broward County - two of the largest and most urbanized regions in the state. Pinellas County (154) is a top 10 county in terms of population.
Monroe County (130) has large positive residuals, indicating our model greatly under-estimated the number of homeless people in this county.
Model Selection
- Comparing Residuals Sum Squared, R^2, and BIC to evaluate
Fit 2versusFit 3, I would selectFit 2for both prediction and inference. Using all values, including interactions, and a log transformation results in the lowest RSS and BIC, and maximizes the Adjusted R-Squared. It provides the most appropriate diagnostic plots.
Interaction terms: Population:Unemployment Rate and Median Income:Poverty (Rate)
I assumed the influence of the unemployment rate would change at different population values. A small unemployment rate of 2% will not have the same effect on the outcome in a county of 100,000 as a 2% rate in a county of 2.5 million.
Our model found the impact of
Unemployment Ratewhen predicting homelessness in a county diminished asPopulationincreased.When considering the number of people living below the poverty line, it’s reasonable to believe the influence of number of citizens living below the poverty line will have a greater impact on homelessness in counties with lower median incomes.
Another negative slope, the model found the impact of
Median Incto decrease (taking it below zero) asPoverty (Rate)increases.
Research Question:
Using all of the values rather than just 2019 not only improves Residual Standard Error and Adjusted R-Squared value, it corrects the signs and magnitude of effects. Several more stressors were deemed significant at the
0.05and0.10level.All of Zugazaga’s effects had the correct sign demonstrating their influence in this model, but only
Foster CareandDrug Arrestswere significant at the0.05level as hypothesized. This significance is a comment on the mathematical properties of the model rather than on the real-life influence of the stressors.IncarcerationandForcible Sexare influential situations that can contribute to homelessness.Drug Arrestsagain has a negative slope, a concerning suggestion would be incarceration as a form of drug abuse intervention is decreasing homelessness; however,Incarceration Ratehas a large positive slope, dispelling this notion.- This result speaks more to recidivism rates in Florida’s communities as well as the challenge that is reintegrating into society after release. The negative slope still indicates drug abuse has a role in increasing homeless in Florida counties.
While the data is great illustration of homelessness in Florida by county, there are improvements that could be made to both data collection and the research question itself to further the study.
Data:
Unfortunately, FL Health Charts did not provide demographic breakdown for the homeless population (Age, Sex, Race), which would drastically widen the scope of the analysis, leading to far more interesting conclusions.
There is only have data for a three year period; this is too small of a range to make a strong statement about the impact of homeless policy on Florida counties or how the relevance of certain stressors has changed over time. For a more in depth study I would begin with a 10 year range.
Research Question:
Demographic breakdown of stressors’ impact (Age, Sex, Race)
Extend the question to the entire country, providing a breakdown by state
Compare to foreign countries to contrast governments’ approaches to homelessness and leading causes of homelessness around the world.
Variable Definitions and Collection Methods here
Carol Zugazaga R4DS LSR R packages?
Footnotes
2.) US Interagency Council on Homelessness
3.) Explanation of variables and collection method in Codebook tab