Import data into R and load the dplyr package to perform the following descriptive analysis on the two variables you are working with:
Start by first plotting the probability as well as cumulative density functions for each of your variables as shown in chapter 2. Instead of using sample() to generate a vector of probabilities, designate ‘probability’ to be the observations in your dataset. You may search online for simple ways to generate these plots for you data.
Group data by the two variables of interest to you (and relevance to the phenomenon you are interested in exploring) and obtain mean and standard deviation for at least one of the variables like in the example below. Please also print your results, as they will be important for your final writeup.
Split both of your variables like illustrated in the example below. You may use ‘greater than’ or ‘less than’ signs to split your data
Rename columns according to the splits you’ve made and obtain difference in means along with standard errors and confidence intervals like so:
Now generate a plot by first designating X and Y according to the variable you would assign as an independent variable (regressor or X) and which one as a dependent variable (Y) like so:
Carry out simple regression analysis that employs lm() function to generate results for the analysis
Generate plot that regresses you X variable on Y. Fit a line through the observations to capture the systematic relationship:
Source Code
---title: "Class Project 1"author: "Qasim Abbas"desription: "First iteration of the class project"date: "07/09/2023"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - final project - Qasim Abbas - dplyr---```{r}#| label: setup#| warning: falselibrary(tidyverse)library(dplyr)knitr::opts_chunk$set(echo =TRUE)```## Instructions1. Import data into R and load the `dplyr` package to perform the following descriptive analysis on the two variables you are working with: i) Start by first [plotting]{.underline} the probability as well as cumulative density functions for each of your variables as shown in chapter 2. Instead of using sample() to generate a vector of probabilities, designate ‘probability’ to be the observations in your dataset. You may search online for simple ways to generate these plots for you data. ii) Group data by the two variables of interest to you (and relevance to the phenomenon you are interested in exploring) and obtain mean and standard deviation for at least one of the variables like in the example below. Please also print your results, as they will be important for your final writeup. 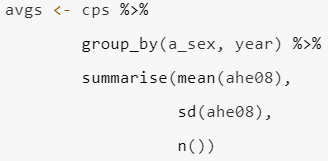{fig-align="center"} iii) Split both of your variables like illustrated in the example below. You may use ‘greater than’ or ‘less than’ signs to split your data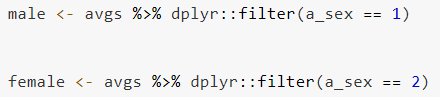{fig-align="center"} iv) Rename columns according to the splits you’ve made and obtain difference in means along with standard errors and confidence intervals like so:{fig-align="center"} v) Now generate a plot by first designating X and Y according to the variable you would assign as an independent variable (regressor or X) and which one as a dependent variable (Y) like so:{fig-align="center"}2. Carry out simple regression analysis that employs lm() function to generate results for the analysis i) Generate plot that regresses you X variable on Y. Fit a line through the observations to capture the systematic relationship:{fig-align="center"}




