This data set looks like a customer review collected by a company. It contains nearly 50,000 people’s review and each data distinguished by their id, neighborhood, and etc.
Univariate Visualizations
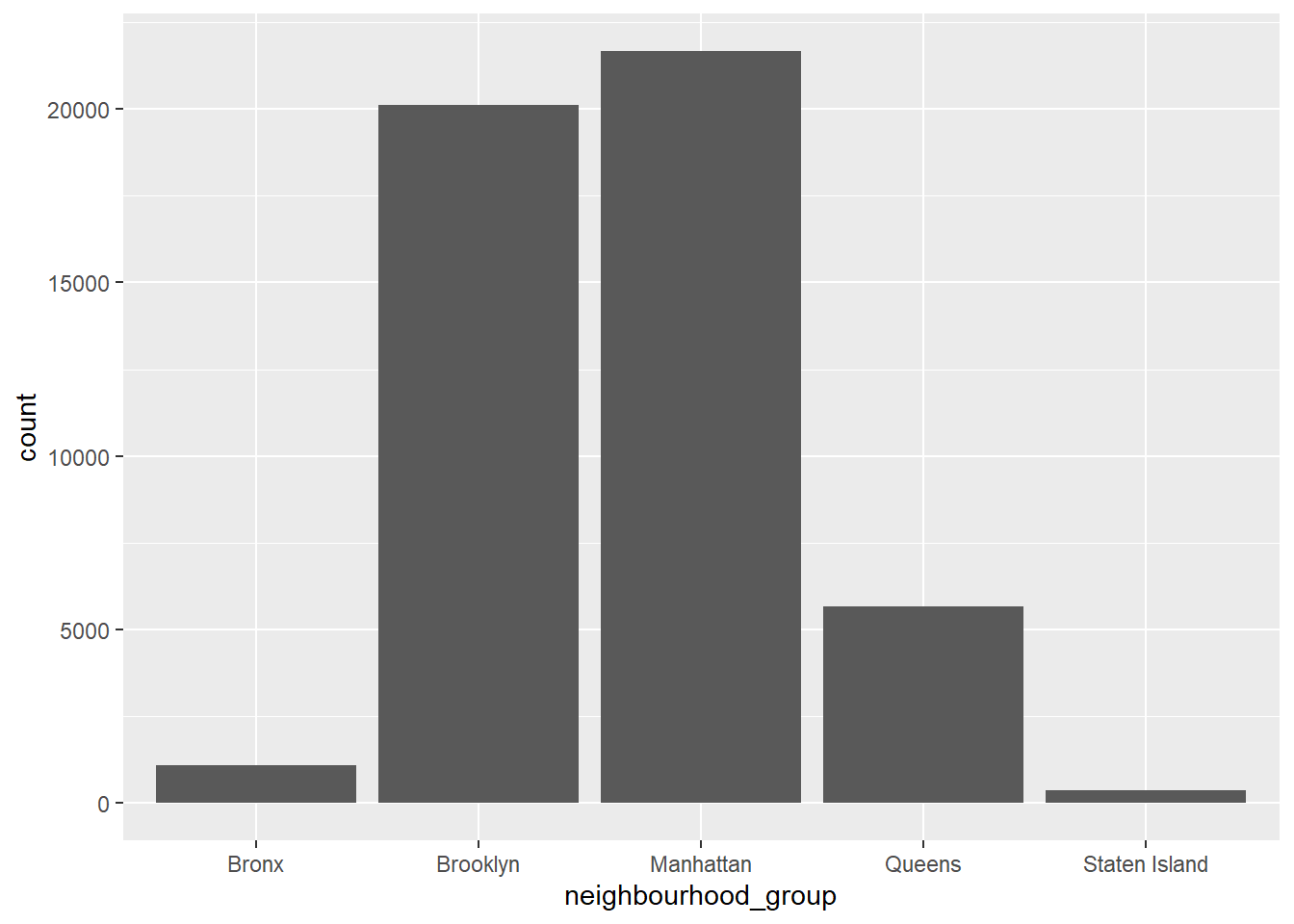
First of all, I took a look about their neighbourhood group. I choosed bar graph because it can be recognized easily.
count(ab_nyc, neighbourhood_group)
# A tibble: 5 × 2
neighbourhood_group n
<chr> <int>
1 Bronx 1091
2 Brooklyn 20104
3 Manhattan 21661
4 Queens 5666
5 Staten Island 373
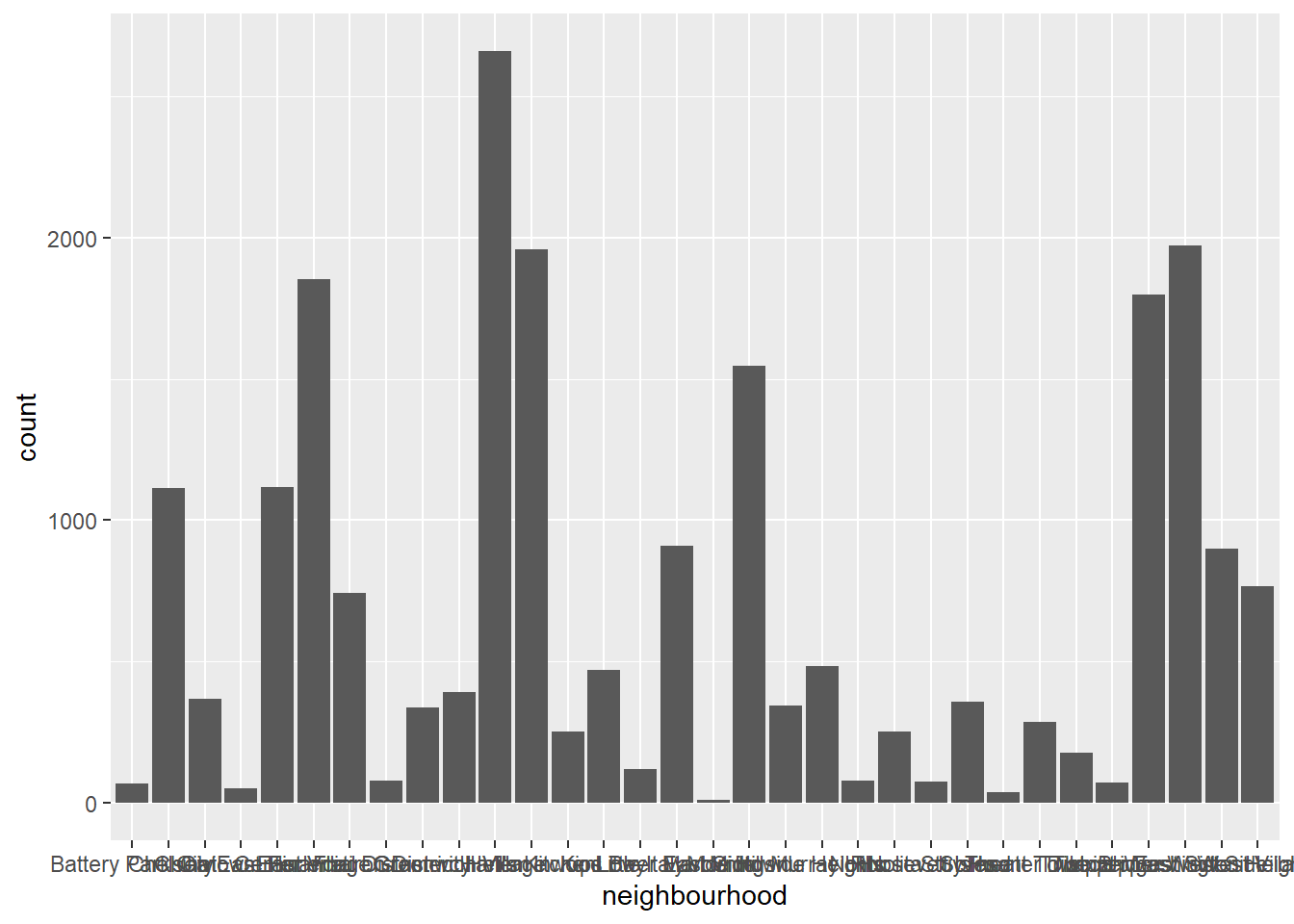
# A tibble: 32 × 2
neighbourhood n
<chr> <int>
1 Battery Park City 70
2 Chelsea 1113
3 Chinatown 368
4 Civic Center 52
5 East Harlem 1117
6 East Village 1853
7 Financial District 744
8 Flatiron District 80
9 Gramercy 338
10 Greenwich Village 392
# … with 22 more rows
32 neighbourhood are in the Manhattan and Harlem’s proportion is the largest.
Bivariate Visualization
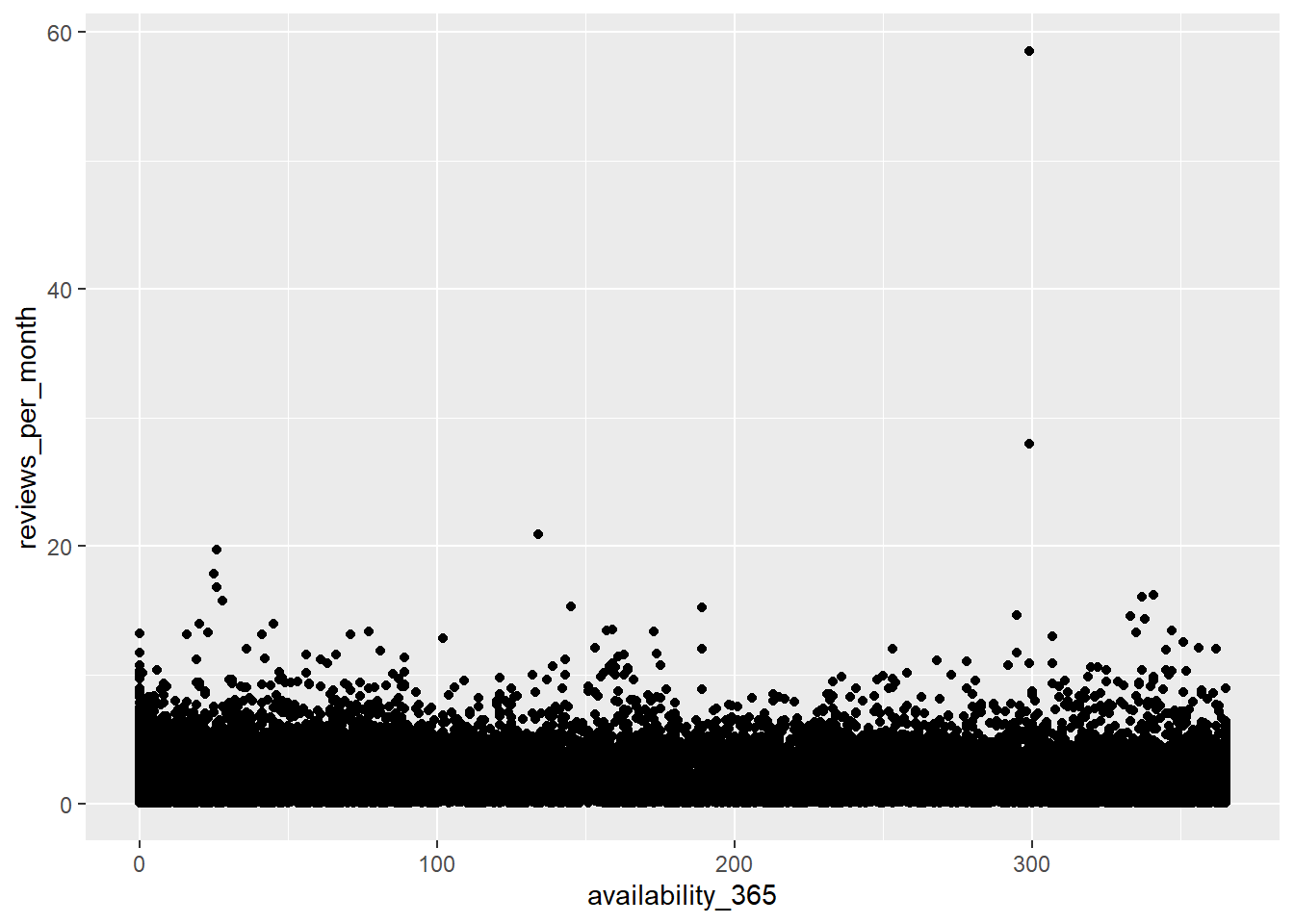
Now, I wondered whether availity and amount of review is related. So I made scatter plot regarding availity and reviews per month. I selected review per month to avoid distortion due to subscription period, etc.