| X
[numeric] |
| Mean (sd) : -92.9 (16.9) | | min ≤ med ≤ max: | | -176.6 ≤ -89.3 ≤ 144.9 | | IQR (CV) : 20.2 (-0.2) |
|
97136 distinct values |
 |
0
(0.0%) |
| Y
[numeric] |
| Mean (sd) : 37.8 (5.8) | | min ≤ med ≤ max: | | -14.3 ≤ 38.8 ≤ 71.3 | | IQR (CV) : 7.7 (0.2) |
|
97136 distinct values |
 |
0
(0.0%) |
| OBJECTID
[numeric] |
| Mean (sd) : 50365 (29078.1) | | min ≤ med ≤ max: | | 1 ≤ 50365 ≤ 100729 | | IQR (CV) : 50364 (0.6) |
|
100729 distinct values |
 |
0
(0.0%) |
| NCESSCH
[character] |
| 1. 010000500870 | | 2. 010000500871 | | 3. 010000500879 | | 4. 010000500889 | | 5. 010000501616 | | 6. 010000502150 | | 7. 010000600193 | | 8. 010000600872 | | 9. 010000600876 | | 10. 010000600877 | | [ 100719 others ] |
|
| 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 1 | ( | 0.0% | ) | | 100719 | ( | 100.0% | ) |
|
 |
0
(0.0%) |
| NMCNTY
[character] |
| 1. Los Angeles County | | 2. Cook County | | 3. Maricopa County | | 4. Harris County | | 5. Orange County | | 6. Jefferson County | | 7. Montgomery County | | 8. Washington County | | 9. Wayne County | | 10. Dallas County | | [ 1949 others ] |
|
| 2264 | ( | 2.2% | ) | | 1388 | ( | 1.4% | ) | | 1256 | ( | 1.2% | ) | | 1142 | ( | 1.1% | ) | | 1074 | ( | 1.1% | ) | | 980 | ( | 1.0% | ) | | 888 | ( | 0.9% | ) | | 848 | ( | 0.8% | ) | | 817 | ( | 0.8% | ) | | 814 | ( | 0.8% | ) | | 89258 | ( | 88.6% | ) |
|
 |
0
(0.0%) |
| SURVYEAR
[character] |
1. 2017-2018 |
|
 |
0
(0.0%) |
| STABR
[character] |
| 1. CA | | 2. TX | | 3. NY | | 4. FL | | 5. IL | | 6. MI | | 7. OH | | 8. PA | | 9. NC | | 10. NJ | | [ 46 others ] |
|
| 10323 | ( | 10.2% | ) | | 9320 | ( | 9.3% | ) | | 4808 | ( | 4.8% | ) | | 4375 | ( | 4.3% | ) | | 4245 | ( | 4.2% | ) | | 3734 | ( | 3.7% | ) | | 3610 | ( | 3.6% | ) | | 2990 | ( | 3.0% | ) | | 2691 | ( | 2.7% | ) | | 2595 | ( | 2.6% | ) | | 52038 | ( | 51.7% | ) |
|
 |
0
(0.0%) |
| LEAID
[character] |
| 1. 7200030 | | 2. 0622710 | | 3. 1709930 | | 4. 1200390 | | 5. 3200060 | | 6. 1200180 | | 7. 1200870 | | 8. 1500030 | | 9. 4823640 | | 10. 1201500 | | [ 17451 others ] |
|
| 1121 | ( | 1.1% | ) | | 1009 | ( | 1.0% | ) | | 655 | ( | 0.7% | ) | | 537 | ( | 0.5% | ) | | 381 | ( | 0.4% | ) | | 336 | ( | 0.3% | ) | | 320 | ( | 0.3% | ) | | 294 | ( | 0.3% | ) | | 284 | ( | 0.3% | ) | | 268 | ( | 0.3% | ) | | 95524 | ( | 94.8% | ) |
|
 |
0
(0.0%) |
| ST_LEAID
[character] |
| 1. PR-01 | | 2. CA-1964733 | | 3. IL-15-016-2990-25 | | 4. FL-13 | | 5. NV-02 | | 6. FL-06 | | 7. FL-29 | | 8. HI-001 | | 9. TX-101912 | | 10. FL-50 | | [ 17451 others ] |
|
| 1121 | ( | 1.1% | ) | | 1009 | ( | 1.0% | ) | | 655 | ( | 0.7% | ) | | 537 | ( | 0.5% | ) | | 381 | ( | 0.4% | ) | | 336 | ( | 0.3% | ) | | 320 | ( | 0.3% | ) | | 294 | ( | 0.3% | ) | | 284 | ( | 0.3% | ) | | 268 | ( | 0.3% | ) | | 95524 | ( | 94.8% | ) |
|
 |
0
(0.0%) |
| LEA_NAME
[character] |
| 1. PUERTO RICO DEPARTMENT OF | | 2. Los Angeles Unified | | 3. City of Chicago SD 299 | | 4. DADE | | 5. CLARK COUNTY SCHOOL DISTR | | 6. BROWARD | | 7. HILLSBOROUGH | | 8. Hawaii Department of Educ | | 9. HOUSTON ISD | | 10. PALM BEACH | | [ 17147 others ] |
|
| 1121 | ( | 1.1% | ) | | 1009 | ( | 1.0% | ) | | 655 | ( | 0.7% | ) | | 537 | ( | 0.5% | ) | | 381 | ( | 0.4% | ) | | 336 | ( | 0.3% | ) | | 320 | ( | 0.3% | ) | | 294 | ( | 0.3% | ) | | 284 | ( | 0.3% | ) | | 268 | ( | 0.3% | ) | | 95524 | ( | 94.8% | ) |
|
|
0
(0.0%) |
| SCH_NAME
[character] |
| 1. Lincoln Elementary School | | 2. Lincoln Elementary | | 3. Jefferson Elementary | | 4. Washington Elementary | | 5. Washington Elementary Sch | | 6. Central Elementary School | | 7. Jefferson Elementary Scho | | 8. Lincoln Elem School | | 9. Central High School | | 10. Roosevelt Elementary | | [ 88366 others ] |
|
| 64 | ( | 0.1% | ) | | 61 | ( | 0.1% | ) | | 53 | ( | 0.1% | ) | | 49 | ( | 0.0% | ) | | 46 | ( | 0.0% | ) | | 42 | ( | 0.0% | ) | | 33 | ( | 0.0% | ) | | 33 | ( | 0.0% | ) | | 32 | ( | 0.0% | ) | | 32 | ( | 0.0% | ) | | 100284 | ( | 99.6% | ) |
|
 |
0
(0.0%) |
| LSTREET1
[character] |
| 1. 6420 E. Broadway Blvd. Su | | 2. Box DOE | | 3. 2405 FAIRVIEW SCHOOL RD | | 4. 1820 XENIUM LN N | | 5. Main St | | 6. 335 ALTERNATIVE LN | | 7. 2101 N TWYMAN RD | | 8. 720 9TH AVE | | 9. 50 Moreland Rd. | | 10. 951 W Snowflake Blvd | | [ 92384 others ] |
|
| 33 | ( | 0.0% | ) | | 28 | ( | 0.0% | ) | | 22 | ( | 0.0% | ) | | 19 | ( | 0.0% | ) | | 13 | ( | 0.0% | ) | | 12 | ( | 0.0% | ) | | 11 | ( | 0.0% | ) | | 11 | ( | 0.0% | ) | | 10 | ( | 0.0% | ) | | 10 | ( | 0.0% | ) | | 100560 | ( | 99.8% | ) |
|
 |
0
(0.0%) |
| LSTREET2
[character] |
| 1. Suite B | | 2. Ste. 100 | | 3. P.O. Box 1497 | | 4. Suite A | | 5. Suite 200 | | 6. Building B | | 7. Ste. 102 | | 8. Ste. A | | 9. Suite 1 | | 10. SUITE 111 HART | | [ 482 others ] |
|
| 8 | ( | 1.4% | ) | | 7 | ( | 1.2% | ) | | 6 | ( | 1.0% | ) | | 6 | ( | 1.0% | ) | | 5 | ( | 0.8% | ) | | 4 | ( | 0.7% | ) | | 4 | ( | 0.7% | ) | | 4 | ( | 0.7% | ) | | 4 | ( | 0.7% | ) | | 4 | ( | 0.7% | ) | | 540 | ( | 91.2% | ) |
|
 |
100137
(99.4%) |
| LSTREET3
[logical] |
|
|
|
100729
(100.0%) |
| LCITY
[character] |
| 1. HOUSTON | | 2. Chicago | | 3. Los Angeles | | 4. BROOKLYN | | 5. SAN ANTONIO | | 6. Phoenix | | 7. BRONX | | 8. DALLAS | | 9. NEW YORK | | 10. Tucson | | [ 14624 others ] |
|
| 783 | ( | 0.8% | ) | | 664 | ( | 0.7% | ) | | 577 | ( | 0.6% | ) | | 569 | ( | 0.6% | ) | | 520 | ( | 0.5% | ) | | 446 | ( | 0.4% | ) | | 441 | ( | 0.4% | ) | | 378 | ( | 0.4% | ) | | 359 | ( | 0.4% | ) | | 330 | ( | 0.3% | ) | | 95662 | ( | 95.0% | ) |
|
 |
0
(0.0%) |
| LSTATE
[character] |
| 1. CA | | 2. TX | | 3. NY | | 4. FL | | 5. IL | | 6. MI | | 7. OH | | 8. PA | | 9. NC | | 10. NJ | | [ 45 others ] |
|
| 10325 | ( | 10.3% | ) | | 9320 | ( | 9.3% | ) | | 4808 | ( | 4.8% | ) | | 4377 | ( | 4.3% | ) | | 4245 | ( | 4.2% | ) | | 3736 | ( | 3.7% | ) | | 3610 | ( | 3.6% | ) | | 2990 | ( | 3.0% | ) | | 2693 | ( | 2.7% | ) | | 2595 | ( | 2.6% | ) | | 52030 | ( | 51.7% | ) |
|
 |
0
(0.0%) |
| LZIP
[character] |
| 1. 85710 | | 2. 10456 | | 3. 85364 | | 4. 78521 | | 5. 78572 | | 6. 78577 | | 7. 00731 | | 8. 10457 | | 9. 78539 | | 10. 60623 | | [ 22526 others ] |
|
| 53 | ( | 0.1% | ) | | 45 | ( | 0.0% | ) | | 44 | ( | 0.0% | ) | | 43 | ( | 0.0% | ) | | 42 | ( | 0.0% | ) | | 41 | ( | 0.0% | ) | | 39 | ( | 0.0% | ) | | 37 | ( | 0.0% | ) | | 37 | ( | 0.0% | ) | | 36 | ( | 0.0% | ) | | 100312 | ( | 99.6% | ) |
|
 |
0
(0.0%) |
| LZIP4
[character] |
| 1. 8888 | | 2. 1199 | | 3. 1299 | | 4. 9801 | | 5. 2099 | | 6. 1399 | | 7. 1699 | | 8. 1599 | | 9. 1499 | | 10. 1899 | | [ 8615 others ] |
|
| 899 | ( | 1.5% | ) | | 113 | ( | 0.2% | ) | | 111 | ( | 0.2% | ) | | 106 | ( | 0.2% | ) | | 104 | ( | 0.2% | ) | | 101 | ( | 0.2% | ) | | 100 | ( | 0.2% | ) | | 99 | ( | 0.2% | ) | | 94 | ( | 0.2% | ) | | 89 | ( | 0.2% | ) | | 57411 | ( | 96.9% | ) |
|
 |
41502
(41.2%) |
| PHONE
[character] |
| 1. (505)880-3744 | | 2. (520)225-6060 | | 3. (505)721-1051 | | 4. (480)461-4000 | | 5. (972)316-3663 | | 6. (505)527-5800 | | 7. (520)745-4588 | | 8. (480)497-3300 | | 9. (623)445-5000 | | 10. (480)484-6100 | | [ 91818 others ] |
|
| 141 | ( | 0.1% | ) | | 63 | ( | 0.1% | ) | | 36 | ( | 0.0% | ) | | 35 | ( | 0.0% | ) | | 34 | ( | 0.0% | ) | | 33 | ( | 0.0% | ) | | 33 | ( | 0.0% | ) | | 29 | ( | 0.0% | ) | | 28 | ( | 0.0% | ) | | 27 | ( | 0.0% | ) | | 100270 | ( | 99.5% | ) |
|
 |
0
(0.0%) |
| GSLO
[character] |
| 1. PK | | 2. KG | | 3. 09 | | 4. 06 | | 5. 07 | | 6. 05 | | 7. 03 | | 8. 04 | | 9. M | | 10. 01 | | [ 8 others ] |
|
| 31179 | ( | 31.0% | ) | | 23839 | ( | 23.7% | ) | | 16627 | ( | 16.5% | ) | | 12912 | ( | 12.8% | ) | | 5441 | ( | 5.4% | ) | | 2578 | ( | 2.6% | ) | | 1581 | ( | 1.6% | ) | | 1165 | ( | 1.2% | ) | | 1113 | ( | 1.1% | ) | | 964 | ( | 1.0% | ) | | 3330 | ( | 3.3% | ) |
|
 |
0
(0.0%) |
| GSHI
[character] |
| 1. 05 | | 2. 12 | | 3. 08 | | 4. 06 | | 5. 04 | | 6. 02 | | 7. 03 | | 8. PK | | 9. M | | 10. N | | [ 9 others ] |
|
| 28039 | ( | 27.8% | ) | | 26443 | ( | 26.3% | ) | | 21860 | ( | 21.7% | ) | | 10873 | ( | 10.8% | ) | | 3938 | ( | 3.9% | ) | | 1591 | ( | 1.6% | ) | | 1446 | ( | 1.4% | ) | | 1430 | ( | 1.4% | ) | | 1113 | ( | 1.1% | ) | | 796 | ( | 0.8% | ) | | 3200 | ( | 3.2% | ) |
|
 |
0
(0.0%) |
| VIRTUAL
[character] |
| 1. A virtual school | | 2. Missing | | 3. Not a virtual school | | 4. Not Applicable |
|
| 656 | ( | 0.7% | ) | | 183 | ( | 0.2% | ) | | 99049 | ( | 98.3% | ) | | 841 | ( | 0.8% | ) |
|
 |
0
(0.0%) |
| TOTFRL
[numeric] |
| Mean (sd) : 249.4 (275.2) | | min ≤ med ≤ max: | | -9 ≤ 178 ≤ 9626 | | IQR (CV) : 297 (1.1) |
|
1906 distinct values |
 |
0
(0.0%) |
| FRELCH
[numeric] |
| Mean (sd) : 221.6 (253.9) | | min ≤ med ≤ max: | | -9 ≤ 149 ≤ 7581 | | IQR (CV) : 272 (1.1) |
|
1765 distinct values |
 |
0
(0.0%) |
| REDLCH
[numeric] |
| Mean (sd) : 26 (36.9) | | min ≤ med ≤ max: | | -9 ≤ 16 ≤ 2045 | | IQR (CV) : 37 (1.4) |
|
399 distinct values |
 |
0
(0.0%) |
| PK
[numeric] |
| Mean (sd) : 34.8 (53.5) | | min ≤ med ≤ max: | | 0 ≤ 22 ≤ 1912 | | IQR (CV) : 43 (1.5) |
|
468 distinct values |
 |
64621
(64.2%) |
| KG
[numeric] |
| Mean (sd) : 65 (46.9) | | min ≤ med ≤ max: | | 0 ≤ 62 ≤ 948 | | IQR (CV) : 57 (0.7) |
|
393 distinct values |
 |
43684
(43.4%) |
| G01
[numeric] |
| Mean (sd) : 64.4 (44.8) | | min ≤ med ≤ max: | | 0 ≤ 62 ≤ 1408 | | IQR (CV) : 56 (0.7) |
|
353 distinct values |
 |
43333
(43.0%) |
| G02
[numeric] |
| Mean (sd) : 64.6 (44.4) | | min ≤ med ≤ max: | | 0 ≤ 63 ≤ 688 | | IQR (CV) : 56 (0.7) |
|
345 distinct values |
 |
43268
(43.0%) |
| G03
[numeric] |
| Mean (sd) : 66.4 (46.3) | | min ≤ med ≤ max: | | 0 ≤ 64 ≤ 783 | | IQR (CV) : 59 (0.7) |
|
358 distinct values |
 |
43253
(42.9%) |
| G04
[numeric] |
| Mean (sd) : 67.9 (48.7) | | min ≤ med ≤ max: | | 0 ≤ 65 ≤ 877 | | IQR (CV) : 61 (0.7) |
|
382 distinct values |
 |
43470
(43.2%) |
| G05
[numeric] |
| Mean (sd) : 69.7 (56.7) | | min ≤ med ≤ max: | | 0 ≤ 64 ≤ 985 | | IQR (CV) : 65 (0.8) |
|
494 distinct values |
 |
44673
(44.3%) |
| G06
[numeric] |
| Mean (sd) : 91.5 (108.4) | | min ≤ med ≤ max: | | 0 ≤ 56 ≤ 1155 | | IQR (CV) : 111 (1.2) |
|
641 distinct values |
 |
58585
(58.2%) |
| G07
[numeric] |
| Mean (sd) : 102.7 (126.2) | | min ≤ med ≤ max: | | 0 ≤ 52 ≤ 1439 | | IQR (CV) : 153 (1.2) |
|
687 distinct values |
 |
63682
(63.2%) |
| G08
[numeric] |
| Mean (sd) : 101.9 (127.1) | | min ≤ med ≤ max: | | 0 ≤ 50 ≤ 1608 | | IQR (CV) : 152 (1.2) |
|
700 distinct values |
 |
63449
(63.0%) |
| G09
[numeric] |
| Mean (sd) : 124.7 (185.8) | | min ≤ med ≤ max: | | 0 ≤ 40 ≤ 2799 | | IQR (CV) : 166 (1.5) |
|
987 distinct values |
 |
68499
(68.0%) |
| G10
[numeric] |
| Mean (sd) : 120.4 (178.1) | | min ≤ med ≤ max: | | 0 ≤ 39 ≤ 1837 | | IQR (CV) : 157 (1.5) |
|
945 distinct values |
 |
68706
(68.2%) |
| G11
[numeric] |
| Mean (sd) : 115.4 (170.1) | | min ≤ med ≤ max: | | 0 ≤ 40 ≤ 1719 | | IQR (CV) : 149 (1.5) |
|
914 distinct values |
 |
68720
(68.2%) |
| G12
[numeric] |
| Mean (sd) : 114.1 (165.5) | | min ≤ med ≤ max: | | 0 ≤ 43 ≤ 2580 | | IQR (CV) : 150 (1.5) |
|
891 distinct values |
 |
68814
(68.3%) |
| G13
[logical] |
|
|
 |
100692
(100.0%) |
| TOTAL
[numeric] |
| Mean (sd) : 515.7 (450.2) | | min ≤ med ≤ max: | | 0 ≤ 434 ≤ 14286 | | IQR (CV) : 408 (0.9) |
|
2945 distinct values |
 |
2229
(2.2%) |
| MEMBER
[numeric] |
| Mean (sd) : 515.6 (449.9) | | min ≤ med ≤ max: | | 0 ≤ 434 ≤ 14286 | | IQR (CV) : 408 (0.9) |
|
2944 distinct values |
|
2229
(2.2%) |
| AM
[numeric] |
| Mean (sd) : 6.7 (30.3) | | min ≤ med ≤ max: | | 0 ≤ 1 ≤ 1395 | | IQR (CV) : 4 (4.5) |
|
424 distinct values |
 |
20609
(20.5%) |
| HI
[numeric] |
| Mean (sd) : 142.5 (240.6) | | min ≤ med ≤ max: | | 0 ≤ 49 ≤ 4677 | | IQR (CV) : 160 (1.7) |
|
1745 distinct values |
 |
3852
(3.8%) |
| BL
[numeric] |
| Mean (sd) : 83 (151.4) | | min ≤ med ≤ max: | | 0 ≤ 19 ≤ 5088 | | IQR (CV) : 90 (1.8) |
|
1166 distinct values |
 |
8325
(8.3%) |
| WH
[numeric] |
| Mean (sd) : 247.9 (275.1) | | min ≤ med ≤ max: | | 0 ≤ 182 ≤ 8146 | | IQR (CV) : 312 (1.1) |
|
1839 distinct values |
 |
3993
(4.0%) |
| HP
[numeric] |
| Mean (sd) : 3.1 (24.7) | | min ≤ med ≤ max: | | 0 ≤ 0 ≤ 1394 | | IQR (CV) : 2 (8) |
|
305 distinct values |
 |
30008
(29.8%) |
| TR
[numeric] |
| Mean (sd) : 20.7 (27.3) | | min ≤ med ≤ max: | | 0 ≤ 12 ≤ 1228 | | IQR (CV) : 24 (1.3) |
|
307 distinct values |
 |
7137
(7.1%) |
| FTE
[numeric] |
| Mean (sd) : 32.6 (25.6) | | min ≤ med ≤ max: | | 0 ≤ 27.6 ≤ 1419 | | IQR (CV) : 24 (0.8) |
|
10066 distinct values |
 |
5233
(5.2%) |
| LATCOD
[numeric] |
| Mean (sd) : 37.8 (5.8) | | min ≤ med ≤ max: | | -14.3 ≤ 38.8 ≤ 71.3 | | IQR (CV) : 7.7 (0.2) |
|
96746 distinct values |
 |
0
(0.0%) |
| LONCOD
[numeric] |
| Mean (sd) : -92.9 (16.9) | | min ≤ med ≤ max: | | -176.6 ≤ -89.3 ≤ 144.9 | | IQR (CV) : 20.2 (-0.2) |
|
96911 distinct values |
 |
0
(0.0%) |
| ULOCALE
[character] |
| 1. 21-Suburb: Large | | 2. 11-City: Large | | 3. 41-Rural: Fringe | | 4. 42-Rural: Distant | | 5. 13-City: Small | | 6. 43-Rural: Remote | | 7. 32-Town: Distant | | 8. 12-City: Mid-size | | 9. 33-Town: Remote | | 10. 22-Suburb: Mid-size | | [ 2 others ] |
|
| 26772 | ( | 26.6% | ) | | 14851 | ( | 14.7% | ) | | 11179 | ( | 11.1% | ) | | 10279 | ( | 10.2% | ) | | 6635 | ( | 6.6% | ) | | 6412 | ( | 6.4% | ) | | 6266 | ( | 6.2% | ) | | 5876 | ( | 5.8% | ) | | 4138 | ( | 4.1% | ) | | 3305 | ( | 3.3% | ) | | 5016 | ( | 5.0% | ) |
|
 |
0
(0.0%) |
| STUTERATIO
[numeric] |
| Mean (sd) : 16.9 (85.7) | | min ≤ med ≤ max: | | 0 ≤ 15.3 ≤ 22350 | | IQR (CV) : 5.3 (5.1) |
|
3854 distinct values |
 |
6835
(6.8%) |
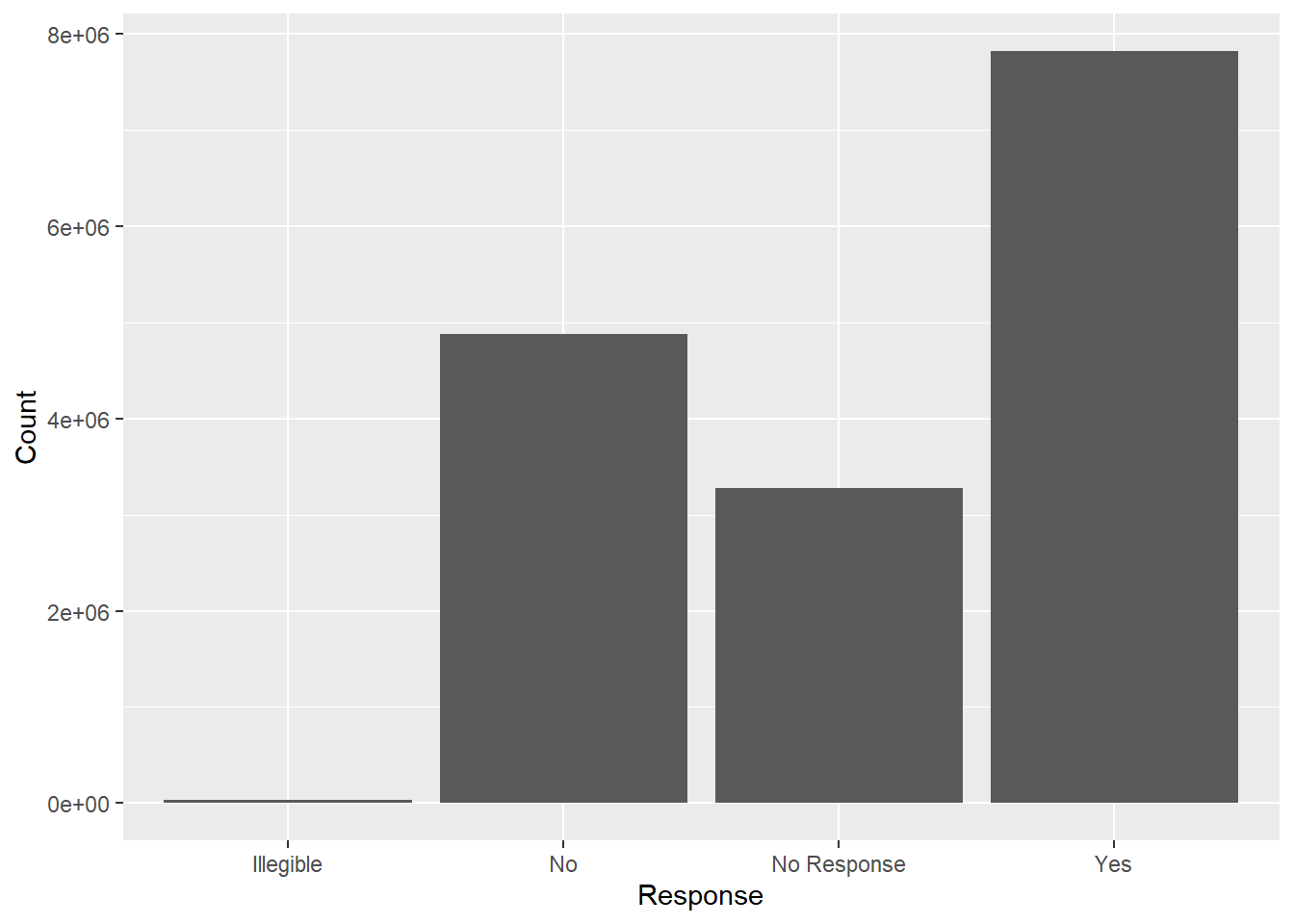
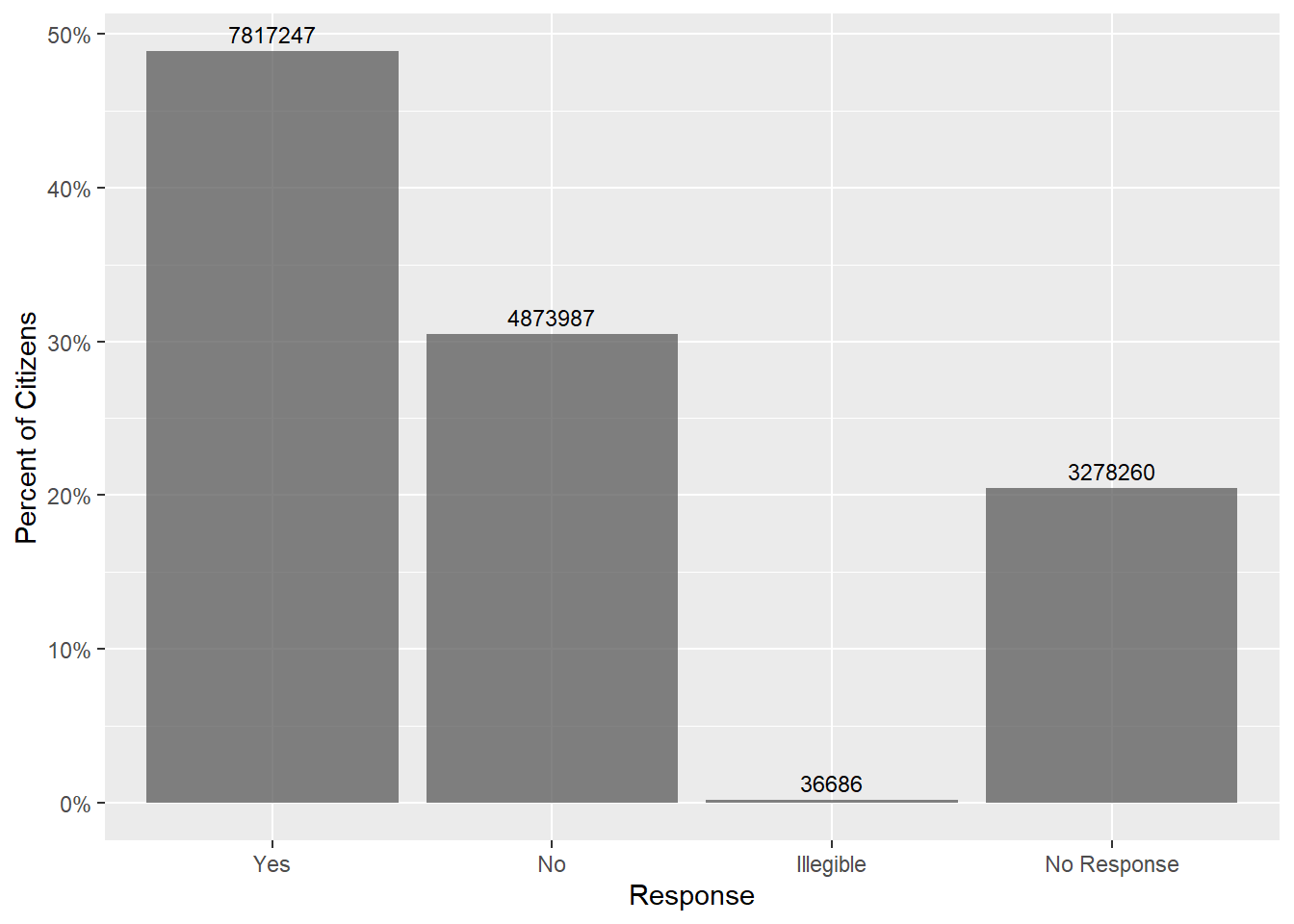
| STITLEI
[character] |
| 1. Missing | | 2. No | | 3. Not Applicable | | 4. Yes |
|
| 864 | ( | 0.9% | ) | | 14596 | ( | 14.5% | ) | | 29199 | ( | 29.0% | ) | | 56070 | ( | 55.7% | ) |
|
 |
0
(0.0%) |
| AMALM
[numeric] |
| Mean (sd) : 3.7 (16.1) | | min ≤ med ≤ max: | | 0 ≤ 1 ≤ 743 | | IQR (CV) : 2 (4.4) |
|
268 distinct values |
 |
26365
(26.2%) |
| AMALF
[numeric] |
| Mean (sd) : 3.6 (15.5) | | min ≤ med ≤ max: | | 0 ≤ 1 ≤ 652 | | IQR (CV) : 2 (4.4) |
|
263 distinct values |
 |
26708
(26.5%) |
| ASALM
[numeric] |
| Mean (sd) : 15.9 (45.2) | | min ≤ med ≤ max: | | 0 ≤ 3 ≤ 1997 | | IQR (CV) : 11 (2.8) |
|
522 distinct values |
 |
16162
(16.0%) |
| ASALF
[numeric] |
| Mean (sd) : 15.1 (42.5) | | min ≤ med ≤ max: | | 0 ≤ 3 ≤ 1532 | | IQR (CV) : 11 (2.8) |
|
495 distinct values |
 |
16080
(16.0%) |
| HIALM
[numeric] |
| Mean (sd) : 73.7 (123.5) | | min ≤ med ≤ max: | | 0 ≤ 25 ≤ 2292 | | IQR (CV) : 83 (1.7) |
|
1073 distinct values |
 |
4774
(4.7%) |
| HIALF
[numeric] |
| Mean (sd) : 70.5 (118.7) | | min ≤ med ≤ max: | | 0 ≤ 24 ≤ 2461 | | IQR (CV) : 79 (1.7) |
|
1047 distinct values |
 |
5121
(5.1%) |
| BLALM
[numeric] |
| Mean (sd) : 43.5 (77.3) | | min ≤ med ≤ max: | | 0 ≤ 11 ≤ 2473 | | IQR (CV) : 48 (1.8) |
|
687 distinct values |
 |
10801
(10.7%) |
| BLALF
[numeric] |
| Mean (sd) : 42.1 (76.8) | | min ≤ med ≤ max: | | 0 ≤ 10 ≤ 2615 | | IQR (CV) : 46 (1.8) |
|
693 distinct values |
 |
11485
(11.4%) |
| WHALM
[numeric] |
| Mean (sd) : 128.6 (140.5) | | min ≤ med ≤ max: | | 0 ≤ 95 ≤ 3854 | | IQR (CV) : 160 (1.1) |
|
1046 distinct values |
 |
4502
(4.5%) |
| WHALF
[numeric] |
| Mean (sd) : 120.8 (135.6) | | min ≤ med ≤ max: | | 0 ≤ 88 ≤ 4292 | | IQR (CV) : 152 (1.1) |
|
1030 distinct values |
 |
4682
(4.6%) |
| HPALM
[numeric] |
| Mean (sd) : 1.7 (13.4) | | min ≤ med ≤ max: | | 0 ≤ 0 ≤ 751 | | IQR (CV) : 1 (7.9) |
|
210 distinct values |
 |
34182
(33.9%) |
| HPALF
[numeric] |
| Mean (sd) : 1.6 (12.2) | | min ≤ med ≤ max: | | 0 ≤ 0 ≤ 643 | | IQR (CV) : 1 (7.7) |
|
212 distinct values |
 |
34563
(34.3%) |
| TRALM
[numeric] |
| Mean (sd) : 10.8 (13.9) | | min ≤ med ≤ max: | | 0 ≤ 6 ≤ 512 | | IQR (CV) : 13 (1.3) |
|
174 distinct values |
 |
9200
(9.1%) |
| TRALF
[numeric] |
| Mean (sd) : 10.5 (14) | | min ≤ med ≤ max: | | 0 ≤ 6 ≤ 716 | | IQR (CV) : 12 (1.3) |
|
183 distinct values |
 |
9477
(9.4%) |
| TOTMENROL
[numeric] |
| Mean (sd) : 264.9 (229) | | min ≤ med ≤ max: | | 0 ≤ 224 ≤ 6890 | | IQR (CV) : 210 (0.9) |
|
1691 distinct values |
 |
2296
(2.3%) |
| TOTFENROL
[numeric] |
| Mean (sd) : 251.1 (222.8) | | min ≤ med ≤ max: | | 0 ≤ 211 ≤ 7396 | | IQR (CV) : 200 (0.9) |
|
1646 distinct values |
 |
2362
(2.3%) |
| STATUS
[numeric] |
| Mean (sd) : 1.1 (0.6) | | min ≤ med ≤ max: | | 1 ≤ 1 ≤ 8 | | IQR (CV) : 0 (0.5) |
|
| 1 | : | 98557 | ( | 97.8% | ) | | 3 | : | 1103 | ( | 1.1% | ) | | 4 | : | 77 | ( | 0.1% | ) | | 5 | : | 110 | ( | 0.1% | ) | | 6 | : | 500 | ( | 0.5% | ) | | 7 | : | 341 | ( | 0.3% | ) | | 8 | : | 41 | ( | 0.0% | ) |
|
 |
0
(0.0%) |
| UG
[numeric] |
| Mean (sd) : 11.2 (33.6) | | min ≤ med ≤ max: | | 0 ≤ 2 ≤ 1017 | | IQR (CV) : 10 (3) |
|
217 distinct values |
 |
88689
(88.0%) |
| AE
[logical] |
|
|
 |
100665
(99.9%) |
| SCHOOL_TYPE_TEXT
[character] |
| 1. Alternative/other school | | 2. Regular school | | 3. Special education school | | 4. Vocational school |
|
| 5531 | ( | 5.5% | ) | | 91737 | ( | 91.1% | ) | | 1948 | ( | 1.9% | ) | | 1513 | ( | 1.5% | ) |
|
 |
0
(0.0%) |
| SY_STATUS_TEXT
[character] |
| 1. Currently operational | | 2. New school | | 3. School has changed agency | | 4. School has reopened | | 5. School temporarily closed | | 6. School to be operational | | 7. School was operational bu |
|
| 98557 | ( | 97.8% | ) | | 1103 | ( | 1.1% | ) | | 110 | ( | 0.1% | ) | | 41 | ( | 0.0% | ) | | 500 | ( | 0.5% | ) | | 341 | ( | 0.3% | ) | | 77 | ( | 0.1% | ) |
|
 |
0
(0.0%) |
| SCHOOL_LEVEL
[character] |
| 1. Adult Education | | 2. Elementary | | 3. High | | 4. Middle | | 5. Not Applicable | | 6. Not Reported | | 7. Other | | 8. Prekindergarten | | 9. Secondary | | 10. Ungraded |
|
| 28 | ( | 0.0% | ) | | 53287 | ( | 52.9% | ) | | 22977 | ( | 22.8% | ) | | 16506 | ( | 16.4% | ) | | 796 | ( | 0.8% | ) | | 1113 | ( | 1.1% | ) | | 3824 | ( | 3.8% | ) | | 1430 | ( | 1.4% | ) | | 602 | ( | 0.6% | ) | | 166 | ( | 0.2% | ) |
|
 |
0
(0.0%) |
| AS
[numeric] |
| Mean (sd) : 29.8 (85.8) | | min ≤ med ≤ max: | | 0 ≤ 5 ≤ 3529 | | IQR (CV) : 21 (2.9) |
|
850 distinct values |
 |
12717
(12.6%) |
| CHARTER_TEXT
[character] |
| 1. No | | 2. Not Applicable | | 3. Yes |
|
| 87007 | ( | 86.4% | ) | | 6387 | ( | 6.3% | ) | | 7335 | ( | 7.3% | ) |
|
 |
0
(0.0%) |
| MAGNET_TEXT
[character] |
| 1. Missing | | 2. No | | 3. Not Applicable | | 4. Yes |
|
| 6256 | ( | 6.2% | ) | | 77531 | ( | 77.0% | ) | | 13520 | ( | 13.4% | ) | | 3422 | ( | 3.4% | ) |
|
 |
0
(0.0%) |