library(tidyverse)
library(googlesheets4)
knitr::opts_chunk$set(echo = TRUE)UMass Admissions Data
reading data
Reading in multiple sheets with two categories
UMass Admissions Data
Historical UMass admissions data, and data on the number of majors, are available in excel format from the University Analytics and Institutional Research Office. For this example, I transferred the excel workbooks into a google spreadsheet to read in using googlesheets4.
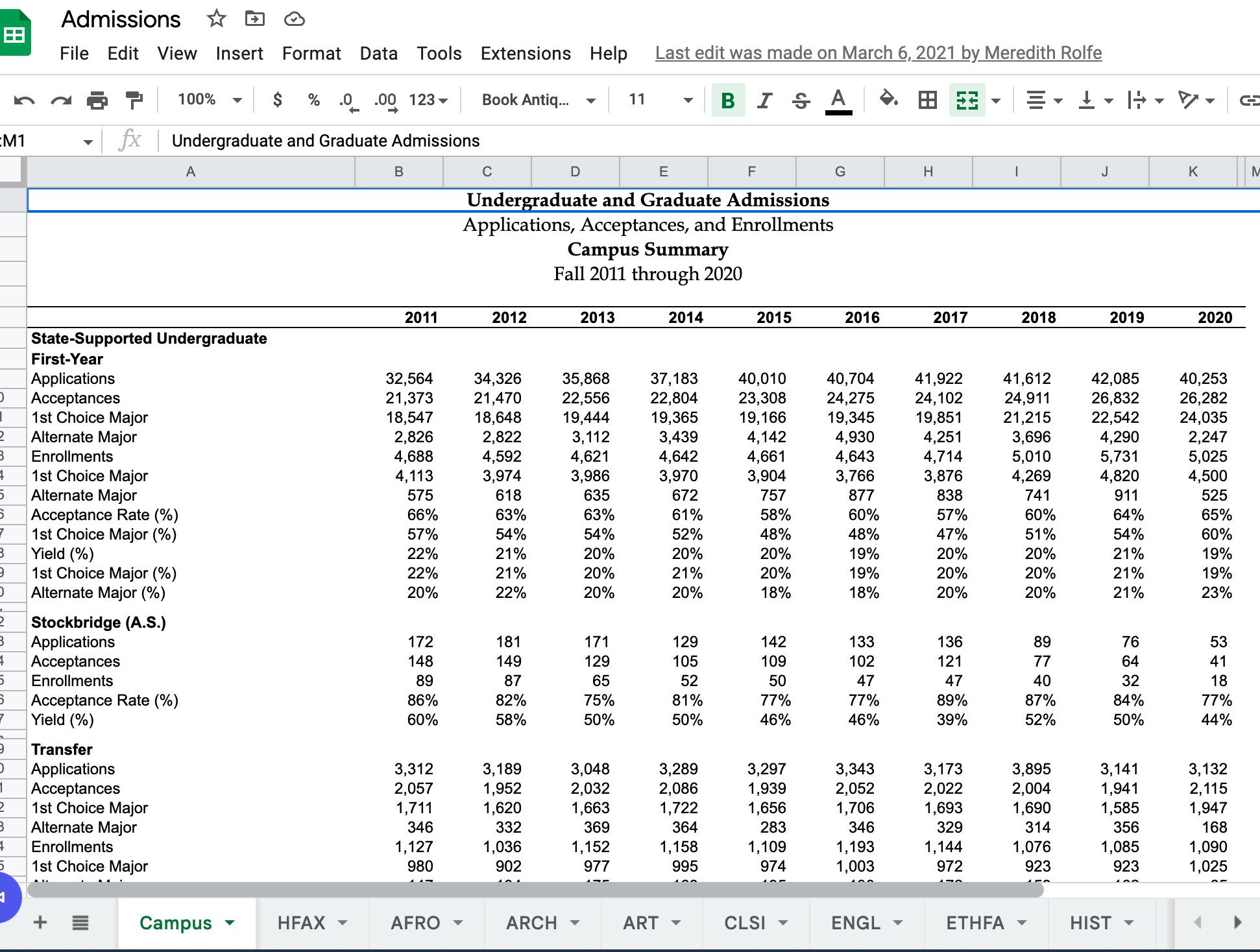
First, we will set up the base URLs to use to access the data from google sheets. You will need to change this to access your own googlesheet or excel spreadsheet. (and modify subsequent “read” commands.)
admissions.url <- gs4_get("https://docs.google.com/spreadsheets/d/1t-oEWdYCJndOSSW8dtn1dBC9U5-2KzjmL8cgbcPwDYs/edit?usp=sharing")ℹ Suitable tokens found in the cache, associated with these emails:• 'mrolfe@umass.edu'• 'mrrolfe@gmail.com' Defaulting to the first email.! Using an auto-discovered, cached token. To suppress this message, modify your code or options to clearly consent to
the use of a cached token. See gargle's "Non-interactive auth" vignette for more details: <https://gargle.r-lib.org/articles/non-interactive-auth.html>ℹ The googlesheets4 package is using a cached token for 'mrolfe@umass.edu'.majors.url <-gs4_get("https://docs.google.com/spreadsheets/d/1sezSHYMsNqjJSzteVD1cogRFb0o0RdnuBilgZ5Ul4c0/edit?usp=sharing")Create list of colleges and depts.
As can be viewed above, each workbook contains multiple sheets with the abbreviated name of the college or dept as the sheet name. Therefore, as a starting point for reading in the sheets, we need a list of them - much as we have done in the past using sheet_names. The difference this time is that we also need to recover which college each department belongs to, which we can guess based on the order in which the departments appear (after the colleges, whose abbreviations all end in “X”.) We need to remove the overall Campus totals and only keep the individual Department pages, but also be sure to retain the additional College column indicated which college each department belongs to.
dept_names<-sheet_names(admissions.url)
colleges <- c(dept_names[str_ends(dept_names, "X")])
colleges [1] "HFAX" "ICSX" "CNSX" "SBSX" "EDUX" "ENGX" "SOMX" "NURX" "PUBX" "OTHX"dept_names<-dept_names[dept_names!="Campus"]
#find the position of colleges (depts follow)
temp<-which(str_ends(dept_names, "X"))
temp<-temp[-1]-temp[-length(temp)]
temp<- c(temp, 5)
depts<-tibble(college = unlist(map2(colleges, temp, rep)),
dept = dept_names)%>%
filter(!str_ends(dept, "X"))
deptsRead in dept. information
The general format of a department page can vary based on which programs are offered by the department. For example, we can see from the screenshot above that there are four categories of State-Supported Undergraduate admissions: First-Year, Stockbridge (A.S.), Transfer, Post-graduate; two categories of State-Supported Graduate admissions: Master’s and Doctoral; and three categories of University Without Walls (online or CPE) admissions: Undergraduate (Transfer and Post-graduate), Master’s, and Doctoral. Essentially, we have four critical pieces of information in the first column of each department sheet.
- mode: Campus or Online (UWW)
- degree: Undergraduate, Master’s or Doctoral
- ug_type: First-Year, Transfer, Stockbridge, or Post-graduate
- count (Applications, Acceptances, and Enrollments)
Note that both acceptance rate and yield could be easily calculated from the first three statistics provided, or could be kept. Our goal now will be to develop a function to read in data from a single sheet, and reshape it so that the counts are variables while the years (currently presented as column names) are in a column. This reshaping will make it easier to caluculate growth rates and other overtime information.
dept_info<-read_sheet(admissions.url$spreadsheet_id,
sheet = depts$dept[1], skip=6,
col_names = c("X1", 2011:2020))
end <- grep("Definitions", dept_info$X1)-1
dept_info <- dept_info[1:end,]%>%
filter(!is.na(X1))
dept_infoWe now have a condensed data set read in with the correct column names, but need to break X1 into multiple columns with the correct information.
mode_terms <-c("State-Supported Undergraduate",
"State-Supported Graduate",
"University Without Walls")
degree_terms<-c("State-Supported Undergraduate",
"Master's", "Doctoral")
ug_cats<-c("First-Year", "Stockbridge (A.S.)", "Transfer",
"Post-graduate")
counts<-c("Applications", "Enrollments", "Acceptances")
dept_info<-dept_info%>%
mutate(dept = depts$dept[1],
mode = ifelse(X1 %in% mode_terms, X1, NA),
degree = ifelse(X1 %in% degree_terms, X1, NA),
ug_cats = ifelse(X1 %in% ug_cats, X1, NA)
)%>%
fill(mode, degree, ug_cats)%>%
mutate(mode = ifelse(str_detect(mode, "State"),
"Campus", "Online"),
degree = ifelse(str_detect(degree, "State"),
"Undergraduate", degree),
ug_cats = ifelse(str_detect(degree, "Undergraduate"),
ug_cats, NA),
counts = ifelse(X1%in%counts, X1, NA))%>%
filter(!is.na(counts))%>%
select(-X1)
dept_infoNow, this is looking much better! Now our final step is to swap the rows and columns by using both pivot_longer and pivot_wider.
dept_info<-dept_info%>%
pivot_longer(cols=starts_with("20"),
names_to = "year",
values_to = "value")%>%
pivot_wider(id_cols = c(dept, mode, degree, ug_cats, year),
names_from = "counts",
values_from = "value")
dept_infoTa da! We have all the information read in and the categorical variables are working and in the correct order. Now we can write a quick function using the steps above, and purrr:map it into a dataframe!
read.programs <-function(sheet.url= admissions.url,
dept.name){
dept_info<-read_sheet(admissions.url$spreadsheet_id,
sheet = dept.name,
range="A7:K85",
col_names = c("X1", 2011:2020))
end <- grep("Definitions", dept_info$X1)-1
dept_info <- dept_info[1:end,]%>%
filter(!is.na(X1))
dept_info<-dept_info%>%
mutate(dept = dept.name,
mode = ifelse(X1 %in% mode_terms, X1, NA),
degree = ifelse(X1 %in% degree_terms, X1, NA),
ug_cats = ifelse(X1 %in% ug_cats, X1, NA)
)%>%
fill(mode, degree, ug_cats)%>%
mutate(mode = ifelse(str_detect(mode, "State"),
"Campus", "Online"),
degree = ifelse(str_detect(degree, "State"),
"Undergraduate", degree),
ug_cats = ifelse(str_detect(degree, "Undergraduate"),
ug_cats, NA),
counts = ifelse(X1%in%counts, X1, NA))%>%
filter(!is.na(counts))%>%
select(-X1)
dept_info%>%
pivot_longer(cols=starts_with("20"),
names_to = "year",
values_to = "value")%>%
pivot_wider(id_cols = c(dept, mode, degree, ug_cats, year),
names_from = "counts",
values_from = "value")
}
admissions<-map_dfr(depts$dept,
~read.programs(admissions.url, .x))✔ Reading from "Admissions".✔ Range ''AFRO'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ARCH'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ART'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CLSI'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ENGL'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ETHFA'!A7:K85'.✔ Reading from "Admissions".✔ Range ''HIST'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ARTH'!A7:K85'.✔ Reading from "Admissions".✔ Range ''JUDA'!A7:K85'.✔ Reading from "Admissions".✔ Range ''LANG'!A7:K85'.✔ Reading from "Admissions".✔ Range ''LING'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MUS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PHIL'!A7:K85'.✔ Reading from "Admissions".✔ Range ''SVES'!A7:K85'.✔ Reading from "Admissions".✔ Range ''THEA'!A7:K85'.✔ Reading from "Admissions".✔ Range ''WOST'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CSCI'!A7:K85'.✔ Reading from "Admissions".✔ Range ''INFO'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ASTR'!A7:K85'.✔ Reading from "Admissions".✔ Range ''BIOC'!A7:K85'.✔ Reading from "Admissions".✔ Range ''BIOL'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CHEM'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CNSO'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ENVC'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ENVS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ETCNS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''FD S'!A7:K85'.✔ Reading from "Admissions".✔ Range ''GEO'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MATH'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MICB'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MC-B'!A7:K85'.✖ Request failed [429]. Retry 1 happens in 100.9 seconds ...✔ Reading from "Admissions".✔ Range ''NSB'!A7:K85'.✔ Reading from "Admissions".✔ Range ''OEB'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PHYS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PB'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PS E'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PSYC'!A7:K85'.✔ Reading from "Admissions".✔ Range ''SCI'!A7:K85'.✔ Reading from "Admissions".✔ Range ''STOC'!A7:K85'.✔ Reading from "Admissions".✔ Range ''VETS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ANTH'!A7:K85'.✔ Reading from "Admissions".✔ Range ''COMM'!A7:K85'.✔ Reading from "Admissions".✔ Range ''DACS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ECON'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ETSBS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''JOUR'!A7:K85'.✔ Reading from "Admissions".✔ Range ''LARP'!A7:K85'.✔ Reading from "Admissions".✔ Range ''POLS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PUBA'!A7:K85'.✔ Reading from "Admissions".✔ Range ''RESE'!A7:K85'.✔ Reading from "Admissions".✔ Range ''STPE'!A7:K85'.✔ Reading from "Admissions".✔ Range ''SOCI'!A7:K85'.✔ Reading from "Admissions".✔ Range ''EDUC'!A7:K85'.✔ Reading from "Admissions".✔ Range ''EPRA'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ETEDU'!A7:K85'.✔ Reading from "Admissions".✔ Range ''SDPS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''TECS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''BME'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CH E'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CEE'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ECE'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ENGI'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MIE'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ACCT'!A7:K85'.✖ Request failed [429]. Retry 1 happens in 100.9 seconds ...✔ Reading from "Admissions".✔ Range ''HTM'!A7:K85'.✔ Reading from "Admissions".✔ Range ''FIN'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MGT'!A7:K85'.✔ Reading from "Admissions".✔ Range ''MKTG'!A7:K85'.✔ Reading from "Admissions".✔ Range ''OIM'!A7:K85'.✔ Reading from "Admissions".✔ Range ''SOM'!A7:K85'.✔ Reading from "Admissions".✔ Range ''SPOR'!A7:K85'.✔ Reading from "Admissions".✔ Range ''BIEP'!A7:K85'.✔ Reading from "Admissions".✔ Range ''COMD'!A7:K85'.✔ Reading from "Admissions".✔ Range ''EHS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''ETPUB'!A7:K85'.✔ Reading from "Admissions".✔ Range ''HPP'!A7:K85'.✔ Reading from "Admissions".✔ Range ''KIN'!A7:K85'.✔ Reading from "Admissions".✔ Range ''NUTR'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PUB'!A7:K85'.✔ Reading from "Admissions".✔ Range ''PUBS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''BGS'!A7:K85'.✔ Reading from "Admissions".✔ Range ''BDIC'!A7:K85'.✔ Reading from "Admissions".✔ Range ''UWW'!A7:K85'.✔ Reading from "Admissions".✔ Range ''CA S'!A7:K85'.admissions_orig<-admissions%>%
left_join(depts)%>%
relocate(college, .before = dept)Joining, by = "dept"admissions_origAnd now we have all of the admissions data in a single R object, with the ability to easily filter and group by the various categorical information from the original sheets - including the type of program, mode, degree, department, and college.
Yield rate and accept rate can be recalulated easily, as can lags or growth using the following information.
admissions<-admissions_orig%>%
mutate(enroll_chg3yr = Enrollments - lag(Enrollments, n=3),
admit_rate = Acceptances/Applications,
yield_rate = Enrollments/Acceptances)
admissions