library(tidyverse)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 8
challenge_8
railroads
snl
audrey_bertin
Joining Data
For this challenge, I’ll be reading in and joining the snl ⭐⭐⭐⭐⭐ data.
There are three SNL datasets: actors, casts, and seasons.
We read them in below:
actors <- readr::read_csv("_data/snl_actors.csv")
casts <- readr::read_csv("_data/snl_casts.csv")
seasons <- readr::read_csv("_data/snl_seasons.csv")Tidying / Mutating Data
Actors
head(actors)The actors data has four columns:
- actor ID (
aid) - a url identifying them on the snl website – however, note that I tested a lot of these and they don’t actually seem to work (
url) - what type of role the person was (
type)
actors %>%
group_by(type) %>%
summarize(n = n())- their gender (
gender)
actors %>%
group_by(gender) %>%
summarize(n = n())Note that there is a gender here called “andy” that is very unclear. Doing a quick sanity check, some of the “andy” classified people are musical guests who are a group and some have a known gender identity (e.g. Peyton Manning). It’s unclear what this is representing, so to make it easy, and because there are relatively few marked “andy” we’ll just replace these with “unknown”.
We can make the following changes to clean this data up: - rename aid to actor_id to be more clear - remove the URL column that does not lead to functional web addresses - rename type to actor_type and convert it to a factor - rename gender to actor_gender, convert to factor, and replace “andy” with unknown
We do this below:
actors_clean <- actors %>%
mutate(
type = as_factor(type),
gender = as_factor(ifelse(gender == "andy", "unknown", gender))
) %>%
rename(actor_id = aid, actor_type = type, actor_gender = gender) %>%
select(-url)
head(actors_clean)Why are we renaming so many columns? One thing we need to pay attention to when preparing data to be joined is to make sure the columns have unique names across datasets except for the columns we are using as our join identifiers (in otherwords, other than unique ID columns, we don’t want any pair of columns with the same name in two datasets). If we don’t do this, we’ll end up with confusing columns like column_name_x/column_name_y and it’s not always obvious which data frame x belongs to and which one y belongs to. We’ll do the same with the other datasets.
Casts
Next we look at the casts data.
head(casts)This data table seems to link actors to the seasons they participated in. There is a row for each actor/each season they participated. This has the following columns:
- actor ID, same as the last dataset (
aid) - season ID (
sid) - an indicator column called
featuredwhich stores whether or not the actor classified as “featured” that season
casts %>%
group_by(featured) %>%
summarize(n = n())According to an online search, SNL uses a two-tiered system for classifying cast members. “Repertory Players” (featured == FALSE) are the top tier cast members who lead skits, while “Featured Players” (featured == TRUE) are the second tier. These cast members may show up in a skit or two but take on much smaller roles in the show. This column tells us which group each person was classified in on each season.
- first and last episode IDs (
first_epid,last_epid) - whether they were an anchor on the weekend update segment (
update_anchor) - the number of episodes they were in that season (
n_episodes) and what fraction of the total season that was (season_fraction)
We can clean this as follows: - rename aid to actor_id like the last dataset - rename sid to season_id - replace featured with season_role which will store “Featured” and “Repertory” as options and be saved as a factor - rename first/last_epid to first_ep_credited and last_ep_credited - rename update_anchor to anchored_weekend_update - rename n_episodes to n_episodes_acted - rename season_fraction to acted_episodes_fraction
casts_clean <- casts %>%
mutate(featured = as_factor(ifelse(featured == TRUE, "Featured", "Repertory"))) %>%
rename(
actor_id = aid,
season_id = sid,
season_role = featured,
first_ep_credited = first_epid,
last_ep_credited = last_epid,
anchored_weekend_update = update_anchor,
n_episodes_acted = n_episodes,
acted_episodes_fraction = season_fraction
)
casts_cleanSeasons
Finally, we can clean the seasons data.
head(seasons)Here we have: - season ID - season year - first and last episode IDs - number of episodes in season
To keep consistent naming and make sure we are differentiating column names across datasets, we can complete the following renaming:
sid->season_idyear->season_yearfirst/last_epid->first_ep_season/last_ep_seasonn_episodes->n_episodes_season
seasons_clean <- seasons %>%
rename(
season_id = sid,
season_year = year,
first_ep_season = first_epid,
last_ep_season = last_epid,
n_episodes_season = n_episodes
)
seasons_cleanJoining Data
Next, we can join the data together to start doing analysis.
All three datasets are joinable together due to a shared set of identifiers. We can use a left join to make sure we don’t exclude any data in the event that matches are missing for some of our actors.
snl_joined <- actors_clean %>%
left_join(casts_clean, by = "actor_id") %>%
left_join(seasons_clean, by = "season_id")
snl_joinedNote that we have more rows in this data table than we did in the actors data alone. This can happen with a left join. The main thing that’s important is that we have at least as many rows as we did in the actors table alone (which was our original “left” dataframe).
As another sanity check, we can look at the two current hosts of weekend update and make sure their data looks correct.
Colin Jost joined SNL in 2005 and still performs. Michael Che joined in 2013.
snl_joined %>%
filter(actor_id %in% c("Colin Jost", "Michael Che"))Both Colin Jost and Michael Che have anchored weekend update since they started. We see this in the data. We can also look at Colin’s first season, 39. He is listed as acting in 8 episodes as a Featured player. If we check on wikipedia to confirm this information, we see that he was correctly listed as “Featured”. Colin’s first episode is episode 14, which aired March 1st 2014. This matches his first_ep_credited, 20140301 (or “2014-03-01”). Starting on that episode and going to the end of the season is 8 episodes, which also correctly matches how many episodes he’s credited for that season, so all seems to have gone correctly in this join.
https://en.wikipedia.org/wiki/Saturday_Night_Live_(season_39)
Analysis
Using this newly joined data, we can do some quick analysis.
Let’s do some analysis on how long actors stayed on the cast in different roles:
snl_joined %>%
filter(actor_type == "cast") %>%
group_by(actor_id, season_role) %>%
summarize(n_seasons = n()) %>%
group_by(season_role) %>%
summarize(avg_seasons = mean(n_seasons), min_seasons = min(n_seasons), max_seasons= max(n_seasons))On average, actors spent 1.65 seasons in Featured roles, and ~4 seasons in Repertory. The minimum number of seasons in each role was 1, with the longest serving tenure being 11 seasons in Featured and 16 seasons in Repertory.
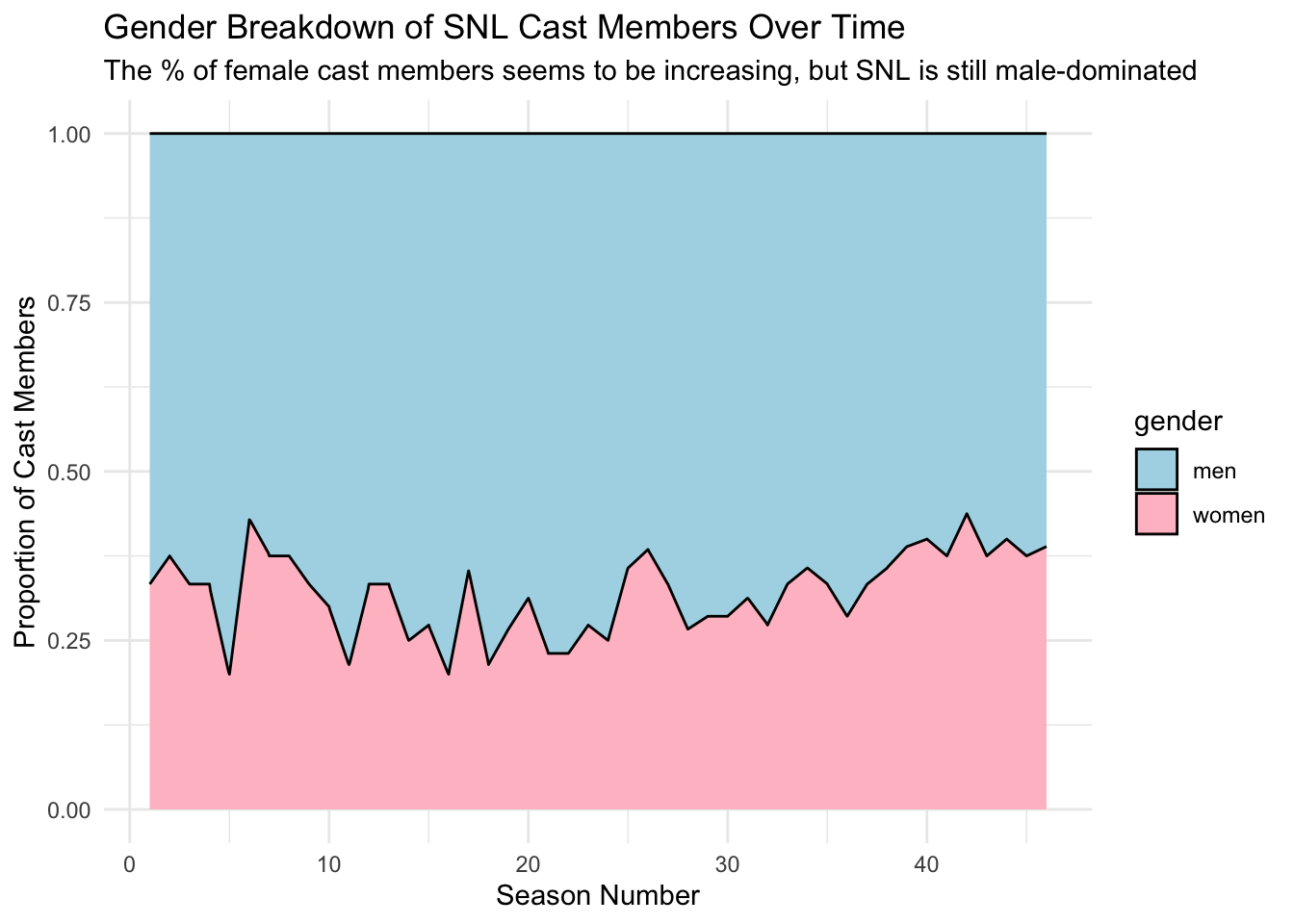
Next, we can look at how the gender divide has shifted over time:
gender_breakdown <- snl_joined %>%
filter(actor_type == "cast", actor_gender != "unknown") %>%
select(actor_gender, season_id) %>%
group_by(season_id) %>%
summarize(men = sum(actor_gender == "male"), women = sum(actor_gender == "female")) %>%
pivot_longer(-season_id, names_to = "gender", values_to = "n_cast_members")
gender_breakdowngender_breakdown %>%
ggplot(aes(x= season_id, y = n_cast_members, fill = gender)) +
geom_area(position = "fill", color="black") +
scale_fill_manual(values=c("lightblue","pink")) +
xlab("Season Number") +
ylab("Proportion of Cast Members") +
ggtitle("Gender Breakdown of SNL Cast Members Over Time", subtitle = "The % of female cast members seems to be increasing, but SNL is still male-dominated") + theme_minimal()