Code
library(tidyverse)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)library(tidyverse)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)For this homework, your goal is to read in a more complicated data set. Please use the category tag “hw2” as well as a tag for the data set you choose to use
Read in one (or more) of the following datasets, using the correct R package and command.
Ans: For HW2 and for my Final Project I am going to use the hotel_bookings.csv data set that is already provided to us in the _data folder. This data set is challenging since it is a large data set with 119390 rows and 32 columns and has difficulty rating of 4-star.
data_hotels <- read_csv("_data/hotel_bookings.csv")
data_hotelsglimpse(data_hotels)Rows: 119,390
Columns: 32
$ hotel <chr> "Resort Hotel", "Resort Hotel", "Resort…
$ is_canceled <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, …
$ lead_time <dbl> 342, 737, 7, 13, 14, 14, 0, 9, 85, 75, …
$ arrival_date_year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 201…
$ arrival_date_month <chr> "July", "July", "July", "July", "July",…
$ arrival_date_week_number <dbl> 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,…
$ arrival_date_day_of_month <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ stays_in_weekend_nights <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ stays_in_week_nights <dbl> 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 4, 4, 4, …
$ adults <dbl> 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
$ children <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ babies <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ meal <chr> "BB", "BB", "BB", "BB", "BB", "BB", "BB…
$ country <chr> "PRT", "PRT", "GBR", "GBR", "GBR", "GBR…
$ market_segment <chr> "Direct", "Direct", "Direct", "Corporat…
$ distribution_channel <chr> "Direct", "Direct", "Direct", "Corporat…
$ is_repeated_guest <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ previous_cancellations <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ previous_bookings_not_canceled <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ reserved_room_type <chr> "C", "C", "A", "A", "A", "A", "C", "C",…
$ assigned_room_type <chr> "C", "C", "C", "A", "A", "A", "C", "C",…
$ booking_changes <dbl> 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ deposit_type <chr> "No Deposit", "No Deposit", "No Deposit…
$ agent <chr> "NULL", "NULL", "NULL", "304", "240", "…
$ company <chr> "NULL", "NULL", "NULL", "NULL", "NULL",…
$ days_in_waiting_list <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ customer_type <chr> "Transient", "Transient", "Transient", …
$ adr <dbl> 0.00, 0.00, 75.00, 75.00, 98.00, 98.00,…
$ required_car_parking_spaces <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ total_of_special_requests <dbl> 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 3, …
$ reservation_status <chr> "Check-Out", "Check-Out", "Check-Out", …
$ reservation_status_date <date> 2015-07-01, 2015-07-01, 2015-07-02, 20…Ans: The code for cleaning the hotel_booking data set is given below:
colSums(is.na(data_hotels)) hotel is_canceled
0 0
lead_time arrival_date_year
0 0
arrival_date_month arrival_date_week_number
0 0
arrival_date_day_of_month stays_in_weekend_nights
0 0
stays_in_week_nights adults
0 0
children babies
4 0
meal country
0 0
market_segment distribution_channel
0 0
is_repeated_guest previous_cancellations
0 0
previous_bookings_not_canceled reserved_room_type
0 0
assigned_room_type booking_changes
0 0
deposit_type agent
0 0
company days_in_waiting_list
0 0
customer_type adr
0 0
required_car_parking_spaces total_of_special_requests
0 0
reservation_status reservation_status_date
0 0 Also there are a few rows in the data set where no adult or there are children with no adults that have checked in. Now babies and children can’t check-in on their own so we will remove those entries from the data set.
data_hotels <- data_hotels %>% filter(data_hotels$adults != 0)This covers most of the preliminary data cleaning for HW2 and Final Project. As I start working on the Final Project, I’m sure I’ll run into more issues and will need to do some further data cleaning.
Ans: After cleaning the data set above we can now see that it has 118,987 rows and 32 columns.
glimpse(data_hotels)Rows: 118,987
Columns: 32
$ hotel <chr> "Resort Hotel", "Resort Hotel", "Resort…
$ is_canceled <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, …
$ lead_time <dbl> 342, 737, 7, 13, 14, 14, 0, 9, 85, 75, …
$ arrival_date_year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 201…
$ arrival_date_month <chr> "July", "July", "July", "July", "July",…
$ arrival_date_week_number <dbl> 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,…
$ arrival_date_day_of_month <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ stays_in_weekend_nights <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ stays_in_week_nights <dbl> 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 4, 4, 4, …
$ adults <dbl> 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, …
$ children <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ babies <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ meal <chr> "BB", "BB", "BB", "BB", "BB", "BB", "BB…
$ country <chr> "PRT", "PRT", "GBR", "GBR", "GBR", "GBR…
$ market_segment <chr> "Direct", "Direct", "Direct", "Corporat…
$ distribution_channel <chr> "Direct", "Direct", "Direct", "Corporat…
$ is_repeated_guest <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ previous_cancellations <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ previous_bookings_not_canceled <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ reserved_room_type <chr> "C", "C", "A", "A", "A", "A", "C", "C",…
$ assigned_room_type <chr> "C", "C", "C", "A", "A", "A", "C", "C",…
$ booking_changes <dbl> 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ deposit_type <chr> "No Deposit", "No Deposit", "No Deposit…
$ agent <chr> "NULL", "NULL", "NULL", "304", "240", "…
$ company <chr> "NULL", "NULL", "NULL", "NULL", "NULL",…
$ days_in_waiting_list <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ customer_type <chr> "Transient", "Transient", "Transient", …
$ adr <dbl> 0.00, 0.00, 75.00, 75.00, 98.00, 98.00,…
$ required_car_parking_spaces <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ total_of_special_requests <dbl> 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 3, …
$ reservation_status <chr> "Check-Out", "Check-Out", "Check-Out", …
$ reservation_status_date <date> 2015-07-01, 2015-07-01, 2015-07-02, 20…We can also see that there are two different types of hotels; Resort hotels and City hotels.
table(data_hotels$hotel)
City Hotel Resort Hotel
78940 40047 We can get an idea of the nationality of the different guest by looking at the list of countries below:
data_hotels %>%
group_by(country)%>%
summarise(num=n())%>%
arrange(desc(num))Based on the data above of the top 15 countries, the top 3 countries are Portugal(PRT), Great Britain(GBR) and France (FRA).
This is visualized in the plot given below:
data_country <- data_hotels %>% group_by(country) %>% summarise(booking_count = n()) %>% arrange(desc(booking_count))
top_n(data_country,15,booking_count) %>%
ggplot(aes(x = reorder(country,booking_count), y = booking_count)) +
geom_bar(stat = "identity", width = 0.25)+
coord_flip()+
ylab('Number of Guests')+
xlab('Nationality')+
ggtitle('Guests by country') +
labs(fill='Hotel type')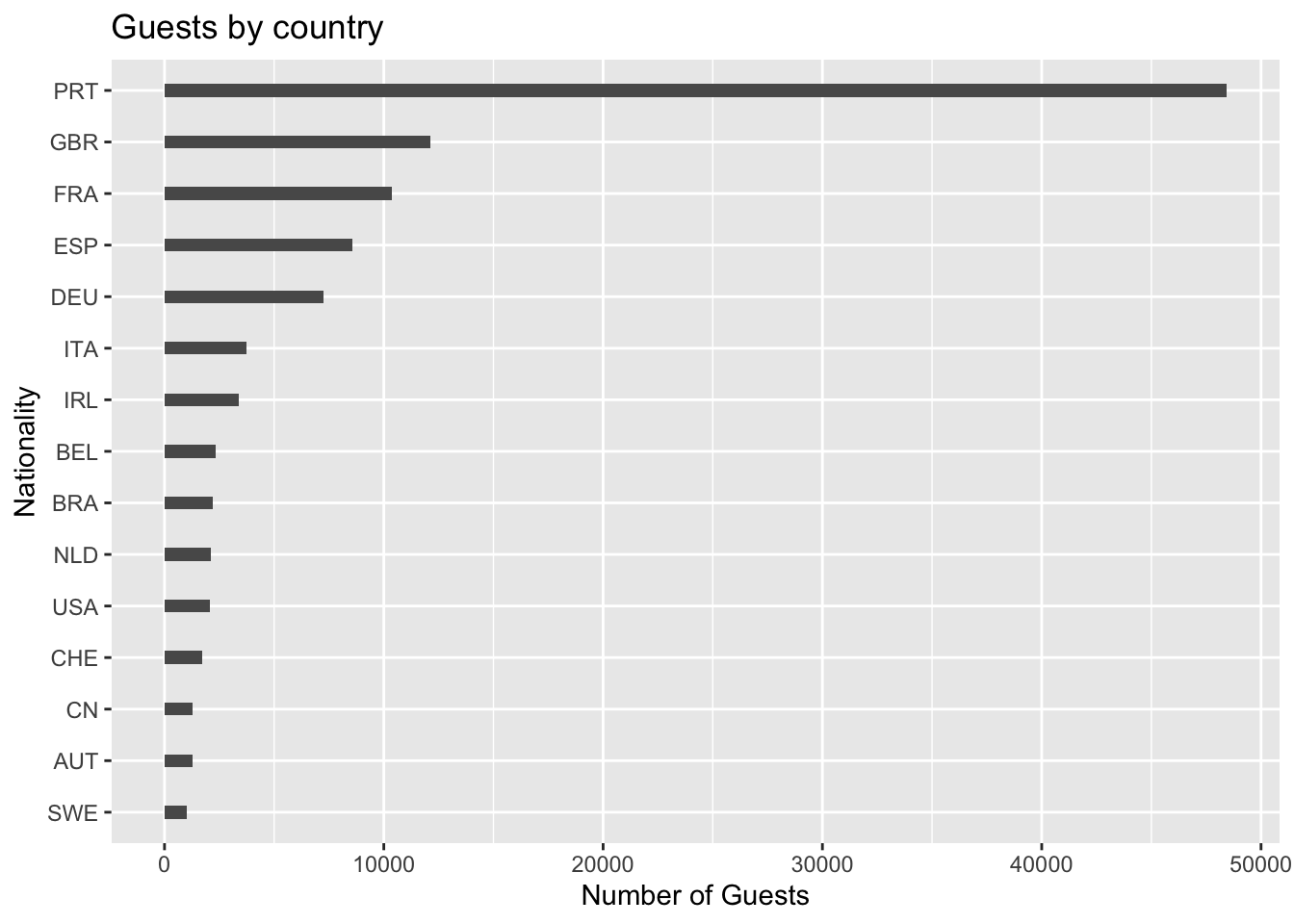
We can also get an idea of the number of reservations that are successfully checked-out vs canceled vs No-show. Looking at the data we can say that a significant chunk of the reservations are canceled.
table(data_hotels$reservation_status)
Canceled Check-Out No-Show
42912 74872 1203 Ans: Looking at the hotel_bookings data set we can try to answer many of the exploratory research questions. They are:
What is the preferred hotel type for guests (City hotel vs Resort hotel)?
Hotel bookings are usually seasonal in nature. Which month has the highest booking rate/revenue?
Which countries have the highest number of incoming guests?
What is the average length of stay per booking? Average number of guests per booking?
Which months have the highest rate of cancellations?
Finding correlation between the numerical data columns (e.g. ADR vs number of guests) to get useful insights.
This is just a preliminary list of the exploratory questions. As I start working on the Final Project, I’ll discover more research questions that I can add to this list.