Code
library(tidyverse)
library(readxl)
knitr::opts_chunk$set(echo = TRUE)library(tidyverse)
library(readxl)
knitr::opts_chunk$set(echo = TRUE)Today’s challenge is to
Our advanced datasets ( ⭐⭐⭐ and higher) are tabular data (i.e., tables) that are often published based on government sources or by other organizations. Tabular data is often made available in Excel format (.xls or .xlsx) and is formatted for ease of reading - but this can make it tricky to read into R and reshape into a usable dataset.
Reading in tabular data will follow the same general work flow or work process regardless of formatting differences. We will work through the steps in detail this week (and in future weeks as new datasets are introduced), but this is an outline of the basic process. Note that not every step is needed for every file.
filter (and stringr package)mutate new variables as required, using separate, pivot_longer, etcIt is hard to get much information about the data source or contents from a .csv file - as compared to the formatted .xlsx version of the same data described below.
railroad<-read_csv("_data/railroad_2012_clean_county.csv")Rows: 2930 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): state, county
dbl (1): total_employees
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.railroadFrom inspection, we can that the three variables are named state, county, and total employees. Combined with the name of the file, this appears to be the aggregated data on the number of employees working for the railroad in each county 2012. We assume that the 2930 cases - which are counties embedded within states1 - consist only of counties where there are railroad employees?
railroad %>%
select(state) %>%
n_distinct(.)[1] 53railroad%>%
select(state)%>%
distinct()With a few simple commands, we can confirm that there are 53 “states” represented in the data. To identify the additional non-state areas (probably District of Columbia, plus some combination of Puerto Rico and/or overseas addresses), we can print out a list of unique state names.
1: We can identify case variables because both are character variables, which in tidy lingo are grouping variables not values.
Once again, a .csv file lacks any of the additional information that might be present in a published Excel table. So, we know the data are likely to be about birds, but will we be looking at individual pet birds, prices of bird breeds sold in stores, the average flock size of wild birds - who knows!
The FAOSTAT*.csv files have some additional information - the FAO - which a Google search reveals to be the Food and Agriculture Association of the United Nations publishes country-level data regularly in a database called FAOSTAT. So my best guess at this point is that we are going to be looking at country-level estimates of the number of birds that are raised for eggs and poultry, but we will see if this is right by inspecting the data.
birds<-read_csv("_data/birds.csv")Rows: 30977 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): Domain Code, Domain, Area, Element, Item, Unit, Flag, Flag Description
dbl (6): Area Code, Element Code, Item Code, Year Code, Year, Value
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.birdschickens<-read_csv("_data/FAOSTAT_egg_chicken.csv")Rows: 38170 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): Domain Code, Domain, Area, Element, Item, Unit, Flag, Flag Description
dbl (6): Area Code, Element Code, Item Code, Year Code, Year, Value
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.chickensIt is pretty difficult to get a handle on what data are being captured by any of the FAOSTAT* (including the birds.csv) data sets simply from a quick scan of the tibble after read in. It was easy with the railroad data, but now we are going to have to work harder to describe exactly what comprises a case in these data and what values are present for each case. We can see that there are 30977 rows in the birds data (and 38170 in the chickens data) - but this might not mean that there are 30,970 (or 38,170) cases because we aren’t sure what constitutes a case at this point.
One approach to figuring out what constitutes a case is to identify the value variables and assume that what is leftover are the grouping variables. Unfortunately, there are six double variables (from the column descriptions that are automatically returned), and it appears that most of them are not grouping variables. For example, the variable “Area Code” is a double - but doesn’t appear to be a value that varies across rows. Thus, it is a grouping variable rather than a true value in tidy nomenclature. Similar issues can be found with Year and “Item Code” - both appear to be grouping variables. Ironically, it is the variable called Value which appears to the sole value in the data set - but what is it the value of?
Another approach to identifying a case is to look for variation (or lack of variation) in just the first few cases of the tibble. (Think of this as the basis for a minimal reproducible example.) In the first few cases, the variables of the first 10 cases appear to be identical until we get to Year and Year Code (which appear to be identical to each other.) So it appears that Value is varying by country-year - but perhaps also by information in one of the other variables. It also appears that many of the doubles are just numeric codes, so lets drop those variables to simplify (I’m going to drop down to just showing the birds data for now.)
birds_sm<-birds%>%
select(-contains("Code"))
birds_smchickens_sm<-chickens%>%
select(-contains("Code"))Before we go doing detailed cross-tabs to figure out where there is variation, lets do a high level summary of the dataset to see if - for example - there are multiple values in the Element variable - or if we only have a dataset with records containing estimates of Chicken Stocks (from Element + Item.)
To get a better grasp of the data, lets do a quick skim or summary of the dataset and see if we can find out more about our data at a glance. I am using the dfSummary function from the summarytools package -one of the more attractive ways to quickly summarise a dataset. I am using a few options to allow it to render directly to html.
print(summarytools::dfSummary(birds_sm,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.70,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Error in loadNamespace(x): there is no package called 'summarytools'We can also use the base R summary function.
summary(birds_sm) Domain Area Element Item
Length:30977 Length:30977 Length:30977 Length:30977
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Year Unit Value Flag
Min. :1961 Length:30977 Min. : 0 Length:30977
1st Qu.:1976 Class :character 1st Qu.: 171 Class :character
Median :1992 Mode :character Median : 1800 Mode :character
Mean :1991 Mean : 99411
3rd Qu.:2005 3rd Qu.: 15404
Max. :2018 Max. :23707134
NA's :1036
Flag Description
Length:30977
Class :character
Mode :character
Finally - we have a much better grasp on what is going on. First, we know that all records in this data set are of the number of Live Animal Stocks (Domain + Element), with the value expressed as 1000 heads (Unit). These three variables are grouping variables but DO NOT vary in this particular data extract - but are probably used to create data extracts from the larger FAOSTAT database.. To see if we are correct, we will have to checkout the same fields in the chickens data below.
Second, we can now guess that a case consists of a country-year-animal record - as captured in the variables Area, Year and Item, respectively - estimate of the number of live animals (Value.) ALso, as a side note, it appears that the estimated number of animals may have a long right-hand tail - just looking at the mini-histogram. So we can now say that we have estimates of the stock of five different types of poultry (Chickens, Ducks, Geese and guinea fowls, Turkeys, and Pigeons/Others) in 248 areas (countries??) for 58 years between 1961-2018.
birds_clean_1 <- birds_sm %>%
select(Area, Item, Year, Value, Flag)The only minor concern is that we are still not entirely sure what information is being captured in the Flag (and matching Flag Description) variable. It appears unlikely that there is more than one estimate per country-year-animal case (see the summary of Area where all countries have 290 observations.) An assumption of one type of estimate (the content of Flag Description) per year is also consistent with the histogram of Year, which is pretty consistent although more countries were clearly added later in the series and data collection is not complete for the most recent time period.
We can dig a bit more, and find the description of the Flag field on the FAOSTAT website.. Sure enough, this confirms that the flags correspond to what type of estimate is being used (e.g., official data vs an estimate by FAOSTAT or imputed data.)
We can also confirm that NOT all cases are countries, as there is a Flag value, A, described as aggregated data. A quick inspection of the areas using this flag confirm that all of the “countries” are actually regional aggregations, and should be filtered out of the dataset as they are not the same “type” of case as a country-level case. To fix these data into true tidy format, we would need to filter out the aggregates, then merge on the country group definitions from FAOSTAT to create new country-group or regional variables that could be used to recreate aggregated estimates with dplyr.
birds_sm%>%
filter(Flag=="A")%>%
group_by(Area)%>%
summarize(n=n())birds_final <- birds_sm %>%
select(Area, Item, Year, Value, Flag) %>%
filter(Flag!="A")Lets take a quick look at our chickens data to see if it follows the same basic pattern as the birds data. Sure enough, it looks like we have a different domain (livestock products) but that the cases remain similar country-year-product, with three slightly different estimates related to egg-laying (instead of the five types of poultry.)
print(summarytools::dfSummary(chickens_sm,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.70,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Error in loadNamespace(x): there is no package called 'summarytools'The “wild_bird_data” sheet is in Excel format (.xlsx) instead of the .csv format of the earlier data sets. In theory, it should be no harder to read in than an Excel worksheet (or even workbook) as compared to a .csv file - there is a package called read_xl that is part of the tidyverse that easily reads in excel files.
However, in practice, most people use Excel sheets as a publication format - not a way to store data, so there is almost always a ton of “junk” in the file that is NOT part of the data table that we want to read in. Sometimes the additional “junk” is incredibly useful - it might include table notes or information about data sources. However, we still need a systematic way to identify this junk and get rid of it during the data reading step.
For example, lets see what happens here if we just read in the wild bird data straight from excel.
wildbirds<-read_excel("_data/wild_bird_data.xlsx")
wildbirdsHm, this doesn’t seem quite right. It is clear that the first “case” has information in it that looks more like variable labels. Lets take a quick look at the raw data.
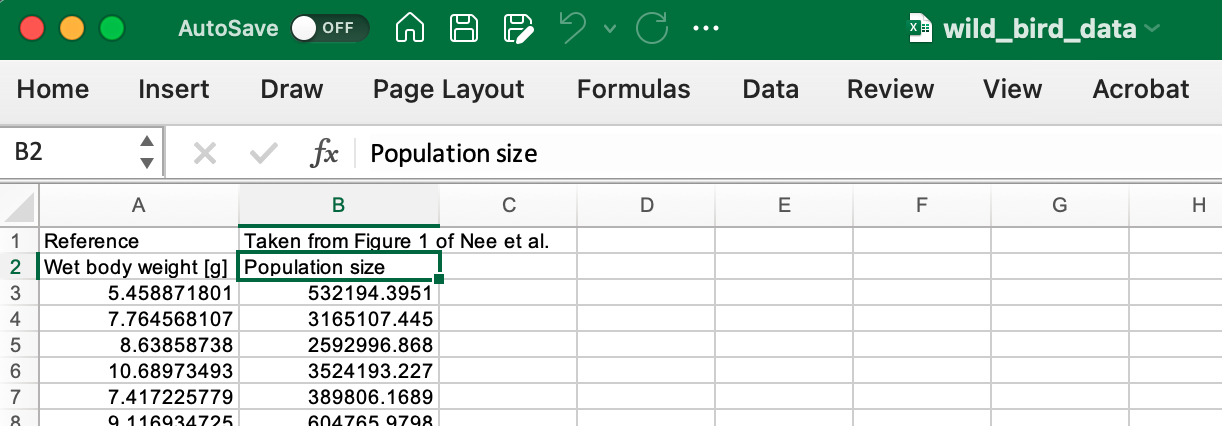
Sure enough the Excel file first row does contain additional information, a pointer to the article that this data was drawn from, and a quick Google reveals the article is [Nee, S., Read, A., Greenwood, J. et al. The relationship between abundance and body size in British birds. Nature 351, 312–313 (1991)] (https://www.nature.com/articles/351312a0)
We could try to manually adjust things - remove the first row, change the column names, and then change the column types. But this is both a lot of work, and not really a best practice for data management. Lets instead re-read the data in with the skip argument from read_excel, and see if it fixes all of our problems!
wildbirds <- read_excel("_data/wild_bird_data.xlsx",
skip = 1)
wildbirds This now looks great! Both variables are numeric, and now they correctly show up as double or (
Note that I skip two rows this time, and apply my own column names.
wildbirds <- read_excel("_data/wild_bird_data.xlsx",
skip = 2,
col_names = c("weight", "pop_size"))
wildbirdsThe railroad data set is our most challenging data to read in this week, but is (by comparison) a fairly straightforward formatted table published by the Railroad Retirement Board. The value variable is a count of the number of employees in each county and state combination. 
Looking at the excel file, we can see that there are only a few issues: 1. There are three rows at the top of the sheet that are not needed 2. There are blank columns that are not needed. 3. There are Total rows for each state that are not needed
For the first issue, we use the “skip” option on read_excel from the readxl package to skip the rows at the top.
read_excel("_data/StateCounty2012.xls",
skip = 3)New names:
• `` -> `...2`
• `` -> `...4`For the second issue, I name the blank columns “delete” to make is easy to remove the unwanted columns. I then use select (with the ! sign to designate the complement or NOT) to select columns we wish to keep in the dataset - the rest are removed. Note that I skip 4 rows this time as I do not need the original header row.
There are other approaches you could use for this task (e.g., remove all columns that have no valid volues), but hard coding of variable names and types during data read in is not considered a violation of best practices and - if used strategically - can often make later data cleaning much easier.
read_excel("_data/StateCounty2012.xls",
skip = 4,
col_names= c("State", "delete", "County", "delete", "Employees"))%>%
select(-contains("delete"))New names:
• `delete` -> `delete...2`
• `delete` -> `delete...4`For the third issue, we are going to use filter to identify (and drop the rows that have the word “Total” in the State column). str_detect can be used to find specific rows within a column that have the designated “pattern”, while the “!” designates the complement of the selected rows (i.e., those without the “pattern” we are searching for.)
The str_detect command is from the stringr package, and is a powerful and easy to use implementation of grep and regex in the tidyverse - the base R functions (grep, gsub, etc) are classic but far more difficult to use, particularly for those not in practice. Be sure to explore the stringr package on your own.
railroad<-read_excel("_data/StateCounty2012.xls",
skip = 4,
col_names= c("State", "delete", "County", "delete", "Employees"))%>%
select(!contains("delete"))%>%
filter(!str_detect(State, "Total"))New names:
• `delete` -> `delete...2`
• `delete` -> `delete...4`railroadTables often have notes in the last few table rows. You can check table limits and use this information during data read-in to not read the notes by setting the n-max option at the total number of rows to read, or less commonly, the range option to specify the spreadsheet range in standard excel naming (e.g., “B4:R142”). If you didn’t handle this on read in, you can use the tail command to check for notes and either tail or head to keep only the rows that you need.
tail(railroad, 10)#remove the last two observations
railroad <- head(railroad, -2)
tail(railroad, 10)range approachWe can manually specify the range of cells we want to read in using the range argument. To do so, you’ll need to open the file up in Excel (or a similar program) and figure this out on your own.
railroad_new <- read_excel("_data/StateCounty2012.xls",
range = "B4:F2990",
col_names= c("State", "delete", "County", "delete", "Employees"))%>%
select(!contains("delete"))%>%
filter(!str_detect(State, "Total"))New names:
• `delete` -> `delete...2`
• `delete` -> `delete...4`railroad_newtail(railroad_new,10)And that is all it takes! The data are now ready for analysis. Lets see if we get the same number of unique states that were in the cleaned data in exercise 1.
railroad%>%
select(State)%>%
n_distinct(.)[1] 54railroad%>%
select(State)%>%
distinct()Oh my goodness! It seems that we have an additional “State” - it looks like Canada is in the full excel data and not the tidy data. This is one example of why it is good practice to always work from the original data source!