library(tidyverse)
library(ggplot2)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 7 Solutions
challenge_7
hotel_bookings
australian_marriage
air_bnb
eggs
abc_poll
faostat
usa_households
Visualizing Multiple Dimensions
Challenge Overview
Today’s challenge is to:
- read in a data set, and describe the data set using both words and any supporting information (e.g., tables, etc)
- tidy data (as needed, including sanity checks)
- mutate variables as needed (including sanity checks)
- Recreate at least two graphs from previous exercises, but introduce at least one additional dimension that you omitted before using ggplot functionality (color, shape, line, facet, etc) The goal is not to create unneeded chart ink (Tufte), but to concisely capture variation in additional dimensions that were collapsed in your earlier 2 or 3 dimensional graphs.
- Explain why you choose the specific graph type
- If you haven’t tried in previous weeks, work this week to make your graphs “publication” ready with titles, captions, and pretty axis labels and other viewer-friendly features
R Graph Gallery is a good starting point for thinking about what information is conveyed in standard graph types, and includes example R code. And anyone not familiar with Edward Tufte should check out his fantastic books and courses on data visualizaton.
(be sure to only include the category tags for the data you use!)
Read in data
Read in one (or more) of the following datasets, using the correct R package and command.
- eggs ⭐
- abc_poll ⭐⭐
- australian_marriage ⭐⭐
- hotel_bookings ⭐⭐⭐
- air_bnb ⭐⭐⭐
- us_hh ⭐⭐⭐⭐
- faostat ⭐⭐⭐⭐⭐
Read in Data
setwd("C:/Users/chion/OneDrive/Desktop/DACSS 601/DACSS_601_Summer2023_Sec1/posts")
library(readr)
AB_NYC_2019 <- read_csv("_data/AB_NYC_2019.csv")Briefly describe the data
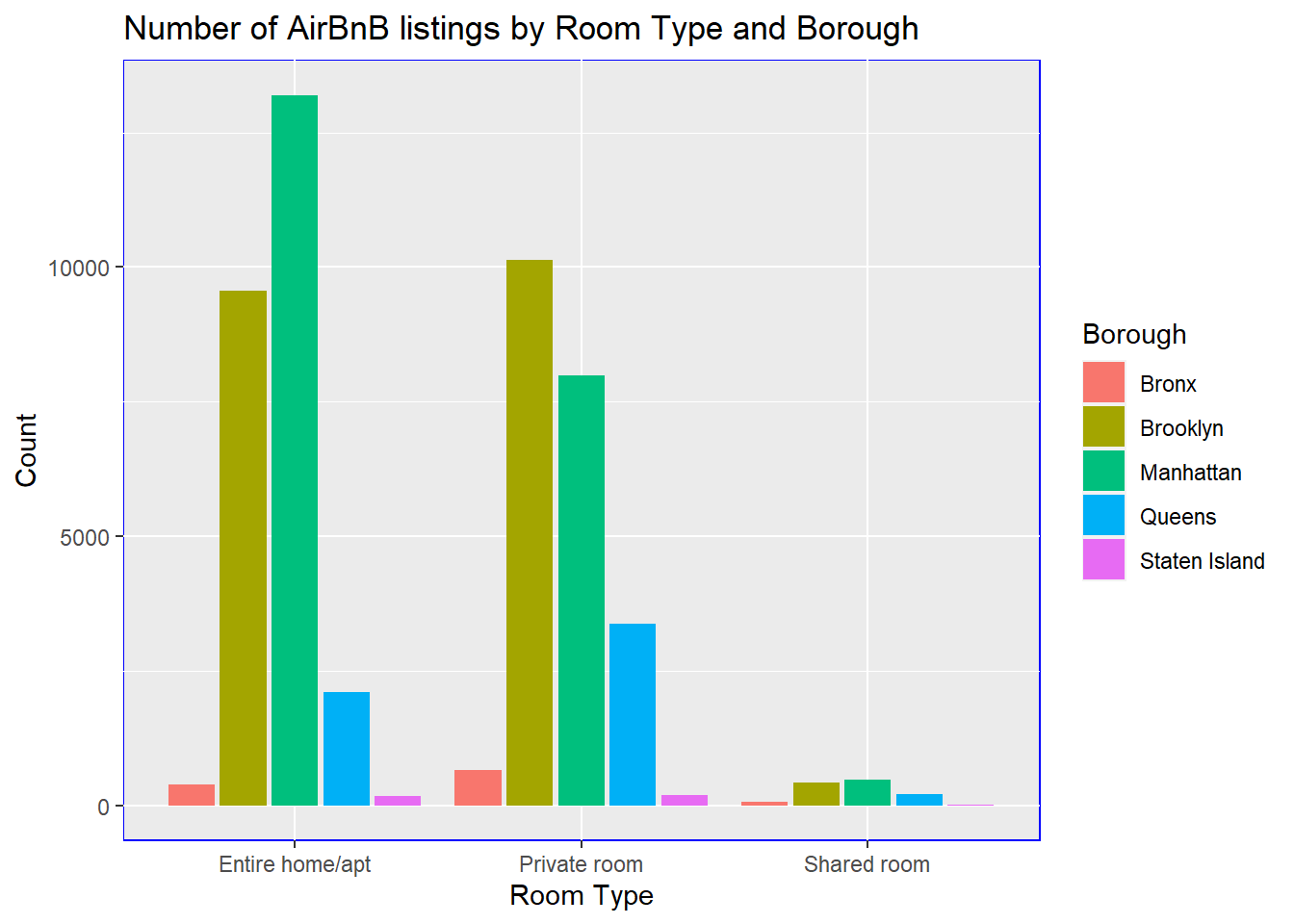
There are 48895 observations with 17 variables. The data set pertains to review and other administrative records for AirBnB in New York City. There are categorical variables in the data set, namely the boroughs of Brooklyn, Manhattan, Queens, Staten Island and Bronx, as well as room type: private room, entire home/apartment and shared room. The dates of the last review range from March 2011 to July 2019. The minimum cost ranges from 0 to $1.2M. The mean minimum cost is $1284.43. The composition of the lodging by room type is as follows: 52% Entire home/apartment, 46% private room and 2.4% shared room. In terms of boroughs where the Airbnb lodging is located, 2% where in the Bronx, 41% in Brooklyn, 44% in Manhattan, 12% in Queens and 1% in Staten Island.
The minimum cost data is skewed right, with a mean of 1284 considerably higher than the median of 300. Similarly, the minimum nights data is also skewed right with a mean of 7.03 and a median of 3.0. This suggests that minimum cost and minimum nights is concentrated toward the lower ends of the scale- but be aware that the range is wide for the minimum cost and minimum nights, with smaller numbers on the scale still constituting considerable absolute numbers.
Summary Statistics
AirbnbNYC.id AirbnbNYC.minimum_cost AirbnbNYC.minimum_nights Min. : 2539 Min. : 0.0 Min. : 1.00
1st Qu.: 9471945 1st Qu.: 135.0 1st Qu.: 1.00
Median :19677284 Median : 300.0 Median : 3.00
Mean :19017143 Mean : 1284.4 Mean : 7.03
3rd Qu.:29152178 3rd Qu.: 734.5 3rd Qu.: 5.00
Max. :36487245 Max. :1170000.0 Max. :1250.00
Tidy Data (as needed)
Is your data already tidy, or is there work to be done? Be sure to anticipate your end result to provide a sanity check, and document your work here.
Are there any variables that require mutation to be usable in your analysis stream? For example, do you need to calculate new values in order to graph them? Can string values be represented numerically? Do you need to turn any variables into factors and reorder for ease of graphics and visualization?
Document your work here.
Mutate Data
AirbnbNYC <- AB_NYC_2019 %>%
mutate(`minimum_cost`= `price`*`minimum_nights`)Summarize data
Airbnbselect <- data.frame(AirbnbNYC$id,AirbnbNYC$minimum_cost,AirbnbNYC$minimum_nights)
summary(Airbnbselect) AirbnbNYC.id AirbnbNYC.minimum_cost AirbnbNYC.minimum_nights
Min. : 2539 Min. : 0.0 Min. : 1.00
1st Qu.: 9471945 1st Qu.: 135.0 1st Qu.: 1.00
Median :19677284 Median : 300.0 Median : 3.00
Mean :19017143 Mean : 1284.4 Mean : 7.03
3rd Qu.:29152178 3rd Qu.: 734.5 3rd Qu.: 5.00
Max. :36487245 Max. :1170000.0 Max. :1250.00 vis1a <- ggplot(AirbnbNYC, aes(x=last_review, y=minimum_cost, color=room_type)) +
geom_point(size=5) +
labs(y= "Minimum Cost", x= "Date of Last Review", color= "Room Type", title = "Minimum Cost over Date of Last Review") +
theme(panel.background=element_rect(colour="blue"))
print(vis1a)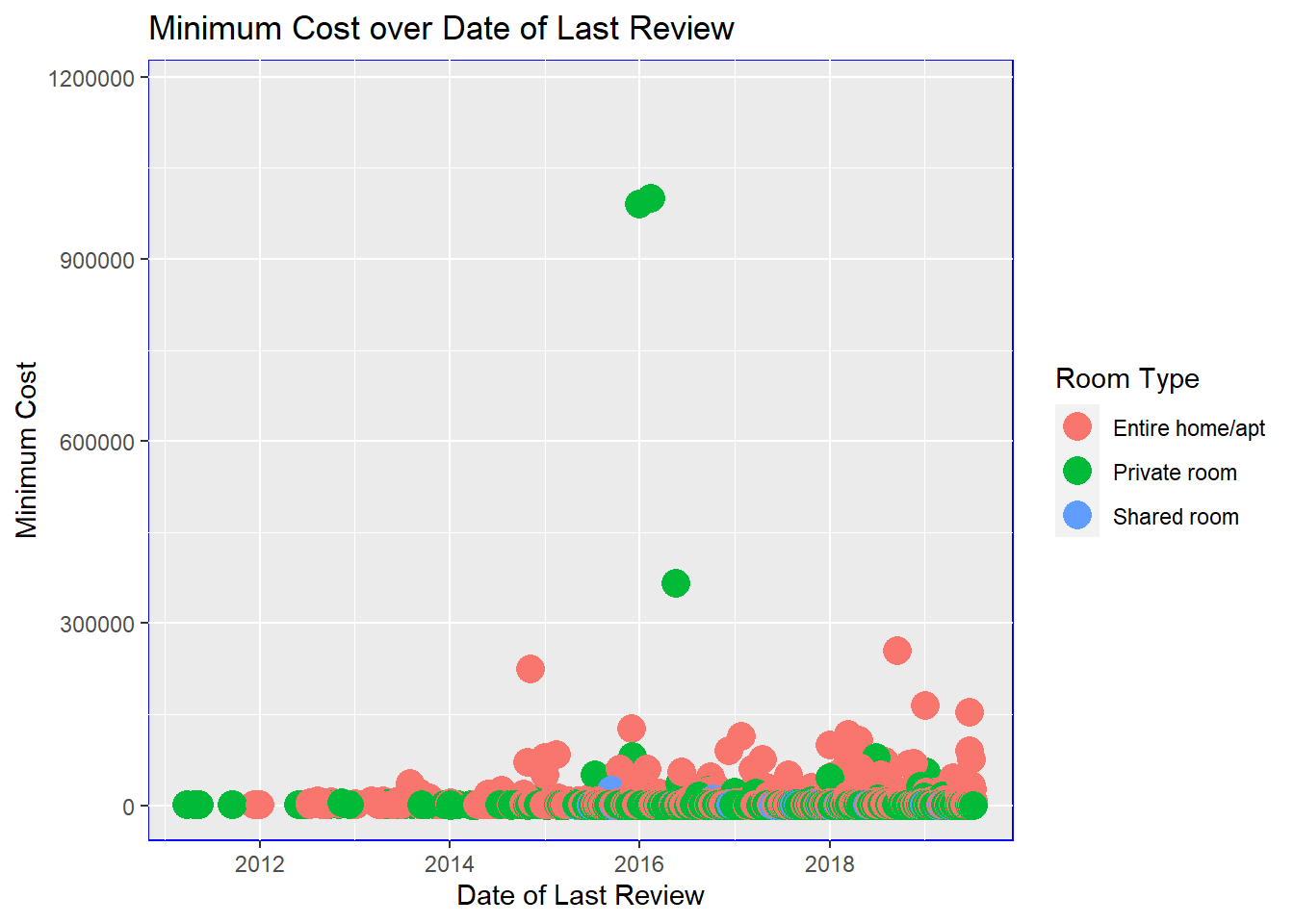
vis2a <-
ggplot(AirbnbNYC, aes(factor(room_type), fill = factor(neighbourhood_group))) +
geom_bar(position = "dodge2") +
labs(x="Room Type", y="Count", fill="Borough", title="Number of AirBnB listings by Room Type and Borough") +
theme(panel.background=element_rect(colour="blue"))
print(vis2a)