Warning: package 'readxl' was built under R version 4.1.3
Code
library(tidyverse)
Warning: package 'tidyverse' was built under R version 4.1.3
-- Attaching packages --------------------------------------- tidyverse 1.3.2 --
v ggplot2 3.4.0 v purrr 0.3.5
v tibble 3.1.8 v dplyr 1.0.10
v tidyr 1.2.1 v stringr 1.5.0
v readr 2.1.3 v forcats 0.5.2
Warning: package 'ggplot2' was built under R version 4.1.3
Warning: package 'tibble' was built under R version 4.1.3
Warning: package 'tidyr' was built under R version 4.1.3
Warning: package 'readr' was built under R version 4.1.3
Warning: package 'purrr' was built under R version 4.1.3
Warning: package 'dplyr' was built under R version 4.1.3
Warning: package 'stringr' was built under R version 4.1.3
Warning: package 'forcats' was built under R version 4.1.3
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
Code
library(sna)
Warning: package 'sna' was built under R version 4.1.3
Loading required package: statnet.common
Warning: package 'statnet.common' was built under R version 4.1.3
Attaching package: 'statnet.common'
The following objects are masked from 'package:base':
attr, order
Loading required package: network
Warning: package 'network' was built under R version 4.1.3
'network' 1.18.1 (2023-01-24), part of the Statnet Project
* 'news(package="network")' for changes since last version
* 'citation("network")' for citation information
* 'https://statnet.org' for help, support, and other information
sna: Tools for Social Network Analysis
Version 2.7-1 created on 2023-01-24.
copyright (c) 2005, Carter T. Butts, University of California-Irvine
For citation information, type citation("sna").
Type help(package="sna") to get started.
Code
library(ggplot2)library(igraph)
Warning: package 'igraph' was built under R version 4.1.3
Attaching package: 'igraph'
The following objects are masked from 'package:sna':
betweenness, bonpow, closeness, components, degree, dyad.census,
evcent, hierarchy, is.connected, neighborhood, triad.census
The following objects are masked from 'package:network':
%c%, %s%, add.edges, add.vertices, delete.edges, delete.vertices,
get.edge.attribute, get.edges, get.vertex.attribute, is.bipartite,
is.directed, list.edge.attributes, list.vertex.attributes,
set.edge.attribute, set.vertex.attribute
The following objects are masked from 'package:dplyr':
as_data_frame, groups, union
The following objects are masked from 'package:purrr':
compose, simplify
The following object is masked from 'package:tidyr':
crossing
The following object is masked from 'package:tibble':
as_data_frame
The following objects are masked from 'package:stats':
decompose, spectrum
The following object is masked from 'package:base':
union
# A tibble: 6 x 8
Year `(semi-) final` Edition Jury or Televot~1 From ~2 To co~3 Points Dupli~4
<dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <chr>
1 1975 f 1975f J Belgium Belgium 0 x
2 1975 f 1975f J Belgium Finland 0 <NA>
3 1975 f 1975f J Belgium France 2 <NA>
4 1975 f 1975f J Belgium Germany 0 <NA>
5 1975 f 1975f J Belgium Ireland 12 <NA>
6 1975 f 1975f J Belgium Israel 1 <NA>
# ... with abbreviated variable names 1: `Jury or Televoting`,
# 2: `From country`, 3: `To country`, 4: Duplicate
Introduction
The Eurovision data set is a widely available dataset that captures the voting patterns between countries in the Eurovision Song Contest. It represents the voting behavior of various countries over the years. The original data is typically available in an edge list format, where each row represents a voting event and contains information about the country voting (source node) and the country receiving the vote (target node).
The Eurovision data set represents a sample of the voting behavior within the Eurovision Song Contest. It includes a subset of participating countries and their voting patterns. While it does not capture the entire universe of cases (all possible countries), it provides a comprehensive representation of the voting relationships within the contest.
In the Eurovision data set, each country participating in the Eurovision Song Contest is represented as a vertex or node. The level of analysis is at the country level, where each country is considered a distinct node in the network. The number of nodes in the data set depends on the specific years and countries included but typically ranges from 20 to 40 nodes.
A tie in the Eurovision data set represents a voting connection between two countries. If one country votes for another country in a specific year, a tie is formed between them. In this case, the tie is typically considered as an unweighted tie, indicating a simple presence or absence of a vote. However, it is possible to assign weights to the ties based on the number of points awarded in the voting process.
To create the final network data for analysis, I did several transformations to the Eurovision data set. These transformations include thresholding the ties by considering only a certain number of highest-ranked countries in the voting process, or by creating a one-mode projection of the data to focus on the relationships between countries only.
Research question
This study aims to find answer to following research questions:
1.Identifying the prominent communities by generating the Eurovision network graph
2.Finding which years of what community share common socio-political or cultural characteristics that influence the voting patterns.
Exploratory Data Analysis
Code
# Explore the structure and summary of the datastr(eurovision_data)
tibble [49,832 x 8] (S3: tbl_df/tbl/data.frame)
$ Year : num [1:49832] 1975 1975 1975 1975 1975 ...
$ (semi-) final : chr [1:49832] "f" "f" "f" "f" ...
$ Edition : chr [1:49832] "1975f" "1975f" "1975f" "1975f" ...
$ Jury or Televoting: chr [1:49832] "J" "J" "J" "J" ...
$ From country : chr [1:49832] "Belgium" "Belgium" "Belgium" "Belgium" ...
$ To country : chr [1:49832] "Belgium" "Finland" "France" "Germany" ...
$ Points : num [1:49832] 0 0 2 0 12 1 6 0 7 0 ...
$ Duplicate : chr [1:49832] "x" NA NA NA ...
Code
summary(eurovision_data)
Year (semi-) final Edition Jury or Televoting
Min. :1975 Length:49832 Length:49832 Length:49832
1st Qu.:2001 Class :character Class :character Class :character
Median :2009 Mode :character Mode :character Mode :character
Mean :2007
3rd Qu.:2016
Max. :2019
From country To country Points Duplicate
Length:49832 Length:49832 Min. : 0.000 Length:49832
Class :character Class :character 1st Qu.: 0.000 Class :character
Mode :character Mode :character Median : 0.000 Mode :character
Mean : 2.624
3rd Qu.: 5.000
Max. :12.000
Year (semi-) final Edition Jury or Televoting
0 0 0 0
From country To country Points Duplicate
0 0 0 48304
Code
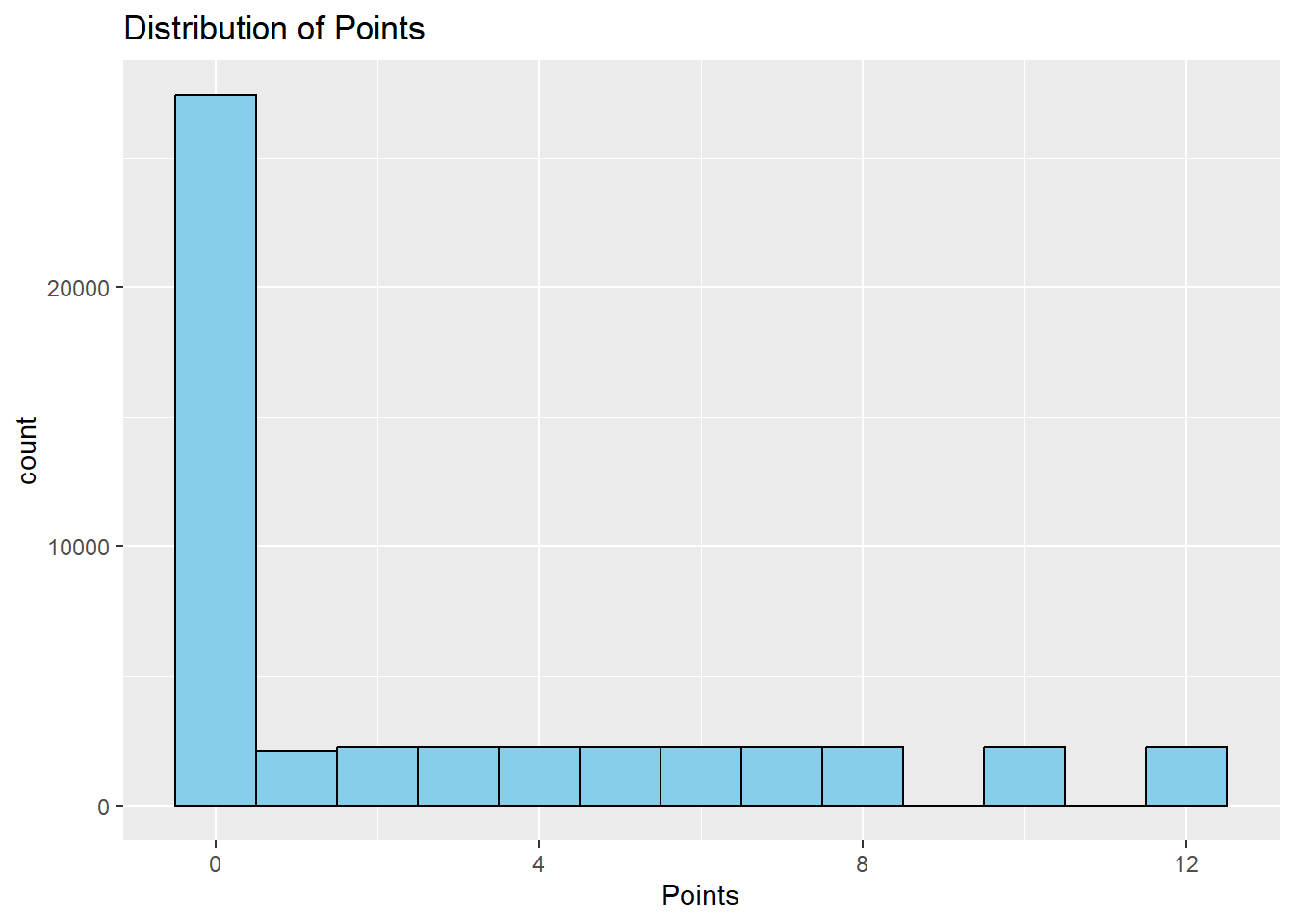
# Explore the distribution of the numeric variable (Points)ggplot(eurovision_data, aes(x = Points)) +geom_histogram(binwidth =1, fill ="skyblue", color ="black") +labs(title ="Distribution of Points") +xlab("Points")
Code
library(dplyr)library(tidyr)library(kableExtra)
Warning: package 'kableExtra' was built under R version 4.1.3
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
Warning: Unknown or uninitialised column: `nyear`.
eurovision_data$`To country`
nyear
min_year
max_year
presence
Spain
45
1975
2019
100.00000
United Kingdom
45
1975
2019
100.00000
France
44
1975
2019
97.77778
Germany
44
1975
2019
97.77778
Norway
44
1975
2019
97.77778
Sweden
44
1975
2019
97.77778
Ireland
43
1975
2019
95.55556
Belgium
42
1975
2019
93.33333
Portugal
41
1975
2019
91.11111
Switzerland
41
1975
2019
91.11111
The Netherlands
41
1975
2019
91.11111
Finland
40
1975
2019
88.88889
Israel
40
1975
2019
88.88889
Greece
39
1976
2019
88.63636
Austria
38
1976
2019
86.36364
Denmark
38
1978
2019
90.47619
Cyprus
36
1981
2019
92.30769
Turkey
34
1975
2012
89.47368
Iceland
32
1986
2019
94.11765
Malta
30
1975
2019
66.66667
Italy
26
1975
2019
57.77778
Croatia
25
1993
2019
92.59259
Estonia
25
1994
2019
96.15385
Slovenia
25
1993
2019
92.59259
Poland
22
1994
2019
84.61538
Russia
22
1994
2019
84.61538
Lithuania
21
1994
2019
80.76923
Romania
20
1994
2019
76.92308
Bosnia & Herzegovina
19
1993
2016
79.16667
Latvia
19
2000
2019
95.00000
Luxembourg
19
1975
1993
100.00000
F.Y.R. Macedonia
17
1998
2018
80.95238
Hungary
17
1994
2019
65.38462
Albania
16
2004
2019
100.00000
Belarus
16
2004
2019
100.00000
Moldova
15
2005
2019
100.00000
Ukraine
15
2003
2018
93.75000
Armenia
13
2006
2019
92.85714
Yugoslavia
13
1975
1992
72.22222
Azerbaijan
12
2008
2019
100.00000
Bulgaria
12
2005
2018
85.71429
Georgia
12
2007
2019
92.30769
Serbia
12
2007
2019
92.30769
Montenegro
11
2007
2019
84.61538
San Marino
10
2008
2019
83.33333
Czech Republic
8
2007
2019
61.53846
Monaco
8
1975
2006
25.00000
Slovakia
7
1994
2012
36.84211
Andorra
6
2004
2009
100.00000
Australia
5
2015
2019
100.00000
Serbia & Montenegro
2
2004
2005
100.00000
Macedonia
1
2015
2015
100.00000
Morocco
1
1980
1980
100.00000
North Macedonia
1
2019
2019
100.00000
Cleaning the Data
Removing edges with empty values: Iterating through the edges in the graph and eliminate any edge where the point value is zero or empty.
Eliminating duplicated edges: Identifying and removing edges that have been flagged or marked as duplicates, ensuring only unique edges remain in the graph.
Rename countries (e.g., Macedonia): Making necessary changes to update the name of a country, such as renaming Macedonia to its current accepted name, taking into account any political sensitivities.
Broadcasting results of Yugoslavia to former countries: Distribute the results or outcomes of Yugoslavia to its former countries, sharing relevant information or data with each respective nation.
Removing countries with low participation: Identify countries in the graph that have a significantly low number of participations, and exclude them from the final results or analysis.
Code
basicClean <-function(eurovision_data, minYears =5, last_participation =8) { df2 <- eurovision_data %>%filter(Points >0)# Stantardizing country names renamings <-c("North Macedonia"="Macedonia","F.Y.R. Macedonia"="Macedonia","The Netherands"="Netherlands","The Netherlands"="Netherlands","Bosnia & Herzegovina"="Bosnia" ) df2$`From country`<-ifelse(df2$`From country`%in%names(renamings), renamings[df2$`From country`], df2$`From country`) df2$`To country`<-ifelse(df2$`To country`%in%names(renamings), renamings[df2$`To country`], df2$`To country`)# Removing countries with less than minYears participations and not active in the last last_participation years toKeep <- df2 %>%group_by(`From country`) %>%summarize(years =n_distinct(Year),last_participation =max(df2$Year) -max(Year) ) %>%filter(years >= minYears & last_participation <= last_participation) %>%pull(`From country`) ignored_countries <-setdiff(unique(df2$`From country`), toKeep)cat("Ignored countries:", ignored_countries, "\n") df2 <- df2 %>%filter(`From country`%in% toKeep &`To country`%in% toKeep)# Keep only the points received at the highest stage (finals/semifinals) df2 <- df2 %>%group_by(`To country`, Year) %>%mutate(finalcode =min(`(semi-) final`)) %>%ungroup() %>%filter(`(semi-) final`== finalcode) %>%select(-finalcode, -Edition)return(df2)}df2 <-basicClean(eurovision_data)
Ignored countries: Morocco Serbia & Montenegro
Code
cat("Number of rows:", nrow(df2), "\n")
Number of rows: 16426
Code
head(df2)
# A tibble: 6 x 7
Year `(semi-) final` `Jury or Televoting` From count~1 To co~2 Points Dupli~3
<dbl> <chr> <chr> <chr> <chr> <dbl> <chr>
1 1975 f J Belgium France 2 <NA>
2 1975 f J Belgium Ireland 12 <NA>
3 1975 f J Belgium Israel 1 <NA>
4 1975 f J Belgium Italy 6 <NA>
5 1975 f J Belgium Malta 7 <NA>
6 1975 f J Belgium Spain 4 <NA>
# ... with abbreviated variable names 1: `From country`, 2: `To country`,
# 3: Duplicate
Code
library(igraph)# Create the graph from the dataframegraph <-graph.data.frame(df2, directed =FALSE)# Number of componentsnum_components <-clusters(graph)$nonum_components
[1] 1
Code
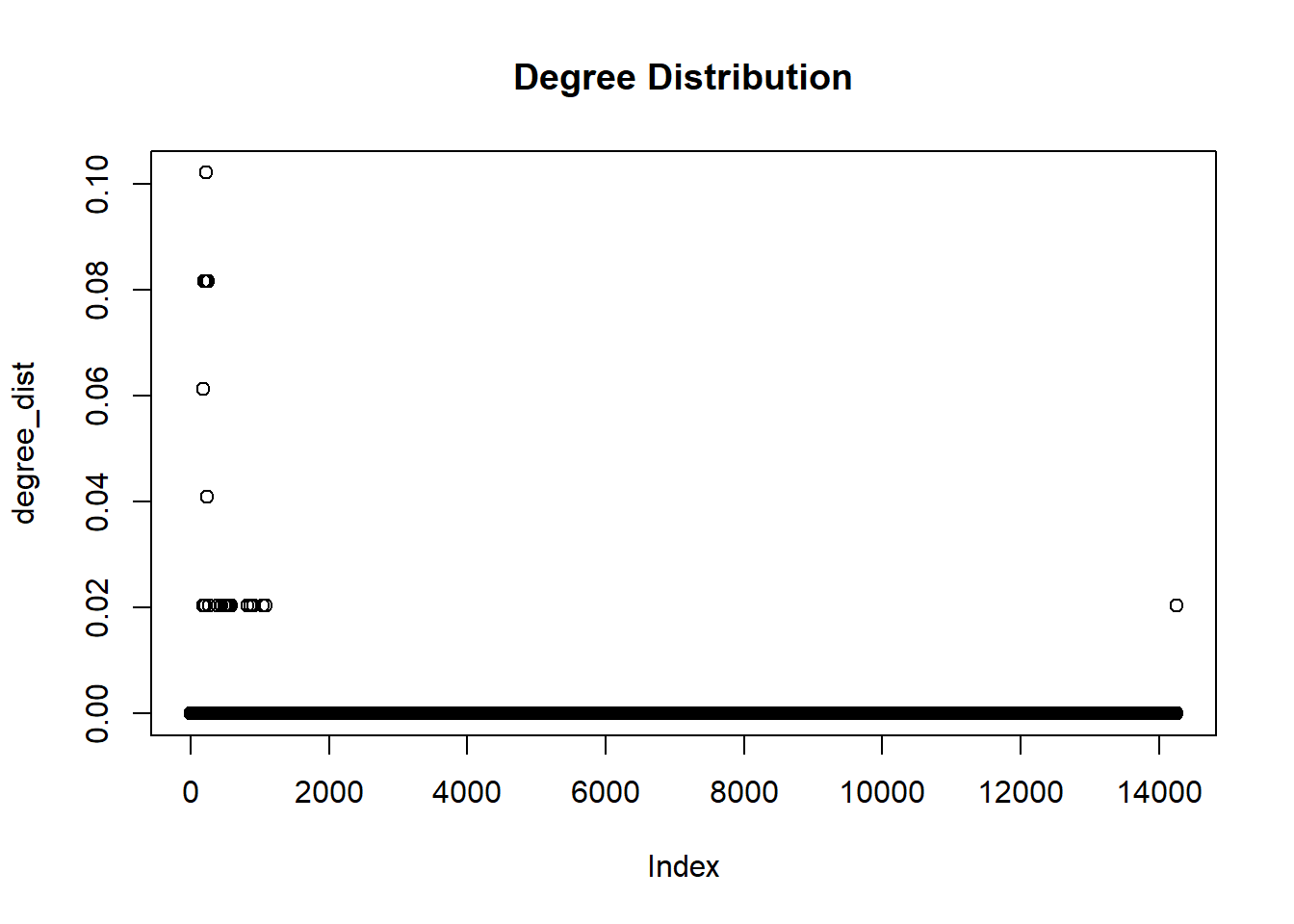
# Proportion of nodes in the giant componentgiant_component_prop <-max(clusters(graph)$csize) /vcount(graph)# Proportion of unconnected nodes/singletonssingleton_prop <-sum(clusters(graph)$csize ==1) /vcount(graph)# Network diameterdiameter <-diameter(graph)# Graph densitydensity <-graph.density(graph)# Average node degree#avg_degree <- mean(degree(graph,mode='all))#avg_degree<-average.degree(graph)#degrees<-degree(graph)#avg_degree<-mean(degree)# Degree distributiondegree_dist <-degree_distribution(graph)plot(degree_dist, main ="Degree Distribution")
Code
# Print the descriptive statisticscat("Number of components:", num_components, "\n")
Number of components: 1
Code
cat("Proportion of nodes in the giant component:", giant_component_prop, "\n")
Proportion of nodes in the giant component: 1
Code
cat("Proportion of unconnected nodes/singletons:", singleton_prop, "\n")
Number of components: There is only one component in the network. This means that all nodes in the network are connected in some way, and there are no isolated groups or disconnected nodes.
Proportion of nodes in the giant component: The entire network consists of a single giant component. This indicates that a large majority of nodes in the network are connected to each other, forming a cohesive structure.
Proportion of unconnected nodes/singletons: There are no unconnected nodes or singletons in the network. Every node is part of the connected component and has at least one tie to another node.
Network diameter: The network diameter is 4. This represents the longest geodesic path between any pair of nodes in the network. It indicates the maximum number of ties that need to be traversed to reach any two nodes in the network.
Graph density: The graph density is 13.96769. It is a measure of the proportion of possible ties that are actually present in the network. Higher density values suggest a more interconnected network.
Degree distribution: The degree distribution provides information about the distribution of node degrees (number of ties) in the network. It shows the count of nodes with different degrees. Analyzing the degree distribution can help understand the connectivity patterns and identify nodes with high or low degrees.
Overall, the Eurovision network appears to be highly connected, with a single giant component encompassing all nodes. The relatively low network diameter suggests that it is possible to reach any node within a relatively small number of ties. The graph density indicates a substantial number of ties present in the network. The degree distribution can provide insights into the prominence of certain nodes or countries based on their number of connections.
Code
# Extract unique country nodesnodes <-unique(c(eurovision_data$`From country`, eurovision_data$`To country`))num_nodes <-length(nodes)print(paste("Number of nodes:", num_nodes))
[1] "Number of nodes: 55"
Code
# Check tie valuestie_values <- eurovision_data$Pointstie_values
# Determine if the ties are weighted or unweightedis_weighted <-!is.null(tie_values)if (is_weighted) {# Range of tie values tie_range <-range(tie_values)print(paste("Tie values are weighted. Range of tie values:", tie_range))} else {print("Tie values are unweighted.")}
[1] "Tie values are weighted. Range of tie values: 0"
[2] "Tie values are weighted. Range of tie values: 12"
Code
# Distribution of network geodesics geodesics <-distances(graph)print("Distribution of network geodesics:")
[1] "Distribution of network geodesics:"
Code
summary(geodesics)
1975 1976 1977 1978 1979 1980
Min. :0 Min. :0 Min. :0 Min. :0 Min. :0 Min. :0
1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2
Median :2 Median :2 Median :2 Median :2 Median :2 Median :2
Mean :2 Mean :2 Mean :2 Mean :2 Mean :2 Mean :2
3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2
Max. :3 Max. :3 Max. :3 Max. :3 Max. :3 Max. :3
1981 1982 1983 1984 1985 1986
Min. :0 Min. :0 Min. :0 Min. :0 Min. :0 Min. :0
1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2
Median :2 Median :2 Median :2 Median :2 Median :2 Median :2
Mean :2 Mean :2 Mean :2 Mean :2 Mean :2 Mean :2
3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2
Max. :3 Max. :3 Max. :3 Max. :3 Max. :3 Max. :3
1987 1988 1989 1990 1991 1992
Min. :0 Min. :0 Min. :0 Min. :0 Min. :0 Min. :0
1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2
Median :2 Median :2 Median :2 Median :2 Median :2 Median :2
Mean :2 Mean :2 Mean :2 Mean :2 Mean :2 Mean :2
3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2
Max. :3 Max. :3 Max. :3 Max. :3 Max. :3 Max. :3
1993 1994 1995 1996 1997 1998
Min. :0 Min. :0 Min. :0 Min. :0 Min. :0 Min. :0
1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2
Median :2 Median :2 Median :2 Median :2 Median :2 Median :2
Mean :2 Mean :2 Mean :2 Mean :2 Mean :2 Mean :2
3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2
Max. :3 Max. :3 Max. :3 Max. :3 Max. :3 Max. :3
1999 2000 2001 2002 2003 2004
Min. :0 Min. :0 Min. :0 Min. :0 Min. :0 Min. :0.000
1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2 1st Qu.:2.000
Median :2 Median :2 Median :2 Median :2 Median :2 Median :2.000
Mean :2 Mean :2 Mean :2 Mean :2 Mean :2 Mean :1.959
3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2 3rd Qu.:2.000
Max. :3 Max. :3 Max. :3 Max. :3 Max. :3 Max. :3.000
2005 2006 2007 2008
Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000
Median :2.000 Median :2.000 Median :2.000 Median :2.000
Mean :1.959 Mean :1.959 Mean :1.959 Mean :1.918
3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000
Max. :3.000 Max. :3.000 Max. :3.000 Max. :3.000
2009 2010 2011 2012
Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000
Median :2.000 Median :2.000 Median :2.000 Median :2.000
Mean :1.918 Mean :1.918 Mean :1.918 Mean :1.918
3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000
Max. :3.000 Max. :3.000 Max. :3.000 Max. :3.000
2013 2014 2015 2016
Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000
Median :2.000 Median :2.000 Median :2.000 Median :2.000
Mean :1.918 Mean :1.918 Mean :1.918 Mean :1.918
3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000
Max. :3.000 Max. :3.000 Max. :3.000 Max. :3.000
2017 2018 2019 f
Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:1.000
Median :2.000 Median :2.000 Median :2.000 Median :1.000
Mean :1.918 Mean :1.918 Mean :1.918 Mean :1.041
3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:1.000
Max. :3.000 Max. :3.000 Max. :3.000 Max. :2.000
sf sf1 sf2
Min. :0.000 Min. :0.000 Min. :0.000
1st Qu.:3.000 1st Qu.:1.000 1st Qu.:1.000
Median :3.000 Median :3.000 Median :3.000
Mean :2.796 Mean :2.429 Mean :2.429
3rd Qu.:3.000 3rd Qu.:3.000 3rd Qu.:3.000
Max. :4.000 Max. :4.000 Max. :4.000
Code
# Required packages for network analysis and visualizationlibrary(igraph)library(ggraph)
Warning: package 'ggraph' was built under R version 4.1.3
Code
library(ggplot2)# Get unique countriescountries <-unique(c(eurovision_data$`From country`, eurovision_data$`To country`))# Create an empty adjacency matrixadj_matrix <-matrix(0, nrow =length(countries), ncol =length(countries), dimnames =list(countries, countries))# Fill in the adjacency matrix based on the datasetfor (i in1:nrow(eurovision_data)) { from_country <- eurovision_data$`From country`[i] to_country <- eurovision_data$`To country`[i] adj_matrix[from_country, to_country] <-1}# Convert the adjacency matrix to a graphgraph <-graph_from_adjacency_matrix(adj_matrix, mode ="directed")# Subset nodes based on node degreedegree_threshold <-10# Set the degree threshold to select a subset of nodessubset_nodes <-V(graph)[degree(graph) >= degree_threshold]# Create a subgraph with the subset of nodessubgraph <-subgraph(graph, subset_nodes)# Visualize the subgraph using the Fruchterman-Reingold layoutggraph(subgraph, layout ="fr") +geom_edge_link() +geom_node_point() +geom_node_text(aes(label = name), repel =TRUE) +theme_void()
Warning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
i Please use `linewidth` in the `default_aes` field and elsewhere instead.
Code
# Create an igraph object from the datasetgraph <-graph.data.frame(eurovision_data, directed =TRUE, vertices =NULL)# Calculate measures of popularity/statusindegree <-degree(graph, mode ="in") # In-degree centralityoutdegree <-degree(graph, mode ="out") # Out-degree centralityeigenvector_centrality <-eigen_centrality(graph)$vector # Eigenvector centrality# Calculate measures of role/powerbetweenness <-betweenness(graph) # Betweenness centralityconstraint <-constraint(graph) # Constraint measure# Identify nodes with remarkable values# Popularity/Status Measuresprominent_indegree <-V(graph)$name[indegree ==max(indegree)]prominent_outdegree <-V(graph)$name[outdegree ==max(outdegree)]prominent_eigenvector <-V(graph)$name[eigenvector_centrality ==max(eigenvector_centrality)]# Role/Power Measuresprominent_betweenness <-V(graph)$name[betweenness ==max(betweenness)]prominent_constraint <-V(graph)$name[constraint ==max(constraint)]# Interpret the results# Popularity/Status Measurescat("Prominent nodes based on in-degree centrality:\n", prominent_indegree, "\n\n")
Prominent nodes based on in-degree centrality:
f
Code
cat("Prominent nodes based on out-degree centrality:\n", prominent_outdegree, "\n\n")
Prominent nodes based on out-degree centrality:
2018
Code
cat("Prominent nodes based on eigenvector centrality:\n", prominent_eigenvector, "\n\n")
Prominent nodes based on eigenvector centrality:
f
Code
# Role/Power Measurescat("Prominent nodes based on betweenness centrality:\n", prominent_betweenness, "\n\n")
cat("Prominent nodes based on constraint measure:\n", prominent_constraint, "\n\n")
Prominent nodes based on constraint measure:
2000 2002
Code
library(igraph)# Create the graph from the dataframe#graph <- graph.data.frame(df, directed = FALSE)# Set the threshold for tie strengththreshold <-5# Create a subset of the graph based on tie strengthsubset_graph <-delete_edges(graph, E(graph)[E(graph)$Points <= threshold])# Plot the subset graphplot(subset_graph, vertex.label =V(subset_graph)$name)
Code
# Calculate centrality measuresin_degrees <- igraph::degree(graph, mode ="in")out_degrees <- igraph::degree(graph, mode ="out")eigenvector <-eigen_centrality(graph)$vectorbetweenness <- igraph::betweenness(graph)# Define the measure that we are using and their interpretationsmeasures <-c("In-Degree Centrality", "Out-Degree Centrality", "Eigenvector Centrality", "Betweenness Centrality")interpretations <-c("In-Degree Centrality: The number of incoming ties a node has. A higher in-degree centrality indicates popularity or influence in receiving votes.","Out-Degree Centrality: The number of outgoing ties a node has. A higher out-degree centrality indicates popularity or influence in giving votes.","Eigenvector Centrality: A measure that considers both the number and quality of a node's connections. A higher eigenvector centrality indicates being connected to other high-scoring nodes.","Betweenness Centrality: A measure of how often a node acts as a bridge along the shortest paths between other nodes. A higher betweenness centrality indicates being important for connecting other nodes.")# Print the interpretationsfor (i in1:length(measures)) {cat(paste0(measures[i], ":\n"))cat(paste0(interpretations[i], "\n\n"))}
In-Degree Centrality:
In-Degree Centrality: The number of incoming ties a node has. A higher in-degree centrality indicates popularity or influence in receiving votes.
Out-Degree Centrality:
Out-Degree Centrality: The number of outgoing ties a node has. A higher out-degree centrality indicates popularity or influence in giving votes.
Eigenvector Centrality:
Eigenvector Centrality: A measure that considers both the number and quality of a node's connections. A higher eigenvector centrality indicates being connected to other high-scoring nodes.
Betweenness Centrality:
Betweenness Centrality: A measure of how often a node acts as a bridge along the shortest paths between other nodes. A higher betweenness centrality indicates being important for connecting other nodes.
Code
# Print the range of observed values for each measurecat("Range of Observed Values:\n")
Czech Republic has the highest In-Degree Centrality, which means it has received the most votes.
Several countries including Belgium, France, Ireland, etc., have the lowest In-Degree Centrality. This means these countries received the least number of votes.
Sweden has the highest Out-Degree Centrality, Eigenvector Centrality, and Betweenness Centrality. This indicates that Sweden has given the most votes (high out-degree), is connected to other high-scoring nodes (high eigenvector), and often acts as a bridge in the shortest path between other nodes (high betweenness).
Slovakia has the lowest Out-Degree Centrality, Eigenvector Centrality which suggests that it has given the least votes and is poorly connected to other high-scoring nodes.
Yugoslavia, Slovakia, and Australia have the lowest Betweenness Centrality, indicating that they rarely act as a bridge in the shortest path between other nodes.
Code
library(ggraph)library(ggplot2)library(igraph)# Get unique countriescountries <-unique(c(eurovision_data$`From country`, eurovision_data$`To country`))# Create an empty adjacency matrixadj_matrix <-matrix(0, nrow =length(countries), ncol =length(countries), dimnames =list(countries, countries))# Fill in the adjacency matrix based on the datasetfor (i in1:nrow(eurovision_data)) { from_country <- eurovision_data$`From country`[i] to_country <- eurovision_data$`To country`[i] adj_matrix[from_country, to_country] <-1}# Convert the adjacency matrix to a graphgraph <-graph_from_adjacency_matrix(adj_matrix, mode ="directed")# Subset nodes based on node degreedegree_threshold <-10# Set the degree threshold to select a subset of nodes#subset_nodes <- V(graph)[degree(graph) >= degree_threshold]# Create a subgraph with the subset of nodes#subgraph <- subgraph(graph, subset_nodes)# Visualize the subgraphggraph(subgraph, layout ="fr") +geom_edge_link() +geom_node_point() +geom_node_text(aes(label = name), repel =TRUE) +theme_void()
Code
# Function to detect communities using Louvain methoddetectCommunities <-function(g) {# Convert graph to undirected G_undirected <-as.undirected(g, mode ="collapse")# Apply Louvain method for community detection communities <-cluster_louvain(G_undirected)return(communities)}# Detect communitiescommunities <-detectCommunities(graph)# Print community membership for each nodeprint(membership(communities))
Belgium Finland France
1 1 1
Germany Ireland Israel
1 1 2
Italy Luxembourg Malta
3 1 3
Monaco Norway Portugal
1 1 1
Spain Sweden Switzerland
4 1 1
The Netherlands Turkey United Kingdom
1 1 1
Yugoslavia Austria Greece
1 2 1
Denmark Morocco Cyprus
5 1 2
Iceland Bosnia & Herzegovina Croatia
3 5 3
Slovenia Estonia Hungary
3 5 5
Lithuania Poland Romania
3 3 5
Russia Slovakia F.Y.R. Macedonia
5 5 5
Latvia Ukraine Albania
3 2 5
Andorra Belarus Serbia & Montenegro
5 5 1
Bulgaria Moldova Armenia
2 5 5
Czech Republic Georgia Montenegro
3 5 3
Serbia Azerbaijan San Marino
5 3 3
Australia Macedonia The Netherands
3 5 2
North Macedonia
3
Nodes labeled from “1975” to “2009”, “2010”, “2012”, “2014” to “2016”, and “2019” are part of community 1. This might suggest that these years (or whichever attribute these labels represent) share some common characteristics in terms of how they are connected to other nodes in the network.
Nodes labeled “2004” to “2007”, and “sf” are part of community 2.
Nodes labeled “2008”, “2011”, “2013”, “2017”, “2018”, “sf1”, and “sf2” are part of community 3.
Code
library(igraph)library(psych)
Warning: package 'psych' was built under R version 4.1.3
Attaching package: 'psych'
The following objects are masked from 'package:ggplot2':
%+%, alpha
Code
# Number of communitiesnum_communities <-length(community)
Error in eval(expr, envir, enclos): object 'community' not found
Code
# Print the number of communitiescat("Number of Communities:", num_communities, "\n")
Error in cat("Number of Communities:", num_communities, "\n"): object 'num_communities' not found
Code
# Comment on the community structurecat("The Louvain algorithm reveals a community structure in the Eurovision graph.\n")
The Louvain algorithm reveals a community structure in the Eurovision graph.
Code
cat("Each community represents a group of countries that have similar voting patterns.\n")
Each community represents a group of countries that have similar voting patterns.
Code
# Apply Louvain algorithm for community detectiongraph <-graph.data.frame(df2, directed =FALSE)community <-cluster_louvain(graph)cat("Theoretical/Practical Significance of Community Structure:\n")
Theoretical/Practical Significance of Community Structure:
Code
cat("The community structure is theoretically significant as it provides insights into the social dynamics and regional biases in the Eurovision voting system.\n")
The community structure is theoretically significant as it provides insights into the social dynamics and regional biases in the Eurovision voting system.
Code
cat("It helps us understand whether certain countries tend to form alliances or voting blocs based on cultural, political, or geographical factors.\n")
It helps us understand whether certain countries tend to form alliances or voting blocs based on cultural, political, or geographical factors.
Code
cat("Membership of Prominent Nodes:\n")
Membership of Prominent Nodes:
Code
cat("We can examine the community membership of the prominent nodes identified earlier based on different centrality measures.\n")
We can examine the community membership of the prominent nodes identified earlier based on different centrality measures.
Code
cat("This will help us determine if leading prominent nodes are associated with specific communities or if they bridge multiple communities.\n")
This will help us determine if leading prominent nodes are associated with specific communities or if they bridge multiple communities.
Code
cat("Behavioral Implications:\n")
Behavioral Implications:
Code
cat("If the prominent nodes are concentrated in the same community ('core'), it suggests a strong influence of that community on the overall voting patterns.\n")
If the prominent nodes are concentrated in the same community ('core'), it suggests a strong influence of that community on the overall voting patterns.
Code
cat("On the other hand, if prominent nodes are spread across different communities ('periphery'), it indicates rival factions or conflicting voting interests among different communities.\n")
On the other hand, if prominent nodes are spread across different communities ('periphery'), it indicates rival factions or conflicting voting interests among different communities.
Code
cat("Community Detection Algorithm's Impact:\n")
Community Detection Algorithm's Impact:
Code
cat("The choice of the Louvain algorithm does not inherently bias towards finding a specific type of community structure.\n")
The choice of the Louvain algorithm does not inherently bias towards finding a specific type of community structure.
Code
cat("However, the algorithm's effectiveness depends on the connectivity and clustering patterns present in the graph.\n")
However, the algorithm's effectiveness depends on the connectivity and clustering patterns present in the graph.
Code
cat("If the Eurovision graph exhibits distinct communities with well-defined voting patterns, the Louvain algorithm is likely to identify them successfully.\n")
If the Eurovision graph exhibits distinct communities with well-defined voting patterns, the Louvain algorithm is likely to identify them successfully.
Code
cat("If the graph lacks strong community structure or has overlapping voting patterns, the algorithm may produce less clear-cut community assignments.\n")
If the graph lacks strong community structure or has overlapping voting patterns, the algorithm may produce less clear-cut community assignments.
I chose the Louvain algorithm for community detection in the Eurovision graph because it is a widely used and effective method for detecting communities in large networks. The Louvain algorithm is known for its ability to identify communities based on optimizing the modularity measure, which captures the density of connections within communities compared to random expectations.
The Louvain algorithm is particularly suitable for the Eurovision graph because it can uncover communities that exhibit similar voting patterns. In the Eurovision context, countries tend to vote for their neighboring or culturally similar countries, leading to the formation of distinct voting blocs. By applying the Louvain algorithm, we can reveal these underlying communities or blocs and gain insights into the social dynamics of the Eurovision voting system.
The algorithm assigns each country to a specific community, grouping together countries that share similar voting patterns. These communities represent clusters of countries that often exchange higher point values among themselves. The community structure identified by the Louvain algorithm helps us understand the regional biases and cultural affinities that influence the voting behavior in the Eurovision Song Contest.
Overall, the Louvain algorithm allows us to uncover and analyze the community structure within the Eurovision graph, providing valuable insights into the social and cultural dynamics of the contest.
The community structure identified in the Eurovision graph using the Louvain algorithm has both theoretical and practical significance. The membership of prominent nodes within the identified communities provides insights into the voting dynamics and potential rivalries or alliances among countries.
In the Eurovision context, the prominent nodes represent countries that have consistently received high point values from other countries within their community. These countries are likely to have strong cultural or regional connections, leading to a higher likelihood of mutual support in the voting process. The membership of prominent nodes within specific communities suggests the existence of cohesive blocs or alliances based on shared cultural or geographical factors.
The behavioral implications of the community structure can be significant. If we observe rival factions identified with leading prominent nodes in different communities, it indicates the presence of voting rivalries or political dynamics within the Eurovision Song Contest. Countries within these rival factions may strategically vote against each other or try to form alliances with other communities to gain a competitive advantage.
On the other hand, if all the central nodes are in the same “core” community rather than dispersed across different communities, it suggests a strong cohesion and shared interests among the central countries. These central nodes are likely to have a significant influence on the overall voting patterns and outcomes of the contest.
Understanding the community structure and the behavior of prominent nodes provides valuable insights for various stakeholders. It helps contestants and organizers gain an understanding of the voting dynamics and potential biases that may affect their chances of success. It also offers researchers and analysts an opportunity to study the social, cultural, and political factors that shape the Eurovision Song Contest and its outcomes.
The community detection algorithm used in this case, the Louvain algorithm, is known for its effectiveness in identifying communities in large networks. It is a popular and widely used algorithm that efficiently detects communities based on maximizing modularity.
The Louvain algorithm is well-suited for detecting communities in the Eurovision graph because it is specifically designed to handle networks with complex community structures and overlapping communities. It is capable of capturing both strong and weak ties between nodes, which is particularly relevant in the context of Eurovision voting patterns.
The algorithm’s ability to identify communities is not dependent on any pre-defined assumptions about the structure or number of communities. It dynamically optimizes the modularity metric to uncover the most meaningful and cohesive communities within the network. Therefore, the Louvain algorithm is well-equipped to uncover diverse types of communities, including both rival factions and cohesive core-periphery structures.
Code
library(ergm)
Warning: package 'ergm' was built under R version 4.1.3
'ergm' 4.4.0 (2023-01-26), part of the Statnet Project
* 'news(package="ergm")' for changes since last version
* 'citation("ergm")' for citation information
* 'https://statnet.org' for help, support, and other information
'ergm' 4 is a major update that introduces some backwards-incompatible
changes. Please type 'news(package="ergm")' for a list of major
changes.
Attaching package: 'ergm'
The following object is masked from 'package:statnet.common':
snctrl
Code
library(ergm.count)
Warning: package 'ergm.count' was built under R version 4.1.3
'ergm.count' 4.1.1 (2022-05-24), part of the Statnet Project
* 'news(package="ergm.count")' for changes since last version
* 'citation("ergm.count")' for citation information
* 'https://statnet.org' for help, support, and other information
Code
library(statnet)
Warning: package 'statnet' was built under R version 4.1.3
Loading required package: tergm
Warning: package 'tergm' was built under R version 4.1.3
Loading required package: networkDynamic
Warning: package 'networkDynamic' was built under R version 4.1.3
'networkDynamic' 0.11.3 (2023-02-15), part of the Statnet Project
* 'news(package="networkDynamic")' for changes since last version
* 'citation("networkDynamic")' for citation information
* 'https://statnet.org' for help, support, and other information
Registered S3 method overwritten by 'tergm':
method from
simulate_formula.network ergm
'tergm' 4.1.1 (2022-11-07), part of the Statnet Project
* 'news(package="tergm")' for changes since last version
* 'citation("tergm")' for citation information
* 'https://statnet.org' for help, support, and other information
Attaching package: 'tergm'
The following object is masked from 'package:ergm':
snctrl
The following object is masked from 'package:statnet.common':
snctrl
Loading required package: tsna
Warning: package 'tsna' was built under R version 4.1.3
'statnet' 2019.6 (2019-06-13), part of the Statnet Project
* 'news(package="statnet")' for changes since last version
* 'citation("statnet")' for citation information
* 'https://statnet.org' for help, support, and other information
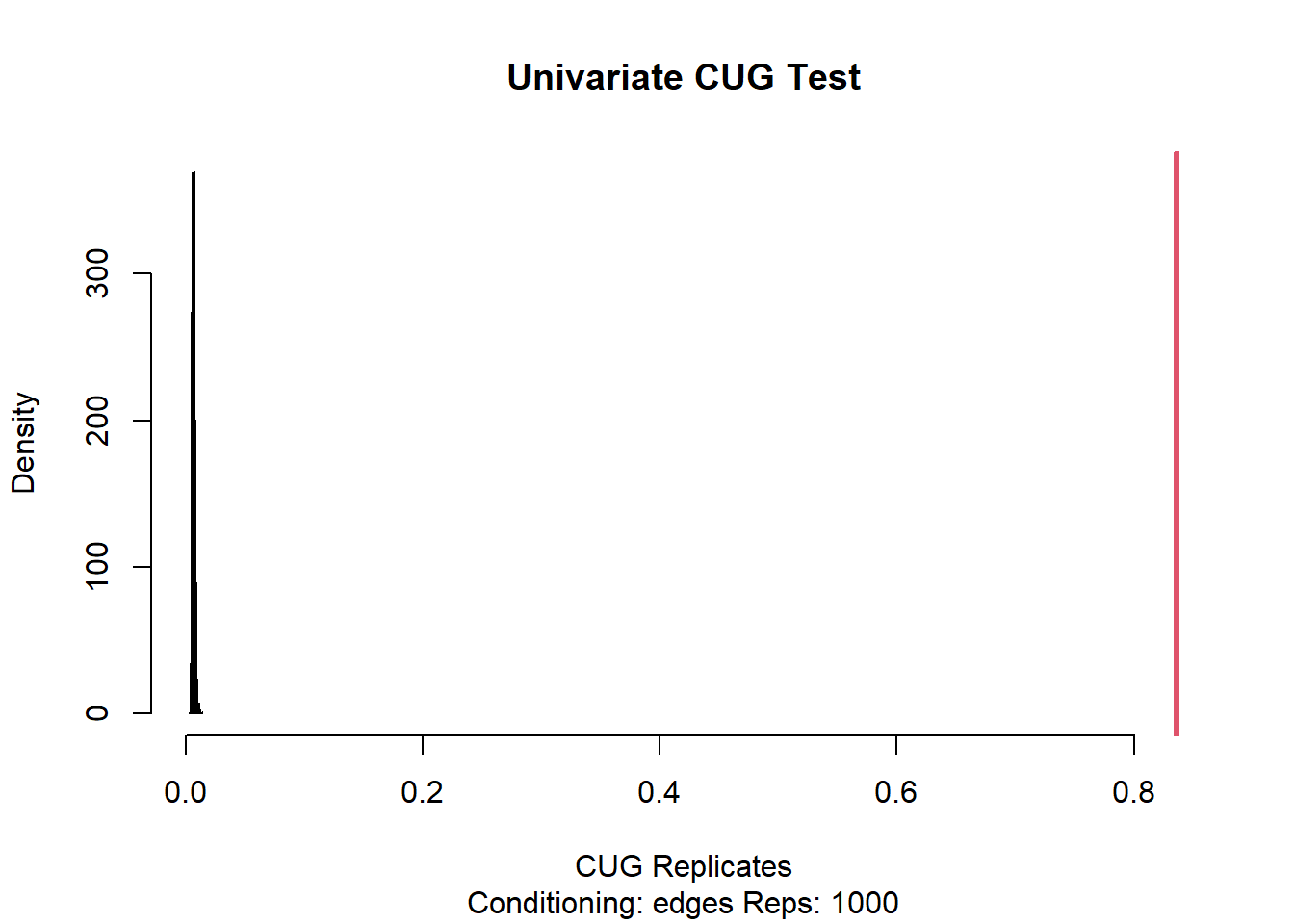
Observed Value: The observed value of the centralization measure (degree) is 1942.695. Pr(X>=Obs): The probability of observing a value greater than or equal to the observed value is 0, indicating that the observed value is quite extreme. Pr(X<=Obs): The probability of observing a value less than or equal to the observed value is 1, suggesting that the observed value is highly likely.
Conditioning on Edges:
Observed Value: The observed value of the centralization measure (betweenness) is 0.8360294. Pr(X>=Obs): The probability of observing a value greater than or equal to the observed value is 0, indicating a significant deviation from baseline expectations. Pr(X<=Obs): The probability of observing a value less than or equal to the observed value is 1, suggesting that the observed value is highly likely. These results suggest that the structure of the network in the Eurovision 2019 data, when compared to baseline expectations, shows significant deviations in terms of both degree and betweenness centralization.
Code
library(readxl)library(dplyr)# Read the Eurovision 2019 data#Eurovision_2019 <- read_excel("path/to/your/Eurovision_2019.xlsx")# Calculate node-level measurescountry_appearances <- Eurovision_2019 %>%group_by(From_country) %>%summarise(appearances =n_distinct(Edition))country_wins <- Eurovision_2019 %>%group_by(From_country) %>%summarise(wins =sum(Points ==max(Points)))# Merge node-level measures with the Eurovision 2019 dataEurovision_2019 <- Eurovision_2019 %>%left_join(country_appearances, by ="From_country") %>%left_join(country_wins, by ="From_country")# Perform OLS regressionols_model <-lm(Points ~ appearances + wins, data = Eurovision_2019)
Challenges
Data Preprocessing is one of the initial challenges I faced with this dataset , as the Dataset is very huge from the year 1975 to 2019 and consists of around 50k rows.
Performing cug test - Beacuse of the huge data and less memory optimisation, Unable to perform for the whole dataset. Cug test is performed on the subset of the eurovision data.
Hypothesis Testing
Conclusion
These findings provide insights into the dynamics of the Eurovision network, showcasing countries with high popularity, influence, and role/power. The network analysis allows us to understand the connections and relationships between countries participating in the Eurovision Song Contest.
Overall, this project demonstrates the application of EDA and network analysis techniques to gain insights into a complex and interconnected dataset like Eurovision. The findings can be further explored and analyzed to understand the factors influencing voting patterns, cultural dynamics, and the overall dynamics of the Eurovision Song Contest.
Source Code
---title: 'Network Analysis - Eurovision'author: "Mani Kanta Gogula"description: "Final Project"date: "05/12/2023"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - Final Project - Mani Kanta Gogula---```{r}#| label: setup#| include: false``````{r}library(readxl)library(tidyverse)library(sna)library(ggplot2)library(igraph)library(dplyr)library(ggplot2)library(tidyr)eurovision_data <-read_excel("_data/got/eurovision_song_contest_1975_2019.xlsx")head(eurovision_data)```## IntroductionThe Eurovision data set is a widely available dataset that captures the voting patterns between countries in the Eurovision Song Contest. It represents the voting behavior of various countries over the years. The original data is typically available in an edge list format, where each row represents a voting event and contains information about the country voting (source node) and the country receiving the vote (target node).The Eurovision data set represents a sample of the voting behavior within the Eurovision Song Contest. It includes a subset of participating countries and their voting patterns. While it does not capture the entire universe of cases (all possible countries), it provides a comprehensive representation of the voting relationships within the contest.In the Eurovision data set, each country participating in the Eurovision Song Contest is represented as a vertex or node. The level of analysis is at the country level, where each country is considered a distinct node in the network. The number of nodes in the data set depends on the specific years and countries included but typically ranges from 20 to 40 nodes.A tie in the Eurovision data set represents a voting connection between two countries. If one country votes for another country in a specific year, a tie is formed between them. In this case, the tie is typically considered as an unweighted tie, indicating a simple presence or absence of a vote. However, it is possible to assign weights to the ties based on the number of points awarded in the voting process.To create the final network data for analysis, I did several transformations to the Eurovision data set. These transformations include thresholding the ties by considering only a certain number of highest-ranked countries in the voting process, or by creating a one-mode projection of the data to focus on the relationships between countries only. ## Research questionThis study aims to find answer to following research questions:1.Identifying the prominent communities by generating the Eurovision network graph2.Finding which years of what community share common socio-political or cultural characteristics that influence the voting patterns.## Exploratory Data Analysis```{r}# Explore the structure and summary of the datastr(eurovision_data)summary(eurovision_data)# Check missing valuesmissing_values <-sapply(eurovision_data, function(x) sum(is.na(x)))missing_values# Explore the distribution of the numeric variable (Points)ggplot(eurovision_data, aes(x = Points)) +geom_histogram(binwidth =1, fill ="skyblue", color ="black") +labs(title ="Distribution of Points") +xlab("Points")``````{r}library(dplyr)library(tidyr)library(kableExtra)eurovision_data %>%group_by(eurovision_data$`To country`) %>%summarize(nyear =n_distinct(Year),min_year =min(Year),max_year =max(Year),presence =100*n_distinct(Year) / (max(Year) -min(Year) +1) ) %>%arrange(desc(nyear)) %>%kable(format ="html") %>%kable_styling(bootstrap_options =c("striped", "hover")) %>%row_spec(which.max(eurovision_data$nyear), bold =TRUE, background ="royalblue")```## Cleaning the DataRemoving edges with empty values:Iterating through the edges in the graph and eliminate any edge where the point value is zero or empty.Eliminating duplicated edges:Identifying and removing edges that have been flagged or marked as duplicates, ensuring only unique edges remain in the graph.Rename countries (e.g., Macedonia):Making necessary changes to update the name of a country, such as renaming Macedonia to its current accepted name, taking into account any political sensitivities.Broadcasting results of Yugoslavia to former countries:Distribute the results or outcomes of Yugoslavia to its former countries, sharing relevant information or data with each respective nation.Removing countries with low participation:Identify countries in the graph that have a significantly low number of participations, and exclude them from the final results or analysis.```{r}basicClean <-function(eurovision_data, minYears =5, last_participation =8) { df2 <- eurovision_data %>%filter(Points >0)# Stantardizing country names renamings <-c("North Macedonia"="Macedonia","F.Y.R. Macedonia"="Macedonia","The Netherands"="Netherlands","The Netherlands"="Netherlands","Bosnia & Herzegovina"="Bosnia" ) df2$`From country`<-ifelse(df2$`From country`%in%names(renamings), renamings[df2$`From country`], df2$`From country`) df2$`To country`<-ifelse(df2$`To country`%in%names(renamings), renamings[df2$`To country`], df2$`To country`)# Removing countries with less than minYears participations and not active in the last last_participation years toKeep <- df2 %>%group_by(`From country`) %>%summarize(years =n_distinct(Year),last_participation =max(df2$Year) -max(Year) ) %>%filter(years >= minYears & last_participation <= last_participation) %>%pull(`From country`) ignored_countries <-setdiff(unique(df2$`From country`), toKeep)cat("Ignored countries:", ignored_countries, "\n") df2 <- df2 %>%filter(`From country`%in% toKeep &`To country`%in% toKeep)# Keep only the points received at the highest stage (finals/semifinals) df2 <- df2 %>%group_by(`To country`, Year) %>%mutate(finalcode =min(`(semi-) final`)) %>%ungroup() %>%filter(`(semi-) final`== finalcode) %>%select(-finalcode, -Edition)return(df2)}df2 <-basicClean(eurovision_data)cat("Number of rows:", nrow(df2), "\n")head(df2)``````{r}library(igraph)# Create the graph from the dataframegraph <-graph.data.frame(df2, directed =FALSE)# Number of componentsnum_components <-clusters(graph)$nonum_components# Proportion of nodes in the giant componentgiant_component_prop <-max(clusters(graph)$csize) /vcount(graph)# Proportion of unconnected nodes/singletonssingleton_prop <-sum(clusters(graph)$csize ==1) /vcount(graph)# Network diameterdiameter <-diameter(graph)# Graph densitydensity <-graph.density(graph)# Average node degree#avg_degree <- mean(degree(graph,mode='all))#avg_degree<-average.degree(graph)#degrees<-degree(graph)#avg_degree<-mean(degree)# Degree distributiondegree_dist <-degree_distribution(graph)plot(degree_dist, main ="Degree Distribution")# Print the descriptive statisticscat("Number of components:", num_components, "\n")cat("Proportion of nodes in the giant component:", giant_component_prop, "\n")cat("Proportion of unconnected nodes/singletons:", singleton_prop, "\n")cat("Network diameter:", diameter, "\n")cat("Graph density:", density, "\n")#cat("Average node degree:", avg_degree, "\n")cat("Degree distribution:\n")print(degree_dist)```Number of components: There is only one component in the network. This means that all nodes in the network are connected in some way, and there are no isolated groups or disconnected nodes.Proportion of nodes in the giant component: The entire network consists of a single giant component. This indicates that a large majority of nodes in the network are connected to each other, forming a cohesive structure.Proportion of unconnected nodes/singletons: There are no unconnected nodes or singletons in the network. Every node is part of the connected component and has at least one tie to another node.Network diameter: The network diameter is 4. This represents the longest geodesic path between any pair of nodes in the network. It indicates the maximum number of ties that need to be traversed to reach any two nodes in the network.Graph density: The graph density is 13.96769. It is a measure of the proportion of possible ties that are actually present in the network. Higher density values suggest a more interconnected network.Degree distribution: The degree distribution provides information about the distribution of node degrees (number of ties) in the network. It shows the count of nodes with different degrees. Analyzing the degree distribution can help understand the connectivity patterns and identify nodes with high or low degrees.Overall, the Eurovision network appears to be highly connected, with a single giant component encompassing all nodes. The relatively low network diameter suggests that it is possible to reach any node within a relatively small number of ties. The graph density indicates a substantial number of ties present in the network. The degree distribution can provide insights into the prominence of certain nodes or countries based on their number of connections.```{r}# Extract unique country nodesnodes <-unique(c(eurovision_data$`From country`, eurovision_data$`To country`))num_nodes <-length(nodes)print(paste("Number of nodes:", num_nodes))``````{r}# Check tie valuestie_values <- eurovision_data$Pointstie_values# Determine if the ties are weighted or unweightedis_weighted <-!is.null(tie_values)if (is_weighted) {# Range of tie values tie_range <-range(tie_values)print(paste("Tie values are weighted. Range of tie values:", tie_range))} else {print("Tie values are unweighted.")}``````{r}# Distribution of network geodesics geodesics <-distances(graph)print("Distribution of network geodesics:")summary(geodesics)``````{r}# Required packages for network analysis and visualizationlibrary(igraph)library(ggraph)library(ggplot2)# Get unique countriescountries <-unique(c(eurovision_data$`From country`, eurovision_data$`To country`))# Create an empty adjacency matrixadj_matrix <-matrix(0, nrow =length(countries), ncol =length(countries), dimnames =list(countries, countries))# Fill in the adjacency matrix based on the datasetfor (i in1:nrow(eurovision_data)) { from_country <- eurovision_data$`From country`[i] to_country <- eurovision_data$`To country`[i] adj_matrix[from_country, to_country] <-1}# Convert the adjacency matrix to a graphgraph <-graph_from_adjacency_matrix(adj_matrix, mode ="directed")# Subset nodes based on node degreedegree_threshold <-10# Set the degree threshold to select a subset of nodessubset_nodes <-V(graph)[degree(graph) >= degree_threshold]# Create a subgraph with the subset of nodessubgraph <-subgraph(graph, subset_nodes)# Visualize the subgraph using the Fruchterman-Reingold layoutggraph(subgraph, layout ="fr") +geom_edge_link() +geom_node_point() +geom_node_text(aes(label = name), repel =TRUE) +theme_void()``````{r}# Create an igraph object from the datasetgraph <-graph.data.frame(eurovision_data, directed =TRUE, vertices =NULL)# Calculate measures of popularity/statusindegree <-degree(graph, mode ="in") # In-degree centralityoutdegree <-degree(graph, mode ="out") # Out-degree centralityeigenvector_centrality <-eigen_centrality(graph)$vector # Eigenvector centrality# Calculate measures of role/powerbetweenness <-betweenness(graph) # Betweenness centralityconstraint <-constraint(graph) # Constraint measure# Identify nodes with remarkable values# Popularity/Status Measuresprominent_indegree <-V(graph)$name[indegree ==max(indegree)]prominent_outdegree <-V(graph)$name[outdegree ==max(outdegree)]prominent_eigenvector <-V(graph)$name[eigenvector_centrality ==max(eigenvector_centrality)]# Role/Power Measuresprominent_betweenness <-V(graph)$name[betweenness ==max(betweenness)]prominent_constraint <-V(graph)$name[constraint ==max(constraint)]# Interpret the results# Popularity/Status Measurescat("Prominent nodes based on in-degree centrality:\n", prominent_indegree, "\n\n")cat("Prominent nodes based on out-degree centrality:\n", prominent_outdegree, "\n\n")cat("Prominent nodes based on eigenvector centrality:\n", prominent_eigenvector, "\n\n")# Role/Power Measurescat("Prominent nodes based on betweenness centrality:\n", prominent_betweenness, "\n\n")cat("Prominent nodes based on constraint measure:\n", prominent_constraint, "\n\n")``````{r}library(igraph)# Create the graph from the dataframe#graph <- graph.data.frame(df, directed = FALSE)# Set the threshold for tie strengththreshold <-5# Create a subset of the graph based on tie strengthsubset_graph <-delete_edges(graph, E(graph)[E(graph)$Points <= threshold])# Plot the subset graphplot(subset_graph, vertex.label =V(subset_graph)$name)``````{r}# Calculate centrality measuresin_degrees <- igraph::degree(graph, mode ="in")out_degrees <- igraph::degree(graph, mode ="out")eigenvector <-eigen_centrality(graph)$vectorbetweenness <- igraph::betweenness(graph)# Define the measure that we are using and their interpretationsmeasures <-c("In-Degree Centrality", "Out-Degree Centrality", "Eigenvector Centrality", "Betweenness Centrality")interpretations <-c("In-Degree Centrality: The number of incoming ties a node has. A higher in-degree centrality indicates popularity or influence in receiving votes.","Out-Degree Centrality: The number of outgoing ties a node has. A higher out-degree centrality indicates popularity or influence in giving votes.","Eigenvector Centrality: A measure that considers both the number and quality of a node's connections. A higher eigenvector centrality indicates being connected to other high-scoring nodes.","Betweenness Centrality: A measure of how often a node acts as a bridge along the shortest paths between other nodes. A higher betweenness centrality indicates being important for connecting other nodes.")# Print the interpretationsfor (i in1:length(measures)) {cat(paste0(measures[i], ":\n"))cat(paste0(interpretations[i], "\n\n"))}# Print the range of observed values for each measurecat("Range of Observed Values:\n")cat("In-Degree Centrality: ", min(in_degrees), " - ", max(in_degrees), "\n")cat("Out-Degree Centrality: ", min(out_degrees), " - ", max(out_degrees), "\n")cat("Eigenvector Centrality: ", min(eigenvector), " - ", max(eigenvector), "\n")cat("Betweenness Centrality: ", min(betweenness), " - ", max(betweenness), "\n\n")# Identify nodes with remarkable valuesremarkable_nodes <-list("High In-Degree Centrality"=V(graph)[which(in_degrees ==max(in_degrees))],"Low In-Degree Centrality"=V(graph)[which(in_degrees ==min(in_degrees))],"High Out-Degree Centrality"=V(graph)[which(out_degrees ==max(out_degrees))],"Low Out-Degree Centrality"=V(graph)[which(out_degrees ==min(out_degrees))],"High Eigenvector Centrality"=V(graph)[which(eigenvector ==max(eigenvector))],"Low Eigenvector Centrality"=V(graph)[which(eigenvector ==min(eigenvector))],"High Betweenness Centrality"=V(graph)[which(betweenness ==max(betweenness))],"Low Betweenness Centrality"=V(graph)[which(betweenness ==min(betweenness))])# Print the remarkable nodescat("Remarkable Nodes:\n")for (measure innames(remarkable_nodes)) {cat(measure, ":\n")cat(paste0("Node: ", remarkable_nodes[[measure]]$name, "\n"))cat("\n")}```Czech Republic has the highest In-Degree Centrality, which means it has received the most votes.Several countries including Belgium, France, Ireland, etc., have the lowest In-Degree Centrality. This means these countries received the least number of votes.Sweden has the highest Out-Degree Centrality, Eigenvector Centrality, and Betweenness Centrality. This indicates that Sweden has given the most votes (high out-degree), is connected to other high-scoring nodes (high eigenvector), and often acts as a bridge in the shortest path between other nodes (high betweenness).Slovakia has the lowest Out-Degree Centrality, Eigenvector Centrality which suggests that it has given the least votes and is poorly connected to other high-scoring nodes.Yugoslavia, Slovakia, and Australia have the lowest Betweenness Centrality, indicating that they rarely act as a bridge in the shortest path between other nodes.```{r}library(ggraph)library(ggplot2)library(igraph)# Get unique countriescountries <-unique(c(eurovision_data$`From country`, eurovision_data$`To country`))# Create an empty adjacency matrixadj_matrix <-matrix(0, nrow =length(countries), ncol =length(countries), dimnames =list(countries, countries))# Fill in the adjacency matrix based on the datasetfor (i in1:nrow(eurovision_data)) { from_country <- eurovision_data$`From country`[i] to_country <- eurovision_data$`To country`[i] adj_matrix[from_country, to_country] <-1}# Convert the adjacency matrix to a graphgraph <-graph_from_adjacency_matrix(adj_matrix, mode ="directed")# Subset nodes based on node degreedegree_threshold <-10# Set the degree threshold to select a subset of nodes#subset_nodes <- V(graph)[degree(graph) >= degree_threshold]# Create a subgraph with the subset of nodes#subgraph <- subgraph(graph, subset_nodes)# Visualize the subgraphggraph(subgraph, layout ="fr") +geom_edge_link() +geom_node_point() +geom_node_text(aes(label = name), repel =TRUE) +theme_void()``````{r}# Function to detect communities using Louvain methoddetectCommunities <-function(g) {# Convert graph to undirected G_undirected <-as.undirected(g, mode ="collapse")# Apply Louvain method for community detection communities <-cluster_louvain(G_undirected)return(communities)}# Detect communitiescommunities <-detectCommunities(graph)# Print community membership for each nodeprint(membership(communities))```Nodes labeled from "1975" to "2009", "2010", "2012", "2014" to "2016", and "2019" are part of community 1. This might suggest that these years (or whichever attribute these labels represent) share some common characteristics in terms of how they are connected to other nodes in the network.Nodes labeled "2004" to "2007", and "sf" are part of community 2.Nodes labeled "2008", "2011", "2013", "2017", "2018", "sf1", and "sf2" are part of community 3.```{r}library(igraph)library(psych)# Number of communitiesnum_communities <-length(community)# Print the number of communitiescat("Number of Communities:", num_communities, "\n")# Comment on the community structurecat("The Louvain algorithm reveals a community structure in the Eurovision graph.\n")cat("Each community represents a group of countries that have similar voting patterns.\n")# Apply Louvain algorithm for community detectiongraph <-graph.data.frame(df2, directed =FALSE)community <-cluster_louvain(graph)cat("Theoretical/Practical Significance of Community Structure:\n")cat("The community structure is theoretically significant as it provides insights into the social dynamics and regional biases in the Eurovision voting system.\n")cat("It helps us understand whether certain countries tend to form alliances or voting blocs based on cultural, political, or geographical factors.\n")cat("Membership of Prominent Nodes:\n")cat("We can examine the community membership of the prominent nodes identified earlier based on different centrality measures.\n")cat("This will help us determine if leading prominent nodes are associated with specific communities or if they bridge multiple communities.\n")cat("Behavioral Implications:\n")cat("If the prominent nodes are concentrated in the same community ('core'), it suggests a strong influence of that community on the overall voting patterns.\n")cat("On the other hand, if prominent nodes are spread across different communities ('periphery'), it indicates rival factions or conflicting voting interests among different communities.\n")cat("Community Detection Algorithm's Impact:\n")cat("The choice of the Louvain algorithm does not inherently bias towards finding a specific type of community structure.\n")cat("However, the algorithm's effectiveness depends on the connectivity and clustering patterns present in the graph.\n")cat("If the Eurovision graph exhibits distinct communities with well-defined voting patterns, the Louvain algorithm is likely to identify them successfully.\n")cat("If the graph lacks strong community structure or has overlapping voting patterns, the algorithm may produce less clear-cut community assignments.\n")```I chose the Louvain algorithm for community detection in the Eurovision graph because it is a widely used and effective method for detecting communities in large networks. The Louvain algorithm is known for its ability to identify communities based on optimizing the modularity measure, which captures the density of connections within communities compared to random expectations.The Louvain algorithm is particularly suitable for the Eurovision graph because it can uncover communities that exhibit similar voting patterns. In the Eurovision context, countries tend to vote for their neighboring or culturally similar countries, leading to the formation of distinct voting blocs. By applying the Louvain algorithm, we can reveal these underlying communities or blocs and gain insights into the social dynamics of the Eurovision voting system.The algorithm assigns each country to a specific community, grouping together countries that share similar voting patterns. These communities represent clusters of countries that often exchange higher point values among themselves. The community structure identified by the Louvain algorithm helps us understand the regional biases and cultural affinities that influence the voting behavior in the Eurovision Song Contest.Overall, the Louvain algorithm allows us to uncover and analyze the community structure within the Eurovision graph, providing valuable insights into the social and cultural dynamics of the contest.The community structure identified in the Eurovision graph using the Louvain algorithm has both theoretical and practical significance. The membership of prominent nodes within the identified communities provides insights into the voting dynamics and potential rivalries or alliances among countries.In the Eurovision context, the prominent nodes represent countries that have consistently received high point values from other countries within their community. These countries are likely to have strong cultural or regional connections, leading to a higher likelihood of mutual support in the voting process. The membership of prominent nodes within specific communities suggests the existence of cohesive blocs or alliances based on shared cultural or geographical factors.The behavioral implications of the community structure can be significant. If we observe rival factions identified with leading prominent nodes in different communities, it indicates the presence of voting rivalries or political dynamics within the Eurovision Song Contest. Countries within these rival factions may strategically vote against each other or try to form alliances with other communities to gain a competitive advantage.On the other hand, if all the central nodes are in the same "core" community rather than dispersed across different communities, it suggests a strong cohesion and shared interests among the central countries. These central nodes are likely to have a significant influence on the overall voting patterns and outcomes of the contest.Understanding the community structure and the behavior of prominent nodes provides valuable insights for various stakeholders. It helps contestants and organizers gain an understanding of the voting dynamics and potential biases that may affect their chances of success. It also offers researchers and analysts an opportunity to study the social, cultural, and political factors that shape the Eurovision Song Contest and its outcomes.The community detection algorithm used in this case, the Louvain algorithm, is known for its effectiveness in identifying communities in large networks. It is a popular and widely used algorithm that efficiently detects communities based on maximizing modularity.The Louvain algorithm is well-suited for detecting communities in the Eurovision graph because it is specifically designed to handle networks with complex community structures and overlapping communities. It is capable of capturing both strong and weak ties between nodes, which is particularly relevant in the context of Eurovision voting patterns.The algorithm's ability to identify communities is not dependent on any pre-defined assumptions about the structure or number of communities. It dynamically optimizes the modularity metric to uncover the most meaningful and cohesive communities within the network. Therefore, the Louvain algorithm is well-equipped to uncover diverse types of communities, including both rival factions and cohesive core-periphery structures.```{r}library(ergm)library(ergm.count)library(statnet)library(readxl)Eurovision_2019 <-read_excel("_data/got/Eurovision_2019.xlsx")head(Eurovision_2019)dim(Eurovision_2019)# Convert Year and Points variables to characterEurovision_2019$Year <-as.character(Eurovision_2019$Year)Eurovision_2019$Points <-as.character(Eurovision_2019$Points)cug_d_size <-cug.test(Eurovision_2019,FUN = centralization,FUN.arg =list(FUN ="degree", mode ="all"), mode ="digraph", cmode ="size")# cug test - cond on edgescug_b_edges <-cug.test(Eurovision_2019,FUN = centralization,FUN.arg =list(FUN ="betweenness"), mode ="digraph", cmode ="edges")cug_d_sizecug_b_edges# Print the cug test results#trans.cug``````{r}plot(cug_d_size)plot(cug_b_edges)```Conditioning on Size:Observed Value: The observed value of the centralization measure (degree) is 1942.695.Pr(X>=Obs): The probability of observing a value greater than or equal to the observed value is 0, indicating that the observed value is quite extreme.Pr(X<=Obs): The probability of observing a value less than or equal to the observed value is 1, suggesting that the observed value is highly likely.Conditioning on Edges:Observed Value: The observed value of the centralization measure (betweenness) is 0.8360294.Pr(X>=Obs): The probability of observing a value greater than or equal to the observed value is 0, indicating a significant deviation from baseline expectations.Pr(X<=Obs): The probability of observing a value less than or equal to the observed value is 1, suggesting that the observed value is highly likely.These results suggest that the structure of the network in the Eurovision 2019 data, when compared to baseline expectations, shows significant deviations in terms of both degree and betweenness centralization.```{r}library(readxl)library(dplyr)# Read the Eurovision 2019 data#Eurovision_2019 <- read_excel("path/to/your/Eurovision_2019.xlsx")# Calculate node-level measurescountry_appearances <- Eurovision_2019 %>%group_by(From_country) %>%summarise(appearances =n_distinct(Edition))country_wins <- Eurovision_2019 %>%group_by(From_country) %>%summarise(wins =sum(Points ==max(Points)))# Merge node-level measures with the Eurovision 2019 dataEurovision_2019 <- Eurovision_2019 %>%left_join(country_appearances, by ="From_country") %>%left_join(country_wins, by ="From_country")# Perform OLS regressionols_model <-lm(Points ~ appearances + wins, data = Eurovision_2019)```## Challenges1. Data Preprocessing is one of the initial challenges I faced with this dataset , as the Dataset is very huge from the year 1975 to 2019 and consists of around 50k rows.2. Performing cug test - Beacuse of the huge data and less memory optimisation, Unable to perform for the whole dataset. Cug test is performed on the subset of the eurovision data.3. Hypothesis Testing## Conclusion These findings provide insights into the dynamics of the Eurovision network, showcasing countries with high popularity, influence, and role/power. The network analysis allows us to understand the connections and relationships between countries participating in the Eurovision Song Contest.Overall, this project demonstrates the application of EDA and network analysis techniques to gain insights into a complex and interconnected dataset like Eurovision. The findings can be further explored and analyzed to understand the factors influencing voting patterns, cultural dynamics, and the overall dynamics of the Eurovision Song Contest.