Code
import pandas as pd
import re
import numpy as np
import collections
import matplotlib.pyplot as pltimport pandas as pd
import re
import numpy as np
import collections
import matplotlib.pyplot as pltFurther investigation into Zipf’s law and ancient texts
To analyze ancient texts in relation to the Zipf law and the general complexity compared to modern-day language A large source of documents needed to be gathered. For this, I used a collection created by the Department of History, School of History, Religions & Philosophies of SOAS University of London. This collection’s purpose was to hear how the ancient language of Akkadian sounded like and have recordings of each text as well as a phonetic spelling of each word. Each text is separate line by line with its direct translation of the line rather than a reworded contextual translation. The collection of these texts was made more difficult since the website I found currently is being reorganized and I needed to use the WayBackMAchine archived webpages which does not include the sound recording but all of the texts were saved
def cleaner(the_input):
the_input = re.sub("\(\(.*\)\)",'', the_input)
the_input=the_input.lower()
the_input = the_input.replace('(ii',"").replace("iii.","").replace("ii.","").replace("i ii ","").replace("i i ","").replace("i iii ","")
the_input = the_input.replace('#',"").replace('˺',"").replace('˹',"").replace(':',"").replace('<',"").replace('>',"").replace('*',"").replace('\xa0',"").replace('|',"").replace('/',"").replace('–',"").replace('“',"").replace('”',"").replace("[","").replace("]","").replace("(","").replace(")","").replace("’","").replace(".","").replace("…","").replace(":","").replace("!","").replace("?","")
the_input = the_input.replace(" "," ").replace(" "," ").replace(",","").replace(";","").replace('"',"")
return the_input
def grab_html2(url,text_output):
df = pd.read_html(url)
df=df[1]
for x in range(0,len(df)):
akk=df.iloc[x][0]
akk = re.sub(r'[0-9]+', '', akk)
akk = cleaner(akk)
akk = akk.replace('- '," ")
akk = akk.replace(' -'," ")
eng=df.iloc[x][1]
eng = re.sub(r'[0-9]+', '', eng)
eng = cleaner(eng)
eng = eng.replace('- '," ")
eng = eng.replace(' -'," ")
akk=akk[1:] if akk.startswith(" ") else akk
eng=eng[1:] if eng.startswith(" ") else eng
if akk=='' or "lines" in akk and "lost" in akk or "fragmentary" in akk:
continue
else:
text_output.append([akk,eng])
return text_output
def grab_html(url,text_output):
error_flag=0
df = pd.read_html(url)
df=df[1]
temp_text = []
for x in range(0,len(df)):
tester=df.iloc[x][0]
tester = cleaner(tester)
if "lines" in tester and "lost" in tester or "fragmentary" in tester:
tester=""
akk = re.split('([0123456789]+)', tester)
index=-1
while '' in akk:
akk.remove('')
while '-' in akk:
index = akk.index('-')
del akk[index]
del akk[index]
tester=df.iloc[x][1]
tester = cleaner(tester)
if "lines" in tester and "lost" in tester or "fragmentary" in tester:
tester=""
eng = re.split('([0123456789]+)', tester)
index=-1
while '' in eng:
eng.remove('')
while '-' in eng:
index = eng.index('-')
del eng[index]
del eng[index]
if len(akk)!=len(eng):
error_flag=1
break
for y in range(0,len(akk)):
if akk[y].isnumeric() or akk[y]=='':
continue
else:
akk[y]=akk[y][1:] if akk[y].startswith(" ") else akk[y]
eng[y]=eng[y][1:] if eng[y].startswith(" ") else eng[y]
akk[y]=akk[y][2:] if akk[y].startswith("’ ") else akk[y]
eng[y]=eng[y][2:] if eng[y].startswith("’ ") else eng[y]
temp_text.append([akk[y],eng[y]])
if error_flag==1:
return grab_html2(url,text_output)
else:
text_output.extend(temp_text)
return text_outputBelow is a loop scraping and collecting all the data from a list of URLs, originally the function would be able to grab each element from the home webpage but being archived by the way back machine each URL for a text needs to be specified.
text = []
urls=["https://web.archive.org/web/20220920202225/https://www.soas.ac.uk/baplar/recordings/ammi-ditnas-hymn-to-itar-read-by-k-hecker.html","https://web.archive.org/web/20220920202226/https://www.soas.ac.uk/baplar/recordings/the-codex-hammurabi-prologue-i1-49-read-by-albert-naccache.html","https://web.archive.org/web/20220920202223/https://www.soas.ac.uk/baplar/recordings/the-codex-hammurapi-epilogue-xlix-18-28-and-53-80-read-by-aage-westenholz.html","https://web.archive.org/web/20220920202227/https://www.soas.ac.uk/baplar/recordings/the-epic-of-gilgame-old-babylonian-version-tablet-ii-lines-85-111-read-by-michael-streck.html","https://web.archive.org/web/20220920202232/https://www.soas.ac.uk/baplar/recordings/the-epic-of-gilgame-old-babylonian-version-tablet-ii-lines-1-61-read-by-jacob-klein.html","https://web.archive.org/web/20220920202229/https://www.soas.ac.uk/baplar/recordings/gilgamesh-x-huehnergard.html","https://web.archive.org/web/20220920202226/https://www.soas.ac.uk/baplar/recordings/the-epic-of-gilgamesh-old-babylonian-version-bmvat-lines-ii0-iii14-read-by-martin-west.html","https://web.archive.org/web/20220920202232/https://www.soas.ac.uk/baplar/recordings/the-epic-of-anz-old-babylonian-version-from-susa-tablet-ii-lines-1-83-read-by-claus-wilcke.html","https://web.archive.org/web/20220920202229/https://www.soas.ac.uk/baplar/recordings/atramass-ob-version-from-sippir-tablet-i-lines-i1-iii16-read-by-claus-wilcke.html","https://web.archive.org/web/20220920202231/https://www.soas.ac.uk/baplar/recordings/diviners-prayer-to-the-gods-of-the-night-read-by-michael-streck.html","https://web.archive.org/web/20220920202228/https://www.soas.ac.uk/baplar/recordings/incantation-for-dog-bite-read-by-michael-streck.html","https://web.archive.org/web/20220920202223/https://www.soas.ac.uk/baplar/recordings/letter-of-marduk-nir-to-ruttum-abb-iii-15-read-by-wilfred-van-soldt.html","https://web.archive.org/web/20220920202225/https://www.soas.ac.uk/baplar/recordings/letter-of-kurkurtum-to-erb-sn-abb-xii-89-read-by-wilfred-van-soldt.html","https://web.archive.org/web/20220920202230/https://www.soas.ac.uk/baplar/recordings/ob-letter-iddin-sin.html","https://web.archive.org/web/20220920202225/https://www.soas.ac.uk/baplar/recordings/the-epic-of-gilgame-standard-version-tablet-xi-lines-1-163-read-by-karl-hecker.html","https://web.archive.org/web/20220920202224/https://www.soas.ac.uk/baplar/recordings/the-poem-of-the-righteous-sufferer-ludlul-bl-nmeqi-tablet-ii-lines-1-26-and-56-82-read-by-brigitte-groneberg.html","https://web.archive.org/web/20220920202229/https://www.soas.ac.uk/baplar/recordings/the-poem-of-the-righteous-sufferer-ludlul-bl-nmeqi-tablet-ii-lines-1-55-read-by-margaret-jaques-cavigneaux.html","https://web.archive.org/web/20220920202231/https://www.soas.ac.uk/baplar/recordings/itars-descent-to-the-netherworld-lines-1-125-read-by-martin-west.html","https://web.archive.org/web/20220920202231/https://www.soas.ac.uk/baplar/recordings/the-ama-hymn-lines-15-52-read-by-martin-west.html"]
for source in urls:
text = grab_html(source,text)
for x in range(0,10) : print(text[x])['iltam zumrā rašubti ilātim', 'sing ye of the goddess the most fearsome of the gods']
["litta''id bēlet iššī rabīt igigī", 'praise be upon the lady ruler of men the greatest of the igigi']
['ištar zumrā rašubti ilātim', 'sing ye of ishtar the most fearsome of the gods']
["litta''id bēlet ilī nišī rabīt igigī", 'praise be upon the lady ruler of the people the greatest of the igigi']
['šāt mēleṣim ruāmam labšat', 'she who gets excited clothed in sex appeal']
["za'nat inbī mīkiam u kuzbam", 'adorned with fruits charm and allure']
['šāt mēleṣim ruāmam labšat', 'she who gets excited clothed in sex appeal']
["za'nat inbī mīkiam u kuzbam", 'adorned with fruits charm and allure']
['šaptīn duššupat balāṭum pīša', 'she is sweet at the lips her mouth is life']
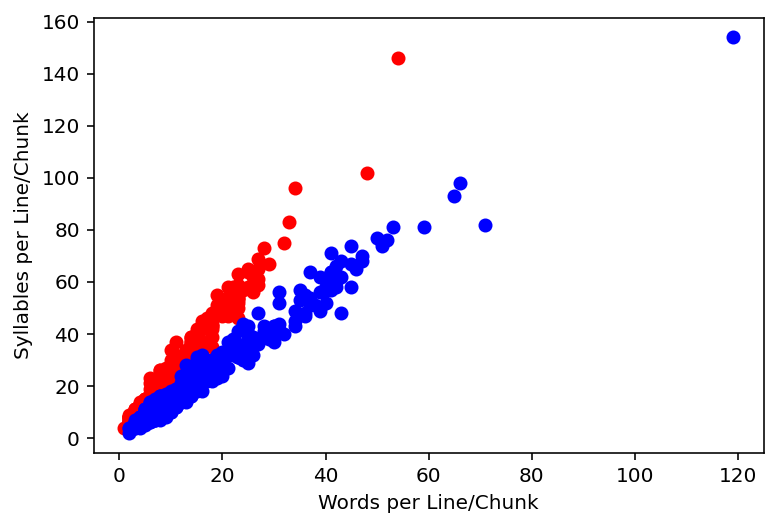
['simtišša ihannīma ṣīhātum', 'delights are lush on her cheeks']Here each is separating the Akkadian only text from the array. Each line or chunk is broken down into an array of words and then appended to a list of all the Akkadian words. Using the counter class it fills a dictionary with each word being a key and the value is that word’s frequency. The graph displays on the x axis in order of theier frequency of usage of the first 12 words and the y-axis is how many times that word was used.
all_words = []
akkadian=[i[0] for i in text]
for z in range(0,len(akkadian)):
stuff = re.split(' ', akkadian[z])
all_words = all_words + stuff
all_words=np.sort(all_words)
all_words=all_words[all_words!='']
elements_count = collections.Counter(all_words)
print("In Akkadian there are ",len(all_words)," and",len(elements_count),"of which are unique")
elements = sorted(elements_count.items(), key=lambda item: (-item[1], item[0]))
elements_count=collections.OrderedDict(elements)
index=0
for key, value in elements_count.items():
index+=1
print(f"{key}: {value}")
if index > 11: break
specific_word = list(elements_count.keys())
word_freq = list(elements_count.values())
plt.bar(specific_word[:12], word_freq[:12])
plt.show()In Akkadian there are 4160 and 2253 of which are unique
ana: 158
ina: 119
ša: 93
u: 77
ul: 57
lā: 47
kīma: 30
ilī: 27
ištar: 23
enlil: 21
ilū: 18
lū: 18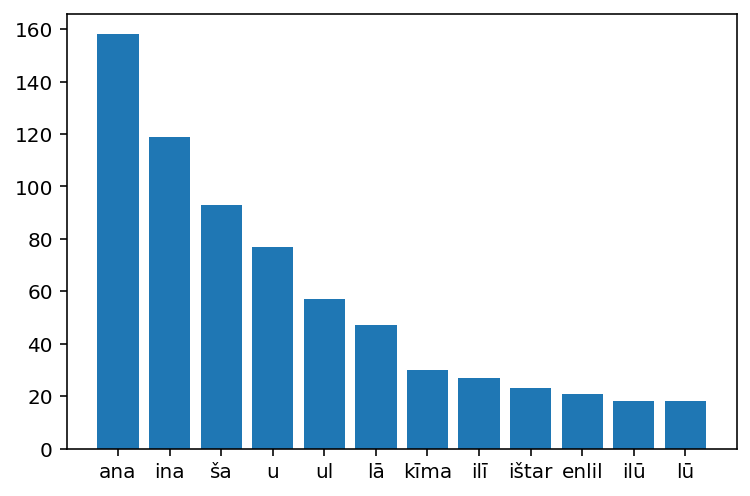
Below the same process was repeated for all of the English translations of the same lines. This is done as a control since the content should be nearly the same the word distribution should be similar if it follows Zipf law the same way English does.
all_words = []
english=[i[1] for i in text]
for z in range(0,len(english)):
stuff = re.split(' ', english[z])
all_words = all_words + stuff
all_words=np.sort(all_words)
all_words=all_words[all_words!='']
elements_count = collections.Counter(all_words)
print("In English there are ",len(all_words)," and",len(elements_count),"of which are unique")
elements = sorted(elements_count.items(), key=lambda item: (-item[1], item[0]))
elements_count=collections.OrderedDict(elements)
index=0
for key, value in elements_count.items():
index+=1
print(f"{key}: {value}")
if index > 11: break
specific_word = list(elements_count.keys())
word_freq = list(elements_count.values())
plt.bar(specific_word[:12], word_freq[:12])
plt.show()In English there are 7706 and 1709 of which are unique
the: 660
of: 239
and: 195
to: 175
i: 148
my: 136
her: 123
his: 109
a: 108
in: 104
you: 94
he: 86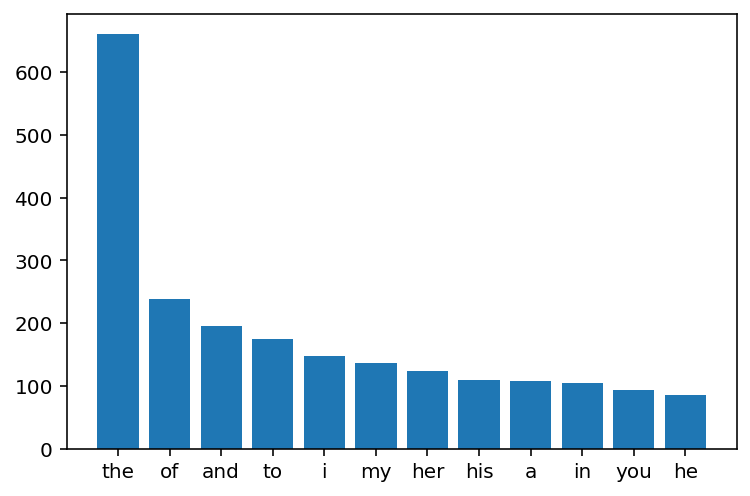
The next area of calculation is finding the syllable count for the words and there will need to be separate functions for each language. Normally this would be very difficult if had the raw cuniform of Akkadian but since it is phonetic spelling there are no silent letters or special rules unique to that language
def syllable_eng(word):
word = word.lower()
count = 0
vowels = "aeiouy"
if word[0] in vowels:
count += 1
for index in range(1, len(word)):
if word[index] in vowels and word[index - 1] not in vowels:
count += 1
if word.endswith("e"):
count -= 1
if count == 0:
count += 1
return count
def syllable_akk(word):
word = word.lower()
count = 0
vowels = "īāîáâêeēíûaoūui"
if word[0] in vowels:
count += 1
for index in range(1, len(word)):
if word[index] in vowels and word[index - 1] not in vowels:
count += 1
if count == 0:
count += 1
return countHere the average number of syllabls per word is calulated over all for each language showing that akkadian despite having many fewer words to describe the same concept they are longer and have more syllabuls. In the graph each dot represents a line or chunk of text the red in Akkadian and the blue in English
akkadian=[i[0] for i in text]
english=[i[1] for i in text]
words_akk,syl_akk,words_eng,syl_eng=[],[],[],[]
for line in range(0,len(akkadian)):
words_akk.append(len(akkadian[line].split()))
syl_akk.append(syllable_akk(akkadian[line]))
words_eng.append(len(english[line].split()))
syl_eng.append(syllable_eng(english[line]))
print("Average number of syllables per word Akkadian: ",(sum(syl_akk)/sum(words_akk)))
print("Average number of syllables per word English: ", (sum(syl_eng)/sum(words_eng)))
plt.plot(words_akk,syl_akk, 'o', color='red');
plt.plot(words_eng,syl_eng, 'o', color='blue');
plt.xlabel('Words per Line/Chunk')
plt.ylabel('Syllables per Line/Chunk')
plt.show()Average number of syllables per word Akkadian: 2.4793269230769233
Average number of syllables per word English: 1.4600311445626784