Code
#load this here so I don't have to rerun everything
# dat <- readr::read_csv("_data/out.csv")
# load("dat9.RData")#load this here so I don't have to rerun everything
# dat <- readr::read_csv("_data/out.csv")
# load("dat9.RData")Questions:
How: Compare language use in anatomy textbooks
Acquiring textbooks from the Internet Archive (IA) took me multiple steps. On the IA website, there is an option to search through the text portion of a book. On the IA API, however, I couldn’t find this option. The best I could find was looking through a book’s metadata, which wasn’t the same. When I looked for the word “vagina”, this returned gynecology books and almost no anatomy books, compared to when I searched in the text. I decided to search “vagina” instead of “genital” because some anatomy books historically haven’t reviewed the vagina/vulva. Because of this I performed the data review in multiple steps:
I found that most of the texts I could download were from pre-1970. I requested titles retrieved from my IA search through the UMass library or through an inter-library loan, which were primarily PDFs like the IA data. I then processed both datasets:
I performed the search explained in step 1 above. As a note, when I tried to use “AND” to include both “penis” and “vagina”, but when I flipped the order, a different number of results appeared. I confirmed with the IA API search manual I used the correct syntax. Because of this, I left the search-word at “vagina” since many texts historically don’t include vaginal anatomy but will include penis’.
In order to confirm that I can webscrape, I use the package “bow” to check the website url. It says that I need a 5 minute delay.
bow("https://archive.org/details/texts?query=vagina")<polite session> https://archive.org/details/texts?query=vagina
User-agent: polite R package
robots.txt: 2 rules are defined for 1 bots
Crawl delay: 5 sec
The path is scrapable for this user-agentThe webpage has 2 options. There is infinite scrolling, but there is also a webscraping-friendly option which is with pages. I checked that the last page number is 133, so I make a set of urls to webscrape with through all these pages.
#i found out that the max page number is 133, and starts at page 0
urls<- paste0("https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=",
0:133)
urls %>% head[1] "https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=0"
[2] "https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=1"
[3] "https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=2"
[4] "https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=3"
[5] "https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=4"
[6] "https://archive.org/details/texts?query=vagina&sin=TXT&and[]=languageSorter%3A%22English%22&page=5"I want to retrieve the title of each result as well as the hyperlink to its page. I next practiced scraping from one webpage. Once I confirmed that the code worked, I put it into a function. This allows me to iteratively scrape pages using map_dfr(). I make sure to include a 5 second wait period after each page is webscraped. After map scrapes all the pages, the function outputs all the results into a dataframe (which is the dfr option) so I can begin manipulating them without much more pre-processing.
#make a function that does all the work for me
get_titles_dates<-function(aurl){
page<- read_html(aurl)
#scrape titles
titles<- page %>%
html_elements(., xpath="//div[contains(concat(' ',normalize-space(@class),' '),' item-ttl C C2 ')]/a") %>%
html_attr("title")
hrefs<- page %>%
html_elements(., xpath="//div[contains(concat(' ',normalize-space(@class),' '),' item-ttl C C2 ')]/a") %>%
html_attr("href")
#combine
tempdat<- bind_cols(titles = titles,
hrefs = hrefs)
return(tempdat)
}
# iteratively scrape urls and return as a dataframe
dat<-map_dfr(urls, ~{
Sys.sleep(5)
tryCatch({get_titles_dates(.x)},
error = function(e){
cat("\n\n", .x, "\n\n") #report bad urls -- used for testing
})
})
##save data in case it crashes
# save(dat, file = "/Users/emmanuelmiller/Desktop/dacss697d/forblog/Text_as_Data_Fall_2022/posts/_data/hrefs.RData")dat %>% head# A tibble: 6 × 2
titles hrefs
<chr> <chr>
1 A NEW HYGROMIIDAE FROM THE ITALIAN APENNINES AND NOTES ON THE GENUS CER… /det…
2 Operative gynecology /det…
3 Pathology of the uterine cervix, vagina, and vulva /det…
4 Diseases of women: a manual of gynecology designed especially for the u… /det…
5 A treatise on gynaecology, clinical and operative /det…
6 The Principles and practice of gynecology : for students and practition… /det…I first need to clean the webscraped titles so I can identify duplicate uploads. This is because multiple users can upload the same book and all results are included in my search. I’ll remove duplicates a bit further down.
#clean titles
dat2<- dat %>%
mutate(original_titles = titles,
titles = trimws(titles, which = "both"),
titles = tolower(titles),
titles = str_replace_all(titles, c("[[:punct:]]|electronic resource" = " ",
"æ" = "ae",
"\\bvol\\w*" = "",
"microform" = "",
"\\s+" = " ")), #theres extra punct at ends
titles = trimws(titles, which = "both")
) %>%
select(-matches("\\.")) %>% #get rid of the extra row that map gives us
unique
dat2 %>% head# A tibble: 6 × 3
titles hrefs origi…¹
<chr> <chr> <chr>
1 a new hygromiidae from the italian apennines and notes on the g… /det… A NEW …
2 operative gynecology /det… Operat…
3 pathology of the uterine cervix vagina and vulva /det… Pathol…
4 diseases of women a manual of gynecology designed especially fo… /det… Diseas…
5 a treatise on gynaecology clinical and operative /det… A trea…
6 the principles and practice of gynecology for students and prac… /det… The Pr…
# … with abbreviated variable name ¹original_titlesI remove titles, following what I have described primarily in blog post 1 about my text selection criteria. Here I will go into further detail:
dat3<- dat2 %>%
filter(!str_detect(titles, "essay|journ|memoi|ency|icd|cata|studies|experim")) %>%
filter(!str_detect(titles, "trans|doctrin|repor|iss|malign|notes|review")) %>%
filter(!str_detect(titles, "current operative urology|papers|double uterus|dysfunction")) %>%
filter(!str_detect(titles, "key|idiot|illustrated anatomy|colou*r|crash|treatis|cookbook")) %>%
filter(str_detect(titles, "anatomy|anatomical|urolog|clinic|surgical clinics of north america")) %>%
filter(!str_detect(titles, "patho|disea|morbid|canc|treatm|gravid|midwif")) %>%
filter(!str_detect(titles, "restora|pedia|adolescen|private parts")) %>%
filter(!str_detect(titles, "marr|achatinidae|cleistogamia|elephant|cow|cestoidea")) %>%
filter(!str_detect(titles, "myrmecophaga|snail|equine|omphalina|neniinae|philosoph")) %>%
filter(!str_detect(titles, "ariolimax|gaseopoa|horse|sociology|psycho|ants")) %>%
filter(!str_detect(titles, "sex|dog|anatomie des menschen|albolabris|disor"))In order to retrieve information on the publication date of each title, I use the internetarchive package. The hyperlink extracted earlier has the identifier that I can use to retrieve information. I found that the internetarchive ‘ia_search()’ function doesn’t return as accurate information just looking up the name of the book. Searching using the identifier of the book only didn’t work for one book. I looked it up on the website and I couldn’t download the book anyway because of the copyright.
dat4<- dat3 %>%
mutate(hrefs = str_extract(hrefs, "(?<=details/).*(?=\\?q=vagina)"),
hrefs = str_replace_all(hrefs, c("/.*" = ""))) %>%
mutate(dates = map(hrefs, ~ia_search(c("identifier" = .)) %>%
ia_get_items %>%
ia_metadata))
dat5<- dat4 %>%
mutate(hmm = map(dates, ~nrow(.))) %>%
unnest(hmm) %>%
filter(hmm!=0)I also retrieved information as to the confidence level of the OCR. If there is a confidence level reported, I select a cutoff of >85%. I also select books with a date reported which is greater than 1875.
#reshape data
dat5<- dat5 %>%
mutate(dates = map(dates, . %>%
filter(field %in% c("date", "ocr_detected_script_conf")))) %>%
unnest(dates) %>%
pivot_wider(names_from = field, values_from = value )
#clean dates
dat6<- dat5 %>%
rename(dates = date) %>%
mutate(dates = case_when(
dates == "[n.d.]" ~ NA_character_,
!is.na(dates)~ str_extract(dates, "\\d{4}"),
T~ NA_character_
)) %>%
mutate(dates = as.numeric(dates))
#filter
dat6<- dat6 %>%
filter(ocr_detected_script_conf > 0.85 | is.na(ocr_detected_script_conf)) %>%
select(-ocr_detected_script_conf) %>%
filter(dates > 1875) %>%
filter(!is.na(dates))dat7 %>% select(titles, dates, hrefs) %>% head()# A tibble: 6 × 3
titles dates hrefs
<chr> <dbl> <chr>
1 researches in female pelvic anatomy 1892 rese…
2 atlas of pelvic anatomy and gynecologic surgery 2001 atla…
3 clinical gynaecology medical and surgical 1895 clin…
4 contraception healthy choices a contraceptive clinic in a book 2009 cont…
5 textbook of female urology and urogynaecology 2001 text…
6 the anatomy and physiology of obstetrics a short textbook for stu… 1969 anat…I was originally going to use the internetarchive package to download the text versions of these books. I found that in some cases, I was not able to download some of the books because they contained “due to issues with the item’s content” (according to the file that I did receive). When I looked the book up on the IA website, I could access a text version of the book. I webscraped versions of these books but they didn’t have delimiters between different pages, which meant that I couldn’t reasonably remove headers and footers like the PDF files that I retrieved from the library. I was concerned about the quality of the data for this reason. After review of the IA website, I found out that I could download PDF versions of many of these books. I also found out that the UMass Library had Adobe Acrobat editor. I decided that because this dataset is relatively small I would spend an afternoon editing these PDFs to have better data.
I examined the url structure on the IA website for downloading PDFs. I used the previously-webscraped hyperlink to construct the url I would download PDFs from.
dat7<- dat6 %>%
select(titles, dates, hrefs) %>%
mutate(url = paste0("https://archive.org/download/",
hrefs, "/", hrefs, ".pdf"))I then used download.file() to download iteratively the urls I constructed. This returned for me 68 PDFs. This is approximately the same number of results as webscraping.
setwd("/Users/emmanuelmiller/Desktop/dacss697d/forblog/Text_as_Data_Fall_2022/posts/download_pdfs")
temp<- dat7$url
for (url in temp){
tryCatch({
download.file(url, destfile = basename(url), mode = "wb")
Sys.sleep(5)
}, error = function(e){
cat("\n\n", url, "\n\n")
})
}I reviewed these PDFs to confirm that there were no duplicates and all files could be downloaded. I found that a number were in fact duplicates or did not fit the inclusion criteria (such as being journal articles). There were a total of 44 documents remaining.
Joining, by = "files"Below is the distribution of dates of the IA texts. The majority of the books in the dataset are before the 1930s, which makes sense because copyrights expire within this time frame. The lack of titles in 2000s could greatly skew the sample for downstream analysis. I continue with data retrieval from the books I requested through inter-library loan in the same way I do for that of the IA texts in the next sections.
temp<- dat8 %>%
select(files, dates) %>%
unique %>%
mutate(after1970 = ifelse(dates > 1970, "after", "before"))
ia_hist<-ggplot(temp, aes(x = dates, fill = after1970))+
geom_histogram()
# save(ia_hist, file = "/Users/emmanuelmiller/Desktop/dacss697d/Text_as_Data_Fall_2022/posts/_data/ia_hist.RData")ia_hist`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.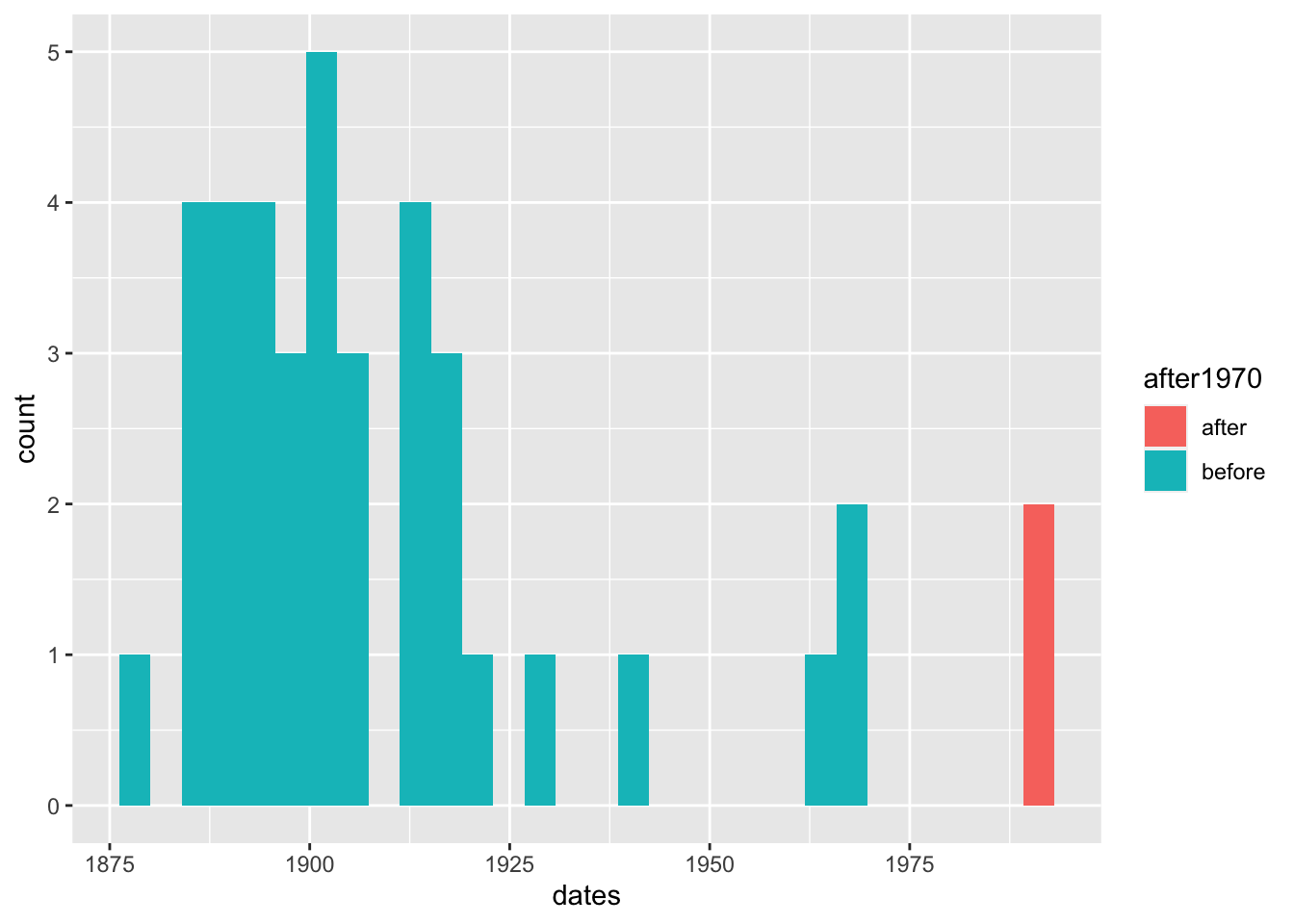
To OCR, I considered two programs. I considered using Adobe Acrobat’s built-in OCR functionality which has been used in the literature (related to medical records: Hsu et al., 2022; Nguyen et al., 2020, etc). I also considered the ocr() function from the Tesseract package, a widely used (specific to medical text OCR: Goodrum et al., 2020; Hsu et al., 2022; Liu et al., 2020; Rasmussen et al., 2011; and many more), free, OCR program. Both are used in the literature, but I was more partial to Tesseract because it is more frequently used in the extraction of medical text data. In a larger study, it would be interesting to compare the quality of the OCR of both softwares. I also liked that the Tesseract command-line software would allow me to play with OCR parameters manually unlike Adobe. I decided on use of the Tesseract package as I wanted more control over the OCR conditions and its frequent use in the literature.
The Tesseract vignette recommends a number of procedures for altering images that increase the quality of the OCR. This includes deskewing text, trimming whitespace, removing noise and artifacts, converting images to black and white (binarization), and changing the thickness of the characters (dilation/erosion). All my images were above 10px so I didn’t have to resize them. Historical data is notoriously difficult to OCR. Many of my documents are in a serif font, which is problematic because the middle of letters is typically much thinner.
I tried using 2 different programs, Magick and ImageJ2. I didn’t use Magick (which is in R) because the software wasn’t effective at removing background effects. Using ImageJ2 (v 2.9.0) I did the above preprocessing. To deskew, I used the following code and saved it in plugins/Analyze folder. I took the code from this user.
#@ ImagePlus imp
#@ ResultsTable rt
import fiji.analyze.directionality.Directionality_
d = new Directionality_()
d.setImagePlus(imp)
d.setMethod(Directionality_.AnalysisMethod.LOCAL_GRADIENT_ORIENTATION)
d.computeHistograms()
d.fitHistograms()
result = d.getFitAnalysis()
mainDirection = Math.toDegrees(result[0][0])
rt.incrementCounter()
rt.addValue("Main Direction", mainDirection)
rt.show("Results")I ran the following ImageJ2 macro on my dataset. This script took several hours to run because image processing is a computationally heavy task. In addition to this, I selected time images and used the “erode” feature.
input = "/Volumes/em_2022/good_pngs/";
output = "/Volumes/em_2022/good_tiffs/";
fileList = getFileList(input);
function action(input, output, filename) {
open(input + filename);
//clean up
run("Sharpen");
run("Despeckle");
run("Gaussian Blur...", "sigma=1");
//make binary
run("Sharpen");
run("Find Maxima...", "prominence=10 exclude light output=Count");
x = getResult("Count", 0);
if (x > 50){
//for the black and white images that have the black box
if (bitDepth!=24) {
run("Find Maxima...", "prominence=10 exclude light output=[Point Selection]");
run("Fit Rectangle");
run("Enlarge...", "enlarge=60");
run("Crop");
}
run("Subtract Background...", "rolling=100 light");
run("Sharpen");
run("Smooth");
run("Convert to Mask");
}
//crop
run("Select Bounding Box");
run("Enlarge...", "enlarge=50");
run("Crop");
//transform
if (x > 50){
selectWindow(filename);
run("Select Bounding Box");
run("Copy");
run("Create Mask");
title_mask = getTitle();
selectWindow(title_mask);
run("Paste");
run("Gaussian Blur...", "sigma=30");
run("Enhance Contrast...", "saturated=0.1");
run("Clear Results");
run("Get Main Direction", "rt=[title=Results, size=1, hdr= \tMain Direction]");
angle = getResult("Main Direction", 0);
angle = angle * -1.0;
if (abs(angle) < 30){
selectWindow(filename);
run("Rotate... ", "angle="+ angle+ " grid=1 interpolation=Bilinear fill");
}
selectWindow(title_mask);
close();
}
//remove results window
selectWindow("Results");
run("Clear Results");
run("Close");
saveAs("Tiff", output + filename);
close();
}
for (i = 0; i < fileList.length; i++){
action(input, output, fileList[i]);
}Below is an example of the clean image.
magick::image_read("posts/_data/edited_b2041349x_001_Page_047.png") %>%
printError in magick_image_readpath(path, density, depth, strip, defines): R: UnableToOpenBlob `posts/_data/edited_b2041349x_001_Page_047.png': No such file or directory @ error/blob.c/OpenBlob/2924magick::image_read("posts/_data/1edited_b2041349x_001_Page_047.tif") %>%
magick::image_background(color = "black") %>%
printError in magick_image_readpath(path, density, depth, strip, defines): R: UnableToOpenBlob `posts/_data/1edited_b2041349x_001_Page_047.tif': No such file or directory @ error/blob.c/OpenBlob/2924It is possible to provide Tesseract with an updated dictionary as well as pages to OCR in its database. Users have to re-render the model after doing this. I tried to add just to the dictionary (using vocabulary I made which I will describe in my next blog post). Unfortunately, my computer crashed. Given greater computational resources, this would be an avenue to follow to improve the accuracy of the OCR. For the purposes of this pilot study, I instead used the following loop to save text to a separate file.
setwd("/Users/emmanuelmiller/Desktop/text_ia")
temp<- tibble(files = list.files())
#ocr and save to files
for(i in 1:nrow(temp)){
filename <- temp$files[i]
dat <- tesseract::ocr(filename)
cat(dat, file = file(paste0(basename(filename), ".txt")), sep = "\n")
}Below is an example of some of the raw OCR data. I will demonstrate how I clean it in the next blog post.
book_peek<- tibble(files = list.files("/Users/emmanuelmiller/Desktop/text_ia/",
full.names = T)) %>%
slice(40:50) %>%
mutate(dat = map(files, ~str_c(read_lines(.), collapse = "\n")),
dat = str_sub(dat, 0, 250),
url = str_extract(files, "(?<=edit\\w{0,3}_).*(?=_Page)"),
page = str_extract(files, "(?<=Page_)\\d+")) %>%
select(url, page, dat) %>%
kable %>%
kable_styling()
# save(book_peek, file = "/Users/emmanuelmiller/Desktop/dacss697d/Text_as_Data_Fall_2022/posts/_data/book_peek.RData")book_peek| url | page | dat |
|---|---|---|
| atextbookoperat00huetgoog | 040 | A’. The peroneal artery, a branch of the posterior tibial, descends vertically along the posterior aspect of the fibula as far as the lower tibio-fibular articulation, being covered above by the soleus, then lying between the flexor longus pollicis a |
| atextbookoperat00huetgoog | 041 | If. LicaTtuRE oF THE UpreR Part or THE ANTERIOR TIBIAL ARTERY. (1). At rather more than an inch external to the crest of the tibia, and in the course of a line which would extend from the head of the fibula to the'centre of the) ankle joint make an |
| atextbookoperat00huetgoog | 042 | PLATE XIV. LIGATURE OF THE POSTERIOR TIBIAL ARTERY. Fig. 1.—ANaTomy. 1. The patella. 2. Internal malleolus. 3. Internal surface of the tibia. 4. Internal aponeurosis. 5. Soleus muscle drawn backwards. A. The posterior tibial artery commencing at th |
| atextbookoperat00huetgoog | 043 | @ d, the common flexor ; ¢, the posterior tibial nerve; A, the artery. Incision No. 3.—Ligature of the upper third of the posterior tibial artery. a, The skin ; 6, the aponeurosis ; c, the gastrocnemius drawn back by a retractor; d, an incision made |
| atextbookoperat00huetgoog | 044 | (4). Whilst these muscles are held backwards and outwards . by a retractor, divide upon a director the deep aponeurotic fascia, beneath which can be seen the vessels. ( (5). Isolate the artery, and pass the ligature with either a Cooper’s or a Desch |
| atextbookoperat00huetgoog | 045 | PLATE XV. LIGATURE OF THE POPLITEAL ARTERY. Figs. 1, 2, and 3.—ANaToMY. Fig. 1.—Aponeurotic layer, superficial cessels and nerves. . 1—1. Popliteal aponeurosis in part removed. 2. Semi- membranosus. 3. Biceps. 4. Cutaneous vessels and nerves. 5. In |
| atextbookoperat00huetgoog | 046 | lower part of the artery is somewhat internal and at the upper part external to the artery. These two vessels are covered superiorly by the belly of the semi-membranosus (1), and at the lower part by the two bellies of the gastrocnemius (2 and 3). Th |
| atextbookoperat00huetgoog | 047 | (4). Recognize the outer border of the semimembranosus muscle, and the popliteal nerve will be now seen coming from beneath it. (5). Push the nerve inwards, and beneath and a little internal to it will be found the popliteal vein. (6). Isolate the |
| atextbookoperat00huetgoog | 048 | PLATE XVI. LIGATURE OF THE FEMORAL ARTERY. Fig. 1.—ANaTOMY. A. The femoral artery, a continuation of the external iliac, extends from the middle of the crural arch (1) to the end of Hunter's canal, where it becomes the popliteal. The vessel is in fr |
| atextbookoperat00huetgoog | 049 | d, internal saphenous nerve ; ¢, tendinous sheath of the femoral veasels at Hunter's canal ; A, the artery. Incision No. 2.—Ligature of , the femoral artery im its upper ird, @, the skin and cellular tissue; 6, aponeurosis; c, sheath of the femora |
| atextbookoperat00huetgoog | 050 | which unites the vessels together, and pass the ligature from bebind forwards. Ligature of the femoral artery in the middle of the thigh. HUNTER’S OPERATION. Fig. 2, Incision 2. The limb being placed as in the preceding operation— (1). Make an in |
Goodrum H, Roberts K, Bernstam EV. Automatic classification of scanned electronic health record documents. Int J Med Inform. 2020 Dec;144:104302. doi: 10.1016/j.ijmedinf.2020.104302. Epub 2020 Oct 17. PMID: 33091829; PMCID: PMC7731898. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7731898/
Hsu E, Malagaris I, Kuo YF, Sultana R, Roberts K. Deep learning-based NLP data pipeline for EHR-scanned document information extraction. JAMIA Open. 2022 Jun 11;5(2):ooac045. doi: 10.1093/jamiaopen/ooac045. PMID: 35702624; PMCID: PMC9188320. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9188320/
Liu X, Meehan J, Tong W, Wu L, Xu X, Xu J. DLI-IT: a deep learning approach to drug label identification through image and text embedding. BMC Med Inform Decis Mak. 2020 Apr 15;20(1):68. doi: 10.1186/s12911-020-1078-3. PMID: 32293428; PMCID: PMC7158001. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7158001/
Nguyen, A., O’Dwyer, J., Vu, T., Webb, P. M., Johnatty, S. E., & Spurdle, A. B. (2020). Generating high-quality data abstractions from scanned clinical records: text-mining-assisted extraction of endometrial carcinoma pathology features as proof of principle. BMJ open, 10(6), e037740. https://doi.org/10.1136/bmjopen-2020-037740 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7295399/
Rasmussen LV, Peissig PL, McCarty CA, Starren J. Development of an optical character recognition pipeline for handwritten form fields from an electronic health record. J Am Med Inform Assoc. 2012 Jun;19(e1):e90-5. doi: 10.1136/amiajnl-2011-000182. Epub 2011 Sep 2. PMID: 21890871; PMCID: PMC3392858.https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3392858/