Nowadays, most organizations and businesses develop online services, which add value to their business and even increase their customer base. Surveys and reviews have changed the dynamics of digital marketing. The feedback platform gave the power to customers to post, share, and review content. Customers can directly interact with other customers and companies.There are many companies that use public opinion to be able to achieve the goals of the company. 20-30 companies in the United States of America offer sentiment analysis as one of the tools to help corporate decision-making. Therefore, we use dynamic sentiment to discover additional information. This research uses dynamic sentiment because it can gather more precise and detailed result.
Along with the increasing number of internet, social media users and mobile devices will certainly impact on the increasing amount of data or user-generated content. The simple forms to collect opinions are application review and rating people give for their experience. With a massive information flows from social media, a highly effective approach is needed to summarize and retrieve information in a real-time situation. Several classification methods are suitable to analyze the data, such as Support Vector Machine (SVM), Naïve Bayes (NB), Nearest Neighbors (NN), Logistic Regression and Decision Tree. The model used to summarize is Naïve Bayes classification method.
We use topic modeling to determine topics that contained in the data. Numerous way of topic distribution is applicable such as Clustering, Feature Generation, and Dimensionality Reduction. Dimensionality reduction has an advantage compared to the other because each document’s distribution over topics gives a summary of the document. Compare them in this reduce feature space can be more meaningful than comparing in the original feature space.
Uber is one of the largest and greatest innovation in transport with its fast development, the interaction among user in the platform is high.In this research, we aim to dig further information from the dataset. We see the topics from the public opinion perspective in application reviews and ratings, especially their opinion regarding Uber, the sentiment is surely changing every day then which topic has positive or negative sentiment. This is useful for data processing to be more effective and fast.
What are research questions?
In this research, we will analyze huge user-generated content which can be used by organizations for their customer engagement strategies.The purpose of this study is to to map the public opinion towards certain topic by analyzing the sentiment of the text and create a topic model. The reviews feedback provide a lot of information about the product experience, any technical or operational gaps, and even their general sentiment towards the product company. The analysis will help in identifying the gaps in the priorities of the stakeholders. With the right customer engagement strategies, companies can make benefit.
We pick Uber as the case study, viewed as one of the most favored transportation methods in most part of the world to do the following search question.
Analyse the user’s sentiments with Uber cabs.
Problems faced by customers.
How are the data collected?
Collected the data from play store reviews. I scrapped the latest 50,000 reviews from there irrespective of the rating. https://play.google.com/store/apps/details?id=com.ubercab
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting bertopic
Downloading bertopic-0.12.0-py2.py3-none-any.whl (90 kB)
|████████████████████████████████| 90 kB 4.0 MB/s
Requirement already satisfied: scikit-learn>=0.22.2.post1 in /usr/local/lib/python3.7/dist-packages (from bertopic) (1.0.2)
Collecting pyyaml<6.0
Downloading PyYAML-5.4.1-cp37-cp37m-manylinux1_x86_64.whl (636 kB)
|████████████████████████████████| 636 kB 28.0 MB/s
Collecting hdbscan>=0.8.28
Downloading hdbscan-0.8.29.tar.gz (5.2 MB)
|████████████████████████████████| 5.2 MB 36.0 MB/s
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Collecting sentence-transformers>=0.4.1
Downloading sentence-transformers-2.2.2.tar.gz (85 kB)
|████████████████████████████████| 85 kB 4.7 MB/s
Collecting umap-learn>=0.5.0
Downloading umap-learn-0.5.3.tar.gz (88 kB)
|████████████████████████████████| 88 kB 7.4 MB/s
Requirement already satisfied: tqdm>=4.41.1 in /usr/local/lib/python3.7/dist-packages (from bertopic) (4.64.1)
Requirement already satisfied: numpy>=1.20.0 in /usr/local/lib/python3.7/dist-packages (from bertopic) (1.21.6)
Requirement already satisfied: plotly>=4.7.0 in /usr/local/lib/python3.7/dist-packages (from bertopic) (5.5.0)
Requirement already satisfied: pandas>=1.1.5 in /usr/local/lib/python3.7/dist-packages (from bertopic) (1.3.5)
Requirement already satisfied: scipy>=1.0 in /usr/local/lib/python3.7/dist-packages (from hdbscan>=0.8.28->bertopic) (1.7.3)
Requirement already satisfied: cython>=0.27 in /usr/local/lib/python3.7/dist-packages (from hdbscan>=0.8.28->bertopic) (0.29.32)
Requirement already satisfied: joblib>=1.0 in /usr/local/lib/python3.7/dist-packages (from hdbscan>=0.8.28->bertopic) (1.2.0)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=1.1.5->bertopic) (2.8.2)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas>=1.1.5->bertopic) (2022.6)
Requirement already satisfied: tenacity>=6.2.0 in /usr/local/lib/python3.7/dist-packages (from plotly>=4.7.0->bertopic) (8.1.0)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from plotly>=4.7.0->bertopic) (1.15.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.22.2.post1->bertopic) (3.1.0)
Collecting transformers<5.0.0,>=4.6.0
Downloading transformers-4.24.0-py3-none-any.whl (5.5 MB)
|████████████████████████████████| 5.5 MB 48.7 MB/s
Requirement already satisfied: torch>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.4.1->bertopic) (1.12.1+cu113)
Requirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.4.1->bertopic) (0.13.1+cu113)
Requirement already satisfied: nltk in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.4.1->bertopic) (3.7)
Collecting sentencepiece
Downloading sentencepiece-0.1.97-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)
|████████████████████████████████| 1.3 MB 65.0 MB/s
Collecting huggingface-hub>=0.4.0
Downloading huggingface_hub-0.11.0-py3-none-any.whl (182 kB)
|████████████████████████████████| 182 kB 62.2 MB/s
Requirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (4.13.0)
Requirement already satisfied: packaging>=20.9 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (21.3)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (2.23.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (3.8.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (4.1.1)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=20.9->huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (3.0.9)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers<5.0.0,>=4.6.0->sentence-transformers>=0.4.1->bertopic) (2022.6.2)
Collecting tokenizers!=0.11.3,<0.14,>=0.11.1
Downloading tokenizers-0.13.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (7.6 MB)
|████████████████████████████████| 7.6 MB 38.9 MB/s
Requirement already satisfied: numba>=0.49 in /usr/local/lib/python3.7/dist-packages (from umap-learn>=0.5.0->bertopic) (0.56.4)
Collecting pynndescent>=0.5
Downloading pynndescent-0.5.8.tar.gz (1.1 MB)
|████████████████████████████████| 1.1 MB 55.1 MB/s
Requirement already satisfied: llvmlite<0.40,>=0.39.0dev0 in /usr/local/lib/python3.7/dist-packages (from numba>=0.49->umap-learn>=0.5.0->bertopic) (0.39.1)
Requirement already satisfied: setuptools in /usr/local/lib/python3.7/dist-packages (from numba>=0.49->umap-learn>=0.5.0->bertopic) (57.4.0)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (3.10.0)
Requirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from nltk->sentence-transformers>=0.4.1->bertopic) (7.1.2)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (1.24.3)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (3.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (2022.9.24)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.4.1->bertopic) (2.10)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision->sentence-transformers>=0.4.1->bertopic) (7.1.2)
Building wheels for collected packages: hdbscan, sentence-transformers, umap-learn, pynndescent
Building wheel for hdbscan (PEP 517) ... done
Created wheel for hdbscan: filename=hdbscan-0.8.29-cp37-cp37m-linux_x86_64.whl size=2340708 sha256=53bc0bb953e90a895585f195baa09e9fd9290730256b66ca6d2efb6b0bc549d6
Stored in directory: /root/.cache/pip/wheels/93/78/2e/03ee191669a772e9653260aa3bd53e0b1a768751a9676e8c82
Building wheel for sentence-transformers (setup.py) ... done
Created wheel for sentence-transformers: filename=sentence_transformers-2.2.2-py3-none-any.whl size=125938 sha256=fd02db609451a465d4881555fa549ba0b011e12b20d3316257394406ef022e1d
Stored in directory: /root/.cache/pip/wheels/bf/06/fb/d59c1e5bd1dac7f6cf61ec0036cc3a10ab8fecaa6b2c3d3ee9
Building wheel for umap-learn (setup.py) ... done
Created wheel for umap-learn: filename=umap_learn-0.5.3-py3-none-any.whl size=82829 sha256=cf40e4ca256f56196492c8a9f957d3b481b2577f4d67838ebb9e02fc9b93fd1d
Stored in directory: /root/.cache/pip/wheels/b3/52/a5/1fd9e3e76a7ab34f134c07469cd6f16e27ef3a37aeff1fe821
Building wheel for pynndescent (setup.py) ... done
Created wheel for pynndescent: filename=pynndescent-0.5.8-py3-none-any.whl size=55513 sha256=a48b42f5614e9fe1afb301bec6e786fc4ea496358e8afe424ca6502185322ddc
Stored in directory: /root/.cache/pip/wheels/19/bc/eb/974072a56a7082a302f8b4be1ad6d21bf5019235c2eff65928
Successfully built hdbscan sentence-transformers umap-learn pynndescent
Installing collected packages: pyyaml, tokenizers, huggingface-hub, transformers, sentencepiece, pynndescent, umap-learn, sentence-transformers, hdbscan, bertopic
Attempting uninstall: pyyaml
Found existing installation: PyYAML 6.0
Uninstalling PyYAML-6.0:
Successfully uninstalled PyYAML-6.0
Successfully installed bertopic-0.12.0 hdbscan-0.8.29 huggingface-hub-0.11.0 pynndescent-0.5.8 pyyaml-5.4.1 sentence-transformers-2.2.2 sentencepiece-0.1.97 tokenizers-0.13.2 transformers-4.24.0 umap-learn-0.5.3
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting google-play-scraper
Downloading google_play_scraper-1.2.2-py3-none-any.whl (28 kB)
Installing collected packages: google-play-scraper
Successfully installed google-play-scraper-1.2.2
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting keybert
Downloading keybert-0.7.0.tar.gz (21 kB)
Requirement already satisfied: sentence-transformers>=0.3.8 in /usr/local/lib/python3.7/dist-packages (from keybert) (2.2.2)
Requirement already satisfied: scikit-learn>=0.22.2 in /usr/local/lib/python3.7/dist-packages (from keybert) (1.0.2)
Requirement already satisfied: numpy>=1.18.5 in /usr/local/lib/python3.7/dist-packages (from keybert) (1.21.6)
Collecting rich>=10.4.0
Downloading rich-12.6.0-py3-none-any.whl (237 kB)
|████████████████████████████████| 237 kB 6.6 MB/s
Requirement already satisfied: typing-extensions<5.0,>=4.0.0 in /usr/local/lib/python3.7/dist-packages (from rich>=10.4.0->keybert) (4.1.1)
Requirement already satisfied: pygments<3.0.0,>=2.6.0 in /usr/local/lib/python3.7/dist-packages (from rich>=10.4.0->keybert) (2.6.1)
Collecting commonmark<0.10.0,>=0.9.0
Downloading commonmark-0.9.1-py2.py3-none-any.whl (51 kB)
|████████████████████████████████| 51 kB 6.9 MB/s
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.22.2->keybert) (1.2.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.22.2->keybert) (3.1.0)
Requirement already satisfied: scipy>=1.1.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.22.2->keybert) (1.7.3)
Requirement already satisfied: torch>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (1.12.1+cu113)
Requirement already satisfied: nltk in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (3.7)
Requirement already satisfied: transformers<5.0.0,>=4.6.0 in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (4.24.0)
Requirement already satisfied: tqdm in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (4.64.1)
Requirement already satisfied: sentencepiece in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (0.1.97)
Requirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (0.13.1+cu113)
Requirement already satisfied: huggingface-hub>=0.4.0 in /usr/local/lib/python3.7/dist-packages (from sentence-transformers>=0.3.8->keybert) (0.11.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (3.8.0)
Requirement already satisfied: packaging>=20.9 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (21.3)
Requirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (4.13.0)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (2.23.0)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.7/dist-packages (from huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (5.4.1)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=20.9->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (3.0.9)
Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in /usr/local/lib/python3.7/dist-packages (from transformers<5.0.0,>=4.6.0->sentence-transformers>=0.3.8->keybert) (0.13.2)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.7/dist-packages (from transformers<5.0.0,>=4.6.0->sentence-transformers>=0.3.8->keybert) (2022.6.2)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (3.10.0)
Requirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from nltk->sentence-transformers>=0.3.8->keybert) (7.1.2)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (2022.9.24)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (2.10)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->huggingface-hub>=0.4.0->sentence-transformers>=0.3.8->keybert) (1.24.3)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision->sentence-transformers>=0.3.8->keybert) (7.1.2)
Building wheels for collected packages: keybert
Building wheel for keybert (setup.py) ... done
Created wheel for keybert: filename=keybert-0.7.0-py3-none-any.whl size=23800 sha256=49508069c4659c598fcc32b73d6a40c49e6a426b25ee97908a6715614d5f3c5e
Stored in directory: /root/.cache/pip/wheels/85/0d/12/77d219f3ebbb22dc22234b4d665886c0eace86a26eca0aa72b
Successfully built keybert
Installing collected packages: commonmark, rich, keybert
Successfully installed commonmark-0.9.1 keybert-0.7.0 rich-12.6.0
#importing the required packagesfrom google_play_scraper import Sort, reviewsimport pandas as pdfrom bertopic import BERTopicfrom google.colab import files
#strings#go to google play store: https://play.google.com/store/apps#go to playstore app page#copy the app id id={appid}appURL ='com.ubercab'
#scraping reviews from google play storeresult, continuation_token = reviews( appURL, #app url lang='en', #language country='us', #country sort=Sort.NEWEST, count =50000,# filter_score_with = 1 # defaults to None(means all score))result, _ = reviews( appURL, continuation_token=continuation_token)
#putting everything into a dataframedf = pd.DataFrame(result)
import pandas as pd
#df1 = pd.read_csv('_data/uberData.csv')#df1
Discription
In this post, I will focus on cleaning and pre-processing my data into a format that is useful for analysis. This post will specifically focus on cleaning the content of the reviews, pre-processing them in python, then trying out different descriptives.
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Error loading en: Package 'en' not found in index
[nltk_data] Downloading package wordnet to /root/nltk_data...
[nltk_data] Downloading package omw-1.4 to /root/nltk_data...
[nltk_data] Downloading package words to /root/nltk_data...
[nltk_data] Unzipping corpora/words.zip.
def tokenize( data ): data1 = data.map(lambda x: word_tokenize(x))return data1def removeStopwords( data ): stop_words =set(stopwords.words('english')) data1 = data.map(lambda x: [ w for w in x if w.lower() notin stop_words ])return data1def lemmatize( data ): lemmatizer = WordNetLemmatizer() lemma_words = [ lemmatizer.lemmatize(w, pos='a') for w in data ]return lemma_words# def stemming( data ):# ps = PorterStemmer()# stemmed_words = [ ps.stem(w) for w in data ]# return stemmed_wordsdef cleaning_data(data): data = data.map(lambda x: re.sub(r'\d+', ' ', x)) # Remove numbers data = data.map(lambda x: x.translate(x.maketrans('', '', string.punctuation))) # Remove Punctuation data = data.map(lambda x: x.strip()) # Remove white spaces data = tokenize( data ) data = removeStopwords( data ) data = data.map(lambda x: [w for w in x if w.isalpha()]) # Remove non alphabetic tokens data = data.map(lambda x: [w for w in x iflen(w)>3 ]) #Removing small strings data = data.map(lambda x: ' '.join(x)) # turning back to string words =set(nltk.corpus.words.words()) data = data.map(lambda x: [ w for w in nltk.wordpunct_tokenize(x) if w.lower() in words ]) # Remove non english words data = data.map(lambda x: ' '.join(x)) # turning back to stringreturn datadf['content'] = lemmatize ( cleaning_data(df['content']) )df = df.loc[df['content']!=''] #remove rows with empty content value
Word Cloud Plot
Word cloud is a technique for visualising frequent words in a text where the size of the words represents their frequency. Here we are trying to find common words in postive,negative and neutral reviews.
def scoreToSentiment(df): data = df['score']if data<=2:return"negative"elif data==3:return"neutral"else:return"positive"df['sentiment'] = df.apply(lambda x : scoreToSentiment(x), axis =1)
def wordcloudPlot(data, color ='grey'): words =' '.join(data) cleaned_word =" ".join([word for word in words.split()if'http'notin wordandnot word.startswith('#')and word !='RT' ]) wordcloud = WordCloud(stopwords=STOPWORDS, background_color=color, width=2500, height=2000 ).generate(cleaned_word) plt.figure(1,figsize=(13, 13)) plt.imshow(wordcloud) plt.axis('off') plt.show()print(wordcloudPlot(df['content']))
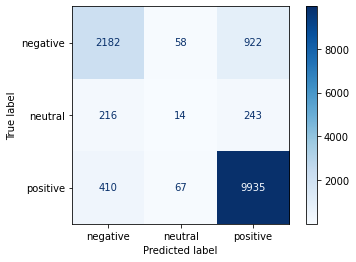
Sentiment analysis is contextual mining of text which identifies and extracts subjective information in source material, and helping a business to understand the social sentiment of their brand, product or service while monitoring online conversations.
The same logic we are using to extract the contextual information from the reviews of uber to analys the what people think about uber.
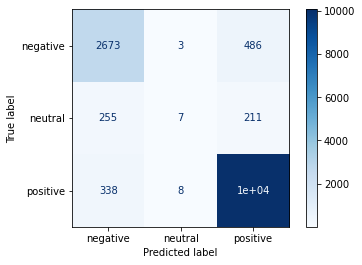
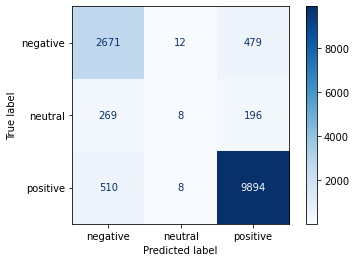
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics import confusion_matrix, classification_report, accuracy_scorefrom sklearn.model_selection import train_test_splitimport numpy as npimport seaborn as snsvectorizer = TfidfVectorizer(max_features=50000)X = vectorizer.fit_transform(df['content']).toarray()Y = df['sentiment']X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size =0.3, random_state =True )